
领域对抗自适应的短任务负载预测模型
2023-12-27 14:53刘春红王敬雄李为丽张俊娜
计算机工程与应用 2023年24期
刘春红,焦 洁,王敬雄,李为丽,张俊娜
1.河南师范大学 计算机与信息工程学院,河南 新乡 453007
2.智慧商务与物联网技术河南省工程实验室,河南 新乡 453007
云计算能为用户提供便捷的网络资源,计算服务以及相关应用。云平台通过按需分配的特性进行弹性资源管理[1]。资源数量的弹性伸缩取决于负载预测得到的需求量。对资源需求量的预测是云平台运行弹性管理性能的关键[2-3],也是提高云平台的资源利用率和服务质量决定性因素。因此,构建高效的云平台负载预测模型对实现资源的动态配置和共享使用有重要意义[4]。
大规模云平台中存在许多运行周期相对较短的任务,以谷歌云平台提供的监控日志数据为例进行研究,短任务负载序列作为一类特殊的批处理作业,其资源利用率较低[5]。短负载资源的快速调度和响应是整个集群系统迫切解决的问题之一。这类资源频繁的提交请求使调度系统随时都有新的调度问题亟待解决。由于系统混入的人为原因使得短任务数据中CPU的资源调度呈现出高度离散和不平滑的特性。故本文引入SSA 对数据进行降噪,消除负载的混沌性,利用信息性分量重建负载。短任务负载数据具有历史信息不充分,自身变化特性难以捕捉,周期性弱的特点,利用此类数据量不足的短小数据难以建立准确的预测模型[6]。
基于迁移学习的领域自适应回归预测方法能够有效地解决因数据不足带来的预测精度问题,且其在应用中具有出色的效果。如Hu 等[7]通过提出一种基于数据增强的领域自适应预测方法,以辅助目标域样本较少的情况下进行预测。Laptev等[8]定义一个迁移学习架构和用于时间序列预测的重构损失函数,并在不同领域证明了其方法的有效性。Mathelin等[9]提出了一种新的基于实例的迁移学习方法来处理监督领域自适应背景下的多种回归任务。Ragab等[10]提出一种具有对比损失的对抗性领域自适应架构,其在学习领域不变特征时能够考虑目标特定信息。He 等[11]提出两个多源传输学习的方法,有效地解决了序列过短时出现的单源迁移学习模型效果差的问题。以上研究表明基于迁移学习的领域自适应技术在少样本的回归领域都有应用,领域自适应技术与对抗学习的融合对于短序列的预测结果具有较强的互补效果,但其在云负载预测工作上的应用微乎其微。上述研究为本文引用领域自适应和对抗神经网络技术提供了一定的理论基础。
相似域的选取对于迁移学习来说能够使模型达到性能增益的效果。源域的选择能有效地过滤与目标域之间存在较大差异的负载。从而充分利用不同但相似的域进行有效的特征传递。本文使用时间特征对不同负载之间的全局信息进行最大化比较,同时利用MASS_V4定量计算负载间的相似性以实现快速有效的度量[12]。迁移学习中的领域自适应技术多用于图片、视觉等分类任务,在负载回归领域的应用极少,其不仅需要大量的训练数据,且易忽略不同域中的时间维度问题。本文通过对领域自适应对抗神经网络的框架及目标函数进行改进,采用纯监督的度量指标构造目标函数,使其适用于负载预测的回归任务。
