
基于视觉跟踪与自主导航的移动机器人目标跟随系统
2024-01-08 00:52蒋婉玥
工程设计学报 2023年6期
张 瑞,蒋婉玥
(青岛大学 自动化学院未来研究院,山东 青岛 266071)
近年来,越来越多的机器人参与到人类的生产和生活中。在许多场景,要求机器人能够在复杂环境中跟随目标移动,如跟随购物车、高尔夫球车等[1-2],这些都是跟随技术的应用实例。
目前已有多种基于传感器的目标跟随方法[3-4]。通过激光雷达、相机、UWB(ultra wide band,超宽带)技术等实现对目标位置的感知,并根据目标位置设计机器人导航与控制算法。如:Ferrer等[5]通过激光雷达对目标进行定位,利用SFM(social force mode,社会力模型)量化行人运动意图,使机器人能够并排跟随目标行人;Chung等[6]通过激光点云获得行人腿部模型,分析了行人腿部运动,得到目标行人的位置,但仅凭点云数据很难区分不同的行人;Ling 等[7]提出了一种通过检测反射材料来跟随行人的方法。
在视觉跟随及视觉目标跟踪方面,也已有不少的研究成果。视觉跟随研究方面:Cheng等[8]提出了一种通过检测目标行人的上身和脚实现跟随的方法;Sun等[9]开发了一种基于手势的方法,机器人可以根据手势完成不同的任务;Koide等[10]提出了一种结合身高和颜色特征来识别目标行人的方法,然而这些身体信息很容易受到目标行人姿势和步态的干扰;余铎等[11]通过将快速判别尺度空间的算法与卡尔曼滤波算法进行切换来实现稳定跟随;万琴等[12]采用改进的卡尔曼滤波器来预测目标的状态,并通过数据关联进行目标匹配,利用多目标跟踪并通过标定目标人的ID(identity document,身份标识号)来跟随。视觉目标跟踪研究方面:Henriques 等[13-14]提出了CSK (circulant structure of tracking-by-detec‐tion with kernels,核检测跟踪的循环结构)算法,利用循环矩阵进行图像密集采样,提高了跟踪精度,随后又拓展了多特征通道,提出了KCF(kernelized correlation filters,核相关滤波)算法;Danelljan等[15]优化了平移检测和尺度检测滤波,提出了FDSST(fast discriminative scale space tracking,快速判别尺度空间跟踪)算法;Bertinetto等[16]将孪生网络应用于跟踪,提出了SiamFC(fully-convolutional Sia‐mese network,全卷积孪生网络)算法;Li等[17-18]在SiamFC 算法的基础上加入区域候选网络,提出了SiamRPN(Siamese region proposal network,孪生候选区域生成网络)算法,后又提出了SiamRPN++算法,采用空间感知采样策略,在目标跟踪时采用深层网络进行特征提取。上述研究考虑了人的外观特征,而当场景中有外观相似的行人时则不易区分,在机器人跟随目标行人时会出现跟踪失败的问题。
