
基于情感分析和机器学习的用户评论信息挖掘
2024-01-02 00:41:24张倩男
科技和产业 2023年23期
张倩男
(商丘工学院 基础教学部, 河南 商丘 476000)
伴随着互联网行业的飞速发展和广泛应用,网购消费者发表的评论数量呈几何指数增长。这些评论文本包含了用户对产品或者服务的认可和接受度,集中反映了消费者对商品各个方面的反馈,针对性强且具有强烈的褒贬倾向,能够为其他消费者获取产品体验信息以及平台服务提供可靠的信息来源。对于产品或者服务的提供商或者销售商来说,通过挖掘用户评论信息解读消费者想法,了解消费者对产品的喜好及购买欲望,把握产品的质量情况,能更好地与竞品进行对比分析,并作为后续产品与服务改进或者营销策略优化的重要参考依据。因此如何有效地利用用户评论进行情感分析和用户价值分析,具有重要的现实意义。
在用户评论情感分析研究中,汪梦欣等[1]以在线产品评论为数据来源,采用基于机器学习的情感分析技术训练学习产品各个属性评论的情感极性,并将产品属性作为评价指标,采用基于直觉模糊妥协解的方案选择与排序(mea-surement of alternatives and ranking according to compro-mise solution,MARCOS)的多属性决策方法进行顾客满意度评价研究。杨嘉怡等[2]采用 SnowNLP 对评论文本进行情感分析,通过线性判别分析 (linear discriminant analysis,LDA) 模型对正、负面评价进行主题分析,为手机厂商改进产品及服务质量提供参考建议。丁美荣[3]等基于双向长短期记忆网络(bi-directional long short-term memory,BiLSTM) 神经网络构建预训练模型对酒店领域的评论信息进行情感分析,同时与传统的机器学习算法进行比较,并以基础词典为主体,构建适用于酒店评论的扩展情感词典, 将基础词典与扩展词典对获取的同一语料进行情感分类,结果显示扩展词典分类比基础词典的分类效果更好。姚珂[4]采用基于词典和自定义规则的方法对在线评论进行分析,并利用K折交叉验证调整自定义规则的权重,提高了分类结果的准确性。
在情感词典构建中,刘若兰和杨建萍[5]在前期构建维吾尔语情感词典的基础上,基于 Word2Vec 开展了情感词的自动扩展研究。江华等[6]利用用户评分的评价方法来确定目标词的极性,计算出目标词的情感极性强度,从而构建出基于影评领域的情感词典,再引入用户的点赞数进一步优化。颜明阳等[7]提出一种领域特定情感词典生成方法的扩展方法,结果表明所提方法提取出的特征显著优于从通用情感词典(general purpose emotion lexicons,GPEL)提取出的特征,与逐点互信息、n元语法等方法相比,所提方法的性能更优。