
基于RetinaNet-AACIDD的铝合金铸件X-ray图像缺陷检测方法*
2024-01-03 01:31孙心海武晓轩
组合机床与自动化加工技术 2023年12期
丛 明,孙心海,武晓轩
(大连理工大学机械工程学院,大连 116024)
0 引言
随着轻量化技术的发展,铝合金压铸件已广泛应用于汽车、航空航天等领域。在压铸过程中,铸件产生气泡、缩孔、裂纹等缺陷是不可避免的。对于此类铝合金铸件内部的缺陷,通常通过射线成像进行无损检测[1]。传统的检测算法以手工设计特征为主,对于复杂的工业场景,这种方法的泛化能力较弱不具有普适性[2]。
在铝合金铸件X-ray图像缺陷检测的最新研究中,FERGUSON等[3]基于Mask R-CNN是一种可同时检测和分割X射线图像中缺陷的铸件缺陷检测系统[4],通过使用迁移学习来减少训练所需的数据集规模并获得更高的检测精度。DU等[5]通过在Faster R-CNN的基础上引入特征金字塔(feature pyramid networks,FPN)网络[6],提高了模型对X射线图像中小尺度缺陷的检测精度。但是缺陷简单识别单一。REN等[7]提出了一种三阶段深度学习算法,该算法可以准确识别汽车发动机X射线图像中的气泡缺陷,准确率可达到90%以上。TANG等[8]提出了一种将空间注意力机制和双线性池结合的卷积神经网络,提高了网络对细微缺陷的学习能力。然而,对铝合金铸件X射线图像的缺陷检测工作仍存在缺陷检测种类单一、对多尺度缺陷检测性能较差以及各类缺陷样本分布不均匀等问题。
针对上述问题,本文制作了含有14 640张铝合金铸件内部X射线图像缺陷数据集ALU-Xray,提出了一种基于深度学习的缺陷检测算法,采用横向连接的方式将浅层特征与上采样后的深层语义信息自上而下依次融合,实现了模型对气泡、裂纹等尺度较小的缺陷和复杂背景下的疏松、缩孔等缺陷的高精度检测。
1 缺陷检测算法模型
1.1 RetinaNet-AACIDD算法结构
铝合金铸件X射线图像缺陷检测算法RetinaNet-AACIDD主要是基于RetinaNet算法[9]进行改进,如图1所示。算法的主干网络采用ResNet-50[10],使用深层次的网络可以获取缺陷图像更深层的语义特征,并且ResNet网络使用的残差块结构可以克服学习效率和准确率随网络深度加深而无法有效提高的问题,相对于传统的VGG等分类网络可以获得更高准确度。为了减少X射线图像噪声以及复杂背景的干扰,在Conv3_x、Conv4_x、Conv5_x后加入将通道注意力机制和空间注意力机制混合的注意力模块CS-Block,通过对特征图中不同通道和空间上的特征信息进行进一步筛选,来抑制无关信息,进而增加缺陷所在区域和有效的特征信息在特征图中所占权重,降低背景、噪声等其他信息对缺陷检测的干扰。为了更充分地利用提取出的特征,进一步提高模型对多尺度缺陷,尤其是小尺度缺陷的检测精度,在CS-Block模块后加入使用特征金字塔网络结构的多尺度特征融合模块(multid-scale feature integration module,MFIM),采用横向连接的方式将浅层特征与上采样后的深层语义信息自上而下依次融合,构建出兼具各级语义信息和缺陷位置信息的多尺度融合特征图。再通过Conv3×3的卷积层对生成的特征图再次进行特征提取,以消除上采样过程可能带来的混叠效应。之后再将多尺度融合后的特征图输入到分类和回归模块。

