
FPGA平台轻量化卷积神经网络辐射源信号识别方法
2023-12-27 12:59肖帅龚帅阁李想王昊陶诗飞
计算技术与自动化 2023年4期
肖帅,龚帅阁,李想,王昊,陶诗飞†
(1.电子信息系统复杂电磁环境效应国家重点实验室,河南 洛阳 471003;2.南京理工大学 电子工程与光电技术学院,江苏 南京 210094;3.北方电子设备研究所,北京 100191;4.南湖实验室,浙江 嘉兴 314050)
电磁信号频谱是一种重要的战略资源,对电磁信号的有效识别具有重要意义。随着雷达技术和通信技术的发展,电磁信号的波形具有多样、捷变以及复合调制等特性,其密度也呈指数级激增,导致信号识别的难度大幅增加。早期学者提出了参数匹配法来识别雷达信号[1]。参数匹配法通过测量截获雷达信号的参数,并与雷达信号数据库进行匹配,从而识别出雷达信号。但该方法对先验知识依赖程度高。针对通信信号,研究人员则提出了自动调制识别方法[2]。自动调制识别方法主要包含基于决策理论的最大似然假设检验方法[3]和基于特征提取的统计模式识别算法[4]。基于决策理论的方法对信道环境适应性差,容易出现模型失配问题。基于统计模式识别方法需要人为提取特征,对特征选取要求较高。
传统人为提取信号特征的方式容易造成信息遗漏,近年来的研究开始利用变换域特征结合深度学习进行信号分类识别[5]。深度学习可以处理多维数据并具有强大的特征提取能力,已广泛应用于雷达信号[6]和通信信号[7]的识别。利用深度学习识别信号时,为了保证识别的准确率,常常采用深层神经网络[8]。Lin等[8]便提出了一种残余注意多尺度累积深度卷积网络,通过融合残差连接和注意连接提取到雷达信号丰富的特征,并利用结构多尺度累积连接来提高特征利用率,网络在低信噪比下仍具有较强的识别能力。虽然深层神经网络识别准确率高,但是需要巨大的算力、存储和功耗,难以在边缘侧的小型化设备部署。因此,在信号识别任务中神经网络的轻量化设计十分重要。神经网络的轻量化方法主要包含两类:一方面是对传统的卷积神经网络的结构进行改进,形成了以SqueezeNet网络[8]、MobileNet网络[10]、ShuffleNet网络[11]和GoogleNet网络[12]等为代表的轻量化网络结构;另一方面研究者通过分析网络结构的特点提出了模型剪枝、低秩分解、知识蒸馏和参数量化等神经网络轻量化方法[13]。何重航等[14]利用深度可分离卷积结构设计了轻量化卷积神经网络,通过对抗学习,对-2 dB~-4 dB的信号识别准确率提升至90%以上,证明了轻量化网络在信号识别领域的可行性。但经过轻量化设计的神经网络相比于原始网络识别准确率降低。因此,探索出一种高效的轻量化方法十分重要。
