
添加注意力机制的YOLOv5s算法对带钢表面缺陷检测
2023-12-24 12:13:24舒睿
农业装备与车辆工程 2023年12期
舒睿
(200093 上海市 上海理工大学 机械工程学院)
0 引言
热轧带钢是当今钢材行业的主要原材料,由于热轧带钢本身具有的易加工、强韧性和抗腐蚀性等优点,使其在工业制造、土地建筑、航空航天等领域得到了广泛的应用,在整个世界的工业中都是不可或缺的战略性工业品。2000 年以后我国工业迅速发展,带动了对热轧带钢的需求。2021 年我国钢铁总产量位居世界第一,但是在钢材生产制备过程中,受到材料本身质量和加工过程中制备工艺和生产环境等一系列问题的影响,在有些加工好的钢材上会出现内部和外部缺陷,如表面裂纹、刮伤、疏松、缩孔和气泡等,钢材的硬度、强度、耐磨度等因此会出现相应的下降。
近年来随着机器视觉的发展,机器视觉在生产生活各个方面都得到广泛的应用。早期的钢材缺陷检测或使用传统的目标检测算法[1]或采用人工检测方法(工作人员在生产线上用肉眼判断是否存在缺陷)。人工检测存在工作强度大、准确率和效率低等问题,所以钢材表面缺陷检测开始向着计算机视觉检测这一方向发展,检测速度和精度都在不断上升。相关研究中,曹义亲等[2]利用改进YOLOv5算法,构造了一种带残差边的SPP_Res 特征金字塔结构,加快了模型的训练速度;韩强等[3]提出一种特征融合和级联检测网络的Faster-R-CNN 钢材表面缺陷检测算法,将特征融合,提高了检测精度。本文采用新型YOLOv5s 网络,并对结构进行修改之后,在检测头之前加上NAM 注意力机制,提高模型检测精度的同时加快了模型的收敛速度。
1 网络结构及改进
1.1 YOLOv5 网络结构
YOLOv5s 算法在YOLO 算法系列中网络最小、速度最快,在大目标检测方面效果很好。图1 为本文修改后的网络结构,主要包括4 部分:输入端、Backbone、Neck、Head。Backbone 部分主要负责提取图片中一些实现定位和分类功能必要的特征信息,提取特征信息的质量直接影响到后续其他数据的处理。由于深度学习已经能够将图像特征提取做得很好,所以不进行修改;Neck 接在Backbone 之后是为了将前一部分处理的图像特征与Neck 网络处理的图像特征融合,从而提高整个网络的性能;Head 检测头用来完成分类或定位任务。
