
基于改进Alphapose的红外图像人体摔倒检测算法
2024-01-03 07:31:46沈玉真李培华张恺翔
红外技术 2023年12期
张 鹏,沈玉真,李培华,张恺翔
基于改进Alphapose的红外图像人体摔倒检测算法
张 鹏,沈玉真,李培华,张恺翔
(中航华东光电有限公司,安徽 芜湖 241002)
红外图像中的人体摔倒检测不受环境光照射的影响,在智能安防领域有着重要的研究意义和应用价值。现有的摔倒检测方法没有充分考虑人体关键点的位置变化规律,容易对类摔倒动作造成误检。针对这一问题,本文提出一种基于改进Alphapose的红外图像摔倒检测算法。该算法使用Yolo v5s目标检测网络,在提取人体目标框输入姿态估计网络的同时,对人体姿态进行直接分类,再结合人体骨架关键点的位置信息和姿态特征进行判断。通过实验证明,该算法在准确度和实时性方面都有良好的表现。
红外图像;摔倒检测;关键点;目标检测
0 引言
人体摔倒检测可以有效地检测视频中的摔倒行为,降低人在摔倒后无法及时呼救的风险[1-3]。现有的基于计算机视觉的人体摔倒检测方法大多使用可见光图像,这类方法受光照影响在昏暗环境下效果不佳。红外图像能够保护个人隐私,而且不受光照和恶劣天气的影响,适用于全天候的人体摔倒检测,本文将对红外图像摔倒检测算法进行研究。现有的人体摔倒检测方法大致可分为以下3类:1)基于Freeman链码的检测方法,文献[4]利用Freeman链码记录轮廓信息,计算实际Freeman链码与摔倒模板链码的欧式空间距离结合时间判定条件判断是否发生摔倒行为,但在大规模遮挡时容易出现误差;2)基于关键点的摔倒检测方法,文献[5]利用建立的红外图像摔倒数据集进行CenterNet网络训练,识别红外图像中的人体姿态,但没有突出摔倒动作的时序性,容易对缓慢坐地等类摔倒动作造成误检;3)基于宽高比和质心变化率的检测方法,文献[6]利用人体宽高比这一特征来判断是否有人摔倒,并使用质心变化率和有效面积比对容易造成误判的情况进行修正,从几何特征的角度判断人体是否摔倒,但对特定角度的摔倒检测效果不佳。
针对上述算法的不足,本文在现有的摔倒检测方法的基础上提出了一种基于改进Alphapose的红外图像摔倒检测算法,该算法使用改进后的Alphapose检测红外图像中的骨架关键点和人体姿态,利用得到的人体骨架关键点信息和姿态类别进行摔倒判定,兼顾了摔倒动作的时序性和前后动作的关联性。
1 改进的Alphapose算法
1.1 YOLO v5s
人体检测的精度直接影响后续关键点检测的效果,是整个算法精度的保证。YOLO系列算法[7-9]将候选框的搜索和目标的识别定位合二为一,相对于RCNN[10-12]系列算法先搜索再识别的两阶段处理模式,YOLO算法的处理速度更快,适用于端到端的训练与预测,目前已发展至YOLO v5版本。YOLO v5的目标检测网络有4种版本,主要区别在于网络深度不同,如表1所示。

