
大学初期学业表现与学生倾向性指标的相关性研究
——基于机器学习的预测及可解释性分析
2023-12-30 08:44梅盛旺赵慧芳万洪芳侯英杰
河北科技大学学报(社会科学版) 2023年4期
梅盛旺,赵慧芳,万洪芳,侯英杰
(1.江西农业大学南昌商学院 招生就业处,江西 九江 332020;2.江西农业大学 教务处,江西 南昌 330045)
一、引言
学生学业表现不仅影响着学生未来的职业发展[1](P350-366),而且也是评价教育质量和教师教学能力的重要指标[2](P5-8)。学者们通过问卷调查法、观察法、实验法等方法,对大学生学业表现影响因素进行了深入研究[3](P1460-1479)。通常将学业表现的影响因素分为两类指标[4](P5-15,44,79):一是倾向性指标(静态指标),即学生进入学习环境时自身已经带有的一些属性,如学生的个人特性[5](P1-16)、家庭背景[6](P189-214);二是行为表现指标(动态指标),即学生在学习过程中体现的动态指标,如学校因素[7](P1-8)、社会性活动或联系[8](P2117-2127)。在学习初期,倾向性指标对学业表现的预测能力往往要强于行为表现指标[9](P65-86)。
从已有的研究来看,影响学生学业表现的因素错综复杂,并且很难从单一的因素明确预测学生的学业表现。长期以来,教育学的研究大多基于小数据,以传统统计法为主,研究模式相对单一。绝大部分学业表现的相关研究数据是通过问卷调查和自我报告获取,样本数据量相对有限,并且传统的统计分析方法在揭示变量之间复杂关系的能力方面受到限制。当前随着机器学习方法在各领域广泛应用,在社会科学研究领域也受到广大学者的关注和应用[10](P1-8)。算法时代的到来,改变了教育学研究的范式,从以往的“设计式研究”转变成“全量式研究”。在评估影响学生学业表现因素方面,机器学习的优势明显,其更擅长处理大数据并提取传统方法可能遗漏的隐藏的内在联系,有利于重塑教育定量研究的取向和功能期望,助推教育定量研究乃至整个教育研究的范式实现突破[11](P35-44)。最近,支持向量机(SVM)、随机森林、深度神经网络(DNN)、XGBoost等监督机器学习方法已经开始解决教育学研究领域的分类和预测问题[12](P881-889),如大学生行为规律性等行为模式对学习成绩的影响[7](P1-8)、学生自杀率因素的预测模型建立[10](P1-8)等。
虽然机器学习模型在分析结果上表现很优异,但它的黑箱算法和模型内部运行机制(特别是深度模型、集成树模型等复杂模型)很难理解。而可解释的机器学习使机器学习系统的行为和预测更易理解。SHAP(Shapley Additive exPlanations)使用来自博弈论及其相关扩展的经典 Shapley value将最佳信用分配与局部解释联系起来,是一种基于游戏理论上最优的 Shapley value来解释个体预测的方法[13](P4768-4777)。