本文提出了一种基于深度相机的移动机器人目标跟随方法,通过视觉跟踪和自主导航实现机器人跟随社交目标移动。常规的目标跟踪算法仅能解决目标在短时间内被遮挡的问题;当目标在走廊拐角处转弯后不再出现在机器人视野内时,就需要机器人主动转弯,改变相机的视野。本文将机器人跟随问题分为目标在机器人视野内和目标消失两种情况。针对前者,将基于卡尔曼滤波的运动信息处理方法与基于特征网络提取的外观特征信息处理方法相结合,提高目标识别的精度;针对后者,根据目标消失前与机器人的相对位置,利用自主导航使机器人移动到目标消失位置附近进行搜索,提高对目标跟随的成功率。本文采用OTB100公开测试集和机器人应用场景下的跟随测试集进行视觉跟踪效果评估,并在机器人平台上进行跟随实验,来验证机器人在室内外行人众多的环境中对目标行人的跟随性能。
1 移动机器人结构及跟随系统框架
移动机器人主要由视觉跟踪定位模块和机器人跟随控制模块组成,如图1所示。视觉跟踪定位模块通过深度相机获取机器人跟随所需的RGB视频序列和深度视频序列。外置主机是视觉跟踪定位信息的处理器,用来处理深度相机获取的视频序列,确定目标与机器人的相对位置。移动机器人平台为由麦克纳姆轮驱动的ROS(robot operating system, 机器人操作系统)平台,搭载Jetson TX1 控制主板,其通过控制算法在该平台上运行。

图1 移动机器人结构Fig.1 Structure of mobile robot
移动机器人目标跟随系统框架如图2所示。深度相机获取RGB视频序列和深度视频序列;通过目标检测及目标跟踪在RGB视频序列中找出目标,深度视频序列用来确定目标与相机的相对位置;若跟踪成功,根据机器人与目标的相对位置,控制机器人进行跟随;若在视觉跟踪过程中目标长时间消失,则认定跟踪失败,此时启动自主导航,将目标消失前的相对位置转化为世界坐标系中的坐标,机器人移动到目标消失的位置去主动寻找。本方法可以有效解决在视觉跟踪过程中目标长时间消失或被遮挡等问题,较好地处理在机器人跟随过程中目标在走廊拐角、门口处转弯而消失的情况。
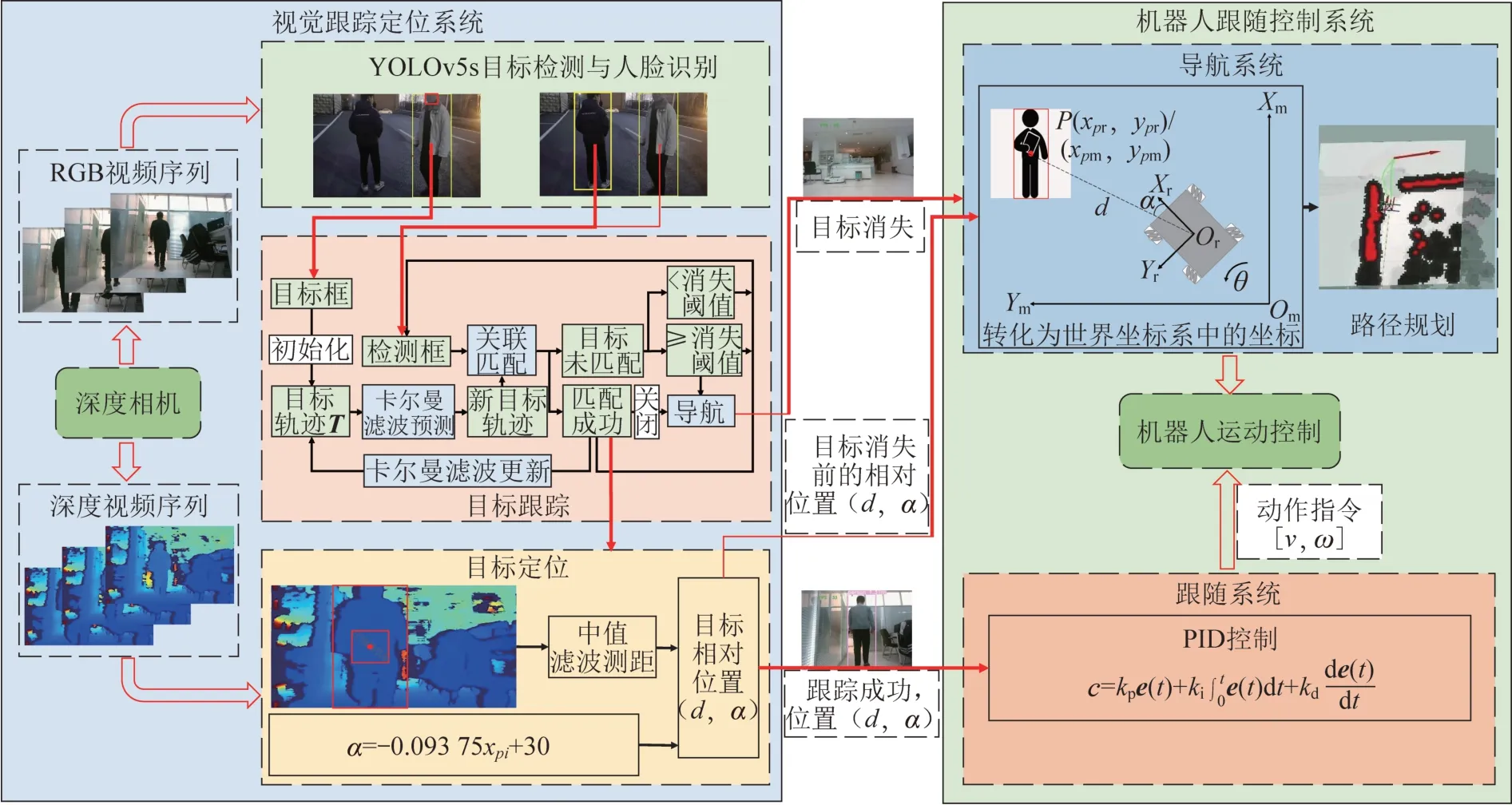
图2 移动机器人目标跟随系统框架Fig.2 Framework of mobile robot target following system
2 视觉跟踪定位
视觉跟踪定位包括目标检测与识别、目标跟踪和目标定位三部分。首先,由深度相机获取视频的帧图像,利用YOLOv5s 进行行人检测,结合人脸识别判定目标是否位于机器人视野范围内;其次,对跟踪算法进行初始化,并提取目标的运动状态和外观特征,在后续帧中对目标进行跟踪,并对跟踪成功的目标进行定位;最后,输出目标与机器人的相对位置信息。
