
基于代码序列与图结构的源代码漏洞检测方案
2024-01-04 06:26:28王守梁
中北大学学报(自然科学版) 2023年6期
王守梁
(中北大学 计算机科学与技术学院,山西 太原 030051)
0 引 言
软件源代码漏洞检测一直是软件安全领域的一个重要挑战[1-3]。随着大数据时代的来临,软件代码数量以量级攀升,软件更加复杂与多样,任何微小的漏洞都可能导致整个系统的崩溃。据统计,2022年,缺陷名录网站(NVD)全年的漏洞总数为6 515个,预期年增长率提升了170%; 公共漏洞披露平台(CVE)全年的漏洞总数为10 703个,预期年增长率为70%。政府单位、银行以及科技企业已成为漏洞攻击的重点[4],为了维护网络安全,需对软件源代码漏洞检测相关工作提出更高的要求。
传统的漏洞检测主要使用3种技术:静态分析技术[5]、动态分析技术[6]及机器学习技术[7]。静态分析指在不执行程序的情况下,通过扫描源代码,分析代码词法、语法、数据流及控制流等信息来筛选漏洞,耗时耗力。动态分析指在执行程序的情况下,通过聚焦执行路径、程序状态等信息来筛选漏洞,可扩展性差。机器学习技术借助预设特征的机器学习算法来检测漏洞,在复杂数据集上效果较差。
近年来,该领域研究方向有所转变,由被动检测转向漏洞代码的主动预测。同时,深度学习与漏洞检测的结合成为研究热点。现有的基于深度学习的漏洞检测成果表明,深度学习较传统技术检测具有更优越的检测性能。现有的检测方案亦存在一定的局限性。一类研究[8-11]将源代码看作特殊的自然语言,使用自然语言处理领域的成熟模型解决漏洞检测任务,未考虑代码的结构信息; 另一类研究[12-13]抽取代码对应的图表示并借助图神经网络解决漏洞检测任务,现有的相关方案一方面未考虑异类边的处理,另一方面忽略了节点内语句的局部语义信息。此外,现有研究多使用以word2vec[14]、glove[15]、fasttext[16]及doc2vec[17]为代表的传统词向量模型为标记生成固定的向量表示,未考虑代码上下文差异。
为解决以上问题,本文提出了一种函数级源代码漏洞检测方案,综合考虑源代码基于图的中间表示与基于序列的中间表示来辅助漏洞检测。
本文方案的实现步骤过程如下:1) 对源代码进行预处理,并抽取其代码属性图(Code Property Graph,CPG)[18]。受文献[19-20]中方法的启发,通过增加自定义类型的边对CPG图进行扩展,得到CPG’,其中,代码语句被解析为图节点,语句之间的关系被解析为图边。对于节点,分别对其类型与语句进行编码; 对于边,分别对其类型与方向进行编码。同时,采用关系图卷积神经网络(RGCN)聚合信息来生成最终图表示。2) 切分预处理后的源代码得到对应的标记序列,并使用基于程序语言的预训练模型CodBert[21]编码器,生成源代码对应的词向量矩阵。3) 集成以上两种表示并采用由全连接神经网络(FCNN)与sigmoid层组成的分类器实现漏洞检测。
1 相关工作
在源代码漏洞检测领域,现有的综述已从不同的角度对漏洞检测领域的研究进行了全面的总结[22-26]。本节将聚焦本文研究工作的三个关键方面:源代码中间表示、词向量技术与神经网络模型,并从以上三个角度对已有的漏洞检测工作分别进行总结回顾。
1) 源代码中间表示形式主要分为两类:一是序列形式,即将源代码转换成线性标记序列。Wang[27]、Russell[28]及Li[29]等在源代码序列基础上借助不同的神经网络模型实现了漏洞检测。二是图形式,即将源代码转换成结构图。Chakraborty[30]、Li[31]及Dong[32]等将源代码转换成CPG图,Li等[33]将源代码转换成PDG图,Fan等[19]将源代码转换成AST、CFG、DFG及NCS四种图。成果汇总见表1。本文按照图种类与所抽取的信息类型,对现有研究进行梳理,成果如表2 所示。其中,CPG图因其含有更多类型的边关系,能反映更丰富的程序结构信息而被多数研究采用。