图1 RetinaNet-AACIDD算法结构图
在分类和回归阶段,在P3、P4、P5预测特征层(prediction layer)上分别得到经过Conv3×3的卷积层再次卷积融合后的Mp3、Mp4、Mp5三个多尺度特征图。其中,Mp3对应图像的浅层纹理特征,Mp4对应中间层的过渡特征,Mp5对应图像较深层的语义特征。在Mp5的基础上,依次通过Conv3×3,stride=2的卷积层得到Mp6、Mp7,对应图像的深层语义特征。最后,在P3、P4、P5、P6、P7等5个预测特征层上进行缺陷的检测。
RetinaNet-AACIDD缺陷检测算法的预测器由分类子网络(class subnet)和定位子网络(box subnet)两部分组成。其中class subnet负责预测目标类别,box subnet负责预测目标边界框回归参数。两个子网络均由4个Conv3×3,stride=1,channel=256的卷积层和一个Conv3×3,stride=1,channel=36的卷积层组成。
1.2 注意力机制CS-Block
铝合金铸件X射线图像中存在大量噪声,而且缺陷所在的背景复杂,会影响网络对缺陷的检测。为了减少图像中噪声和复杂背景的干扰,在RetinaNet-AACIDD主干网络的Conv1和Conv5_x后加入混合注意力机制,即卷积注意力模块(CBAM),以增加缺陷相关特征在特征图中的权重,从而降低背景等信息对缺陷检测的干扰。CBAM模块由通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)组成,相比于只关注通道的注意力机制SENet(squeeze and excitation networks)可以取得更好的检测效果,其模型结构如图2所示。

(a) CS-Block-A
Conv1和Conv5_x输出的结果作为CBAM的输入特征图,首先经过CAM模块:在空间维度进行基于宽度和高度的平均池化和最大池化来压缩空间尺寸,然后将池化后的结果分别输入多层感知机MLP中来学习通道维度的特征,再将MLP输出的特征进行add操作,接着经过Sigmoid函数进行激活,得到最终的通道注意力特征图;然后作为SAM模块的输入特征图,在通道维度进行平均池化和最大池化来对通道进行压缩,然后将提取的两个单通道图合并得到一个channel=2的特征图,接着通过Conv7×7的卷积层进行卷积操作,再经过Sigmoid函数激活,最后加权得到调整后的特征。
1.3 多尺度特征融合MFIM模块
经过注意力机制CS-Block模块共生成Ocs3、Ocs4、Ocs5三个特征图,其中Ocs5是低分辨率、具有较大的感受野和深层语义+特征的深层特征,用于检测尺度较大的缺陷;Ocs3是高分辨率、具有浅层纹理而缺少深层语义信息的浅层特征,用于检测小尺度的缺陷;Ocs4介于二者之间,是具有图像过渡特征的中间层。为了更充分地利用提取出的特征,提高模型对多尺度缺陷,尤其是小尺度缺陷的检测性能,在CS-Block模块后加入多尺度特征融合模块,该模块使用特征金字塔网络结构。首先Ocs3、Ocs4、Ocs5三个特征图分别通过Conv1×1,通道为256的卷积层,在不改变特征图原有宽高两个维度的情况下,将所有输出特征图的通道数进行降维,都统一变为256。再采用横向连接,即将浅层纹理位置等特征与上采样后的深层语义信息自上而下地依次融合,完成深层语义信息的向下传递。进而在Ocs3、Ocs4上构建出兼具各级语义信息和缺陷位置信息的多尺度融合特征图,如图3所示。

图3 多尺度特征融合模块结构图
由于上采样后的深层特征图在与横向连接的浅层特征图叠加过程中可能导致特征不连续,使得融合后的特征图失真,所以需要使用3×3的卷积核对生成的多尺度特征融合特征图再次进行卷积融合,即对特征进行再次提取,保证特征的稳定性,以消除上采样过程可能带来的混叠效应。之后再将多尺度融合后的特征图输入到分类和回归模块,在P3、P4、P5、P6、P7等5个预测特征层上进行分类和回归。最终提高模型对多尺度缺陷,尤其是小尺度缺陷的检测性能。
1.4 预测特征层上的锚框尺寸设计
在RetinaNet-AACIDD网络中,P3、P4、P5、P6、P7等5个预测特征层用于缺陷检测。每个位置都采用由3个尺度和3个比例组成的共9组锚点进行预测。在预测时,每个锚点根据目标缺陷的Ground Truth与其交并比(intersection over union,IoU)的大小来衡量缺陷检测的准确度。为了获得适合X射线图像数据集的锚点尺寸,提高模型对ALU-Xray数据集中不同尺度缺陷检测的准确率,对ALU-Xray数据集中所有缺陷的Ground Truth边界通过K-means聚类算法进行了统计分析,得到气泡、裂纹、缩孔、疏松等4类缺陷的聚类中心分别为[13,13]、[17,15]、[32,55]、[68,21],结合其尺寸分布散点图(如图4所示),设计如表1所示的锚点的尺度和比例,以获得锚点与缺陷的Ground Truth间最大的IoU。

