
基于时序异常检测的动力电池安全预警
2024-01-09 04:00张安勤王小慧
计算机应用 2023年12期
张安勤,王小慧*
基于时序异常检测的动力电池安全预警
张安勤1,2,王小慧1*
(1.上海电力大学 计算机科学与技术学院,上海 201306; 2.汕头大学地方政府发展研究所,广东 汕头 515063)(∗通信作者电子邮箱y21208007@mail.shiep.edu.cn)
电动汽车由于电池内部异常情况无法得到及时预测与预警,易导致事故发生,给驾驶员和乘客的生命和财产安全带来严重威胁。针对上述问题,提出基于Transformer和对比学习的编码器解码器(CT-ED)模型用于多元时间序列异常检测。首先,通过数据增强构造一个实例的不同视图,并利用对比学习捕获数据的局部不变特征;其次,基于Transformer对数据从时间依赖和特征依赖两方面进行编码;最后,通过解码器重构数据,计算重构误差作为异常得分,对实际工况下的机器进行异常检测。在SWaT、SMAP和MSL这3个公开数据集和电动汽车动力电池(EV)数据集上的实验结果表明,所提模型的F1值对比次优模型分别提升6.5%、1.8%、0.9%和7.1%。以上结果表明CT-ED适用于不同实际工况下的异常检测,平衡了异常检测的精确率和召回率。
时间序列;异常检测;对比学习;多头注意力;自动编码器
0 引言
由于温室效应,新能源汽车逐渐取代燃油汽车成为绿色出行的工具。电池作为汽车最主要的构成部分存在老化和滥用而导致爆炸的危险[1]。驾驶人的不良习惯可能会损害电动汽车动力电池的性能,因此需要对整车数据进行监控,对异常情况进行及时预警。
对于电池故障预警,研究人员基于实验室电池故障数据形成了初步的理论体系和解决方案。然而在电动汽车实际应用过程中运行工况的变化复杂,实验条件下所建立的风险报警机制难以应对实车工况下多因素耦合的故障现象[1]。并且传统电池诊断的方法大都需要进行特征工程,依赖人工设计的特征提取方法,需要有专业知识,同时每个方法都是针对具体故障,泛化能力及鲁棒性较差。
近年来,深度学习和大数据技术在医学、交通、自然语言领域均得到广泛应用,在新能源汽车领域也展现出良好的应用前景。深度学习主要是数据驱动进行特征提取,根据大量样本的学习得到深层的、数据集特定的特征表示,对数据集的表达更高效和准确,所提取的抽象特征鲁棒性更强,泛化能力更好。其中,多元时间序列异常检测技术通过监测物联网运营产生的大量高维传感器数据,检测数据是否含有不符合预期趋势的行为,及时发现机器的故障并修理[2],避免了故障机器持续运行而产生更大的损耗,推动了现代工业和智慧城市的发展。电动汽车在实际运行中,也产生了大量多维时间序列,因此可以将时间序列异常检测领域的技术和大数据背景下的动力电池故障预警结合起来,监测电动汽车在行驶状态下的动力电池数据,对异常情况进行及时预警。
实际工况下的时间序列异常检测通常存在如下挑战:1)数据通常是没有标签的,并且异常类型繁多;2)传感器在运行过程中和数据传输到系统中都会产生噪声,可能导致模型产生错误报警;3)现有的异常检测方法大都需要人工设定阈值。大量研究使用无监督模型重构数据,利用重构误差作为异常指标判断数据,通常训练数据为不包含异常的正常数据,因此模型可以学习到传感器的正常行为模式,对异常数据进行重构时可能产生较大误差,从而检测到异常情况。传感器的正常行为模式通常是不变的,若数据分布产生变化,可以参考文献[3]中使用迁移学习训练新的模型,实现模型的动态更新。经典的无监督模型,比如基于聚类的K均值算法忽视了数据的时间依赖,而能捕获时间相关性的基于循环神经网络(Recurrent Neural Network, RNN)[4]的相关模型缺少对特征之间依赖关系的捕获[5]。由于交通路况的复杂和驾驶人的驾驶习惯不同,电动汽车行驶状态下的动力电池数据相较于其他多元时间序列的动态性更强。