表1 YOLO v5各版本参数对比
从表1可以看到,YOLO v5s的模型更小、速度更快,方便部署在嵌入式设备上,本文算法使用YOLO v5s的网络结构。
YOLO v5s网络首先使用Focus模块对输入图像进行切片操作,如图1所示。如果网络输入的图片大小为640×640×3,则将图像隔行隔列取值,生成320×320×12的子图,再通过32个卷积核卷积生成320×320×32的特征图。相对于普通下采样,Focus模块保留了原始图片的完整信息。
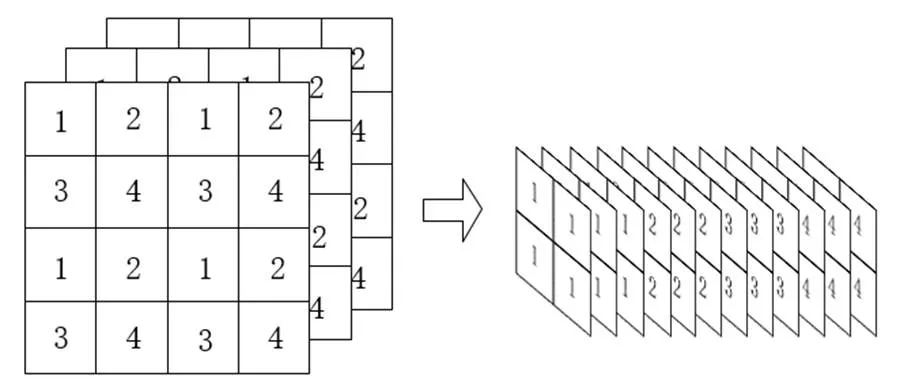
图1 Focus模块
YOLO v5s的Backbone部分使用了CSP[13]模块,将输入的特征映射划分为两部分,其中一部分经过多个残差组件和卷积,然后与另一部分拼接,在减少计算量的同时可以保证准确率。
Neck部分采用了PANet[14]结构,主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
1.2 Alphapose算法
Alphapose[15]算法是一种人体姿态估计算法,能够检测出图像中的人体骨架,其提出一种区域多人姿态估计框架(regional multi-person pose estimation,RMPE),主要由对称空间变换网络(symmetric spatial transformer network,SSTN)、参数化姿态非极大抑制(parametric pose no-maximum-suppression,PP-NMS)、姿态引导建议发生器(pose-guided proposals generator,PGPG)和并行单人姿态估计器(parallel single person pose estimation,Parallel SPPE)组成,其中PGPG用于生成大量训练样本,Parallel SPPE则充当额外的正则项,以避免局部最小值,而SSTN又由空间变换网络(STN)、单人姿态估计器(SPPE)和空间反变换网络(spatial de-transformer network,SDTN)组成。Alphapose首先使用目标检测算法检测单张图片,得到单人人体目标框,作为RMPE的输入,进入SSTN模块。检测到的人体目标框可能目标偏离中心或者目标框中人体占比过小,影响后续姿态估计的效果,所以需要先使用STN提取出高质量的单人区域,然后输入SPPE得到估计的姿态,再由SDTN将估计的姿态反变换到原始人体区域框中。冗余的人体区域框输入姿态估计网络,可能会检测到冗余的姿态。Alphapose提出PP-NMS用来消除多余的姿态。其定义了一种姿态距离来度量姿态间的相似度,并在此基础上建立了冗余姿态的消除标准。PP-NMS首先选取最大置信度的姿态作为参考,并且根据消除标准将靠近该参考的区域框进行消除,多次重复这个过程直到消除所有的冗余识别框。
1.3 改进的Alphapose算法
原Alphapose算法主要使用的人体检测器是YOLO v3,与之相比,YOLO v5s的模型更小,速度更快。本文算法使用YOLO v5s作为Alphapose的人体检测器,改进后的Alphapose算法结构如图2所示。
改进后的算法使用YOLO v5s网络完成对人体姿态的直接分类,同时从输入的红外图像中提取人体区域框,输入人体姿态估计网络检测人体骨架关键点,将关键点信息与预测的姿态类别一并输出。
2 基于改进Alphapose的红外图像摔倒检测方法
本文提出基于改进Alphapose的红外图像摔倒检测算法。该算法首先使用YOLO v5s网络对图像中的人体姿态进行分类,再提取人体目标框检测出单人的骨架关键点,最后利用关键点和姿态类别信息,通过关键点分析和摔倒判定,判断是否出现摔倒。