表1 预测特征层锚点尺度及比例

图4 ALU-Xray数据集缺陷尺寸分布散点图
1.5 迁移学习
RetinaNet-AACIDD检测算法采用ResNet-50作为主干网络,其Conv1_x、Conv2_x、Conv3_x等卷积层主要用来提取图像的纹理信息、边缘信息等浅层特征,对不同的检测目标具有一定的通用性。而深层网络Conv5_x是用来提取图像更深层的语义信息的,这种深层特征的提取通常针对的是具体的数据集。为此,在模型训练时利用ResNet-50网络在ImageNet大型数据集上训练好的权重来进行模型初始化。在训练过程中将浅层网络的权重固定保持不变,对深层的网络权重进行微调,即使用迁移学习的方式进行模型训练,如图5所示。
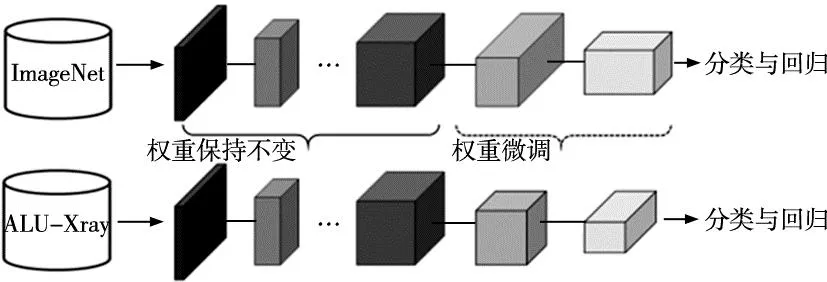
图5 迁移学习原理框图
由于是使用在ImageNet数据集上训练好的模型预训练权重基础上训练,大大缩短了模型的训练时间,提高了计算资源的利用率。同时,通过迁移学习利用不同任务间浅层特征的共性,可以提高模型对浅层一般特征的提取能力,在样本数量有限的情况下提高模型的分类精度。
2 数据集制作及模型评价指标
2.1 数据集制作
数据集中铝合金铸件内部缺陷图像来源于一家汽车零部件工厂,包括汽车散热板、链条罩盖、油底壳、曲轴箱体、离合器壳体、变速器壳体等零部件的X射线缺陷图像。制作数据集时,采用LabelImg软件进行图像中缺陷的标注和类标签的生成,并将每个图像中的缺陷类别、位置等信息以Pascal VOC格式保存在对应的XML文件中。原始缺陷图像分辨率为1140×1192像素,调整为512×512像素,即本文所制作的铝合金铸件X射线图像缺陷数据集ALU-Xray的图像分辨率大小。最终制作成的ALU-Xray数据集中具体包括的缺陷有气孔、缩孔、疏松、裂纹等,共计14 640张,数据集中部分缺陷图像展示如图6所示。

(a) 气泡 (b) 缩孔
随机划分数据集为训练集、验证集、测试集3个部分,所占比例为8:1:1,数据集各缺陷的数量等信息如表2所示。

表2 ALU-Xray数据集信息
2.2 模型评价指标
精确率(precision,P)和召回率(recall,R)是目标检测任务中模型性能常用的评价的指标,计算公式为:
(1)
(2)
式中:TP(true positive)指被正确划分为正样本的个数,FP(false positive)指被错误划分为正样本的个数,FN(false negative)指被错误划分为负样本的个数。
因此,精确率也被称为查准率,侧重考察在预测结果中为正样本的准确程度,召回率也可被称为查全率,侧重考察真实的正样本被正确预测的全面程度。将模型对每一类样本检测结果的Precision作为横坐标,Recall作为纵坐标所得到的图像称为P-R曲线,P-R曲线与横纵坐标轴所围成的面积就是这类样本的平均精度(average precision,AP)值,计算公式如下:

(3)
但是AP只是针对一个缺陷类别计算所得的评价指标,为了在与Faster R-CNN、YOLOv5、YOLOv3以及RetinaNet基准模型等网络进行对比时更好的评估RetinaNet-AACIDD网络模型对多个缺陷类别检测的性能,本文选择的模型评价指标为目标检测任务中最常用的评估指标mAP,即所有类别AP的平均值,计算公式为:
(4)
式中:n表示数据集中类别的个数。
在目标检测任务中还有一个与召回率相对的常用评价指标,反映的是模型没有正确预测出的正样本占所有正样本的比例,即漏检率(miss rate,MR),计算公式为:
(5)
此外,对于目标检测任务,模型的性能好坏还有一个重要评测标准就是检测速度。本文采用帧率(frame rate)作为模型检测速度的度量标准,测量单位为每秒钟模型所能检测的图像的数量(frame per second,FPS),计算公式为:
(6)
式中:ImageNum表示检测图像的总数量,Time表示检测所用的总时间。
3 实验
3.1 铝合金铸件X射线数字平板成像检测系统
本文采用的铝合金铸件X射线数字平板成像检测系统由高频X射线机、控制台、工业级数字平板探测器、计算机图像处理系统、机械传动控制系统、铅房防护系统等组成。检测内容包括气泡、疏松、缩孔、裂纹等,检测节拍为1.2~15帧,可分辨的最小深孔为0.3~0.4 mm,X射线机在实时成像时对铝合金的透照能力可以达到80 mm。检测时工件置于X射线源和工业级数字平板探测器中间的工作平台上,如图7所示。
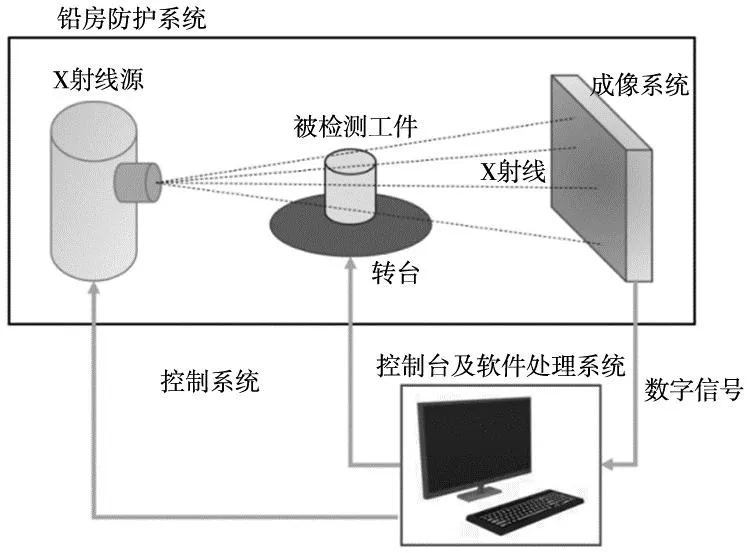
图7 铝合金铸件X射线数字平板成像检测系统
3.2 缺陷检测算法的软件和硬件环境
本实验的深度学算法在Ubuntu16.04的操作系统下进行训练,GPU选用NVIDIA GeForce RTX 3090,软件环境采用CUDA11.1和cuDNN8.0,处理器使用Intel Core i9-10900X,如表3所示,所提出的缺陷检测算法模型基于PyTorch深度学习框架实现[11]。
3.3 模型设置
根据本文铝合金铸件X-ray缺陷图像数据集的特点,对网络的相关模型参数进行了相应设置,以达到模型最佳的检测性能。RetinaNet-AACIDD缺陷检测算法在训练过程中,为了减少模型中的参数,将输入图片大小调整为512×512。采用BN(batch normalization)对数据进行批量初始化,来提高模型的收敛数速度。并综合考虑GPU内存利用率和参数调整速度,将模型的批处理大小(batch size)设置为4。在训练中,采用随机梯度下降法(stochastic gradient descent,SGD)优化网络参数,最大迭代次数(epoch)设为15。为防止模型过拟合,对模型的初始学习率(learning rate)、动量(momentum)、权重衰减系数(weight decay)等非网络训练所得的超参数取值进行了多次实验,并对以上超参数设置如下:学习率设置为0.005,动量设置为0.9,权重衰减系数设置为0.000 5。
3.4 锚框改进前后对比实验结果
在模型改进的过程中,为了更好的验证针对ALU-Xray数据集,使用改进的K-means聚类算法重新设计的锚框对基准模型RetinaNet网络性能提升的效果,在锚框改进前后设计了算法对气泡、疏松、缩孔、裂纹等不同尺度缺陷的检测性能对比实验,以及算法整体检测性能的对比。以每类缺陷的检测平均精度和所有类别的均值平均精度作为模型性能评价指标,对比结果如表4、图8和图9所示。

