
基于随机森林算法的CPTu土类识别模型研究及其在不同区域的应用
2023-12-29 01:53伍圣超王睿张建民
中南大学学报(自然科学版) 2023年11期
伍圣超 ,王睿 ,张建民
(1. 清华大学 水沙科学与水利水电工程国家重点试验室,北京,100084;2. 城市轨道交通绿色与安全建造技术国家工程试验室,北京,100084;3. 清华大学 土木水利学院,北京,100084)
CPTu 具有测试快捷、成本低、可靠性高以及测试数据沿深度连续的特点,在岩土工程勘察中得到了广泛应用[1-3]。CPTu 无法获取土样,因此,不能采用传统基于颗粒级配、塑性指数、液限的规范方法判别土类,但CPTu 在工程中应用广泛。已有研究提出一些利用CPTu数据来识别土类的方法,如:利用CPTu测试物理量组成二维图表,以图表不同区域代表不同土类。工程中常用的有ROBERTSON[2,4-5]提出的土类指数分类图、SBT分类图、SBTn 分类图以及ESLAMI 等[6]提出的双对数模型分类图等。这类图表法的缺点是其均基于土的力学行为分类,与基于土的物理特性的分类标准(如美国统一土质分类标准和中国国家标准《岩土工程勘察规范》分类标准)缺乏一致性,无法直接对应土的工程分类。同时,这些土分类图表法常用的归一化参数(归一化锥尖阻力(Qt)、归一化侧壁摩阻力(Fr)、归一化孔隙水压力(Bq))对于浅层土体常出现偏大的结果,造成浅层土体土类识别出现误差。一些学者提出了基于概率统计理论的土类识别方法[7-10],但这些方法多仍以SBT/SBTn图表法的框架为基础。蔡国军等[11]利用聚类分析方法实现了基于CPTu 的土层界面划分。刘松玉等[12]采用SBTn 图表法建立了基于CPTu 的中国实用土分类方法,其分类结果符合中国标准的土的工程分类结果。实际上,土的工程分类和CPTu测试物理量之间的映射关系非常复杂,二维图表无法充分反映这种映射关系,且无法充分利用CPTu数据的所有信息。机器学习方法适合解决这类复杂映射关系问题,且适用于多维输入,能够充分挖掘CPTu数据中关于土类的信息。应用机器学习的方法解决岩土工程中的复杂映射关系问题受到了普遍的关注,如基于CPTu 预测黏性土应力历史[13]、液化判别[14-15]、建立黏性土不排水抗剪强度预测模型[16-17]等。但目前对于基于CPTu 的土分类问题,缺乏基于全球多地区数据库的有效机器学习模型。
针对已有研究中的不足,本文作者基于3个地区(新西兰、奥地利、德国)的“CPTu+钻孔”数据库,建立一个具有良好泛化性能的土类识别机器学习模型,探讨多地区广泛适用的土类识别模型的可行性。该模型采用CPTu数据的统计特征作为输入,使得模型拥有良好的泛化性能;以基于USCS 标准对标土的工程分类为模型输出。同时,为了选择最优算法,研究对比随机森林(RF)、支持向量机(SVM)、BP 神经网络(BPANN)和最近邻(KNN) 4种机器学习算法对本问题的适用性;将建立的模型与工程中广泛采用的SBTn图表法性能进行对比,以阐明新方法的优越性,并通过4个工程实例论证该模型应用于工程实践的有效性。
