
多学科交叉新秀:古生物信息学的兴起与发展
2024-01-02 13:05刘建妮李忠虎颜建强王惠亚黄康俊章勇勤张卫国
西北大学学报(自然科学版) 2023年6期
刘建妮,冯 筠,李忠虎,韩 健,颜建强,王惠亚,黄 康,黄康俊,姜 博,温 超,张 敏,章勇勤,张卫国,沈 妍
(1.西北大学 地质学系/大陆动力学国家重点实验室,陕西省早期生命与环境重点实验室,西安市古生物信息学重点实验室,陕西 西安 710069;2.西北大学 信息科学与技术学院/西安市古生物信息学重点实验室,陕西 西安 710069;3.西北大学 生命科学学院/西安市古生物信息学重点实验室,陕西 西安 710069;4.西北大学 数学学院/西安市古生物信息学重点实验室,陕西 西安 710069;5.西北大学 艺术学院/西安市古生物信息学重点实验室,陕西 西安 710069)
古生物学作为一门传统基础学科,研究对象主要为古生物化石,目标是揭示地球生命发展历程并提供地球环境变化的证据。在以往的古生物学研究中,绝大多数研究是依靠化石形态学分析得到的数据继而展开推理研究。随着地球科学新方法和新技术的应用,以及生命科学和信息技术的迅速发展,古生物学这门古老学科逐渐进入了纵深发展的新时代。当下学科间界限越来越模糊,不同学科间的跨界融合不断加深,针对古生物化石的信息化和可视化的研究成果日益增多。化石的三维复原、谱系演化分析、化石图像检索等教学、科普等相关研究在国内外发展迅猛。
2012年,本交叉学科创始人兼负责人刘建妮教授意识到必须将古生物学、信息技术、生物学、数学及艺术相融合,以人工智能、大数据及图像图形处理技术为工具挖掘化石中蕴含的规律,最终将古生物化石面貌及化石赋存的环境以鲜活的形式展示给大众,由此她率先提出了古生物信息学的概念。
古生物信息学(paleo-bioinformatics)是指在古生物学的研究中,以信息技术、大数据技术、人工智能技术为工具对古生物化石及其环境信息进行收集、检索、分析以及表达的学科。具体而言,古生物信息学作为一门新的学科领域,是以古生物数据库的建立为基础,综合地质、地理、生物科学,研究适用于古生物谱系分析、古生物化石图像分析、地球生物演化规律推理分析的算法和软件工具,最终以艺术的手段复原并展示古生物及其生活环境。
开展古生物信息学交叉研究,目的是希望利用现代信息等技术,更快、更准、更好地挖掘化石中尘封的生物演化奥秘。要实现这一目标,首先,需要建立古生物信息平台,为后期的推演和复原提供数据基础;其次,探索适合于古生物学的谱系分析和化石检索的算法,准确推演地球生物之间的演化关系;再次,研究基于古生物化石三维重建、化石复原和可视化的新方法和新技术,让化石“活”起来。
总体而言,古生物信息学是集古生物学、信息学、数学、生物学及艺术等多学科于一身的新兴交叉学科,是古生物研究发展的必经之路。
1 古生物化石资源平台建设
经过多年的学科发展,传统古生物学的研究内容在各方面已经形成了丰富完整的体系,对各种化石的分类研究也趋于精细。同时,新技术的发展应用也为古生物的研究提供了便利。目前的研究从原来的定性分析逐渐发展成定量分析,研究范围也由有限范围扩展至更宏观和更微观的领域,研究方法和手段也都得到了相应的提高。古生物化石资源平台也因此应运而生。
西北大学地质学系联合信息科学与技术学院,从2013年开始建设以寒武纪澄江生物群及关山生物群为核心、综合全球其他寒武纪开放化石库的古生物化石信息平台。该平台融合化石形态学、生态学、生物地理分布、沉积学、埋藏学等多种参数,数据描述规范、管理逻辑清晰、系统安全性高、查阅数据迅速、操作逻辑简单,为古生物信息学的进一步研究奠定了基础。
