
基于深度学习的文本分类研究综述
2024-01-09 09:01:26汪家伟
电子科技 2024年1期
汪家伟,余 晓
(1.东南大学 网络空间安全学院,江苏 南京 210096;2.东南大学 继续教育学院,江苏 南京 210096)
文本分类指用计算机对文本按照一定的分类标准进行自动分类标记。随着互联网的发展,信息量快速增长,人工标注数据耗时、质量低下,且易受到标注人主观意识的影响,因此利用机器自动化地实现对文本的标注具有现实意义。将重复且枯燥的文本标注任务由计算机进行处理能够有效克服以上问题,同时所标注的数据具有一致性、高质量等特点。文本分类的应用场景众多,包括词性标注、情感分析、意图识别、主题分类、问答任务和自然语言推理等。
深度学习是一种机器学习方法,通过结合多层次神经网络,计算机能自动完成学习过程。与传统的机器学习相比,深度学习不仅减少了面对不同问题时的人工设计成本,实现了自动化的机器学习,还针对数据中的潜在信息提升了对其提取和分析的能力。本文对当前深度学习在文本分类领域的发展展开综述性讨论,详细阐述了目前文本分类的研究进展和最新的技术方法。
1 基于传统模型的文本分类方法
不同于数值、图像或信号数据,文本数据需要利用自然语言处理技术(Natural Language Processing, NLP)提取文本特征。传统模型通常需要通过人工方法获得良好的样本特征,然后用经典机器学习算法进行分类。因此,该方法的有效性在较大程度上受到特征提取的限制。
在过去几年,传统的文本分类模型占主导地位。传统方法是指基于统计的模型,例如朴素贝叶斯(Naive Bayes, NB),K-最近邻(K-Nearest Neighbor, KNN)和支持向量机(Support Vector Machine, SVM)。NB的参数较小,对缺失数据不太敏感,算法简单,但其假定特征之间相互独立。当特征数量较大或特征之间相关性显著时,NB的性能下降。支持向量机可以解决高维和非线性问题,具有较高的泛化能力,但对缺失数据较敏感。KNN主要依靠周围有限的相邻样本,而不是区分类域来确定类别。因此,对于要用类域的交叉或重叠进行划分的数据集,它比其他方法更适合。基于传统模型的方法从数据中学习,这些数据是对预测值性能较重要的预定义特征。然而,特征工程是一项重要且复杂的工作。在训练分类器之前,研究人员需要收集知识或经验以从原始文本中提取特征。此外,这些方法通常忽略文本数据中的自然顺序结构或上下文信息,使学习单词的语义信息具有挑战性。
2 深度学习概述
深度学习[1]是机器学习的一个新领域。与传统的浅层模型不同,深度学习模型结构相对复杂,不依赖于人工获取的文本特征,可以直接对文本内容进行学习、建模。其次,深度学习阐明了特征学习的重要性,并通过逐层特征变换将样本在原空间的特征表示转换为新的特征空间,从而使NLP更容易。
2.1 循环神经网络
循环神经网络(Recurrent Neural Networks, RNN)能挖掘数据中的时序信息和语义信息,故其能有效处理具有序列特性的数据。
