
移动网络隐私信息库未知访问源安全性预警
2024-01-01 00:00:00曹敬馨刘洲洲
吉林大学学报(信息科学版) 2024年4期
关键词:主成分分析法







摘要:针对互联网信息安全预警过程中,受信息数据规模大、种类多影响,导致预警精度低、耗时长的问题,为提高预警效率,提出移动网络隐私信息库未知访问源安全性预警。利用主成分分析法对信息库数据进行降维处理,降低检测难度;利用迭代多元自回归预测(IMAP: Iterative Multivariate AutoRegressive Modelling andPrediction)算法进行数据聚类处理,提取离散性孤立数据点,完成信息库未知访问源数据筛查。将未知访问源数据输入到支持向量机中,利用时间窗口将信息库安全预警模型的构建问题转化为支持向量机学习的凸优化问题,输出安全性预警结果,并对预警模型的构建参数进行全局寻优,提高安全预警模型的预警输出能力。实验结果表明,所提方法对信息库的安全检测效率较高,且面对多类型信息库入侵攻击能做到稳定、精准预警输出。
关键词:主成分分析法;IMAP聚类法;时间窗口;支持向量机学习法;凸优化问题
中图分类号:TP393. 08 文献标志码:A
0 引言
互联网作为一种开放式信息交互平台,包含大量应用信息,其在为用户提供数据查询、资源获取、信息存储的同时,还存在众多安全问题。随着互联网用户量的逐年上升,网络信息泄露、盗取事件的发生频率也逐年增加,一旦网络遭受恶意攻击,网络数据库系统内包含的大量个人、企业乃至国家的机密数据将面临被窃取的风险,造成不可挽回的损失。因此,在互联网技术高速发展的同时,需要对信息的存储安全实施检测。然而,由于网络环境的复杂性和移动终端的普及,移动网络隐私信息库也面临着各种安全威胁,其中包括未知访问源的攻击。这种攻击可利用网络漏洞或恶意软件等方式,窃取移动网络隐私信息库中的数据,对用户隐私构成极大的威胁。因此,开发出更加安全可靠的移动网络隐私信息库系统,保障用户的隐私安全,探究移动网络隐私信息库未知访问源的安全问题,在信息安全领域具有一定的理论和实践价值。
陈丽芳等首先获取当前网络运行数据,并对数据进行去噪处理,引入决策树算法,提取安全状态下的数据运行特征。引入支持向量机模型,在对特征数据进行降维处理后,将低维特征数据输入支持向量机中,并对支持向量机进行数据训练,基于支持向量机建立数据库模型,其具备异常检测功能,最终根据异常检测模型的判别结果对入侵行为进行预警。但此方法入侵检测效率低。
胡梦杰等针对网络数据库的入侵情况,引入入侵检测技术对网络未知攻击进行分析,结合最长公共子序列(LCS:Longest Common Subsequence)算法对攻击特征进行提取;利用蜜罐技术建立信息库主动防御模型,结合结构化查询语言(SQL:Structured Query Language)语义分析法,实现网络数据库的入侵检测。但此方法面对多类别信息库入侵攻击时,存在预警漏报现象。
童瀛等首先对网络中信息库数据进行深度挖掘,利用深度神经网络对信息库数据进行聚类处理,通过神经网络内参数节点的连接,实现邻接矩阵的搭建,进而对网络节点的连接均匀度进行计算,将计算结果与信息聚类结果相结合,实现网络预警响应。但此方法异常检测准确度较低。
基于上述,笔者提出移动网络隐私信息库未知访问源安全性预警。
1 信息库数据降维
降维的目的是为了减少数据的维度,同时保留最重要的信息。在使用协方差矩阵进行数据降维时,可得到每一维度上的方差和协方差信息,这些信息可帮助判断每个维度的重要性,即维度包含信息量的大小。选择保留重要的维度,删除包含较少信息的维度。因此,通过计算协方差矩阵,可有效地分离出数据中最重要的信息,从而完成数据降维任务。
由于互联网信息数据庞大且繁琐,为提高预警效率,实现互联网安全状态有效监控,首先需要对信息库内高维数据进行降维处理。主成分分析法(PCA:Principal Component Analysis)作为一种无标签数据降维方法,能在最大程度保护原始数据完整性的同时,利用高维数据在低维空间内的线性投影,实现数据的降维处理,且对后续数据分析的影响较小。
