
用户评论中基于事件图谱的代码质量分析
2023-12-27 14:53张培园
计算机工程与应用 2023年24期
张培园,姜 瑛
1.云南省计算机技术应用重点实验室,昆明 650500
2.昆明理工大学 信息工程与自动化学院,昆明 650500
近年来,随着用户需求的不断提高,软件项目的代码规模日益扩大,同时出现了大量的代码托管平台,例如Gitee 凭借其“高速、稳定、通用、源代码管理”等优势迅速获得国内外软件项目开发者的青睐,大量开发人员在代码托管平台进行代码部署,并开源向所有开发者进行学习和交流。但是开源代码托管平台中项目的代码质量参差不齐,用户在选择软件代码时,很难选择出符合自己需求的高质量代码。
为了满足用户需求,代码托管平台允许用户对下载的软件代码进行评论,用户可以通过发表评论与开发者交流软件代码的信息。用户经常在评论中表达他们对应用程序功能的看法,例如评论“代码运行不了,存在很多bug”,其中包含了丰富的代码质量信息,这些信息可以作为其他用户选择软件的依据,并且为应用程序的开发和演变提供帮助[1]。最近的研究表明,用户撰写的评论为应用程序供应商和开发人员提供了丰富的信息来源,它们包括关于bug 的信息、新功能的想法或发布功能信息,对软件的迭代和演进提供了帮助[2]。Anchiêta等人[3]使用无监督的方法对评论进行分类,旨在总结用户指出的主要错误和新功能,通过对用户评论信息进行分析来帮助开发人员修复bug 并实现用户所需的新功能。Li等人[4]提出了一种从应用程序市场比较评论识别移动应用程序的方法,该方法可用于提供基于不同主题的细粒度应用程序比较,帮助用户根据自己的喜好找到所需的应用程序。
以上研究发现,通过对用户评论进行分析,可以帮助开发人员进一步完善和维护应用程序,并且为使用者选择软件提供了参考。但是通过统计发现代码托管平台中有1 500万代码仓库,用户量超过600万,并且由于用户群体不同,用户评论往往体现出数据量大、领域性强、非结构化等特点。因此,如何从海量用户评论中综合分析得到准确的代码质量信息是一个亟待解决的问题。
1 相关工作
目前国内外对于代码质量的分析主要集中在使用静态度量工具对代码进行度量和研究。徐海燕等人[5]提出了包含静态特性和动态特性的代码质量模型,以及识别并分析用户评论中代码质量信息的方法。黄沛杰等人[6]针对Java代码质量度量进行研究,选取了较有代表性的23个代码度量元和包括代码规模、规范性、可维护性、可扩展性和潜在危险5 个方面的质量特性,使用五种静态测试工具对其进行度量和综合分析。孙梦璘等人[7]选取16个度量元作为评价软件质量的度量指标,进而建立评分值分布函数模型,并通过测试9个不同型号的软件确定出模型参数,同时依据度量元权值的不同,对软件进行综合评分,以量化数据的形式计算出软件程序代码的质量水平。
