
基于GEE 的黑龙江省松花江流域水质等级遥感反演
2024-01-03 01:05:22赵梓琦ZHAOZiqi
价值工程 2023年35期
赵梓琦ZHAO Zi-qi
(哈尔滨师范大学地理科学学院,哈尔滨 150025)
0 引言
水质监测是进行水质状况综合评价与水污染防治的重要依据,尤其是对内陆水体的水质监测[1-3]。传统的水质监测指标是通过野外采集水样,进行化学分析来确定,这种现场采样测量方式具有很高的准确度,但此过程因监测范围广,采样数据量大,耗费大量的时间和劳动力,且在区域大尺度上,使用传统的点采样方式分析水质,在进行识别水质的时空变化上具有不确定性[4-6]。近几十年来,学者们主要关注各种遥感数据源的应用和众多反演方法的改进,以追求高精度的预测[7-9]。传统技术已经无法满足研究人员的需求且传统方法由于数据的底层关系无法描述,很难捕捉到水质特征。作为人工智能的一个重要分支,机器学习是利用大量数据产生数学模型的学习算法。近年来,随着水环境领域监测数据的增多,机器学习在水质预测中的应用研究逐渐增多[10]。Tiyasha[11,12]等使用支持向量机进行水质分类,该方法在水质监测领域取得了广泛的应用,但在基于遥感和物联网的水质监测站,目前并没有很成熟的测量传感器,使得越来越多的数据以高速和不规则的方式产生,导致水质数据具有复杂性[13],不能以高精度和高效率实时处理数据[14]。李雪清等通过收集广东省31 个水质监测站在2008-2016 间的水质等级数据作为训练样本,运用机器学习技术,建立区域水质等级预测模型,但该模型以每周的数据为研究对象,对样本量较少的水质等级预测适用性较差,难以实现水质实时动态监测[15]。
松花江为黑龙江省在中国境内的最大支流,现有研究对区域大尺度水环境综合治理的支撑能力不足,随着水环境实时数据的不断丰富,为长时序动态监测内陆水体提供了数据支持。
本研究采用黑龙江省松花江流域37 个国控断面2022 年6 月、7 月、8 月实时水质等级数据以及Landsat8 OLI 遥感影像作为数据源。相比传统遥感影像需要先下载后处理的研究方式,本研究使用GEE 遥感云服务平台,直接对Landsat8 OLI 数据集进行在线分析,将更多的精力用于后端的科学分析,更加适用于长时间序列的研究。分别运用RF、CART、SVM,建立水体光谱反射率与水质等级之间的关系,分析三种机器学习模型在样本量较少,区域大尺度上水质等级预测上的性能表现,提供更精确和更高时间分辨率的长期动态监测,为区域水环境治理实时提供宏观决策支持。
1 区域概况
松花江是中国七大河之一,涵盖东北四省区。松花江流域介于41°42'~51°38'N、119°52'~132°31'E 之间,分为南北两源。流域面积55.72×104km2,超过珠江流域面积,径流总量759×109m3,超过黄河的总径流量,为黑龙江省在中国境内的最大支流,是三江平原的孕育者[16]。(图1)
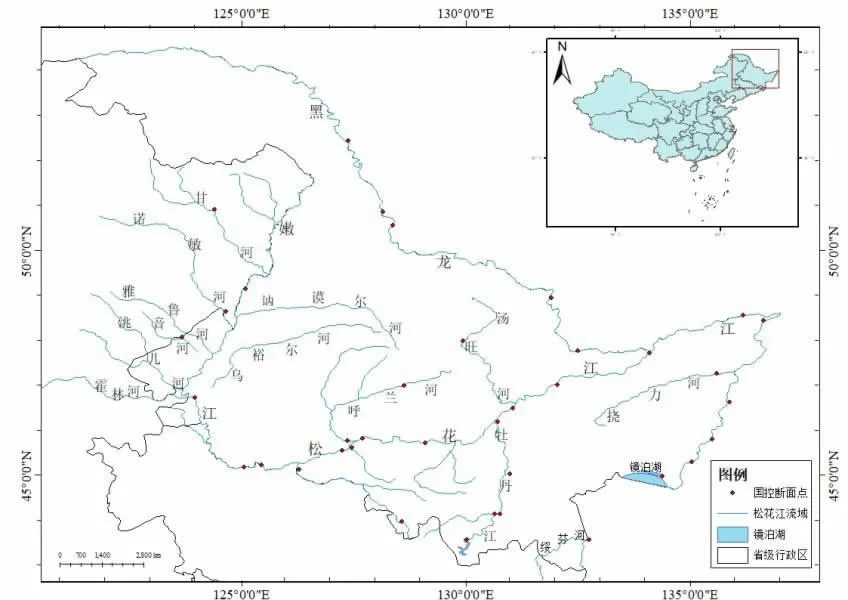
图1 黑龙江省松花江流域水区和监测点
2 材料与方法
2.1 数据获取与预处理
Landsat8 于2013 年2 月11 日由NASA 成功发射,携带两个传感器:操作陆地成像仪(OLI)和热红外传感器(TIRS)。本文中的遥感数据来自前者,遥感影像来自GEE网站[17]。实测数据来源于国家地表水水质自动监测数据发布系统国控断面收集点,由于这些数据收集点广泛的分布在黑龙江省松花江流域的各个地区,其特征具有表达整体的能力,这为后续的水质等级反演提供了可靠有效的数据源。
数据预处理均在GEE 上进行,按GB3838-2002 的二级标准进行水质计算,将实测数据水质等级分为5 类,制作水质等级标签。最后遍历当前影像样本点特征集合,与实测数据进行时空匹配,剔除水质等级为null 的特征,建立实测数据与光谱反射率之间的关系,匹配后的数据用于训练模型。
2.2 反演模型的建立
基于GEE 平台分别建立RF、CART、SVM 分类反演模型。其中RF 的基本原理是由很多决策树分类模型组成的组合分类模型。通过randomColumn 函数将全部特征集合按照7∶3 随机分为训练集以及测试集,考虑标记水质等级的特征为6 月、7 月的数据,8 月数据未进行水质等级的划分,因此训练集选用6 月、7 月与实测数据进行时空匹配后具有水质等级属性的特征集。建立RF 反演模型公式如下:
注:H(x)表示组合分类模型,hi是单个决策树分类模型,Y 表示目标变量,I()为示性函数。
CART 的基本原理是通过对训练数据集的循环分析形成二叉树形式的决策树。当决策树的层数达到预先设置的最大值,或所有叶结点中的样本属于同一个类别或样本数为1 时,CART 决策树算法建树停止生长,完成分类器的训练。使用smileChart 函数,建立分类决策树的公式为:
注:式中GINI(D,A)为在已知特征A 的条件下集合D的GINI 指数。GINI(D,A)取值越大,样本的不确定性也越大,此处需要选择满足GINI(D,A)取最小值的特征A。
SVM(是一种二分类模型,基本模型是定义在特征空间的间隔最大的线性分类器。SVM 的主优化问题为凸优化问题,满足强对偶性,可通过最大化对偶函数求解。模型选择优先选择高斯核,相比线性核更能处理复杂的问题。建立支持向量机反演模型公式如下:
注:根据输入训练集得到分类决策函数,选择惩罚参数C>0 得到最优解α*,选择α*的一个分量得到b*。
3 结果与分析
其中6 月、7 月份符合要求影像共35 张,遍历影像集后返回样本点特征集共66 个特征,根据实测数据集进行时空匹配后共48 个特征具有水质等级属性。对具有标签的48 个特征和8 月未进行水质等级划分的数据进行反演,随机抽取的测试集共32 个样点,其中8 月数据共18个样点,结合8 月实测数据制作混淆矩阵如图2。其中随机森林相比其他两种模型对每种类别反演准确率和精确度较好,准确率为71.875%。从模型分类精度以及反演准确率上来看,随机森林使用多颗决策树对样本进行训练并预测,其中包含多个决策树的算法。相比单独使用CART决策树或SVM 支持向量机进行分类,其输出的类别是由个别决策树输出的众树决定,在水质等级划分上分类结果更加准确,且容易实现并行化计算。
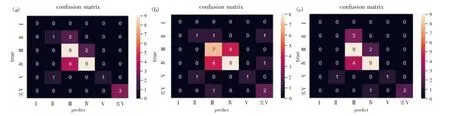
图2 a、b、c 分别代表随机森林、CART 决策树、SVM 支持向量机的混淆矩阵
4 结论
本研究应用GEE 遥感云服务平台Landsat8 OLI 遥感影像,结合黑龙江省松花江流域37 个国控断面点水质监测6 月、7 月的实时更新数据,进行时空匹配,作为模型输入数据。分别运用决策树、随机森林,建立水质等级反演模型,主要结论如下:
①本文以黑龙江省6 月份、7 月份、8 月份松花江流域国控断面实时更新的水质等级数据作为研究对象,通过评估模型的泛化能力发现,随机森林受样本不均衡的影响较小,具有较好的泛化能力。
②通过机器学习的方式进行水质等级预测中,在小样本数据集下,相比决策树支持向量机,随机森林反演模型的性能最佳,平均准确率为66.88%,准确率高达71.875%,Kappa 系数约为0.59,反演结果与官方信息基本一致。
③结果表明光谱信息与水质等级之间具有相关性,通过GEE 结合随机森林模型能够较好地模拟黑龙江省松花江流域水质变化。机器学习方法可在小样本区域大尺度上,使用GEE 平台和机器学习模型结合可有效用于水质等级反演,利用实时更新水质数据对水质变化进行预测,可在长时序动态监测内陆水体上提供技术支撑。
猜你喜欢
中等数学(2022年5期)2022-08-29 06:07:38
江苏农业科学(2021年19期)2021-11-18 17:43:06
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
经济研究导刊(2019年19期)2019-08-24 05:58:03
电子制作(2018年16期)2018-09-26 03:27:06
南水北调与水利科技(2018年6期)2018-02-01 15:15:10
石油地球物理勘探(2017年4期)2017-12-18 07:14:55
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
安徽农业科学(2016年4期)2016-10-21 16:47:53
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
