
对稀疏点云规则化处理的分类卷积神经网络
2023-12-27 14:53李恒宇杨家志张峻恺
计算机工程与应用 2023年24期
李恒宇,杨家志,沈 洁,张峻恺
1.桂林理工大学 信息科学与工程学院,广西 桂林 541004
2.广西嵌入式技术与智能系统重点实验室,广西 桂林 541004
近年来,3D扫描设备和技术的发展,促进了许多依赖3D 点云数据的应用兴起。例如,机器人、自动驾驶、AR等,因此,如何高效地处理点云数据逐渐成为了人们关注的焦点。深度学习被广泛应用在计算机视觉、语音识别和自然语言处理等研究领域,同时也常常被用于点云分类实验。但是,由于三维点云数据集规模小、维度高、结构无序和稀疏性等特点[1],导致深度卷积神经网络在对三维点云数据处理时存在一定难度。
目前主流的点云分类方法分为三种:基于多视图的方法、基于体素化的方法和基于点的方法。基于多视图的方法是将三维形状投影到多个视图中,提取视图特征,然后融合这些特征来进行准确的形状分类。这种方法通常会造成大量信息丢失。因为是将三维数据投影成了二维数据,三维数据的内部结构无法获取,导致几何的内在关系被破坏,三维空间的上下文信息无法有效利用。基于体素化的方法是将点云转化为规则的三维网格,在三维网格上使用卷积神经网络。这种方法会受到体素大小这一个关键因素限制,因为需要体素化后的规则体素网络作为输入,体素分辨率的高低将直接影响到整体精度。体素的分辨率低则导致有用信息丢失、整体精度降低,体素的分辨率高提升整体精度的同时也导致了庞大的计算量和严重的内存占用[2-3]。基于点的方法是将点云的三维坐标(x,y,z)轴作为输入,直接对点云三维坐标进行卷积操作。许多算法得利于基于点的方法可以保留点云信息的完整性和算法性能良好,在多个数据集上都取得了不错的效果。基于原始点云的算法现如今是基于深度学习的点云处理的主要研究趋势[4]。
Qi 等人[5]提出了PointNet 的方法,开创了基于点的方法的先河。PointNet使用多个共享的多层感知器(multilayer perceptron,MLP)对输入的点云进行学习,并使用最大池化来获得全局特征,最后使用全连接层(fully connected layer,FC)进行最终的分类。但是这种设计中每个点的特征都是独立学习的,因此忽略了点与点之间的结构关系。白静等人[6]提出的LightPointNet虽然优化了参数量,减少了训练时间,但仍存在忽略空间信息的问题。闫林等人[7]提出的双路径神经网络模型虽然能够挖掘到局部粒度特征,但临近点参数对不同数据集有较大影响,需要手动设置,这就导致算法的适应性受到影响。由Qi等人[8]提出的PointNet++通过构建抽象层来从每个点的邻域构成的局部区域捕捉精细的几何结构,从局部几何结构中学习并逐层提取局部特征。