贾东立等[8]结合现有的自然语言处理技术,提取高频词汇扩充情感词典,提升了商品评价系统的准确率。杨小平等[9]利用Word2vec工具筛选了知网情感词典、大连理工大学情感词典等通用词典,并构建了SentiRuc词典,在通用领域数据集上取得了不错的实验结果。
在对聚类和分类预测方法研究中,王盈等[10]通过挖掘商品评论信息中的商品特征及相应的情感反馈,建立商品特征细粒度上的情感分值向量,在此基础上利用自组织映射(self-organizing map,SOM)神经网络模型对评价用户进行聚类,建立电商用户情感画像,并针对不同电商用户群体特征制定个性化营销策略,从而帮助平台商家从繁杂的商品评论中快速获取有效信息。蒋铁铮等[11]提出基于K-means聚类和模糊神经网络的母线负荷态势感知方法。吴广建等[12]提出利用手肘法关系图初始点和末尾点连接的关系直线,求k值范围下直线y值与误差平方和的最大差值的方法,根据此方法自动获取K-means最优k值,而且提高了大数据集的处理效率。洪庆等[13]针对弹幕文本口语化的特点,建立了网络弹幕常用词词典,通过改进传统的K-means聚类算法,对所有发表弹幕的用户进行基于情感值的分类。王伟和千博[14]提出了一种根据模糊聚类对用户情感进行分析的方法。
在本文中以Vivo手机用户评论数据为研究对象,首先利用Excel、Python结合多部词典构建基础积极、消极情感词典,加入针对手机评论领域的情感词,构建成完备的手机领域情感词典,并基于情感分析算法设计训练词典,基于判断规则对用户评论进行情感倾向性分析。然后基于情感词典得到积极情感均值、消极情感均值、积极情感方差、消极情感方差,同时结合用户评分星级特征,并对其进行独热编码处理,采用K-means算法对用户进行聚类分析,利用手肘法确定最优k值,并对各类用户采用TextRank算法分析,挖掘提取用户群体的兴趣特征。最后将聚类分析的用户类别作为因变量,利用支持向量机(support vector machines,SVM)、决策树、随机森林、K近邻算法(Knearest neighbors,KNN)4种机器学习方法建立用户分类预测模型,并对模型效果进行评价,以便于商家预知用户价值类别,针对不同用户类型进行不同的营销和服务工作。
1 基于情感词典的用户评论情感分析
1.1 情感词典的构建
将从京东商城采集到的Vivo手机用户的评论数据,通过初步清洗、文本去重、机械压缩去重等数据清洗步骤完成数据的规整,以提高后续情感分析的精确性。