在用户评论分析方面,徐海燕等人[8]提出针对复杂用户评论的代码质量属性判断方法来分析用户评论中的代码质量信息,帮助开发者在了解用户的代码使用情况和用户关注的代码质量属性后有针对性地提升代码质量。Maalej等人[2]使用评论元数据,如星级和时态,以及文本分类、自然语言处理和情感分析技术,将应用程序评论分为四种类型:bug报告、功能请求、用户体验和评级。Panichella等人[9]提出了一种分类法,将应用程序评论分类为与软件维护和演化相关的类别,以及一种融合自然语言处理、文本分析和情感分析三种技术的方法,自动将应用程序评论分类为建议的类别。
通过分析以上研究发现:
(1)当前大多数文献主要对用户评论做分类的任务来分析用户在使用软件过程中的反馈情况,仅对代码质量的部分方面进行分析。例如文献[2]对bug报告、功能请求、用户体验和评级四种类别的用户评论进行分析。文献[6]仅仅针对Java代码中代码规模、规范性、可维护性、可扩展性和潜在危险5 个方面的质量特性进行研究,文献[9]认为用户评论与信息提供、信息查询、功能请求、问题发现四种类型的建议类别相关。然而代码质量通常包括多个方面,例如“可读性”“功能性”等,需要进行更细粒度的划分。
(2)识别代码质量信息不够准确。例如文献[5]通过代码质量特征词库与评价对象进行匹配来识别具有代码质量的用户评论,对于词库中不存在的特征词无法识别。文献[6-7]使用静态测试工具对质量特性或者度量元进行度量分析,而没有考虑程序运行时的动态质量特性;文献[8]对用户评论进行主题划分,仅判断主题间是否存在因果连词来识别代码质量属性表现结果,对于隐性的因果关系无法进行判断,导致识别的代码质量信息不够准确。
因此,为了更全面地分析用户评论中的代码质量信息,本文通过借鉴软件质量模型,构建代码质量层次图对用户评论中的多个方面的代码质量信息进行结构化表示,其次针对代码质量信息识别准确率不高的问题,本文在文献[7]的基础上首先采用事件图谱提取用户评论信息,然后通过映射为代码质量层次图的方法对用户评论进行分析,最后识别代码质量信息。
本文的主要贡献有:(1)基于ISO软件质量模型,构建代码质量层次图。(2)提出一种模式匹配的方法识别事件属性,并构建基于代码用户评论的事件图谱。(3)提出事件图谱到代码质量层次图的映射方法并进一步识别代码质量信息。
2 基于事件图谱的用户评论代码质量分析
在针对代码的用户评论中,用户会对使用代码过程中存在的问题或者针对代码存在的某些质量属性发表主观的评价,并且这些评价通常能够体现多个方面的代码质量信息。因此,本文首先构建代码质量层次图对代码质量信息进行结构化表示;其次通过构建针对代码用户评论的事件图谱对用户评论中的事件进行提取;然后将事件图谱映射为代码质量层次图并对代码质量信息进行识别;最后识别代码质量信息,以此得到用户评论中的代码质量信息。基于事件图谱的用户评论代码质量分析方法流程图如图1所示。