综上所述,本文提出一种针对短负载序列的领域自适应域对抗模型(S-domain adversarial neural networks,S-DANN)。本文的工作包括以下三个方面的贡献:(1)为防止源域与目标域数据量差距过大而导致权重偏移,提出了一种利用域对抗迁移算法和生成域对抗网络的预测框架,联合三个深度网络以及梯度反转层构造模型,定义新的对抗损失函数,求出最佳样本权重,获得较高的预测精度。(2)针对云平台数据量大的问题,提出了一种快捷的筛选源域的方法,采用MASS_V4和时间特征进行度量以获取源域的负载序列集。(3)针对小样本负载高离散及不平滑的特性,提出利用SSA对目标样本集做平滑处理,与领域对抗迁移学习的方法相融合,为精准的负载预测提供了必要的样本特征优势。
1 相关工作
1.1 SSA
奇异谱分析是针对短而有噪声的混沌信号算法,通过对序列中的一般趋势、波动和噪声等成分进行分离,将最小特征值对应于非信息性分量,最大特征值对应于负载序列的总体趋势[13]。对观测到的负载序列构建轨迹矩阵,进而对其分解和重构,提取负载序列中的不同部分从而有效消除序列中的噪声,保留原始信号的特征。因此,SSA能够有效地将序列中的异常数据进行重构,增强负载数据的平稳性。
1.2 MASS_V4
MASS 是针对时间序列数据查询创建的一种距离分布度量算法,改进版本的MASS_V4[14]是在MASS 的基础上不断优化而产生的。MASS_V4 的实现速度快,它使用快速傅里叶变换实现半卷积,用于计算所有查询和窗口之间的滑动点积。MASS_V4没有因频域混叠而造成数值错误。同时,对样本进行分块便于计算处理,避免样本过长时出现卷积计算的数值误差。
与常用的动态时间规整算法DTW相比,MASS_V4的实现速度更快、计算成本相对较低、只需要很小的空间开销,能够更好地应对云平台中海量的负载数据。
1.3 领域对抗自适应
领域自适应是通过把不同分布域的数据映射到相同的特征空间中,使其在该空间中的距离尽可能地接近。将在源域中学习到的模型传递到具有不同特征分布的目标域中以执行相同的任务。在领域自适应的策略中,对抗式训练获得了大量关注。在训练过程中依据域之间的相似性对源实例进行重新加权,以避免数据分布不同时出现的模型飘移现象。
目前的工作旨在解决负载预测问题中协变量移位下的领域自适应现象。基于无监督的特征迁移方法易出现负迁移的挑战,基于实例的迁移方法具有较大的计算负担。而监督方法可以大大提高域适应的性能。综合上述原因在源分布和目标的不同分布之间选择监督度量:Y差异[15]。使用该差异距离作为分布之间散度的度量,能够获得更严格、信息更丰富的界限。在云负载预测领域,很少有研究试图解决不同领域之间的知识迁移问题。
2 预测模型
本文针对智能云资源管理中短任务负载的预测定义了一个新的架构。将建模和预测这两种功能分离为单独的组件,并联合优化它们。S-DANN在基于实例的迁移学习的基础上同时能够有效地挖掘负载之间的短时信息和长时依赖信息,更易于训练对抗网络模型。
该方法对应的具体流程图如图1所示:共包含以下三个重要步骤,首先,提取具体数据集中的目标数据和辅助数据,进行常规的数据预处理操作,包括空值填充、归一化和SSA去噪;其次是源域的获取,利用MASS_V4对数据集中预处理得到的负载序列进行相似性度量,再提取负载的时间特征进行比较以衡量序列之间的差异性,最大化目标域数据的输入空间和潜在空间之间的互信息;最后,通过三个深度网络门控循环单元(gated recurrent unit,GRU)的对抗框架构造差异损失函数,利用梯度反转层得出对抗损失。在此过程中,表征能力更好的神经网络能够对负载的深度特征进行提取。