2.1 目标检测与识别
在实验中手动框选跟踪目标是不方便的,因此在运行跟踪算法前加入人脸识别,且只在第1帧或者前几帧进行人脸识别,一旦检测到目标进入机器人视野,则进行目标跟踪。采用已经训练好的检测模型YOLOv5s作为行人检测器[19]。该模型运行速度快、识别精度高,可以很好地检测到目标行人。人脸识别算法采用人脸识别库face_recognition,其在人脸数据集Labeled Faces in the Wild 测试中有99.38%的准确率[20]。
在第1帧中,将人脸识别框和YOLOv5s检测框进行IOU(intersection over union,交并比)匹配,IOU距离最小的检测框为目标框。IOU距离可以表示为:
式中:Βface=[x1y1x2y2],Βi=[xi1yi1xi2yi2],其元素分别为人脸检测框和第i个行人检测框的左上角以及右下角在图像坐标系中的坐标。
2.2 目标跟踪
目标跟踪流程如图3所示。当目标出现时,基于上述的目标检测与识别方法可以得到目标框;提取目标框的图像特征以及位置信息,将该目标框初始化为一个目标轨迹T=[xyrhsF],其中包含目标边界框中心位置(x,y)、目标边界框宽高比r、高度h、当前轨迹经过卡尔曼滤波器预测的次数s以及目标的外观特征库F;在第t帧,通过卡尔曼滤波器预测当前帧的目标位置,并将预测次数s加1,将YOLOv5s检测到的行人框与预测后的轨迹进行关联匹配;若匹配目标成功,更新目标轨迹的外观特征库F、卡尔曼滤波的参数,并将卡尔曼预测次数s置零;若目标匹配不成功,目标轨迹T不进行更新,当预测次数大于消失阈值,认定目标长时间消失,则进行自主导航;当检测框与目标轨迹再次成功匹配后,关闭自主导航。

图3 目标跟踪流程Fig.3 Target tracking process
2.2.1 卡尔曼滤波
本文采用具有恒定速度模型的标准卡尔曼滤波器,假定行人的运动速度是恒定的。跟踪场景在八维状态变量上定义,该变量包含目标的4个位置状态变量及其在各自图像坐标系中的变化速度,其中将边界框状态zt=[xyrh]Τ作为目标状态的直接观测值。
状态预测:
状态更新:
式中:I为8×8型单位矩阵;分别为t时刻的状态预测值和t-1时刻的状态最优估计值,分别为t时刻的先验估计协方差矩阵和t-1时刻的后验估计协方差矩阵,A为8×8型状态转移矩阵,Q为8×8 型过程噪声矩阵,R为4×4 型测量噪声矩阵,H为4×8型状态观测矩阵,Κt为卡尔曼增益。
2.2.2 关联匹配
关联匹配模块解决了卡尔曼预测的目标轨迹与新一帧检测量之间的关联问题。通过余弦距离和马氏距离来整合外观信息和运动信息。
针对外观信息,用余弦距离来度量。利用训练好的特征提取网络提取第i个行人检测框的外观特征fi以及目标轨迹的外观特征库F=[f1f2…f100]。第i个检测框与目标轨迹的最小余弦距离为:
式中:fΤi⋅fj为第i个检测框特征与目标轨迹第j个特征的余弦相似度。
当有外观相似的行人时,仅根据余弦距离不能进行准确区分而造成跟踪漂移,因此须用运动信息进行衡量。为了结合运动信息,采用预测的卡尔曼状态与新一帧检测量之间的马氏距离:
式中:Di为第i个检测框的状态向量,为由卡尔曼预测状态向量映射的4×1 型可观测的状态向量,为映射的4×4型协方差矩阵。
这2 种度量可以在不同方面相互补充。一方面,马氏距离提供了目标基于运动的位置信息,有助于短期预测;另一方面,余弦距离考虑了外观信息,这些信息对于目标被遮挡或相机抖动后的运动信息不具有辨别力,但有助于对恢复的目标进行跟踪。设置权重λ加权这2 个度量值,得到最优关联值d:
为了避免目标被遮挡而导致关联错误,加入一个阈值δ来衡量关联值d是否可以接受。若d≤δ,则认为关联成功。
目标轨迹与检测框匹配成功后,须对目标轨迹的外观特征库F进行更新。将匹配成功的检测框的外观特征替换掉与其外观特征相似度最高的目标轨迹的特征fj。
外观特征的提取采用ResNet残差网络,其结构如图4 所示。输入模型的尺寸为128×64×3,经过步长为1,64 个3×3 的卷积核卷积并最大池化后得到64×32×64的输出,然后经过16个普通残差块卷积后得到8×4×512 的输出,经自适应平均池化后进行全连接层分类。在目标跟踪方法中,采用该特征提取网络时不需要全连接层分类,在自适应平均池化后对该数据进行归一化,得到512维的特征,再进行余弦距离计算。对该网络在行人重识别的Market-1501数据集上进行训练。该数据集包括由6个摄像头拍摄到的1 502个行人、32 668个检测到的行人矩形框。在训练过程中,学习率衰减采用余弦退火方法。验证集中分类概率最高类别的准确率(top-1 accuracy)为89.348%。

图4 外观特征提取网络的结构Fig.4 Structure of appearance feature extraction network
2.3 目标定位
为了完成跟随行人的任务,机器人须知道目标的位置信息。根据跟踪检测结果,通过目标矩形框中心点的坐标来计算机器人与目标之间的相对距离。为了减小计算量,根据中心像素的位置确定搜索框,然后从搜索框中选择40个搜索点进行测距,并对搜索点的有效值进行中位值平均滤波以获得目标的距离。
根据目标的最优状态向量,确定搜索框的边长as为:
则搜索框状态向量为[xyasas],搜索点为Ps(x+ε,x+ε),其中ε为偏差,。
通过测试可知,深度相机的深度视野约为60°,图像分辨率为(640×480)像素。将机器人的正前方设为0°,左侧为负角度,右侧为正角度。将相机视野与图像大小线性映射,可以算出机器人与目标之间的相对角度。设xpi为目标中心的横坐标,则相对角度α为:
深度相机测得的目标距离和角度如图5所示。

图5 深度相机测得的目标距离和角度示意Fig.5 Schematic of distance and angle of target measured by depth camera