图2 改进的Alphapose算法结构
2.1 关键点分析
Alphapose算法检测出的人体骨架关键点如图3所示。

图3 Alphapose关键点检测结果
图3(a)是站立时的人体骨架,图3(b)是摔倒后的人体骨架。图中编号为0~17的点代表检测得到的18个人体骨架关键点,其中点11和点12所在位置代表髋关节。
通过实验发现,站立或行走的人体目标在发生摔倒时,最直观的表现是髋关节位置在垂直方向上的迅速下跌,所以通过监测髋关节在序列帧中的移动速度可以及时发现产生的摔倒动作。但随着运动中的人体目标与摄像头的距离越来越远,其髋关节在图像上的位移速度也越来越小,容易造成漏检。针对该问题,本文提出以前一帧中人体目标框的高度作为参考对象,计算髋关节关键点的相对移动速度。
在对红外视频的检测中,设第帧与第-1帧均为单人红外图像,2≤≤,表示红外视频的总帧数,且都是非遮挡状态,其髋关节关键点均被检出。设图像左上角为原点,水平向右为轴正方向,垂直向下为轴正方向,建立直角坐标系。记第帧人体骨架中编号为的关键点的纵坐标为y,取点11和点12的中心点代表髋关节,则点在第帧中的纵坐标y如式(1)所示。

在摔倒过程中,当前一帧人体目标框的高度明显小于其宽度时,即使下降速度不变,也会因为前一帧目标框高度减小,导致计算得到的速度偏大,所以本算法引入前一帧人体目标框的宽高比作为限制条件,防止前一帧目标框宽高比过大导致点的微小起伏被误识别为摔倒。记第帧中人体目标框的高度为H,宽度为W,则第帧中的人体宽高比P如公式(2)所示:

记第帧中点在垂直方向上的相对移动速度为v,如公式(3)所示:
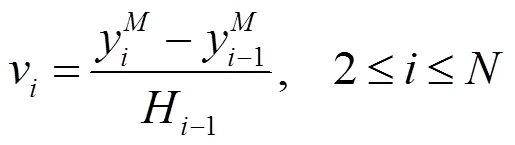
设置大于0的阈值Th,检测可能出现的摔倒行为,如公式(4)所示。
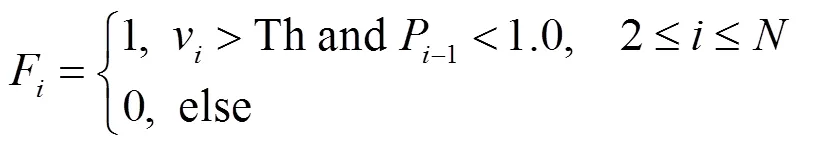
当F等于1时,判断可能发生了摔倒。
2.2 摔倒判定
仅仅分析关键点的下落速度有可能将快速下蹲、俯身拾取等类摔倒动作误识别为摔倒,为了减少误判,需要结合关键点分析结果和姿态分类做进一步判定。
经实验发现,摔倒后人体姿态会在短时间内稳定,直观表现是坐在地上、躺下或手部撑地,所以本文算法在经过关键点分析判断有可能发生摔倒后,继续检测后续多帧内的人体姿态。
在统计后续的人体姿态中,若第帧图像中人体姿态类别为l,则对应的人体图像得分为s,两者关系可用公式(5)表示:
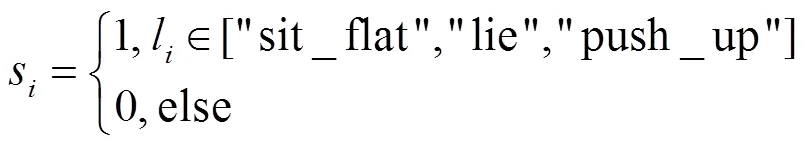
式(5)中:当图像中的人体姿态类别l为“sit_flat”(坐地)、“lie”(躺下)、“push_up”(撑地)这3种姿态中的任意一种时,该人体图像的得分记为1,否则得分记为0。
当F=1,即第帧检测到可能发生摔倒时,继续检测后续20帧图像的人体姿态,若累计图像得分大于10,最终判定为摔倒,记为FF=1,如公式(6)所示:
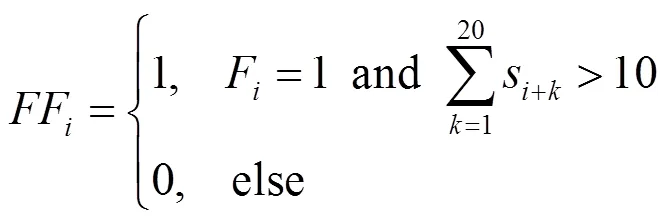
在实时检测过程中,以实时视频流作为输入,检测每一帧当前画面中的人体姿态和骨架关键点。从第二帧开始,如果前一帧与当前帧均检测出同一人的髋关节位置,即“无遮挡”状态,则进行关键点分析,计算髋关节关键点在这相邻两帧间的相对移动速率和方向。当满足可能摔倒的条件后,进行摔倒判定,开始统计后续20帧图像中的姿态类别,如果满足最终摔倒条件,则判断为一次摔倒。实时检测的情况下一次完整的摔倒检测流程图如图4所示。
3 数据集
3.1 采集和分类
本文使用的数据集分为3部分。第一部分是自建的室内红外数据集,摄像头采用艾睿光电红外热成像模组Xmodule T3,分辨率384×288,样本共6787张,场景包括走廊、办公室、大厅等室内场景;第二部分是运动物体热红外成像数据集(moving object thermal infrared imagery dataset,MOTIID),样本取自其中三段室外行人行走的视频,获取样本571张,均为室外场景;第三部分使用的是开放的免费FLIR热数据集FLIR_ADAS,获取样本926张。
本文对红外图像下的人体姿态定义了8种类别,分别是“直坐”、“躺下”、“下蹲”、“站立”、“弯腰”、“撑地”、“坐地”和“遮挡”,如图5所示。