深度学习的应用和发展的离不开硬件支持,硬件的算力、存储能力和功耗也成了神经网络算法设计一个重要的关注点。由于早期中央处理器(Central Processing Unit, CPU)串行执行指令的方式限制了神经网络的进一步发展,目前更多的神经网络算法通过图形处理器 (Graphic Processing Unit, GPU)完成。但GPU在算力增加的同时,功耗也成倍增加,在边缘场景应用受限。因此,学者开始使用现场可编程逻辑门阵列(Field Programmable Gate Array, FPGA)加速神经网络推理[15]。FPGA具有可编程性、可重用性和低功耗的优点,能够实现并行计算。面对现代电磁信号认知的低延时和低功耗需求,FPGA具有很大优势。目前FPGA加速神经网络大多将权重和中间特征图缓存在外部存储器DDR中,存储器和计算单元之间数据传输存在较大的延迟。孙明等[16]采用乒乓结构减少了这种延迟,并针对FPGA进行了网络的并行化设计。但这些方法仅考虑了硬件层面的加速,对网络的轻量化设计考虑较少。
针对上述问题,本文利用深度神经网络提取信号的时频特征,通过知识蒸馏融合深度可分离卷积完成神经网络轻量化,并建立注意力特征图以提高知识蒸馏的效率,减少因网络轻量化造成的准确率损失,然后面向FPGA对轻量化网络进行结构优化和并行设计,完成轻量化信号识别方法从算法设计到硬件部署的完整流程。本文在第1节阐述了基于知识蒸馏的神经网络轻量化的方法;在第2节基于FPGA加速了第1节设计的轻量化信号识别网络;在第3节给出了轻量化网络识别信号的结果,并分析了算法和硬件系统的有效性;第4节总结了本文工作并对工作的扩展性做出了展望。
1 基于知识蒸馏的轻量化分类网络设计
轻量化信号识别方法包括知识蒸馏和FPGA加速两部分,总体框图如图1所示。知识蒸馏利用教师网络和学生网络提取信号的时频特征,通过最小化注意力损失和蒸馏损失实现学生网络对教师网络的学习,利用深度可分离卷积进一步稀疏网络,实现了将教师网络轻量化为学生网络的目的。最后在FPGA平台通过参数量化、参数融合、循环优化和流水线设计等方法加速信号的识别过程。