3 机器人跟随控制
机器人跟随控制系统是在带有Jetson TX1控制主板的ROS平台上运行的。通过局域网接收视觉跟踪定位系统传输的机器人与目标的相对距离、相对角度以及目标是否长时间消失的标志位。根据目标是否长时间消失,进行常规跟随和自主导航两种处理。
3.1 常规跟随
在目标长时间消失或被遮挡前,根据机器人与目标的相对距离d(t)、相对角度α(t),采用PID(proportion-integral-derivative,比例‒积分‒微分)控制器求解机器人线速度v及角速度ω,令c=[vω]Τ。
式中:kp、ki、kd为PID控制参数;e(t)为t时刻机器人与目标期望位置的误差;d∗为期望的跟随距离,d∗=1 m;α∗为期望的跟随角度,α∗=0°。
3.2 自主导航
当目标消失后,将目标消失前的位置保存下来,同时机器人停止运动,等待目标出现。当目标消失30帧后,认定目标长时间消失,则启动自主导航,机器人主动寻找目标。其路径规划采用A*算法。
3.2.1 坐标转换
2.3 节中定位的目标位置即为机器人与目标的相对位置,在机器人自主导航时须将其转化为世界坐标系中的坐标。将相机坐标系看作机器人坐标系,则机器人坐标系与世界坐标系的转换如图6所示。
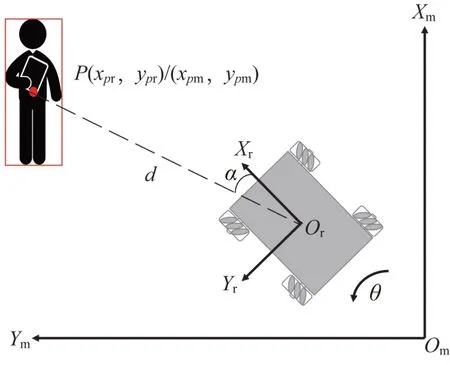
图6 机器人坐标系与世界坐标系的转换Fig.6 Transformation of robot coordinate system and world coordinate system
世界坐标系为XmOmYm,机器人坐标系为XrOrYr,机器人坐标系与世界坐标系的偏转角为θ。机器人在世界坐标系中的坐标为Or(xr,yr),目标在机器人坐标系中的坐标为P(xpr,ypr),即:
则目标在世界坐标系中的坐标为:
3.2.2 机器人朝向
根据目标在机器人左前方还是右前方消失决定机器人移动到目标位置时的朝向。例如,目标在机器人左前方消失,那么机器人最终朝向是左转90°。
在实际运行过程中,相机检测到目标消失前的最后一帧时,因为机器人运动的滞后性,机器人会根据目标消失前检测到的位置转动,从而造成目标定位偏差,如图7所示。目标消失位置为P1,机器人坐标系为XrOrYr。机器人根据目标位置转动,此时机器人坐标系为。若根据目标消失时的相对距离以及相对角度,目标将会被定位到世界坐标中的P2。如果目标位置被定位到障碍物,会导致路径规划失败,所以需要对目标消失时的世界坐标进行角度补偿。
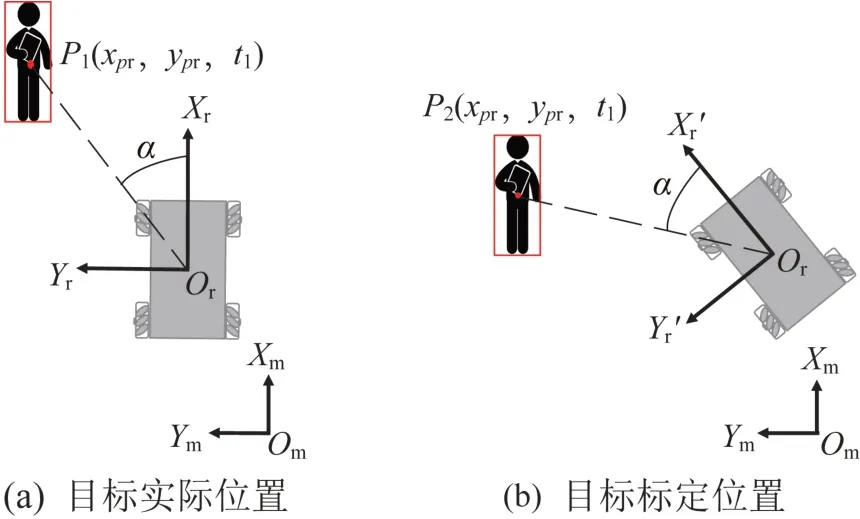
图7 机器人偏移后目标定位偏差Fig.7 Target positioning deviation after robot offset
根据式(15),可得:
目标消失时机器人的朝向可以通过机器人发布的Odom的四元数(x,y,z,w)求出:
机器人最终的朝向可表示为:
最终,将得到的欧拉角转换为四元数(x,y,z,w)发布。因为机器人只有偏航,不涉及俯仰和翻转,故只求z和w:
4 移动机器人目标跟随实验
移动机器人视觉跟踪定位系统采用搭载了RTX2060 GPU 的主机和Realsense D435 深度相机,其中CUDA (computer unified device architecture,计算机统一设备架构)版本为11.6,深度相机的分辨率为(640×480)像素,目标跟踪与定位算法运行速度为30帧/s,能够满足实时性要求。机器人搭载了Jetson TX1控制主板、四轮麦克纳姆轮,通过ROS操作系统进行控制,平均移动速度为0.8 m/s。
4.1 目标跟踪实验
首先在OTB100公开测试集上进行测试和评估。由于本文所提出的跟踪算法适用于行人跟踪,选取了OTB100测试集上的行人序列。
将本文算法的参数选为表1中的参数组1。当最优关联值小于0.175 时,认定目标关联成功,则更新卡尔曼滤波器以及目标的外观特征库F。当成功关联的检测框的外观特征余弦距离小于0.15,则将其更新到特征库F中。由于在测试集上评估,无法实现目标丢失后自主导航,故当目标丢失30帧后,将λ置为0。
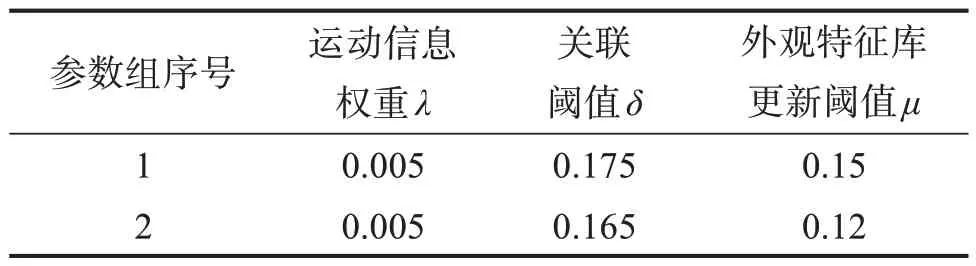
表1 本文算法的参数取值Table 1 Parameter values for the algorithm in this paper
采用精确度和成功率两个性能指标对算法进行评估。精确度是算法运行后输出的目标边界框中心点与真实框中心点的距离小于给定阈值的帧数占总帧数的百分比。绘制不同中心误差阈值下的精确度曲线,并将阈值为20像素所对应的精确度作为代表性的评价指标。成功率是目标边界框与真实框的区域重叠面积比大于给定阈值的帧数占总帧数的百分比,其取值范围为0~1,因此可以绘制出重叠率阈值从0到1时的成功率曲线。
采用OTB100 数据集对本文算法与KCF[14]、SiamFC[16]、SiamR-CNN(Siamese re-detection convolu‐tional neural network,孪生重检测卷积神经网络)[21],TLD(tracking-learning-detection,跟踪学习检测)[22]、DSST(discriminative scale space tracker,判别尺度空间跟踪)[23]、SRDCF(spatially regularized discrimina‐tive correlation filters,空间正则判别相关滤波)[24]等其他7 种算法进行比较,结果如图8 所示。由图可知,在OTB100数据集上测试时,本文算法的性能稍差于SiamRPN++算法,这是由于结合卡尔曼滤波后目标行人的肢体快速移动不会迅速影响跟踪框的位置,跟踪框主要集中在人体的躯干部分,导致一些视频的帧目标框与准确框的重叠面积比不够高。