基于以上思考,本文提出了基于Transformer[6]和对比学习[7]的编码器解码器结构。对比学习作为自监督学习通过缩小不同形式相同数据来源的编码距离学习数据的一般特征,Transformer在自然语言处理和图像中均取得了广泛应用,它通过多头注意力机制和位置编码函数捕获数据的时间依赖和数据之间的相关性。利用以上技术,针对数据缺少异常标签、含有时间依赖和特征依赖、动态性较强的3个特点进行建模,并对几种不同的阈值调整方法进行了对比。
本文的主要工作如下:
1)提出一种新的基于Transformer和对比学习的编码器解码器(Contrastive Transformer Encoder Decoder, CT-ED)模型用于多元时间序列异常检测,对原始数据进行频域数据增强构建一个实例的不同视图,利用对比学习增强模型捕获动态时间序列中不变特征的能力并对比了不同数据增强方式的性能。
2)结合Transformer和SENet(Squeeze and Excitation Network)[8]对数据进行时间依赖和特征相关性两方面的编码,使模型编码表示更加全面。使用一次性解码重构数据,利用重构偏差作为异常得分。
3)在3个公共数据集和电动汽车动力电池(Electric Vehicle power battery, EV)数据集上进行大量实验,评估CT-ED的性能,实验结果表明,CT-ED的性能优于其他基线模型。
1 相关工作
1.1 多元时间序列异常检测
传统的多元时间序列异常检测采用统计学方法或者经典机器学习方法对数据分布建模。这些方法通常效率较高,但不能有效捕捉数据的时间依赖性。
最近基于深度学习的方法在多元时间序列异常检测方面取得了显著的进步。根据所使用的技术可以分为基于时间的方法、基于相关性的方法和综合方法。
基于时间的方法 大部分依赖RNN相关模型,比如长短期记忆(Long Short-Term Memory, LSTM)网络和门控循环单元(Gated Recurrent Unit, GRU)。文献[4]中提出了长短期记忆非参数动态阈值(LSTM-Nonparametric Dynamic Thresholding, LSTM-NDT)算法,利用LSTM构造编码器解码器结构,并基于预测误差提出自动阈值调整方法检测异常。文献[9-11]中采用不同的方式组合LSTM和变分自动编码器(Variational Auto-Encoder, VAE),增加了重构数据的多样性。文献[12]中提出了多变量异常检测生成对抗网络(Multivariate-Anomaly Detection with Generative Adversarial Networks, MAD-GAN),采用了生成式对抗网络(Generative Adversarial Networks, GAN)框架,利用LSTM作为生成器和鉴别器捕获时间依赖;然而在原始GAN的结构中,随机采样的向量重构的数据和需要检测的时间序列片段在隐空间(Latent Space)可能是不对应的,因此在检测阶段需要迭代寻找对应的向量,比较耗时。文献[13]中提出了随机递归神经网络OmniAnomaly,将GRU和VAE进行有效融合,利用相对熵(Kullback-Leibler Divergence,KL散度)学习数据在隐空间的分布,可以有效地重构数据。
基于相关性的方法 文献[14]中提出了多尺度卷积循环编码器解码器(Multi-Scale Convolutional Recurrent Encoder-Decoder, MSCRED)网络,构造不同窗口大小的多元时间序列相关性矩阵,通过LSTM变体获得数据的时间依赖和特征相关性,但该模型不适用于维度较少或者相关性较低的数据。文献[15]中提出的图偏差网络(Graph Deviation Network, GDN)和文献[16]中提出的多元时间序列异常检测图注意力网络(Multivariate Time-series Anomaly Detection via Graph ATtention network, MTAD-GAT),通过图注意力机制学习传感器和相关传感器之间的关系。
