
自适应特征融合的复杂道路场景目标检测算法
2023-12-27 14:53:26冉险生苏山杰陈俊豪张之云
计算机工程与应用 2023年24期
冉险生,苏山杰,陈俊豪,张之云
重庆交通大学 机电与车辆工程学院,重庆 400074
目标检测作为计算机视觉领域的一项基础任务,在各个领域都有广泛应用,如自动驾驶、军事侦察、行人检测、视觉机器人等。近年来,计算机视觉领域相关技术取得了突破性的创新,随着自动驾驶汽车出现及道路测试实验不断深入,道路场景下的目标检测技术也日益重要,并对自动驾驶技术环境感知模块起着决定性的作用。
随着深度学习和卷积神经网络的快速发展,主流的深度学习检测算法分为两类:基于锚框和不基于锚框的检测算法[1-2],其中基于锚框的检测算法检测精度高,但网络结构较为复杂,模型计算对硬件设备有着更严格的要求,难以满足自动驾驶技术环境感知模块实时性检测的要求;而不基于锚框的检测算法虽然在精度上不及前者,但在实时性方面更有优势。研究学者针对复杂道路场景下的目标检测做了大量研究,研究发现通用目标检测中[3]图像质量较高,环境因素影响较小,算法能充分提取特征信息,较好地定位并识别出目标,而复杂道路场景下[4]目标尺度变化大,目标多而杂,且由于成像距离、行车视角变化快和光线,目标之间遮挡严重,多以小尺度目标形式存在,容易出现漏检和误检,进一步降低算法检测精度。
因此如何提升复杂道路场景目标检测算法的检测性能,降低遮挡目标、小尺度目标漏检率和误检率是近年来的研究重点。为解决道路场景中实时性检测问题,文献[5]提出了一种动态阈值方法删除错误的候选框,采用高斯衰减函数过滤重叠的候选框。文献[6]以RetinaNet 为基础框架,设计了基于不同扩张率组合的残差卷积分支模块,提高了各类目标的检测精度。文献[7]改进了YOLOV4-Tiny 算法,提高了街道场景中小目标的识别能力,并在极端天气具有一定的鲁棒性。除此之外国内外研究者针对不同道路场景采用了不同的改进策略[8-10],但现阶段复杂道路场景下的目标检测仍然面临较大挑战,在检测精度和实时性方面存在一定的进步空间。2020—2021 年,YOLOv5 及YOLOX 相继问世,以极高的检测速度成为了实时检测和移动端部署的首要选择,但以上两种算法难以对复杂道路场景下的密集遮挡目标、小尺度目标进行有效检测。
为了解决密集遮挡目标,小尺度目标检测效果差的问题,国内外的研究学者主要从anchor 优化、增加感受野、引入注意力机制、改进损失函数、增强特征提取、改变特征融合方式、改进网络结构等方面进行大量探索实验。针对小尺度目标特征信息在传递过程中容易丢失的问题,Lin 等人[11]首先提出了FPN(feature pyramid networks)结构将含有更多语义信息的深层特征与含有更多细节信息的浅层特征进一步融合,较好提升了检测效果,近年来研究学者进一步优化了FPN结构[12-17],对检测性能均有不同程度的提升。Yu 等人[18]创造性地提出空洞卷积扩大感受野,进一步提升模型对小尺度目标的识别精度,同时研究学者通过实验证明空洞卷积的有效性,并提出了改进方法[19-23]。Liu等人[24]提出自适应空间特征融合的方法,允许网络能够直接学习如何在空间上过滤其他层次的特征,只保留有用的信息用于组合。近些年来研究学者更加关注注意力机制对目标检测性能的影响,提出了有效改进方法[25-32]。通过对数据集的分析,在损失函数的改进上更多采用EIOU[33]和Focal Loss[34]来提升小尺度目标的检测效果。因此如何提升复杂道路场景小尺度目标检测算法的精度、实时性和鲁棒性是本文的主要研究目标。