图1 智能云资源管理中短任务负载的预测框架图Fig.1 Short task workload prediction framework in intelligent cloud resource management
2.1 数据预处理
数据预处理是建立预测模型前重要的步骤之一:对原始负载数据进行丢弃、填充、替换、去重等操作。处理后的数据集进行数据清洗,可视化。采用线性归一化消除负载数据之间的量纲差异,便于观察负载序列的变化特征,假设S是从云数据集中提取得到的负载序列,Smin、Smax为序列中的最小、最大值,则负载归一化具体见公式(1):
2.2 SSA去噪
将序列中较为异常的数据重构成相对正常的数值,以增强数据的平稳性,其步骤如下:
步骤1对于一维负载序列S(N)=((S1),(S2),…,(SN)),定义窗口长度L(2 ≤L≤2/N),对原始负载滞后重排得到其对应的轨迹矩阵:
步骤2对公式(2)中的矩阵进行奇异值分解得到L个非负特征值ωi及其对应的奇异向量σi,其中1 ≤i≤L。若令v=max{i}(ωi>0),则得到:
步骤3假设共有N个奇异值,将原有数据按照贡献率分为多个序列,其中第i个(1 ≤i≤N)奇异值的贡献率为:
步骤4新的负载序列由前i个主要成分构成以实现重构。特征向量Ki被划分到若干个组,并在组内进行相加。设I={i1,i2,…,ip},对应的SI=Si1+Si2+…+Sip,其中对应的各个子矩阵不相交。
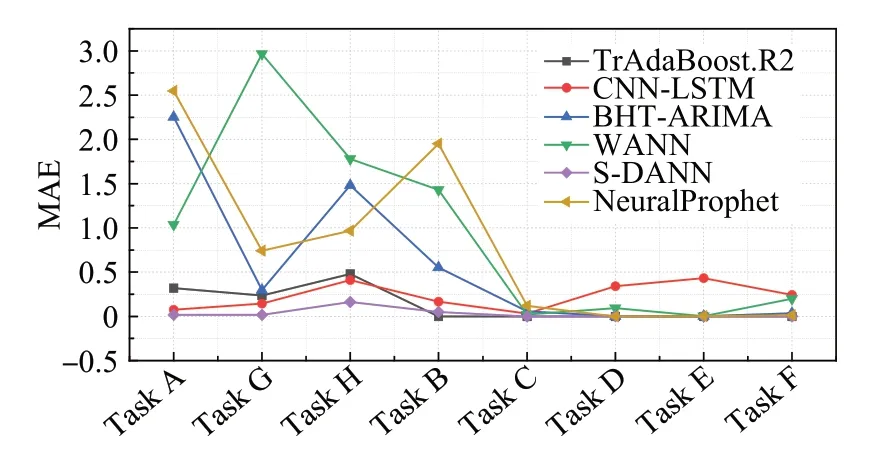
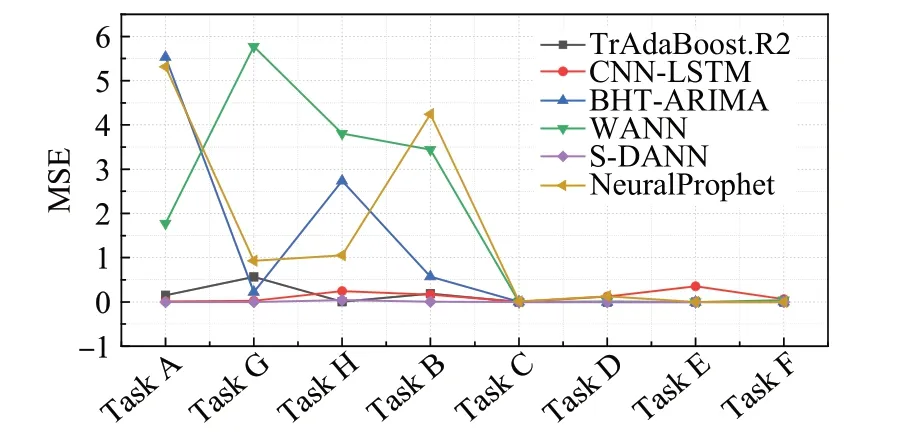
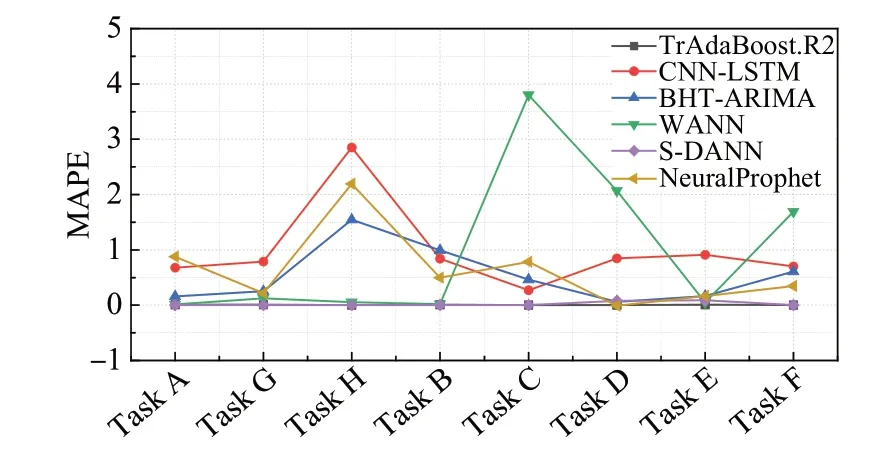
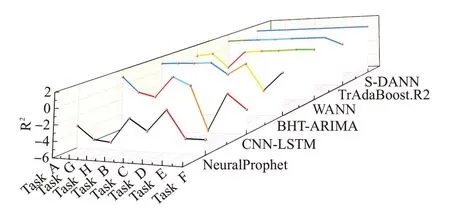
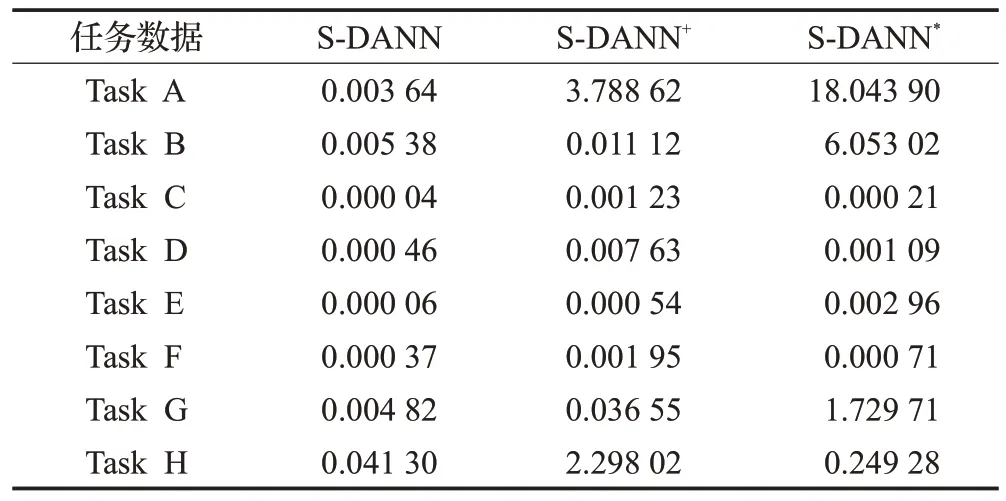
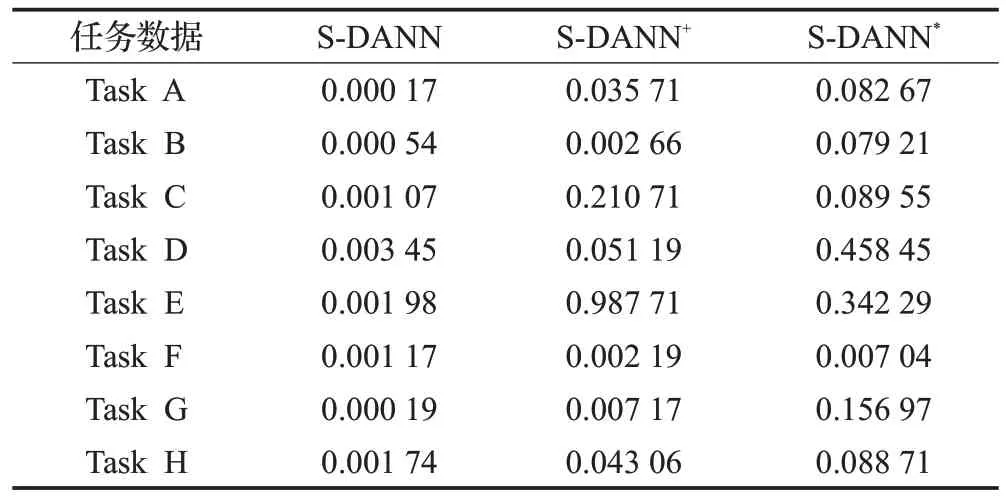
设L*=min(L,J),J*=max(L,J),N=L-K+1,若L 对于本文中提取的短任务负载数据,利用奇异谱分析对短负载序列的降噪处理是必要的,通过对数据的SSA 去噪能有效地消除噪声,平滑化处理负载数据,处理效果如图2所示。 图2 SSA平滑数据对比Fig.2 SSA smoothed data comparison 该部分共包括两个主要步骤:MASS_V4 对负载序列进行相似性度量,利用时间特征对序列之间的差异进行最小化约束。 (1)MASS_V4:对于长度为n和m的负载T和Q,Q=Z-Norm(Q),分段参数记为k,首先需要对序列Q进行归一化操作,再将序列进行分段处理,计算距离度量的流程如下: 当PL 当PL>k时,dbs=dbs-1: 其中,C=∑T,C2=∑T2。 则两条负载之间的距离定义为: (2)时间特征:一般来说,相似负载之间的系统变化指标能够更充分的显示其互信息量。对两个连续窗口下的负载数据进行比较来统计相应的时间特征,如表1所示。 