表4 锚框改进前后对比实验结果(mAP)
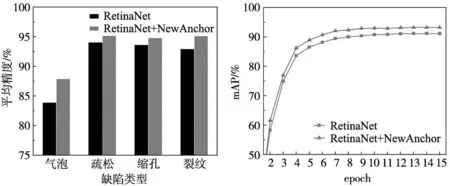
图8 锚框改进前后平均精度对比图 图9 锚框改进前后mAP对比图
可以看出锚框通过使用改进的K-means聚类算法重新设后,对不同尺度的缺陷平均检测精度都有明显的提升,均值平均精度由原来的91.15%提升到93.28%,提升了2.13%。其中,锚点的改进对小尺度缺陷检测性能提升更明显,如尺度最小的气泡类缺陷,平均检测精度提升了4%,对于数据集中小尺度缺陷较多的裂纹类缺陷提升幅度也相对较大,提升了2.3%。此外,对于疏松、缩孔类尺度相对较大的缺陷,其平均检测精度也有所提升。可见,对特定的数据集如ALU-Xray,使用改进的K-means聚类算法重新设计与数据集中待检测目标大小相近的锚框,对检测算法的检测精度提升是有效的。对于待检测目标尺度差距较大的数据集,这种改进的对模型检测精度的提升效果更显著。
3.5 混合注意力模块CS-Block对比实验分析
在模型锚框改进的基础上,为了验证混合注意力模块CS-Block,对于提高模型在图像噪声和复杂背景环境下对缺陷检测性能提升的效果,在RetinaNet+NewAnchor的基础上,设计了加入混合注意模块CS-Block和未加入CS-Block进行训练的两组模型的对比实验。在保证模型所有训练参数相同的前提下,以两组模型分别对各类型缺陷检测的平均精度和所有类别的均值平均精度作为指标进行了对比,如表5所示。其中各类型缺陷检测的平均精度和所有类别的均值平均精度对比如图10和图11所示,噪声和复杂背景下两个模型检测效果的对比如图12所示。
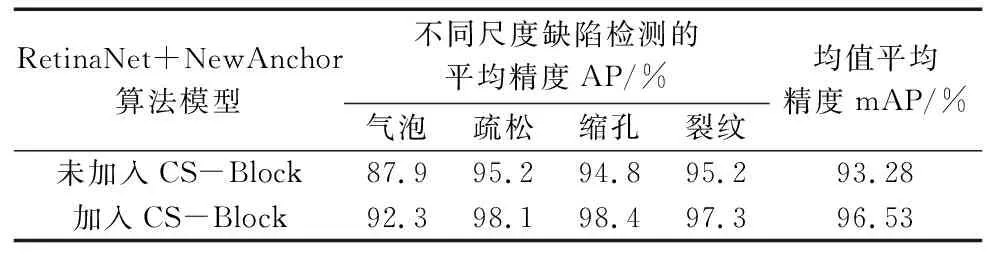
表5 混合注意力模块CS-Block加入前后模型性能对比(mAP)