综合方法 文献[17]中提出的无监督异常检测(Unsupervised Anomaly Detection,USAD)模型参考GAN的思想,提出了一种同步对抗式训练策略放大正常和异常数据之间的差异,可以适应训练数据中含有少量的异常样本的情况,仅使用全连接层构成编码器和解码器。Transformer在自然语言领域的广泛应用证实了它在序列数据上的优越性,因此也有不少基于Transformer的异常检测模型,比如:文献[2]中提出的基于Transformer的异常检测(Transformer-based Anomaly Detection, TranAD)模型在Transformer基础上通过同步对抗式训练和自调节技术提高性能,不依赖RNN模型,具有很高的效率。文献[18]中提出多尺度基于Transformer的残差变分自动编码器(Multiscale Transformer-based Residual VAE, MTRVAE)在VAE的基础上,使用Transformer的自注意力机制捕获序列之间的潜在相关性,并通过改进的位置编码和上采样算法捕获多尺度时间信息,通过残差连接抵抗KL散度消失问题。文献[5]中提出对比自动编码器(Contrastive AutoEncoder for Anomaly Detection,CAE-AD)模型,通过多粒度对比方法捕获数据的时间相关性和局部不变特征。
1.2 Transformer
Transformer主要由多头自注意力机制和前馈层通过残差连接组成,模型结构是自动编码器。一段时间序列长度为、特征维度为的时序数据,通过不同的线性映射后得到、、,注意力计算如式(1)所示:
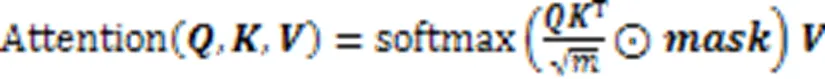
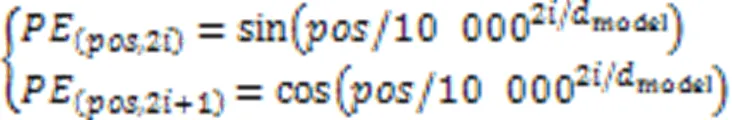
其中:是数据在滑动窗口中的位置,是一个时间戳中不同特征的位置,model是模型的特征维度。
2 动力电池异常检测模型
2.1 问题定义
对每个时间序列片段进行重构得到异常分数,当异常分数超过某个阈值时,判断该时间点为异常。
2.2 模型框架
CT-ED模型整体框架如图1所示。首先,针对数据的动态性,通过频域增强创建一个实例的不同视图作为一对正例,利用对比学习捕获数据的局部不变特征;其次,针对数据的时间依赖和特征依赖,通过多尺度卷积学习时间片段中不同范围的特征、编码器的时间模块和特征模块捕获卷积结果在时间维度和特征维度上的相关性;最后,模型的解码器结合编码器输出对数据进行重构。
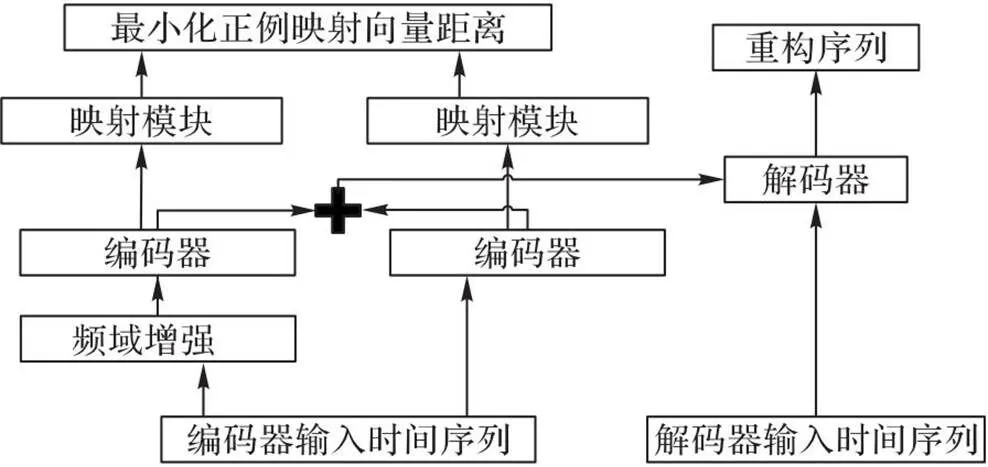
图1 CT-ED模型整体框架
2.3 频域数据增强
在信号处理中,时序数据可以从时域和频域两个角度分析。有时,时域上复杂的信号从频域角度看会比较简单,因此对于时间序列的数据增强方式也可以从时域和频域两个角度进行。模型CAE-AD[5]将数据通过注意力机制映射后,从时域和频域两个角度进行数据增强。由于传感器数据本身含有噪声以及电动汽车行驶时随机性较大,并且经过实验发现如果对数据分别进行时域和频域增强,模型训练会极不稳定。本文的模型选择在原始数据上进行频域增强和原数据构成一对实例的不同视图,另外在3.7节对比了不同数据增强方式的性能。首先将输入数据进行式(3)的二维傅里叶变换:
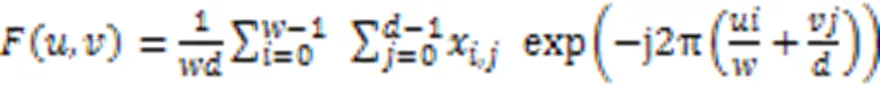
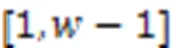
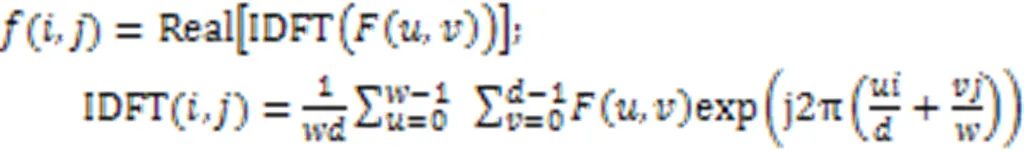
2.4 编码器
图2是CT-ED模型编码器的细节,主要由数据嵌入模块、特征模块和时间模块三部分组成。
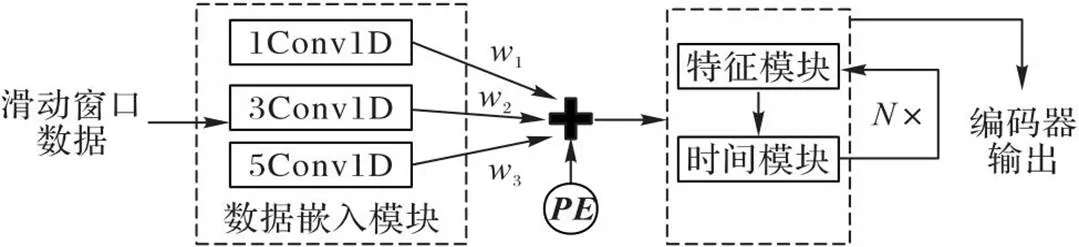
图2 CT-ED模型编码器的细节
2.4.1数据嵌入模块
不同大小的一维卷积在时间维度上滑动捕获不同范围的特征,单一大小的卷积核得到的结果可能遗失信息,因此融合不同大小卷积核的结果,可以获得更强健的表示。在编码器中,首先通过多尺度卷积对数据进行映射。模型自动学习3种卷积核的权重,通过式(5)的softmax后与各自的卷积结果相乘后融合。如式(6)所示,数据卷积融合后添加位置信息:
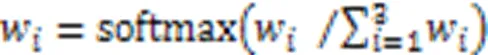
其中w是模型学习到的权重,通过softmax后归一化。
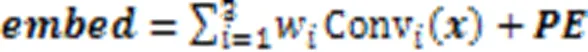
其中:Conv()是一维卷积操作,是通过与原始Transformer相同的位置编码函数得到的位置信息矩阵。
2.4.2时间模块和特征模块
多元时间序列包含时间依赖和特征依赖,因此需要从两个角度捕获数据特征。在时间依赖方面,沿用Transformer的Encoder部分作为模型中时间编码模块;在特征依赖方面,如图3所示,将每个特征序列全局池化后通过两层非线性激活得到特征注意力,特征注意力和对应的特征序列相乘后进行残差相加,对数据进行调整。时间模块和特征模块作为一个整体,可进行多次迭代。最终得到CT-ED模型的Encoder编码表示。

图3 模型编码器中的特征模块
2.4.3对比损失
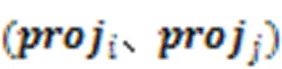
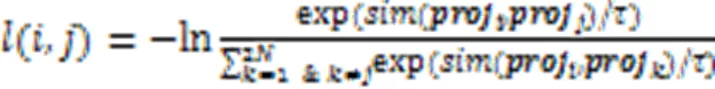
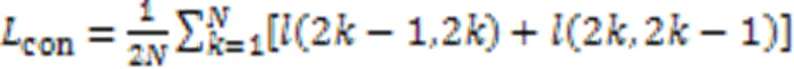
2.5 解码器
原始Transformer的解码器需要迭代解码,后面的输出依赖前面一个时间步的预测结果,导致推理变慢[19]。如图4所示,模型的解码器对Transformer的Decoder的改进,结合GRU进行数据重构。
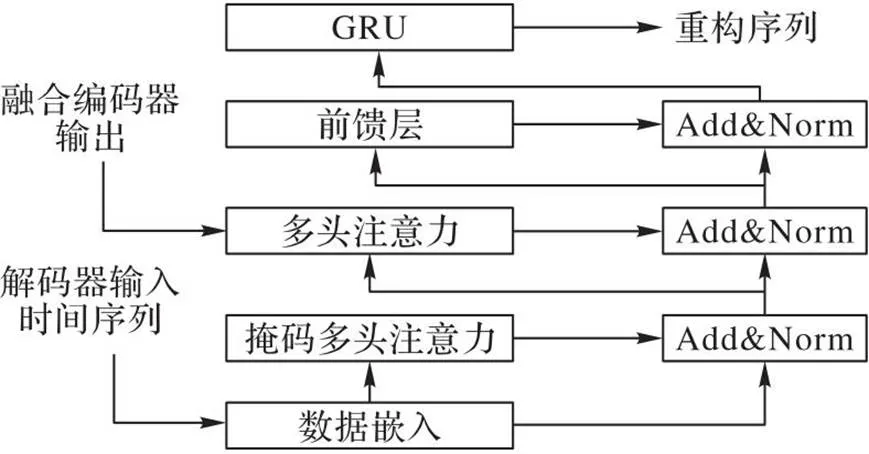
图4 模型解码器
将解码器输入decoder通过式(6)的多尺度数据嵌入后进行不同的线性映射得到111。通过掩码多头注意力机制输出,如式(9)所示;将模型编码器输出的两个编码表示加权相加得到,如式(10)所示:
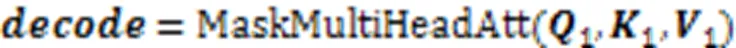
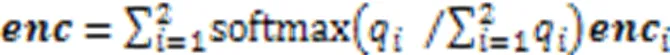
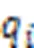
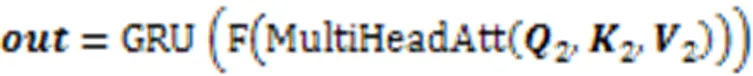
其中:MultiHeadAtt()代表多头注意力,F()是由两层全连接和激活函数组成的前馈层。最后训练阶段的总体损失计算公式如式(12)所示:
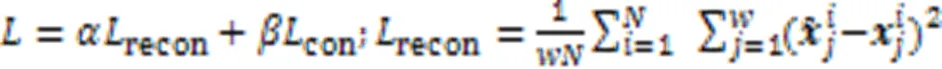

2.6 异常检测
经过实验发现计算窗口内最后一步时间的重构误差比计算窗口的平均误差效果更好,因此利用单步重构误差作为异常得分。当该窗口的异常得分大于设定的阈值时,判定为异常。对于不同的数据集定义初始阈值并逐步寻找最优阈值需要消耗人力,因此采用文献[20]中的自动阈值调整方法。该方法基于极值理论中不通过原始数据分布推断极端事件的分布的思想,目标是给定一系列观测值和异常发生的概率,计算阈值Z,使(>Z)<。首先初始化一个阈值,通常为数据的百分数,筛选超过初始阈值的时间点作为新的峰值数据,通过极大似然估计与广义帕累托分布进行拟合,其次通过这个分布自动调整阈值。对于误报警,采用文献[4]中的剪枝方法对正常波动进行处理。当检测到异常值时,与异常时间点之前的正常时间点序列的最大值进行比较,若比值小于(为一个超参数,根据实验获得),则判定为正常波动。
3 实验与结果分析
本文实验的对比模型包括MAD-GAN[12]、OmniAnomaly[13]、USAD[17]、GDN[15]和TranAD(Transformer-based Anomaly Detection model)[2]。
实验使用PyTorch-1.11.0,随机梯度下降优化器(Stochastic Gradient Descent, SGD)训练所有模型。
3.1 实验指标
通过精确率(Precision, P),召回率(Recall, R)和F1值测评模型效果。
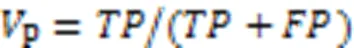