因此,当重叠率阈值为0.4~0.8 时,成功率下降较快。同时,本文算法明显优于其他6种算法,能够较快速地测到行人位置并识别目标,在目标被遮挡后具有更好的重识别能力。减小λ,可以有效处理相机剧烈晃动的情况。对于目标被遮挡,特别是当目标与其他行人重合时,可以通过减小δ和μ来解决。

图8 不同算法在OTB100数据集中的跟踪性能Fig.8 Tracking performance of different algorithms in OTB100 dataset
在OTB100 评估集上,测试序列大多在监控视角下,而缺少相机与行人近距离同时运动的情况。为了进一步评估本文算法的跟踪性能,作者在室外不同环境中收集了2个数据流。在黑暗环境中,光照有变化,目标有遮挡;在明亮环境中,背景复杂,相似行人多,干扰因素也较多。在收集的数据流中,图像的分辨率为(1 280×720)像素。采取本文算法对数据流中的目标进行跟踪,结果如图9所示。由图可知,在不同的照明条件下,采用本文算法均可以检测和定位目标。

图9 本文算法对数据流中目标的跟踪效果Fig.9 Tracking effect of the algorithm in this paper on the target in the data stream
从对上述2个数据流的测试结果可以看出,本文算法在行人跟踪方面有更好的表现。这主要源于以下两方面:其一,基于YOLOv5s 的检测器可以准确检测复杂环境中的人;其二,当目标消失后,得益于算法的目标跟踪机制,机器人可以准确地重识别目标。将基于卡尔曼滤波预测的运动信息与基于ResNet网络行人重识别的外观特征相结合来重识别目标,提高了重识别的准确性和目标跟踪的稳定性。
此外,为了进一步验证本文算法的优势,将本文算法的参数选为表1中的参数组2,采用收集的数据流对本文算法与SiamRPN[17]、SiamRPN++[18]和SiamBAN(Siamese box adaptive network,孪生自适应框网络)[25]等其他3 种算法进行对比实验,结果如图10所示。对于用于比较实验的数据流,通过Labelimg标注工具手动标记每帧中目标行人的边界框来获得真实标签(ground truth)。从2 个指标来看,本文算法明显优于其他算法。当场景中有相似行人时,其他方法仅通过外观特征很难在多个相似行人中跟踪到目标。本文算法加入了运动信息,可以有效解决出现外观相似行人后目标切换的问题。从整体上看,本文算法对复杂环境具有更好的适应性,对目标的重识别具有更高的准确性。
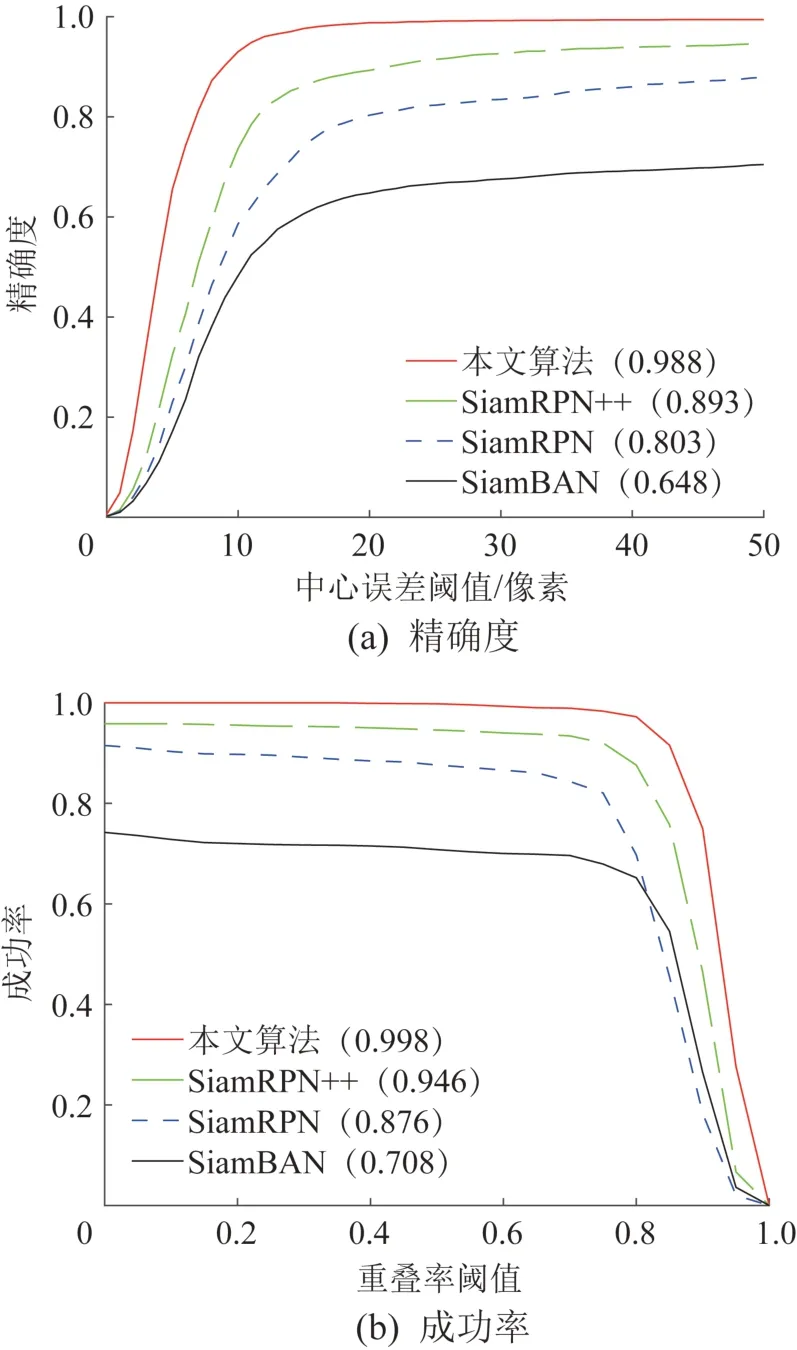
图10 不同算法在收集的数据流中的跟踪性能Fig.10 Tracking performance of different algorithms in the collected data stream