1 “CPTu+钻孔”数据库
1.1 新西兰岩土工程数据库(NZGD)
通过数据预处理[19],将CPTu 数据拆分成若干0.3 m 长、无数据突变、土类相同的数据段,单个数据段作为土类识别模型的一个样本。数据预处理的作用如下:1) 删除土层界面附近的CPTu 数据,消除界面附近的噪声数据对模型训练的影响;2) 消除数据突变(如CPTu 测试过程中碰到石块、贝壳等)对模型训练的影响;3) 单个CPTu 数据段可包含16~31个数据,因此,可采用这些数据的统计值作为土类识别模型的输入,以提取更多特征训练模型,增强模型性能。训练集、验证集(基督城)、验证集(北岛)中样本数量如表1所示,共包含砾石(GW、GP)、砂土(SW、SP)、粉质砂土(SM)、粉土(ML、MH) 4种土类。

表1 NZGD数据库中训练集和验证集样本数量Table 1 Number of samples for training and validation sets in NZGD
1.2 “ 奥地利+ 德国”数据库(Premstaller Geotechnik Database)
Premstaller Geotechnik 数据库由OBERHOLLENZER 等[20]建立,包含由Premstaller Geotechnik ZT GmbH 公司在奥地利和德国开展的静力触探测试结果(CPT、CPTu、SCPT、SCPTu)和钻孔测试结果。采用EN ISO 14688-1[21]对钻孔中土进行分类。该数据库中,将测点距离在50 m 以内的“CPTu+钻孔”作为1对数据,并认为其具有相同的土层剖面,共有46对“CPTu+钻孔”测点。采用与NZGD 数据库相同的数据预处理方法提取各类土的样本,样本数量如表2所示。该数据库包含砾石(Gr, sa, si→Gr, co)、砂土(Sa, si→Sa, gr, si)、粉土(Si, sa, cl→Si, sa, gr)、黏土(Cl, Si, fsa→Cl, gr)4 种土类。由于NZGD 数据库中缺乏黏土样本,Premstaller Geotechnik 数据库能够成为NZGD 数据库的有效补充。

表2 Premstaller Geotechnik数据库中训练集和验证集样本数量Table 2 Number of samples for training and validation sets in Premstaller Geotechnik database
