
动态场景下基于视觉传感器的SLAM研究*
2024-01-03 01:31杜晓英袁庆霓齐建友
组合机床与自动化加工技术 2023年12期
杜晓英,袁庆霓,b,c,齐建友,王 晨
(贵州大学 a.现代制造技术教育部重点实验室;b.机械工程学院;c.省部共建公共大数据国家重点实验室,贵阳 550025)
0 引言
同步定位与建图(simultaneous localization and mapping,SLAM)[1]能够在未知环境下完成地图的自主构建与定位,是工业机器人、自主导航、无人驾驶等应用中的基础技术之一。近年来以相机作为传感器的视觉SLAM逐渐成为SLAM领域的主要研究方向之一。如ORB-SLAM2[2]、LSD-SLAM(large-scale direct monocular SLAM)[3]、稀疏直接法里程计(direct sparse odometry,DSO)[4]等视觉SLAM算法。
如何解决视觉SLAM在动态场景下鲁棒性差、定位与建图精度受到动态物体干扰成为当前研究热点,张慧娟等[5]通过特征点匹配的结果计算两帧之间的变换矩阵,之后利用该矩阵提取线特征,并对其进行静态权重的评估,最后通过余下的静态特征进行相机位姿估计,完成跟踪任务。杨世强等[6]对传统SLAM系统进行改进,提出一种基于几何约束的动态目标检测算法。DAI等[7]采用Delaunay三角剖分方法为地图点建立与图类似的结构,以此判断其邻接关系。之后,将多个关键帧之间观测不一样的边缘移除,最终,完成动态物和静态背景的分离。但以上几种SLAM算法构建的地图只包含简单的几何信息,且构建的稀疏地图不能直接用于机器人后续的导航工作。YU等[8]提出DS-SLAM算法,利用语义分割网络SegNet和运动一致性检测方法剔除动态特征点,并创建语义地图。ZHONG等[9]采用目标检测方法SSD[10]检测帧中的动态物体,利用特征匹配和扩展影响区域的方式对动态特征点进行运动概率传播,在跟踪线程中剔除动态点。唐鼎新等[11]同样使用PSPNet检验先验运动物体,剔除动态物体,并创建了语义地图。语义分割和目标检测网络虽然可以检测动态物体,为SLAM提供语义信息,但如何选择一个精度高且计算量较小的语义分割网络与SLAM结合是也是需要考虑的重要问题。针对以上问题,本文结合语义分割网络和多视图几何方法,提出一种面向动态场景的视觉SLAM方法,分割出具体的动态对象和静态对象,去除动态目标,然后将剩余的静态特征用于位姿估计,提高定位精度,并生成包含语义信息的八叉树地图。最后与现有算法进行了对比实验分析,表明了该算法的有效性。
1 算法框架
本文以ORB-SLAM2为基础框架,提出基于语义分割和几何的视觉SLAM算法,在视觉ORB-SLAM2的RGB-D相机模式中,结合语义分割,在原有的前端里程计、局部建图、回环检测3个线程基础之上,添加了语义分割模块和构建语义八叉树地图的线程。总体框架如图1所示,首先,RGB-D相机获取的RGB图像传入跟踪线程,在跟踪线程中,采用GCNv2网络提取当前帧的关键点和描述子。之后通过语义分割网络对RGB图像进行像素级的语义分割,分割出具体的对象,包括动态目标对象和静态目标对象,并对动态特征点进行初步的剔除,如行走的人等。并结合多视图几何方法检测[12]、进一步去除动态物体,将剩余的静态特征用于位姿估计。最后,在语义地图构建线程中利用语义分割提取的语义信息生成点云地图并转换为八叉树地图。

图1 视觉SLAM算法总体框架
1.1 特征提取
GCNV2是一种为三维投影几何训练的网络,能够用来提取特征点和描述子。它受SuperPoint的启发只对单个帧进行检测,并通过删除部分不必要的参数,采用更低的尺度等操作简化网络结构。与一般采用单张图像进行训练的方式不同,GCNv2在TUM和SUN-3D数据集上使用图像对进行训练,之后将图像对之间的相对位姿(相对位姿是通过数据集中ground-truth获得的)参与到损失函数的设计中去,可以让其提取的特征点更加适用于位姿匹配,提高系统在动态环境下的精度和稳定性。GCNv2接收输入进的单通道图像,将其调整为320×240尺寸,网络接收调整之后的图像,对其进行特征提取,并对特征进行均匀化与非极大值抑制处理,最终获得分布均匀的特征点及其对应的描述子。图2为采用GCNv2方法进行的特征提取结过程。从图中我们可以很明显的看到中提取的特征均匀的分布在整张图像中。