基于词典的情感分析赋予情感词库中每个词相应的情感倾向度权值,然后从文本中提取情感词并计算情感得分,根据情感得分判断文本的情感极性。构造的词典如下。
1)积极、消极情感词典。首先将HowNet情感词典、中文情感极性词典(NTUSD)、数据堂的正面与负面情绪词整合,去除重复和无用单词,构成基础积极情感词典和消极情感词典;然后将苏州大学人类语言研究构建的电子商务情感词典(E-commerce sentiment dict,ECSD)(包括通用的情感词条和电商领域特有的情感词条)加载到基础积极情感词典和消极情感词典中;最后利用基于Python语言的词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)算法从评论中抽取情感词汇加入词典,再次进行筛选、去重处理。最终积极情感词典包含5 841个词语,消极情感词典包含6 184个词语,构成完整的积极、消极情感词典。
2)程度副词词典。程度副词对情感词的修饰会使得情感词的情感倾向程度发生变化,比没有修饰之前更加强烈。为了准确表达文本的情感倾向,将HowNet情感词典中的6个等级的中文程度级别词语重新赋以相应的权重,以区分其表达的语气情感强弱程度。程度副词及权重见表1。
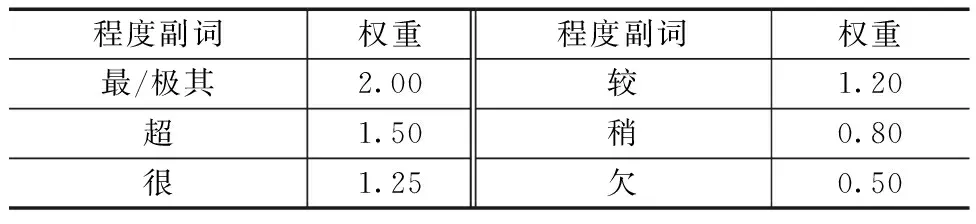
表1 程度副词及权重
3)否定词词典。在手机评论文本情感分析中,若在情感词汇之前出现否定词,将会对情感词表达起到情感反置作用,故将否定词词典中的词汇权重设置为-1。采用常用的否定词,并根据用户评论文本进行扩充,最终否定词词典包含“不”“不能”“木有”“拒绝”等72个否定词。
4)关联、转折、归总词典。从句子情感而言,关联词、转折词或总结词在中文语句中的出现频率比较高,存在这些词汇的评论语句情感更加重要,所表达的情感也更为强烈,忽略这些词汇可能会使得情感极性出现误差,故将该词典的词汇权重赋值为1.2。采用常用的关联词、转折词汇和归总词汇,包含“可是”“却”“但是”“然而”“总而言之”“总之”等共22个词汇。
5)停用词词典。停用词是指文本中经常出现但是没有意义的不携带有价值的功能性词汇。过滤停用词的目的是为了减少信息冗余,提高分析的效率和准确性。首先使用哈工大停用词词库过滤数据集中的停用词,由于使用该停用词库过滤效果不干净,故整合四川大学机器学习智能实验室停用词库、百度停用词表,将3种停用词库利用Excel进行停用词的人工整理、匹配、筛选、去重;然后利用Python的TF-IDF算法重点筛选对手机评论数据无帮助和无意义的词汇,加入停用词词典,停用词表共包含2 185个词汇;最后基于新的停用词表对分词后的用户评论数据进行二次过滤,对分词结果进行检查,判断其是否属于停用词,若分词结果中包含停用词则直接剔掉。