NZGD 数据库和Premstaller Geotechnik 数据库分别采用USCS和EN ISO 14688-1土分类标准,这2种标准存在一定的差别。例如:对于砂土颗粒和粉土颗粒的界限,EN ISO 14688-1 标准为63 μm,USCS 标准为75 μm;对于砾石颗粒和砂土颗粒的界限,EN ISO 14688-1 标准为2 mm,USCS 标准为4.75 mm。EN ISO 14688-1 标准中,fSa(fine sand,细砂)的粒径范围是63~200 μm,但此部分fSa 在USCS 标准中会被归类为粉土;EN ISO 14688-1 标准中fGr(fine gravel,细砾)的粒径范围是2~6.3 mm,但此部分fGr在USCS标准中会被归类为砂土。为了使得Premstaller Geotechnik数据库和NZGD数据库能够合并使用,需要对Premstaller Geotechnik数据库中样本进行处理,因此,本研究删除了Premstaller Geotechnik数据库中以fSa和fGr为主要成分的土类样本,以实现两个数据库的统一。
2 机器学习土类识别模型
2.1 模型建立
建立机器学习模型需要考虑输入选择、输出选择、学习器选择、参数优化等问题。本研究将一段CPTu 数据(包含16~31 个数据点)的统计值作为模型输入,同时在模型输入中增加了相应深度处的竖向应力和静水压力。因此,模型共有8个输入特征,分别为修正后锥尖阻力qt的平均值、摩阻比Rf的平均值、孔隙水压力σv0的平均值、初始竖向应力u0的平均值、初始孔隙水压力的平均值、归一化锥尖阻力Qtn的邻近偏差、归一化侧壁摩阻力Fr的邻近偏差、归一化孔隙水压力Bq的邻近偏差s*。其中,邻近偏差的定义为:
其中:xi为CPTu 数据段中第i个数据点(Qtn、Fr或Bq);n为CPTu 数据段中数据点总数。邻近偏差表示CPTu数据段中数据的离散程度,是与土类相关的重要数据特征参数。
该土类识别模型共有4 个输出:砾石、砂土、粉土、黏土。SM根据细粒含量可划分为砂土或粉土,该细粒含量阈值为37%[19]。采用总体精确度(ra)、单类土精确度(rs)和Kappa 系数(κ) 3 个指标来衡量模型性能。其中,κ用来衡量真实值和模型预测值之间的一致性程度,其取值范围为-1~1;ra、rs和κ越大表示模型性能越好,同时,κ是评估模型对不平衡分类问题性能的指标。ra、rs和κ的定义见式(2)~(4)。
其中:ni为某一土类(砾石、砂土或粉土)分类正确的数量;Ni为相应土类的样本总数;Po和Pe分别为观测结果和预测结果的一致性概率。
达沙替尼和伊马替尼的不良反应信号检测研究…………………………………………………… 吴邦华等(20):2840
2.2 不同机器学习方法性能对比
随机森林(RF)模型是若干决策树学习器的集合,该集合中的每个决策树学习器均可估计一个分类,而随机森林综合每个决策树的分类决定最终的分类结果,随机森林通过样本选择和特征选择提高模型预测性能。支持向量机(SVM)基于训练集在样本空间中找到一个划分超平面,将不同类别的样本区分开,当超平面距离最近数据样本的间隔越大时,分类的鲁棒性越好。BP 神经网络(BPANN)关键在于学习大量数据样本中隐藏的输入-输出模式映射关系,学习规则采用最速下降法,通过反向传播来不断调整网络的权值和阈值。最近邻(KNN)原理是根据预测样本与训练样本的距离排序,并选取k个距离最近的训练样本,根据这些样本分类判断最终分类结果。