图2 GCNv2网络结构
1.2 语义分割网络
为了对图像中的像素进行像素级的语义信息提取,进而确定先验的运动目标,本文采用分割网络Deeplabv3+[13]完成图像帧的语义分割任务。近年来许多学者不断提出新的语义分割网络,如PSPNet像素准确率为0.929 3,BiSeNet像素准确率为0.933 7。DeepLabV3+在DeepLabv3的框架上增加了一个解码器模块,并在其中基于空洞卷积的空间金字塔池化层(ASPP)模块中融合了多尺度信息,在解码器架构中通过空间信息恢复来获得更加准确的对象边界,优化分割结果,其像素准确率达到0.943 1,因此本文选择DeepLabv3+。图3显示了语义分割算法的过程,其中,粉色像素表示人,蓝色像素表示显示屏。图像输入到网络之后,经过DCNN特征提取之后得到两个输出值:包含高级语义信息的特征图map1和含有低级特征(low_level_features)的特征图map2。map1先通过ASPP模块,然后利用1×1卷积调整通道数得到map1′。map2利用1×1卷积调整通道数得到map2′,将map1′进行4次上采样操作之后与map2′堆叠(concat),最后利用3×3卷积进行通道调整之后,四倍上采样得到最终分割结果。

图3 DeepLabv3+语义分割
1.3 多视图几何方法
利用语义分割网络只能检验如人这样的先验的运动目标对象,忽略了椅子,书本等静态物体发生被动运动时对SLAM的影响,如人们手中的书本或者人为推动的椅子等目标,应该被视为动态目标对象,却被视为静态对象,这将会对SLAM产生较大影响。因此本文同时采用多视图几何的动态特征点检测方法:将地图点云投影到当前帧,并利用视点差异和深度值变化大小将目标对象区分为动态目标和静态目标对象。多视图几何的原理如图4所示,对于每个输入帧,选择多个之前与输入图像帧重合度较高的帧,把关键帧KF中的关键点p投影到当前帧CF,得到投影点p′和投影深度Dproj,每个关键点对应的3D点是P,然后计算视差角α(p的反投影与p′之间形成的夹角α)。根据TUM数据集上的测试实验发现,当α>30°,可判断其为动态点。同时,我们还要计算深度值差ΔD=Dproj-D′,D′表示当前帧中关键点深度,若ΔD=0,该点被认为是静态的,若ΔD>0, 则该点被认为是动态的。