表1 漏洞检测源代码中间表示研究汇总

表2 基于图表示的漏洞检测研究汇总
2) 词向量技术用于生成神经网络可处理的实值向量,其选取决定着漏洞代码的上下文信息的提取,进而影响模型的检测性能。Pradel和Sen[37]使用Word2Vec生成代码向量,用于训练深度学习模型,以检测JavaScript代码中的漏洞。Henkel等[38]应用GloVe从C程序的抽象符号轨迹中学习向量表示。Fang等[39]应用FastText进行基于集成机器学习模型的漏洞预测。Kanade等[40]提出了CuBERT,它通过在软件源代码上训练BERT模型来生成上下文嵌入。Karampatsis和Sutton[41]提出了一个名为SCELMo的模型来生成上下文代码向量。详细成果汇总见表3。

表3 词向量转化技术研究汇总
3) 神经网络模型主要分为两类,分别对应两种中间表示形式。包括卷积神经网络(CNN)、多层感知器(MLP)、深度置信网络(DBN)、长短期记忆网络(LSTM)及门控单元网络(GRU)等在内的多种神经网络模型被应用在基于序列的漏洞检测中并取得了良好的检测效果; 包括门控图神经网络(GGNN)、图卷积神经网络(GCN)等在内的多种图神经网络模型被应用在基于图的漏洞检测中,用于生成图向量。成果汇总见表4。

表4 漏洞检测神经网络模型汇总
2 模型设计
2.1 问题定义与整体架构
2.1.1 问题定义

2.1.2 整体架构
如图1 所示,该漏洞检测方案将函数级源程序样本作为输入,包括以下两大模块:特征抽取与特征学习。特征抽取阶段,使用两种方式对源代码进行处理:① 抽取函数源代码对应的多类型边结构图。② 抽取函数源代码对应标记序列。特征学习阶段,分别生成以上两种形式的中间表示对应的实值向量,并将二者集成拼接。最后,使用全连接网络输出漏洞检测结果。详细原理将在后续章节中进行阐述。

图1 本研究漏洞检测方案的整体架构
2.2 基于图的特征学习
2.2.1 图的生成
为学习源代码中的结构信息并提取漏洞特征,需要将其转换成合适的结构图。结构图的质量在很大程度上决定了从训练数据中学习到的特征数量,进而影响模型的漏洞检测性能。代码属性图(简称CPG) 提供了控制流图(简称CFG)和数据流图(简称DFG)中的元素以及抽象语法树(简称AST)和程序依赖图(简称PDG)的代码组合,是现存最综合全面的程序图表示,本文选择其作为源代码的初始结构图。
源代码函数对应的CPG按照以下流程生成:① 解析源代码函数生成AST。② 应用控制流分析生成CFG。③ 应用依赖性分析生成PDG。④ 在AST中添加CFG与PDG边生成CPG。以上过程使用工具Joern实现。
CPG在富含多种结构信息的同时,缺失了语句中的顺序信息,为解决此问题,本文在初始结构图CPG基础上增加自然代码序列边(NCS)[50]并对其进行了扩展,通过在AST中的相邻叶节点之间从左到右添加有向边,增加了代码编辑的时序信息,辅助漏洞检测。本文将最终得到的结构图记为CPG’=〈V,E〉,其中,V={v|v∈ASTnode}表示图中的节点集合,ASTnode表示函数的AST中的节点,每个节点包含节点类型与节点代码两种元素;E={e|e∈CFGedge或e∈DDGedge或e∈CDGedge或e∈ASTedge或e∈NCSedge}表示图中的边集合,这些边分别反映了节点之间的控制流、数据依赖、控制依赖、语法结构与时序信息。图2对应一个缓冲区溢出漏洞的简单样例,其main函数对应的CPG’如图3 所示。