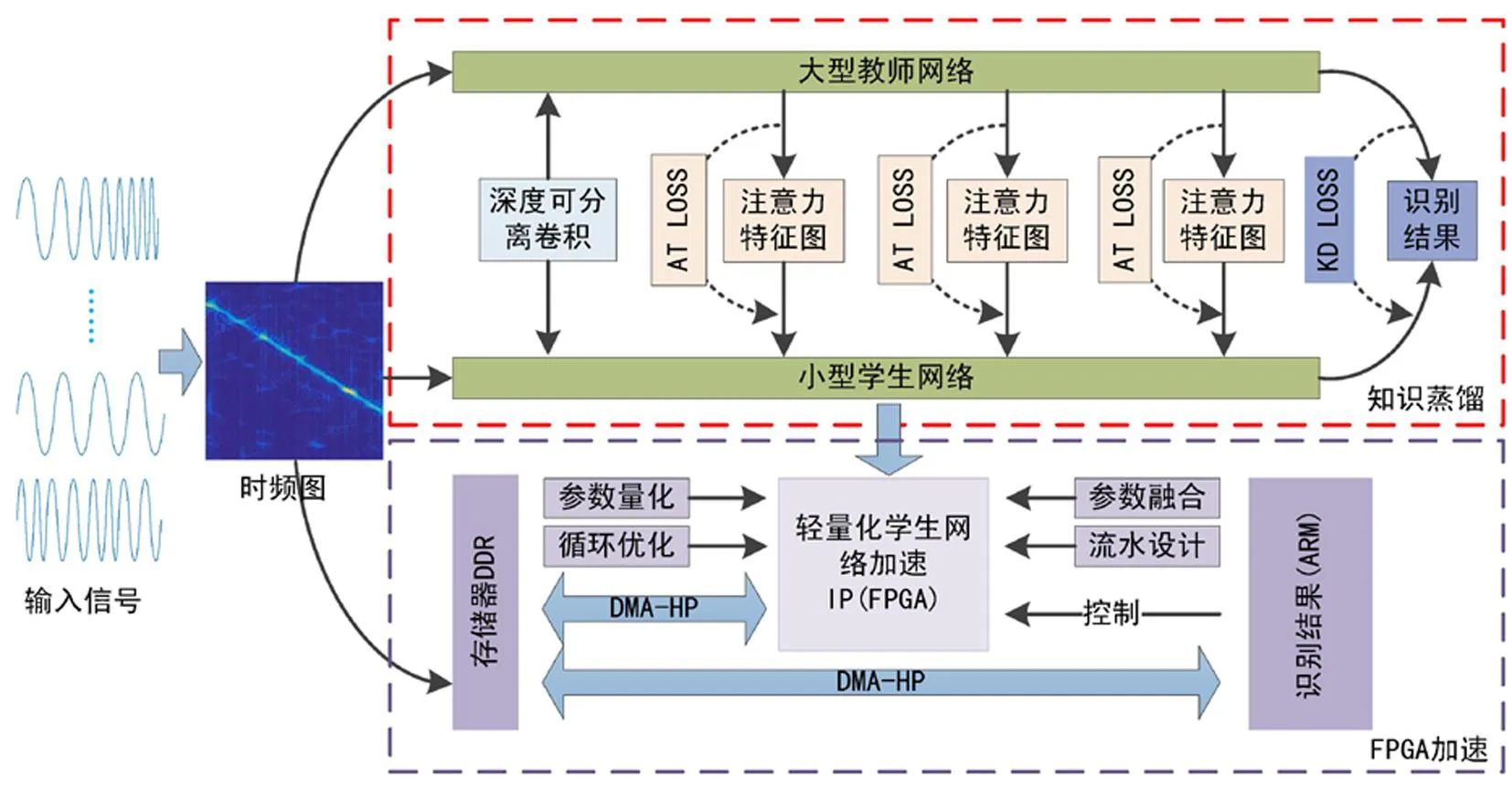
图1 轻量化信号识别系统总体框图
1.1 基于响应的知识蒸馏
知识蒸馏利用教师-学生网络模型实现网络的轻量化,是一种有效的神经网络轻量化方法。最基本的知识蒸馏利用学生网络分类输出学习教师网络的分类输出,从而将大型教师网络的分类能力迁移到小型学生网络中,其损失函数如式(1)所示。
Ltotal=αLsoft+(1-α)Lhard
(1)
其中Ltotal为总损失,Lsoft为对网络输出向量的交叉熵损失,Lhard为对实际分类目标的交叉熵损失,α为Lsoft的比例系数。
1.2 基于注意力图的知识蒸馏
基本的知识蒸馏中学生网络仅对教师网络的结果进行学习,知识迁移能力有限。本文引入注意力特征图来增强时频图中信号表现的特征,并融合深度可分离卷积进一步降低网络参数量。
为了使注意力图有效用于知识蒸馏,本文设计的教师网络与学生网络整体结构相似,如图2所示。
教师网络和学生网络的第一层均为16通道的普通卷积,第一层之后的每一个BLOCK都由普通卷积层、归一化层和普通卷积层构成,并在每一个归一化层后增加ReLU激活函数来增加网络的非线性。学生网络中的BLOCK 0-2通道数分别为16、32、64,教师网络中的BLOCK 0-2通道数分别为16、32、64的整数倍。每一个BLOCK中的第一层都使卷积步长为2以降低特征图尺寸。最后使用全局平均池化降低特征尺寸,并使用全连接层来完成分类。

图2 基于注意力图的知识蒸馏
注意力图(Attention Map, AM)模拟了生物视觉中的注意力,能使神经网络关注特征图中更加需要学习的区域。时频特征的提取在空间上更加关注信号所在区域,与空间注意力图关注目标所在区域的特性一致。因此,本文选择空间注意力图来增强信号的特征。注意力图在生成时,利用一个映射将三维的特征图转化为二维的空间注意力图。本文采用式(2)所示方法。
(2)

图3以NLFM信号为例给出了神经网络中不同层次的注意力图,AM 0-AM4分别是第一卷积层及BLOCK 0-2后的注意力图。可以看出,随着深度加深,神经网络的注意力越集中于信号特征所处区域,有利于知识蒸馏中特征信息的传递。

图3 NLFM信号在卷积神经网络中的注意力图