不同的家庭背景[14](P129-148)、个人特征[5](P1-16)、大学入学标准考试成绩[15](P74-80)、对教育的期望或专业满意度[16](P70-76)以及目标期望[17](P1-15) [18] (P121-160)对学生的学业表现都有着重要影响。而这些信息属于倾向性指标,并且能够从学生入学信息中提取出来,因此,本研究以学生倾向性指标信息为基础,利用机器学习算法(随机森林、XGBoost、朴素贝叶斯、逻辑回归)识别影响学生大学初期(大学一年级)学习成绩的重要因素,并建立模型来反映这些因素对不同学业表现学生的影响程度(如图1所示),以便于学校和教师能够提前关注学业成绩存在风险的学生。同时,基于SHAP方法分析模型的可解释性,以确保结果易于理解并在实践中应用。

图1 研究流程
二、 数据和方法
(一) 数据收集
研究数据为江西省一所地方院校2020年和2021年入学的共计4 273名学生的信息和数据,其中,2020年入学学生1 934名,2021年入学学生2 339名。依据学者们的相关研究和典型应用,选取关键倾向性指标(见表1),包括高考录取投档信息、在校表现、个人信息、家庭背景、录取期望、目标期望等。其中,特征变量说明见表2。所使用的学生数据均匿名,不涉及个人隐私。

表1 关键倾向性指标
1.个人信息、家庭背景信息及学生高考录取投档信息
一是个人信息,从该校招生录取系统中获取,包括性别、政治面貌、民族、地区、年龄等信息。二是家庭背景信息,通过问卷调查方式获取,包括独生子女、父母最高学历、家庭收入情况等信息。三是高考录取投档信息,包括投档分数、语文成绩、数学成绩、外语成绩、考生类别、录取志愿、考试科类、招生省份、录取院系、外语语种、考试类别、批次、科类、特长、获奖情况等信息。其中,高考成绩变量由于不同省份高考本科分数线不同,为公平地衡量学生高考成绩,本研究中采取分控比形式,即考生投档分数与生源省份当年本科省控线的比作为该生生源质量的赋分,以及语文、数学、外语成绩;考生类别,包括农村应届、农村往届、城市应届、城市往届4个类别;录取志愿,即学生被录取的专业是其报考专业志愿顺序数。
2.录取期望和目标期望信息
数据由对学生的问卷调查方式获取,本文使用录取到本专业意愿、录取到本学校意愿、对专业的满意度、对学校的满意度、毕业去向的初步想法等字段,并对这些字段进行特征化处理。
3.在校表现信息