表1 特征描述Table 1 Characterization 计算当前值Sn和前t个值Sn-l之间的差异,其中Sn由2.2节中的SSA处理之后得到,并作如下设置: 这些描述性特征是在从周期为σ派生的滑动窗口中计算的。lσr利用一些时间序列的索引记录时长等相关先验知识确定,例如,本文所用负载是按照每5 min记录一次的,则定义lσr=12,通过对时间特征的统计以有效地捕捉负载之间的上下文依赖信息,分别经过计算得到相关性差异值Dift。 本节所提出的领域自适应对抗神经网络是由三个标准的子神经网络组成,其分别对应的是任务网络,利用Y 差异公式构建的差异网络和重加权网络Eθh。由实验结果证明(见3.4 节中的消融实验),GRU网络相比于其他神经网络算法更适用于短负载序列的预测,故本模型中采用GRU做为基准器进行构建。 目标域MT由云平台某一个虚拟机中存在的大量的短任务负载序列XT构成,其对应的数据分布为PT(XT)。 源域MS由相似性度量得到,其是另一组CPU使用情况数据XS,相应的XS数据分布的描述为PS(XS)。 源域中云负载序列的长度m′与目标域序列长度n′之间的关系为:n′≤m′,且两个域之间的分布不同:PS(XS)≠PT(XT)。 综上,本文构建的模型应能解决如下问题:通过利用源域数据MS的辅助,使得构建出基于MT和MS的短负载序列训练模型,通过最小化预测误差。以对目标域中对应的无标签数据进行预测并得到较高的精度。 S-DANN的损失函数的构建过程如下:定义βt、βd、βw为对应网络的权重,该模型以相同的梯度下降并行训练三个网络。通过最小化Gd的过程寻求在长序列和短序列负载训练任务上提供对抗性能。使用加权网络E是为了捕获源域样本与目标域之间的潜在依赖性,并学习新的源域样本权重。其中任务网络的反向传播函数为: 权重网络的反向传播函数为: 差异网络的反向传播函数为: 在目标函数最小化的过程中引入监督距离Y差异,构造差异网络的目标函数。并利用对抗性技术计算逼近Y 差异。在训练阶段对源域的样本损失进行最优加权。该模型首先利用权重及相关变量参数得到对应的损失函数,再利用反向传播计算学习率、偏导调整变量、权重参数,以此迭代获得最优的目标函数。在训练阶段对源域的样本损失进行最优加权来计算目标任务的假设。通过引入一个差异网络Gd,并利用对抗技术来最小化Y 差异。基于实例的领域自适应方法通过重新加权源实例来纠正源和目标分布之间的差异,选择出最佳适应源样本,以捕获源域样本之间的潜在依赖性。因此,S-DANN 损失函数的构建如公式(17)~(24)所示。源域任务损失函数的构建: 目标域任务损失函数的构建: 差异网络源域损失函数的构建: 差异网络目标域损失函数的构建: 该模型对应的总损失函数如式(24)所示: loss_t_s标准神经网络前馈层的损失函数。loss_t_t是对损失函数第一项的正则化,由于目标域的样本量比较小,因此添加一个可选的标记源数据防止过拟合现象。损失函数中|loss_disct_loss-loss_disc_s|是根据估计的Y差异选择与目标实例最相似的源域样本。 实验的验证数据采用两个大规模公开云负载数据集:谷歌云数据集(Google trace data)[16]和阿里云数据集(Cluster-trace-v2018)[17],其在该领域具有一定的代表性。目前,大部分云负载工作的研究均是基于这两个大型云数据集。 在Google trace data 记录的是谷歌云29 天的工作日志记录。