目前YOLOv5 及YOLOX 算法拥有较好的检测性能,其中YOLOv5-s 和YOLOX-s 属于轻量级的检测算法,是嵌入到移动部署设备的首要选择,但两类算法对遮挡目标,小尺度目标的检测仍有提升的空间。本文以YOLOv5-s 检测算法为基础框架,针对目前复杂道路场景中密集遮挡目标检测、小尺度目标检测漏检率较高、检测精度偏低的问题进行改进。具体改进如下:为了减缓相邻尺度特征融合时对模型产生的负面影响,借鉴了特征融合因子的思想,改进了融合因子计算方式,增加特征融合后有效样本,提升中小尺度目标的学习能力;为了提升复杂道路场景下的中小尺度目标的检测精度,进一步有效利用浅层特征层提取的特征信息,增加了一层浅层检测层;针对复杂道路场景下尺度变化大的车辆行人目标特征信息提取不充分的问题,借鉴RFB(receptive field block)网络结构的思想,构建自适应感受野融合模块,允许模型训练时自动选择合适的感受野特征;为了提升算法对遮挡程度高,密集小尺度目标的检测能力,损失函数引用Quality Focal Loss进行优化,并融入CA注意力机制,改变模型关注的重点,增强算法的特征提取能力。
1 YOLOv5目标检测算法及改进
1.1 YOLOv5算法整体结构
YOLOv5 算法是目前YOLO 系列最新版本检测算法,YOLOv5主要结构如图1所示,模型由输入端(Input)、主干网络(Backbone)、多尺度特征融合网络(Neck)、检测网络(YOLOHead)等四部分组成。输入端的创新点主要是采用mosaic 图像增强,增加自适应锚框计算等。主干网络包含C3 结构,空间金字塔池化SPPF 结构,主干网络主要对输入端数据增强的图像进行特征信息的有效提取,同时最大程度减少信息下采样时的丢失,实现不同尺度信息的有效融合。多尺度特征融合网络主要采用FPN+PAN结构,经过Backbone的待识别图像在浅层具有更多的定位信息,在深层具有更多的语义信息,采用FPN 结构把含有更多语义信息的特征传给浅层,增强每个尺度上的语义信息,达到更好的检测效果;PAN 结构实现了从浅层把含有更多定位信息特征传递给高层,增强每个尺度上的定位信息,改善了多尺度目标检测的性能。检测网络采用GIoU损失函数计算边界锚框的损失值,并在后处理过程中采用加权NMS,筛选密集重合的多个锚框。
1.2 相邻尺度特征有效融合模块
YOLOv5-s 算法Neck 网络采用PAFPN 双向特征金字塔结构并加上横向连接结构实现不同尺度特征的融合,其中FPN 结构本质上是进行多任务学习,得到待检测目标的具有更多定位信息的浅层特征和具有更多语义信息的深层特征,在理想的情况下,不同的特征层只专注于其对应的不同尺度目标的检测。而在实际情况下,目标检测过程中会有以下问题:不同尺度的特征层在监督学习中总会受到其他层的影响(损失传递),其中相邻两个特征层之间的影响较为严重,其次是YOLOv5-s算法在表面上可以覆盖多个尺度的检测,但在相邻层之间往往存在部分尺度的目标在两个相邻特征图中均有较大的响应,而网络自动学习时只是根据响应值粗暴地判别到某一层进行识别,导致检测效果较差和网络收敛效果不好。应用于小尺度的遮挡车辆、行人的目标检测中,除了浅层特征图上含有小尺度目标有效特征信息,深层特征图上也可能存在对检测结果有影响的特征信息,也是需要学习的。由于待检测的目标尺度较小,特征信息的提取难度大,浅层网络学习到的特征信息有限,深层网络学习到的特征信息不足以对浅层网络进行辅助,从而影响小尺度目标的检测效果。