包括大学一年级的GPA、参加比赛奖励分、操行表现分等。GPA越高,说明该学生在大学初期学业表现越好。参加比赛奖励分按照学校学生守则中的规定进行赋分,根据比赛级别和获奖等级情况进行累加赋分,代表学生的在校活动表现情况,分数越高说明学生在学校活动中表现越优秀;操行表现分是指在校操行表现、参加课外活动情况所得的分数,分数越高说明学生操行表现越好。
(二)方法
1.模型训练
利用机器学习算法对大学生学业表现进行分类预测。GPA数据作为分类标签,并做以下规定:分为3.0以下(低GPA 组)、3.0~3.5(中GPA 组)以及3.5以上(高GPA 组)三组,其中3.0以下为学业表现一般,3.0~3.5为学业表现良好,3.5以上为学业表现优秀。学生的GPA分布情况如图2所示,将近55%的学生属于学业表现一般,将近40%的学生属于学业表现良好,而将近5%的学生属于学业表现优秀。由于高GPA组的样本偏少,采取重复增加高GPA组数据至20%的方式,便于训练模型。
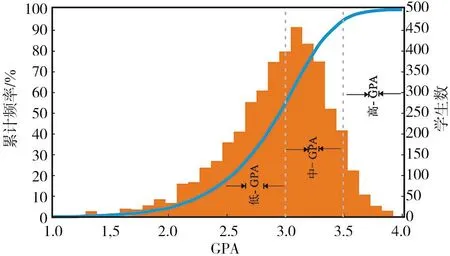
图2 GPA频率分布图
采用随机森林、XGBoost、朴素贝叶斯、逻辑回归等四类机器学习的算法,利用网格搜索验证法优化以上模型的参数配置。其中,利用机器学习工具Scikit-Learn随机分隔数据,将数据的80%作为训练集,20%作为测试集,分别对机器学习模型进行训练和验证评价。对缺失字段的数据样本进行删除。
分类模型在测试集上的性能用准确度、精确度、混淆矩阵、召回率、F1分数、Jaccard分数和海明损失等评价指标来衡量。
2.可解释SHAP模块
使用SHAP度量数据特征重要性并进行解释。①基于合作博弈中SHAP理论的归因分析方法, 计算机器学习模型中各因素的重要性估计值贡献g(x′)用式(1)表示,其中,x′为M个特征的简化输入,φ0为平均贡献值,φj为贡献特征j的Shapley值。当φ0为模型输出期望E(f(x))时,SHAP输出值与模型的真实输出值相接近[19](3386-3404)。
f(x)(i.e.φ0)=E(f(x))。
(1)
(三) 特征工程处理
1.独热编码
对于分类特征变量,特征值不连续,呈现出离散、无序状态,采取独热编码(One-Hot Encoding)进行处理。独热编码是将离散变量的特征取值扩展到欧式空间,将分类数据进行二进制化向量表示。本研究中对招生省份、录取院系、外语语种、性别、民族、考试类别代码、批次代码、科类代码、政治面貌、地区、特长代码、高中获奖代码等12个分类变量进行独热编码,共获得2 421个特征。
2.Lasso特征选择
Lasso是一种采用L1正则化的线性回归算法[20](P273-282),利用绝对系数函数作为惩罚函数,通过加入L1正则惩罚项来缩减变量的系数至0,从而达到特征选择的目的[21](P1-49)。通过Lasso变量选择,最终确定130个特征作为机器学习的变量。