该数据集共包含六部分csv 表,采样频率为5 min。本文选取task resource usage table 下的数据进行实验。该数据集中的作业按照优先级可以分为三种:Free、Production、Batch。其中,优先级为Batch的任务为存储或服务型作业,其运行时长相对较短。例如,选取短负载作业为job ID:6249832520,该作业下包含有200个任务,采样点长度为501,随机选取四组同类型任务进行实验验证。为方便实验操作,对谷歌云四组任务数据进行形式化命名,具体内容见表2。 表2 谷歌云数据Table 2 Google cloud data Alibaba cluster数据集记录的是在集群中的每台机器上运行的在线服务(长期运行的应用程序)和批处理工作负载。本文的研究点主要针对的是集群中运行时长相对较短的批处理工作负载。Cluster-trace-v2018 共包含大约4 000台机器在8天的时间内的工作日志记录情况,由六种表组成,每个表是一个文件。本实验采用表machine_usage.csv 中的CPU 利用率,其是以百分比的形式记录的。从阿里云中随机提取四组短任务数据并对其进行形式化命名,具体内容见表3。实验是基于两个公共数据集随机选取的八组复杂变化模式的短负载序列,分别进行了负载预测趋势和评价指标的对比实验,其目的为:使实验结论更具有一般性。 表3 阿里云数据Table 3 Alibaba cloud data 在所有实验场景中,本文考虑80%的负载数据用于训练模型,剩余20%的数据用于模型的验证。神经网络的层数为三层,Adam 优化器用于神经网络训练的所有实验,学习率设置为0.001,循环次数设置为200。训练样本在输入和输出前进行了标准缩放预处理。 在实验中,从谷歌和阿里云数据集中共选取四组数据进行对不同负载预测对比算法下的预测趋势图做可视化分析。其中的四组数据指的是任务B、任务G、任务F 和任务D,预测结果对比与图3~6 对应。选用的对比算法共五种:其中迁移学习类的负载预测算法包括TrAdaBoost.R2[18]、WANN(weighted adversarial neural network)[9];非迁移学习类的负载预测算法:CNN-LSTM(convolutional neural networks-long short-term memory)[19]、BHT-ARIMA(block hankel tensor autoregressive integrated moving average)[20]和NeuralProphet[21]。 图3 任务B不同算法预测结果对比Fig.3 Comparison of prediction results of different algorithms under Task B 图4 任务G不同算法预测结果对比Fig.4 Comparison of prediction results of different algorithms under Task G NeuralProphet是一种复合算法,既有神经网络和线性模型的优势,又具有较强的可扩展性组件结构。CNNLSTM,BHT-ARIMA 都是针对于短序列提出的预测算法,并在非线性时序预测问题中得到了广泛的应用。