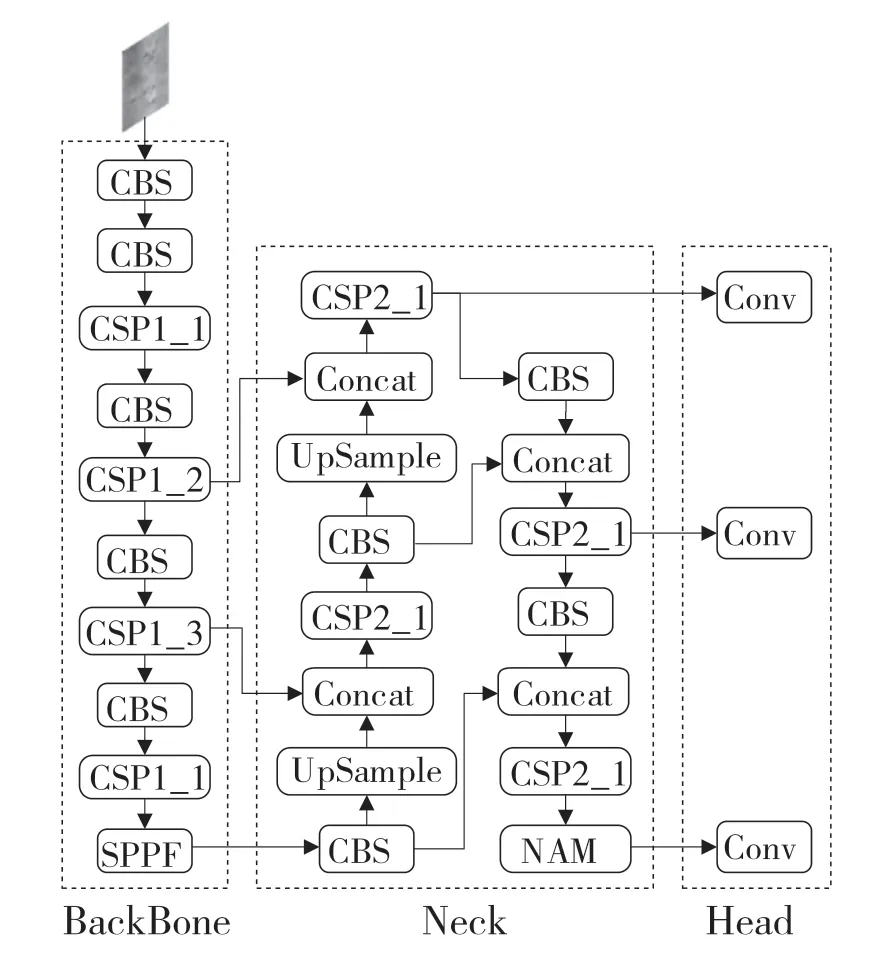
图1 YOLOv5 网络结构Fig.1 YOLOv5 net structure
1.2 输入端
在将图片放入网络之前,本文使用的YOLOv5s网络相比其他网络自行将输入图片进行了一系列数据预处理,包括为了增强数据使用的Mosaic 数据增强。为了结果准确,使用自适应锚框计算设计,以及方便图像处理使用的自适应图片缩放功能,然后将Focus 结构替换成卷积层,不仅提高了运算速度,还减少了计算量。此外,用较大的卷积核增大了感受野,能够保存更多的图像特征信息。Mosaic数据增强在YOLOv4 中便开始使用,这种将4 张图片随机裁剪、缩放、排布的方式把选出的4 张图片随机拼接,一方面增加了数据集的数量,另一方面使网络的鲁棒性更好。在YOLOv5s 中未使用之前的聚类算法,而是将锚框的计算嵌入到训练之中,在设定好的初始锚框的基础上输出预测框,然后和Ground-truth 进行对比计算Loss,进行更新,从而不断更新大小计算出最佳锚框值。
1.3 CSP 结构
Backbone 主要由CBS、CSP(如图2 所示)以及SPPF 等组成,其中CSP 在YOLOv5s 网络里被多次使用。CSP 结构设计的目的是通过分割梯度流在减小计算量的前提下将输入特征分为2 条分路进行处理,一条分路直接对输入特征进行卷积操作,减少输入通道数量至原来的一半,另一条分路把输入特征先进行卷积后,经过多个残差结构处理,将2 个分路的输出数组连接起来,最后一步将Concat得到的结果再通过一次CBS 处理得出最后结果。
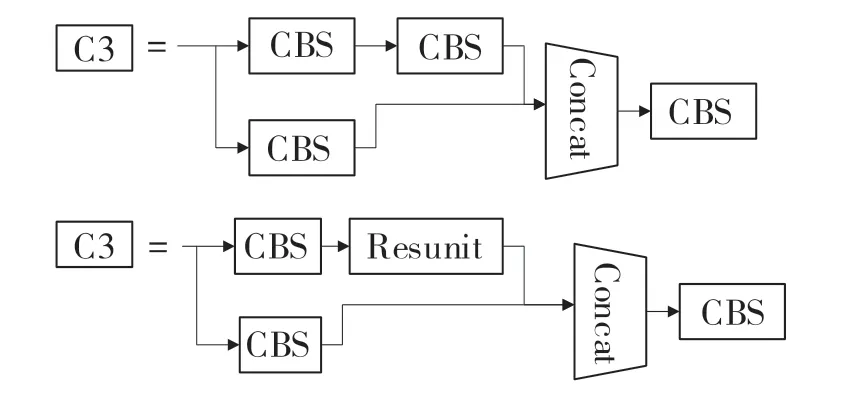
图2 YOLOv5s 网络中的两种C3 结构Fig.2 Two C3 structures inYOLOv5s network
1.4 SiLU 激活函数