三、结果分析与讨论
(一)部分特征工程描述
1.高考成绩
高考总成绩与GPA呈现两段式变化,第一段是分控比值≤1.04时,随着分控比值升高,GPA值呈上升趋势;第二段是分控比值>1.04时,随着分控比值升高,GPA值整体有下降趋势。分控比值主要是集中于1.03~1.05,而分控比值≤1.04的学生占比较大,为67.2%。
以5分为区间取得的语文、数学和外语成绩相应的GPA平均值(如图3所示),高考分控比(图3(a))、高考语文成绩(图3(b))、高考数学成绩(图3(c))和高考外语成绩(图3(d))与GPA的分布情况。高考语文(R2=0.22,Pearson=0.47)、数学(R2=0.57,Pearson=0.76)和外语(R2=0.63,Pearson=0.83)成绩拟合的曲线斜率为正值,对GPA表现都呈现出正向影响,其中外语成绩的影响最为明显,曲线斜率最大,拟合程度最好。
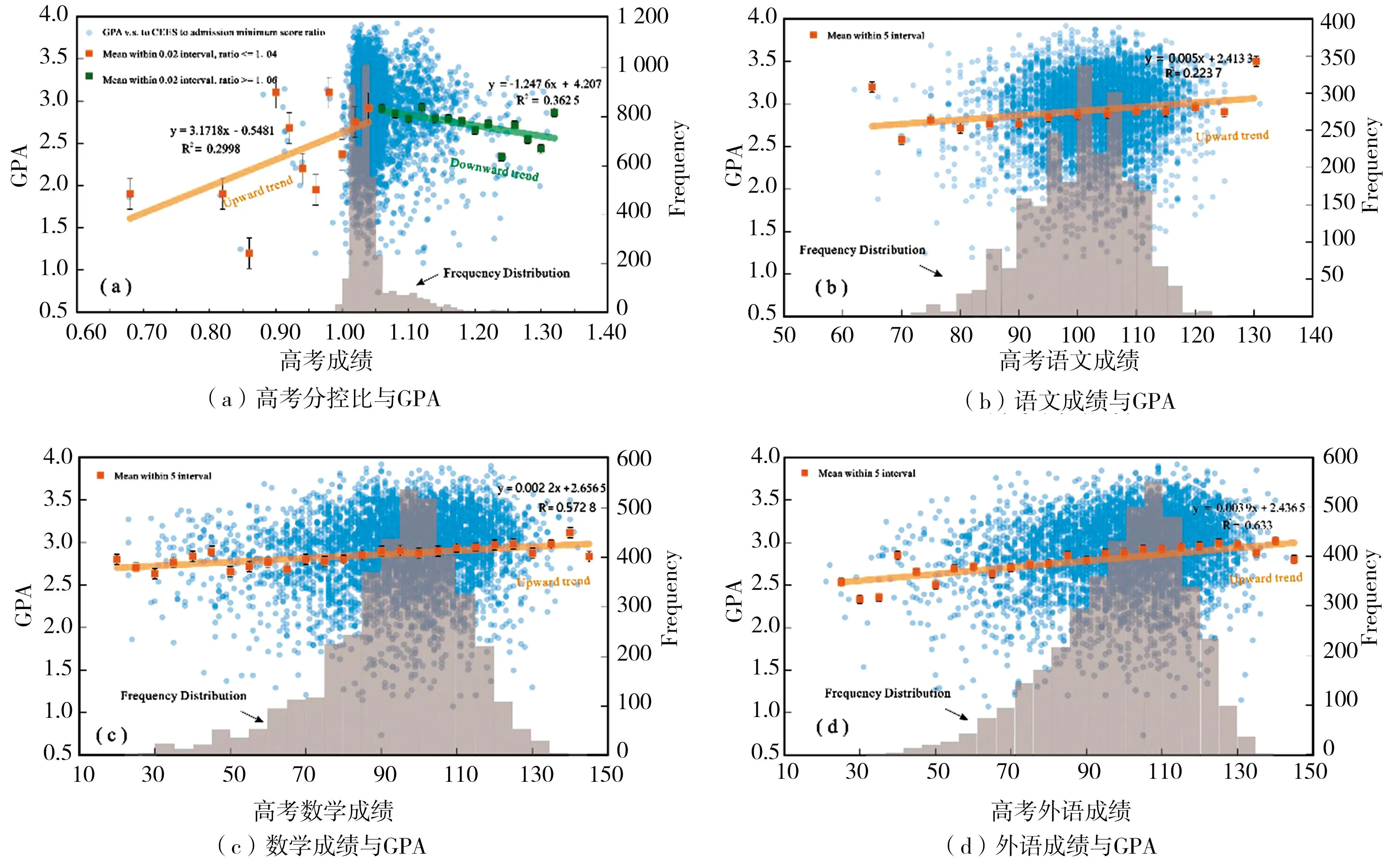
图3 高考成绩与GPA关系图
2.考生类别
将考生类别分为城镇应届、农村应届、城镇往届和农村往届4类,进一步分析4类学生的GPA分布情况。如图4所示,由农村应届—城镇应届—农村往届—城镇往届的GPA平均值和中值呈现出轻微依次递减的趋势,表明城乡应、往届类别与学业表现存在一定的联系。这与其他学者的研究结果一致,即城镇和农村学生的学业表现是存在差异的[22](P353-372)。
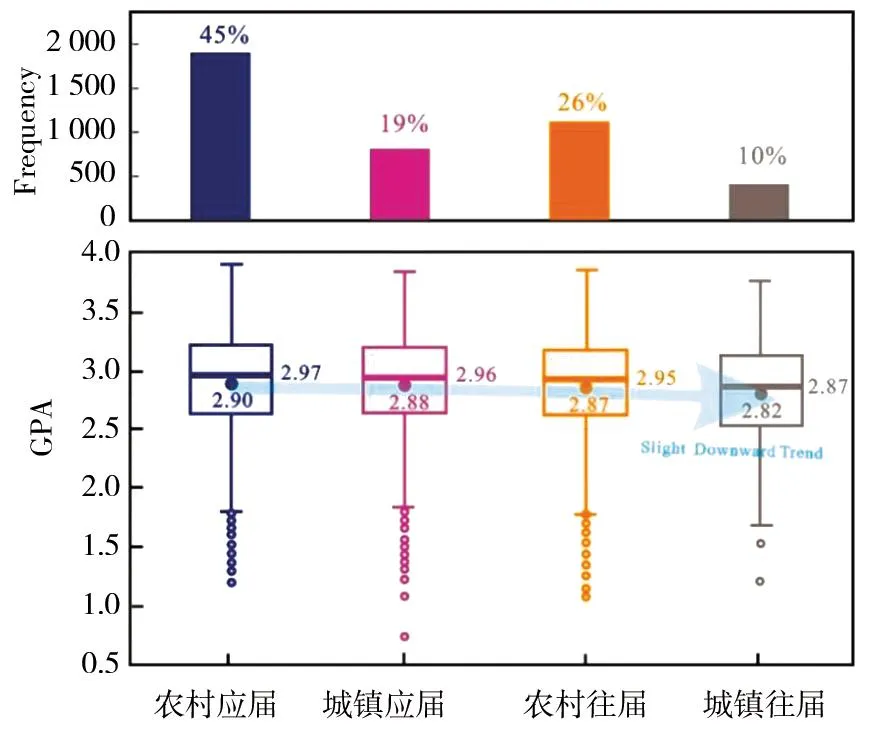
图4 不同考生类别的GPA箱型图
3.在校表现
奖励分数与GPA关系如图5、图6所示。操行奖励分数、比赛奖励分数与GPA呈线性关系。如热力图所示,操行奖励分<5分的学生密度较大,比赛奖励分<20分的学生密度较大。其中,比赛奖励分和GPA呈强烈的正相关性(R2=0.92),而操行奖励分和GPA的相关性相对较小(R2=0.59),说明学生在校的表现与学业表现是存在关系的。
4.目标期望
学生毕业的初步目标包括自主创业、目前还没想法或暂不考虑就业、自由职业、直接就业、参军入伍和继续升学等6个目标。据表3和图7显示,毕业去向目标与学生的学业表现存在一定的联系,其中想继续升学的学生的学业表现最优,明显要优于其他目标意愿的学生,而自主创业意愿的学生学业表现最差。
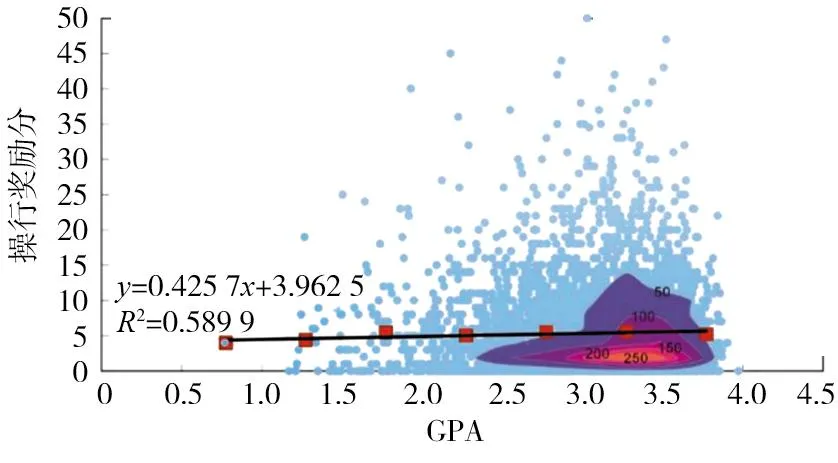
图5 操行奖励分与GPA热力图

图6 比赛奖励分与GPA热力图

表3 毕业目标期望分布情况

图7 毕业目标期望频率分布关系
(二)分类模型比较:模型效果的分析与比较