由以上分析得知,每一层学习到的信息都有着至关重要的作用,深浅层的特征信息对不同尺度的待检测目标的贡献程度不同,同时特征信息流动中对其他层的影响有弊有利。为了减缓特征融合对模型带来负面的影响,提出了一种改进的相邻尺度特征融合策略。主要考虑到同一个有效样本在不同尺度的特征图有不同的响应,按照1∶1比例的融合策略并不能达到最优的融合效果,容易造成信息丢失,导致FPN 结构中某些层的训练样本相较于其他层会减少很多,故需要改变深层特征参与浅层特征学习的程度,过滤掉相邻层传递过程中的无效样本,保证深层特征图上存在更多的有效样本进行学习,进而指导浅层的学习,提升不同尺寸目标的检测效果。FPN的特征融合过程的表达式为:
其中,Ci和Pi+1分别表示在进行特征融合前后第i层的特征图,flateral表示在FPN 横向连接中的1×1 卷积操作,fupsample表示用来调整分辨率的2 倍上采样的操作,fconv表示特征处理的卷积操作,表示第i+1 层特征图向第i层特征图传递时应相乘的特征融合因子。文献[8]提出的特征融合因子是经过统计的方式得到,分别统计每层对应的目标数量,公式表达式为:
文献[9]提出了使用注意力模块计算融合因子的方式,本文融合BAM[35]注意力机制的思想,改进了相邻尺度特征有效融合模块,如图2 所示,计算出特征融合因子,用来减缓特征融合过程中的负面影响,公式表达式如下:

图2 相邻尺度特征有效融合模块(AFEF)Fig.2 Adjacent scale feature effective fusion module(AFEF)
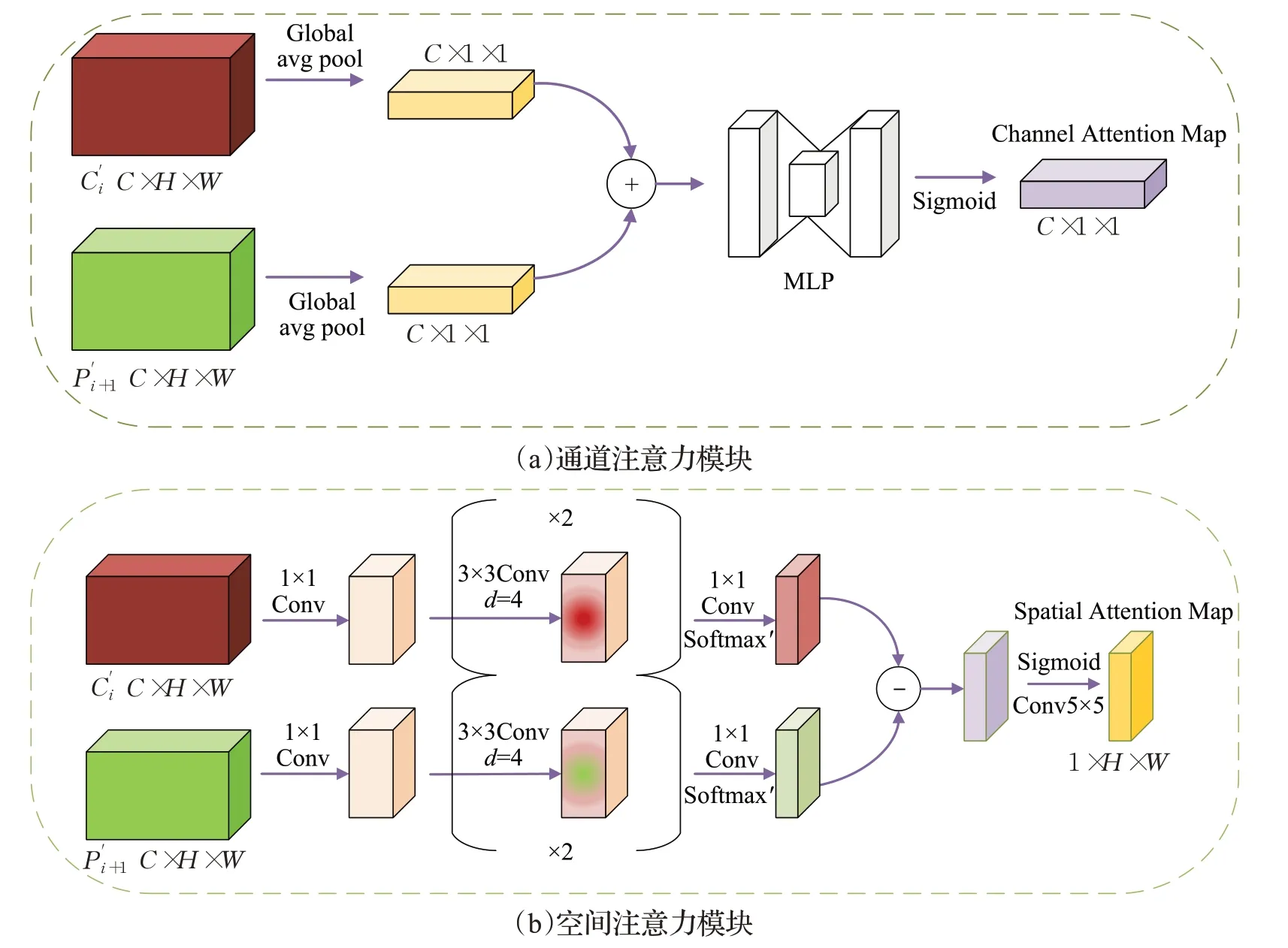
图3 空间与通道注意力模块结构图Fig.3 Structure diagram of spatial and channel attention module
空间注意力模块主要功能为对传递中的深层与浅层的空间信息进行对比,分析相邻特征图含有信息值的差异,用来确定深层传入浅层的无效样本并过滤。Ms模块公式如下:
其中,σ表示Sigmoid 激活函数,f1×1表示可压缩通道数的1×1 卷积,f3×3表示卷积核为3×3 的扩张卷积,可共享参数信息,f5×5表示卷积核为5×5 的卷积操作,Softmax′表示乘积出特征图不同维度(行和列)Softmax运算后的值。
特征图的每一个通道都携带着大量信息,通道注意力模块更加集中关注特征图中有意义的内容,配合空间注意力模块,从通道层面更好地处理特征信息,减少无意义的特征融合通道,达到更优异的性能。Mc模块公式如下:
其中,GAP表示全局平均池化操作,MLP表示带有一个隐藏层的多层感知器,是由全连接层和Relu激活函数共同组成,先将通道数压缩为原来通道数的1/r倍,再扩张为原来的通道数,经过Relu 函数得到激活后的结果,r值在实验中取为16,表示Sigmoid 激活函数。
1.3 多尺度宽感受野自适应融合模块