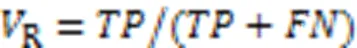
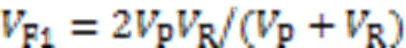
其中:是被正确检测的异常时间点数,是被误判为异常的正常时间点数,是被误判为正常的异常时间点数。
3.2 数据集
安全水处理数据集(Secure Water Treatment, SWaT)[21]。一共包括连续11 d数据,7 d为正常操作,4 d为阶段性受到攻击,共41次攻击。参考文献[22]中的18个连续值属性作为特征。
土壤湿度主动被动卫星(Soil Moisture Active Passive satellite, SMAP)/火星漫游车(Mars Science Laboratory rover, MSL)数据集[4]。真实航天器遥测数据和异常。数据集由多个小数据集组成,变量主要是离散型变量。其中SMAP选择P-1、S-1、E-1:9(除了6),MSL选择C-1、D-16、M-1:5、T-12:13、P-11。两个数据集都包含点异常和上下文异常两种类型。
电动汽车动力电池(EV)数据集。电动汽车在行驶状态下的动力电池传感器数据,包含电流电压温度极值等,来自新能源汽车国家大数据联盟和数字汽车大赛。
EV数据集和其他3个公开数据集都是多元时间序列,图5显示了EV数据集的电流时间序列和SMAP数据集的遥测值,其中灰色部分是异常时间点。可以看到EV数据集在时间维度上的表现和SMAP类似,因此在3个公开数据集上有效的模型也可以用于EV数据集的异常检测。表1统计了数据集的大小和异常率等信息。
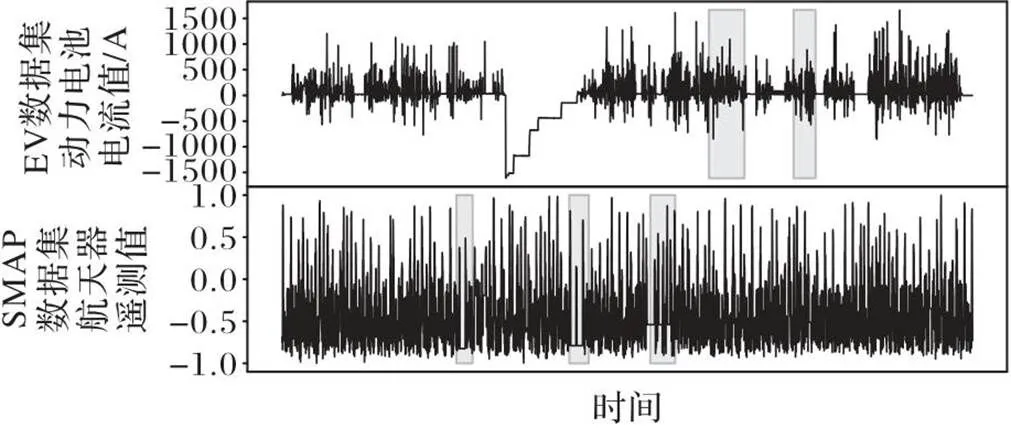
图5 EV和SMAP数据集的时间序列
表1数据集统计信息
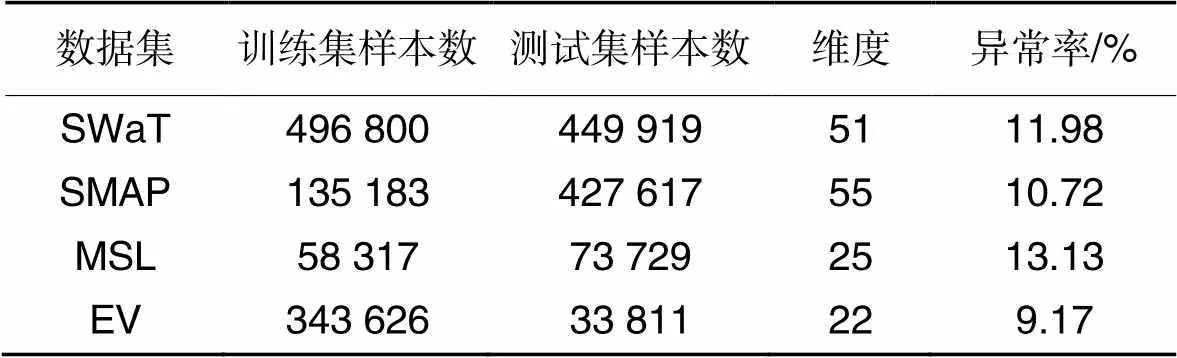
Tab.1 Statistics of datasets
3.3 实验结果
表2展示了CT-ED和其他模型在不同数据集上的精确率(P)、召回率(R)和F1值,其中相较于次优模型,CT-ED的F1值在SWaT、SMAP、MSL和EV数据集上分别提升了6.5%、1.8%、0.9%和7.1%。CT-ED在所有数据集上的F1都取得了最优成绩。CT-ED在不同数据集上的F1平均值达到0.884 1,说明了模型广泛的适用性。
SMAP数据集大部分是点异常,MSL数据集大部分是上下文异常。OmniAnomaly在SMAP数据集取得次优的成绩,在MSL数据集表现最差,可能由于模型学习数据的正常分布,因此能够识别与正常分布差别较大的点异常,但忽视了符合正常数据分布的上下文异常。相反,MAD-GAN可以有效检测MSL数据集异常,在SMAP数据集上表现较差,可能因为对抗式训练放大了生成数据和真实数据的差别,将数据中的噪声或其他正常状态下的窗口数据也检测为异常,导致精度较低。
USAD和TranAD在SMAP和MSL数据集上的表现比较平均,其中TranAD在MSL数据集的F1达到了次优,可能是其中的多头注意力能有效捕获特征相关性,因此在变量更多的MSL数据集上表现优于USAD。另外,GDN在两个数据集上也表现得比较平均,说明基于多元数据之间相关性建模,可以有效地识别不同类型的异常。
CT-ED在SMAP和MSL数据集上的F1值都达到了0.950 0以上,说明模型适用于不同类型的异常。编码器中的多尺度卷积有效地学习窗口内的局部特征和全局特征,能有效检测小范围的点异常和整体的上下文异常。SWaT数据集与SMAP数据集和MSL数据集类似,但数据量更大,大部分模型在该数据集上表现相对较差,而CT-ED的F1相较次优模型提升了6.5%,验证了它能适应不同规模的数据集。
表2CT-ED在不同数据集上的实验结果
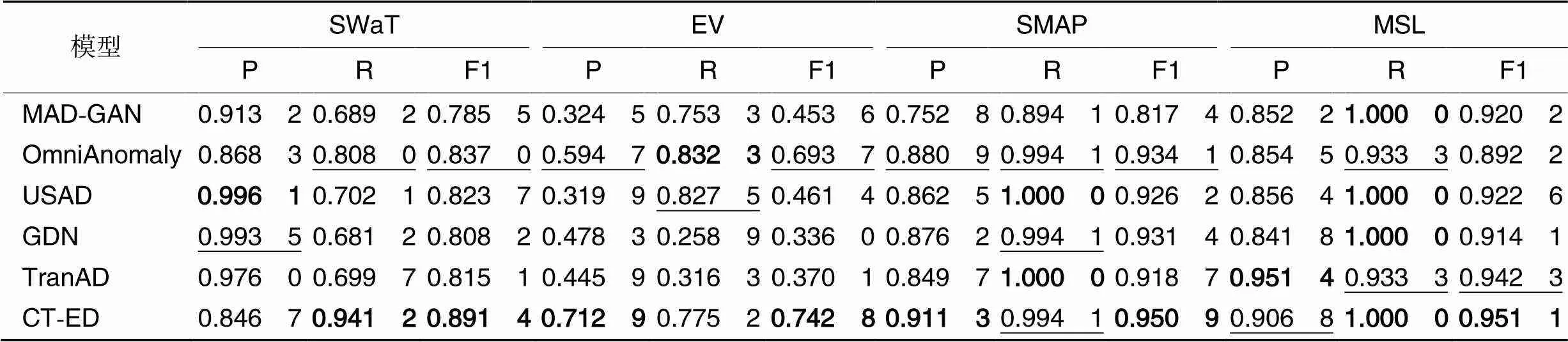
Tab.2 Experimental results of CT-ED on different datasets
注:加粗和下画线分别表示最优和次优值。