模型的测试集结果评价指标如表4、图8所示。模型评价的参数包括准确度、精度、召回率、F1分数、Jaccard score和Hamming loss。表4和图8是这四类机器学习模型的评价指标具体值,显然随机森林分类模型的各项评价指标相对最好,XGBoost、逻辑回归和朴素贝叶斯模型评价指标则相当,模型表现次于随机森林。随机森林的F1分数和Jaccard分数最高,Hamming loss最低,对本研究的分类预测和特征抽取具有重要意义。

表4 模型评价指标
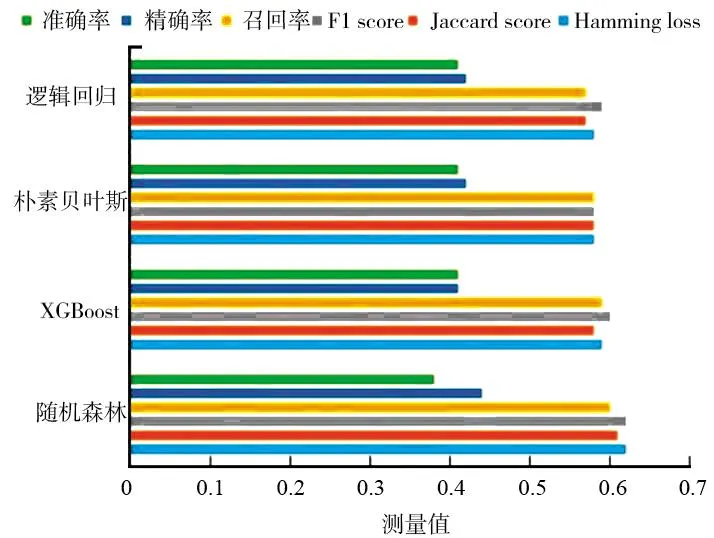
图8 模型评价指标柱状图
随机森林、XGBoost、朴素贝叶斯和逻辑回归4种算法模型的测试集混淆矩阵结果显示(如图9所示),高GPA组和低GPA组分类模型的预测效果相比中GPA组要更好,对三类学业表现组的分类效果排序:随机森林>XGBoost>朴素贝叶斯>逻辑回归。因此,随机森林算法模型对这三类学业表现组分类效果最佳。
(三) 模型结果解释:基于SHAP可解释性方法的学业表现重要特征因素评估
基于上述模型比较,选择最优模型,根据SHAP算法解释随机森林的重要特征,进一步讨论影响学业表现的因素,SHAP值越高的变量对模型的贡献越大。SHAP算法是一种方便的基于树的模型工具,可用于估计每个分类特征的相对重要性,即一个特征的SHAP值表示它通过减少损失来影响模型预测的程度[23](P1-22)。使用随机森林模型实现Tree Explainer来计算每个特性的SHAP值。在多类问题的特征重要性堆叠条形图(如图10所示)中,特征是根据其降序的平均SHAP值或重要性排序的。由图10可知,学生在校活动的表现情况以及高考数学成绩、外语成绩等入学成绩对学生大学初期学业表现的影响较为明显,录取的专业和系别以及学生对本专业的满意度也存在影响,性别、民族、生源省份、考生类别等学生个人信息对学生学业表现的预测结果有较为明显的影响。
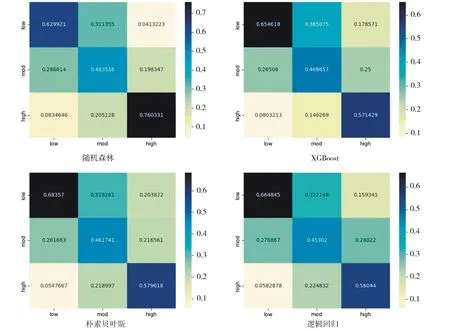
图9 模型混淆矩阵图
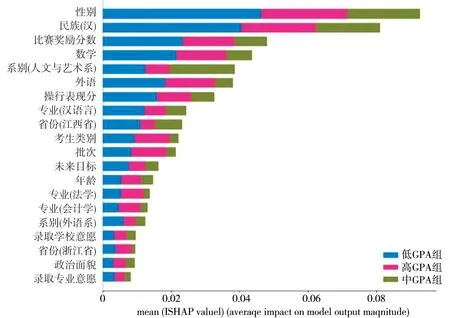
图10 特征绝对值排序图
使用SHAP算法计算测试集每一个样品对输出结果的影响,用以评估各特征对模型的贡献。SHAP概要图(如图11所示)中一个点代表一个特征,正SHAP值代表该特征对模型的影响是正向的,而负SHAP值代表该特征对模型的影响是负向的,其中蓝色表示该特征的贡献是负数,红色则表示该特征的贡献是正数。SHAP值依赖图(如图12所示)用以说明特征变量对模型预测结果的边际效应,能够反映出预测结果与特征之间呈现出的相关关系。
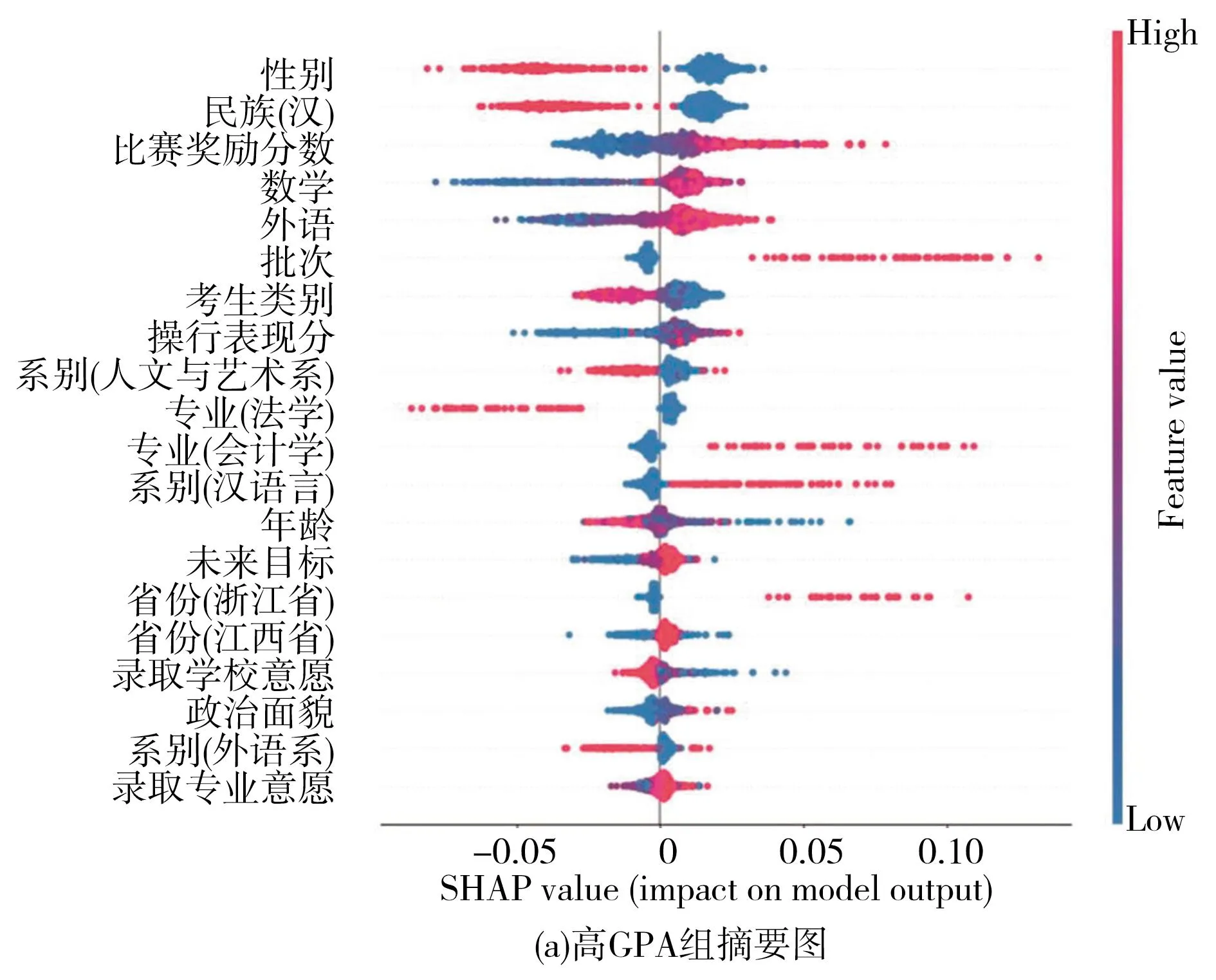