如图1所示,RNN的基本结构由输入层、隐藏层和输出层组成。RNN在处理数据时,每次计算都将当前层的输出送入下一层的隐藏层中,并和下一层的输入一起计算输出。虽然RNN在处理序列数据上具有良好的性能,但对长期的记忆影响较小,不能应对输入较长的情况。
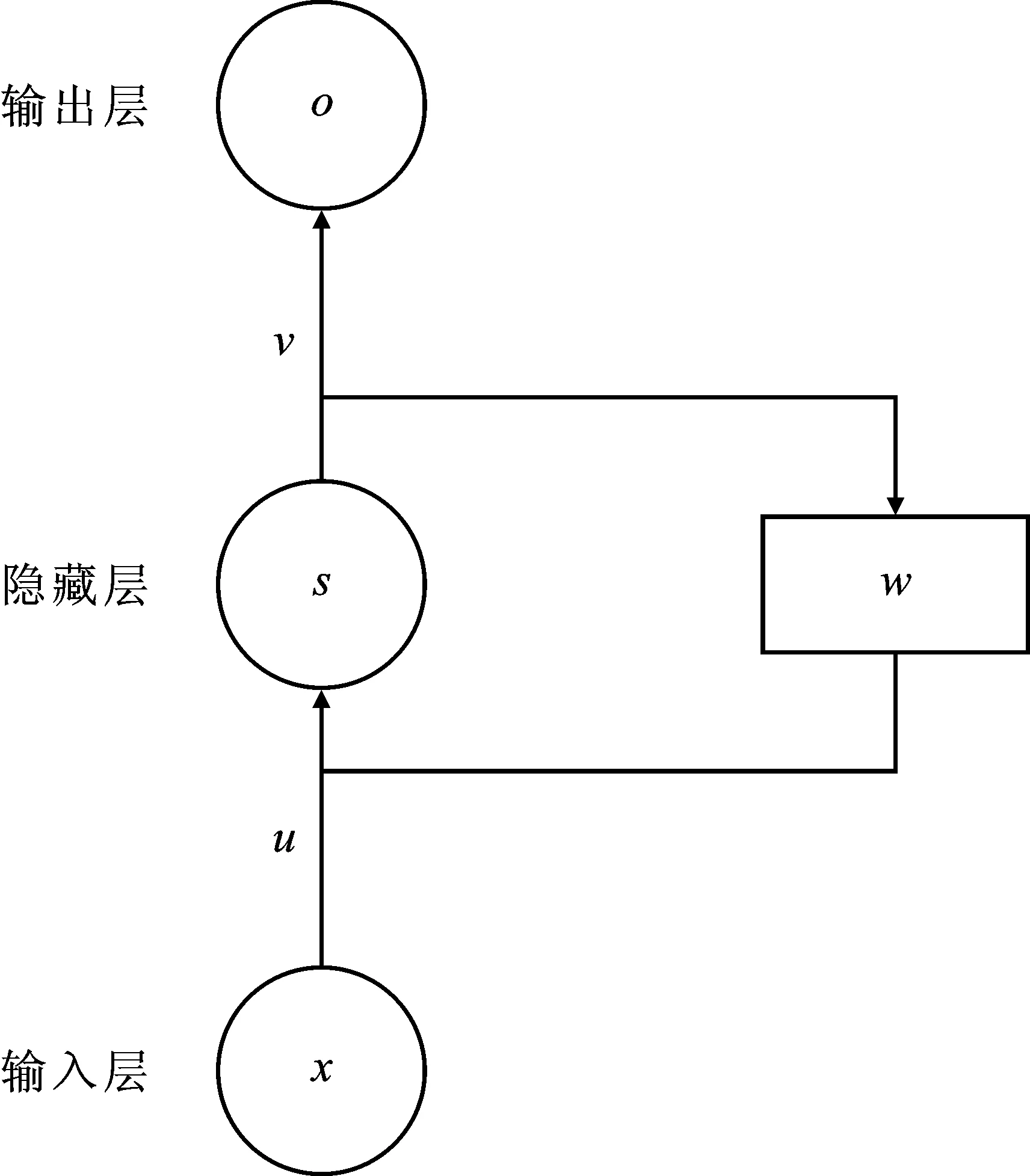
图1 循环神经网络结构Figure 1. Structure of RNN
2.2 长短期记忆网络
长短期记忆网络(Long Short-Term Memory, LSTM)[2]作为特殊的RNN,在长序列训练任务中表现更好。LSTM主要有遗忘阶段、选择记忆阶段和输出阶段,遗忘阶段主要是选择性遗忘上一个节点传过来的输出,选择记忆阶段对当前阶段的输入进行选择性的进行记忆,输出阶段决定被当成当前阶段的输出。LSTM的传输状态通过门控状态来控制。
2.3 卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)的主要特点在于权值共享与局部连接两个方面[3]。作为一种前馈神经网络,CNN一般用于处理图像数据。对一张输入的图片,CNN使用一个卷积核来扫描图片,卷积核里的数就是权重,图片的每个位置被相同的卷积核扫描就叫做权值共享。对图像来说,每个神经元只需要感知当前网络层的局部信息,而全局信息可以由低层的局部信息综合获取。局部连接可以减少参数量,提高训练效率。
卷积神经网络的结构如图2所示。与处理图像不同,在自然语言处理领域,需要将CNN的输入转换成矩阵表示的句子或文档。矩阵的每一行对应于一个元素的向量表示,向量可以是单词,也可以是字符。向量可以通过词嵌入或one-hot编码形式获得。卷积层是CNN中的重要组成部分,通过卷积运算卷积层的每一个节点对应上一层网络的局部信息,其目的是关注输入图片或者文本的不同特征。在处理文本序列问题时,通过改变卷积核的大小能帮助提取文本序列中的不同特征。与卷积层的操作类似,池化层也使用卷积核提取特征,但池化层的卷积核只取对应位置的最大值或平均值。池化层不断减少参数数量,不仅可以提高计算速度和减少计算量,一定程度上也控制了过拟合。在卷积层和池化层之后,CNN一般加上一个全连接层,该层的主要作用是降维,并且保留有用信息。向量通过卷积层和池化层之后,相当于自动完成了特征提取,在特征提取后,可以传输到输出层完成对应的下游任务,例如分类或预测。
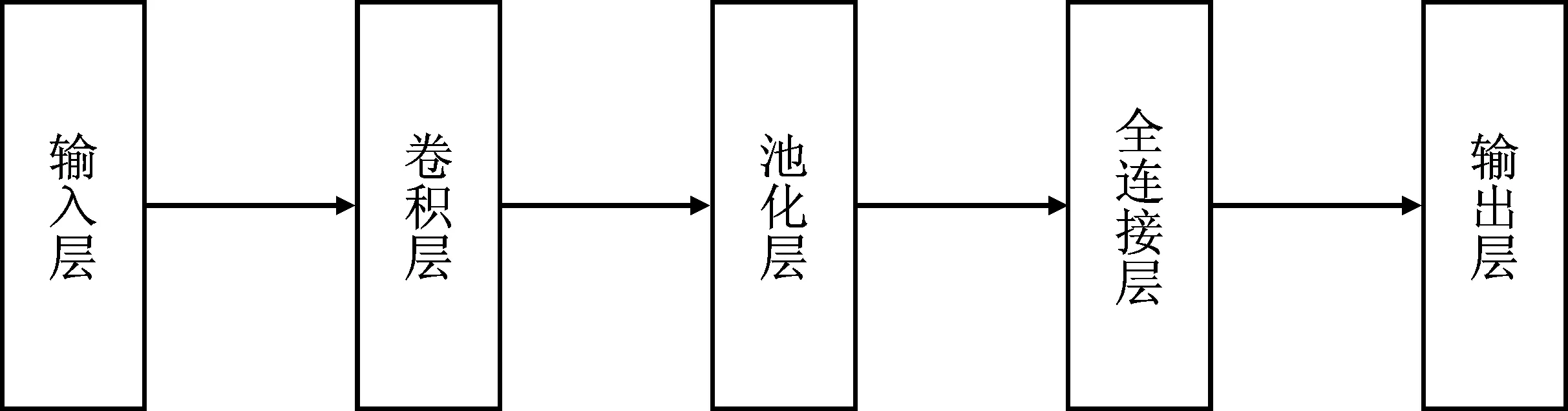
图2 卷积神经网络结构Figure 2. Structure of CNN
2.4 预训练方法
预训练的语言模型[4]有效学习了全局语义表示并且明显提升了自然语言处理任务的性能。首先通过自监督学习获得预训练模型,然后预训练模型针对具体的任务修正网络。