在复杂的道路场景中,上下文信息对车辆行人等目标的检测中起着不可或缺的作用,能够精确地识别和定位出待检测的车辆行人目标,尤其在遮挡场景中,上下文信息的有效利用能够较好提高遮挡目标的识别效果。YOLOv5-s算法中,SPPF空间金字塔池化模块能极大地增加感受野,分离出最显著的上下文特征,进行多重感受野融合。针对遮挡严重的车辆、行人目标,由于尺度较小,会引入过多的背景信息,干扰目标关键特征的表达能力,导致特征信息提取不充分,故引入RFB-s网络结构并改进,有效增大感受野区域使其自适应融合,改进前后结构如图4所示。
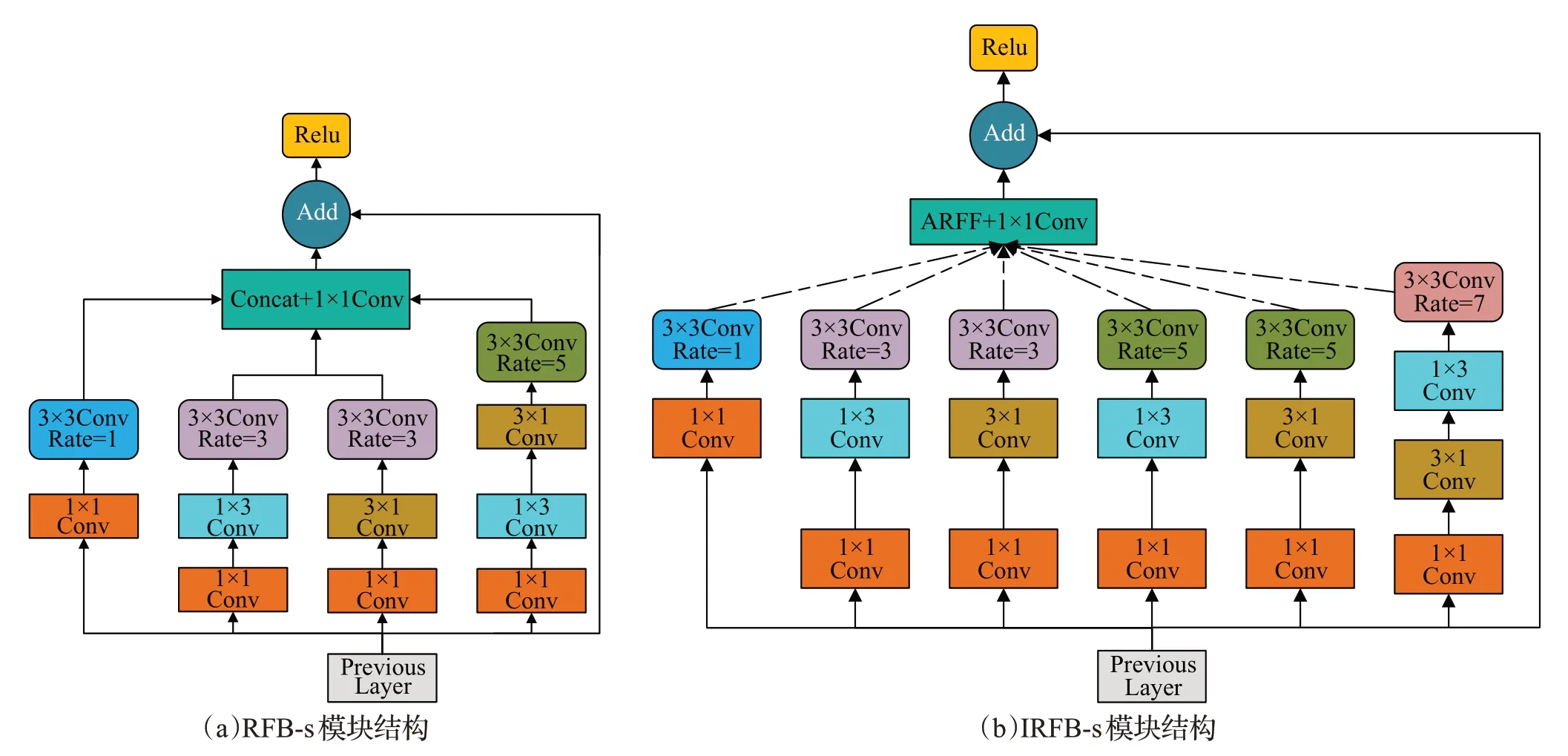
图4 RFB-s模块改进前后结构Fig.4 Structure of RFB-s module before and after improvement
RFB-s模块结构首先对输入的特征图进行1×1卷积操作缩减通道数,降低模型的计算量;然后降维的特征图分别经过4个感受野的分支获取对应特征信息,使用非对称卷积减少参数量,使用扩张率分别为1、3、5的3×3空洞卷积增大特征图感受野;其次对每个感受野分支进行拼接和1×1 卷积操作,融合得到的特征图;最后通过ShortCut 的方式有效缓解网络梯度传播过程中损失值发生爆炸和消失的问题,加快训练速度,并融合原特征和多尺度感受野融合特征。
改进的RFB-s 模块,称作为IRFB-s,整体上依然采用多分支空洞卷积的结构进一步增加感受野,把3×3卷积换为1×3、3×1 非对称卷积,减少参数量和计算量;增加感受野分支,得到更宽、更多的感受野组合;引入ASFF网络[24]的思想,自适应融合每个感受野分支得到的特征图,网络在学习过程中根据不同尺度目标选择最佳的感受野融合方式,有效避免了感受野过大时无关背景信息对有效信息的干扰,能较好完成特征的提取,有效学习上下文信息,改善尺度变化大及遮挡场景下的车辆、行人目标检测。
1.4 注意力机制与损失函数优化
复杂道路场景存在大量的尺度变化大及遮挡的待检测目标,模型在进行特征提取时会混入大量的背景及非检测目标的无效特征信息,会对有效目标的信息提取造成负面的影响,因此模型需要过滤掉这些无效信息,将更多注意力放在有效目标上。国内外研究人员提出注意力机制来关注更加重要的特征,排除无效的信息的干扰,给模型性能带来一定的提升。本文借鉴并引入CA(coordinate attention)注意力模块[32],该模块提供了一种新颖的编码特征图通道信息的方式,分别沿着两个空间方向聚合特征,有效地将空间坐标信息整合到生成的注意图中,使得轻量级网络获得更多区域的有效信息。CA注意力模块结构如图5所示。
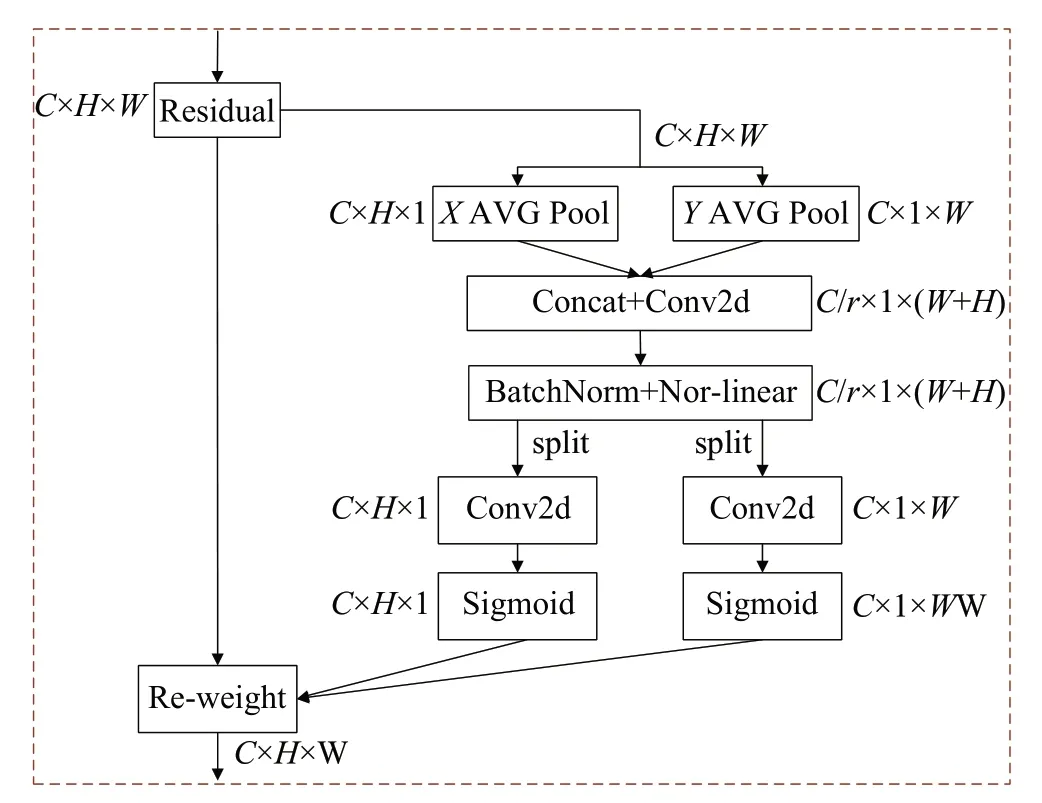
图5 CA注意力模块编码过程Fig.5 CA attention module encoding process
复杂道路场景模型能更好地检测出目标并进行定位,损失函数的作用是不可或缺的,损失函数主要由三部分组成:定位损失、置信度损失和分类损失,公式描述如下:
在不同的检测场景中定位损失函数有着不同的功效,为了提高复杂道路场景中遮挡目标和中小尺度目标的检测效果,模型采用EIOU Loss来计算目标框的定位损失,一般采用交叉熵损失函数(BCEclsloss)和Focal Loss函数计算置信度损失,本次实验采用Focal Loss函数,将分类损失的交叉熵损失函数更改为Quality Focal Loss损失函数[36],Quality Focal Loss损失函数定义为:
其中,σ表示预测,y为0~1的质量标签,|y-σ|β(β≥0)为缩放因子,表示距离绝对值的幂次函数,超参数β用于控制降权的速率,在文献[36]实验中,取β=2 为最优,本次实验也取β=2。在复杂的道路场景下,待检测目标多以遮挡,小尺度密集分布出现,这造成候选框的重叠程度增加,当原始模型的分类损失函数进行NMS 后处理时,更容易抑制错误,降低了一部分定位精度,而Quality Focal Loss 的引入能在一定程度上弥补之前模型的不足,提升复杂道路场景下遮挡目标、密集小尺度目标的检测精度。
1.5 多尺度检测网络改进
原始YOLOv5-s 算法采用20×20、40×40、80×80 三个尺度实现对大、中、小尺度目标的检测。复杂道路场景下存在大量小尺度目标,密集遮挡目标,而这些目标特征信息大多存在于网络更浅层,因此需要增大网络的检测尺度范围,检测出更小尺度目标,提高模型的检测性能,故增加了一层160×160 尺度的浅层检测层,充分利用浅层的特征信息,提高小尺度目标的检测效果。但改进后模型复杂度增加,故考虑减少20×20的深层检测层,通过实验发现,减少深层特征层后,对大尺度目标的特征信息提取不足,导致卡车、公交车及部分汽车等大尺度目标的检测精度大幅度降低,影响了算法模型整体的检测精度。经过对比分析,增加160×160浅层检测层后,相对于模型复杂度的增加,模型的检测精度的提升更能接受,而在此基础上减少20×20 深层特征层后,大尺度目标检测精度降低,从而影响了模型整体检测精度。故本次实验保留20×20的深层检测层,只增加160×160的浅层检测层,改进后网络的整体结构如图6所示。

图6 改进后模型结构Fig.6 Improved model structure
2 模型训练
2.1 数据集构建
在深度学习领域中,针对复杂道路场景下的目标检测,大规模的数据集能有效检验算法的性能。实验选用VOC数据集、BDD100K数据集[37]、Udacity数据集[38]及自制数据集进行对比实验和消融实验。
自制数据集:为了切合国内复杂道路场景下车辆行人目标检测,自制了一个真实道路场景数据集,使用车载行车记录仪,在重庆主城区域采集了不同场景的行车视频38 段,包含不同的天气条件,不同道路场景,不同时间段。采集的视频按每4 s截取一张图像的方式制作成数据集,图像分辨率为1 280×720,共3 427张图片,从中选取2 721 张图片作为训练集,其余图片作为验证集。自建数据集主要对交通参与者进行检测,如小车(car),摩托车(motor),卡车(truck),公交车(bus),行人(person),命名为CQTransport。
2.2 实验环境与参数配置
在本文实验中,实验平台操作环境为Windows10,GPU 为Nvidia Tesla V100 PCIE,显存为32 GB,实验仿真采用的深度学习框架为Pytorch,版本为1.8.0,编程语言为Python 3.9,CUDA10.1。YOLOv5-s的基本训练参数见文献[39],Batch Size 参数根据输入图像分辨率进行调整,在不溢出显卡极限情况下,使用较大Batch Size来获得更好的训练效果。训练轮数(Epoch)根据数据集图像量调整,所有改进模型在同一数据集均采用相同设置(不一定为最优设置),进行对比实验分析。