在本文中,这三种方法被用作S-DANN 的对比模型。TrAdaBoost.R2 和WANN 是迁移学习中针对回归问题的算法。因此在本文中,这五种方法被用作S-DANN的对比模型,并对预测结果进行实验对比。 为了观察负载序列采样点数量对预测模型的影响,实验中的负载序列数据选取不同长度,分别对应为序列Task G、Task B、Task F、Task D。在本文所提算法S-DANN,与实验中选用的其他五种先进的预测算法进行比较,同时对云负载数据集做相应的训练集和测试集的划分,图中仅对测试集的预测对比结果的可视化分析。 尽管随着时间的推移,负载的极大、较小值的取值范围存在很大差异,且不同任务间的走向存在的较大不同,综合变化模式更加复杂。从图3~6 中能够看出,其共同之处是非迁移的深度学习算法CNN-LSTM,NeuralProphet相比于迁移的算法TrAdaBoost.R2,WANN预测效果较不佳,且本文所提的迁移学习算法S-DANN拟合相对较好,明显优于其他比较算法。 由图3、图5 能够看出NeuralProphet 适合于线性数据的预测,而本实验所用的数据具有较强的非线性。故实验效果与真实值存在较大差异。而短序列的数据量并不能满足深度学习训练模型的数据量需求,故CNNLSTM不能很好地发挥其性能。 图5 任务F不同算法预测结果对比Fig.5 Comparison of prediction results of different algorithms under Task F 图6 任务D不同算法预测结果对比Fig.6 Comparison of prediction results of different algorithms under Task D 除了本文所提算法,表现次之的是BHT-ARIMA,因其本身是针对于短小负载设计的算法,但从四个图中能够看出,虽然其能预测大致趋势,但其对于非线性变化的负载,不能很好地挖掘其特征信息,对于峰值点的精确预测,仍然存在差异。综上,S-DANN 算法的预测值与相应样本的测试集数值差异最小,根据预测结果,其表现均优于其他五种负载预测方法。 为评估模型的有效性,本节对模型的性能分析时,实验共采用四个评价指标[19,22]:平均绝对误差(mean absolute error,MAE)、均方误差(mean-square error,MSE)、平均绝对百分比误差(mean absolute percentage error,MAPE)、可决系数R2。 MAE 应用广泛,为模型提供了一个通用且有界的性能度量。MSE 用于检测数据中的异常,函数的平方部分可放大异常值对应的误差。MAPE 在相对误差方面具有非常直观的解释。MAE、MSE、MAPE 的评价指标值越小,则对应该算法的性能越好。R2可以解释为因变量中方差值比例,该指标不同于前述三种,其值越接近于1,模型性能越好。 从图7~9可以看出,本文所提出的算法S-DANN在八组子数据集合上几乎都达到了MAE、MSE、MAPE评价指标的最小值。在MAE、MSE指标中,TrAdaBoost.R2、CNN-LSTM和S-DANN都有着稳定的表现。WANN算法的效果在这三个回归评价指标上均表现最不佳,由于目标函数的问题,并不适用于云负载数据的预测,该算法更适合针对于非负载预测类的回归问题。 