首先,本团队依托西北大学博物馆及陕西省早期生命与环境重点实验室,经过多年的发掘,形成澄江生物群、关山生物群近20万枚精美的标本实体库。其次,通过对化石库中的各类化石进行高清拍摄,对种类、形态、保存环境等进行特征数据记录和保存,形成化石标本数据库。再次,利用现代信息学技术,对化石图像进行图像增强、图像分类、三维重建、古生物复原等,形成化石复原图、古生物三维模型库。最后,对多模态化石数据进行系统整合,形成大规模古生物化石资源平台。
西北大学古生物化石资源平台目前已部署在西北大学域名下,是一个电子化、系统化的古生物信息学数据平台(见图1)。平台采用了先进、高效的信息技术,保证了系统稳健性和易用性。平台具有化石标本查询、化石标本打印、化石标本编辑等多个功能,基本实现了化石标本资源的高质量共享。
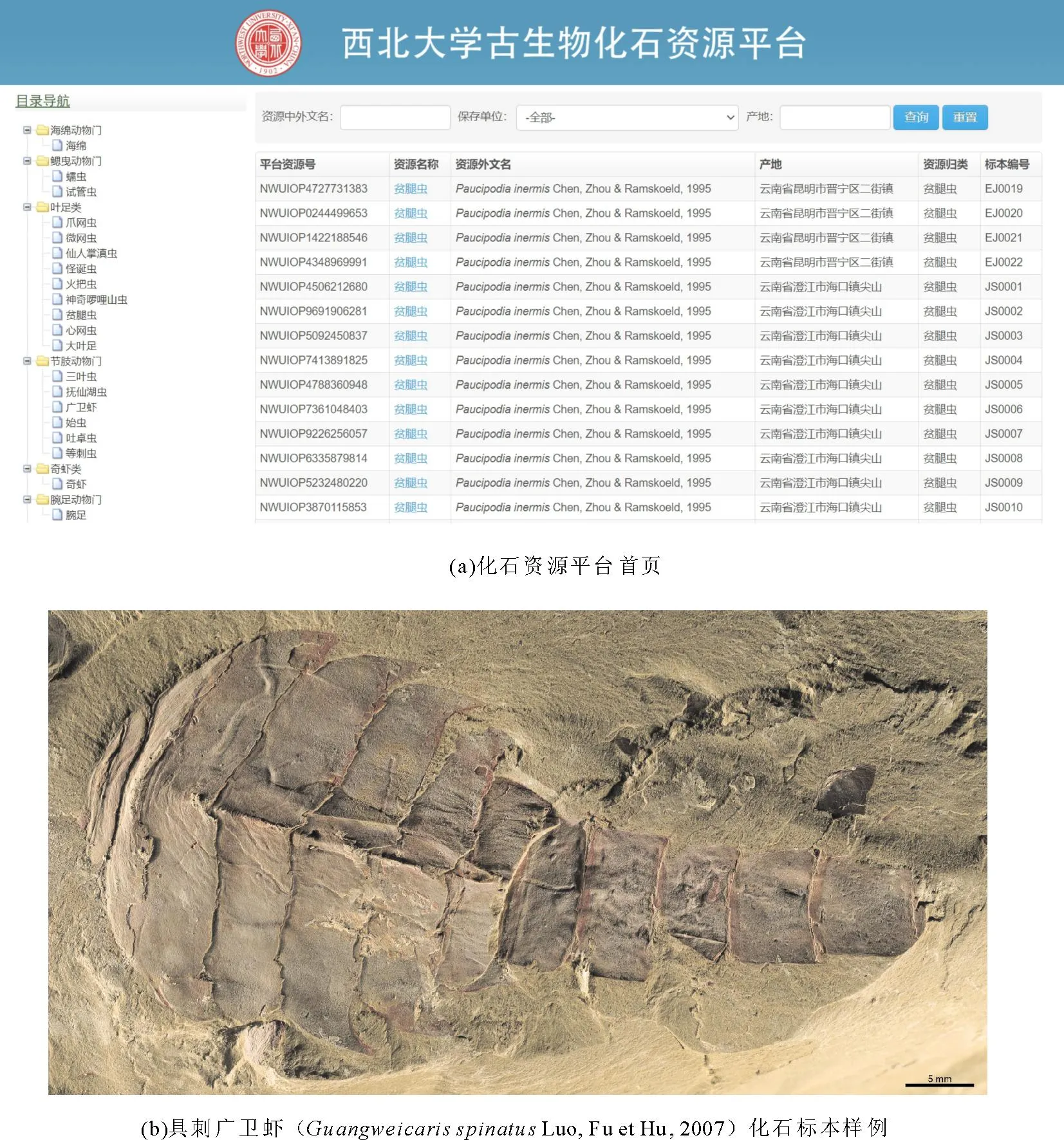
图1 西北大学古生物化石资源平台Fig.1 Northwest University paleontological fossil resource platform
2 古生物谱系分析方法研究
系统发育学是对种群或物种的起源(形成)和演化(进化)关系进行科学研究的学科[1]。其核心是运用共近衍征特征矩阵重建共有祖先关系,并在共同祖先的基础上将分类单元归类,最终得到符合生物进化规律的系统发育树,反映物种的进化历程和物种间的亲缘关系[2]。
当前已有面向现生生物的系统发育树构建方法和软件工具,例如:PAUP[3]、TNT[4]、Mrbayes[5]等,然而古生物的谱系分析和现生生物有所不同,主要原因如下。
1)现生生物主要使用分子数据,如DNA 碱基序列为共近衍征特征矩阵,也就是腺嘌呤(A)、胸腺嘧啶(T)、胞嘧啶(C)与鸟嘌呤(G)的排列方式。如果该碱基序列存在,在计算机命令中以“1”来表示,如果该碱基序列不存在,在计算机命令中以“0”来表示。因为基因测序的精准性,碱基序列是否存在必然精准。然而,在亿年前的古生物化石中无法提取到分子数据,只能使用化石形态学(形状、大小、数目、比例、纹理及装饰物等)特征,如,牙齿形状、复眼数目、体表环纹等人为观察特征。这些特征存在诸多不确定性,和DNA序列确定的表达形式大为不同。
2)化石因为埋藏环境和人为挖掘等因素易造成形态模糊、结构缺损及数目不定等多种数据缺失的情况,此时可将化石的形态特征值记录为“不确定”,也就是计算机命令中的“?”。
3)化石形态特征存在递进层次关系,因而存在由于某些特征缺失继而造成相关特征不可适用的情况。例如,某生物化石显示没有触角,触角特征标定为“0”,那么相关的触角个数、触角长度等形态特征等由于触角的缺失则均不可适用,在计算机命令中我们通常记录为“-”。
利用形态学特征矩阵可形成寒武纪动物系统发育树[6](见图2)。其中特征矩阵的行代表物种,列代表属性,特征值为“0”代表未发现该物种有此特征,“1”代表该特征存在。可以看出形态学特征矩阵中存在大量标记“?”和“-”的数据,这使得古生物的谱系分析结果不稳定,难以获得最优解,现生生物的系统发育树构建方法失效。
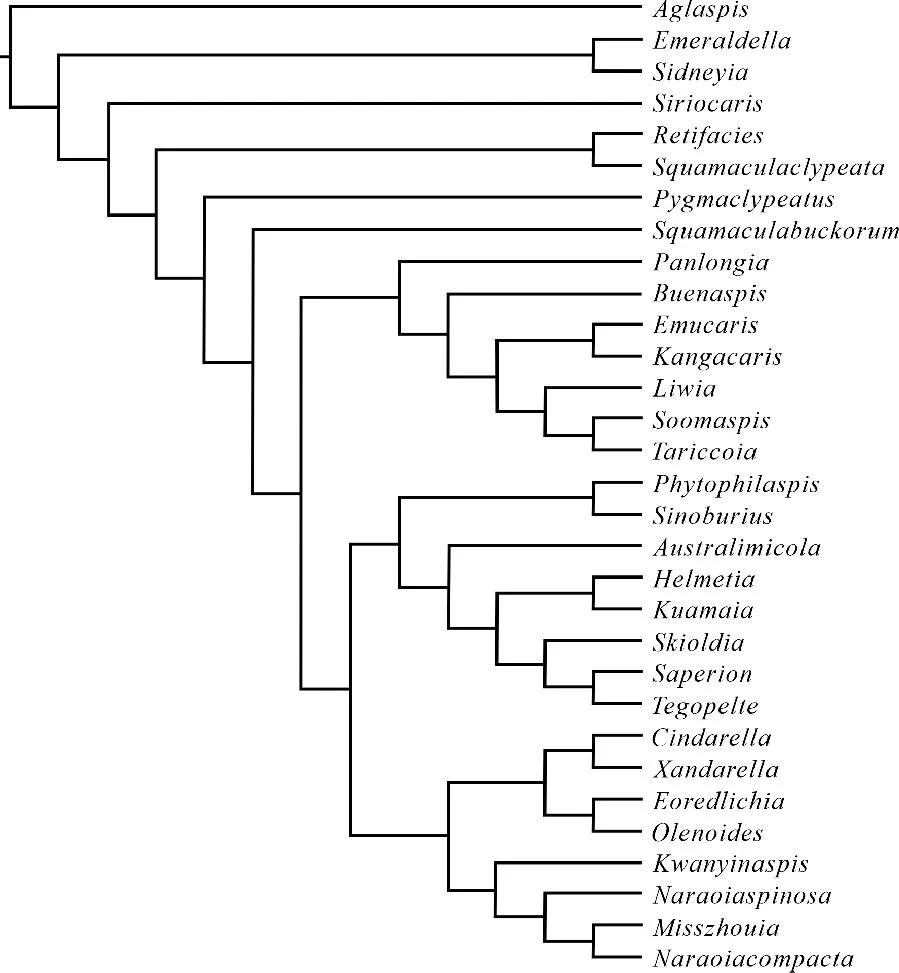
图2 运用现生生物学谱系分析方法所得出的寒武纪动物系统发育树Fig.2 The phylogenetic tree of Cambrian animals obtained by using the method of modern biological pedigree analysis