知识蒸馏过程中,学生网络一方面要学习教师网络输出的概率分布,同时也需要学习教师网络中间的三层注意力图。因此,损失函数由两部分构成,如式(3)所示。
(3)
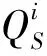
为了进一步稀疏网络,降低网络的参数量,将BLOCK中的普通卷积用深度可分离卷积代替。深度可分离卷积主要由分组卷积和点卷积组成。输入通道为N,输出通道为M,卷积核尺寸为K,普通卷积参数量Wc和深度可分离卷积参数量Wd分别表示为式(4)和式(5)。
Wc=N×M×K2
(4)
Wd=N×K2+N×M
(5)
因此,在融合深度可分离卷积后,卷积神经网络的参数量和计算量约变为原始参数量的1/M+1/K2,降低了神经网络推理对硬件存储的要求。
2 FPGA平台加速流程
为了有效加速轻量化的学生网络,本文以16比特定点数量化权重,8比特用于表示小数,8比特用于表示整数,并针对知识蒸馏得到的轻量化学生网络的结构特点,对归一化层和其邻近的前一层卷积层进行了参数融合,最后利用FPGA设计了流水并行的乘累加阵列加速学生网络的推理过程。
对于输入特征值x到输出特征值y的映射,卷积层和归一化层分别表示为式(6)和式(7)。
(6)
(7)
式(6)中,γ表示尺度因子;β表示偏移因子,这里使用特征图的每个通道的平均值和方差的无偏估计作为μ和σ2;ε为很小的正数,防止分母为0。式(7)中,ω为权重参数;b为偏置项;N为卷积核大小。将式(7)代入式(6)可得融合后的权重参数为式(8)和式(9)。
(8)
(9)
经过参数融合,参数个数减少,输出特征图缓存减少3层,有效降低了资源消耗。
卷积核包含1×1和3×3两种小尺寸,因此将针对卷积核尺寸的循环置于内层,对输入数据进行复用。卷积计算时,输入数据和卷积核权重进行乘累加运算,由于卷积核尺寸为3×3,得到一个输出数据需要9个乘累加周期。将内层循环展开,9个输入数据和9个权重数据可以同时读取,在同一个乘累加周期完成乘法运算,并能在3个乘累加周期内通过加法树得到输出的特征值,每一个卷积运算的速度约提高为原来的3倍。
通道维则采用流水线设计。一次计算包括数据读取、结果计算和数据写回三个独立过程。如图4所示,流水线设计可以使不同数据的计算在时间维度出现一定重叠,在上一个数据计算的同时读取下一个数据,掩盖读取数据的时间,加快了推理速度。
3 实验仿真与分析