1.2 情感分析算法设计
传统的基于情感词典的文本情感分类是对人的记忆和判断思维的最简单的模拟,通过学习来记忆一些基本词汇,在大脑中形成一个基本的语料库,对输入的句子进行拆分,查看记忆的词汇表中是否存在相应的词语,然后根据词语的类别判断情感。基于该思想,对处理后的语料进行句子级别的划分,并加入构建的手机领域词典,通过计算句子里包含的所有情感词的平均值得到情感得分,基于情感得分进行情感分类。情感分析核心流程如图1所示。
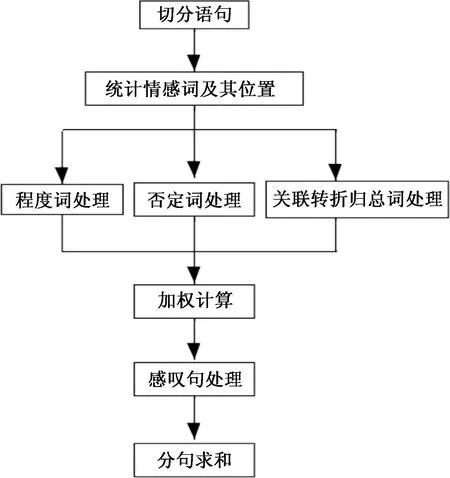
图1 基于情感词典的情感分析核心流程
本文的情感分析算法主要包含3部分。第1部分:读取数据集,并对评论文本进行切割转换。将评论用中文常用标点符号(句号、分号、问号、感叹号等)切割成不同的句子,并进行分词,提取每个分句中的情感词。第2部分:情感词定位。首先将处理后得到的单词依次与预先构建好的情感词表逐个查找,读取情感极性、权值以及位置,循环查找单词,直至整句话判断结束;然后在情感词前查找程度词,找到则停止搜寻,为程度副词设置权值,并乘以情感值;在情感词前查找否定词,若数量为奇数,乘以-1,若为偶数,乘以1;在情感词前查找关联转折归总词,发现后权值乘以1.2;最后倒序扫描感叹号前的情感词,发现后权值加倍,退出循环。第3部分:情感聚合。情感值计算的总体思路是先计算分句积极、消极情感值,再计算整句积极、消极情感值,之后计算积极、消极情感均值和积极、消极情感方差,最后将积极情感均值减去消极情感均值,作为评论的最终情感值。基于语义规则进行权重加权汇总,两情感词之间的所有否定词、程度副词、关联转折归总词与两情感词中的后一情感词构成情感词组,算法流程如图2所示。
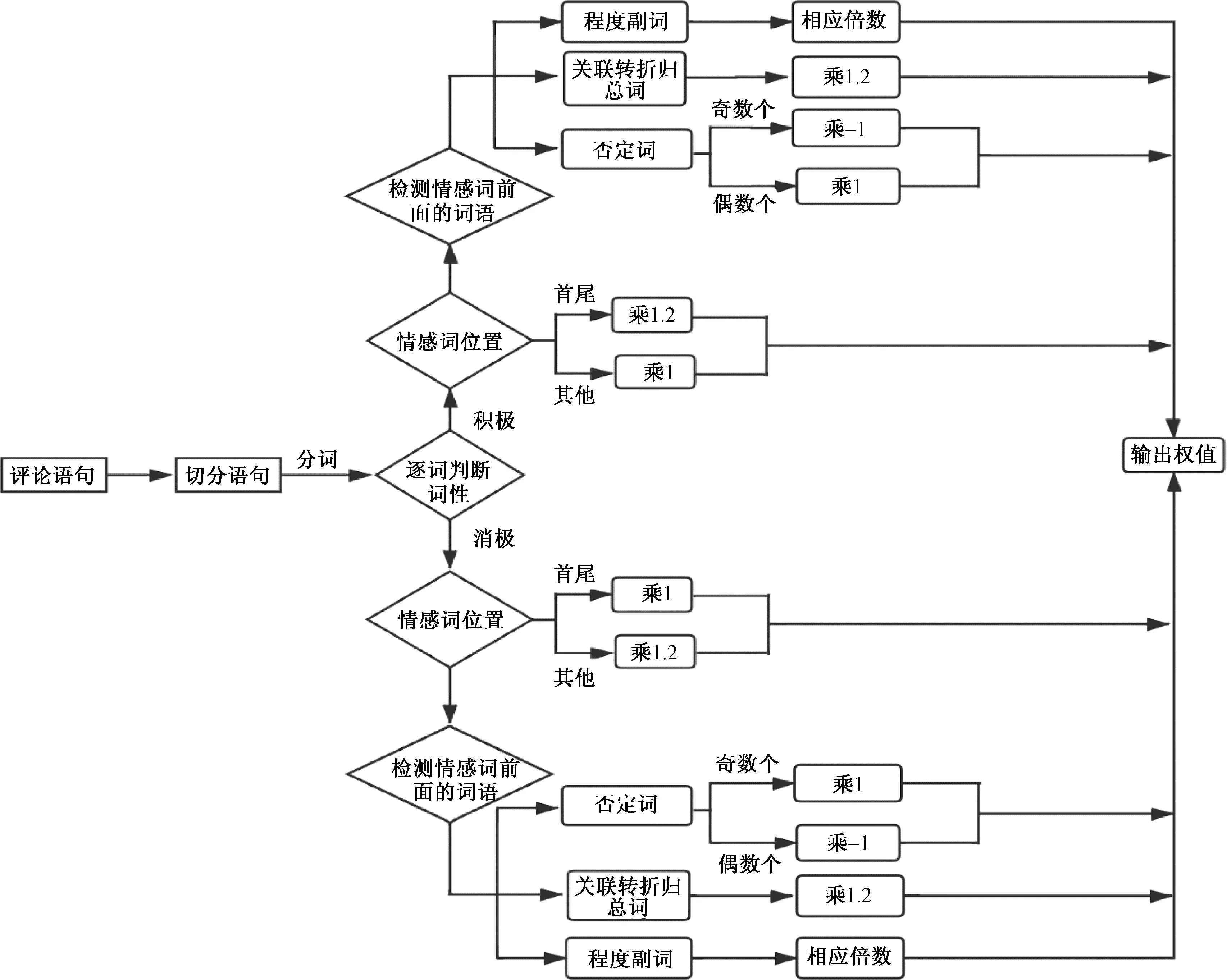
图2 情感得分算法流程图
情感值计算具体描述如下。
1)若情感词前不含有修饰词,情感值Score为基本权重,即Score=w。
2)若情感词前含有程度副词,情感值=情感词权重w×程度副词权重di,即Score=wdi。
3)若情感词前含有否定词,情感值=否定词权重n×情感词权重w,即Score=nw。
4)若同时含有程度副词和否定词,情感值=否定词权重n×程度副词权重di×情感词权重w,即Score=ndiw。
5)若情感词前有关联转折归总词汇,情感值=1.2×原情感值,即Score=1.2wdin。
6)若情感词后有感叹号,新情感值=2×情感值,即Score=2wdin。
1.3 情感词典结果分析