首先设信息库当前包含的数据集合为Y,样本维度为e,运行数据样本集合Y中第j个数据为yj。根据PCA原理中不同维度数据的方差最大化原则,建立投影矩阵X,设xk为投影矩阵中单位投影向量,且满足||xk||22=1,此时投影矩阵X需满足X=[x1,x2,…,xk,…,xe]。用e’表示数据降维过程中,投影子空间的空间维数,此时过渡矩阵可用XT表示。在投影矩阵空间满足标准正交基要求的前提下,建立目标约束条件如下:
其中y为数据中心点。数据的协方差矩阵D运算过程如下:
投影矩阵X中第k列投影向量用wk表示,因此,特征值问题求解结果为Dwk=μwk。按照取值大小,对协方差矩阵D中的特征向量进行降序排列,并取排序结果中的前e’个特征向量进行向量合并,进而确定X的真实值。为优化求解过程中的数值稳定性,引入奇异值分解(SVD: Singular Value Decomposition)法,设R为对角矩阵,U为左特征向量矩阵,W为右特征矩阵,则协方差矩阵D的SVD分解如下:
χ= URW/χ。(6)
根据上文对协方差矩阵D中特征向量进行降序排列以及SVD分解完成数据的信息库降维。
2 信息库安全检测
在信息库安全检测前,先提取未知访问源是为了更加准确地发现安全威胁。未知访问源是指那些没有经过身份认证或授权的访问者,可能通过漏洞、恶意软件或其他方式窃取信息库中的数据。这些未知访问源的攻击常不易被检测或防范,因此需要先将其提取进行分析和探究。如果在信息库安全检测前没有提取未知访问源,就会忽略一些隐藏的安全威胁。提取未知访问源可以准确地掌握系统使用情况,找出异常访问者,并验证其身份,从而发现并消除安全隐患。通过提取未知访问源并对其进行安全检测,可有效地保护信息库中的数据安全性,防止信息泄露、篡改等风险,确保信息库的正常运转和用户数据的安全应用。
2.1 未知访问源提取
实现数据信息的降维处理后,减少未知访问源数据的检测耗时。为提高安全检测精度,引入迭代多元白回归预测(IMAP:Iterative Multivariate AutoRegressive Modelling and Prediction)聚类法对网络入侵情况进行判别。IMAP聚类法是一种基于网络信息传递的二维空间信息聚类方法,将降维后的数据看做二维空间内数据节点,引入偏向参数,通过响应度信息与可用度信息在空间内的传递机制,对二维空间内的节点数据间的相似性进行判断。
设二维空间内存在数据点j、k,此时若k为类聚中心,则j、k两数据点之间相似度计算如下:
εsimilar(j,k)=-||j-k||2=-ψ2j、k。(7)
式(7)数据集相似度取值的计算一定程度上反应数据点k成为数据点j相似点的概率。其中-ψj、k为数据点j、k的偏向参数。偏向参数取值大小对数据点中心聚类能力的影响较大,取值越大,则潜在类代表点越多;取值越小,则潜在类代表点越少。假设原始相似空间中所有数据点可作为类代表点的概率相同,在数据点相似度计算过程中,由于偏向参数取值选择,可能导致矩阵中类聚中心的类聚数目大范围波动。为避免以上原因造成网络信息库未知访问源判别失效,偏向参数的取值通常为二维空间内的矩阵相似度中值,进而达到中等聚类中心个数的稳定生成。
二维空间内响应度信息与可用度信息的更新迭代,可实现聚类结果中聚类数据点个数的判断,进而实现基于IMAP积累结果的信息库未知访问源判别,因此数据节点响应度信息与可用度信息在IMAP运算中具有重要意义。
设数据响应度为s(j,k)的实际意义是:数据点j在考虑所有邻近聚类中心的选择适应度后,最终选择数据点k作为类聚中心支持对象,并对数据点k实施信息交互过程。可用度b(j,k)的实际意义是:确定数据点k为类聚中心后,接收到除数据点j以外的邻近数据点j’,是对数据点j支持信息的反馈过程。响应与可用度信息的更新获取过程,即全部数据点的类聚过程。
响应与可用度信息获取过程如下:
利用式(8)对二维空间的全部数据点展开遍历,分析各个节点之间的响应度与可用度信息交互关系,实现数据点的聚类,设聚类中心集合为L =[l b(j,k)+s(j,k)gt;0],则面临数据点j的聚类中心选择问题时,选择b(j,k)+s(j,k)取值最大的点作为j的聚类中心,实现矩阵内数据的聚类。
完成聚类操作后,将所有成功聚类的数据点视为信息库正常数据,若二维空间中存在不支持其他聚类中心,且不被其他数据点支持的离散性孤立数据点,则判定这些孤立数据点为未知访问源数据,需对其安全性进行检测。