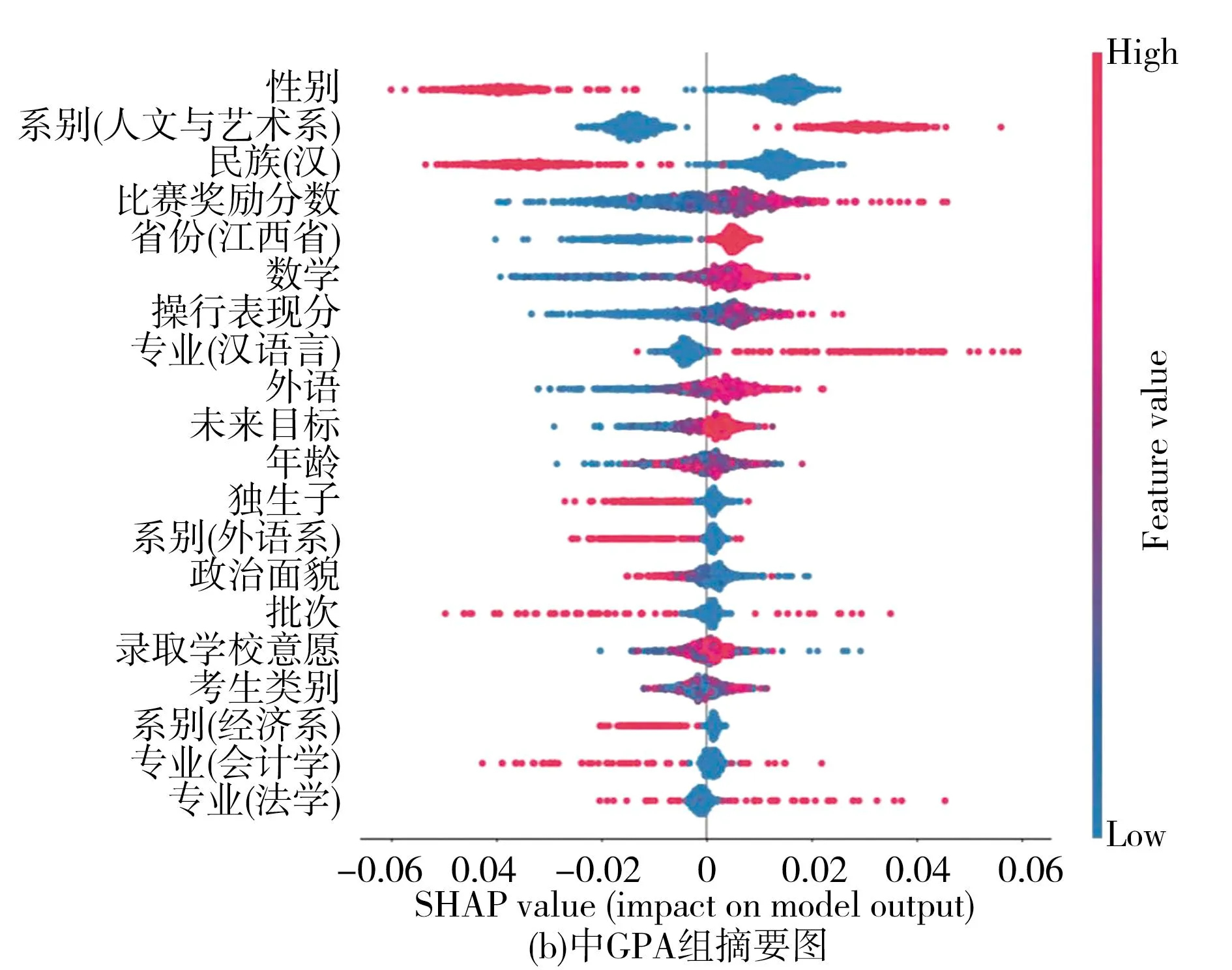
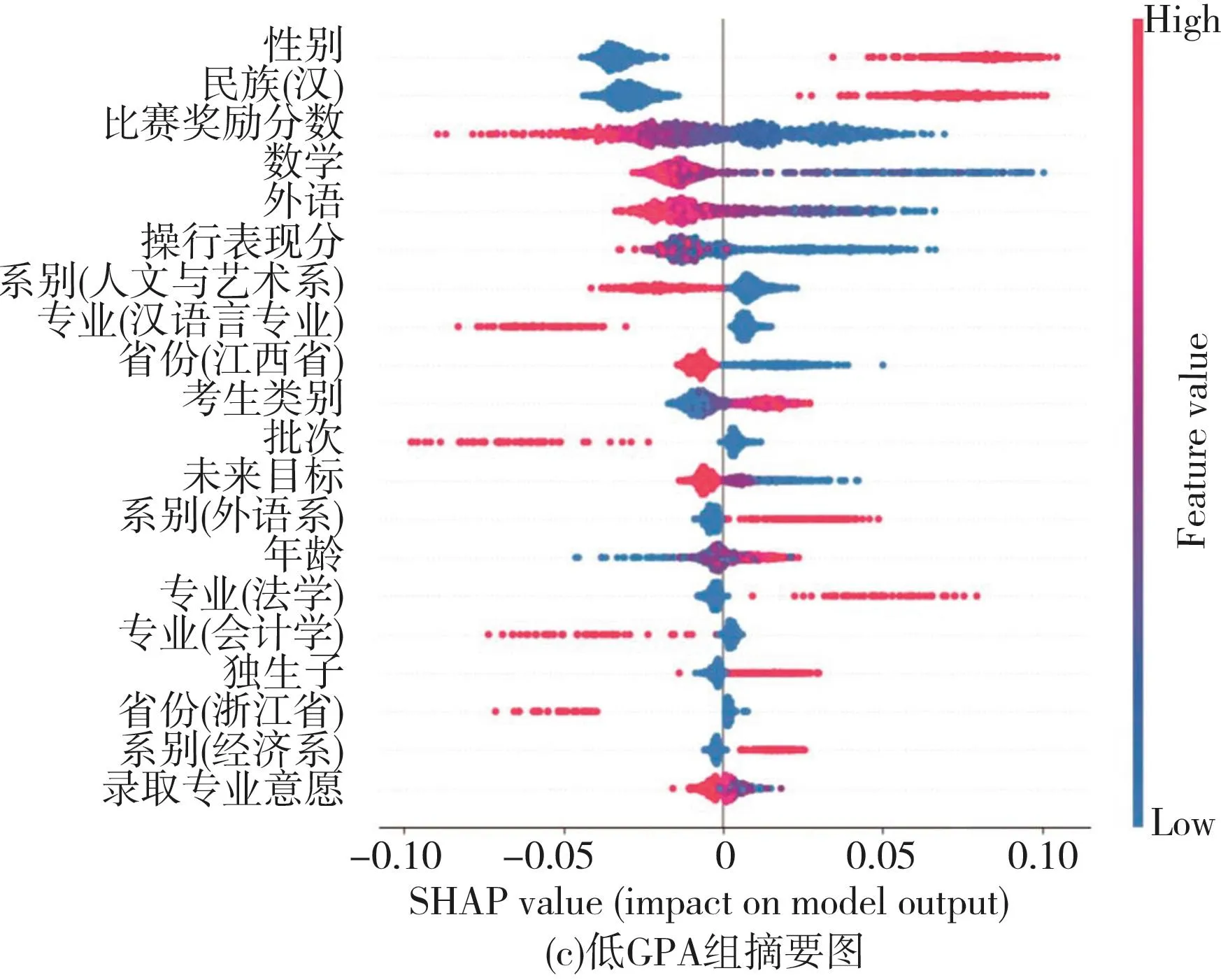
图11 高、中、低GPA组样本SHAP值分布图
1.高GPA组
在随机森林分类算法预测模型中,高考外语和数学成绩的红色数据点主要位于坐标轴右侧,其SHAP值为正值时对模型的正向影响明显。依赖图12(a)—12(f)中显示出与SHAP值正相关的特点,高考外语和数学成绩能够正向影响学生的学业表现,这与其他学者的研究结论一致[15](P74-80)。同时,选择专业的意愿和对未来毕业后的期望对学生的学业成绩具有正向影响(如图11(a)所示)。换而言之,在高GPA组中,学生对专业选择和未来规划有明确想法,其学业表现也相对更出色。此外,从图12(j)可以明显看出,考生类别与SHAP值呈负相关关系,表明在学业表现优秀的学生中,应届生的表现要好于往届生,农村学生要好于城市学生。比赛奖励分对模型具有重要影响。图12(c)中,比赛奖励分特征红色数据点主要位于坐标轴右侧,其SHAP值为正值时对模型的正向影响明显,图12(f)中也显示出比赛奖励分与SHAP值呈现正相关关系,这说明学生的比赛奖励分越高,其学业表现越好。操行表现分呈现出与比赛奖励分相同的特点,说明高GPA组学生参加比赛表现和在校操行表现越好对学业表现越有积极作用。

图12 变量与SHAP值依赖图
2.中GPA组
与高GPA组的影响特征相似,比赛奖励分、高考数学成绩特征对中GPA组模型的影响较大,而操行奖励分对模型的正向影响程度要低于比赛奖励分,但考生类别对中GPA组的学生影响不明显(如图11b所示)。
3.低GPA组
高考外语成绩、数学成绩、比赛奖励分和操行表现分对低GPA组呈负向影响。如图11(c)所示,高考外语成绩、数学成绩、比赛奖励分和操行表现分特征红色数据点主要位于坐标轴左侧;而特征蓝色数据点主要位于坐标轴右侧,说明特征值较小时,其SHAP值为正值,表明学生的高考外语成绩、数学成绩以及比赛奖励分数越低,其GPA值也可能表现出上升的趋势(图12(c)和图12(d))。依赖图(图12(i)-(j))中也显示出比赛奖励分与SHAP值呈现负相关关系,这意味着低GPA组学生的比赛奖励分数越高,其学业表现反而不好。录取专业的意愿、对未来毕业后的想法呈现出与比赛奖励分相似的特点,即蓝色数据点位于坐标轴右侧,红色点位于坐标轴左侧(如图11(c)所示)。实际上,低GPA组的学生往往目标不明确或者渴望自主创业,这一类学生学业上表现较为一般。图12(l)中,考生类别与SHAP值呈正相关关系,说明学业表现一般的学生组中,往届考生对模型的影响要大于应届考生。
四、结论与建议
(一)结论与研究局限
1.结论