图2 缓冲区溢出漏洞代码样例

图3 CPG’
后续任务中基于CPG’生成神经网络能处理的实值向量至关重要,本文将综合考虑结构图中的节点及边。
2.2.2 节点嵌入
节点嵌入模块分别对节点类型与节点代码采用不同嵌入方法来生成初始向量:① 对于节点类型,采用独热编码(one-hot)生成对应向量xi。② 对于节点代码,首先,完成标准化处理,将源代码中用户自定义的变量名称与函数名称采用统一标准进行重命名,用VAR与序号的组合替代自定义变量名,用FUN与序号的组合替代自定义函数名,如“VAR1”和“FUN1”,减少语料库规模与噪声干扰,提升向量生成的质量; 其次,使用基于编程语言的预训练模型CodeBert训练的单词嵌入权重初始化嵌入层权重,CodeBert模型使用的字节对编码(BPE)标记器[51]能在很大程度上缓解Out-Of-Vocabulary(OOV)问题; 最后,连接双向长短期记忆网络(Bi-LSTM)聚合局部语义信息,获得最终向量表示yi。最终,连接xi,yi得到节点vi对应的向量表示gi。
上述过程的形式化表述如下:
对于节点类型v[type,i],有
xi=one-hot(v[type,i])。
(1)
对于源代码S={s1,s2,s3,…,sn},其中,si对应节点vi中的代码。首先,进行标准化处理
S′=normalization(S)。
(2)

其次,通过CodeBert预训练的BPE标记器进行标记并使用CodeBert嵌入层权重来初始化自嵌入权重,以获得每个标记的向量表示eij∈Ei={ei1,ei2,ei3,…,ein}。
(3)
Ei=Codebert(tokensi)。
(4)
最后,连接Bi-LSTM获取与节点vi对应的语句si的向量表示yi。
(5)
(6)