YOLOv5s 采用和之前网络不同的激活函数,SiLU 激活函数表达式为
sigmoid 函数表达式为
SiLU 激活函数最大的特点就是它具有自稳定的特性,并且由于SiLU 激活函数作为隐式正则化器,抑制了大数量权重的学习,所以网络的运算速度得到了一定的提升。对于较大的x 的值SiLU 的值大约等于ReLU 值,而当x 接近-1.2 时它取全局最小值。图3 显示了该激活函数与ReLU 激活函数的对比。
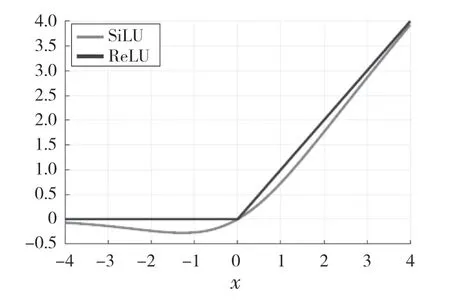
图3 SiLU 激活函数与ReLU 激活函数对比Fig.3 SiLU activation function compared to ReLU activation function
2 注意力机制
注意力机制有多种实现形式,但每种实现形式的核心都类似,即注意力。注意力机制就是由于网络中每层特征的重要性不同,后面的层应该更注重网络中重要的信息,抑制不重要的信息。一般注意力机制分为通道注意力、空间注意力和混合注意力机制[4]。近年来,许多研究通过增加注意力机制给模型性能带来了较大的提升,曹选等[5]通过在YOLOv5s 网络中添加SENet 注意力机制,配合网络的改进将精度提升了10%;程国建等[6]通过修改网络结构,结合注意力机制成功地在带钢检测的数据集提高了较大的检测精度。
2.1 NAM 注意力机制
注意力机制成功地发现了来自不同维度的互信息,但都缺乏对权值贡献因子的考虑,而这个贡献可以进一步抑制不明显的特征,NAM 注意力机制则利用权值的比例因子来提升注意力效果。本文将NAM 嵌入到残差结构的后面。对于通道注意力子模块,NAM 中使用了Batch Normalization 中的比例因子,如式(3)所示,比例因子通过测量通道方差的同时,反映了该通道的重要程度。
式中:μB——最小 batch B 的均值;σB——最小 batch B 的标准差;γ,β——可训练的仿射变换参数。
通道注意力子模块如图4 和式(4)所示。
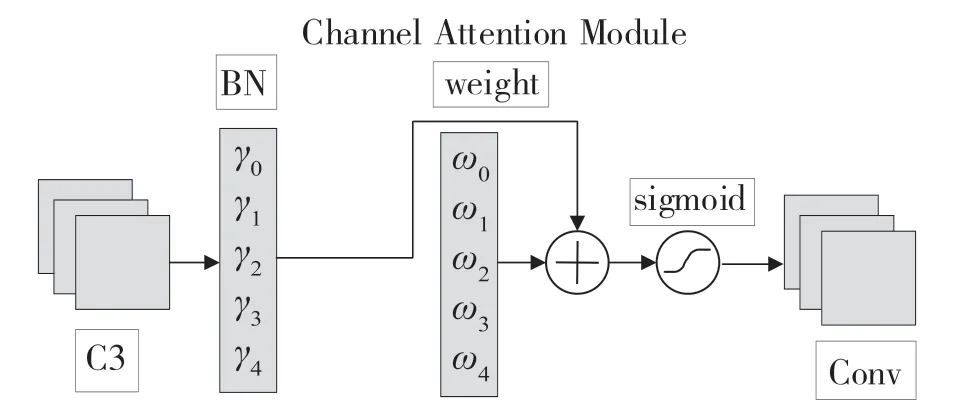