ELMo(Embeddings from Lauguage Models)[5]是一个使用双向LSTM的词表示模型,具有深度上下文化的特征并且易集成到模型中。通过使用双向LSTM并FGPT根据上下文学习每个词嵌入,可以对单词的复杂特征进行建模,并为各种语言上下文学习不同的表示。GPT(Generative Pre-Training Transformer)[6]算法包含两个阶段,即预训练和微调。GPT算法的训练过程通常包括两个阶段:1)神经网络模型的初始参数由建模目标在未标记的数据集上学习;2)根据具体的任务,通过有标签的数据对模型进行微调。BERT(Bidirectional Encoder Representation from Transformers)模型[7]增强了NLP任务的性能。BERT应用双向编码器,旨在通过联合调整所有层中的上下文来预训练深度的双向表示,其可以在预测被屏蔽单词时利用上下文信息。为进行微调,可以通过添加一个额外的输出层来微调多个NLP任务构建模型。
2.5 图神经网络
图神经网络(Graph Neural Network,GNN)[8]是近年来出现的一种利用深度学习直接对图结构数据进行学习的框架,其优异的性能引起了研究人员的高度关注和深入探索。通过在图中的节点和边上制定一定策略,GNN将图结构数据转化为规范而标准的表示,并输入到多种不同的神经网络中进行训练,在节点分类、边信息传播和图聚类等任务上取得了优良的效果。基于GNN的模型通过对句子的句法结构进行编码,在语义角色标记任务、关系分类任务和机器翻译任务上展现了较佳的性能。
DGCNN(Dilate Gated Convolutional Neural Network)[9]能将文本转换为词图结构,具有使用CNN模型学习不同级别语义的优势。TextGCN[10]为整个数据集构建了一个异构的词文本图并捕获了全局词共现信息。TextING[11]通过GNN的方法,为每个文档构建单独的图,并学习文本级单词交互,有效地为新文本中的晦涩单词生成嵌入。
3 文本分类研究进展
文本分类主要研究内容包括情感分析、话题标记、新闻分类、问答系统、对话行为分类、自然语言推理、关系分类以及事件预测等。
3.1 基于RNN方法
文献[12]提出了BiLSTM-CRF(Bi-directional Long Short-Term Memory-Conditional Random Field)模型并将其应用到基于方面的情感分析任务中。利用双向长短期记忆网络可以捕获长距离双向语义依赖关系并且能学习文本语义信息的特点,预测句子级别的全局最佳标签序列。文献[13]提出了上下文推理网络进行对话情绪识别,从认知角度充分理解会话上下文。其还设计了多轮推理模块来提取和整合情绪线索。文献[14]展示了文档可以表示为带有语义含义的向量序列,并使用识别远程关系的循环神经网络进行分类。在该表示中,额外的情感向量可以较容易地作为一个完全连接的层附加到词向量上,以进一步提高分类准确性。文献[15]使用Word2Vec工具对语料库进行训练,得到文本词向量表示后使用引入注意力机制的LSTM模型进行文本特征提取,结合交叉熵训练模型并将模型应用到旅游问题文本分类方法中。