2.2 安全预警模型
基于IMAP聚类法对降维后的数据做聚类处理,从而完成对数据的筛查,实现未知访问源信息的提取,从而实现安全预警,提高安全监测的准确性。将未知访问源数据集输入到支持向量机中,利用支持向量机学习法中的时间窗口,对未知访问源数据的安全状态进行分析及预警。利用支持向量机对输入数据集进行分析后,得到数据动态分布特征量U。设i时刻未知访问源数据在支持向量机内分布情况为Ui,支持向量机内数据稳定分布条件为Si。结合时间窗口与信息库动态预警函数E(M)对信息库展开预警需求分析,如下:
利用式(15)对信息库安全预警模型展开参数优化后,有效提高信息库安全预警模型的收敛速度,优化模型预警能力。
3 实验与分析
为验证所提方法的有效性,在网络正常运行条件下,向信息库人为加入两组未知访问源数据,分别采用所提方法、文献[2-3]方法,对信息库未知访问源信息进行识别,其识别结果如图1所示。
由图1可看出,笔者方法对信息库的未知访问源数据检测结果与实际最相似,能准确识别出网络运行过程中的两组信息库未知访问源数据的入侵。因为笔者方法对信息库内数据进行二维坐标系投影映射后,可获取响应度信息与可用度信息,实现IMAP数据点聚类,并根据数据点聚类结果实现未知访问源信息的提取。因此相较文献[2-3]方法,笔者方法对信息库内未知访问源数据的检测更准确。
为验证笔者方法的未知访问源数据检测效率,在信息库安全存储前提下,加入一组未知访问源数据作为实验样本,分别采用笔者方法、文献[2-3]方法对未知访问源数据进行检测,并对比不同方法的检测耗时。具体耗时对比情况如图2所示。
由图2可看出,在未知访问源数据数量不断增加的前提下,笔者方法的检测耗时波动较为平稳,且检测耗时低于文献[2-3]方法。因为笔者方法利用主成分分析法,对高维原始数据进行了投影映射,在满足标准正交基条件下,引入协方差矩阵,实现了高维原始数据的降维处理,减少了后续未知访问源数据的检测耗时,提高了信息库安全检测及预警检测效率。
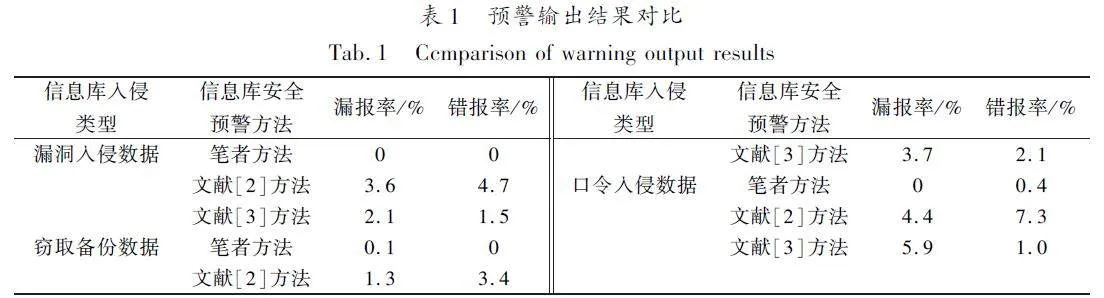
为验证笔者方法的准确性,选取网络平稳运行状态下的信息库正常操作记录1 000条,再人为加入2 000条信息库未知访问源数据,其中包括漏洞入侵数据、窃取备份数据和口令入侵数据各500条。分别采用笔者方法、文献[2-3]方法对上述3种类型信息库入侵操作数据进行预警,对比3种方法的信息库安全预警输出结果,如表1所示。
由表1可看出,笔者方法在面对不同类型的未知访问源信息入侵行为时,预警信息的漏报率、错报率皆低于文献[2-3]方法,因为笔者方法引入支持向量机学习中的时间窗口,将信息库安全预警模型的构建问题转化为支持向量机学习的凸优化问题,实现信息库安全预警模型的建立,为优化安全预警模型的收敛速度,构建信息库安全预警模型最优输出策略,并展开参数寻优,提高了模型整体预警输出能力。
4 结语
网络信息库安全检测及预警技术作为网络攻击的主要防御手段,能促进信息库未知访问源预警的快速响应,有效避免隐私信息的窃取。对信息库数据进行降维处理后,利用IMAP聚类法对信息库数据点进行聚类处理,通过数据聚类结果实现未知访问源数据点的提取:结合向量机学习中的时间窗口,对信息库数据动态分布情况进行分析,实现信息库安全预警模型的建立,并对模型收敛速度实施优化,实现信息库安全检测及预警,保护了信息库内隐私数据的安全。
(责任编辑:刘东亮)
基金项目:陕西省重点研发计划基金资助项目(2023 -YBCY-014)
猜你喜欢
现代商贸工业(2016年21期)2016-12-26 14:04:49
贵州财经大学学报(2016年6期)2016-12-19 19:23:44
经济研究导刊(2016年28期)2016-12-14 09:22:57
科技视界(2016年23期)2016-11-04 23:08:10
商(2016年29期)2016-10-29 13:39:08
现代经济信息(2016年19期)2016-10-20 15:34:24
商(2016年27期)2016-10-17 04:41:37
商(2016年26期)2016-08-10 14:11:18
商(2016年6期)2016-04-20 18:36:52
商(2016年6期)2016-04-20 10:19:35