最终,连接xi,yi得到节点vi的最终向量表示
gi=CONCAT(xi,yi)。
(7)
2.2.3 边嵌入
边嵌入模块分别对边方向与边类型采用不同嵌入方法来生成初始向量:① 对于边方向,采用深度优先遍历(DFS)将节点排序并从0开始编号,以节点编号数对的形式编码边方向; ② 对于边类型,采用标签编码(label encoding)将有限边类型进行编码。
上述过程的形式化表述如下:函数源代码对应的结构图记为CPG’=〈V,E〉,其中,V代表节点集合,E代表边集合。
对于边方向,有
IE={〈vi.order,vj.order〉|e=
〈vi,vj〉,e∈E}。
(8)
对于边类型,有
TE={te|e∈E},
(9)
(10)
图4 为一个函数源代码对应的边嵌入过程的示例。
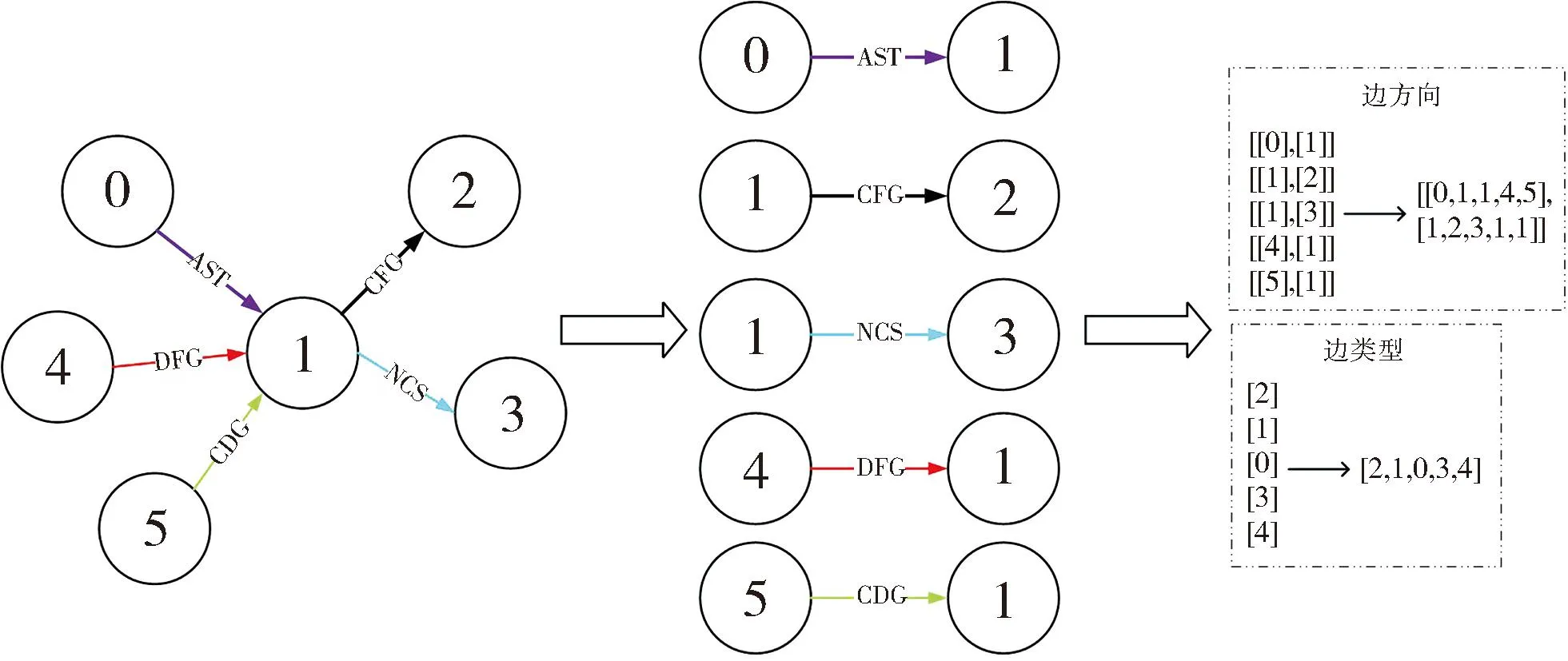
图4 边嵌入策略实例说明
图4 中,节点按照深度优先遍历算法进行编号,5条有向边分别对应5种不同的边类型,还给出了边方向与边类型对应的向量形式。
2.2.4 图神经网络
上述环节孤立考虑每个节点,仅根据单个节点包含的元素进行向量初始化,缺乏相邻节点的状态信息,无法较好地反映源代码的结构信息。本研究采用关系图卷积网络(RGCN)完成邻域聚合,进而更新节点状态。
图卷积网络(GCN)是CNN在图结构上的扩展,是在给定图上应用图卷积运算后,通过聚合其相邻节点的所有特征来更新节点。与连续计算节点状态的递归图神经网络(如GGNN)相比,GCN是每层更新一次节点向量,因此效率更高,可扩展性更强。RGCN是在GCN的基础上进行了增量改进,其通过在每种关系类型下用相邻节点更新节点来区别对待不同类型的边,更适合处理本文所抽取的多类型边异构图CPG’。如图5 所示,在每个RGCN层中,更新单个节点需要按边类型积累其所有相邻节点的信息,这些信息随后与该节点本身的特征相结合,通过激活函数(本文采用ReLU)传递,得到最终表示。
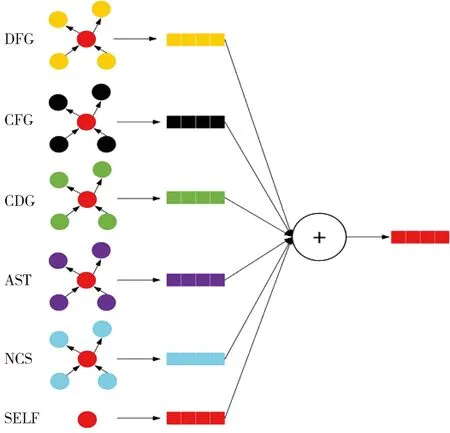
图5 节点更新过程
上述过程的形式化表述如下:
函数源代码对应的结构图记为CPG’=〈V,E〉,其中,V代表节点集合,E代表边集合。单个节点向量的更新公式为
(11)
2.2.5 图嵌入
图嵌入模块为基于图的特征学习的最后一步,目标是得到最终的图向量表示。本文通过聚合所有更新后的节点向量生成代表整个CPG’的单个向量,即
(12)
2.3 基于序列的特征学习
基于序列的特征学习是本方案理解源代码全局语义信息的关键过程。现有研究普遍采用以Word2vec,GloVe及FastText为代表的词向量模型生成源代码对应的实值向量,这些模型无法基于不同的代码上下文为相同标记生成不同向量,即仅为相同标记生成唯一向量,不考虑标记对应变量值的变化,忽略了上下文信息在漏洞检测工作中的关键作用。
本研究采用基于代码语言的预训练模型CodeBert来生成源代码的特征向量,充分考虑了上下文信息。相较传统词向量模型,CodeBert的模型结构要更复杂,其结构继承了BERT的架构,基于一个12层双向transformer,每层包含12个自注意头,每个自注意头的大小设为64,隐藏维度设为768,transformer的多头注意力机制能够集中数据流的多个关键变量,有助于分析和跟踪潜在的漏洞代码数据,帮助学习需长期依赖性分析的漏洞代码模式。此外,其内置字节对编码(BPE)标记器在很大程度上缓解了OOV问题,预训练技术也克服了数据集中漏洞样本过少或漏洞样本与非漏洞样本的不平衡所带来的过拟合问题。最后,对于每一个函数级源代码样本,CodeBert编码器生成对应的向量矩阵,并封装其语义含义。
上述过程的形式化表述如下:fi代表一个函数级源代码样本输入,其向量矩阵为
Pi=CodeBert(fi)。
(13)
2.4 特征融合
基于以上流程,分别获得了所有函数级源代码样本fi的基于结构图生成的向量表示G与基于序列生成的向量表示Pi。本研究采用连接操作组合二者,进而集成两种特征,生成所有源代码函数对应的最终向量表示Hi,其公式为
Hi=CONCAT(G,Pi)。
(14)
2.5 分类器
鉴于全连接神经网络(FCNN)的卓越性能和在顶级分类器中的主导地位,本文使用全连接网络作为漏洞检测分类器,其由输入层、隐藏层与输出层三部分组成。
上述特征融合模块的输出被作为输入层,最终,输出层将利用隐藏层特征进行漏洞预测。