RNN是顺序计算,不能并行计算。RNN的缺点使在当前模型趋于具有更深和更多参数的趋势中成为主流更具挑战性。
3.2 基于CNN方法
文献[16]通过创建接受无序和可变长度池的并行CNN,并在创建双向LSTM时移除了输入/输出门,改进了传统的深度学习方法。该方法使用4个基准数据集进行主题和情感分类。文献[17]将上下文相关特征与基于时间卷积网络(Temporal Convolutional Network,TCN)和CNN的多阶段注意力模型相结合提出了一种新的短文本分类方法。该模型解决了短文本的数据稀疏性和歧义性,并且通过提高模型的并行化以提高效率。文献[18]提出了一种基于CNN的架构TextConvoNet,不仅可以提取句内n-gram特征,还可以捕获输入文本数据中的句间n-gram特征。
CNN通过卷积核从文本向量中提取特征。卷积核捕获的特征数量与其大小有关。CNN由多层神经网络组成,层次足够深,理论上其可以捕获远距离的特征。与RNN相比,CNN具有并行计算能力,可以有效地为改进版的CNN保留位置信息。它对于长距离的特征捕捉能力仍然较弱。
3.3 基于GNN方法
随着图形神经网络受到日益关注,基于GNN的模型通过对文本分类任务中的句子句法结构进行编码获得了优异的性能。
文献[19]提出了一种双图卷积网络模型用于基于方面的情感分析,该模型同时考虑了句法结构的互补性和语义相关性。文献[20]提出了一种使用有向无环图对词语进行编码的想法,并设计了一个有向无环神经网络来实现该想法。该模型提供了一种更为直观的方法来模拟远程对话背景和附近上下文之间的信息流。文献[21]提出了一种新的基于图的方法,通过利用常识知识来建模情感触发路径,以增强候选子句和情感子句之间的语义依赖关系。文献[22]提出了一种用于多标签文本分类的模型,该模型使用图形数据库存储文档。使用标准字典对文档进行预处理,然后生成分类字典,分类字典用于生成子图。该模型维护一个查找表以减少新文档的搜索空间。
GNN为文本构建图。当设计的图结构足够有效时,学习的表示可以更好地捕捉结构信息。
3.4 基于Attention方法
CNN和RNN在与文本分类相关的任务上提供了出色的结果。然而,这些模型不够直观,难以解释,尤其是在分类错误的情况下,由于隐藏数据的不可读性,分类错误无法解释,因此一些研究者将基于注意力的方法应用到了文本分类中。
文献[23]提出了一种使用两种新颖的深度学习架构的医学文本分类范式来对医学文本进行有效处理。第一种方法是利用4个通道实现四通道混合长短期记忆的深度学习模型。第二种方法是开发并实施了具有多头注意力的混合双向门控循环单元深度学习模型。文献[24]构建了FMNN(Fused with Multiple Neural Network)模型,该模型融合了多种神经网络模型的特性并使用Attention提取文本的全局语义特征。
3.5 基于预处理模型方法