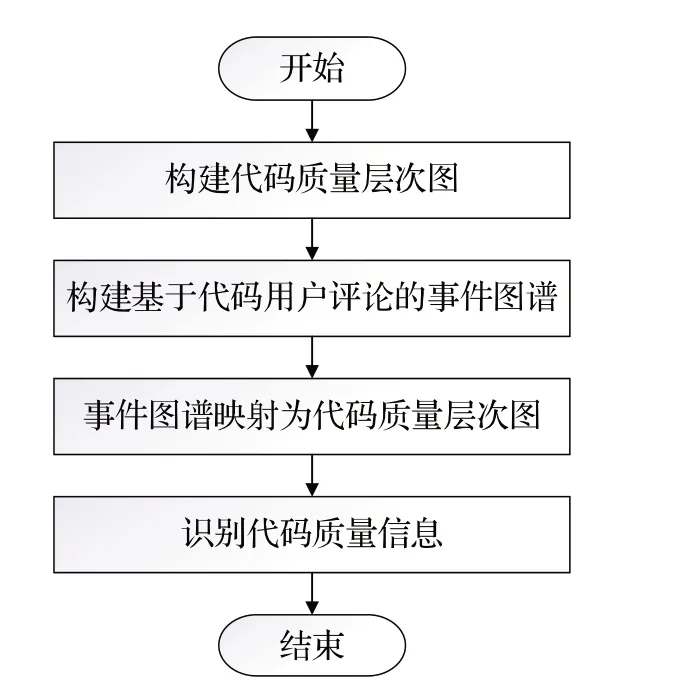
图1 基于事件图谱的用户评论代码质量分析流程图Fig.1 User comment code quality analysis process based on event graph
2.1 构建代码质量层次图
在代码托管平台中,用户通过发表评论对代码的使用情况提出不同的见解。通过对用户评论进行分析发现,在用户评论中,用户能够对不同方面的代码质量进行阐述,但是由于使用代码的用户群体不同,以及软件需求的多样性,用户评论中体现的代码质量信息涉及众多方面。为了分析用户评论中的代码质量,本文基于代码质量模型[8]、ISO软件质量模型[10],构建代码质量层次图(code quality hierarchy diagram,CQHD)。
定义1代码质量层次图表示为CQHD={V,E},V={vroot,vatt,vasp,vres},E={
其中V表示代码质量层次图中的节点,包含四种类型节点,vroot表示第一层以代码质量作为源节点。vatt表示第二层代码质量属性节点,由于用户评论中体现出多个方面的代码质量子属性,因此本文参考文献[8]提出的11个代码质量属性作为代码质量层次图中第二层的节点。vasp表示第三层代码质量属性表现节点,表示对上一层代码质量属性的具体表现,并且通常具有明显的情感倾向,因此将情感倾向作为该层节点的属性。vres表示第四层代码质量属性表现结果节点,是上一层代码质量属性表现引起的某种结果;E表示代码质量层次图中的边,

图2 代码质量层次图(CQHD)Fig.2 Code quality hierarchy diagram(CQHD)
在图2 中,本文使用圆圈代表每一层中的单个节点,使用实线表示相邻层次之间的层级关系,使用虚线表示第二层中相邻代码质量属性之间的关系。
2.2 构建基于代码用户评论的事件图谱
通过分析发现,代码质量的体现是以用户评论中所描述的事件为单位的,用户评论中用户所描述的事情可以被看作事件,事件是一种描述特定人、物、事在特定时间和特定地点相互作用的客观事实[11]。针对代码的用户评论中的事件与代码质量密切相关,通过抽取事件可以认识和理解用户所关注的代码质量,例如用户评论“网页不能访问服务器了”中描述了“访问”这一事件,其体现出代码质量中的“功能性”,事件的具体内容即为代码质量属性表现,并且当两个事件之间存在因果关系时,则一个事件可以作为另外一个事件的代码质量属性表现结果。事件图谱可以对用户评论中的事件进行提取以及对事件之间的关系进行分析和结构化表示,因此本文参考文献[12]提出的事件图谱构建流程对代码用户评论中的事件图谱进行构建,通过事件触发词识别、事件要素识别和事件关系识别建立事件图谱,并基于事件图谱对代码质量进行分析。