(15)
(16)
式中:σ代表隐层激活函数;W1,W2,b1与b2代表可学习的参数。
3 实验设计
3.1 数据集
本文基于7个不同的c/c++源代码数据集开展实验。其中,4个为简单数据集,它们分别为CWE-362,CWE-476,CWE-754与CWE-758,其从代码结构和功能相对简单的软件中收集,包含可能更容易识别的漏洞模式; 剩余3个为复杂数据集,分别为Big-Vul[52],Reveal[30]与FFMPeg+Qemu[50],而Fan等[52]数据集涵盖了2002年至2019年的CWE。在函数粒度上,数据集包含超过10 000个漏洞函数。Reveal[30]数据集包含超过18 000个函数,其中9.16%是漏洞函数。FFMPeg+Qemu[50]数据集包含超过22 000个函数,其中45.0%的为漏洞函数。表5 展示了数据集的相关细节。
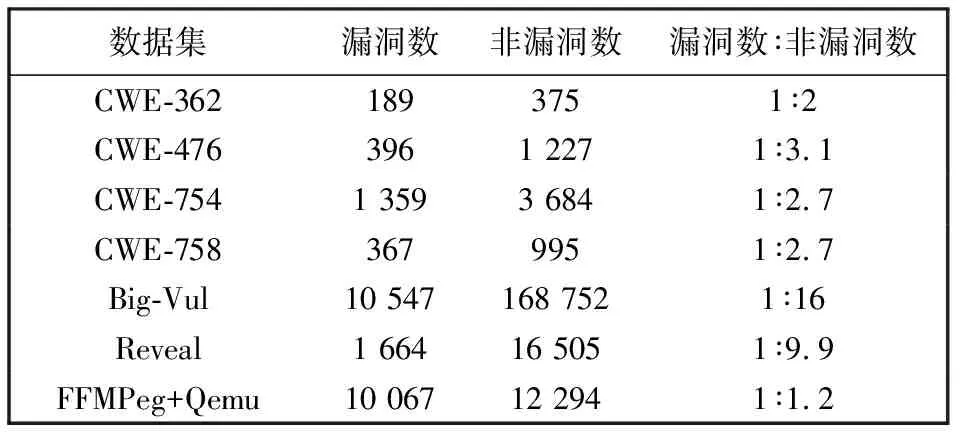
表5 7个数据集
3.2 研究问题
实验结果将以回答以下研究问题的形式呈现:
研究问题1:本文提出的漏洞检测方案与现有软件漏洞检测工具相比性能如何?
对照组1:AVDetect[28],VulDeePecker[29],Codebert[21];
对照组2:Devign[50],Reveal[30],IVDetect[33],FUNDED[20];
对照组3:DeepVulSeeker[34]。
以上实验方案均采用基于深度学习的漏洞检测技术,其中对照组1中的模型采用基于序列的方法,对照组2中的模型采用基于图的方法,而对照组3中的模型采用基于图与序列相结合的方法。
研究问题2:综合考虑图与序列信息是否有助于提升模型的漏洞检测性能?
本研究的漏洞检测方案抽取的信息类型包括图节点(节点类型与节点元素)、图边(边类型与边方向及序列信息),为验证综合考虑多类型信息对漏洞检测模型的有效性,采取控制变量的方法,减少对照组中抽取的信息类型。
对照组1:仅抽取图信息; 对照组2:仅抽取序列信息。
研究问题3:不同的节点初始化嵌入方法是否影响方案的漏洞检测性能?
本文漏洞检测方案采用预训练模型CodeBert对节点元素进行初始化,并通过再次训练微调嵌入权重。通过设计对照实验与其他图节点向量化方法进行比较,具体对照组设置如下:
对照组1:Word2vec; 对照组2:Dov2vec。
研究问题4:不同的序列初始化嵌入方法是否影响方案的漏洞检测性能?
本文漏洞检测方案采用预训练模型CodeBert对序列标记进行初始化,并通过再次训练微调嵌入权重。通过设计对照实验与传统的词向量模型进行比较,具体对照组设置如下:
对照组1:Word2vec; 对照组2:GloVe; 对照组3:Fasttext。
3.3 实验环境
本文漏洞检测系统开发环境为Linux操作系统,使用Python语言进行开发,深度学习库选择以Tensorflow-gpu为后端的Keras框架开发,其具体内置版本信息如表6 所示。

