
基于DDPG的爬塔机器人越障决策控制方法研究
2023-12-22 13:15宁涵雪张伟军
传动技术 2023年4期
宁涵雪 张伟军
(上海交通大学机械与动力工程学院,上海 200240)
1 爬塔机器人研究现状
随着我国经济的快速发展,电力系统已成为国家高效发展的动脉线和社会繁荣的生命线。目前我国电力资源与电力消耗的地理分布极不平衡,国家电网建立了众多输电铁塔来协调各地区的用电与发电。这些铁塔工作环境恶劣,长时间裸露在空气中,可能会出现安全隐患,因此需要维修人员定期对输电铁塔进行巡检和维护。传统的铁塔检修工作通过人工完成,维修人员采用双安全带交替绑定铁塔的方式攀爬铁塔,工作强度高且安全风险极大。使用机器人代替人工执行任务可以降低维修人员劳动强度和安全隐患,并且能够提升巡检效率和覆盖率。目前爬塔机器人大都机械结构复杂,攀爬步态复杂[1-6],不同铁塔的障碍环境又有很大差异,这给机器人的使用和使用带来了一定困难。因此要求机器人具有适应不同障碍环境的自动攀爬能力,从而降低机器人的操作难度,提高机器人工作效率和适用广泛性。
目前对于爬塔机器人的自动控制方法主要分为两类,一类是根据机械结构和任务需求,设计机器人状态机或行为树,在实际工作中结合环境感知数据和机器人状态,按照预设逻辑执行任务[7-10];另一类则是使用强化学习等智能算法来确定机器人运动策略[11-14]。前者便于完成机器人底层控制,但应用场景单一,一般一种状态机或行为树策略只能对应一种障碍环境;后者可以根据不同环境来调整运动策略,但是许多任务实际不需要通过训练就可以直接决策,这些任务增加了学习的负担,在实际控制中计算效率过低。
本论文根据层次化控制理论对输电铁塔攀爬机器人的自动攀爬进行研究,利用深度确定性策略梯度算法(Deep Deterministic Policy Gradient)得出的越障策略作为高层决策,输出任务序列,并将其映射到行为树上具体节点,通过执行行为树节点实现具体动作。