
基于VAE-GWO-LightGBM的信用卡欺诈检测方法
2023-12-21 06:14李妞妞
东北师大学报(自然科学版) 2023年4期
赵 峰,李妞妞
(安徽工业大学管理科学与工程学院,安徽 马鞍山 243032)
0 引言
“互联网+金融”的发展使人们交易方式变得更为便捷,其中,信用卡交易成为线上和线下最为流行的支付方式之一,信用卡交易数量的增加,使得信用卡欺诈行为也时常发生.根据《中国银行卡产业发展蓝皮书(2022)》,截至2021年底,中国共发行信用卡92.5亿张,全年新增发行信用卡2.7亿张,同比增长3.0%;全国银行卡交易金额1 060.6万亿元,同比增长33.8%;银行卡未偿信用余额8.62万亿元,比上年增长8.9%;信用卡逾期半年未偿信用总额860.4亿元,同比增长2.6%;银行卡欺诈率为0.32个基点,较上年下降0.43个基点.
信用卡欺诈是一种以获取经济利益为目的的犯罪欺骗行为,它会扰乱正常的金融发展秩序,制约金融行业的普惠目标和创新发展.因此,对信用卡欺诈的检测已经成为金融机构核心能力之一.中国银行行业协会在《蓝皮书(2019)》中提到,要加强欺诈风险防控体系建设,提高银行卡欺诈防范水平,构建“银行+持卡人”风险管控体系,提高欺诈监控准确性.可见,对信用卡欺诈的检测识别已经成为银行风险控制的关键因素.
信用卡欺诈检测是一个不平衡分类问题,目前,不平衡数据处理方法主要以算法层和数据层为主进行改进.在算法层,有集成学习和成本敏感学习,根据不平衡数据特点对算法进行优化,旨在提高算法处理不平衡分类问题的能力[1].数据级包括上采样、下采样和混合采样.上采样通过对少数类增加样本、下采样是对多数类减少样本,或通过将两者结合来平衡样本[2].
由于数据层面方法对分类算法的通用性以及处理方法的简单性和直观性,在解决不平衡问题上得到广泛应用.但是,在实际应用中,传统过采样仅依据少数样本的信息,容易制造出冗余的数据样本增加模型的训练难度;采样不足会导致大量样本数据信息丢失,处理不平衡问题的能力有限[3].
变分自编码器(VAE)作为一种新的生成式模型,自提出以来一直被认为是深度学习中最有价值的方法之一,并在许多方面得到了应用.如文本分类中,文献[4]提出融合变分自编码器模型和深度置信网络模型(VAE-DBN)进行智能文本分类.语音处理领域中,Tan等[5]使用变分自编码器提取语言特征.文献[6]将VAE应用于语音语料库数据增强和语音特征向量提取中进行声学建模.目前,变分自编码器关于不平衡数据处理的研究较少.
轻量级梯度提升机(LightGBM)[7-8]是以决策树为弱分类器的boosting集成学习框架,是梯度提升决策树(Gradient boosting decision tree,GBDT)的一种高效实现.LightGBM不仅能够有效提升准确率,并且诊断效率高.文献[9-10]研究结果表明,LightGBM与XGBoost(极端梯度提升)、CNN(卷积神经网络)等算法相比,不仅能获得更高的准确率且诊断效率更好.由于集成学习模型涉及的参数较多,许多研究表明,参数的选择将直接影响到模型的性能,因此需要将参数优化.灰狼算法(GWO)是一种全局迭代优化算法.由于其收敛性能强、参数少、易于实现,被广泛应用到作业车间调度、参数寻优和图像分类等领域.然而,关于其在信用卡欺诈检测中的应用研究还较少.
综上所述,为了进一步提高信用卡欺诈识别率,本文提出了基于VAE-GWO-LightGBM的信用卡欺诈诊断模型.基于变分自编码器(VAE)进行过采样平衡样本分布,采用GWO对模型参数进行优化,将获得的超参数组合输入轻量级梯级梯度提升机(LightGBM)进行了分类预测.
1 相关工作
1.1 变分自编码器
深度生成模型VAE是由Kingma[11]等提出的运用变分下界和贝叶斯理论的生成式网络结构.VAE过采样过程如图1所示.VAE包含2个部分:一是编码过程,对原始真实样本X进行输入编码,生成隐变量Z的变分概率分布;另一个是解码器将隐向量Z还原成尽可能接近原始数据的生成数据X′,此过程称为解码过程[12-13].

图1 VAE过采样原理
VAE的损失函数为
cost=KL[N(μ(X),σ2(X)||N(0,1)]-log[Pp(X′/Z)(X)].