表6 实验环境参数
3.4 评估指标
本文采用4个指标对模型进行评估,即漏报率(FNR)、误报率(FPR)、准确率(Accuracy)及F1指数(F1_score),具体计算公式分别为
其中,
式中:NTP表示将正样本预测为正样本的数量;NTN表示将正样本预测为负样本的数量;NFP表示将负样本预测为正样本的数量,即误报;NFN表示将正样本预测为负样本的数量,即漏报。因此,漏报率(FNR)表示漏报的样本占正样本数量的比例,误报率(FPR)表示误报的样本占负样本数量的比例,准确率(Accuracy)表示预测正确的数据占总样本的比例,F1指数(F1_score)是根据准确率(Precision)与召回率(Recall)给出的一种综合评价,是二者的调和平均值。
具有高准确率(Accuracy)、高F1指数(F1_score)和低漏报率(FNR)、低误报率(FPR)的模型被认为是高效的。
4 实验结果及分析
4.1 研究问题1的实验结果
表7 与表8 展示了问题1所涉及的对照组1的实验结果。可以看出,在简单数据集上,本研究模型在 4个数据集上的平均准确率与F1值均高于对照组所有模型; 在真实世界数据集上,实验组除在FFMPeg+Qemu上的F1值略低于VulDeePecker[29]与codebert[21]以外,其他各项结果均高于对照组结果。