论文首先介绍了爬塔机器人的工作环境和机械结构,分析了机器人攀爬时的越障步态,并介绍了环境感知系统以及底层硬件系统,分析了可获取到的机器人状态信息与铁塔障碍信息。接着根据机器人建立马尔可夫决策模型,利用DDPG算法训练机器人越障策略。最后,对该方法在不同障碍环境下进行仿真,并结合行为树集成到爬塔机器人控制系统中进行实地试验,验证其有效性和适应能力。
2 爬塔机器人系统
2.1 工作环境
本文中机器人的工作环境是高压输电铁塔,按照结构可分为羊角塔、猫头塔、干字塔、酒杯塔等,如图1所示。铁塔主材上有角铁、铆钉、螺栓、连接板等障碍,如图2所示,其长度和位置在不同铁塔上有很大差异。本课题的机器人需要在这些常规铁塔的主材上实现自主攀爬功能,因此需要针对不同铁塔的障碍环境调整越障策略,提高爬塔机器人的适应性。

a.羊角塔 b. 猫头塔 c. “干”字塔 d. 酒杯塔

图2 铁塔障碍
2.2 机械与硬件系统
爬塔机器人机械结构如图3所示,由一个导轨式机体和两个结构相同的攀附足构成。

a. 升降机构 b. 伸缩机构 c.旋转机构
机体由铝方管搭建,形成一个矩形框架,机体尾部放置电池、控制器、路由器等电气元件和控制设备;机体头部设置激光雷达、工业相机等传感设备;机体导轨上有固定齿条,可供攀附足沿导轨方向移动。攀附足包含升降、伸缩和旋转三个自由度,足底为一个电磁铁,可通电实现强磁和消磁。升降机构通过齿轮齿条结构实现,伸缩机构通过电推杠实现,旋转机构通过伺服电机实现。机器人总长l1=2.1 m,导轨行程l3=1.6 m,足长l2=0.3 m。
机器人在攀爬过程中可以选择三种动作策略:整体升降、上足升降、下足升降。整体升降需要两足同时吸附在铁塔上,让两足以同方向同速度加速度升降,使机器人机体实现升降。上足升降需要首先让下足电磁铁强磁,上足电磁铁消磁,保证机器人在只有一个攀附足吸附在铁塔上的情况下不会掉落;上足缩到底,判断上足的落足点,将上足移动到指定位置再伸出,从而越过铁塔上障碍;最终让上下足电磁铁去电,恢复两足同时吸附在铁塔的状态。下足升降过程同上足升降。机器人通过升降机构让机体和上下足交替运动,实现机器人相对于铁塔的位移,通过伸缩机构使攀附足避开铁塔环境中的斜拉角钢、螺栓、铆钉等障碍区,在无障碍位置落足,实现攀爬过程中的越障功能,如图4所示。