事件触发词提取是事件抽取的基础,是能够明确表示事件发生的词或者短语,通常是动词和名词[13]。本文借鉴文献[14]中的方法,提取用户评论中动词、名词和动名词作为触发词扩展表,然后对分词后的用户评论提取词特征、词性特征、句法特征、语义特征和上下文特征,使用支持向量机(support vector machine,SVM)与触发词扩展表相结合的方法对用户评论中的触发词进行识别。
在完成了事件触发词识别之后,需要对事件元素进行识别,事件元素是事件发生的参与者,同样体现代码质量信息。在代码用户评论中,事件的主体元素表示主导或者实施该事件的成分,是体现代码质量的主体对象,可以为分析评论是否对同一主体进行评价提供依据并对判断事件之间的关系提供帮助。事件的客体元素表示事件主体实施该事件的主要接受者,同样体现了代码质量信息,事件的方式元素是引领体现代码质量事件发生的成分,通常以关联词语的形式存在,是事件之间关系的直接体现。另外用户可能对当前事件发生的状态进行描述,体现代码运行时的状态,也是体现代码质量的重要成分。
定义2事件元素表示为一个四元组,Event_elements={S,O,Q,T}。其中S表示主体属性,O表示客体属性,Q表示方式属性,S表示状态属性。
针对代码评论领域事件元素的语义解释如表1所示。

表1 代码评论事件元素表Table 1 Code reviews event elements
通过分析用户评论发现,代码用户评论具有固定句法搭配比较频繁、领域词汇搭配相对固定等特点,并且事件元素与词性密切相关。例如主体和客体元素通常为名词(noun,n),方式元素通常为连词(conjunction,conj)。因此,本文首先对用户评论进行分词和词性标注,然后为了进一步识别事件属性,挖掘各个事件属性与触发词之间的句法关系和存在的普遍规律,本文使用依存句法分析获取用户评论中词与词之间的句法关系。研究发现在依存句法中,事件元素通常与事件触发词表现为主谓关系(subject-verb,SBV)、动宾关系(verb-object,VOB)定中关系(attribute,ATT)、状中结构(adverbial,ADV)、动补结构(complement,CMP)等关系。当评论中的词与事件触发词为SBV 关系或者ATT关系,并且其词性为名词时,可以作为事件的主体属性,与触发词为VOB 关系且词性为名词时,在评论中通常作为宾语,可以作为事件的客体属性。