目前现生生物的系统发育树构建方法有邻接法[7]、最大简约法[8]、贝叶斯推断法[9-10]等,古生物的谱系分析尚无公认的方法和工具。团队从对形态学数据中缺失信息的插补和对含不可适用信息的系统发育树构建方法等方面进行了深入研究。
2.1 形态学数据中缺失信息的插补
已有研究证明缺失数据会对系统发育建树结果的准确性和有效性产生负面影响[11-12],因此不少研究对缺失数据进行处理,以方便形态学数据集的使用。目前主要的处理方法有缺失数据直接删除法、缺失数据插补法和缺失数据忽略法[13-19]等。但在大多数情况下,具有大量缺失值的分类单元或特征仍然可以提高进化树构建的准确性,并且剔除分类单元通常会影响其他分类单元之间的演化关系[20-21]。所以对于缺失数据处理方法来说,直接删除或忽略并非良选,因为无法有效利用数据包含的全部信息。有研究表明,相较于直接删除或忽略缺失数据,对缺失数据进行插补是更为有效的方法[22-23]。针对形态学数据中存在的缺失信息导致古生物系统发育分析结果不稳定的问题,团队成员对特征矩阵中缺失数据插补提出了几种方案(见图3),使得形态学数据更加完整,系统发育分析更为有效。
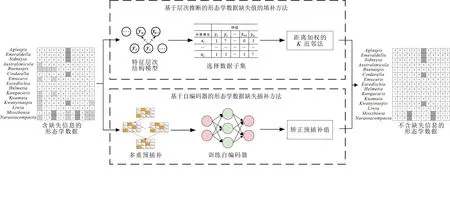
图3 形态学数据中缺失信息的插补Fig.3 Interpolation of missing information in morphological data
团队将机器学习领域中的缺失值填补方法引入形态学数据特征矩阵中缺失值的处理任务,并融入更多演化分析的先验知识,提出一种基于层次推断的形态学数据缺失值的填补方法[24]。该方法先根据特征矩阵中特征间存在的单向逻辑依赖的特点,建立特征层次结构模型,然后以此特征层次结构模型为基础提出了一种层次推断框架,用以处理含层次化特征的形态学数据中缺失数据的插补问题。最后将距离加权的K近邻法引入到层次推断框架中以完成特征矩阵中缺失数据的插补,提高缺失数据插补的准确性。实验结果表明,相较于目前建树方法中基于模糊优化的缺失数据处理方法,层次推断方法可以降低数据的模糊性,挖掘更多的有效信息,从而能够充分利用形态学数据中的信息。
此外,本研究还提出了一种基于自编码器的形态学数据缺失插补方法[19]。受深度学习不断发展的影响以及基于深度网络的缺失插补方法的启发,本团队提出一种全新的结合多重插补与自编码器的两段式缺失插补方法。该方法首先使用基于链式方程的多重预插补模型,结合链式方程与最近邻原则对缺失数据进行多重预插补,得到初始的插补值。随后使用基于自编码器的插补矫正模型,利用全部已知的数据集训练一个自编码,再运用训练好的自编码器对缺失插补值进行矫正,从而得到最终的缺失插补值。实验证明,相对于常见的缺失数据插补方法,该方法有极高的插补准确率,且插补后的数据也有较好的系统发育分析结果,可有效解决形态学数据中缺失信息造成系统发育分析结果不稳定的问题。
2.2 含不可适用特征的古生物发育树构建
化石中特征之间的递进层次关系使得形态学数据中存在不可适用信息, 而不可适用信息往往会导致系统发育树难以有效构建。 对不可适用数据的常见处理方法包括: ①对不可适用数据使用缺失数据进行表示,以缺失信息来处理不可适用信息; ②将多个特征转变为一个多状态的特征进行表示,从而避免出现不可适用信息; ③用全新的特征状态来表示不可适用特征状态, 换言之是将不可适用信息作为普通信息处理。 上述方法都不能准确地利用不可适用数据的信息。 针对不可适用信息导致系统发育分析不稳定的问题, 本研究提出了一系列的优化方法以充分利用形态学数据中的不可适用信息, 并有效构建系统发育树(见图4)。