文献[25]提出了一种基于BERT的文本分类模型BERT4TC。该模型通过构造辅助句将分类任务转化为二元句对,旨在解决训练数据受限问题和任务感知问题。文献[26]BERT模型捕捉审稿人的心理特征,并将其应用于短文本分类,以提高其分类准确率。
BERT学习一种语言表示法,可以用于对许多NLP任务进行微调。主要方法是增加数据,提高计算能力,并设计训练程序以获得更好的结果。
3.6 方法总结
在过去几年中,研究人员提出了较多用于文本分类的深度学习模型,如表1所示,将深度学习模型的主要信息制成表格用于文本分类。表1中的应用包括情感分析(Sentiment Analysis,SA)、主题标签(Topic Lable,TL)、基于方面的情感分析(Aspect-Based Sentiment Analysis,ASBA)、短文本分类(Short Text Classification,STC)、对话情绪识别(Emotion Recognition in Conversation,ERC)和情绪原因提取(Emotion Cause Extraction,ECE)。为提升模型分类的性能,研究人员尝试了,例如融合一些神经网络模型或注意力机制,或者改进常见的神经网络模型等方法。此外,一些研究人员研究了基于图神经网络(GNN)的文本分类技术,以捕获文本中的结构信息,其他方法无法替代。

表1 基于不同模型的文本分类方法
传统模型主要通过改进特征提取方案和分类器设计来提高文本分类性能。相比之下,深度学习模型通过改进演示学习方法、模型结构以及其他数据和知识来提高性能。
深度学习可以基于词和向量学习语言特征,掌握更高层次、更抽象的语言特征。深度学习架构不同于传统方法需要过多的人工干预和先验知识,可以直接学习输入中的特征表示。然而,深度学习以数据为驱动,该技术若要实现高性能,需要大量数据用于训练。
4 结束语
通过使用NLP、机器学习和其他技术,深度学习模型能自动进行不同的分类任务。文本分类的输入可以是多种不同类型的文本,经过预训练文本表示为向量。然后将训练好的词向量输入到网络模型中进行训练,将神经网络得到的输出通过下游任务验证,根据下游任务的结果计算训练模型的性能。现有模型已经显示出在文本分类中的有用性,但需探索改进之处。
该领域研究的难点在于模型的参数调整,较优的参数选择能方便模型的优化。但满足深度学习需要的庞大的训练数据仍然是一个难题。深度学习模型对训练数据量和运算时间的要求较高。深度神经网络的训练结果是否准确,主要取决于训练数据量是否足够庞大。同时,深度神经网络的训练时间随着网络模型的增大而增加,既能保持模型性能不变,又能将模型体积不断减小将是未来的一个研究方向。
深度学习是一种黑盒模型,训练过程难以重现,隐含语义和输出可解释性较差,使模型的改进和优化失去了明确的指导方针。除此之外,目前也无法准确解释深度学习模型性能提高的原因。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