图4 通道注意力子模块Fig.4 Channel attention mechanism
式中:Mc——输出特征;γ——每个通道的缩放因子,它的权重由式(5)获得
其中,还将BN 的比例因子应用于空间维度来衡量像素的重要性,称之为像素归一化。对应的空间注意力子模块为
式中:Ms——输出;λ——缩放因子,它的权重由式(7)得出
为了抑制不突出的权重,在损失函数中添加了一个正则化项,如式(8)所示。
3 实验以及结果分析
3.1 实验数据
本实验采用的数据集是东北大学的开源NEUDET 钢材表面缺陷数据集,收集了6 种典型的表面缺陷即轧制氧化皮(RS)、斑块(Pa)、开裂(Cr)、点蚀表面(PS)、内含物(In)和划痕(Sc)。该数据库包括1 800 个灰度图像,原始图像尺寸为200×200。本文实验将数据集按照8∶1∶1 的大小分别划分训练集、验证集和测试集,数据集每类图片如图5 所示。

图5 数据集部分图片Fig.5 Partial picture of data set
3.2 实验平台
本实验的模型训练以及测试都是在成熟的PyTorch 框架中完成,为了提高运算能力,使用CUDA 和cuDNN 进行加速,其中配置参数文件中参数分别学习率参数设置为0.001,Batch Size=8,输入图片的像素大小为640×640,其他的实验配置如表1 所示。
表1 实验环境所需的软件和硬件配置Tab.1 Hardware and software configuration of experimental environment
3.3 实验结果
在实验过程中,本文主要通过观察平均准确度(mAP)评估网络识别的准确性。精确率表示预测目标中正确的目标个数占所有预测目标个数的比值,表达式为
召回率表示预测目标中正确的目标个数占所有正确目标个数的比值,表达式为
式中:TP——正阳性的数量;FP——假阳性的数量;FN——假阴性的数量。
从图6—图9 可以清晰地看出,无论是平均准确率还是精确率和召回率,它们的值在训练到30次左右时就开始收敛,并且实验准确率在73.8%,而未修改的网络模型实验精度只有71%,相较于未修改的网络模型精准度上升了3%~4%。