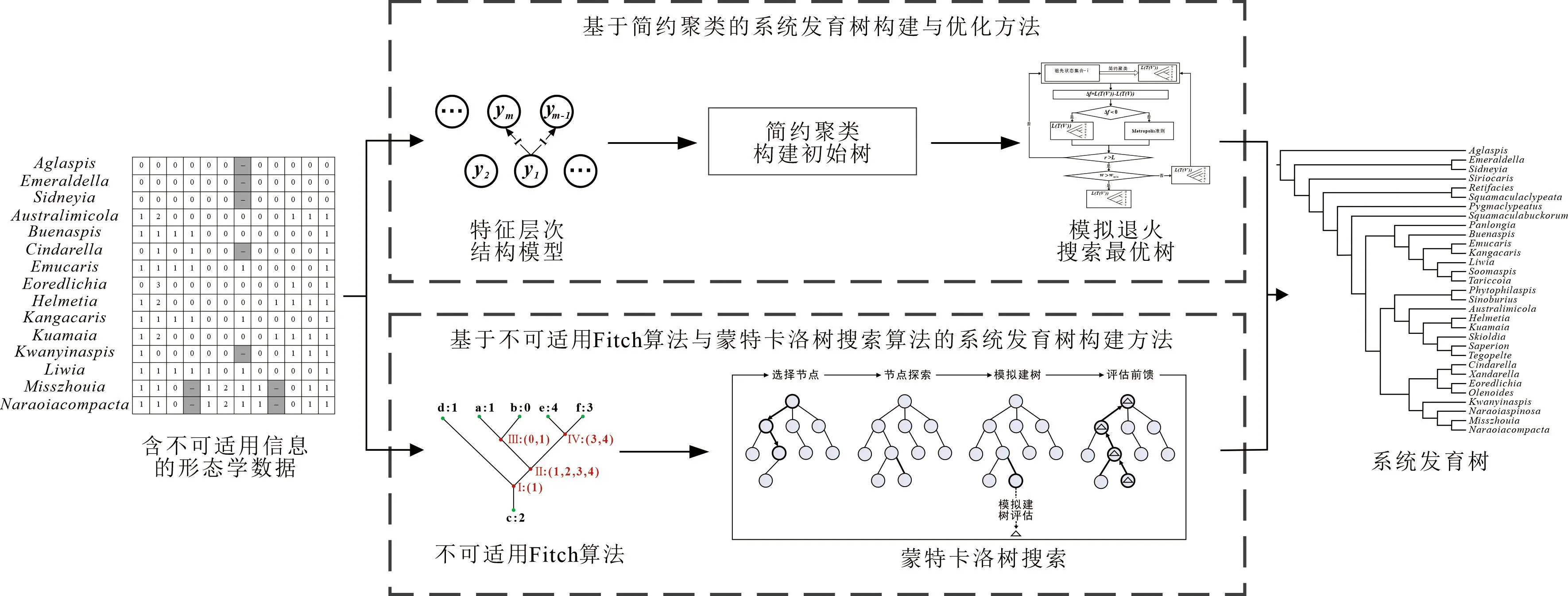
图4 含不可适用信息的系统发育树构建方法Fig.4 Phylogenetic tree construction methods with inapplicable information
从形态学数据的特征层次关系出发,首先提出了一种基于简约聚类的含不可适用信息的形态学数据系统发育树构建与优化方法[24]。该方法包括进化树的构建和最优树的搜索两个阶段。①在进化树的构建过程中,将特征层次结构模型和特征极向等先验知识融入聚类算法,提出一种简约聚类方法,用以构建含不可适用信息的系统发育树;②在最优树的搜索阶段,在简约原则的基础上采用模拟退火算法进行启发式搜索,构建更为有效的系统发育树。实验表明,基于上述方法构建的古生物系统发育树,与目前普遍认可的系统发育树拓扑结构基本一致,验证了该方法在含不可适用信息的古生物系统发育树构建方面的有效性。
此外,团队还提出了一种基于不可适用 Fitch 算法与蒙特卡洛树搜索算法的系统发育树构建方法[19]。形态学数据的不可适用Fitch算法[25]基于最大同源性假设,能对不可适用数据进行更合理的处理,对含有不可适用信息的系统发育树进行更为有效的评估。本研究基于不可适用Fitch算法提出了一种蒙特卡洛树搜索算法,经过多次搜索、模拟建树、评估反馈等步骤,解决了优化搜索中容易陷入局部最优解的问题,使用蒙特卡洛树来平衡搜索的宽度和广度,从而更为有效地进行系统发育树的搜索,构建更加优化的系统发育树。基于不可适用 Fitch 算法与蒙特卡洛树搜索算法的系统发育树构建方法对于不可适用信息的处理更加合理,也使得系统发育树的搜索更为有效。实验结果表明,相较于目前流行的方法,该方法在多个形态学数据上构建的系统发育树有着更短的树长、更优的树得分以及与模型树更高的相似度。
3 古生物化石图像检索
古生物学家或者古生物化石爱好者们发现未知化石之时,需要对其内容进行鉴别,通过将这些未知化石的特征与已知化石的相似特征进行对比,进而初步推测未知化石的形态特征及其所代表的地质时代的生物多样性和生物间相互关系等相关信息。
3.1 基于内容的古生物化石图像检索
古生物领域的研究者对化石图像早期的检索工作通常依赖于人工查找的方式,这不仅消耗大量人力和物力资源,检索速度较慢,且有可能存在主观性因素,因而无法满足用户对实时性和准确性的要求[26]。通过计算机视觉领域的图像识别方法对化石图像的内容进行自动识别和检索,可以有效降低化石图像检索过程中的错误率和主观性,同时提高检索速度。图像检索是指从图像库中找出包含查询图像中某一物体的相关图像。图像检索流程中(见图5),图像数据库的图像经过特征提取方法后存储为向量,当查询未知化石图像时,查询图像会经过同样的特征提取方法转化为向量后,与特征数据库中的特征向量进行比对,继而找出距离最近的K个向量所对应的图像。在特征提取过程中,所有的图像会映射到一个向量空间中,使得原本相似的图像在向量空间中是彼此相近的,原本不相似的图像在向量空间中是彼此远离的。而基于内容的图像检索(content-based image retrieval, CBIR)是图像检索中的一种类型,CBIR查询出的相似图像与查询图像在语义上具有相似性。在CBIR中,图像经过特征提取模型所提取到的特征向量通常都包含着图像的语义信息。借助CBIR技术,可以协助古生物学家和古生物化石爱好者们快速、准确地检索到与未知化石图像相关的化石图像,并提供更详尽的信息描述,以便更为迅速地推断未知化石的形态特征和生物学信息。