本文通过对比RF、SVM、BPANN 和KNN 这4种机器学习算法,以选择最适用于本研究问题的算法。模型训练采用K折交叉验证(K=5),采用贝叶斯算法优化模型参数,4 种算法分别训练的4 个土类识别模型优化后的参数见表3,各模型在训练集、验证集(基督城)、验证集(北岛)、验证集(Premstaller Geotechnik)上的性能分别如表4~7 所示。可见:根据ra、rs和κ这3 个指标,RF 方法具有最优的性能,其次是BPANN、KNN、SVM。对于训练集、验证集(基督城)、验证集(北岛)、验证集(Premstaller Geotechnik),RF 的κ分别为0.98(接近KNN 的1.00)、0.84、0.67、0.72,在4 个模型中分别排名第1、第1、第3、第1。虽然对于验证集(北岛),RF 的κ(0.67)比SVM(κ=0.81)和BPANN(κ=0.78)的低,但观察rs指标可以发现,3个模型针对每类土的预测精度差别较小。
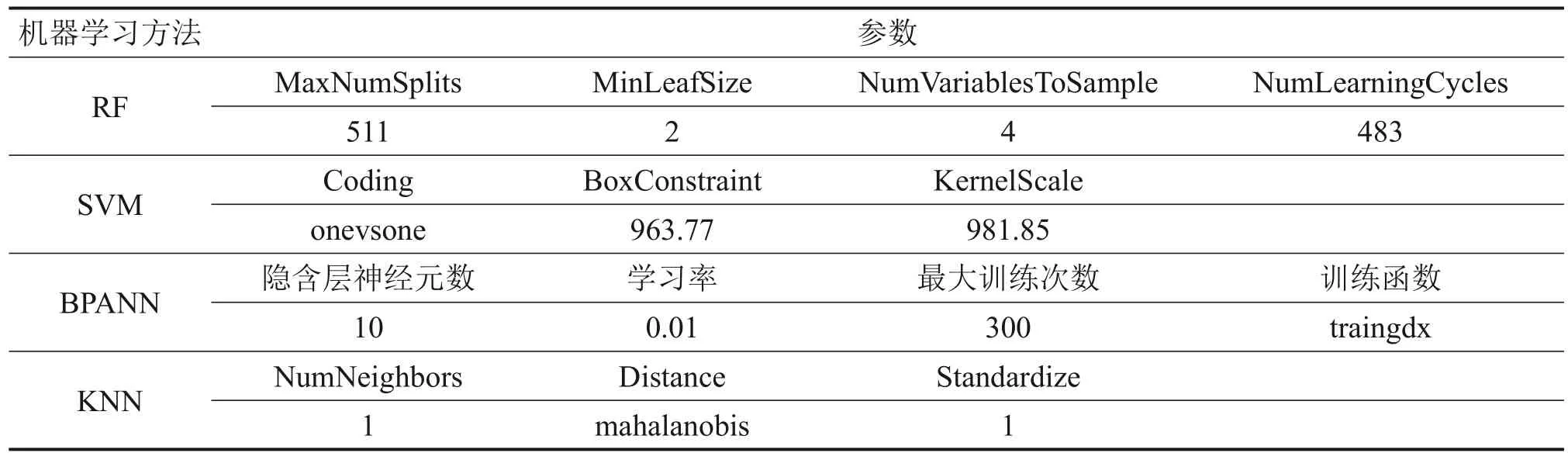
表3 4个土类识别机器学习模型优化后的参数Table 3 Optimized parameters of four kinds of machine learning soil classification models
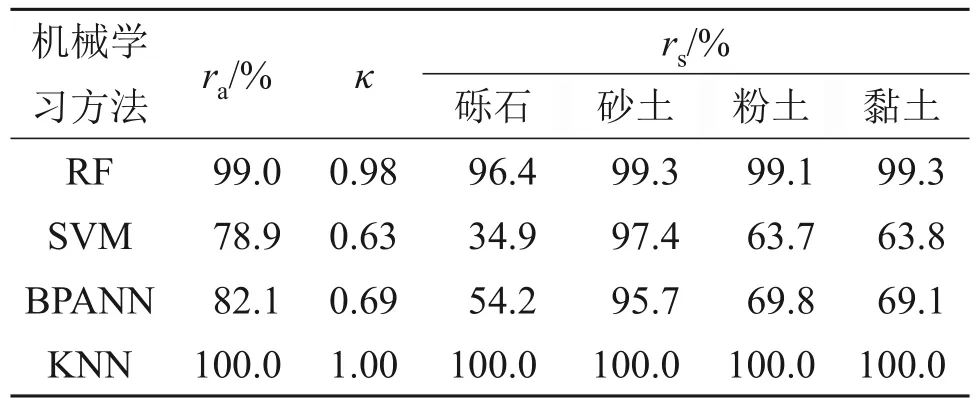
表4 4种机器学习方法性能对比(训练集)Table 4 Performance comparison of four kinds of machine learning methods(training set)

表5 4种机器学习方法性能对比(验证集(基督城))Table 5 Performance comparison of four kinds of machine learning methods(validation set(Christchurch))

表6 4种机器学习方法性能对比(验证集(北岛))Table 6 Performance comparison of four kinds of machine learning methods(validation set(North Island))

表7 4种机器学习方法性能对比(验证集(Premstaller Geotechnik))Table 7 Performance comparison of four kinds of machine learning methods(validation set(Premstaller Geotechnik))