评论中的连词往往引领事件触发词,因此与触发词为ADV 关系的连词可以作为事件的方式属性。状态属性是作为修饰事件触发词当前状态的成份,因此与触发词为ADV结构,或是动宾关系的形容词(adjective,a),或是CMP关系的动词(verb,v)以及修饰动补关系的ADV 结构的词,可以作为事件的状态属性。因此,本文通过制定句法规则模板识别各个事件元素,得到事件结果集。事件元素识别规则如表2所示。

表2 事件元素识别规则Table 2 Event element identification rules
算法1识别事件元素
输入:分词结果集words;词性标注结果集postags;事件触发词word;评论依存句法结果sdp。
输出:识别得到的事件元素集event。
算法1 中,识别事件元素的时间复杂度为O(n),其中n表示评论依存句法结果集合中节点的个数。
在完成事件元素识别之后,研究发现用户评论中可能存在多个事件,针对不同的事件,虽然通常体现出不同的代码质量属性,但是根据代码评论的语言习惯,往往两个事件之间存在某种逻辑关系进行衔接,因此为了帮助分析代码质量属性之间的关系,需要识别两个事件之间的关系。
本文将事件之间的关系划分为转折关系、并列关系、时序关系、原因关系和结果关系。其中转折关系主要体现在事件主体属性不同,并且具有相反情感倾向。例如用户评论“界面很好看,可是代码看不懂”中两个事件主体属性是“界面”和“代码”,并且情感倾向相反。并列关系的事件之间通常体现相同的情感倾向,例如用户评论“已经安装成功了,功能很全面”。原因关系和结果关系也是常见并且重要的一类关系,由于事件发生的先后顺序不同,原因关系是指后一事件是前一事件所发生的原因,相反当前一事件作为后一事件发生的原因时则为结果关系。李良毅等人认为事件时序关系识别有助于读者理清文章脉络,把握全局发展趋势,提出一种双路依存注意力机制来聚合事件句信息,可以使事件时序关系模型的性能得到显著提高[15]。本文借鉴文献[16]中提出的隐式关系识别模型将两个事件的事件元素向量化,使用SVM 机器学习的方法对事件之间的关系进行识别。
通过以上步骤,可以对用户评论进行分析,并构建事件图谱。以用户评论“可能是因为环境配置出错了,所以网页不能访问服务器了,而且代码一直报错”为例构建事件图谱如图3所示。
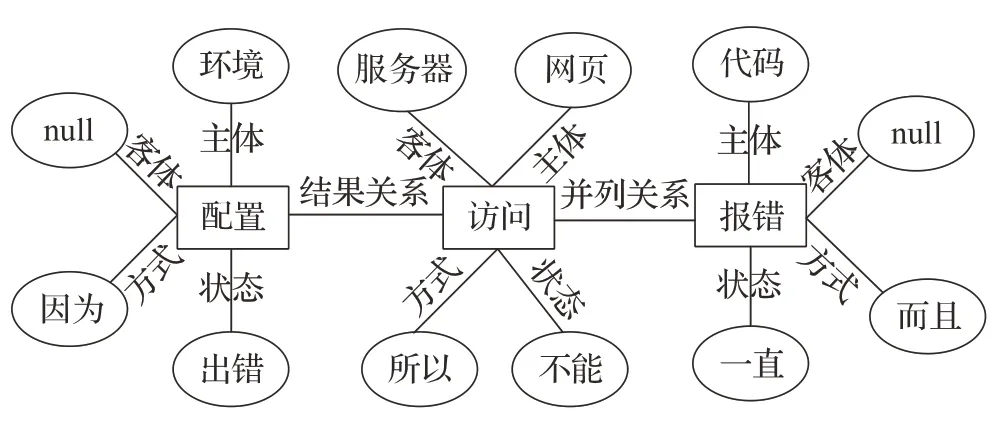
图3 事件图谱示例图Fig.3 Example for event graph
2.3 事件图谱映射为代码质量层次图