2.3 评价指标
实验利用准确率P(precision)、召回率R(recall)、平均精度均值(mean average precision,mAP)以及帧率(frames per second,FPS)对模型进行定量评价。前三个参数是用来评价模型精度性能的指标,通常来说值越高,模型的检测效果越符合实际检测目标,模型性能也越好。准确率(P)和召回率(R)的计算公式如下:
TP 表示图像正样本中被正确预测为正样本的数量,FN表示图像正样本被预测为负样本的数量,FP表示图像负样本被错误预测为正样本的数量。FPS 是衡量模型检测速度性能的指标,表示模型每秒能处理图像的数量,值越大网络模型处理图像的速度越快,本文使用FPS来评估模型实时性性能。
3 实验设计与结果分析
实验主要采用BDD100K数据集、Udacity数据集及CQTransport 数据集对改进的模型进行训练和测试,并建立多组对比实验和消融实验。
3.1 注意力模块融合对比实验
注意力模块融入到模型哪个位置能起到提升性能的作用始终没有固定的理论,为了验证注意力模块融入位置的有效性,本次实验在主干网络和颈部网络及头部网络分别加入CA注意力模块,分别表示YOLOv5-s-A、YOLOv5-s-B、YOLOv5-s-C,在VOC 数据集上对比实验,训练迭代次数400次,实验后在测试集上性能如表1所示。从结果分析,首先注意力模块在VOC 数据集上并不能有效提升模型检测性能,其次颈部融入注意力模块后性能优于其他位置。主要原因有以下3点:VOC数据集中图像多以中、大尺度目标为主,原始算法已经能有效拟合出数据集中的目标并有效识别,而注意力模块加入便有些多余;对尺度变化大,遮挡程度高的待检测目标注意力模块可能更有效果;数据集中图像数量不够大,原始模型已经处于过拟合的状态,注意力模块的加入进一步加剧这个问题,导致模型性能没有提升或性能下降。

表1 VOC数据集注意力模块融入模型位置实验Table 1 Experiments on integration of attention module into model position of VOC dataset
为了验证其他注意力方法融入颈部网络后是否能提升模型性能,建立了多组对比实验,由于原始模型迭代200 轮后出现了过拟合现象,本次实验主要选取前200个周期进行对比分析,表2为测试集性能结果。

表2 注意力模块对比实验Table 2 Comparative experiments of attention modules
根据实验结果,训练周期内融入各类注意力方法没有达到提升模型性能的效果,继续增大训练轮数后,模型存在提升的空间。所有实验的注意力方法中,在颈部网络C3 结构融入注意力机制,能起到降低参数量的作用,同时mAP值表现更优异。由于在VOC 数据集中注意力机制并未有效提升模型检测性能,本文后续工作将在BDD100K数据集上进一步验证CA注意力机制的有效性。
3.2 网络模型消融实验