本研究中数据集属于典型的不平衡数据集,砂土样本数量是黏土的5~6倍、粉土的2倍、砾石的5~6倍。训练数据的不均衡会导致对于各类土的预测精度不均衡,而选择合适的算法以适应该不平衡数据集至关重要。对比上述4 种算法可以发现:RF 对于4 种土类的识别效果较为均衡,其次是KNN和BPANN,SVM的识别效果非常不均衡。因此,RF 适用于本研究中的不平衡分类问题,而SVM则不适用。本研究最终采用RF作为模型训练的学习器。RF 通过训练样本随机采样规则提高了算法针对不平衡数据集的适应性。
2.3 模型验证
采用RF训练土类识别模型,并采用验证集(基督城)、 验证集( 北岛)、 验证集(Premstaller Geotechnik)对其性能进行验证,模型训练和验证的结果以混淆矩阵的形式展示,见表8~11。
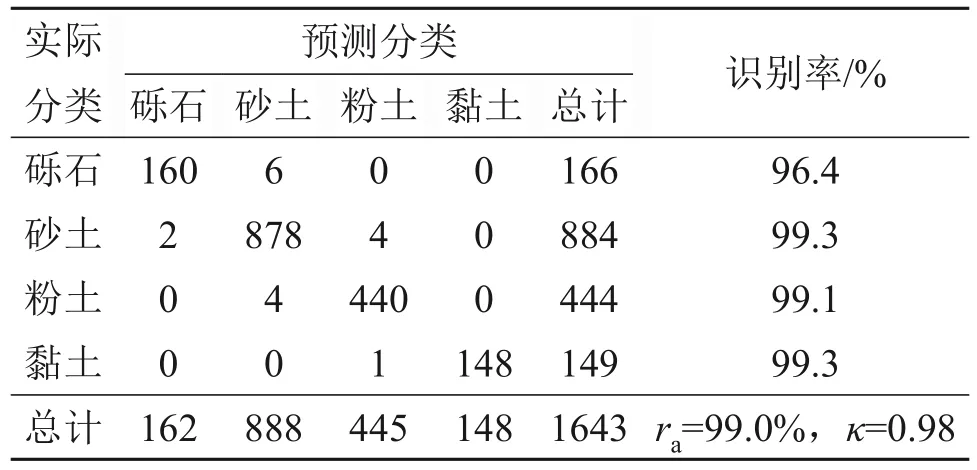
表8 土类识别模型在训练集上的混淆矩阵Table 8 Confusion matrix of soil classification model on training set
从表8可见:土体识别模型对于4种土的识别率均达到了96%以上,κ为0.98。在验证集(基督城)上,对砾石和砂土的识别率达到了95%左右,对粉土的识别率为85%,κ为0.84(表9)。在验证集(北岛)上,对砂土的识别率达到了89%左右,对粉土的识别率为80%,κ为0.67(表10)。在验证集(Premstaller Geotechnik)上,对砾石的识别率为78%,对砂土的识别率为75%,对粉土和黏土的识别率达到了85%左右,κ为0.72(表11)。说明模型在3个验证集上均取得满意的效果。

表9 土类识别模型在验证集(基督城)上的混淆矩阵Table 9 Confusion matrix of soil classification model on validation set(Christchurch)

表10 土类识别模型在验证集(北岛)上的混淆矩阵Table 10 Confusion matrix of soil classification model on validation set(North Island)
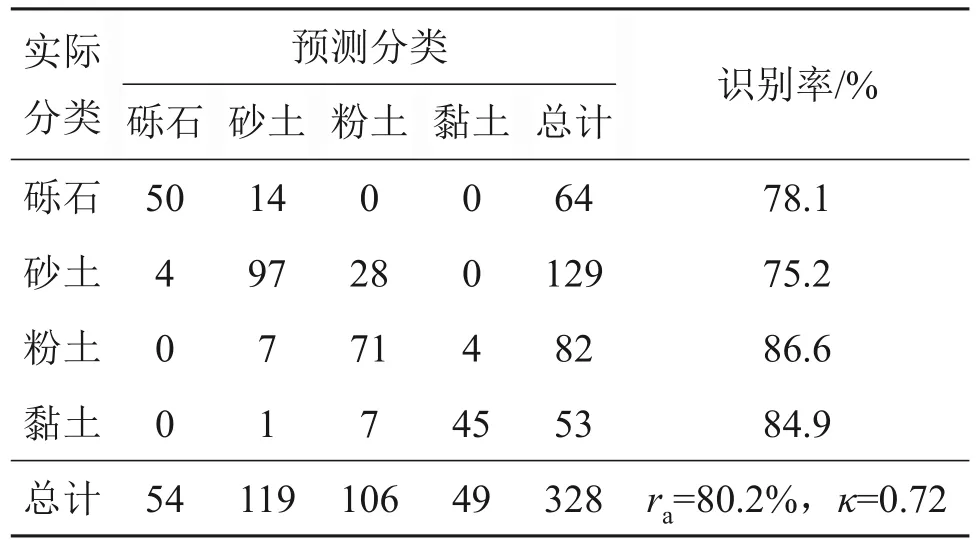
表11 土类识别模型在验证集(Premstaller Geotechnik)上的混淆矩阵Table 11 Confusion matrix of soil classification model on validation set(Premstaller Geotechnik)
ROC曲线和AUC被用来进一步评估模型的性能。ROC曲线是在不同的阈值(某一类土的识别率)下,以纵坐标为真正率(如粉土识别为粉土的概率),以横坐标为对应的假正率(如非粉土识别为粉土的概率),对于单独某一类土绘制而成。综合ROC 曲线整体考虑了各类土的识别效果,是一个针对模型整体性能的评价指标。理论上,最优模型的ROC曲线是顶点在坐标(0,1)处的两段直线,而预测结果随机分布的模型,其ROC 曲线则为通过原点的1∶1 直线。AUC 是指ROC 曲线和坐标轴所包围的面积,是一个评价土类识别模型性能的量化指标,AUC越高,表明模型性能越好。