图4 主材攀爬运动
机器人硬件系统框图如图5所示,可分为运动控制系统和环境感知系统。
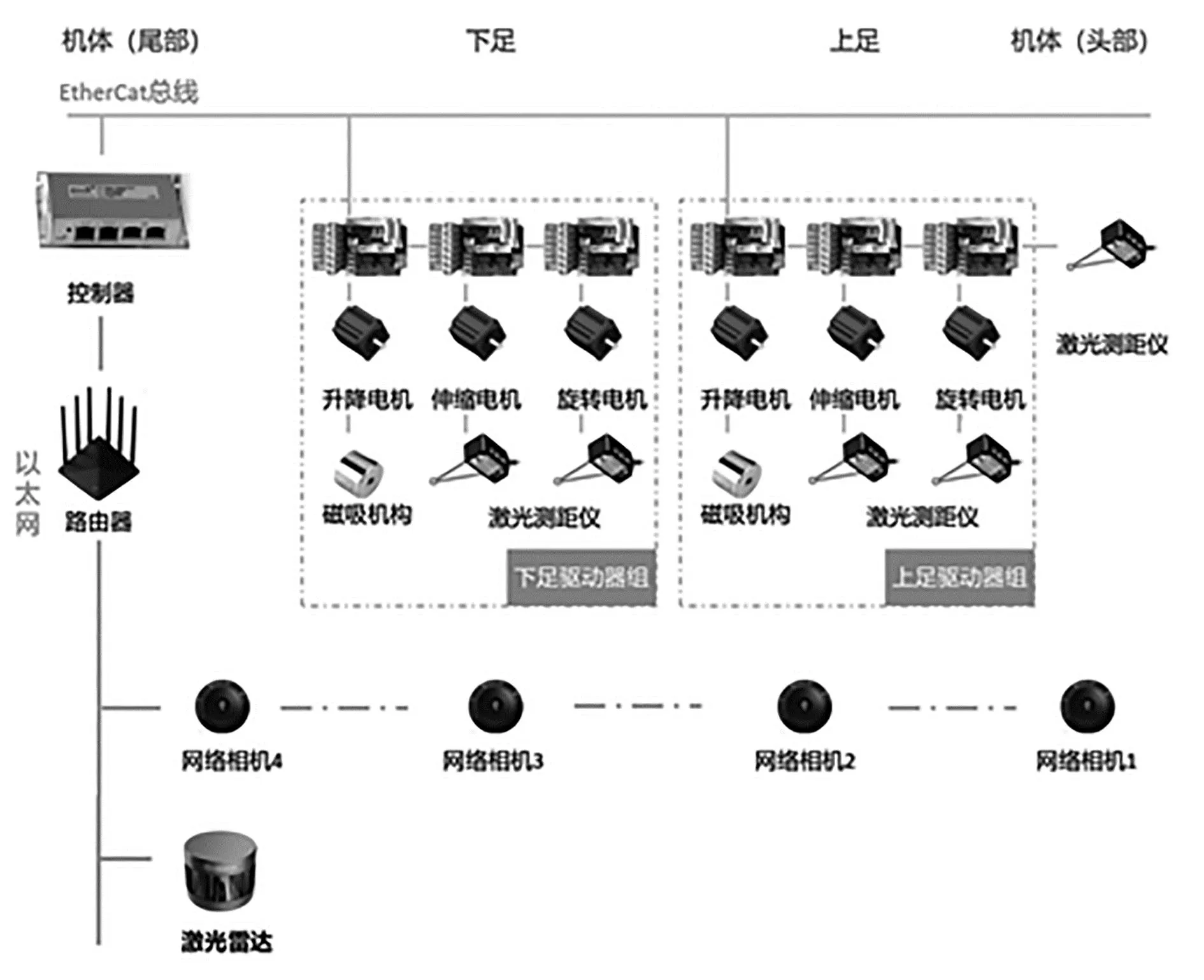
图5 硬件系统框图
(1)运动控制系统:本机器人采用EtherCAT工业总线,主站控制器倍福控制器放置于机体尾部,从站ELMO驱动器放置于足部,实现组的升降、伸缩和旋转功能,控制器的IO模块控制电磁铁的强磁、消磁和去电。
(2)环境感知系统:上下足和机体头尾都装有工业相机和激光测距,机体头部装有激光雷达。相机用于检测铁塔主材与足相对位置,判断足落点是否在铁塔主材范围内,同时供使用者实时监控机器人环境;激光测距用于获取障碍与足之间距离,激光雷达用于获取铁塔上障碍的点云数据,两者结合可获取机器人当前的环境障碍信息,包括障碍相对于机器人的位置和障碍大小,作为后续越障决策的输入参数。
3 基于DDPG算法越障决策
机器人越障过程是一个在基于连续状态空间和连续动作空间的决策过程,因此我们选择DDPG算法,它是基于DQN算法引入了确定性策略梯度,从而解决连续动作问题。
3.1 马尔可夫决策模型
对于一个智能体,如果它t+1时刻的状态只和t时刻的状态有关,那么该状态转换就具有马尔可夫性,当一个随机过程的任意时刻状态都具有马尔可夫性,则被称为马尔可夫过程,即:
P(Xt+1=sj+1│X0=s0,X1=s1,,Xt=st)=P(Xt+1=sj+1|Xt=st)
(1)
爬塔机器人越障过程可看作机器人在一维网格上运动,上下足可以交替向前移动,机器人的当前状态只与前一步的状态和前一步动作相关,因此可建立越障过程的马尔可夫决策模型。