图7 MAE对比Fig.7 Comparison of MAE 图8 MSE对比Fig.8 Comparison of MSE 图9 MAPE对比Fig.9 Comparison of MAPE WANN 算法在这三个回归评价指标上的实验效果都较差,由于目标函数的问题,使其并不适用于短任务负载数据的预测,该算法应更适合针对于非负载预测类的回归问题。 由图7~9中评价指标的数值变化中可看出,在同一个指标图中同一算法在不同任务数据上的指标值也存在较大的差异变化,这说明了数据的不同特性对模型效果的影响是较大的。 CNN-LSTM 是深度网络的融合模型,从图中分析可知该模型评价指标值相对平稳,但其精度的提升对训练数据的要求较高。而NeuralProphet 的评价指标值在不同任务数据上的变化幅度更大,跳跃性较强,该模型对不同特性数据的适应性不同。 从图10 可以看出,在三维折线图中不同的取值范围若取相同的颜色,会出现同取值的堆叠交叉现象,不同颜色的线段在R2指标图内代表不同的取值区间。根据不同对比算法在八组云负载数据上的R2评价指标值,S-DANN、TrAdaBoost.R2、BHT-ARIMA、WANN 算法中指标值在0到1之间的任务数相对较多。迁移学习的方法和针对于短序列预测的算法更适合本文所针对的短负载样本序列。在这种情况下,可以看出,NeuralProphet的模型评价相对较差,可能是由于所选的负载样本长度较短,缺少周期性、季节性等易于捕捉的特性。S-DANN算法相比其他算法,评价指标更接近1,说明本文所提算法的性能更好。 图10 R2对比Fig.10 Comparison of R2 为验证领域自适应对抗模型中选择GRU算法作为基准器的必要性,对本文所提算法中的基准器进行消融实验设计。比较三种适用于序列的神经网络预测算法在回归指标下的差异,实验指标仍选用上述四种:MAE、MSE、MAPE、R2。 将S-DANN中的基准器GRU替换为LSTM和循环神经网络(recurrent neural network,RNN)并进行形式化的命名,将S-DANN的基准器替换为LSTM时算法记为S-DANN+,S-DANN 的基准器替换为RNN 时算法记为S-DANN*。消融实验的具体结果见表4、表5、表6 和图11,其中表4、表5和表6是不同消融算法下MAE、MSE、MAPE 的指标值比较,图11 直方图中为R2指标值在不同消融算法下的比较。由于前三种评价指标越小表明算法性能越好,而R2指标值越大算法性能越优,故分别采用图和表的形式对消融实验的结果进行可视化说明。 表4 消融指标MAE结果对比Table 4 Comparison of ablation index MAE results 表5 消融指标MSE结果对比Table 5 Comparison of ablation index MSE results 表6 消融指标MAPE结果对比Table 6 Comparison of ablation index MAPE results 图11 消融指标R2结果对比Fig.11 Comparison of ablation index R2 results 通过对表4、表5 和表6 中的指标值进行比较可看出,S-DANN在八组数据上均达到了MAE、MSE、MAPE的指标最小值。