表7 对照组1的实验结果1
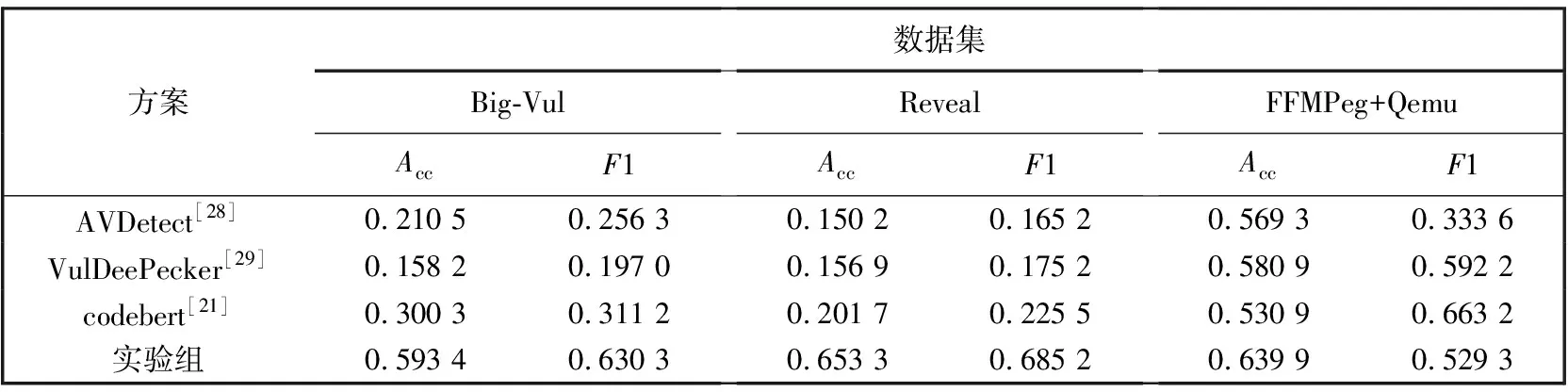
表8 对照组1的实验结果2
表9 与表10 展示了问题1所涉及的对照组2的实验结果。可以看出,在简单数据集上,本研究模型在4个数据集上的平均准确率与F1值均高于对照组所有模型; 在真实世界数据集上,实验组除在FFMPeg+Qemu数据集上的F1值略低于IVDetect[33]与FUNDED[20]以外,其他各项结果均高于对照组结果。

表9 对照组2的实验结果1

表10 对照组2的实验结果2
表11 与表12 展示了问题1所涉及的对照组3 的实验结果。可以看出,在简单数据集上,本研究模型在CWE-362与CWE-476上的两项指标均高于对照组模型,在CWE-754与CWE-758上的两项指标虽然相对略低,但两项指标均值仍分别达到0.980 8与0.972 4; 在真实世界数据集上,实验组除在FFMPeg+Qemu上的F1值略低以外,其他各项结果均高于对照组结果。

表11 对照组3的实验结果1

表12 对照组3的实验结果2
综上所述,可以得出
结论1:与现有方案相比,在两类数据集上,本研究的漏洞检测方案都有更卓越的性能。
4.2 研究问题2的实验结果
表13 与表14 展示了问题2对应的实验结果。可以看出,对照组1(即单独抽取图表示)的整体性能比对照组2(即单独抽取序列表示)更好,但实验组在两类数据集上的准确率与F1值均有更明显的提高。以上差距验证了图结构信息与序列语义信息对漏洞检测的重要性。

表13 研究问题2的实验结果1

表14 研究问题2的实验结果2
基于以上分析,可以得出
结论2:较单独考虑图或单独考虑序列,综合考虑二者的漏洞检测方案有着更好的检测性能。
4.3 研究问题3的实验结果
表15 与表16 展示了问题3对应的实验结果。可以看出,在两类数据集上,实验组都具有更高的准确率与F1值,其中,较对照组1,在简单数据集上,准确率差异的平均值达到0.172 3,F1值差异的平均值达到0.174 4; 在复杂数据集上,准确率差异的平均值达到0.139 4,F1值差异的平均值达到0.116 5。较对照组2,在简单数据集上,准确率差异的平均值达到0.130 1,F1值差异的平均值达到0.133 7; 在复杂数据集上,准确率差异的平均值达到0.110 1,F1值的差异的平均值达到0.091 5。以上差距验证了本文所使用的节点嵌入方式能有效替代传统的词向量方法,具有一定的合理性。

表15 研究问题3的实验结果1

表16 研究问题3的实验结果2
基于以上分析,可以得出
结论3:与传统的节点源代码初始化嵌入方式相比,本研究所采用的方法能更好地提取局部语义信息,进而提升方案的漏洞检测性能。
4.4 研究问题4的实验结果
表17 与表18 展示了问题4对应的实验结果。可以看出,所有对照组中,对照组2(即使用GloVe模型)的整体性能最好,然而,实验组的结果显示,在简单数据集上,准确率平均提高了0.061 1,F1值平均提高了0.070 7; 在真实世界数据集上,准确率平均提高了0.065 8,F1值平均提高了0.066 3。以上差距验证了预训练模型的引入较传统词向量模型对序列的嵌入有更好的效果,具有一定的合理性。