设机体长度为Lrobot,上下足长度为Lfoot,世界坐标下机体顶端位置Ytop,上足顶端位置Yup,下足顶端位置Ydown, 本次越障的目标位置Ytarget。越障目标位置由单次环境感知能获取的范围决定,通过可获取范围内每个障碍起始位置和结束位置的世界坐标,将所有障碍的信息放入队列中,每次进行越障决策前对障碍信息队列更新,若机器人已越障成功,则将队列中该障碍信息弹出,若当前感知到的障碍还未放入队列,则将障碍信息放入队列如图6所示。
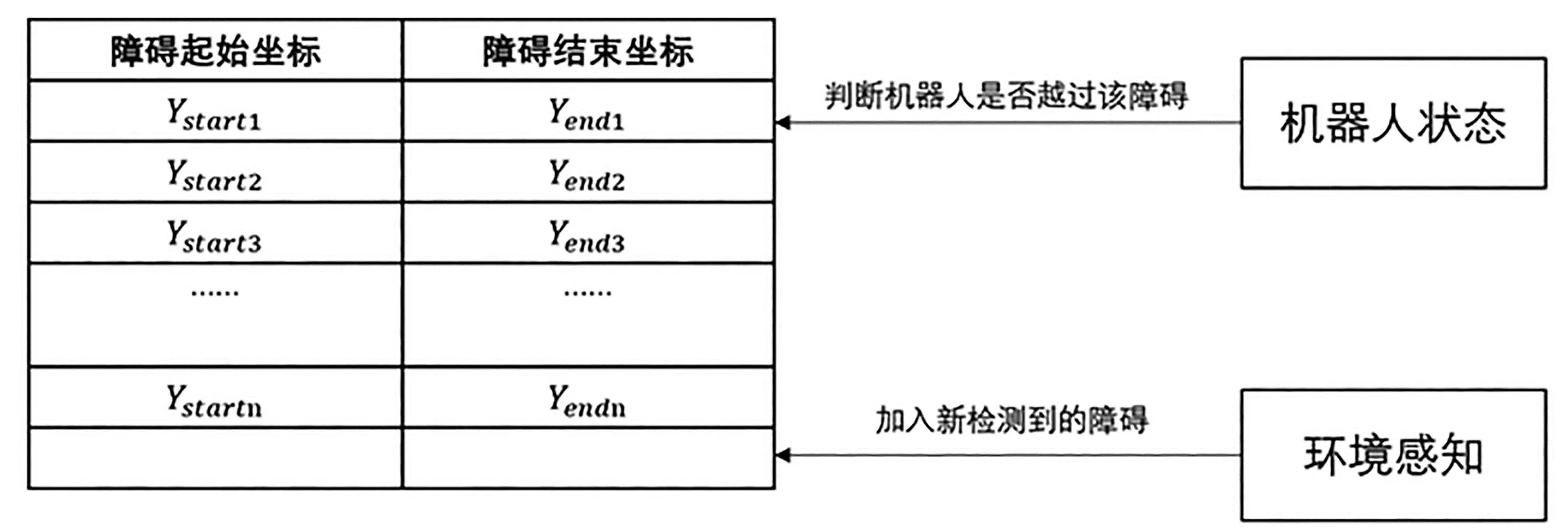
图6 障碍信息更新逻辑

图7 DDPG算法框架
3.1.1 连续状态空间
通过分析越障过程中的决策因素,可知上下足相对于机体的位置以及上下足是否与障碍有碰撞会影响决策结果。根据机器人状态信息和障碍信息,定义状态空间如下:S=[uppos,downpos,upoverlap,downvoerlap],其中uppos表示上足相对机体的位置;downpos表示下足相对机体位置;upoverlap和downvoerlap分别表示上下足当前位置与障碍是否有重叠。
上下足相对机体的位置取值范围为(0,1),分别如式(2)~(3)所示。
(2)
(3)
上下足与障碍的重叠情况判断逻辑如式(4)~式(5)所示。
3.1.2 连续动作空间
机器人越障过程中可选择的动作有上足升、下足升和整体升,因此可以定义动作空间A=[upmove,downmove,bothmove],每个动作的取值范围都是[0,Lrobot]:
机器人位置更新需要受到机械约束,更新公式如式(6)~式(8)所示。
3.1.3 奖励函数
为了加速训练速度,除了跟障碍有重合的情况,我们考虑给接近目标位置的状态更高的奖励,这样在动作选择时策略会更倾向连续运动更远的距离,这也符合实际中我们希望机器人攀爬速度更快的目标如式(9)~式(10)所示。
(4)
(5)
(6)
(7)
(8)
(9)
(10)
机器人按照策略执行动作获取奖励,得到累计奖励如式(11)所示。
(11)
式中:R(s,t)表示当前轨迹下的累计奖励,γ表示折扣系数,反映了奖励随时间重要性下降。