不同区域验证集数据的ROC 曲线和AUC 如图1所示。对于验证集(基督城),其各类土的ROC曲线和综合ROC 曲线接近最优模型的ROC 曲线,AUC 达到0.98 左右,如图1(a)所示,说明土类识别模型在验证集(基督城)上的性能表现优异。对于验证集(北岛),其各类土的ROC 曲线和综合ROC曲线仍与最优模型的ROC曲线较接近,AUC达到0.90左右,如图1(b)所示,土类识别模型在验证集(北岛)上的性能表现良好。验证集(Premstaller Geotechnik)数据来源于奥地利和德国,相比于验证集(北岛),各类土的ROC 曲线和综合ROC 曲线更接近最优模型的ROC曲线,黏土和砾石的AUC在0.98 左右,粉土和砂土的AUC 为0.95 左右,综合ROC 曲线AUC 为0.96,如图1(c)所示,土类识别模型在验证集(Premstaller Geotechnik)上的性能表现同样优异。
3 同SBTn图表法对比
为了证明本文模型的优越性,将本文建立的土类识别模型与工程中应用最为广泛的SBTn图表法[5]进行对比。将SBTn 图表法和本文模型在3 个不同区域(基督城(新西兰)、北岛(新西兰)、奥地利+德国)的土类预测效果同时展示在Qtn-Fr图中,见图2~4。钻孔土分类结果在Qtn-Fr图中用不同的颜色表示,本文模型土类预测结果用不同的符号表示,因此,验证集中的每一个样本在Qtn-Fr图中表示为一个带有颜色的符号。若某一样本的所属颜色和符号指向同一土类,则说明本文模型预测正确,若符号指向其他土类,则模型错误预测为其他土类,例如,黄色上三角的样本代表砾石正确预测为砾石,黄色圆形样本代表砾石错误预测为砂土。SBTn 图表法的预测结果在Qtn-Fr图中用数字1~9代表的不同区域表示,样本点落在某区域则说明SBTn图表法将该样本预测为该区域数字代表的土类。

图2 机器学习土类识别模型和SBTn图表法对比(基督城)Fig. 2 Comparation between machine learning soil classification model and SBTn method(Christchurch)
从图2~4 可以发现,在验证数据所在地区(新西兰、奥地利、德国),本文建立的土类识别模型相对于SBTn图表法具有明显的优势。对于新西兰基督城地区(图2),本文模型对于砾石和粉土的识别率高于SBTn图表法,在SBTn图表法中有1/3的砾石样本落在了区域6(粉质砂土-砂土),而本文模型将其正确识别为砾石;有1/4的粉土样本落在了区域3、6、8、9(黏土-粉质黏土、粉质砂土-砂土、黏质砂土-极硬砂土、极硬细砂),而本文模型将这些被SBTn 图表法错分类的粉土样本正确识别。对于新西兰北岛地区(图3),本文模型对粉土的识别率相对于SBTn 图表法有明显提升,约1/3粉土样本在SBTn 图表中落在了区域3(黏土-粉质黏土),本文模型均将这些粉土样本正确识别;另有一些粉土样本落在了区域9(极硬细砂),本文模型亦成功识别。对于奥地利和德国(图4),本文模型同样较大地提升了砾石和粉土的识别率,另外,该地区砂土样本在SBTn图表中约一半落在了区域5(砂质粉土-粉质砂土),而本文模型将其直接识别为砂土,减少了土类识别的不确定性。