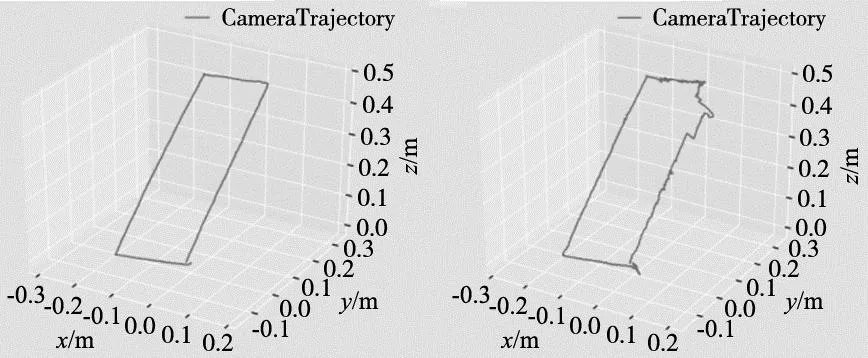
(a) 关键点p′属于一个 静态对象(D′=Dproj) (b) 关键点p′属于一个 动态对象(D′ 语义地图构建线程中,借助PCL库,结合关键帧和深度图生成点云,然后利用当前帧的位姿及其点云,进行点云的拼接和滤波处理,生成点云地图,并在点云地图中进行语义信息的标注。然而点云地图虽然给人很直观的感觉,但点云图存在占用大量存储空间、位置信息冗余以及不能直接用于导航等缺点。与此相比,八叉树地图[14]同样具有点云地图的直观性,但存储空间却远远小于点云地图,适用于各种导航。因此,本文对点云地图做进一步处理,将点云地图转换为八叉树地图,并结合语义信息构建语义八叉树地图。但在建图过程中,由于存在相机的噪声和因动态物体产生的误差,同一个节点在不同时间点会有不同状态。所以,我们选用概率的方式去说明某一节点被占据还是未被占据。但这种方法可能会出现概率大于1的现象,会干扰数据的处理,因此,之后采用概率对数值描述节点是否被占用,设y∈R(实数集)表示概率对数值,占用概率p的数值范围为[0,1],则logit变换公式为: (1) 式(1)可逆变换为: (2) 假设某节点n在T时刻的观测概率是P(n|Zt),Z表示观测数据,则其被占据的概率P(n|Z1:T)表示为: (3) 式中:P(n)代表节点n被占据的先验概率,P(n|Z1:T-1)代表n节点从起始到T-1时刻的估计概率。往往我们将先验概率P(n)设为0.5,那么上式转换为概率对形式为L(n|Z1:T),表示节点n从起始到时间T的概率对数值,则T+1时刻为: L(n|Z1:T+1)=L(n|Z1:T-1)+L(n|ZT) (4) 式中:L(n|Z1:T+1)与L(n|ZT)分别代表节点n在T时刻前和T时刻被占据的概率对数值。由式(4)可知,当某一节点被重复观测到被占据时,其概率对数值随之增加,否则减少。根据获得的这些信息,能动态调整此节点的占据概率,对八叉树地图不断进行更新。 本文将从TUM数据集中选取高动态场景walking序列共4组序列,来验证本文算法在动态场景下的鲁棒性和定位精度。以绝对轨迹误差(absolute trajectory error,ATE)和相对位姿误差(relative pose error,RPE)[15]为性能指标。为了便于区分,本文用fr3、w、half分别代表freiburg3、walking、halfsphere,作为序列的名称。将本文的算法分别与ORB-SLAM2、DS-SLAM以及文献[11]方法进行比较。 表1、表2显示了本文算与ORB-SLAM2、DS-SLAM以及文献[11]算法在绝对轨迹误差和相对位姿误差的方面的比较结果。从表中数据分析可得,与传统ORB-SLAM2相比,在高动态walking序列下,本文算法的绝对轨迹误差(ATE)的RMSE值和S.D.值分别提升了95%以上和94%以上,相对位姿误差的两个指标值提升了60%~80%之间。此外,本文所提算法的绝对轨迹误差和相对位姿误差的RMSE值和S.D.值也小于DS-SLAM、文献[11]的。实验结果证明,在动态环境下本文算法生成的轨迹误差值更小,定位更加准确。 表1 绝对轨迹误差对比结果 表2 相对位姿误差平移部分的对比结果 图5和图6分别显示了在高动态序列fr3/w/xyz下ORB-SLAM2及本文算法得到的相机运动轨迹与真实轨迹之间的偏差。其中,黑线代表真实轨迹,蓝线代表估计轨迹,红线代表相机运动轨迹与真实轨迹之间的偏差,红线越短代表偏差越小。从图5和6中我们可以看出,相较于其他算法,本文所提算法运动轨迹图中红线最短,位姿估计更加准确。同时,也表明了本文提出的算法在动态环境下可以有效的去除动态特征点,得到轨迹误差更小。 图5 fr3/w/xyz序列下ORB-SLAM2的轨迹 图6 fr3/w/xyz序列下本文系统的轨迹 本文将运动的人当做动态物体,通过移动机器人搭载KinectV2相机在动态环境中根据先前设计好的矩形路线匀速运动,感知周围环境,采集场景中的信息。随后,利用ROS工具将获得的真实场景数据拆成一帧帧图像,并以TUM数据集为标准,把获取的真实场景数据制作成TUM数据集的格式,测试本文算法和ORB-SLAM2算法,进而验证本文算法的有效性和可行性。图7a与图7b分别表示本文算法和ORB-SLAM2算法生成的三维运动轨迹,从图7可以明显看出,由于实验场景中有运动物体的存在,ORB-SLAM2算法生成的轨迹与实际运动轨迹相比出现了较大篇幅的波动,而本文算法生成的轨迹与实际运动轨迹基本相符,波动幅度较小。 (a) 本文算法 (b) ORB-SLAM2算法图7 运动轨迹对比 为验证本文算法在动态场景下的建图效果,选取TUM数据集中的walking序列的一个子序列为测试对象。图8是ORB-SLAM2在添加了点云线程后建立的地图,其中图8a是点云地图,图8b是八叉树地图。图9是本文算法建立的地图,其中图9a是包含语义信息的点云地图,图9b是包含语义信息的八叉树地图。为了可视化,本文使用紫色代表显示屏的像素,绿色代表椅子的像素,其余像素使用物体本身颜色。从图8可以明显看出,本文算法建立的语义地图中已剔除动态物体,不存在显著的动态物体如行走的人,表明了较好地完成地图构建。 (a) 点云地图 (b) 八叉树地图图8 ORB-SLAM2在添加了点云线程后建立的地图 本文利用GCNV2进行特征提取,与传统SLAM系统的特征提取方法相比,提取的特征点分布更加均匀,通过语义分割网络DeepLabv3+对VSLAM系统中的图像帧赋予语义信息,检测出对象中的运动目标,再结合几何信息检测动态特征点,增加了视觉SLAM系统在动态环境下的鲁棒性,最后利用语义信息生成静态的语义八叉树地图,节省大量的存储空间,同时生成的地图可直接用于机器人的路径规划中。但本文算法仍有不足之处,去除动态特征点时由于分割的不完成导致部分动态点未被识别,后面的工作中将会选择分割精度更高的网络。1.4 语义地图构建
2 实验结果与分析
2.1 定位误差实验



2.2 建图测试

3 结束语
猜你喜欢
枣庄学院学报(2022年5期)2022-09-21
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
组合机床与自动化加工技术(2014年12期)2014-03-01
机械设计与制造工程(2013年4期)2013-09-12