将预处理之后的27 223条关于Vivo手机的评论文本作为情感分析的数据集,利用Python语言中的pandas、numpy以及自己编写的text_process库,实现读取excel数据、分词、词性标注、分句、去停用词、获取词典的权值等功能,对用户评论进行情感倾向性分析,得到用户评论文本的情感得分,并将情感强度值限制在-1和1之间,若评论情感值大于0,为正向;若小于0,为负向;若等于0,则为中性。对情感分析结果进行统计,用户评价及情感倾向展示见表2,情感极性统计结果见表3。
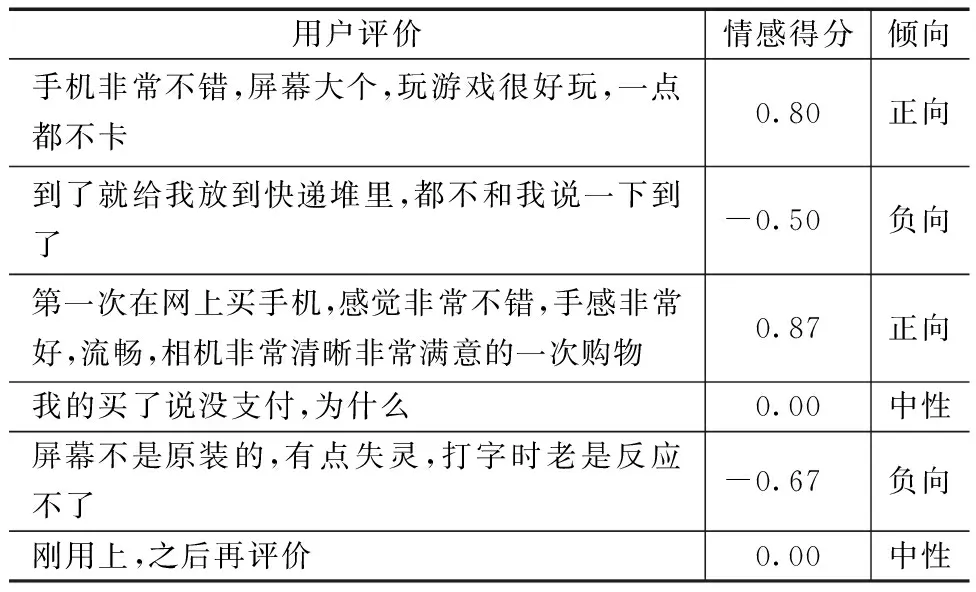
表2 部分用户评价、情感得分及倾向
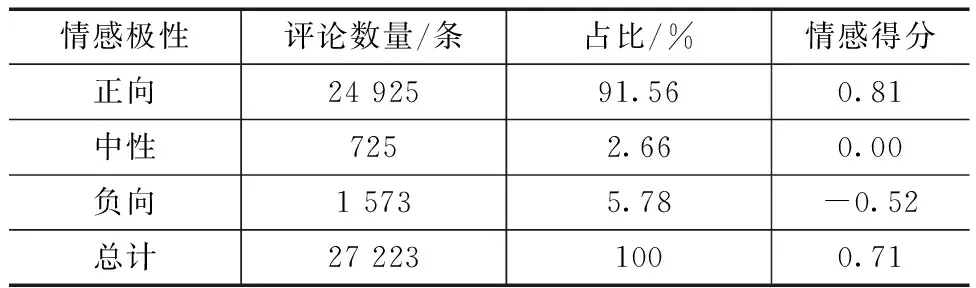
表3 情感极性统计结果
根据情感极性统计结果,在27 223条评论中,积极评论24 925条,占比91.56%,均值为0.81;消极评论1 573条,占比5.78%,均值为-0.52;中性评价725条,占比2.66%。整体来看,用户对Vivo手机的评价是正向的。
为了进一步进行情感态度分析,以-0.5、0、0.5为界限对情感值统计结果进行级别划分,将情感值区间划分为非常消极、消极、一般、积极、非常积极,得到用户各个级别情感态度的占比,情感态度描述统计结果见表4。
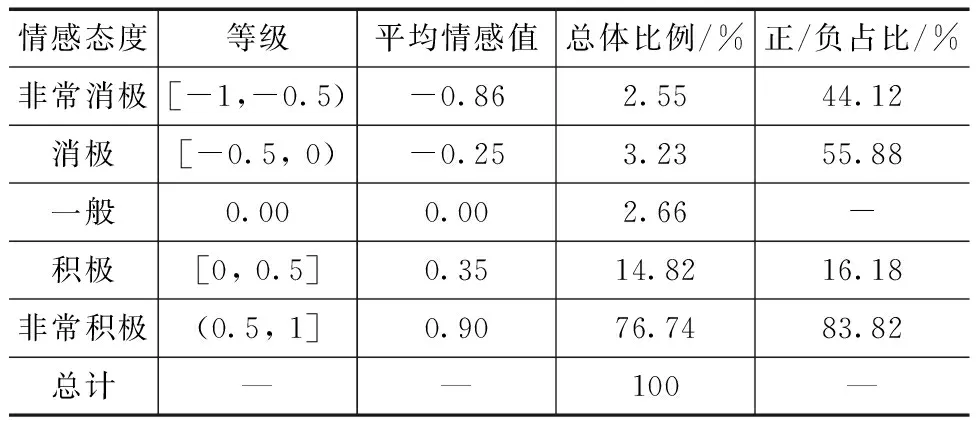
表4 情感态度描述统计结果
在所有积极评价中,“非常积极”的情感评论总体占比76.74%,在所有正向评论中占比为83.82%,平均情感值为0.90;“积极”的情感评论占比14.82%,在所有正向评论中占比为16.18%,平均情感值为0.35。“非常积极”情感区间的用户在正向评论中占比较高,且情感均值较高,可以定义为该区间用户比较偏爱该品牌,是该品牌手机的重度拥护者,商家要重视这一部分用户,增加用户黏性,防止用户流失。对于“积极”情感区间的用户,虽然用户情感倾向是积极的,但正向情感值比较低,手机厂商应该予以重视。
在所有消极评价中,“消极”的情感评论总体占比3.23%,在所有负向评论中占比为55.88%,情感均值为-0.25;“非常消极”的情感评论占比2.55%,在所有负向评论中占比为44.12%,情感均值为-0.86。对于“非常消极”情感区间的用户,该区间用户的负向情感均值极低,可以认定该区间用户与Vivo这一品牌手机不符,可忽略掉这部分用户;而对于“消极”和 “一般”情感区间的用户,该区间用户流动性比较强,商家可以具体定位该区间用户的评价内容,根据用户反馈内容进行手机质量的改进,或者采取相应的政策留住这些用户,将这部分用户转化为积极用户。