在构建了针对代码用户评论的事件图谱之后,可以得到用户评论中一个或多个事件以及事件之间的关系。事件中包含了丰富的代码质量信息,为了将代码质量信息进行结构化表示,需要根据事件图谱中的事件信息以及事件之间的关系将事件图谱映射为代码质量层次图。由于事件触发词是作为事件的核心,体现了具体的代码质量属性,因此将事件触发词与代码质量属性进行映射,事件元素包含了事件的具体描述,与代码质量属性表现进行映射,当事件关系为结果关系时,即后一件事件为前一事件的结果,因此,可以向下映射出第四层代码质量属性表现结果的节点,当事件关系为原因关系时,即后一事件为前一事件的原因,因此先出现代码质量属性表现结果的节点,可以向上映射出第三层代码质量属性表现的节点。另外,当事件关系为转折关系、并列关系和时序关系时,往往存在不同的代码质量属性以及情感倾向,因此,以事件元素的情感倾向映射为代码质量属性间关系。代码事件图谱到代码层次图映射规则如表3所示。

表3 事件图谱到代码质量层次图映射表Table 3 Event graph to code quality hierarchy graph
算法2代码质量层次图映射算法
输入:事件图谱中的事件events;事件之间的关系relations。
输出:映射得到的代码质量层次图G。
在算法2中,映射代码质量层次图的时间复杂度为O(e),其中e表示事件图谱中事件的个数。
通过以上方法,可以将事件图谱映射为代码质量层次图。以上文用户评论为例,将图3映射得到的代码质量层次图如图4所示。
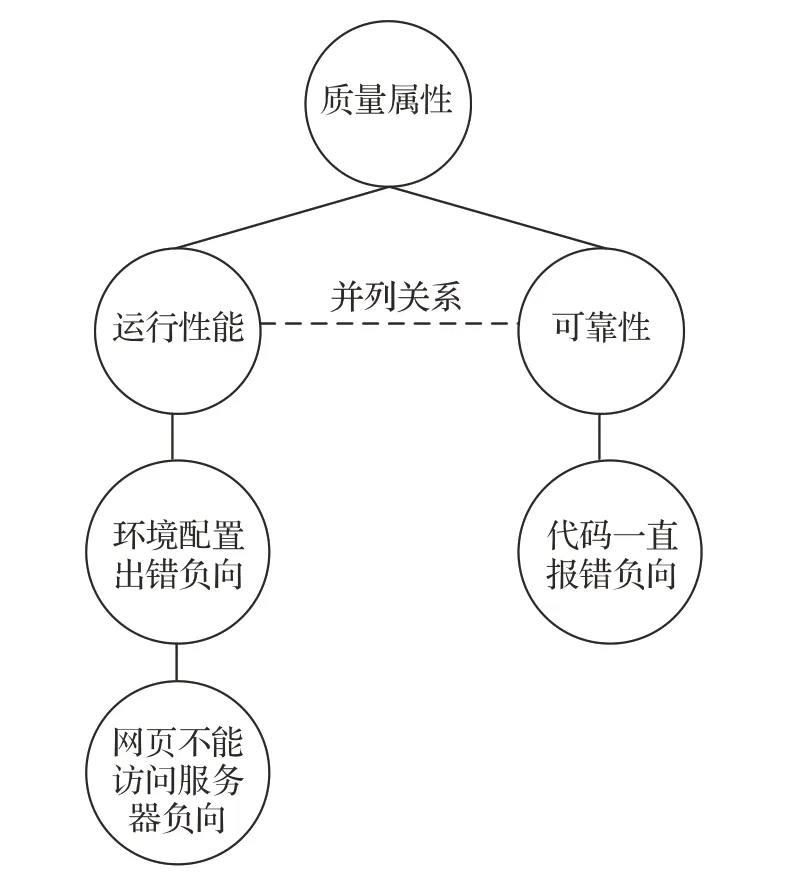
图4 代码质量层次图示例图Fig.4 Example of code quality hierarchy diagram
2.4 识别代码质量信息
在使用事件图谱映射为代码质量层次图之后可以发现,代码质量层次图可以将用户评论中的多个方面的代码质量信息进行结构化表示,通过对代码质量层次图进行遍历,可以进一步识别代码质量信息。但是通过对大量代码质量层次图分析发现,由于用户评论中事件和事件关系不同,导致映射得到的代码质量层次图结构不同。当评论中只存在一个事件时,则映射得到的只有三层节点的代码质量层次图,例如用户评论“这个软件界面真好看”,映射得到的代码质量层次图仅包含了前三层节点,缺少第四层节点。当用户评论中只存在事件的状态属性时,则映射得到的代码质量层次图仅包含第一层和第四层节点,例如用户评论“简直太棒了”映射得到的代码质量层次图缺少第二层和第三层节点,因此为了方便对代码质量信息进行识别,本文将一个代码质量信息描述为一个代码质量三元组E=(a,e,r)。
其中E表示一个代码质量信息,并且包括三个元素,a表示代码质量属性,e表示代码质量属性表现,r表示代码质量属性表现结果。又由于每条用户评论中往往包含多个代码质量信息,因此使用代码质量三元组集对一条评论中多个代码质量信息进行表示CodeAttInfo={E1,E2,…,En}。其中CodeAttInfo表示一条评论的代码质量信息,第n个代码质量三元组表示为En。