EV数据集相较于其他数据集,由于工况的变化和驾驶人不同的行为习惯,数据的随机性更强。大部分模型在该数据集上表现不佳,F1值在[0.3,0.7];OmniAnomaly在编码时添加了高斯噪声,在EV数据集上取得次优的成绩并远优于其他模型。类似地,CT-ED在频域增强时也对数据添加了高斯噪声,增强了模型对抗数据噪声能力和重构数据多样性的能力。另外在CT-ED训练阶段,通过对同一实例不同视图的对比学习,模型能够获得数据的一般特征,以及从时间和特征两个角度进行编码,使模型能够适应不同维度的数据。
3.4 训练过程分析
异常检测需要时刻监测设备状态,设置时间步为1,对于EV数据集,产生的训练时间序列片段数为343 626,测试片段数为33 811。对于由多个子集构成的数据集SMAP和MSL,每个子集构造的时间序列片段范围为[2 000,8 000]。由于数据集较小,SMAP和MSL数据集通常在1~5轮训练达到最优F1值,EV和SWaT数据集在10~20轮训练达到最优F1值。
以EV数据集为例,观察模型训练过程中的损失值和模型指标之间的关系。如图6所示,MSELoss为重构损失,ConLoss为对比损失,随着训练召回率下降,精确率上升,F1在18轮达到最优值,后续损失值继续下降,模型的整体性能却下降了。说明了无监督异常检测不同于有监督学习,可以通过监测训练过程中的损失值判断模型的性能,这是大部分无监督异常检测都存在的问题。
阈值的选择对异常检测任务十分重要,对比不同的自动阈值选择方法的性能,在一个模型产生的异常分数上进行实验。POT为本文采用的自动阈值选择方法;EWMA是对异常分数进行平滑处理后选择均值加方差作为阈值;均方是不对异常分数做处理,直接使用均值加方差作为阈值;NDT是文献[4]中的阈值选择方法。表3显示了在相同模型上,通过均方和EWMA计算阈值效果很差。NDT的F1值最高,但召回率较低;POT相对平衡了召回率和精确率;而POT+剪枝可以在POT的基础上减少错误报警,提高精确率。因此对异常检测任务来说,POT阈值加上适当的剪枝更优。
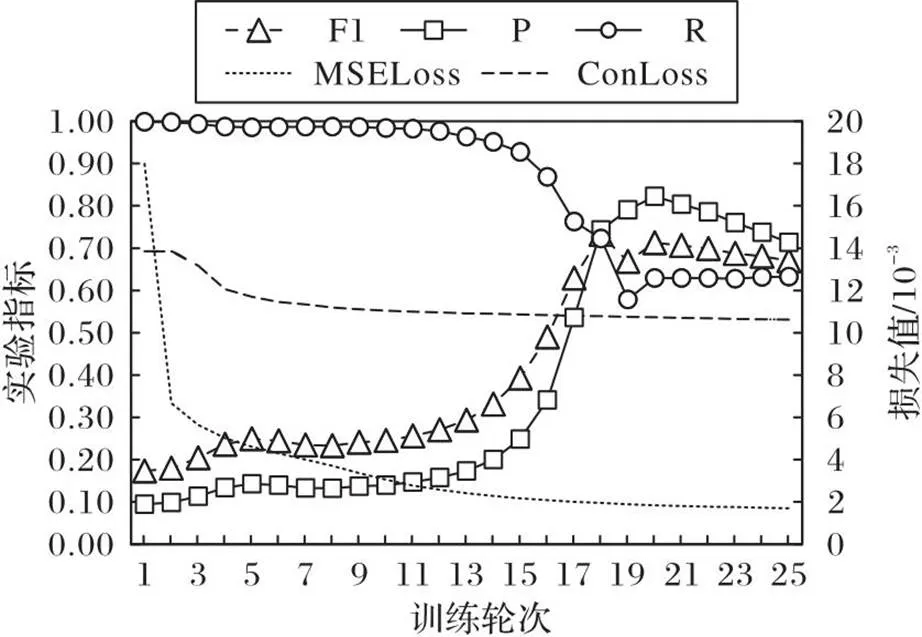
图6 EV数据集上的训练过程
表3相同模型在不同阈值选择方法下的实验结果
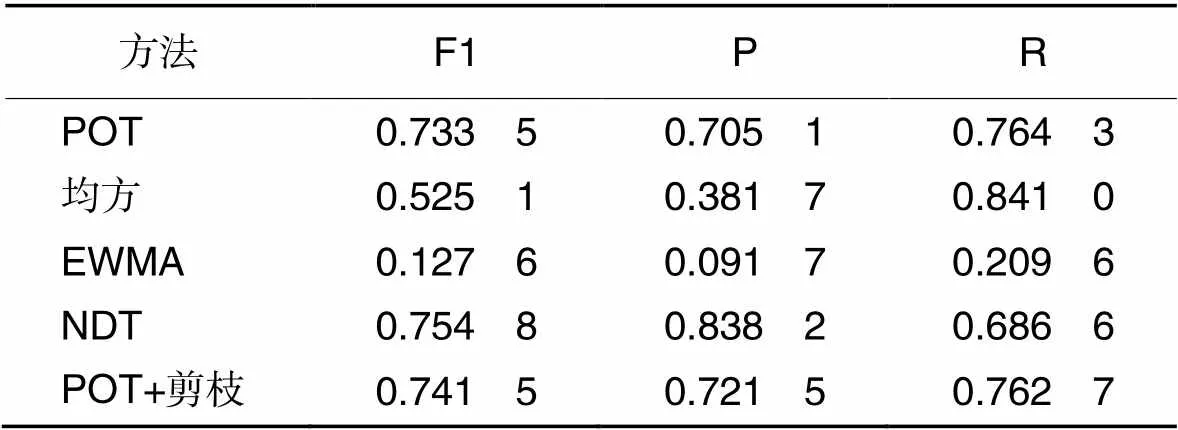
Tab.3 Experimental results of same model with different threshold selection methods
3.5 单变量对比实验
EV数据集中含有多个变量,选择其中的电压、电流和绝缘电阻单变量时间序列进行实验。表4显示了CT-ED的变量实验结果,单变量情况下,最优F1为电流时间序列的0.695 4。单变量相较于多元变量缺少相关性信息,需要更大的窗口提供更多时间信息,但仍然达不到多元变量可以提供的信息量。
表4CT-ED的变量实验结果
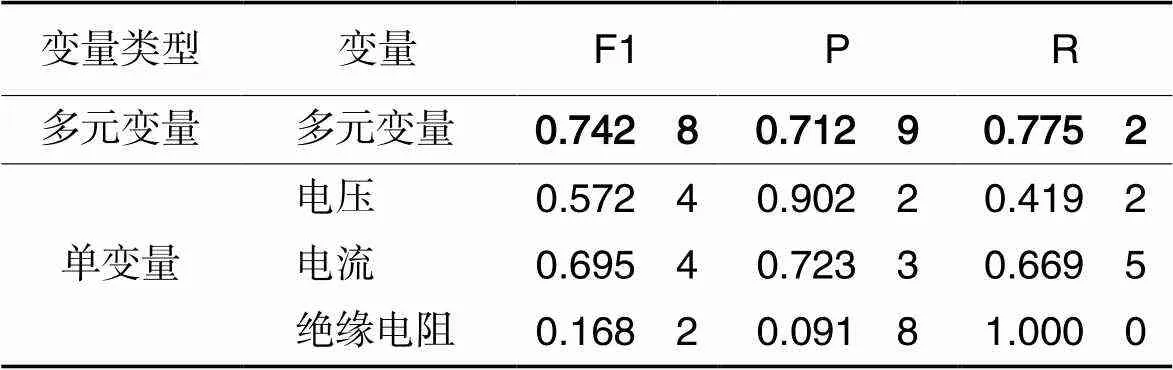
Tab.4 Variate experimental results of CT-ED
表5显示了不同模型在EV数据集电流时间序列上的表现。TranAD和OmniAnomaly都取得较优F1值,但对于异常检测任务,检测的异常数更为重要,召回率反映了异常被检测的概率,CT-ED在多元数据上,同等F1值下具有更高的召回率。
表5不同模型在电流单变量时间序列上的实验结果
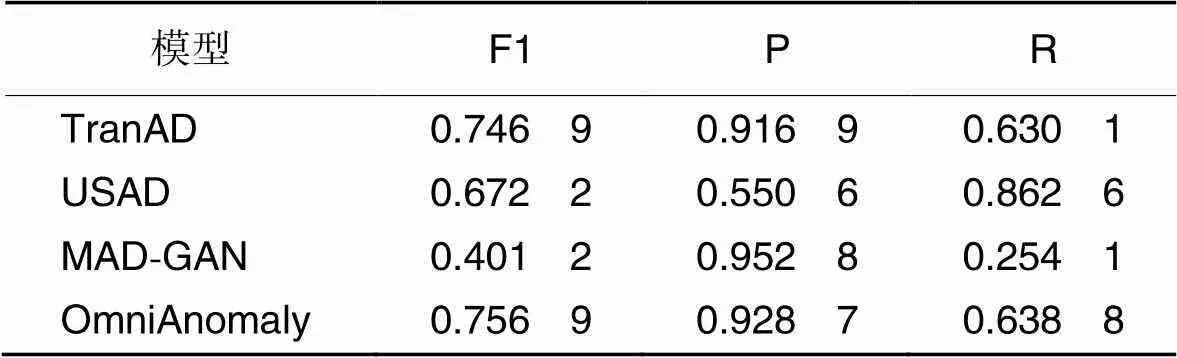
Tab.5 Experimental results of different models on current univariate time series
3.6 参数敏感度
本节研究不同参数对CT-ED性能的影响。模型的主要参数包括编码器的窗口大小、解码器的窗口大小和批大小。本节的所有实验均在EV数据集上进行。
在对比学习中,批大小(batchsize)越大,模型效果越好。如图7所示,其中b为批大小,d为解码器的窗口大小。可见在大部分情况下,小批次的实验结果更好,这和对比学习的结论相悖,可能是因为数据的动态性较强,一批数据中每个窗口的差异较大,因此噪声较大的小批次训练更适合动态性强的EV数据集。