虽然简单地划分了几个局部区域进行局部特征学习,但是没有考虑到点与点之间的关系。Wang 等人[9]在DGCNN(dynamic graph CNN)中提出了一种边缘卷积(edge convolution,EdgeConv)的方法,通过与K近邻点构建局部图结构,之后使用共享的MLP 层对图的每一个边缘进行卷积获取邻边特征,最后使用最大池化的方式来对每一个邻边特征进行聚合获取局部特征,并在网络的每一层之后动态更新。这种方法增强了局部结构中点与点之间的关联,但由于点云并不是均匀分布的,近邻点对于中心点的影响也是不同的,而边缘卷积平等的处理每一个邻边,这对分类结果造成了影响。二维图像数据是机构化存储的,因此每个像素的顺序也是固定的。卷积直接就能从这种潜在的空间结构中获取信息。然而,因为点云稀疏性、无序性、有限性等特点,卷积并不合适用来获取数据间的局部相关性。Point-CNN[10]提出一种X 变换方法,先对点云数据进行处理,然后利用卷积操作,对点云进行处理。X变化可以使点云数据实现数据的“规则化”和加权与点相关联的输入特征的权重,无序性得到解决,相当于顺序发生变化但是得到的卷积效果是相同的。相比其他方法,PointCNN 的参数更少,但是在部分数据上表现出过拟合的问题。
论文基于深度学习方法,针对直接使用卷积提取点的相关特征将导致特征信息的丢失问题,提出了一种经过X 变换后的点云分类卷积神经网络(convolutional neural network based on X-transform,XTNet)。XTNet对输入的原始点云数据进行X变换,将它们置换成潜在的规范顺序,使用K近邻算法构建局部区域,在局部特征提取中使用加宽和跳跃连接的方法缓解过拟合,丰富特征信息。在标准公开数据集ModelNet40和真实数据集ScanObjectNN 中进行了实验,实验结果表明与目前主流的多个高性能网络相比,XTNet分类准确率提高了0.3~4个百分点,并且拥有良好的鲁棒性和普适性。
1 XTNet神经网络模型
XTNet是使用原始点云数据三维坐标(x,y,z)作为输入的网络模型。卷积神经网络(convolutional neural network,CNN)在各种任务上取得成功的一个关键因素是卷积算子能够非常有效地利用数据的空间局部相关性。这是多数类型数据具有的普遍属性,且与数据的表示方式无关[11]。然而,因为点云具有稀疏性、无序性、有限性等特点,卷积算子不能充分提取局部空间相关性,直接使用卷积提取点的相关特征将导致形状信息的丢失。XTNet先将输入的点云数据进行X-变换,将混乱无序的点云数据转变成潜在的规范顺序以减小因为点云的无序、不规则对卷积其造成的影响。然后将转换后的数据送入局部特征提取模块,学习和提取局部特征。在局部特征提取的同时设置稠密连接增强信息的传递。其次在局部特征提取结束后,通过堆叠局部信息后提取全局信息。最后通过全连接层和Softmax函数分类和输出。XTNet整体网络结构如图1所示。