按照一定策略π可获得在状态st下采取动作at的奖励期望Rt,可以评估策略π的价值,用Bellman等式来定义:
Q(st,at)=E[r(st,at)+γQ(st+1,π(st+1))]
(12)
其中最大的价值对应的策略即最优策略π*:
(13)
3.2 深度确定性策略梯度算法
深度确定性策略梯度方法(Deep Deterministic Policy Gradient, DDPG)将Actor-Critic算法作为其基本框架,通过深度学习网络对策略和动作值函数近似,并使用随机梯度法来训练策略网络和价值网络模型中的参数。对于策略函数和价值函数都使用了实时网络和目标网络的双重神经网络模型。同时该算法借鉴了DQN算法中的经验回放机制,Actor与环境交互产生的经验数据将存储到经验池中,再抽取其中一批数据样本训练,使算法更容易收敛。
根据DDPG算法框架,可得DDPG算法执行过程如下。

表1 DDPG算法流程
3.3 仿真结果
仿真运行环境:(1)硬件环境:Intel i7-11800H ,16 G内存,NVIDIA 3060;(2)软件环境:Python 3.7,Paddle 2.5.2。选取不同位置和不同长度的障碍作为训练集和测试集,共进行了160000次训练以学习最佳的越障策略,训练过程的奖励回报如图8所示。
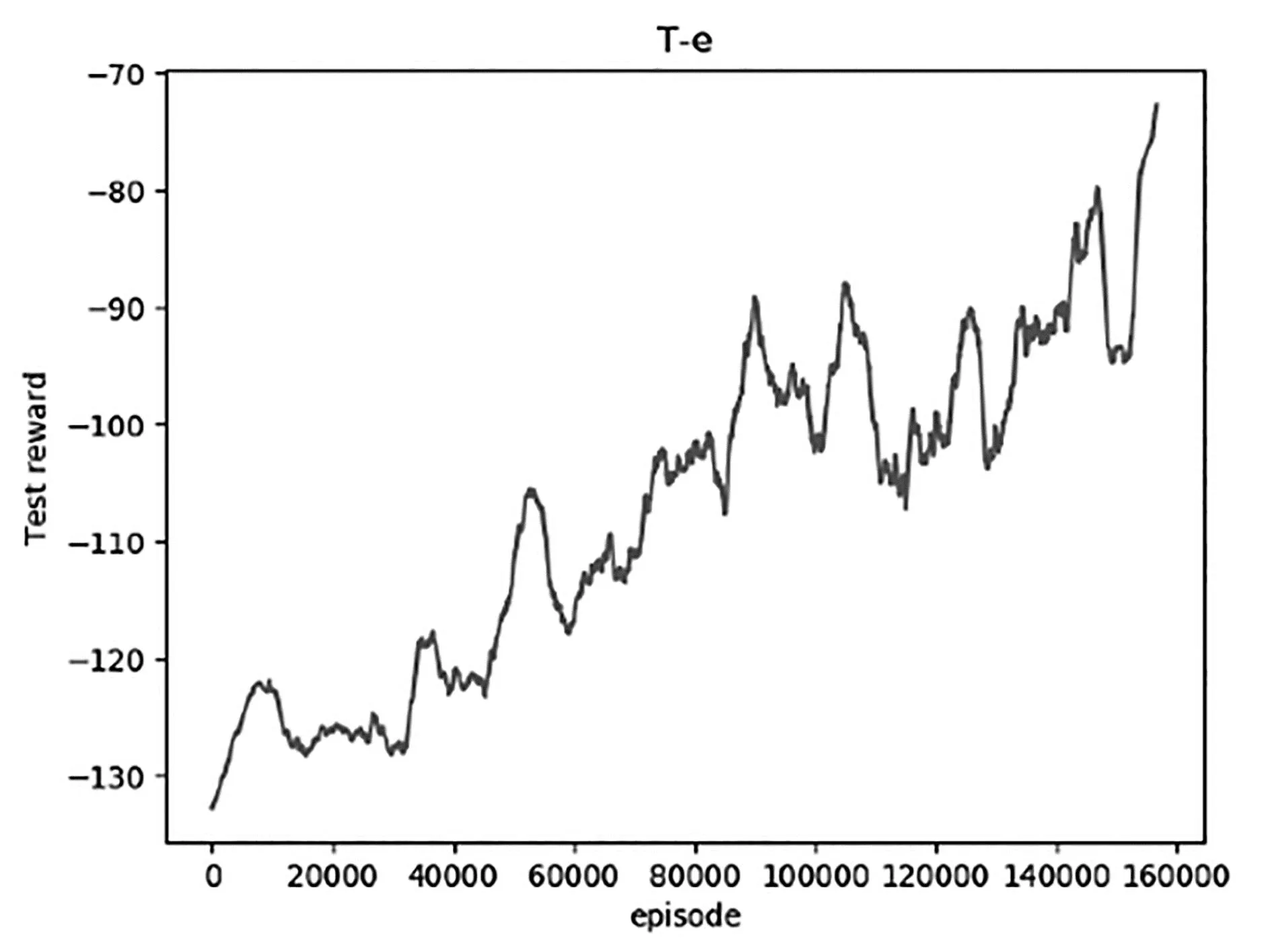
图8 仿真迭代图
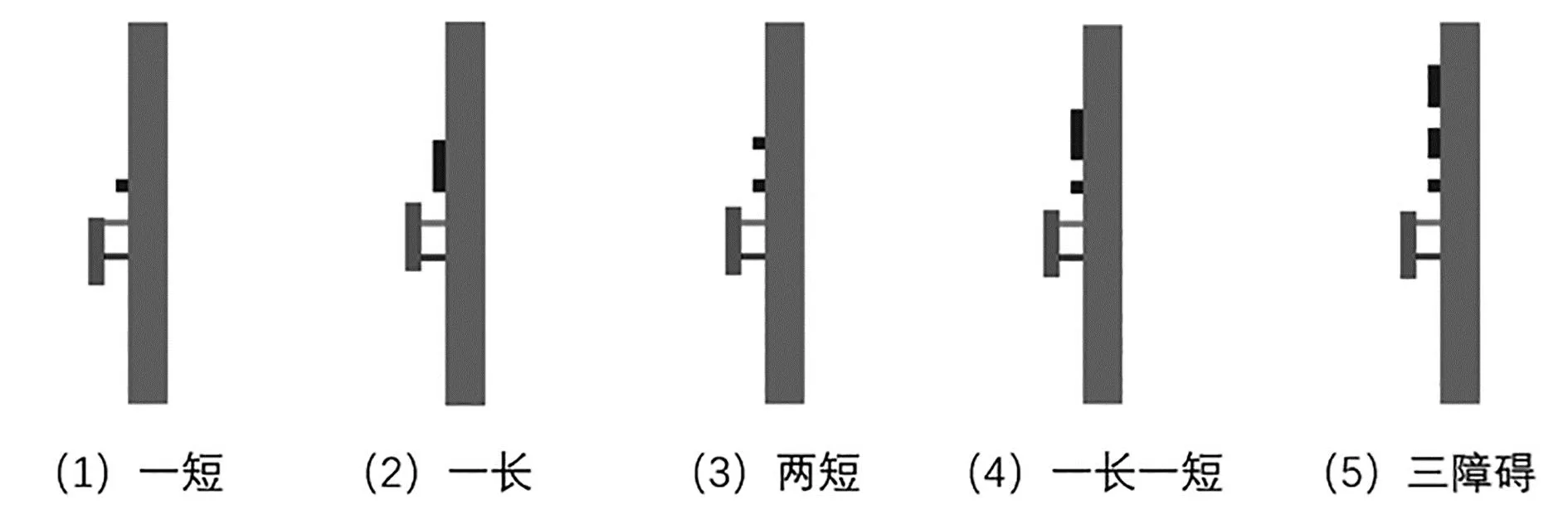
图9 测试环境
从图中可看出训练开始阶段由于智能体没有相关经验,从较低的奖励值开始探索,通过不断从经验中学习来提高奖励回报,Test reward提高到-80左右时可以稳定完成越障。
设置五种障碍环境:一个短障碍、一个长障碍、两个短障碍、一长一短障碍以及三个障碍,每种环境下取10个不同的障碍长度和障碍间隔的数据,将其作为测试集检验训练效果。