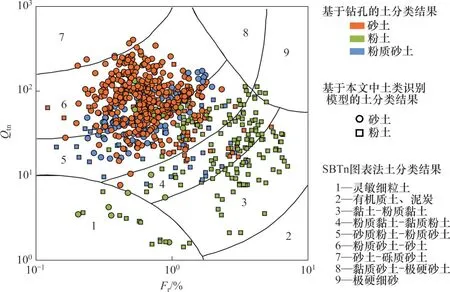
图3 机器学习土类识别模型和SBTn图表法对比(北岛)Fig. 3 Comparation between machine learning soil classification model and SBTn method(North Island)
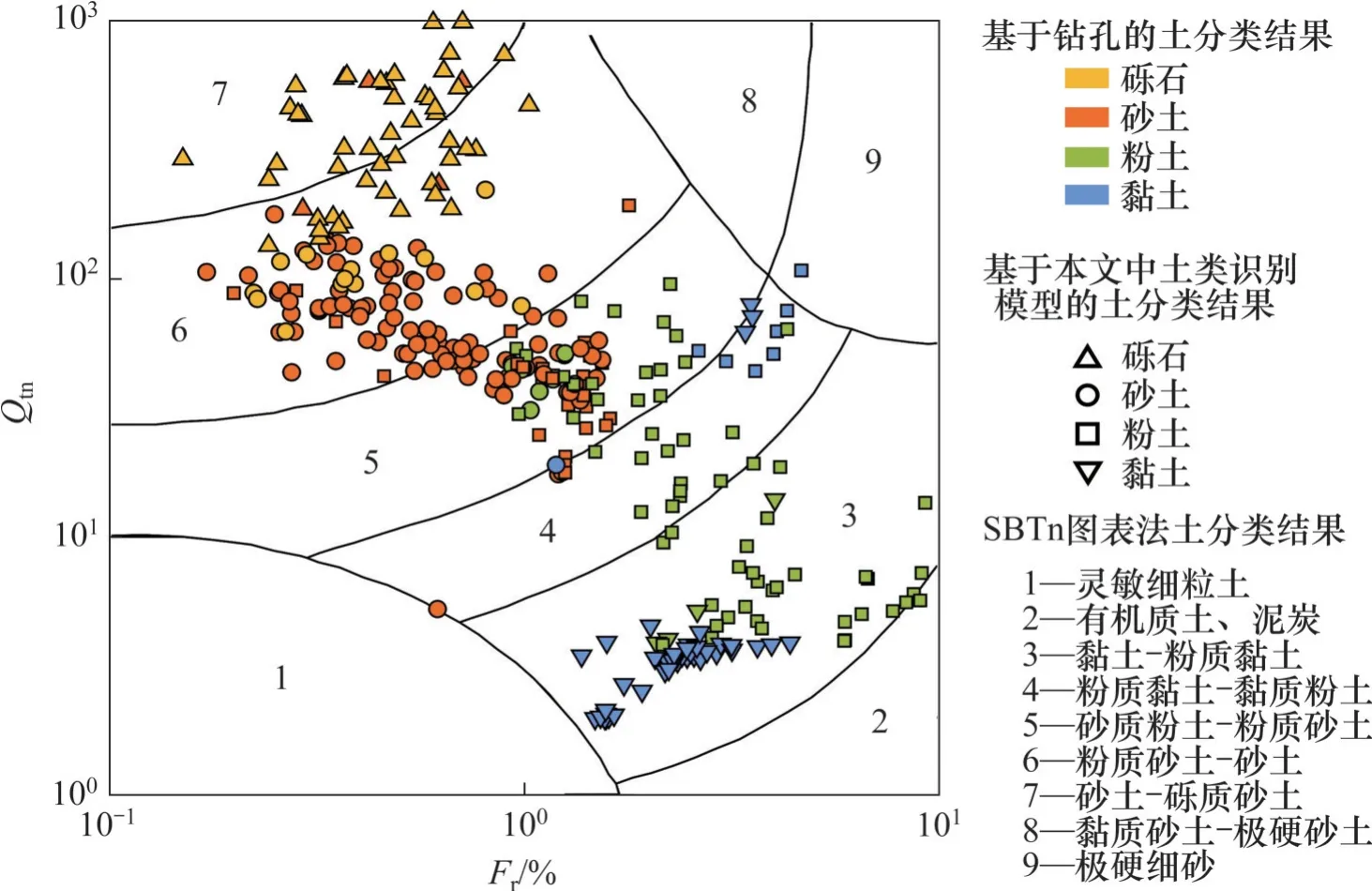
图4 机器学习土类识别模型和SBTn图表法对比(奥地利+德国)Fig. 4 Comparation between machine learning soil classification model and SBTn method(Austria & Germany)
4 工程应用
本文的土类识别模型是基于CPTu数据段的统计特征进行预测,因此,在实际应用于完整的CPTu 测试曲线时,需要提前确定土层界面位置以将CPTu 测试曲线划分成若干段,再基于各段CPTu 数据的统计特征预测土类。采用小波变换模极大值方法(WTMM)[22]确定土层界面。首先,通过WTMM方法确定土层数量和每层土的厚度,然后采用土类识别模型预测每层土的类别,最终重构CPTu测点处的土层分布。本文分别以新西兰和“奥地利+德国”区域实际工程中的CPTu 数据为例,阐述基于CPTu重构土层分布的应用流程,并以邻近的钻孔数据验证其效果。
4.1 新西兰
对新西兰地区2 个CPTu 测点(CPT_19118,CPT_6527,均为NZGD中测点代号)进行土层界面划分和土类识别,重构测点处的土层分布,并对比重构的土层分布和邻近钻孔中土层分布,以说明方法的实际效果。2 个CPTu 测点处的土层重构结果分别如图5和图6所示,可见重构土层分布与钻孔土层分布之间具有较好的一致性。
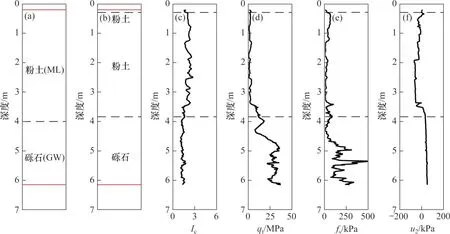
图5 CPT_19118的土层重构结果Fig. 5 Soil stratification results of CPTu log CPT_19118
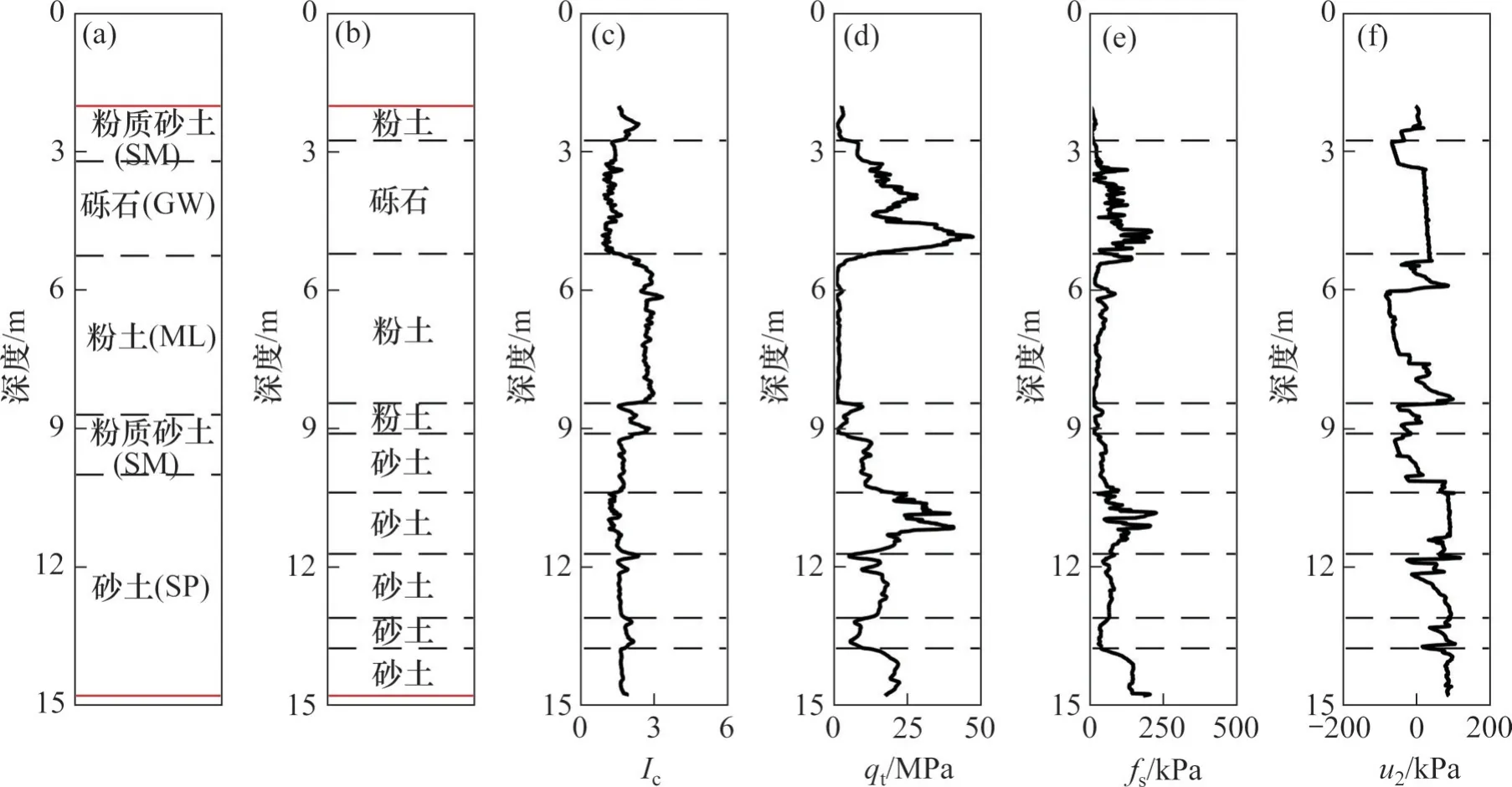
图6 CPT_6527的土层重构结果Fig. 6 Soil stratification result of CPTu log CPT_6527
以钻孔中土层分布作为真实值,以重构土层中与钻孔土层一致的土段长度占总长度的比例作为成功重构率,2 个CPTu 测点的成功重构率分别为97%和95%。对于测点CPT_19118(图5),土层界面识别误差小于0.3 m,上层粉土、下层砾石的土层结构被成功识别;对于测点CPT_6527(图6),虽然钻孔所得土层分布较为复杂,但本方法重构的土层分布与钻孔土层分布基本一致,粉质砂土(SM)被识别为粉土或砂土,因其属于过渡土类。