本文利用机器学习模型对大学生初期学业表现的倾向性影响因素进行了探讨,基于SHAP方法解释了模型特征的贡献程度。通过上述的分析发现,影响大学生初期学业表现的倾向性指标特征是复杂的,不能单独用某个因素解释。总体而言,归结为以下四个方面。
第一,特征SHAP值反映了个体属性,如性别、民族、年龄、家庭结构等学生个人信息,对学生大学初期的学业表现有明显影响。以性别特征为例,学业表现呈现出性别差异,女生在大学初期学业表现要好于男生,这与梁耀明等[24](P55-59)的研究结论一致。男女生的生理和心理成长具有一定的规律性,他们在智力潜能、自觉意识觉醒过程方面存在差异,男生往往具备“后发优势”。而家庭背景因素,如城镇/农村生源性质(考生类别)、是否独生子女、父母学历以及家庭经济状况与学生学业表现情况也存在着一定关系。
第二,对于不同学业层次的学生,影响他们学业表现的因素是有区别的。总体上看,高考数学成绩、外语成绩、比赛奖励分、操行表现分的影响较大。高考成绩是初始知识技能指标,对之后的学习具有一定的延续影响。而学生的校园行为模式,如参加活动或比赛的积极性、在活动或比赛中的表现与学业表现是存在相关性的。但是这种相关性并不是简单的线性关系,在不同学业层次的学生中,学生的校园行为模式的影响是存在差异的。
第三,学生的个人期望对大学生初期学业表现影响相对突出。一方面,录取专业和系别是否符合学生的入学期望影响着大学初期学生的学业表现,通常录取专业符合学生期望,则正向促进学业成就;另一方面,具有明确毕业目标期望的学生学业表现往往较好,学生通过追求学习目标,持续获得驱动学业成就的动力,对学业表现有正向影响。
第四,相较于高、中、低GPA组的学生存在更大的学习困难风险,其影响特征具有一定的可识别性。低GPA组学生的高考数学、外语分数以及在校活动表现相对较差,并且城镇学生比农村学生具有更大的学业风险,部分学生目标定位不明晰、自我认知不足。
此外,虽然高考总分数比值对模型结果有一定程度的影响,但由于该学院的高考录取分数相对集中,学生间高考总分的分差小,呈现扁平化特点,因此在本模型中高考总分对预测结果的贡献程度有限。而对专业和学校的录取意愿、对未来毕业后的想法、考生类别等因素对模型的影响则相对明显。
2.研究的局限性
本研究的局限性主要有两点:第一,本研究仅是观察了一所地方院校的学生,数据涵盖面不够广,不能够很好地建立系统的、具有很强代表性的模型。第二,本研究所采用的数据变量存在一定局限性,当前中国不同层次高校的生源结构已经呈现较为明显的差异分化特点。本文的研究对象是地方院校的学生,实际上地方院校的生源结构已经固化,如家庭背景因素,在这所院校中父辈的教育程度90%为高中及以下学历,机器学习模型难以训练并评估父辈教育程度对学业表现分类的重要性。
(二)建议