最终可以获得不同障碍环境下测试效果如下表,所有测试集均可完成越障,证明了算法的可靠性。
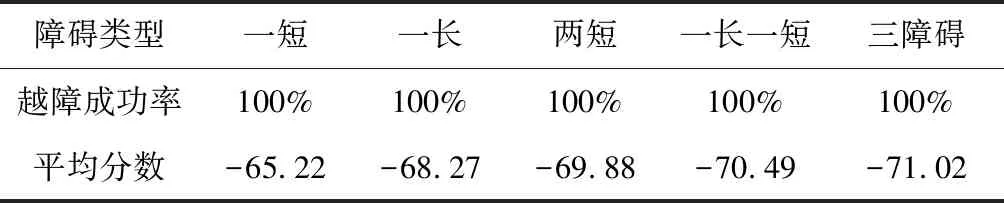
表2 测试结果
4 实验验证
为验证该越障算法实用性,将DDPG算法集成在机器人控制系统中,在实际场景进行越障试验。机器人自动控制由行为树作为基本框架,其中越障决策由强化学习计算得到,将越障策略映射到行为树对应节点来执行底层控制。机器人控制框架图如图10所示。

图10 机器人控制框架
实验工况包括羊角塔、干字塔、酒杯塔、钢管塔、10 kV铁塔,机器人针对工况对应输出了越障策略如图11~图12所示。

图11 不同实验工况
如下页图13所示,在五种工况下,机器人都基于环境感知和强化学习做出了合适的越障决策,并能结合行为树完成越障,表明机器人具备针对不同障碍环境的自主攀爬铁塔能力。
5 总 结
本文针对爬塔机器人在不同障碍环境下都需要具备自主攀爬能力的问题,提出了将传统基于预设控制逻辑的行为树和能针对环境灵活调整决策的强化学习结合的层次化控制方法。建立了爬塔机器人的马尔可夫决策模型,并利用可应用在连续动作空间的DDPG算法进行训练;同时设计了机器人行为树,并将强化学习得到的策略映射到行为树具体节点,实现底层控制动作。室外不同工况下的攀爬实验表明该控制方法能够有效地指导机器人自动攀爬铁塔。
猜你喜欢
中国化肥信息(2022年3期)2023-01-05
中老年保健(2021年7期)2021-08-22
基层中医药(2020年5期)2020-09-11
阅读与作文(小学低年级版)(2020年2期)2020-05-25
柴油机设计与制造(2018年3期)2018-10-13
中国铸造装备与技术(2017年3期)2017-06-21
军营文化天地(2017年4期)2017-06-15
现代电生理学杂志(2016年1期)2016-07-10
电测与仪表(2015年21期)2015-04-09
发明与创新(2015年21期)2015-02-27