图1 XTNet整体网络结构图Fig.1 XTNet overall network structure diagram
1.1 X-变换
相较于常规2D 图片,多个点组成的点云其位置顺序有很多种变换可能。如果直接进行卷积操作,那么输入点的顺序发生变化,输出的也会随之变化。为了抑制输入点云的顺序阻碍卷积操作,先对输入的原始点云数据进行X-变换。X-变换是PointCNN 提出的一种Xtransformation Conv 算子,即X-Conv 的核心部分,首先定义一个X-变换矩阵,这个矩阵可以对输入的带有特定顺序的数据进行处理来获得一个与顺序无关的特征。X-Conv 先经过X 变换矩阵处理,再执行卷积操作。X-Conv算法公式由式(1)所示:
P=(p1,p2,…,pk)T表示邻近点;F=(f1,f2,…,fk)T表示邻近点的特征;K表示卷积的的kernel;p表示目标点(query point,or representative point);Fp表示目标点更新后的特征。因为上式可微,故X 变换的矩阵同样可微,进而可以进行反向传播。
1.2 稠密连接
如果卷积网络包含接近输入层和接近输出层之间的较短连接,则卷积网络可以更深入、更准确和高效地进行训练[12]。因此在本文模型中加入了稠密连接,在本文局部特征提取块中都有D×(D+1)/2 个连接,其中D表示第D个局部特征提取模块D∈(1,2,3)。引入稠密连接有以下好处:缓解了消失梯度问题,加强了特征传播,加强了特征传递,间接地减少了参数数量。
1.3 局部特征提取
很多的经典网络都证明过点云局部结构的构建对于点云高维特征的提取是至关重要的[8-9,13]。局部特征提取能力将间接影响算法识别细粒度模式的能力和对复杂场景的泛化能力。XTNet局部特征提取模块如图2所示,其中f为输入通道数,d为输出通道数。
在XTNet 局部特征提取模块中,首先采用K近邻(K-nearest neighbors,KNN)的方式计算离中心点最近的k个点,将中心点与邻近点组合构建一个局部区域。然后使用二维卷积对局部区域提取k个高维的近邻边特征。在得到k个近邻边特征后用最大池化函数将k个邻边特征聚合为中心的局部特征。X 变换减小了点云无序性对卷积的干扰,将输入数据使用一个1×1卷积扩充通道数后与从k个邻近区域提取到的局部特征相加,一方面每一层可以学习到更加丰富的特征,比如不同方向、不同频率的纹理特征[14-15];另一方面可以增强了信息流通,使上一个局部特征信息直接传导给下一个局部特征提取模块。并且一定程度上起到了抑制梯度消失和退化的问题,表达式如式(2)所示:
1.4 聚合函数
多数现有的网络算法通常采用最大池化函数或者平均池化函数,这样可以保持网络的对称性,但可能存在信息丢失的问题。为减少这方面带来的影响,本文采用将数据分别使用最大池化函数和平均池化函数聚合后再拼接的方法来对特征进行聚合。即保持了网络的对称性,还减少了信息丢失。
2 实验结果与分析
这部分首先与其他经典网络在ModelNet-40 和ScanObjectNN 数据集上的效果进行对比,并对实验结果进一步分析;然后对各模块做消融实验;最后对网络进行鲁棒性和网络复杂度测试。
2.1 数据集
ModelNet40数据集[16]:ModelNet40数据集是Princeton大学公开的三维模型分类标准数据集。ModelNet40 由9 843个训练模型和2 468个测试模型组成,分为40个类。
ScanObjectNN数据集[17]:本文通过ScanObjectNN数据集来证明本网络模型的鲁棒性。这是一个新的基于扫描室内场景数据的真实世界点云对象数据集,数据集包含约15 000个对象,这些对象被分为15个类别,有2 902个唯一的对象实例。因为来自真实世界扫描的对象经常与背景混杂或部分被遮挡而对现有点云分类技术提出更大挑战。
2.2 实验环境及参数设置
实验所用硬件环境为Intel Core i5-11400k CPU+RTX3060(12 GB 显存)GPU,软件环境为Windows11+CUDA11.3.1+cuDNN8.2.1+Pytorch1.10.1+Python3.8。网络优化器选择的是随机梯度下降法(stochastic gradient descent,SGD),学习率设置为0.1,训练批次大小设置为16,训练最大周期设置为250,K值设置为20,激活函数使用的是将斜率设置为-0.2 的Leaky-ReLU,并在每个MLP后面加入设置为0.5dropout层用来抑制过拟合。
2.3 分类实验
本实验输入为仅含1 024 个x、y、z轴三维坐标的点云数据,在实验结果表1 中用1 kpoint表示仅含1 024个三维坐标的点云数据作为输入,同理2 kpoint、5 kpoint分别表示输入的是仅含2 048、5 120个三维坐标点云数据,nor 表示输入了额外的法向量信息,1 kpoint+nor 表示使用了1 024个三维坐标的点云数据和额外的法向量信息作为输入,5 kpoint+nor则表示使用了5 120个三维坐标的点云数据和额外的法向量信息作为输入,vot 表示使用了多次投票验证策略,Volumetric 表示输入的是体素化数据。本文对于分类结果的评价标准采取的是最常用的整体精度(overall accuracy OA)和平均类精度(mean accuracy,mAcc),“OA”表示所有测试实例的平均精度,计算方法如公式(3)所示:
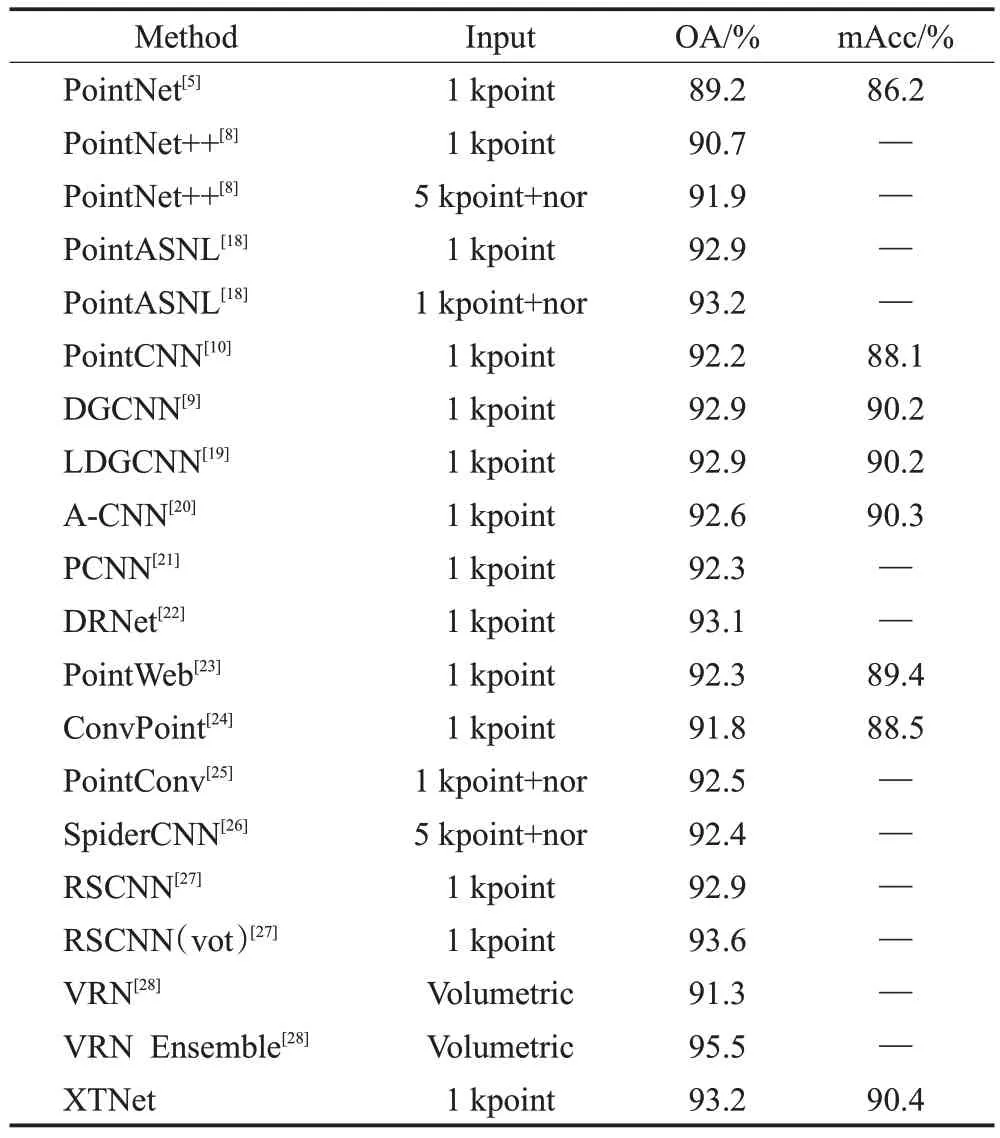
表1 ModelNet40数据集上的分类结果Table 1 Classification results on ModelNet40 dataset
TP(True Positive)表示将正类预测为正类数,TN(True Negative)表示将负类预测为负类,FP(False Positive)表示将负类预测为正类数误报,FN(False Negative)表示将正类预测为负类数漏报。
mAcc 表示所有形状类别的平均精度,计算方法如公式(4)所示:
其中,M是样本类总共分成的类别数目,classiacc是第i类的精确度,i∈(1,2,…,M),hits是预测正确的数量,preds参与预测的样本总量。
对比的网络模型和分类结果均取自数据集官网公布的主流且效果领先的网络模型和数据。
表1 给出了XTNet 和当前主流网络在ModelNet40上的分类结果。从结果上对比可以看出,XTNet整体精度达到93.2%,平均精度为90.4%,与同样是仅输入1 kpoint的网络相比达到领先的结果。还有如PointNet++和SpiderCNN 在输入了额外5 kpoint 和法向量信息后分类精度仍低于本网络。与RSCNN 相比,在仅输入1 kpoint数据时XTNet分类结果优于RSCNN,在使用了10次投票机制后也仅低了0.4个百分点。与分类结果最好的VRN Ensemble 相比,VRN Ensemble 采用的是基于体素化的方法,它充分地发挥了这类方法的优势,在ResNet[15]的基础上设计,搭建了更深、更复杂的网络模型。因此得到了很好的分类结果。但是这种基于体素化的方法需要繁琐的体素化操作且受分辨率大小影响,更深层次的卷积也意味着需要消耗更多的时间、硬件资源。
为了验证XTNet 的鲁棒性和对真实世界数据集的效果,本文在ScanObjectNN 数据集上也进行了分类实验,分类结果如表2 所示。在同样仅是输入1 024 个点云坐标的情况下,XTNet的整体精度为78.7%,平均精度为73.3%,和数据集官网公布的其他几个网络模型相比,都取得了不错的效果,进一步说明了XTNet 具有强鲁棒性。
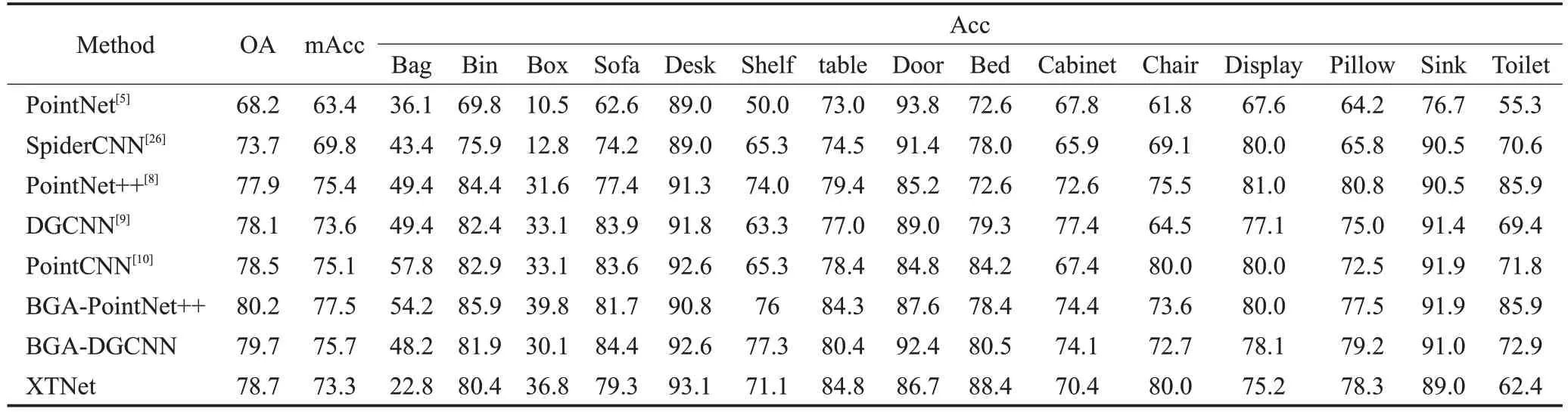
表2 ScanObjectNN数据集上的分类结果Table 2 Classification results on ScanObjectNN dataset 单位:%
2.4 不同模块消融实验