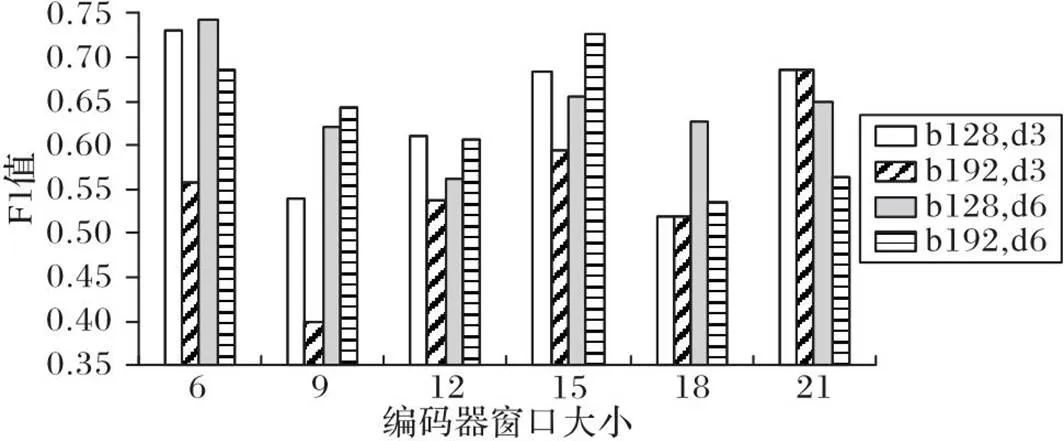
图7 不同参数下CT-ED在EV数据集上的F1值
编码器的输入作为重构数据的历史信息,不同长度会产生不同的效果。从图7可见,模型的性能比较不稳定,没有随着编码器窗口大小变化趋势而变化的规律,但是在窗口为6时取得最好成绩。说明了不同于一些长序列任务,由于数据随机性大,冗余的历史信息反而会使模型性能降低。
解码器输入进行重构后在训练阶段计算重构损失直接影响模型的参数,因此需要选择合适的解码器窗口大小。对比解码器窗口大小为3和6的结果,可以看到在大部分情况下,窗口为6的实验结果更优。
3.7 消融实验
为了研究模型主要模块的效果,删除了一些主要模块,观察模型在EV数据集上的结果变化。
CT-ED-WO-Conv:将编码器的多尺度卷积替换为卷积核为3的单一卷积映射。
CT-ED-WO-Contrastive:删除频域增强和训练时的对比损失,通过单个编码器解码器结构进行训练和检测。
CT-ED-WO-Feature:删除编码器中的特征注意力模块。
CT-ED-WO-Time:删除编码器中时间注意力模块。
如表6所示,CT-ED在EV数据集上性能最佳。
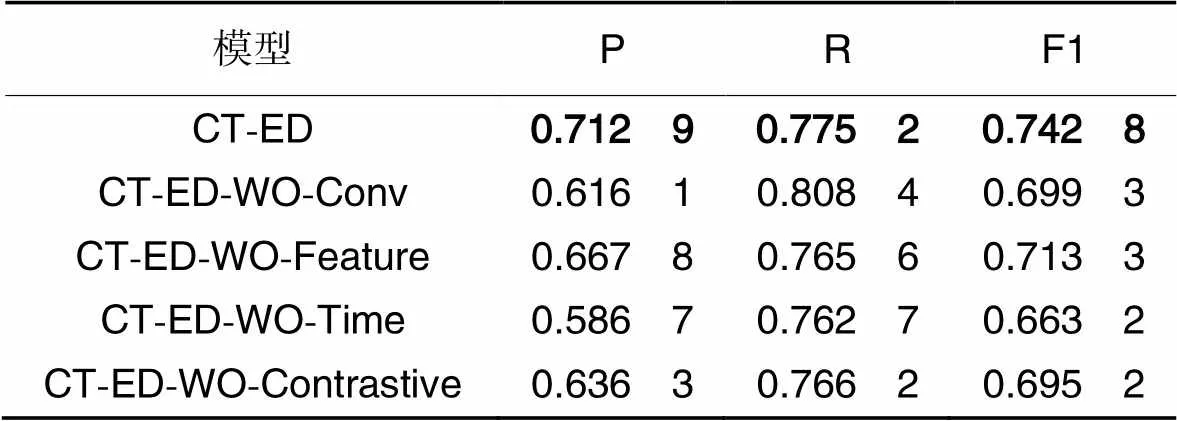
表6 CT-ED在EV数据集上的消融实验结果
其中:CT-ED-WO-Time性能下降最明显,说明了在对时间序列数据建模时,捕获它的时间依赖的重要性;CT-ED-WO-Conv精度有明显下降,说明多尺度卷积有效提取不同范围特征,提高异常检测精度;CT-ED-WO-Contrastive性能也明显下降,说明对比学习有利于模型获取数据的一般特征;CT-ED-WO-Feature性能下降最少,但编码器中的特征注意力模块仍然是整个模型中不可或缺的一部分。
在相同的参数和轮次下,对比不同时间序列数据增强方式,结果如表7所示。其中:FFT是频域增强,移动窗口是将窗口数据往前移,噪声是指对原始序列直接添加高斯噪声。3个数据增强方式在性能上没有明显差别。
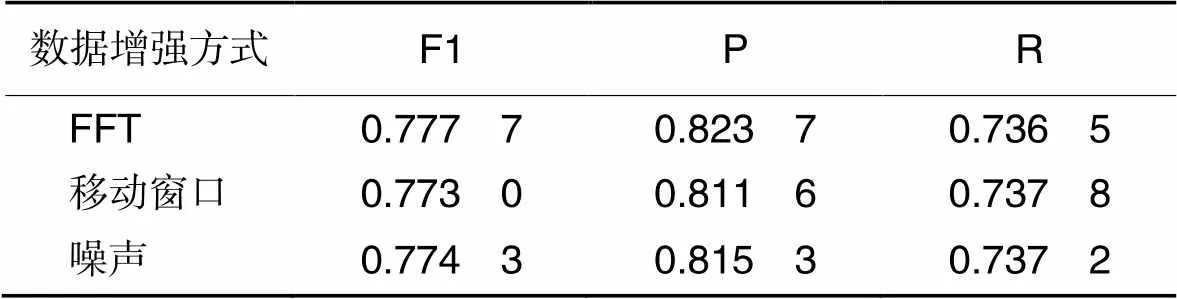
表7 不同数据增强方式的结果对比
4 结语
目前动力电池的相关研究大部分需要专业知识,并且使用实验数据进行建模,不能很好地适应实际工况。本文针对电动汽车行驶状态下的动力电池数据,将相对成熟的时间序列异常检测领域的技术改进后应用于动力电池安全预警。
本文提出了一个适用于不同数据集的多元时间序列异常检测模型。通过频域数据增强产生一个实例的不同视图,利用对比学习捕获动态数据的一般特征;另外,模型在时间和特征两个角度进行编码,使编码更加全面。
对于关系人身安全的动力电池安全预警任务,目前的实验结果并不是很理想,F1值仅达到0.742 8。但本文模型无须特征工程或其他预备知识,并且模型可以识别不同于正常模式的异常行为而无须事先知道异常类型。CT-ED较其他模型在EV数据集上性能有了大幅提升,验证了通过深度学习进行新能源汽车安全监测的可行性。
模型的精确率较低,本文尝试对部分异常值剪枝以减少误报警,但效果不明显,而且模型目前只针对一辆车的运行状态进行建模。在未来的工作中,将提高模型的运算效率,选择合适的阈值调整方法和误报警处理方法;另外,将融合迁移学习修改模型使模型可以适应不同状态和不同车辆的电动汽车数据。
[1] 王震坡,李晓宇,袁昌贵,等. 大数据下电动汽车动力电池故障诊断技术挑战与发展趋势[J]. 机械工程学报, 2021, 57(14):52-63.(WANG Z P, LI X Y, YUAN G C, et al. Challenge and prospects for fault diagnosis of power battery system for electrical vehicles based on big-data[J]. Journal of Mechanical Engineering, 2021, 57(14):52-63.)