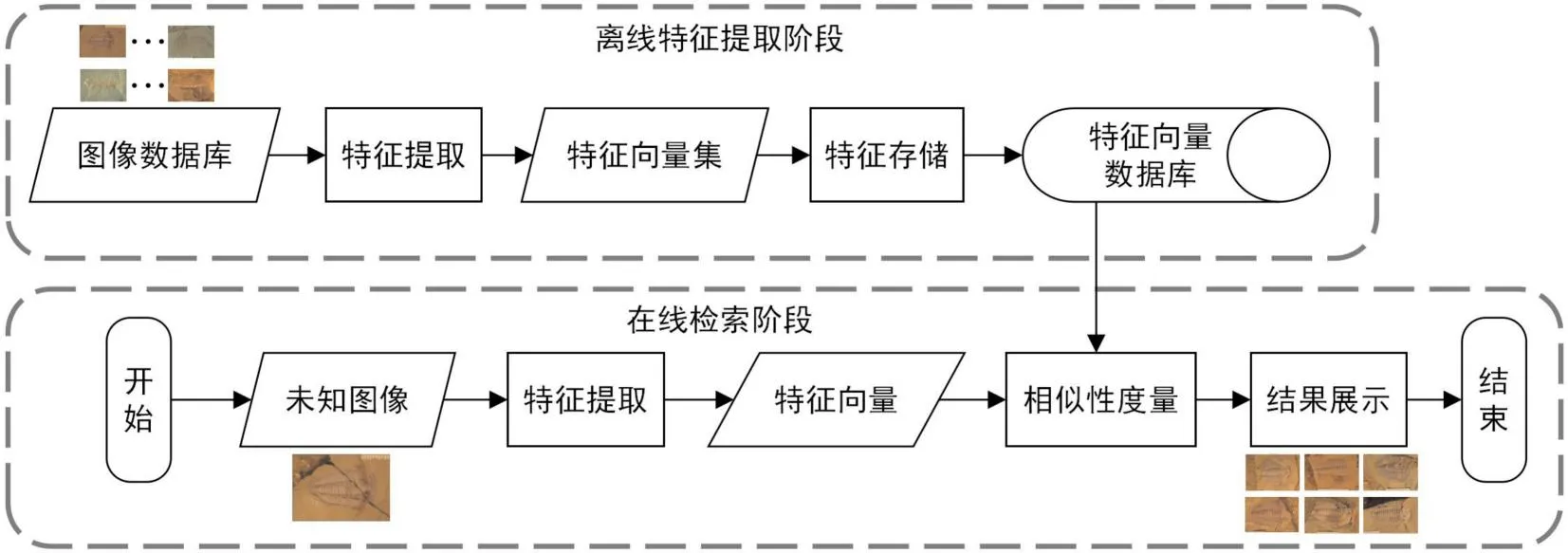
图5 图像检索流程图Fig.5 Flowchart of image retrieval
基于化石语义的图像检索系统的一个关键步骤涉及到特征提取。这一步骤的主要目标是从给定的化石图像中提取出包含有主体语义的特征,并将这些特征映射为一个具有固定维度的向量表示,这是化石图像检索的核心挑战。
3.2 古生物化石特征提取
在早期的化石特征提取的方法中通常使用传统的手工特征方法,如尺度不变特征变换匹配算法(scale-invariant feature transform, SIFT)算法[27]。2018年,团队成员刘曦阳[28]使用改进的SIFT算法对化石图像进行特征提取,改进的SIFT算法在极值检测过程中抑制局部多极值点的产生,并利用Harris角点检测算子对特征点进行筛选。然而,SIFT算法是一种局部特征提取的方法,并不能表达出图像的语义信息。
基于深度学习的卷积神经网络(convolution neural network, CNN)能够提取出表达图像语义的特征,使用分类模型的CNN特征提取网络如AlexNet[29]、ResNet[30]等来提取图像的语义特征是基于内容的图像检索系统中常用的特征提取方法,这些网络所提取到的特征通常称为全局特征。2020年,Marchant等[31]设计了基于循环CNN的网络在大型有孔虫化石图像集训练,利用CNN网络所提取的特征相比SIFT包含更多的语义信息。然而其所使用的化石图像数据都只包含化石主体的纯色背景图像,很难适用于现场拍摄的具有复杂背景的化石图像。
通过实验发现,将CNN网络应用到复杂背景的化石图像提取特征时无法有效地表达复杂背景的化石图像。通过分析ResNet网络中特征权值的分布,研究发现ResNet网络未能捕捉到化石图像的关键特征,特别是主体部分的特征。为了使特征提取网络所提取的特征中包含主体信息,2021年团队提出一种基于显著特征和全局特征融合的化石图像检索方法[26],其特征提取方法如图6所示,使用ResNet提取全局语义特征,显著性检测网络提取显著特征。因此,引入的显著性检测的方法可用于定位并提取化石图像中的显著特征(见图6)。然而,在某些复杂的化石图像上,显著性检测网络无法得到准确或完整的显著特征。
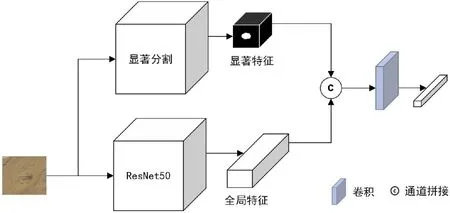
图6 基于全局特征和显著特征融合的化石图像特征提取Fig.6 Fossil image feature extraction based on fusion of global and salient features
为了解决这一问题,团队采用了一种联合描述的方法,将显著特征和全局特征相结合,形成互补的特征表示。分类模型的特征提取网络不易捕捉到的特征,可使用显著性检测进行捕捉。显著性检测效果不佳的化石图像,可使用全局特征进行补充,以提高特征的表达能力,从而改善化石图像的检索效果。在包含三叶虫、鳃曳动物、叶足动物、奇虾类及真节肢动物(三叶虫外)等5个类别的936张化石图像数据集中,该检索系统实现了94.4%的mAP(mean average precision)。虽然以上方法能够有效提高检索性能,但是显著特征和全局特征融合的方式是一种通道拼接方式,使用一般的分类模型的特征提取网络所提取的全局特征中仍然包含着大量的背景噪音。