1.构建学业预警机制,引入有效预测指标
学业预警机制对降低学生学业风险有重要作用。干预措施不能仅限于事后,应提前关注和介入,筛查出潜在的“学困”学生。倾向性指标,如性别、年龄、民族、家庭背景、高中学业成绩等对学生的初期学业表现有较为显著影响。此外,学生的行为表现、生活和学习的规律性、自律程度、日常出勤率等数据指标都能预测出学生的学业表现。对于刚步入大学的一年级新生,以学生的高考成绩作为一项观测指标,可对新生的专业兴趣和未来目标等进行调研。通过综合预警指标,建立学生学业预警机制,及时干预学业表现相对较弱的学生。
2.建立学业帮扶模式,提前关注学业预警学生
对学业表现可能存在危机的学生重点进行引导,建立学业帮扶模式。以专业课老师和辅导员为主体,激发学生的学习动力,帮助剖析造成学生学业困难的原因,遏制学生学业继续恶化的情况[25](P43-50)。一方面,积极的求职或求学目标对学业有着正向的影响,因此可以通过引导学生树立积极的价值观、学业观和就业观,正向促进学生学业进步。另一方面,学生对专业的满意度和兴趣度也是影响学业成绩的一个重要因素,缺乏专业兴趣的学生往往很难取得良好的学业成绩。创新专业课程教学方法,改革传统课程模式,培养学生学习兴趣,将案例分析、小组讨论、游戏活动等方式引入课堂。改革和创新教学方式方法,增强学生对专业学习的兴趣,帮助学生提升自我效能感,改善预警学生的“学困”程度。
3.加强学生心理引导,融通“校师家”育人
在学业表现变化过程中存在边缘化轨迹:心理变化—结构边缘—心理边缘[26](P112-119),一旦不良学业表现结果形成,学生的消极应对行为将使学业成绩陷入恶性循环。从学校角度,应建立学业预警机制,设置学生心理疏导中心、学业帮扶工作室;从教师角度,应提前介入学业预警学生的学习生活,着重关注学业表现存在困难的学生,倾听学生的声音,从心理上正向引导;从家长角度,应主动与学校沟通,适当参与并引导子女的学习方式、帮助他们建立积极的学业观。学校、教师、家长三方共同育人,协同促进学生学业进步,改善“学困”学生的不良状况。
注 释:
①本文使用的机器学习模型训练过程和SHAP方法都是利用Python语言编写。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
红蜻蜓·高年级(2022年6期)2022-06-16
疯狂英语·新悦读(2019年12期)2020-01-06
中学语文(2019年34期)2019-12-27
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
数学小灵通·3-4年级(2017年9期)2017-10-13
集美大学学报(自然科学版)(2015年1期)2015-02-28