基于本文的情感词典及算法设计得到27 223条评论的手机好评度为91.56%,该值高于基于HowNet、NTSUSD得到的手机好评度85.96%,并且接近所爬取的京东官网旗舰店手机好评度93%。实验结果表明,本文的手机领域词典以及情感分析算法对手机评论情感极性分析的结果与实际情况的适配度较高,可有效用于Vivo手机的情感分类。
2 基于情感分析和K-means算法的用户聚类分析
2.1 K-means算法
2.1.1 基本思想
在数据集中根据一定策略选择k个点作为每个簇的初始中心,然后观察剩余的数据,将数据划分到距离这k个点最近的簇中,即将数据划分成k个簇完成一次划分,但形成的新簇并不一定是最好的划分,因此生成的新簇中,重新计算每个簇的中心点,然后在重新进行划分,直到每次划分的结果保持不变。
2.1.2 算法实现
K-means算法是将样本聚类成k个簇,具体算法描述如下。
第1步:随机选择k个中心点;
第2步:把每个数据点分配到离它最近的中心点;
第3步:重新计算每类中的点到该类中心点距离的平均值;
第4步:分配每个数据到它最近的中心点;
第5步:重复第3步和第4步,直到所有的观测值不再被分配或是达到最大的迭代次数,说明聚类不可变,结束。
算法流程如图3所示。
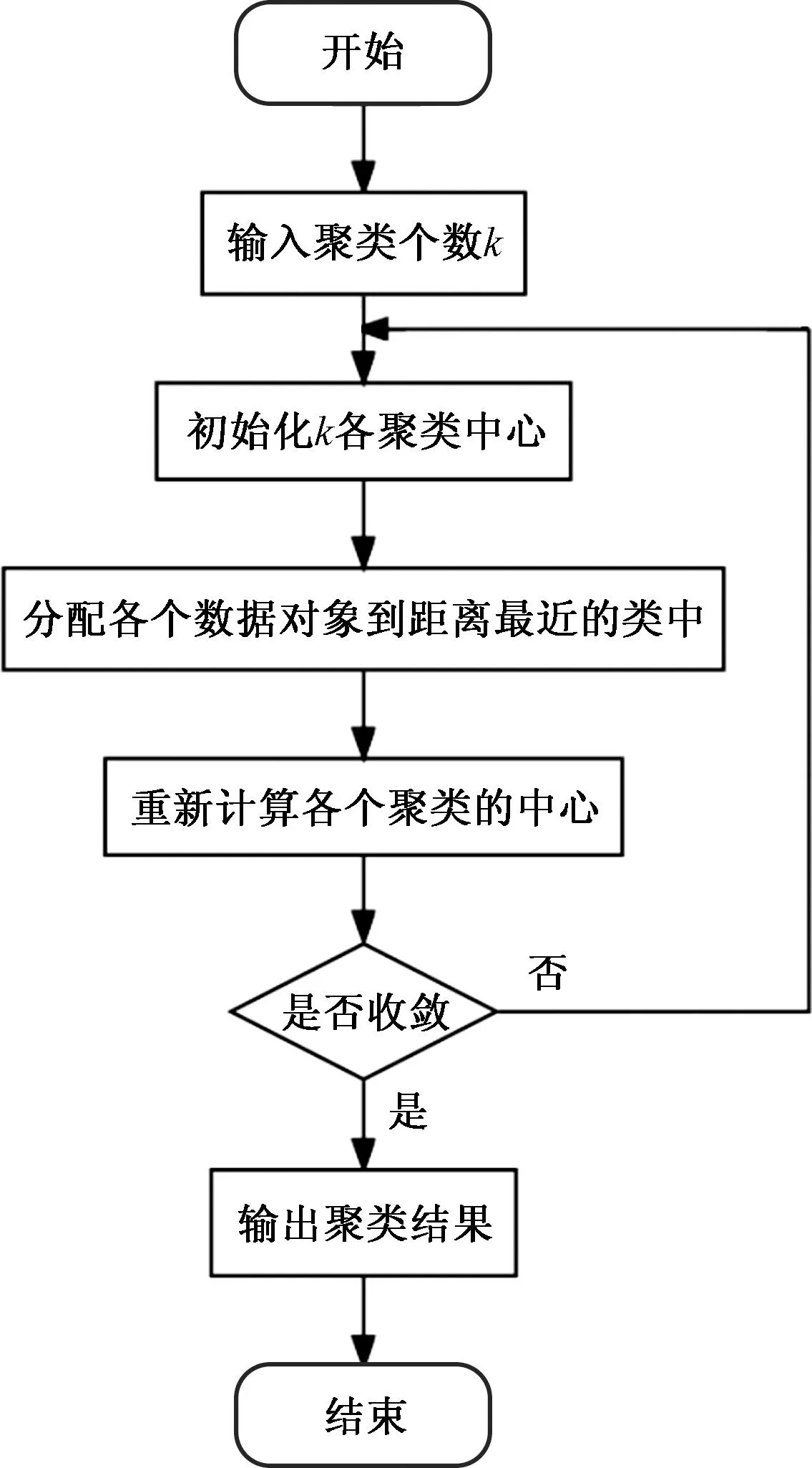
图3 K-means聚类流程
2.2 K-means聚类最优k值的选取和实现
K-means聚类算法中最优k值的选取方法主要有手肘法和轮廓系数法,本文中采用手肘法选取最优k值。手肘法的核心指标是SSE(误差平方和),即
(1)
式中:Ci为第i个簇;p为Ci中的样本点;mi为Ci的质心(Ci中所有样本的均值);SSE为所有样本的聚类误差,代表聚类效果的好坏。
手肘法的核心思想是随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,误差平方和SSE会逐渐变小。当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,SSE的下降幅度会骤减,并随着k值的继续增大而趋于平缓,即SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。
对预处理后的数据利用手肘法选取最佳聚类数k的具体做法:基于Python语言中的sklearn,构造聚类器,让k从1开始取值直到取到合适的上限(选取上限为11),对每一个k进行聚类并且记下对应的SSE,然后画出k和SSE的关系图,利用SSE选择k,最后选取肘部对应的k作为最佳聚类数。