为了更好地验证改进策略的可行性,探究不同改进策略对模型性能的影响,在原始网络结构融入改进方法,并在BDD100K数据集及自制数据集CQTransport上进行消融实验。不同的改进方式使模型结构发生变化,参数量和计算量也在不断改变,从而各方面的评价指标均受到影响,具体消融实验结果如表3、表4 所示。“√”表示模型融入该方法,“×”表示未融入该方法,从表中实验结果得知提出的改进策略在两个数据集上都能不同程度地提升模型性能,其中在自制数据集CQTransport上精度提升效果较为明显。通过消融实验,再次验证了改进方法的可行性,改进模型在不影响实时性检测的同时有着更高的检测精度,能更好地进行复杂道路场景下的目标检测。

表3 BDD100K数据集检测结果Table 3 Detection results of BDD100K dataset

表4 CQTransport数据集检测结果Table 4 Detection results of CQTransport dataset
为了进一步说明改进算法对数据集中各类目标提升程度,选取BDD100K 数据集对目标进行定量和定性分析。其中BDD100K 数据集除公交车和卡车外,各类目标均已中、小尺度目标为主,不同改进算法对各类目标的平均精度如表5所示。

表5 改进模型对各类目标的平均精度Table 5 Average accuracy of improved model for various targets
通过对表3、表5数据对比分析可以得出,复杂道路场景中遮挡目标、小目标居多,训练时原图像中的这些目标(主要是交通灯和交通标识)经过尺寸缩放和特征提取后丢失了大量关键信息,是造成模型在复杂道路场景下检测性能不佳的主要原因,其中引入IRFB-S 模块和AFEF模块对道路场景中交通标识,交通灯等目标的检测精度提升较大,但牺牲了一定的检测实时性;融入CA注意力模块和QFL损失函数在没有任何损耗的前提下分别提升了0.3%、0.2%;采用4 个检测分支能够大幅度提升道路场景中的小目标检测精度,但增加了模型的复杂度。
3.3 模型鲁棒性实验
为验证改进模型在复杂的道路场景下的检测鲁棒性和泛化性,选取含有大量遮挡、阴影等因素的Udacity数据集进行实验验证,经过300 轮训练后,模型趋于稳定,在验证集上得到训练结果如表6所示。
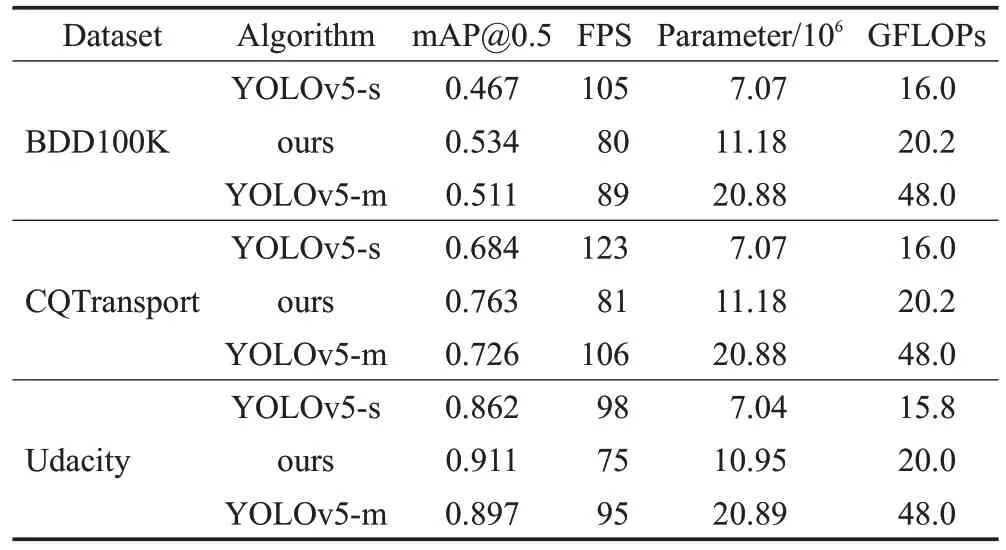
表6 改进模型鲁棒性实验结果Table 6 Experimental results of improved model robustness
为进一步验证改进的算法能否能泛化到基本目标检测场景中,去掉BDD100K 数据集中对检测影响较大的小目标,采用BDD100K 数据集(6 类)和VOC 数据集进行验证,经过300 轮训练后模型趋于稳定,验证结果如表7、表8所示。
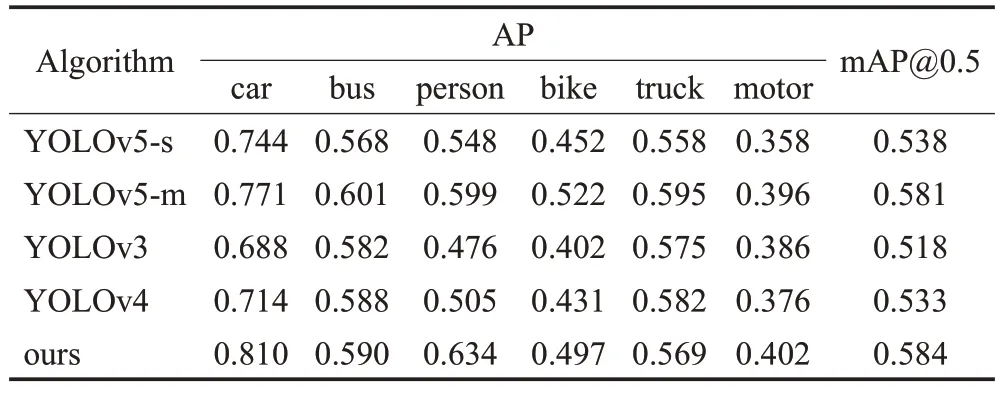
表7 BDD100K数据集实验结果Table 7 Experimental results of BDD100K dataset

表8 VOC数据集实验结果Table 8 Experimental results of VOC dataset
由表6~表8数据分析可知,由于改进算法主要针对复杂道路场景的遮挡目标、小尺度目标进行改进,虽然能泛化到基本的检测场景中,但检测性能提升并不是很大。相比YOLOv5-s算法,在不同的复杂道路场景数据集上,改进策略都能有效提升模型的检测精度,证明了改进模型具有较强的鲁棒性和泛化性。
3.4 模型对比实验