全局特征包含大量背景噪音,主要原因在于化石图像的岩石背景对于化石主体有较大的视觉干扰,化石主体与岩石背景在颜色和纹理上有着极大的相似性,化石主体边缘与围岩背景难以区分,这直接导致了特征提取模型在提取语义特征时没有关注到化石主体区域。为了使网络关注于化石主体而降低背景噪音的干扰,团队提出一种基于显著采样的两阶段注意力金字塔特征的古生物化石图像检索方法,其特征提取阶段由初筛阶段和细化阶段构成(见图7)。
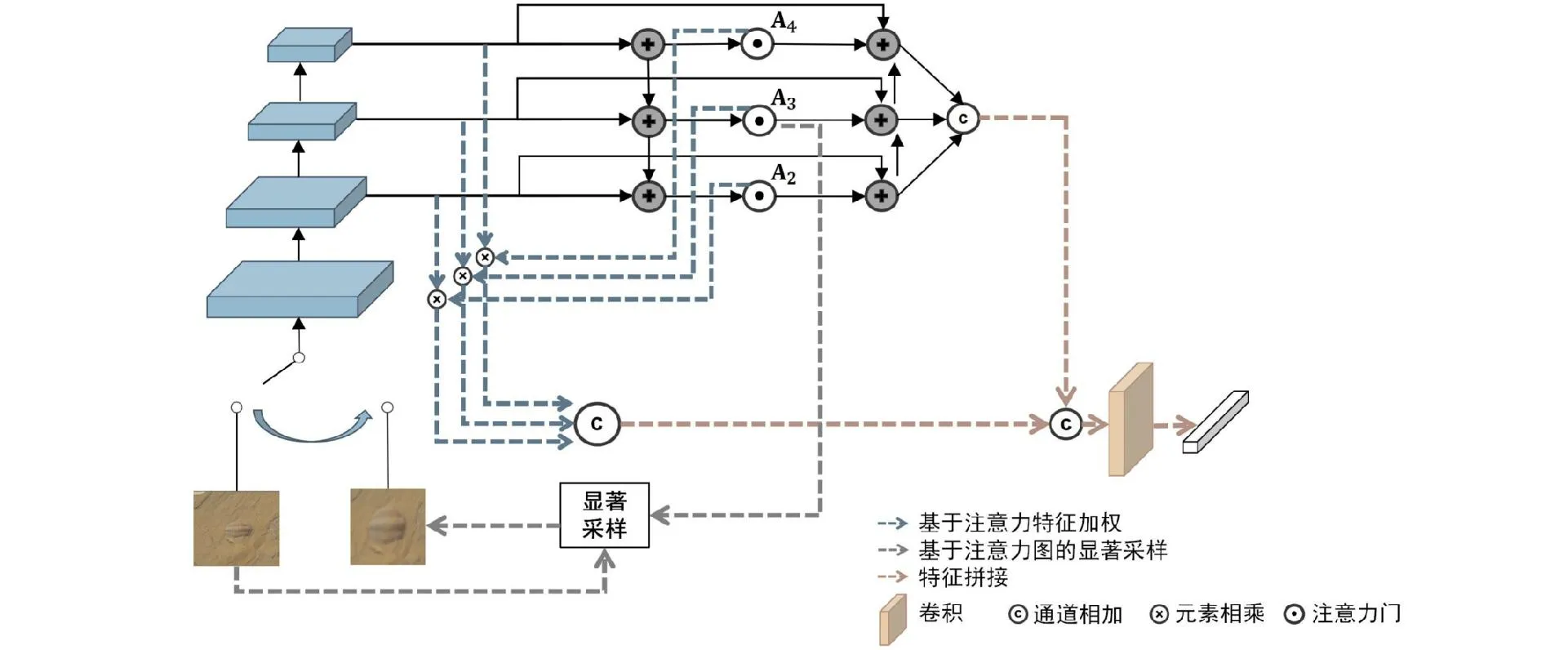
图7 基于注意力金字塔特征和显著采样的化石图像特征提取Fig.7 Fossil image feature extraction based on attention pyramid feature and saliency-based sampling
初筛阶段以原始图像作为输入,而细化阶段以经过显著采样的细化图像作为输入,每个阶段都包括由多尺度特征金字塔和多层次注意金字塔构成的注意力金字塔特征。注意力金字塔特征通过在不同尺度上使用注意力机制,使网络能够注意到化石的主体区域。显著采样通过注意力机制所生成的注意力图放大局部细节,从而使第二阶段的特征提取关注到图像的细节语义信息。除了存在岩石背景对于化石主体有较大的视觉干扰的问题,化石图像还存在着图像之间高相似性的问题。同一纲的古生物化石图像背景和主体具有高相似性,一些不同纲的古生物化石图像背景和主体在视觉上也具有高相似性,这可能会造成特征提取模型将原本不属于同一纲的化石图像映射为特征向量时是彼此相似的。虽然添加注意力机制能使网络在特征提取阶关注到化石的主体区域,但仅使用一般的分类损失训练网络会导致网络无法捕捉图像之间的相似性。因此团队在训练特征提取网络时,为了使网络关注到不同类别化石图像的差异性,使用度量学习框架ProtoNet[32]来学习一个距离函数,使不同类别的化石图像彼此远离,相同类别的化石图像彼此相近。通过使用注意力机制和显著采样,特征提取网络能够有效捕捉化石主体的语义信息。在包含三叶虫、奇虾、广卫虾、始虫、怪诞虫、爪网虫、微网虫、心网虫、神奇啰哩山虫和蠕虫等10个类别的6 059张化石图像数据集中,检索系统实现了96.11%的mAP。图8(a)显示了使用注意力金字塔特征和显著采样作为检索系统的特征提取方法的结果,图8(a)表示查询图像,图8(b)~(f)表示系统返回的前5名结果。

图8 基于注意力金字塔特征和显著采样的化石图像检索结果Fig.8 Fossil image retrieval results based on attention pyramid feature and saliency-based sampling
4 古生物三维重建和可视化
随着计算机视觉三维重建技术的快速发展,从化石图像中自动化重建古生物的三维模型成为可能。基于机器学习的古生物三维重建方法具有广泛的应用前景。重建出的古生物三维模型不仅可以为古生物学研究提供重要参考,而且能够促进古生物科学知识的传播和普及,推动古生物学科的发展。
4.1 古生物化石三维重建
由于化石数据的特殊性,在其形成过程中会造成缺损以及三维空间信息的丢失,古生物学家恢复古生物三维形状有以下两种方法。①利用电子计算机断层扫描(Computed Tomography, CT)[33-35]。这种方法对化石本身的要求较高,需要化石本身完整性好且保存质量高,而且适用性较窄,重建不同化石中的生物要进行多次扫描。另外CT扫描设备成本较高,扫描成形后,还需要人工利用软件修饰细节,耗时费力。②使用三维建模软件来手工绘制出古生物三维模型,这种方法也存在各种限制,要求古生物学家根据化石形态(多是二维特征)推断出化石生物的三维形态,在重建过程中也需要古生物学家和专业建模人员不断交流以实现模型的重建,人力成本消耗极大。为突破传统恢复古生物三维模型方法的诸多限制,减少人力和物力成本,迫切需要新的自动化技术思路和方案,以便从化石图像中重建出古生物的三维模型。