为了验证网络中不同模块的效果,本文还对网络模型进行了消融实验。实验均在数据集ModelNet40上进行,实验结果如表3所示。

表3 模块消融实验结果Table 3 Results of module ablation experiments
网络0是输入仅为1 kpoint的DGCNN的分类结果,在网络1中,将网络0结构修改成与本文网络结构一致,由于缺少了一个特征提取模块,整体精度下降到了90.1%,平均精度下降到84.2%。网络2在网络1的基础上,将用X 变换模块替换掉网络1 的转换模块,整体精度提升到了91.3%,平均精度提升到了88%,可以看出X变换比原来的变换模块更有效果。网络3在网络2的基础上再增加残差连接,增加了模型宽度,增强了特征提取能力,相比之前整体精度和平均精度都有提升。网络4启用了所有模块,整体精度达到93.2%,平均精度达到90.4%。
2.5 鲁棒性实验
本文还在ModelNet40数据集上进行了采样密度鲁棒性实验。分别将点云采样数量设置为128、256、512、1 024。图3是不同采样点采样可视化结果,表4是使用不同采样点时的整体精度。图4是与PointNet、PointNet++、PCNN、DGCNN做对比的结果,可以看到其他网络模型随着采样点的减少,分类精度大幅下降,而本文网络模型仍有90%以上的准确率,进一步说明了本文网络鲁棒性更好。图5显示了不同采样点精度随训练周期epoch变化的变化曲线,在前几轮学习率较大时有少许抖动,随训练周期增加,学习率衰减后不同采样点的训练曲线都无明显抖动。

表4 不同采样点的整体精度Table 4 Overall accuracy in different sampling points
图3 不同采样点的可视化结果Fig.3 Visualization results for different sampling points
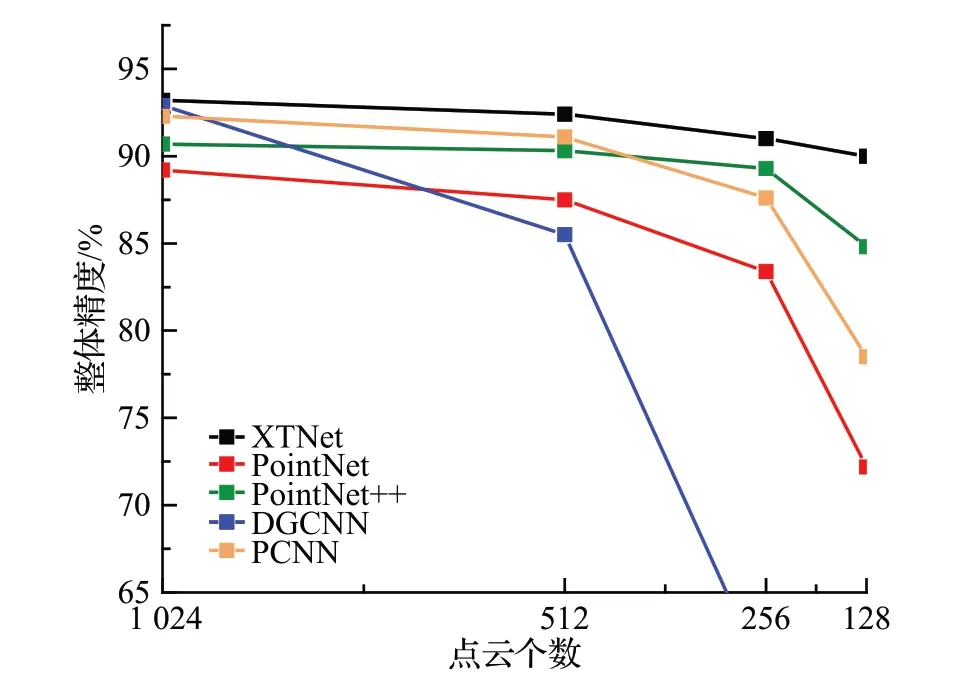
图4 不同采样点下多种模型的分类效果Fig.4 Classification effects of multiple models at different sampling points

图5 不同采样点下XTNet整体精度的变化曲线Fig.5 Variation curve of overall accuracy of XTNet at different sampling points
2.6 网络复杂度实验
本节通过对比网络的参数量(parameters)和浮点运算数(floating point operations,FLOPs)来说明网络的复杂度。数据通过Facebook 提供的fvcore 工具对作者公开的模型代码提取,获取各网络模型的复杂度,网络模型的复杂度对比如表5所示。