图4 总体算法流程

图5 姿态分类:(a) 直坐;(b) 躺下;(c) 下蹲;(d) 站立;(e) 弯腰;(f) 撑地;(g) 坐地;(h) 遮挡
3.2 数据预处理
本文采用了Mosaic数据增强的方式对训练数据进行预处理,如图6所示,Mosaic数据增强通过每次随机抽取数据集中的4张图片,采用随机裁剪、随机缩放、随机组合的方式生成一张新的训练图片。通过Mosaic数据增强,能够丰富场景内容,增强样本多样性,提高目标检测算法的抗干扰性。
4 实验分析
本实验的实验环境为Win10_x64平台,CPU为Intel Core i7-9750H,内存16G,GPU为NVIDIA GeForce RTX 2060,使用框架为torch1.6.0+opencv-python4.4.0,输入图片尺寸384×288,学习率为0.01,epochs为100。实验分为两部分:进行红外人体骨架检测实验,以测试本文算法定位精度和实时性;进行红外视频摔倒判定实验,以验证本文策略的可行性。

图6 Mosaic数据增强
4.1 红外人体骨架检测实验
为了排除遮挡状态对关键点检测的干扰,需准确识别遮挡与非遮挡状态,如图7所示。
图7(a)与图7(d)分别是遮挡状态的两种标注方式示意图,图7(a)将未被遮挡的人体部分标注为遮挡,其预测结果如图7(b)和图7(c)所示,图7(d)在标注遮挡类别的目标框时加入部分遮挡物,其预测结果如图7(e)和图7(f)所示。从图7(b)中可以看到,全身被识别为站立姿态的同时,上身也被识别为遮挡,即出现了冗余检测,而如图7(e)和图7(f)所示,在遮挡状态标记框中加入部分遮挡物后,站立和遮挡得到了明显的区分。经实验,在标记遮挡状态时,当选取的遮挡物在标记框纵向占比为0.2或横向占比为0.3时,对遮挡和非遮挡状态的区分效果较好。
本实验将本文算法与原Alphapose算法进行对比,取500张图片作为测试集,部分检测结果如图8所示。
本实验采用DIoU(Distance-IoU)衡量算法的定位精度,DIoU反映了真实与预测之间的相关度,计算方法如公式(7)所示:
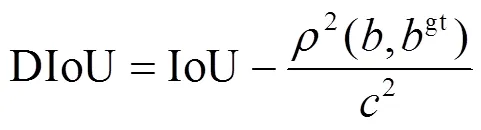