多视图、电子计算机断层扫描图三维重建相对容易,但是从化石图像中恢复古生物的三维形状则属于单视图三维重建的范畴。单视图三维重建是指仅利用对象物体一个视角的图像,在挖掘图像中的特征后重建其三维形状。单视图三维重建一直以来都是一项极具挑战的任务,而化石图像的特殊性又增加了古生物三维重建的难度。在化石图像中,古生物主体与背景岩石相混合,使得古生物主体难以辨别。此外,化石在形成和挖掘过程中不可避免地会受到损坏,导致完整古生物的化石图像数量有限。由于这些限制,化石图像仅能呈现古生物的一个轮廓面,缺乏空间细节信息,这为古生物的三维重建带来了巨大挑战。
在单视图三维重建中, 将二维图像与模板模型结合作为输入的这种方法更贴近人类大脑对物体的三维表达方式。 当人们看到图片时, 通常可以判断出其中物体相似的三维表示, 这种三维表示多是基于个人的先验知识。 近年来, 使用形变模型作为二维图像获取三维信息的先验模型已成为三维重建领域的一个重要方向[36-57]。 这些研究通过引入形变算法或损失函数约束形变, 使模板模型向目标模型不断形变, 最终达到重建的目的。
为了解决上述问题,本团队提出一种基于模板网格模型形变的方法。该方法利用模板模型作为先验知识,通过提取图像中物体轮廓、关键点等特征信息,指导模板网格模型形变并生成符合图像中物体的三维模型。
基于对图像显著性目标检测、图像关键点检测和单视图三维重建技术研究现状的分析,提出基于化石图像显著性特征和关键点检测的古生物三维重建框架(见图9)。我们对化石图像分别进行显著性目标检测和关键点检测,得到化石图像的显著性分割图像和关键点坐标信息,然后以两者为约束和方向,指导模板三维模型形变以生成符合化石图像中古生物姿态的三维模型。通过分析化石图像,发现使用该框架对古生物进行三维重建需要解决以下问题。① 由于化石图像中古生物主体部分与岩石背景融合严重,难以从化石图像中识别出古生物主体;② 不同化石图像中古生物的位姿差异较大,难以检测局部关键点以捕捉古生物局部细节的变化;③ 对大多数化石而言,在形成过程中,古生物由原来的三维形状被“压扁”成二维,因此不同于一般自然图像,化石图像中不包含任何三维空间信息。
针对难以从化石图像中识别出古生物主体问题,本团队提出了一种基于多尺度特征的化石图像显著性目标检测算法;针对难以检测化石图像局部关键点以捕捉古生物局部细节变化的问题,提出了一种基于可分离卷积与空洞卷积池化金字塔的化石图像关键点检测算法;针对化石图像中不包含任何三维空间信息,难以恢复三维形状的问题,结合三维重建技术实例,提出了基于模板模型形变的古生物三维重建算法。采用 Kanazawa 提出的刚度变形优化框架[52],考虑到化石图像不含有任何空间三维信息的特殊性,在优化目标中引入轮廓损失,为后续的变形增加新的约束,综合变种的迭代最近点算法误差函数,尽可能刚性(as-rigid-as-possible, ARAP)能量和局部刚度能量,对模板三维模型的变形进行优化,生成符合化石图像的古生物三维模型(见图10和参考文献[58]中的图21)。

图10 古生物化石三叶虫模板三维模型示意图Fig.10 Schematic diagram of the three-dimensional model of the trilobite template
4.2 古生物信息可视化技术及其相关科普产品研发