为了进一步证明改进的YOLOv5-s算法的优越性,将现阶段性能表现较好的Faster R-CNN、Cascade R-CNN、SSD、CenterNet、YOLOv3、FCOS、YOLOv4、YOLOv5-s、YOLOv5-m等9种算法与改进的算法在BDD100K数据集(10-Class)上进行实验对比,以检测精度和速度作为评价的指标,对比实验结果如表9所示。
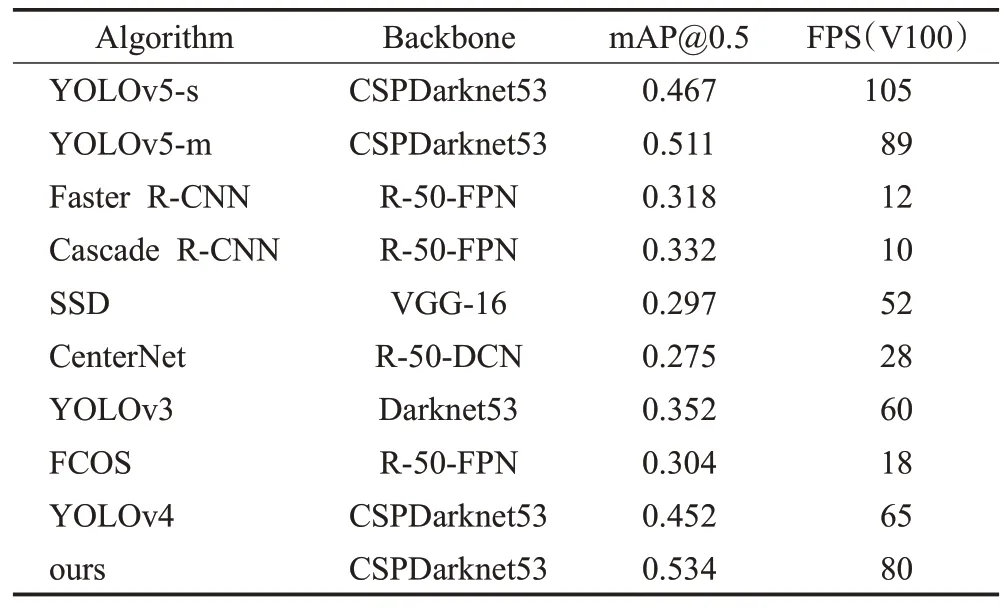
表9 不同算法在BDD100K数据集性能对比Table 9 Performance comparison of different algorithms in BDD100K dataset
对比表7不同算法模型在BDD100K数据集的实验结果,改进的YOLOv5算法相较于其他主流模型有着更高的检测精度及检测速度,相较于YOLOv5-s、YOLOv5-m算法,虽然检测速度不及它们,却拥有更高的检测精度。在不影响模型实时检测性能的前提下,整体表现较为突出,较好实现了复杂道路场景下的目标检测,也证明了改进的YOLOv5算法的优越性,具有实际的应用价值。
3.5 检测结果可视化
为了更加直观地评价改进算法的优越性,在BDD100K数据集和CQTransport数据集展示出模型改进前后的可视化结果,如图7所示。

图7 不同数据集可视化结果Fig.7 Visualization results of different datasets
通过对两组可视化结果对比分析后,不难发现,复杂道路场景下待检测目标存在大量遮挡,且目标尺度较小,原始YOLOv5s 算法容易出现误检、漏检的问题,另外光线的变暗提升了算法的检测难度,而本文改进的YOLOv5s算法能够更好地识别出复杂道路场景下的遮挡目标及小尺度目标,解决误检和漏检的问题,进而提升算法整体的检测精度。
4 结束语
针对复杂道路场景下密集遮挡目标和小尺度目标检测精度低,易出现误检和漏检的问题,提出了一种基于自适应特征融合的复杂道路场景目标检测算法。以YOLOv5s 算法为基础框架,首先引入特征融合因子改进相邻尺度融合策略,增加各层有效样本,提升中小尺度目标的学习能力;其次提出了一种改进的感受野模块,根据不同尺度目标自动选取合适的感受野,提取更多的目标特征信息;然后增加一层更小目标的检测层,进一步提取小尺度目标的特征信息;最后引入CA注意力机制及Quality Focal Loss 损失函数,提升模型对密集遮挡目标,小尺度目标的检测精度。基于多个数据集的实验结果表明,所提方法在保持算法检测速度的同时获得了更高精度,能在一定程度解决遮挡目标,小尺度目标误检和漏检的问题,相比其他主流目标检测模型,本文改进算法有更高的检测精度和检测速度,更适用于复杂道路场景的目标检测。在未来的研究工作将进一步保持或提升模型的检测精度的同时,对模型进行轻量化改进,便于进行移动端的部署。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
太空探索(2016年5期)2016-07-12 15:17:55
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
时代英语·高三(2014年5期)2014-08-26 17:01:17
河南科技(2014年23期)2014-02-27 14:19:15