表5 网络复杂度Table 5 Network complexity
对比PointNet++和DGCNN,XTNet 在整体精度上有不同程度提高,并且参数量和浮点运算数都有一定的减少;与PointCNN 相比参数量和浮点运算数都有明显上升,但是整体精度提升了1个百分点。可以看出XTNet在参数量和浮点运算数做到了让网络尽量更轻的同时不对精确度产生影响。
2.7 超参数K 的取值
在本节中讨论了KNN 算法中的K的取值对模型性能的影响。KNN中的K值选取对分类的结果影响至关重要,K值选取得太小,学习的估计误差会增大,预测结果对近邻的实例点非常敏感;K值选取得太大,导致学习的近似误差增大,与输入实例较远的训练实例也会对预测起作用,使预测发生错误。本实验采用ModelNet40数据集,在输入1 024个点,迭代250次的情况下对不同的K值做了详细的测试,测试结果如表6所示。不同K值随周期变化的变化曲线如图6 所示。根据测试结果和2.5节的分析中,K值选20时分类结果最好,并且不会因为采样点数的减少在训练过程中出现大的抖动,所以本文超参数K取20。

表6 不同K 值对模型的影响Table 6 Effect of different values of K on model
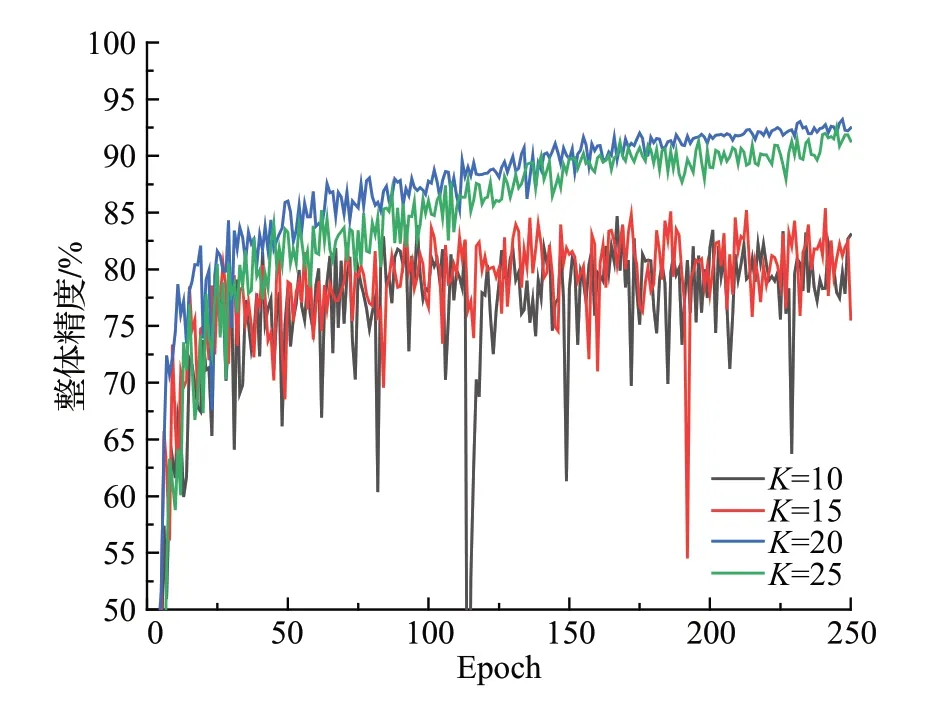
图6 不同K 值下XTNet整体精度的变化曲线Fig.6 Variation curve of overall accuracy of XTNet with different K values
3 结论
针对点云稀疏性、无序性、有限性等特点造成的信息丢失、神经网络模型过拟合等问题,本文提出一种用于点云分类的卷积神经网络模型,可以有效地聚合点云局部和全局特征。首先通过X 变换将原始点云变成潜在的规则矩阵,减少点云的无序性对卷积的干扰;然后通过KNN构建局部区域并使用卷积模块从中提取局部特征,同时用1×1 卷积拓宽模型并构建残差块,对多个局部特征提取模块做稠密连接,丰富特征的同时抑制过拟合;最后使用池化层从堆叠的局部特征中提取全局特征。从ModelNet40和ScanObjectNN两个数据集上的分类结果可以看出:XTNet 与现有的网络模型相比,精度上达到了领先的水平,且通过采样密度鲁棒性实验以及网络复杂度实验证明了本文网络的稳定性和拥有更低的复杂度。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年2期)2021-06-09
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
噪声与振动控制(2015年4期)2015-01-01