式(7)中:和gt分别表示预测框和真实框的中心点位置坐标;(,gt)是两个中心点之间的欧氏距离;表示真实框和预测框的最小外接矩形的对角线距离;IoU表示真实框与预测框之间的交并比。DIoU值越接近于1,则预测位置越接近真实位置。
分别使用原Alphapose算法和本文算法计算DIoU值,其平均值DIoU_Average和平均处理时间如表2所示。

图7 遮挡状态标注与预测图:(a) 标注时不含遮挡物;(b) 无遮挡物标注方式检测无遮挡状态;(c) 无遮挡物标注方式检测遮挡状态;(d) 标注时含部分遮挡物;(e) 含遮挡物标注方式检测无遮挡状态;(f) 含遮挡物标注方式检测遮挡状态
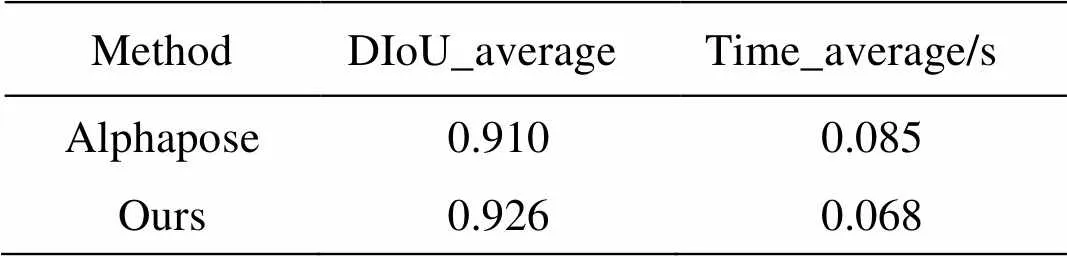
表2 实验结果
由图8(a)和图8(b)可以看到,因为在标记遮挡姿态时加入了部分遮挡物,所以识别出的遮挡姿态目标框也向被遮挡方向进行了部分延伸,符合遮挡的特征,这也验证了本文针对遮挡姿态修改标记方法的有效性。如图8(a)~图8(b)所示,原Alphapose算法与本文算法的检测结果基本相近,但也出现少数偏差。原Alphapose算法对“躺下”姿态的定位不够准确,导致后续的骨架检测出现误差,而本文算法得到的预测框更加逼近其真实目标框,得到的人体区域更加紧凑,检出的人体骨架也较准确。结合表2中的计算结果可知,本文算法对人体区域的定位较准,速度更快。如图8(c)~图8(d)所示,本文算法也可检测室外人体目标,但对于远距离的人体可能产生漏检,如图8(d)所示,远处路灯下的人体没有被检出。同时,在人群聚集和多人重叠场景下,容易发生漏检现象。

图8 实验结果:(a) Alphapose检测自建红外数据集;(b) Ours检测自建红外数据集;(c) Ours检测MOTIID红外测试集;(d) Ours检测FLIR_ADAS数据集
4.2 红外视频摔倒判定实验
本实验使用本文算法检测实时红外视频流,从中截取12段热红外视频,共计36个摔倒动作和51个类摔倒动作,其中类摔倒动作包括快速下蹲、俯身拾取和缓慢坐地。记摔倒动作被识别为摔倒的个数为TP,摔倒动作被识别为非摔倒的个数为FN,类摔倒动作被识别非摔倒的个数为TN,类摔倒动作被识别为摔倒的个数为FP。改变阈值Th,计算不同阈值下的准确率,计算方法如公式(8)所示:

从表3可以看出,当Th大于或等于0.04时,漏检的摔倒个数逐渐增多,因为设定的阈值大于部分真实摔倒动作的相对位移速度,容易将真实的摔倒动作漏检。而当Th小于或等于0.03时,真实的摔倒动作已全部被正确检出,但也出现误识别的情况,如将俯身拾取动作误识别为摔倒,如图9所示。

表3 不同Th下检测结果
图9(a)与图9(b)分别是Th取0.03时,本算法对真实摔倒动作和俯身拾取动作的检测结果,图9(c)是Th取0.01时,本算法对俯身拾取动作的检测结果。从图9(c)可以看出,当Th取值偏小时,因为俯身拾取动作在下蹲过程中可能其速度大于设定的阈值,所以有可能将俯身拾取识别为摔倒。而当Th取0.03时,可有效过滤此类动作,并且能够检测出真实的摔倒动作。因为在本实验环境下,阈值Th为0.03时,准确率最高,所以取0.03作为本实验环境下Th的最佳值。因为本文策略以关键点瞬时位移速度大于阈值为前提,辅以后续姿态加以判定,而快速下蹲动作不满足其后续姿态判定中对撑地、坐地或躺下的要求,所以实验中没有出现快速下蹲被误识别为摔倒的情况。从实验结果来看,本算法对快速下蹲、缓慢坐地、俯身拾取这样的类摔倒动作具有一定的抗干扰性。

图9 摔倒检测结果:(a) Th=0.03时,真实摔倒动作检测结果;(b) Th=0.03时,伪摔倒动作检测结果;(c)Th=0.01时,伪摔倒动作检测结果
本实验的目的是对真实摔倒动作与类摔倒动作进行区分,可以根据当前Th得到的准确率变化情况更新Th值。如果本轮Th得到的准确率高于上一轮的准确率,则表明Th的变化方向是有效的,反之则表明上一轮Th值更接近最优值,转而反方向寻值。在迭代过程中,当准确率变化趋势发生改变时,通过改变步长逼近最佳阈值。阈值Th的更新计算公式如式(9)所示:

式中:Th表示第轮迭代中的阈值;*(-2)-表示阈值的变化步长。本实验中取值0.04,的初始值设为1,记阈值为Th时的检测准确率为Acc。
更新过程步骤如下:
1)设置初始阈值Th0=0.05,此时=0,按式(8)计算对应的检测准确率Acc0;
2)设=1,=0.04,按公式(9)计算Th+1,并计算对应的Acc+1;
3)若Acc+1>Acc,则=+1,再按公式(9)计算下一代阈值Th+1,并计算Acc+1;否则,=+1,=+1,再按公式(9)计算Acc+1;
4)重复执行步骤3)。
5 总结
针对现有人体摔倒检测方法对类摔倒动作容易误检的问题,本文提出基于改进Alphapose的红外图像摔倒检测算法,使用改进的Alphapose算法检测红外图像中的人体关键点和姿态类别,结合人体关键点信息和姿态类别进行摔倒判定。本文在原算法的基础上,使用YOLO v5s作为Alphapose的人体检测器和姿态分类器,在提取人体目标框的同时直接完成对人体姿态的分类,在摔倒与类摔倒场景中,对人体摔倒检测的准确率达到98%。本算法也存在着不足,如本算法利用人体关键点的位置信息做关键点分析,适用于无遮挡状态下的人体摔倒检测。阈值的选取与算法在不同设备上的运行速度有关,对阈值的自适应取值是后续研究的重点。
[1] 禹明娟. 基于视频的室内老人摔倒检测研究[D]. 杭州: 杭州电子科技大学, 2016.
YU M J. Research of Indoor Fall Detection for Elderly Based on Video[D]. Hangzhou: Hangzhou Dianzi University, 2016.
[2] 陈永彬, 何汉武, 王国桢, 等. 基于机器视觉的老年人摔倒检测系统[J]. 自动化与信息工程, 2019, 40(5): 37-41.
CHEN Y B, HE H W, WANG G Z, et al. Fall detection system for the elderly based on machine vision[J]., 2019, 40(5): 37-41.
[3] 杨碧瑶. 基于计算机视觉的独居老人摔倒检测方法研究[D] . 西安: 陕西科技大学, 2020.
YANG B Y. Research on Fall Detection Method of Elderly Living Alone Based on Computer Vision[D]. Xi’an: Shaanxi University of Science & Technology, 2020.
[4] 马照一. 用于老年人居家养老的智能视频终端的设计与实现[D]. 沈阳: 辽宁大学, 2017.
MA Z Y. The Design and Implementation of Intelligent Video Terminal for The Aged Home Care[D]. Shenyang: Liaoning University, 2017.
[5] 徐世文. 基于红外图像特征的人体摔倒检测方法[D]. 绵阳: 西南科技大学, 2020.
XU S W. Detection Method of Human Fall Based on Infrared Image Features[D]. Mianyang: Southwest University of Science and Technology, 2020.
[6] 徐传铎. 夜间模式下基于人体姿态的安全监控研究[D]. 上海: 东华大学, 2017.
XU C D. Research on Safety Monitoring Based on Human Posture for Night Vision[D]. Shanghai: Donghua University, 2017.
[7] Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]//, 2017: 6517-6525.
[8] ZHAO L, LI S. Object detection algorithm based on improved YOLO v3[J]., 2020, 9(3): 537.
[9] 李昭慧, 张玮良. 基于改进YOLO v4算法的疲劳驾驶检测[J]. 电子测量技术, 2021, 44(13): 73-78.
LI Z H, ZHANG W L. Fatigue driving detection based on improved YOLOv4 algorithm[J]., 2021, 44(13): 73-78.
[10] Girshick R, Donahue J, Darrell T, et al. Region-based convolutional networks for accurate object detection and segmentation[J]., 2015, 38(1): 142-158
[11] Girshick R. Fast R-CNN[C]//, 2015: 1440-1448.
[12] REN S, HE K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//, 2015: 91-99.
[13] WANG C Y, Mark Liao H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//, 2020: 390-391.
[14] LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]//, 2018: 8759-8768.
[15] FANG H S, XIE S, TAI Y W, et al. RMPE: regional multi-person pose estimation[C]//2017, 2017: 4321-4331.
Infrared Image Human Fall Detection Algorithm Based on Improved Alphapose
ZHANG Peng,SHEN Yuzhen,LI Peihua,ZHANG Kaixiang
(,241002,)
Human fall detection in infrared images is not affected by ambient light and has important research and application value in intelligent security. Existing fall detection methods do not fully consider the position change law of key points on the human body, which can easily cause false detections of similar fall movements. To solve this problem, we propose an infrared image fall detection algorithm based on an improved alpha pose.The algorithm uses the YOLO v5s object detection network to directly classify human poses while extracting the human body target frame and inputting the pose estimation network. It then evaluates it in combination with the position information and posture characteristics of the key points of the human skeleton. Experiments showed that the algorithm exhibited good performance in terms of accuracy and real-time performance.
infrared images, fall detection, key points, object detection
TP391
A
1001-8891(2023)12-1314-08
2021-09-23;
2021-10-13.
张鹏(1994-),硕士研究生,主要研究领域为模式识别、图像处理。E-mail: zhangpeng2735@163.com。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
金桥(2021年4期)2021-05-21 08:19:20
学生天地(2020年3期)2020-08-25 09:04:16
电子制作(2019年7期)2019-04-25 13:17:14
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
光学精密工程(2016年3期)2016-11-07 09:03:43
中国卫生(2014年2期)2014-11-12 13:00:16