4.2 机器人目标跟随实验
为了在实际的机器人平台上评估本文算法的性能,在室内环境中进行了目标跟随实验。在机器人平台上安装了一台深度相机作为感知传感器。设定的目标行走路径如图11 所示,机器人相机视角的跟随效果如图12 所示,移动机器人跟随效果如13 所示。特别地,当目标消失后,机器人自主导航机制被激活,从而寻找目标并继续跟随,如图14所示。

图11 设定的目标行走路径Fig.11 Predefined target walking path

图12 机器人相机视角的跟随效果Fig.12 Following effect from robot camera's perspective

图13 移动机器人跟随效果Fig.13 Mobile robot following effect

图14 机器人寻找消失的目标Fig.14 Robot looking for the disappearing target
目标长时间消失后,机器人自主寻找目标,如图12(c)和图13(c)所示。当目标再次出现在机器人视野内时,其仍能跟踪到目标并跟随。在跟随过程中,机器人始终可以稳定地跟随目标,且处理图片的平均速率在30帧/s以上。实验表明,采用本文算法可以实现对目标的稳定、实时跟踪。
由图14可知,目标消失后,机器人能够准确地确定目标消失时的位置及方位,可有效解决目标消失后的跟随问题。
5 结 论
本文提出了一种基于视觉传感器的目标跟随方法。采用YoloV5s检测所有行人,通过人脸识别模块确定目标的位置。利用特征提取网络提取目标特征,创建特征库,采用卡尔曼滤波器对目标进行运动信息的预测,并结合运动信息和外观特征跟踪目标。此外,当机器人长时间捕捉不到目标时,通过自主导航移动到目标消失的位置寻找目标。将本文算法在OTB100数据集、收集的测试集中与其他算法进行了比较,并在机器人平台上进行了实验。结果表明,采用本文算法可以解决目标长时间消失或被遮挡的问题,在保证实时性的前提下能够准确、稳定地跟随目标。
未来,将进一步研究机器人在目标跟随过程中的避障问题,使机器人能够应对更加复杂的环境。此外,将多个传感器与相机结合起来,以进一步提高方法的稳健性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年6期)2022-07-02
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
紫禁城(2017年6期)2017-08-07
制造技术与机床(2017年3期)2017-06-23
小天使·一年级语数英综合(2017年6期)2017-06-07
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