目前通过已有技术对古生物进行可视化的结果(见图11),根据可视化结果还衍生出许多科普文创及周边。针对传统化石图像识别与检索领域人工依赖性强、主观偏差性大、耗时耗力、学习门槛高等问题,团队开发了一套化石图像实时检索系统,其中包含数据库管理系统、微信小程序等,实现了数据库管理、化石图像识别检索及三维模型匹配等功能, 具备准确、 高效、 便携、 实时、 交互性好、易于交流共享等优势,实现了化石图像检索领域从人工到AI自动化检索的突破。捕石者微信小程序实现了对用户拍摄或上传的化石本地图片进行后台检索分析,检索后将匹配到的图片和相关信息反馈至前端,还可实现将二维化石图像匹配为对应的三维立体模型,以帮助用户更好地了解化石标本形态等重要信息(见图12a)。同时,为了推动古生物化石信息的传播和发展,还建立了化石科普区和分享交流区“石在有料”,以供用户分享各自拥有的化石样本或图片,并可与其他用户展开交流;“石在有料”版块针对化石爱好者开发,主要侧重古生物及化石知识的科普,同时也支持用户自行浏览搜索,并可对感兴趣的资料进行收藏。“石在有料”“石在有趣”部分界面如图12(b)所示。

图11 “寒武纪恐龙”小奇虾3D复原图Fig.11 3D reconstruction of the "Cambrian Dinosaur" Anomalocaris
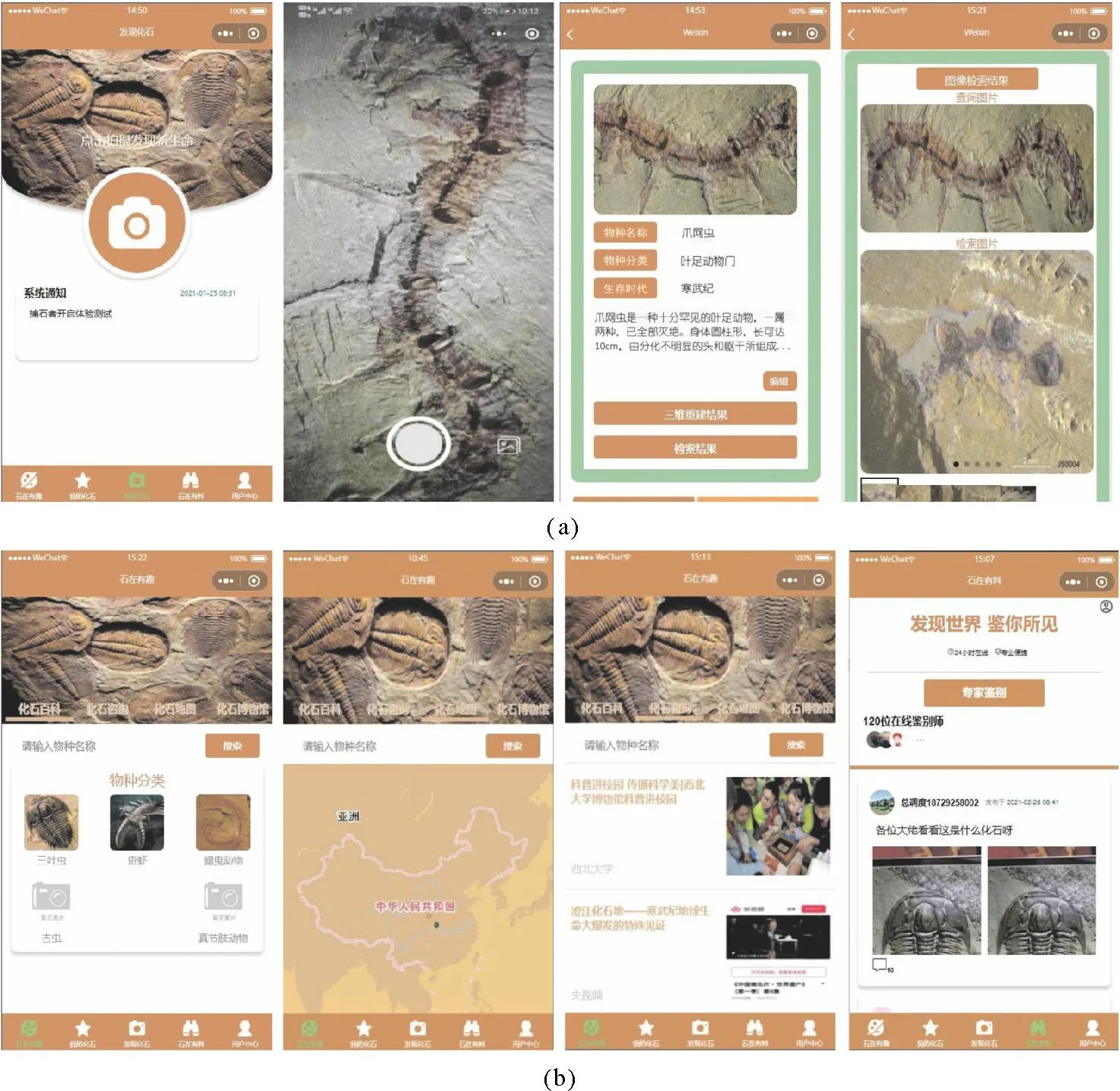
图12 捕石者微信小程序界面图Fig.12 Fossil hunter wechat mini program interface diagram
5 总结与展望
作为古生物学的研究对象,如何让化石‘活’起来一直是古生物学研究的难点与热点之一。本研究将古生物学与信息技术相融合,以智能分析技术、大数据技术及图像图形处理技术为载体和工具挖掘化石信息,从而将化石以鲜活的形式展示给大众,古生物信息学(paleo-bioinformatics)也由此应运而生。
古生物信息学是在古生物学的研究中,以信息技术、大数据技术、人工智能技术为工具对古生物信息进行收集、检索、分析以及表达的学科。历经10多年的潜心研究,古生物信息学团队分别在古生物化石三维重建和古生物谱系分析方法研究等方面做出了重要贡献。目前已逐步形成了一支稳定的、团结合作的、具有国内先进水平的研究团队,发表相关科研论文84篇(SCI收录74篇,包含Nature封面论文、Science、PNAS、NSR封面论文等多篇高质量论文[59-62]),主持包括国家自然科学基金重点项目在内的相关科研项目14项等,获批陕西省“三秦学者”创新团队、陕西省科技创新团队,建立西安市重点实验室并考核优秀挂牌并搭建西安市国际科技合作基地等多个平台。
未来,古生物信息学的发展将融入更多人工智能新技术。作为地质学、信息学、数学、生物学及艺术等多学科的交叉融合的新兴学科,古生物信息学必将是21世纪自然科学的核心领域之一。
猜你喜欢
厦门科技(2021年4期)2021-11-05
软件(2020年3期)2020-04-20
电子制作(2018年19期)2018-11-14
红领巾·探索(2018年12期)2018-01-26
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年6期)2016-11-07
腹腔镜外科杂志(2016年12期)2016-06-01
中国医疗美容(2015年1期)2015-07-12
噪声与振动控制(2015年4期)2015-01-01
生物进化(2014年3期)2014-04-16