图10 混合注意力模块CS-Block加入前后各类型缺陷的AP对比图 图11 混合注意力模块CS-Block加入前后mAP对比图
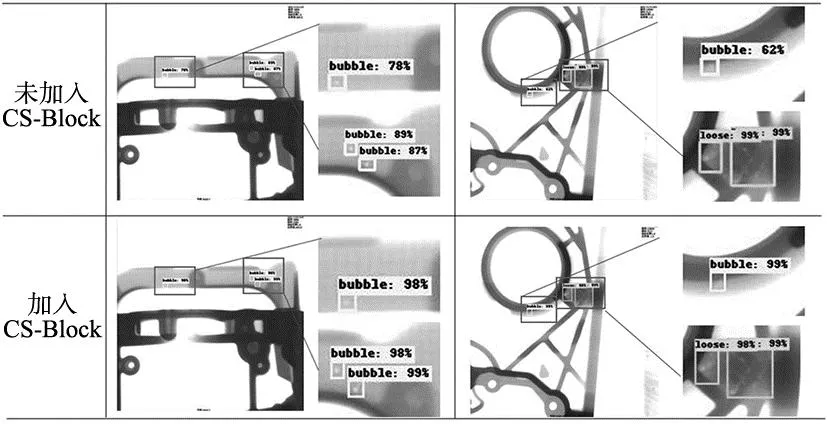
图12 噪声和复杂背景下模型检测效果对比图
通过未加入CS-Block和加入CS-Block训练的算法模型的实验结果对比可以看出,对于噪声和背景复杂的铝合金铸件X射线图像,在模型中加入将通道注意力和空间注意力机制混合的注意力模块CS-Block对检测算法性能的性能有显著地提升效果,均值平均精度从93.28%提升到96.53%,模型整体检测精度提升了3.25%。其中,对气泡类缺陷的检测精度提升效果明显,从87.9%提升到了92.3%,提升了4.4%。对疏松、缩孔、裂纹类缺陷也分别提升了2.9%、3.6%、2.1%。
在设计混合注意力模块CS-Block的过程中,为了验证由通道注意力模块C-Block和空间注意力模块S-Block组成的CS-Block模块,相比于只关注特征通道的通道注意力机制SENet、ECANet对模型性能提升的效果,以RetinaNet+NewAnchor作为基准模型,设计了分别加入混合注意力模块CS-Block、SENet、ECANet的3组模型进行对比实验,以所有类别缺陷的均值平均精度作为评价指标,在保证所有训练参数相同的情况下,实验结果如表6所示。

表6 加入不同注意力模块的模型检测性能对比
可以看出不同注意力模块对模型在铝合金铸件X射线图像中缺陷检测的精度都有一定的提升效果,但是相对于只关注特征图通道间信息的通道注意力机制SENet、ECANet等模型,CS-Block对模型的提升效果更明显,模型整体检测精度提升了3.25%。这是因为CS-Block在通道注意力后加入的空间注意力机制可以使模型对缺陷的空间位置信息的特征进行更好提取,可以进一步提高对处于复杂结构背景中缺陷特征的提取能力。
3.6 与经典模型和基准模型的对比实验
为了验证网络模型的检测性能,将RetinaNet-AACIDD网络模型与常用的目标检测算法进行了对比实验,包括近年提出的模型精度、速度相对工业中使用广泛的YOLOv3目标检测算法都有所改进的一阶段检测算法YOLOv5,以及经典的二阶段检测算法Faster R-CNN。同时,也加入了与基线模型RetinaNet的对比实验。以更好的对比RetinaNet-AACIDD模型改进后检测性能提升的效果。
在实验过程中,分别改变各个检测算法的模型参数进行了多组实验,最终分别取各组效果最好的一组参数训练出的模型进行检测性能的对比。模型性能对比指标包括对各类型缺陷检测的平均精度、漏检率,所有类别的均值平均精度和检测速度,实验结果如表7、表8所示。各检测算法的检测效果对比如图13所示。

表7 各个检测算法性能对比(mAP)
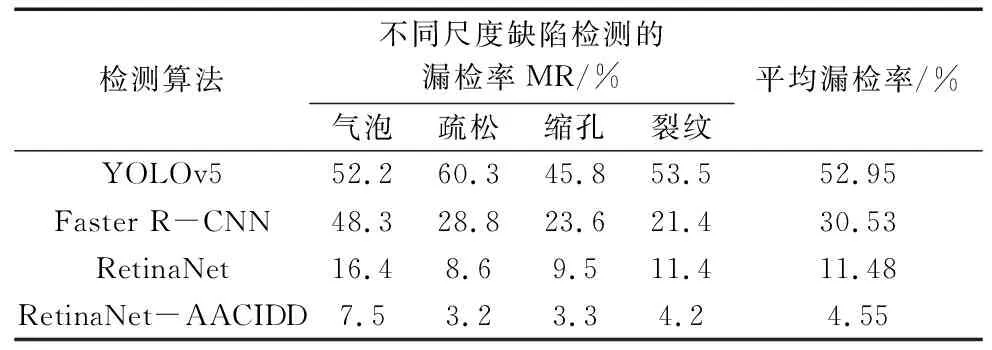
表8 各个检测算法性能对比(MR)