从代码质量层次图的第二次节点开始,每层节点的信息与代码质量三元组的三个元素是一一对应的,因此,为了获取代码质量层次图中的代码质量信息,可以对代码质量层次图进行深度优先搜索,即除最高层节点以外,从第二层节点开始进行遍历搜索至最低层节点,得到一个代码质量信息,直至代码质量层次图中的所有节点遍历完成,识别得到最终的代码质量信息。
算法3识别代码质量信息
在算法3 中,识别代码质量信息的时间复杂度为O(t),其中t表示代码质量层次图中代码质量属性节点的数量。
通过以上遍历代码质量层次图的方法,可以识别出用户评论中的代码质量信息。例如上文图4 中识别到的代码质量信息为:codeAttInfo={(运行性能,环境配置出错,网页不能访问服务器),(可靠性,代码一直报错,null)}。
3 实验及分析
本文从开源中国推出的代码托管平台Gitee网页中爬取了与代码相关的用户评论,选取了总共21 500条评论进行实验。
使用本文方法对用户评论进行分析,由于代码质量层次图中的结构不同,识别得到的代码质量三元组类别不同,具有不同类型代码质量三元组的用户评论数量和占用户评论数的比例以及示例如表4所示。
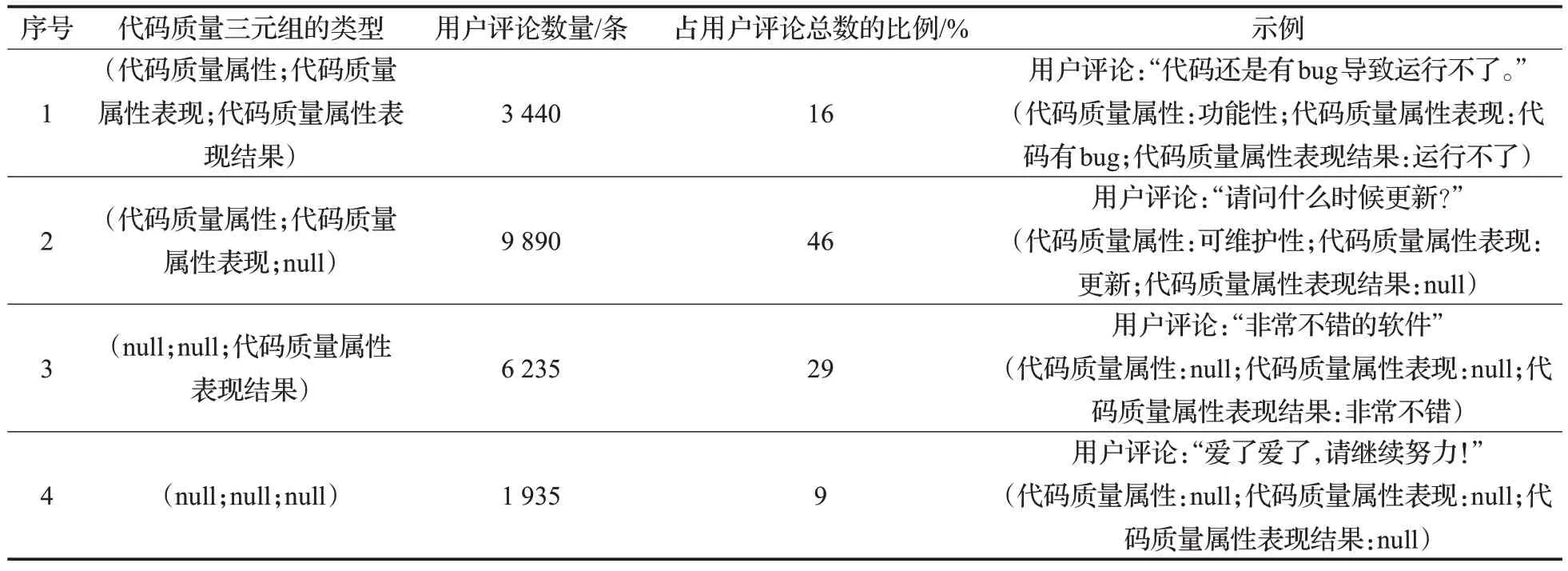
表4 不同类型代码质量三元组的评论数量及示例Table 4 Number of comments and examples for different categories of code quality triples
为了验证本文方法对每种代码质量三元组识别的有效性,以文献[5]和文献[8]方法作为对比方法进行实验,并分析上文四种代码质量三元组类型的识别结果。对比结果如图5所示。
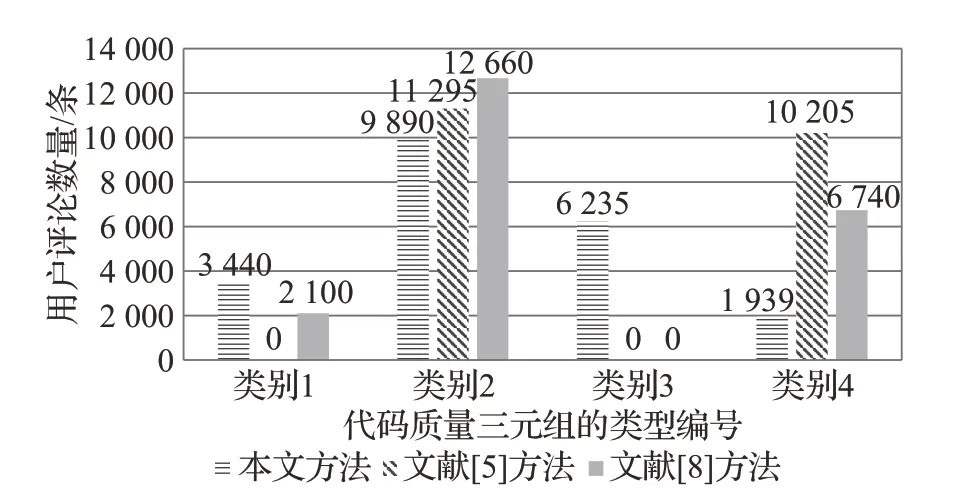
图5 识别代码质量三元组对比结果图Fig.5 Graph of identify code quality triplet comparison results
实验结果表明,本文方法对于类别1 和类别3 的代码质量三元组识别数量均优于对比文献方法,是由于基于事件图谱可以提取事件之间隐性的因果关系,因此识别得到的具有代码质量属性表现结果的三元组数量较多。文献[8]方法对于第2 种类别的代码质量三元组识别数量更多是由于存在部分代码质量属性表现结果未被识别导致,并且对于类型3的代码质量三元组未进行识别。文献[5]方法对第4 种类别的代码质量三元组较多,原因是文献[5]使用句型规则匹配来识别评价对象和评价观点,评价观点识别的误差会导致代码质量信息识别出现误差,另外文献[5]方法并未对代码质量属性表现结果进行识别,对代码质量信息识别不够全面。