[2] TULI S, CASALE G, JENNINGS N R. TranAD: deep transformer networks for anomaly detection in multivariate time series data[J]. Proceedings of the VLDB Endowment, 2022, 5(16):1201-1214.
[3] 毛文涛,施华东,张艳娜,等. 轴承在线早期故障检测的无监督张量深度迁移学习方法[J/OL]. 控制与决策(2022-11-27)[2023-03-04].https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13195/j.kzyjc.2022.1101.(MAO W T, SHI H D, ZHANG Y N, et al. Research on unsupervised tensor-based deep transfer learning for online early fault detection of bearing[J/OL]. Control and Decision (2022-11-27)[2023-03-04].https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13195/j.kzyjc.2022.1101.)
[4] HUNDMAN K, CONSTANTINOU V, LAPORTE C, et al. Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2018: 387-395.
[5] ZHOU H, YU K, ZHANG X, et al. Contrastive autoencoder for anomaly detection in multivariate time series[J]. Information Sciences, 2022, 610: 266-280.
[6] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[7] CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607.
[8] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[9] LIN S, CLARK R, BIRKE R, et al. Anomaly detection for time series using VAE-LSTM hybrid model [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2020: 4322-4326.
[10] XU H, CHEN W, ZHAO N, et al. Unsupervised anomaly detection via variational auto-encoder for seasonal KPIs in Web applications[C]// Proceedings of the 2018 World Wide Web Conference. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2018: 187-196.
[11] PARK D, HOSHI Y, KEMP C C. A multimodal anomaly detector for robot-assisted feeding using an LSTM-based variational autoencoder[J]. IEEE Robotics and Automation Letters, 2018, 3(3): 1544-1551.
[12] LI D, CHEN D, JIN B, et al. MAD-GAN: multivariate anomaly detection for time series data with generative adversarial networks[C]// Proceedings of the 2019 International Conference on Artificial Neural Networks, LNCS 11730. Cham: Springer, 2019: 703-716.
[13] SU Y, ZHAO Y, NIU C, et al. Robust anomaly detection for multivariate time series through stochastic recurrent neural network[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 2828-2837.
[14] ZHANG C, SONG D,CHEN Y, et al. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 1409-1416.
[15] DENG A, HOOI B. Graph neural network-based anomaly detection in multivariate time series [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 44027-4035.
[16] ZHAO H, WANG Y, DUAN J, et al. Multivariate time-series anomaly detection via graph attention network [C]// Proceedings of the 2020 IEEE International Conference on Data Mining. Piscataway: IEEE, 2020: 841-850.
[17] AUDIBERT J, MICHIARDI P, GUYARD F, et al. USAD: unsupervised anomaly detection on multivariate time series[C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 3395-3404.
[18] WANG X, PI D, ZHANG X, et al. Variational Transformer-based anomaly detection approach for multivariate time series[J]. Measurement, 2022, 191: No.110791.
[19] ZHOU H, ZHANG S, PENG J, et al. Informer: beyond efficient transformer for long sequence time-series forecasting[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 11106-11115.
[20] SIFFER A, FOUQUE P A, TERMIER A, et al. Anomaly detection in streams with extreme value theory [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2017: 1067-1075.
[21] MATHUR A P, TIPPENHAUER N O. SWaT: a water treatment testbed for research and training on ICS security [C]// Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks. Piscataway: IEEE, 2016: 31-36.
[22] AHMED C M, ZHOU J, MATHUR A P. Noise matters: using sensor and process noise fingerprint to detect stealthy cyber attacks and authenticate sensors in CPS[C]// Proceedings of the 34th Annual Computer Security Applications Conference. New York: ACM, 2018: 566-581.
Power battery safety warning based on time series anomaly detection
ZHANG Anqin1,2, WANG Xiaohui1*
(1,,201306,;2,515063,)
Abnormal situations inside the vehicle battery cannot be predicted and warned in time, which leads to electric vehicle accidents and brings serious threats to drivers and passengers’ life and property safety. Aiming at the above problem, a Contrastive Transformer Encoder Decoder (CT-ED) model was proposed for multivariate time series anomaly detection. Firstly, different views of an instance were constructed through data augmentation, and the local invariant features of the data were captured by contrastive learning. Then, based on Transformer, the data were encoded from two perspectives of time dependence and feature dependence. Finally, the data were reconstructed by the decoder, and the reconstruction error was calculated as the anomaly score to detect anomalies of the machine under the actual operating conditions. Experimental results on SWaT, SMAP, MSL three public datasets and Electric Vehicle power battery (EV) dataset show that compared to the suboptimal model, the F1-scores of the proposed model increase by 6.5%, 1.8%, 0.9%, and 7.1% respectively.The above results prove that CT-ED is suitable for anomaly detection under different operating conditions, and balancing the precision and recall of anomaly detection.
time series; anomaly detection; contrastive learning; multi-head attention; autoencoder
This work is partially supported by Open Fund Project of Guangdong Province Key Research Base of Humanities and Social Sciences — Local Government Development Research Institute of Shantou University (07422002).
ZHANG Anqin, born in 1974, Ph. D., associate professor. Her research interests include data mining, ubiquitous computing.
WANG Xiaohui, born in 1998, M. S. candidate. Her research interests include data mining, anomaly detection.
TP183; TP206
A
1001-9081(2023)12-3799-07
10.11772/j.issn.1001-9081.2022111796
2022⁃12⁃06;
2023⁃03⁃16;
2023⁃03⁃23。
广东省人文社会科学重点研究基地—汕头大学地方政府发展研究所开放基金课题(07422002)。
张安勤(1974—),女,安徽六安人,副教授,博士,主要研究方向:数据挖掘、普适计算;王小慧(1998—),女,浙江台州人,硕士研究生,主要研究方向:数据挖掘、异常检测。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
数学物理学报(2017年5期)2017-11-23
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