2.3 基于情感分析和K-means算法的用户聚类结果分析
首先对用户评分星级进行独热编码预处理,然后结合情感词典得到的用户评论的积极情感均值、消极情感均值、积极情感方差、消极情感方差对27 223条数据进行K-means聚类,并使用手肘法确定最优k值,得到聚类的手肘图和聚类统计结果,如图4和表5所示。
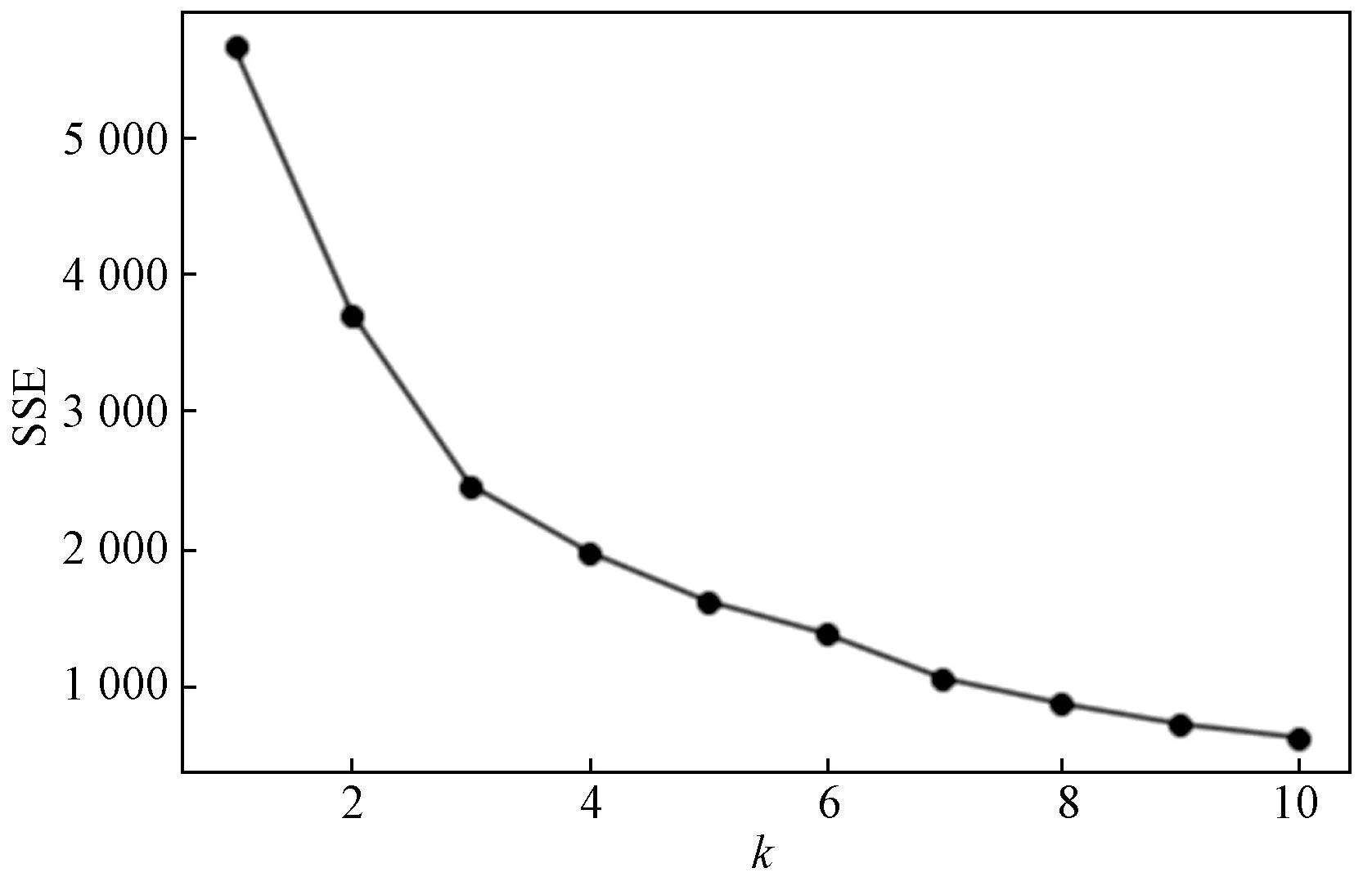
图4 手肘图确定k值

表5 3类用户聚类分析统计结果
从手肘图得到,在k=3时,畸变程度得到大幅改善,故对于这个数据集的聚类而言,最佳聚类数应该选3。经过整理,得到表5所示的聚类结果。第1类用户评分均为5分,且积极情感均值最高,为0.943,消极情感均值最低为0.060,积极情感方差最高为0.921,消极情感方差均为最低0.076,将该类用户定义为A级别用户;第2类用户的评分为5分,积极、消极情感均值分别为0.439、0.218,积极、消极情感方差分别为0.314、0.219,将该类用户定义为B级别用户;第3类用户评分为1~4分,积极情感均值最低,消极情感均值最高,分别为0.356、0.494,积极、消极情感方差分别为0.295、0.488,将该类用户定义为C级别用户。
使用Python语言中的TextRank算法分别对3种类型的用户进行分析,得到A级别用户对手机的关注点按重要程度排序分别是拍照效果、外观、运行、屏幕、手感、性价比、物流、电池、充电;B级别用户对手机的关注点按重要程度排序分别是手机速度、屏幕、拍照、充电、外观、电池、物流;C类用户对手机的关注点按重要程度排序分别是手机外观、运行、拍照、屏幕、物流、电池、手感、性价比。由于C类用户的满意度比较低,说明其对手机的要求更高,可以根据其评论,在手机外观、运行速度、拍照等方面进行进一步改进,既有利于提高C类用户的满意度,又可以增加A类与B类用户的用户黏度。以此类推,商家可根据不同类用户关注频次高低进行相应的营销工作以及手机质量改进工作,以进一步提高客户满意度和品牌认可度。
3 基于情感分析和机器学习的用户分类预测
首先将数据集按照7∶3的比例随机划分为训练集和测试集;然后将用户细分的所属类型结果作为因变量,将用户评分星级、积极情感均值、消极情感均值、积极情感方差、消极情感方差作为自变量,在训练集上分别采用SVM、决策树、KNN、随机森林模型训练用户分类预测模型,最后在测试集上测试模型效果。模型对A、B、C 3种用户类别的分类结果见表6。
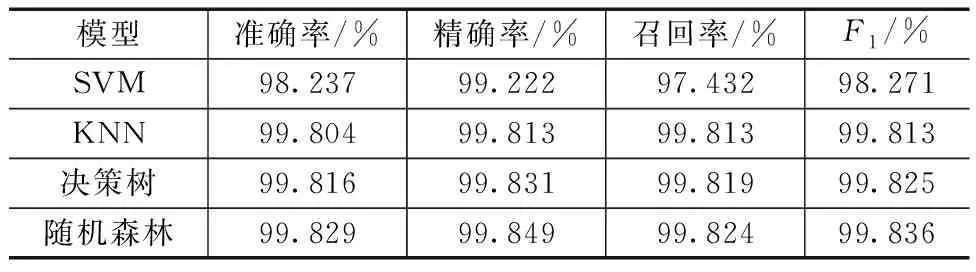
表6 用户分类模型运行结果