4.2 奥地利+德国
对“奥地利+德国”地区2个CPTu测点(CPTu_1172, CPTu_1143,均为Premstaller Geotechnik 数据库中测点代号)进行土层界面划分和土类识别,重构测点处的土层分布,并对比重构的土层分布和邻近钻孔中的土层分布。2 个CPTu 测点的土层重构结果分别如图7和图8所示,可见重构土层分布与钻孔土层分布之间良好的一致性。
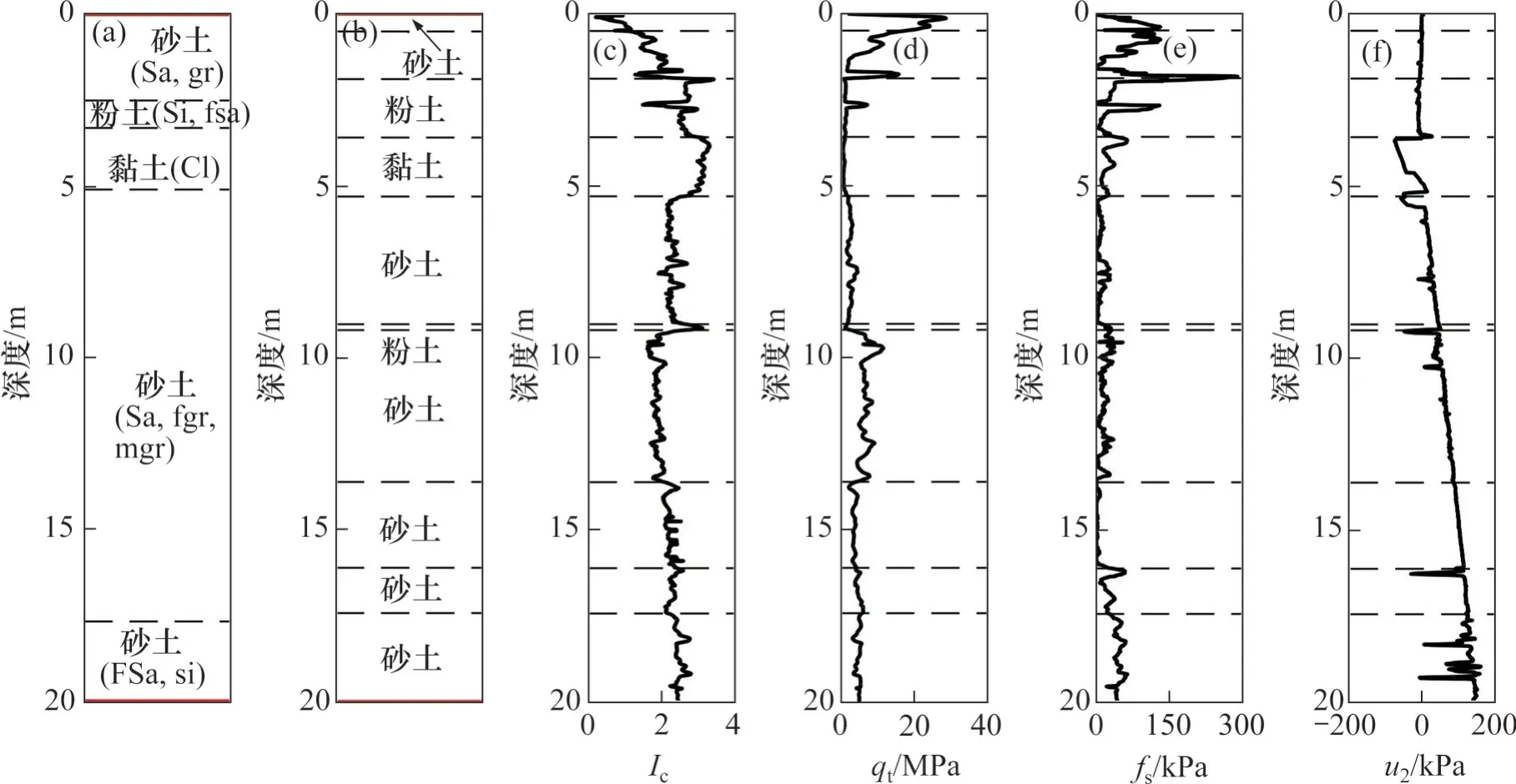
图7 CPTu_1172的土层重构结果Fig. 7 Soil stratification results of CPTu log CPTu_1172

图8 CPTu_1143的土层重构结果Fig. 8 Soil stratification results of CPTu log CPTu_1143
2 个CPTu 测点的成功重构率分别为93%和96%。对于测点CPTu_1172(图7),砂土、粉土、黏土互层的土层结构被成功识别,在9.0 m 深度处,观察CPTu数据可以发现,qt、fs曲线在该深度处发生了突变,说明在该处可能存在薄夹层。对于测点CPTu_1143(图8),砾石-砂土-粉土的土层结构被成功识别,界面位置的预测误差小于0.3 m,在3.3 m深度处,一个薄粉土层同样被识别。
5 结论
1) 在仅区分砾石、砂土、粉土、黏土四大类的情况下,利用随机森林算法的强非线性映射能力,可基于跨地区“CPTu+钻孔”数据库建立一个多地区适用的土类识别模型。
2) 基于随机森林算法的CPTu土类识别模型在新西兰、奥地利、德国具有良好的泛化性能。结合相应的土层界面确定方法,能够成功重构测点处的土层分布,重构土层分布与邻近钻孔中土层分布之间具有很好的一致性。
3) 基于随机森林算法的CPTu土类识别模型相比SBTn图表法具备显著优越的性能,尤其在砾石和粉土的预测方面优势明显。
4) 对于本文中的土类识别问题,相比于SVM、BPANN、KNN 算法,RF 算法具有最优良的性能。RF 对不平衡分类效果良好,对于各类土的识别效果较好,而SVM在不平衡分类问题上效果较差。
猜你喜欢
科学技术与工程(2022年17期)2022-07-28
建材发展导向(2022年10期)2022-07-28
水道港口(2021年3期)2021-08-24
黑龙江水利科技(2020年8期)2021-01-21
当代陕西(2020年24期)2020-02-01
当代陕西(2020年24期)2020-02-01
当代陕西(2020年24期)2020-02-01
陶瓷科学与艺术(2019年3期)2019-07-26
山西建筑(2016年25期)2016-09-29
中国铁道科学(2015年1期)2015-06-26