针对识别到代码质量属性的代码质量三元组所对应的13 330 条用户评论,参考文献[8]中提到的11 种代码质量信息,统计识别到的每种代码质量属性的数量如图6所示。
由图6可知,本文方法可以对11种代码质量属性进行识别,并且用户往往更关注的是功能性,对可重用性关注度较低。与对比实验相比,文献[8]方法采用主题识别可能会出现主题漏判的情况导致代码质量属性识别不够充分,文献[5]方法过于依赖特征词库和词性规则,当评论中出现词库中未收录的特征词时无法进行识别,因此,除个别代码质量属性(“编程规范性”“可维护性”和“可靠性”)外,本文方法对其余代码质量属性识别都优于对比实验方法。
为了进一步分析本文方法准确性,将本文方法与对比实验方法分析得到的结果与人工标注的结果进行对比,计算识别到三种代码质量信息的准确率如表5所示。
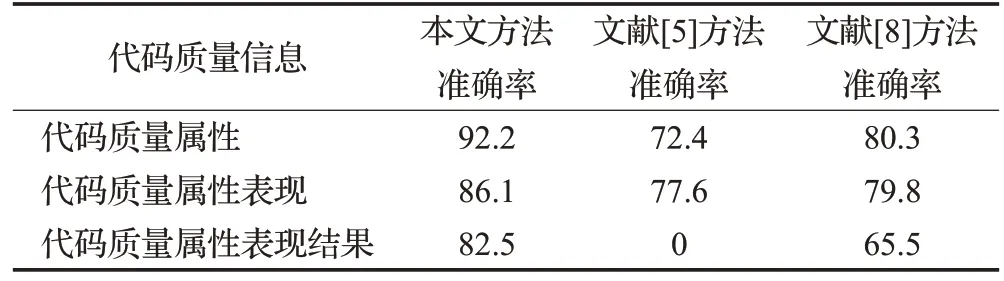
表5 识别代码质量信息准确率Table 5 Accuracy of identification code quality information 单位:%
由表5 发现本文方法对三种代码质量信息识别的平均准确率为86.9%,文献[5]方法的平均准确为75.0%,文献[8]方法的平均准确率为75.2%,因此本文方法准确率均优于对比文献方法。在算法时间复杂度方面,本文方法时间复杂度为O(n+e+t),优于对比实验方法。但是由于本文方法依赖依存句法分析的结果,当用户评论中存在代码片段或者以中英文结合的方式时,无法使用依存句法进行分析,导致存在一定的误差,下一步需要进一步优化算法,减少对依存句法的依赖,进一步提高代码质量信息识别的准确性。
4 结束语
本文提出代码质量层次图的构建方法,并将用户评论信息使用事件图谱进行结构化表示,然后将其映射为代码质量层次图,并基于该代码质量层次图对代码质量信息进行识别。实验结果表明,本文方法针对数据量大,结构复杂等特点的代码用户评论中的代码质量信息能够进行有效识别。但是,由于本文方法依赖依存句法关系,导致在抽取事件元素时存在误差,最终导致识别代码质量信息存在偏差。下一步需要持续改进算法,同时考虑回复评论对原始评论的影响,对残缺的代码质量信息进行推理和补全,得到更准确的代码质量信息。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
国际眼科杂志(2021年9期)2021-09-15
少先队活动(2020年12期)2021-01-14
装备制造技术(2020年2期)2020-12-14
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