使用10种信号参数如表1所示,采用率为2GHz,利用 Choi-Williams分布得到时频图并转化为32×32大小的单通道灰度图作为神经网络的输入。

图4 通道维数据流水设计
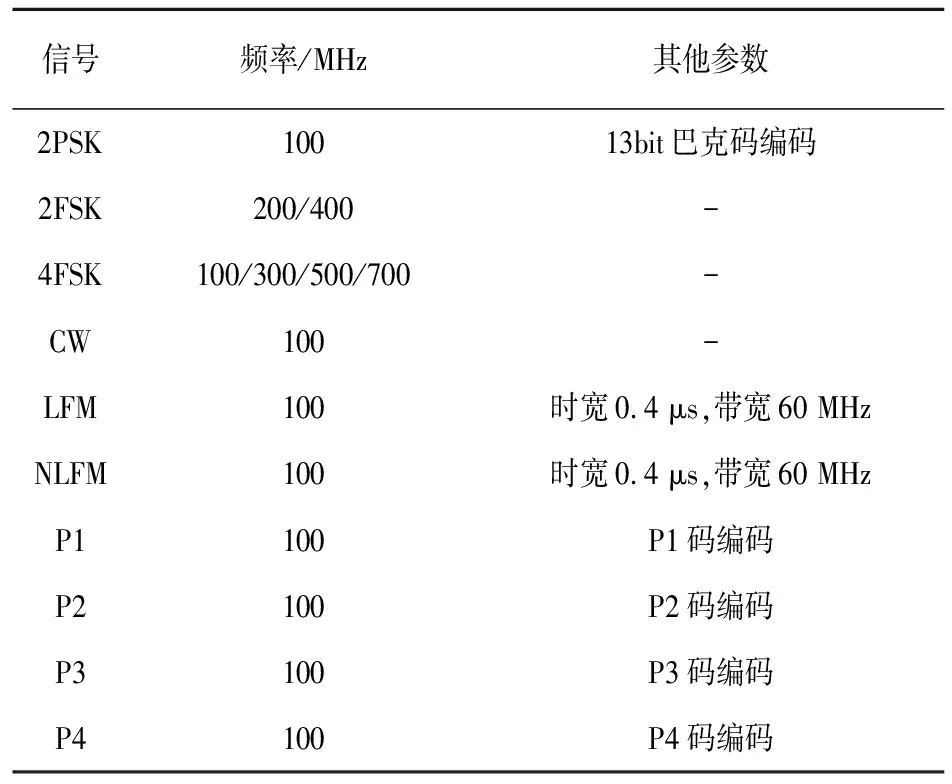
表1 信号参数表
图5给出了其中两种信号时频图。对同一个信号,600张时频图用作训练集,200张时频图用作测试集。

图5 2FSK和2PSK信号的时频图
首先对教师网络进行预训练,初始学习率设置为0.01,每迭代60次衰减为原来的0.2倍,每64张时频图作为一个批次,在型号为RTX2080的GPU上利用Pytorch 1.8.1搭建神经网络,迭代150次完成训练。
在预训练教师网络时,通过改变教师网络BLOCK数来探索深度对教师网络性能的影响。结果如图6所示。

图6 教师网络识别准确率变化曲线
随着深度的增加,教师网络的准确率有所提升,当网络BLOCK数大于15时,网络提升性能不再明显。同时,当网络宽度即通道数变为原来2倍时,网络准确率得到一定提升,但此时教师网络和学生网络参数量差距增加,可能导致知识蒸馏效果变差。因此利用图中BLOCK数为12和15的四个教师网络进行知识蒸馏,得到学生网络识别结果如表2所示。其中BLOCK数代表了神经网络的层数,宽度则表示BLOCK 0-2的卷积通道数。
表2中,与网络1相比,网络3深度增加,网络4深度和宽度同时增加,但网络4对应的学生网络识别准确率相比网络3对应学生网络更低,表明本文所用的知识蒸馏方法中学生网络的准确率除了受教师网络准确率影响,在一定范围也受限于教师网络和学生网络之间参数量的差距。因此,最后采用网络3作为教师网络训练学生网络。相比于未经轻量化的教师网络,轻量化后的学生网络参数下降81.8%。为了进一步验证轻量化卷积神经网络识别信号的有效性,利用学生网络和其他几种网络对不同信噪比下的10种信号识别,结果如图7所示。图7中四种网络的参数量如表3所示。LeNet5、AlexNet8和ResNet18分别是文献[17]~文献[19]中所采用的信号识别网络。可以看出,随着深度的增加,LeNet5、AlexNet8和ResNet18对信号识别准确率逐渐提升,但准确率最高的ResNet18在信噪比低于-6dB时仍然低于本文提出的学生网络。图7和表3表明通过本文知识蒸馏得到的学生网络在参数量大量降低的情况下仍然具有较高的识别准确率,证明了本文所采用的轻量化方法的有效性。