表17 研究问题4的实验结果1
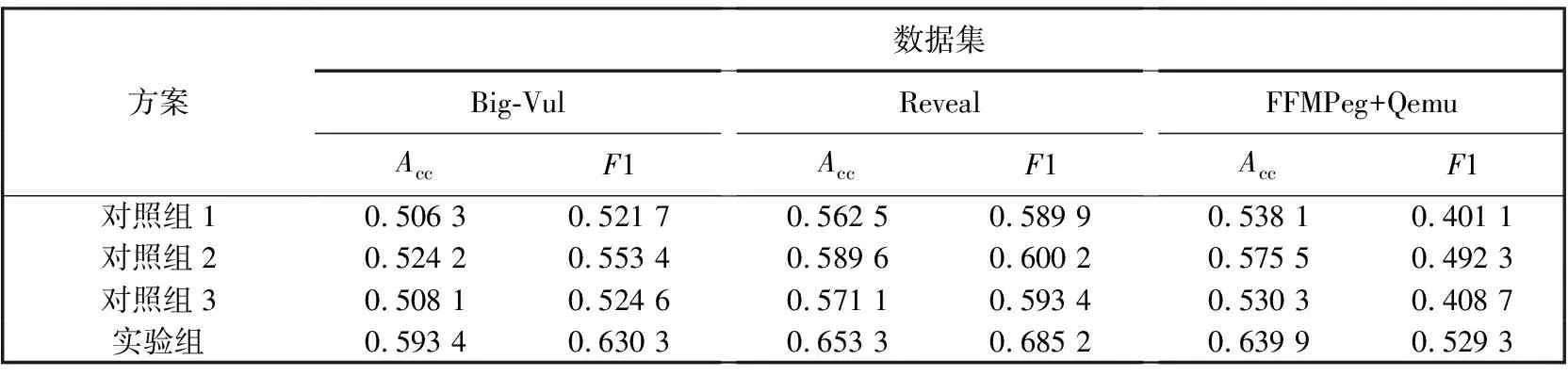
表18 研究问题4的实验结果2
基于以上分析,可以得出
结论4:与传统的源代码序列初始化嵌入方式相比,本研究所采用的针对代码的预训练模型能更好地提取抽取代码全局语义信息,进而提升模型的整体漏洞检测性能。
5 结 论
本文主要结论如下:1) 提出了一个函数级源代码漏洞检测方案,综合学习程序语义和结构信息来识别漏洞。本方案以自动化的方式捕获了比现有方法更综合的特征。2) 在多环节引入基于代码的预训练语言模型来代替传统的词向量模型进行信息编码。使用CodeBert生成源代码序列的词向量矩阵,使用CodeBert进行节点元素初始化并用BiLSTM聚合节点内部的局部语义信息。3) 分别在简单与复杂两类数据集上与现有检测方案进行了对照实验。实验结果表明,该方案在多个评估指标上显著优于现有的漏洞检测方法。此外,对照实验也验证了各环节的有效性,并且表明本研究对节点、边以及序列信息的处理策略优于现有其他方案。
本研究尚存在以下三点局限性:1) 预训练模型CodeBert含12个编码器层,参数多达1.1亿,训练与部署成本高昂。2) 数据集均为C/C++语言书写,语言类型单一。3) 仅关注漏洞识别,为二分类探究,无法准确区分漏洞类型。未来研究工作需要完善以上局限:1) 提出一个轻量级预训练模型。2) 扩展数据集以适应更多种类的程序设计语言。3) 扩展本方案以适应多类型的漏洞检测。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
今日农业(2022年13期)2022-09-15 01:21:08
现代信息科技(2021年21期)2021-05-07 21:44:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国司法鉴定(2018年4期)2018-07-30 06:08:26
数学物理学报(2017年5期)2017-11-23 07:51:31
中国卫生(2016年5期)2016-11-12 13:25:28
儿童时代(2016年6期)2016-09-14 04:54:43
中国房地产业(2016年8期)2016-03-01 01:25:55