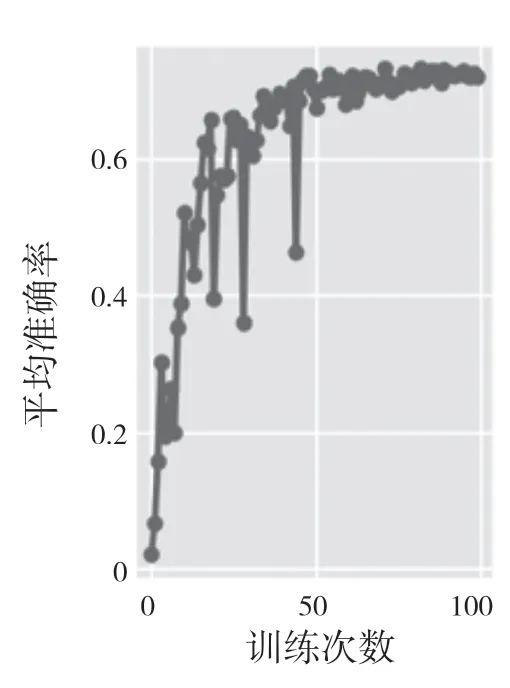
图6 平均准确率Fig.6 mAP
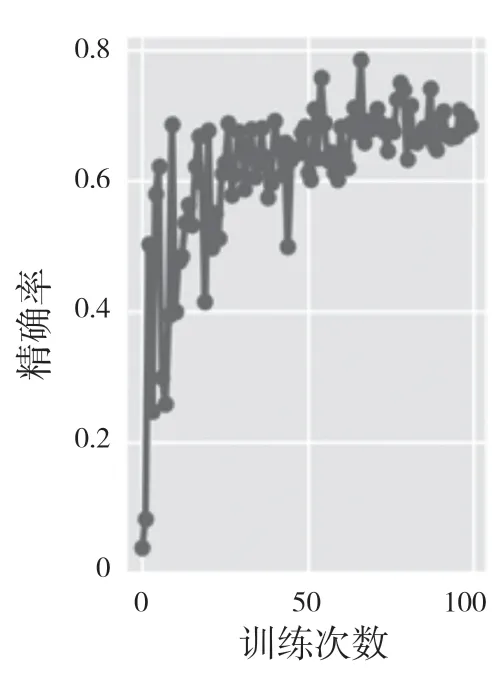
图7 精确率Fig.7 Precision
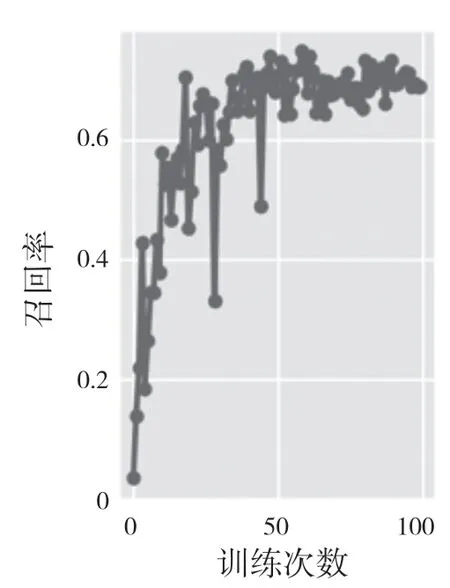
图8 召回率Fig.8 Recall
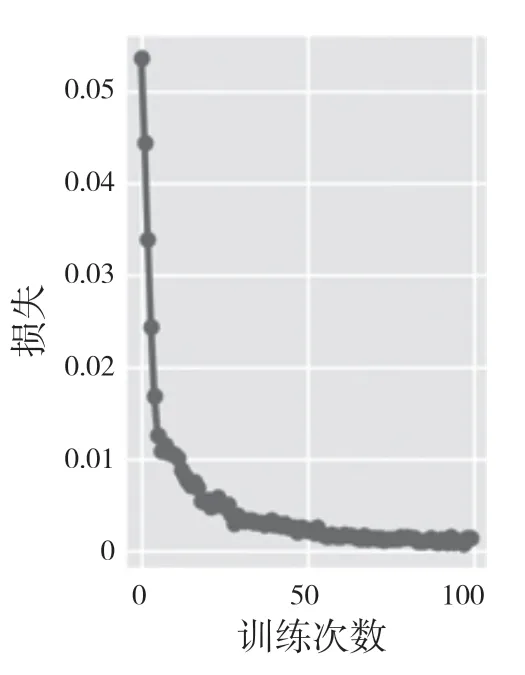
图9 GIoU 损失Fig.9 GIoU loss
YOLOv5s 采用了GIoU 作为本框架的边框预测函数,与IoU 不同的是,IoU 只关注重叠部分,而GIoU 不仅计算重叠部分,还计算了其他的非重叠部分。从图9 可以看出,GIoU 的值下降得很快,说明预测框和实际标注框的重合度在急剧上升,当训练到100 次时,GIoU 已经趋近于0 了,表示损失很小,网络检测效果良好,综合说明本文采用的YOLOv5s算法在带钢的缺陷检测方面的优越性能。
图10、图11 分别是原网络模型和加注意力机制网络模型部分检测效果图。

图10 原效果图Fig.10 Original renderings

图11 改进后效果图Fig.11 Improved renderings
由实际检测效果图的对比可以发现,在原图上检测不到或者是检测不全的部分,改进后的网络可以对缺陷进行较全面、精确的识别。综合上述得出结论,改进后的网络模型精度相较之前的网络模型而言都有一定的提升,而且收敛速度更快,可以较好地完成带钢表面缺陷检测的任务。
4 结语
本文阐释了基于添加注意力的YOLOv5s 算法实现了带钢表面缺陷检测功能,包括网络结构及其改进,注意力机制和结果分析以及创新点等。实验结果表明,添加注意力机制的YOLOv5s 算法网络相较原模型有更好的检测精度和较快的训练速度,在实际检测中能够更好地检测到表面缺陷。对于主流算法检测效果较差的开裂类,下一步的工作是尝试优化网络结构,在保证其他类检测精度的情况下提高这一类的检测精度,从而整体提升模型的检测能力,并将其部署在移动端上,满足生产检测需要。