利用Python语言中的scikit-learn模块来实现用户群体分类,在随机森林模型中,得到预测准确率较高(99.829%)。因此将用户类别作为因变量,基于随机森林的用户分类预测模型效果最优,故可采用随机森林模型对用户类型进行预测。
4 结语
为了充分利用用户评论内容挖掘客户和产品信息,能够根据用户属性和情感值定位用户类别,并开展相应的营销工作,进行产品以及服务的升级改进,对Vivo手机在线评论进行了充分地挖掘分析。首先在基于情感词典的态度分析中,构建了针对手机领域内的情感词典,基于训练的扩充词典,对手机领域用户评论计算,得到每一条评论语句的情感得分,并基于得分结果进行满意度区间的划分,针对每个区间分别进行情感倾向分析,得到了较好的效果。然后基于情感词典的结果,对用户进行价值区间的细分类,根据聚类结果进行用户预测模型的构建,预测模型预测结果较好,可以用于新样本的预测。依据情感词典得到了4个情感指标(积极情感均值、消极情感均值、积极情感方差、消极情感方差),并创新性地利用情感指标构建了用户分类预测模型,将用户分类,能够有效帮助商家根据不同类别用户实现自身产品与服务的优化、营销与竞争策略调整、精细化管理等实际问题。利用用户评论,构造情感词典所得到的4个情感指标,结合用户的其他指标,对用户分类,进而根据用户类型进行服务营销的思想具有可移植性。该思路可用于其他手机品牌产品的用户预测,进而提高服务质量,为情感分析提供了新思路。
从消费者评论角度出发,通过对Vivo手机评论的挖掘分析,结合实际情况,向商家提出以下几点建议:①针对手机质量问题,建议商家在保证手机其他优势的基础上,对手机电池、充电以及屏幕问题进行改进,整体提升手机的质量;②针对客服售后服务问题,建议电商平台改进相关制度,并对用户购物平台的客服人员进行素质培养,站在顾客角度提供各类优化方案,让用户在沟通中产生共鸣,及时解决用户反馈的各种问题,提高解决纠纷的效率,保障消费者权益,提高消费满意度;③针对不同类型的用户,建议在服务中提升顾客购买过程体验,将商品销售转化为沟通和交流活动,丰富消费体验,满足消费者情感需求,提升顾客黏性,诱发消费潜能,满足不同层次的消费需求。
猜你喜欢
我爱学·笑话与口才(2024年6期)2024-06-15 00:00:00
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
海峡姐妹(2015年3期)2015-02-27 15:10:14
中国卫生(2014年12期)2014-11-12 13:12:44
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