验证了领域自适应对抗算法S-DANN中基准器选择GRU网络的准确性。GRU通过相对简单的结构,和高性价比的性能能够更好地处理序列之间的信息。LSTM 和RNN 作为基准器时的评价指标值相比之下,S-DANN+指标值在总体上相比优于S-DANN*。 针对图11中R2指标值消融实验的对比结果能够得出结论:S-DANN 的模型性能最佳,S-DANN+模型的性能次之,S-DANN*的模型性能排在最后。 GRU算法作为LSTM的改进算法,不但继承了其捕捉时序特征的优势,且在简约的参数量上更具有竞争优势。由于在建模负载长期依赖关系上并不占优势,S-DANN*模型性能次之。由于在建模负载长期依赖关系上并不占优势,S-DANN*性能较弱。 在针对短任务负载样本的消融实验中,GRU 算法作为LSTM 的改进算法,简约了参数的数量,且继承了其捕捉时序特征的优势。从实验结果中可知,使用GRU作为基准器的S-DANN算法,在四种回归评价指标上都表现最佳。 短负载序列进行精准预测是云计算领域的难题。负载数据往往随着时间的推移变化较大,新旧数据之间易发生分布漂移,且短负载序列本身的特性导致传统模型的预测效果不佳。针对上述问题,本文提出利用领域自适应的域对抗技术构建深度网络学习模型,该模型利用序列之间的依赖性补充样本的不足,将重建网络结构与回归损失相结合,采用基于领域自适应的思想,对抗网络的结构,对负载序列实现了有效预测,提高了整体的资源利用率。此外,本文提出了一种相似性负载的度量方法,利用MASS_V4和时间特征对负载之间的相似性进行度量,该方法具有较理想的性能和良好的鲁棒性。S-DANN 在不同数据集上的对比预测结果及模型评价均表现优异,能够超越短负载预测实践中通常使用的基线方法。S-DANN 利用源域数据弥补了小样本负载特征不足的缺点,但云平台中仍存在大量的数据特征未得到合理应用。在未来的工作中,将考虑应用自适应域对抗神经网络在半监督领域的问题上,以更好地捕捉和利用云平台中的资源。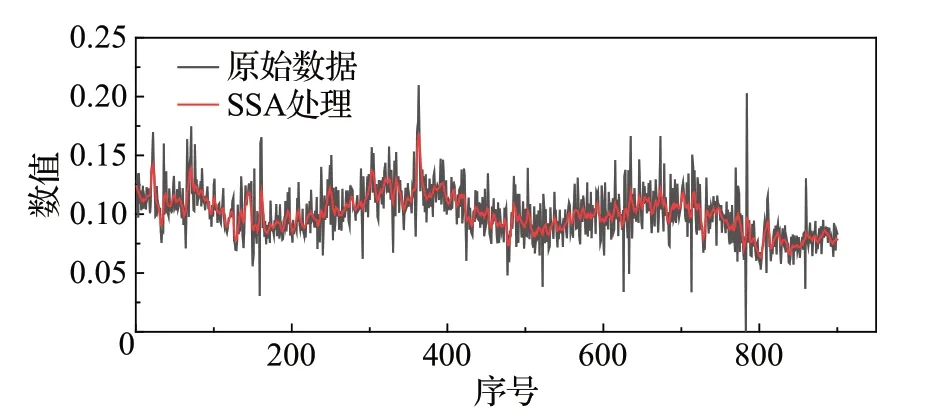
2.3 源域集合的获取

2.4 输入自适应域对抗网络
3 实验结果及讨论
3.1 实验准备


3.2 实验结果分析
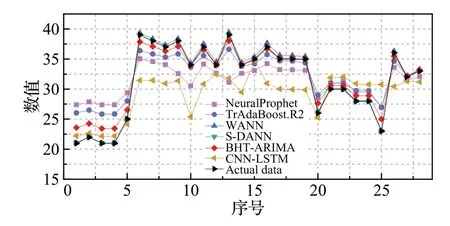
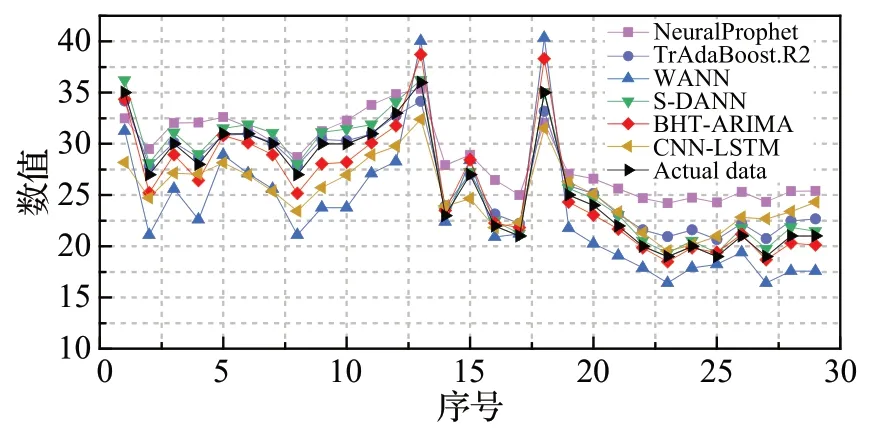
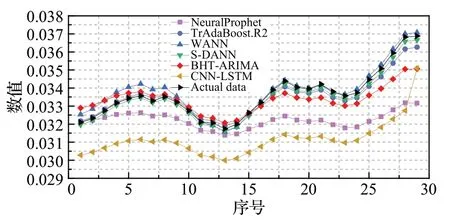
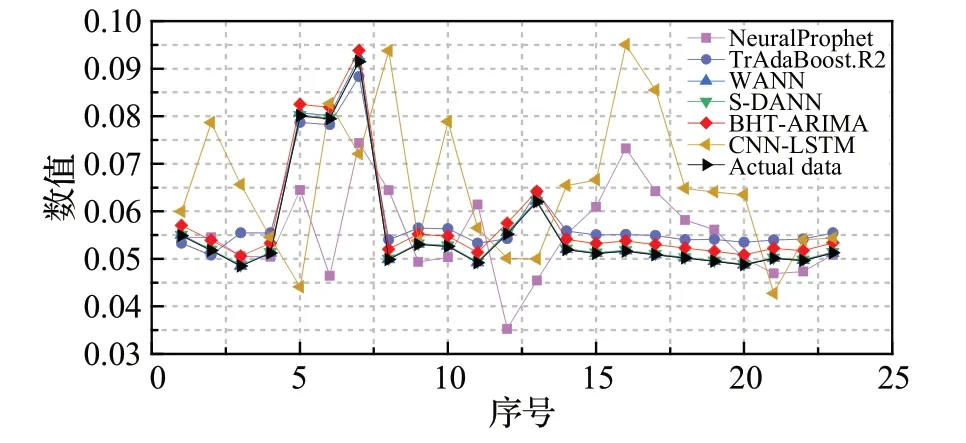
3.3 模型性能分析
3.4 消融实验设计


4 结束语
猜你喜欢
黄河之声(2022年10期)2022-09-27中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化·高一版(2021年2期)2021-03-19计算机技术与发展(2020年11期)2020-12-04知识经济·中国直销(2018年8期)2018-08-23中学生数理化·八年级物理人教版(2017年11期)2017-04-18数学学习与研究(2017年3期)2017-03-09中国老区建设(2016年1期)2016-02-28电子与信息学报(2015年12期)2015-08-17