图13 各检测算法的检测效果对比图
通过各个检测算法的性能对比不难看出RetinaNet-AACIDD在保证了检测速度的前提下,实现了对各个类型缺陷更高的检测精度。模型整体检测性能mAP为96.53%,相对于YOLOv5、Faster R-CNN分别高出30.4%、15.8%,并具有更低的漏检率,平均漏检率为4.55%,相对YOLOv5、Faster R-CNN分别低了48.4%、25.98%。尤其是在小尺度缺陷的检测性能上RetinaNet-AACIDD的检测性能的表现更优异,如对于气泡类缺陷RetinaNet-AACIDD检测的平均精度相对于YOLOv5、Faster R-CNN分别高出31.1%、28.4%,漏检率则低了44.7%、40.8%。此外,RetinaNet-AACIDD对基准模型RetinaNet的检测性能提升效果也很显著,模型总体检测精度mAP提升了5.38%,漏检率则降低了6.93%。对气泡、裂纹、疏松、缩孔4类缺陷的检测精度分别提升了8.4%、3.9%、4.8%、4.4%。漏检率则分别降低了8.9%、5.4%、6.2%、7.2%。
这是因为RetinaNet-AACIDD的特征提取网络采用了更深的ResNet-50残差网络,更有利于对缺陷深层特征的提取,并且加入的CB-Block模块,通过对特征图的通道特征和空间特征进行进一步的特征提取,可以更好地抑制噪声、复杂背景对不同种类缺陷检测的干扰,在CS-Block注意力模块后加入的多尺度特征整合模块,则可以通过将浅层纹理位置等特征与深层语义信息进行融合,完成深层语义信息的向下传递,结合多尺度特征预测,最终使得模型对气泡、裂纹等尺度较小的缺陷以及复杂背景下缺陷的检测精度显著提升。RetinaNet-AACIDD检测算法对各类缺陷的检测效果展示如图14所示。

(a) 气泡 (b) 缩孔
4 结论
本文制作了一个大型的铝合金铸件内部X射线图像缺陷数据集ALU-Xray,并根据缺陷的类型分别进行了标注,包括气泡类4672张、缩孔类3056张、疏松类4832张、裂纹类2080张,共计14 640张。同时,提出一种基于深度学习的面向铝合金铸件X射线图像的缺陷检测算法RetinaNet-AACIDD。该算法基于RetinaNet算法进行改进,通过加入由通道注意力模块C-Block和空间注意力模块S-Block组成的混合注意力模块CS-Block,将计算出的通道注意力权重和空间注意力权重对特征图的特征信息进行进一步整合,有效降低了噪声、背景等无关信息对RetinaNet-AACIDD算法检测精度的影响,并通过在CS-Block注意力模块后加入多尺度特征整合模块,采用横向连接的方式将浅层特征与上采样后的深层语义信息自上而下依次融合,完成了深层语义信息的向下传递,结合多尺度特征预测,最终使得模型对气泡、裂纹等尺度较小的缺陷以及复杂背景下缺陷的检测精度显著提升。并通过对比实验,证明了RetinaNet-AACIDD算法有着优异的检测性能,在IoU=0.5时其mAP为96.53%,相对于YOLOv5、Faster R-CNN、RetinaNet分别高出30.4%、15.8%、5.38%,并具有更低的漏检率,平均漏检率为4.55%,相对YOLOv5、Faster R-CNN分别低了48.4%、25.98%、6.93%。同时,在本文的实验环境下RetinaNet-AACIDD检测算法的检测速度为13 fps,可以有效实现工业生产环境中的铝合金铸件内部缺陷实时检测。
猜你喜欢
中学生数理化·八年级物理人教版(2023年10期)2023-11-30
机电安全(2022年5期)2022-12-13
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
科学(2020年1期)2020-01-06
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电子设计工程(2014年8期)2014-02-27