表2 不同教师网络知识蒸馏结果
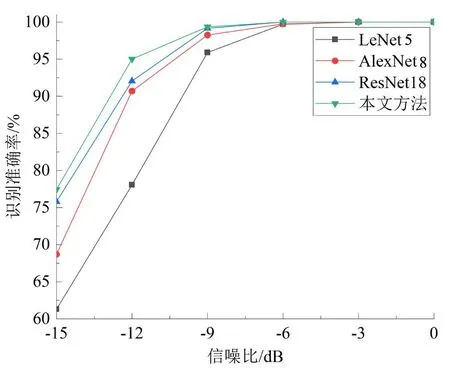
图7 不同网络识别准确率变化曲线

表3 不同网络模型对应参数量
在ZYNQ7020加速轻量化的学生网络时,权重参数存储在片上缓存RAM中,通过SD卡将图片数据导入DDR,利用ARM控制DMA-AXI总线实现计算阵列和存储器、ARM之间的数据交互,完成神经网络图片输入-数据计算-结果输出的推理流程加速。
表4给出了本文方法和其他文献所用方法的对比。文献[20]利用ZYNQ7020对一个三层网络进行流水线设计,但未对访存做优化,网络推理延迟较高。本文经过轻量化无须将中间计算结果和参数存储至DDR,从而提高了推理速度,在性能上要优于文献[20]的方法。
表5展示了不同硬件平台识别效果。在GPU端对-12dB的信号进行识别,准确率为95.01%,权重经过16位量化后,在FPGA端准确率为93.25%。可以看出,量化使得准确率降低1.76%,识别时间为86 ms,同时也消耗更少的资源,使网络在性能和速度上达到平衡,且FPGA所消耗的功耗远小于GPU。
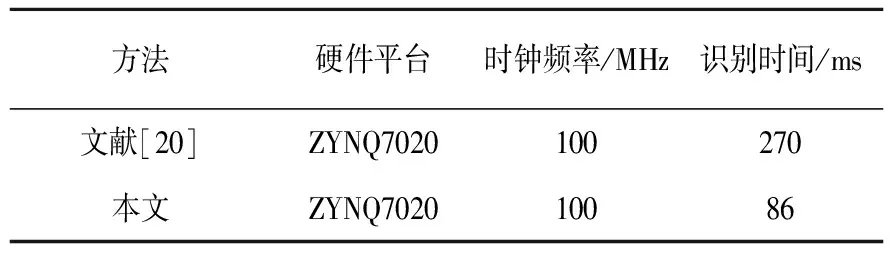
表4 其他文献对比
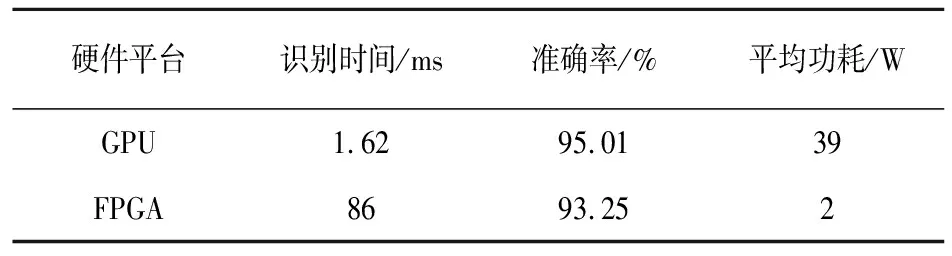
表5 GPU平台和FPGA平台对比
4 结 论
本文提出了一种面向FPGA平台的轻量化辐射源信号识别方法。该方法利用了深度神经网络提取信号的时频特征,通过改进的知识蒸馏实现了神经网络轻量化。知识蒸馏过程通过注意力图有效增强了教师网络与学生网络之间的信息传递,在融合了深度可分离卷积后,网络参数量下降了81.8%,并能在参数量大量降低的同时在信号分类任务中具备较高识别准确率。最后,根据FPGA并行特性设计了轻量化卷积神经网络加速器,通过改进循环策略、融合层间参数和流水线设计加速了信号识别过程,功耗低至2W。可以看出,本文设计的轻量化网络可以应用于边缘侧并表现出良好的能耗性能,为轻量化信号分类研究提供了一种方法。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
专用汽车(2016年1期)2016-03-01