(1)
其中:KL为q=(Z/X)与标准正态分布N(0,1)的距离,P=(X′/Z)为生成样本X′与输入样本X的距离下P(X)的对数似然表示.
1.2 LightGBM算法
LightGBM是一种分布式的梯度Boosting框架[14],其原理与GBDT相似.它使用损失函数的负梯度作为当前决策树的残差近似来拟合新的决策树,即每次迭代都保持原始模型不变,然后向模型添加新函数,使预测值不断接近真实值.
LightGBM的实现如下:
(1) 每一次迭代是为获得一个弱学习器,使迭代损失函数L(y,Ft(x))最小.
L(y,Ft(x))=L(y,Ft-1(x)+ht(x)).
(2)
式中Ft-1(x)和L(y,Ft-1(x))是上一次迭代获得的强学习器和损失函数.
(2) 利用(2)式负梯度拟合本次迭代损失近似值,公式为
(3)
(3) 使用平方差近似拟合为
(4)
(4) 本次迭代获得的强学习器为
Ft(x)=Ft-1(x)+ht(x).
(5)
与标准梯度提升树算法相比,LightGBM使用直方图优化分割连续特征值,通过逐叶生长策略生长树,并限制树的深度以防止过度拟合,这可以有效提高模型预测的准确性和鲁棒性.此外,LightGBM在特征的处理上和并行计算上都做了很多的优化,是当前流行的机器学习模型,相对于神经网络模型和传统机器学习模型,具有运行速度快和精度高的优势,所以本文选择LightGBM模型作为分类器.
1.3 GWO算法
GWO通过对狼的社会等级和捕猎活动建立数学模型,进而提出一种具有群体智能优化的搜索算法,简单、快速且易于实现[15].灰狼优化算法中的狼群有α,β,δ,ω4类.其中头狼α狼是最高领导者;β是α的下属狼,服从并辅助α做决策;δ听从α和β的决策命令;最底层是ω,服从α,β,δ狼,并通过α,β,δ狼的位置寻找猎物.
灰狼捕食猎物的行为定义为
D=|C′·Xp(t)-X(t)|,X(t+1)=Xp(t)-A·D.
(6)
其中:D表示狼群个体与猎物间相对距离,t表示当前迭代次数,X(t)是狼当前位置,猎物当前位置为XP(t).
系数向量A和E可表示为
A=2ar1-a,E=2r2.
(7)

群体中其他灰狼个体根据α,β,δ的位置分别更新各自的位置,即有
(8)
其中:X1,X2,X3表示ω向α,β,δ方向的位移量;X(t+1)是灰狼个体ω位置;X′是灰狼当前位置;Xα,Xβ,Xδ分别为灰狼α,β,δ位置.
1.4 不平衡数据分类评价指标
针对不平衡数据分类性能的评价,整体的分类精度并不能较好地评价一个分类模型的优劣,因此本文采用F1、xAUC和yAUPRC这3个指标对不平衡数据的分类性能进行评估.
(1)F1值为综合评价准确率(P)和召回率(R)的指标,整体衡量不平衡数据检测模型的性能为
(9)
其中P和R分别表示准确率和召回率.
(2)xAUC值用于衡量分类性能的综合指标.
(10)
其中:TFP和TFN分别代表欺诈类样本被误判为正类数量、正类样本被误判为欺诈类样本数量,N代表正类样本数量,M表示欺诈类样本的数目.
(3)yAUPRC:P-R精确回忆曲线下面积,数值范围是0至1,值越大越好,能够反映全局的指标,直观看出分类器性能好坏,yAUPRC值越大,或者PR曲线越接近右上角(p=1,r=1),则模型就越理想.
2 基于VAE-GWO-LightGBM的欺诈检测
VAE作为当前流行的深度生成模型,该模型过采样时考虑到少数类样本不同层次的特征,学习到少数类采样数据的分布,进而通过生成器模型生成相似但具有更多信息的数据样本,使数据集达到均衡.在文本分类、自然语言处理、语音识别等领域得到多方面应用,说明其作为数据采样方法具有很大的优势.因此本文将VAE应用到信用卡欺诈数据集中,通过VAE过采样平衡少数类欺诈样本,降低因数据集不平衡导致样本检测准确率低带来的影响[16-18].
机器学习中的LightGBM算法具有训练速度快、泛化性好、分类精度高等优点.然而,由于训练前模型参数数量较多,参数的随机设置会导致一些参数未达到最佳状态,这容易导致输出结果不稳定[17].GWO算法作为智能搜索算法,具备较强的收敛性能,且参数少易于实现,迄今为止,该优化算法被广泛地应用在各科学研究领域.因此选用GWO对LightGBM参数进行优化,寻找LightGBM最优的参数组合.
针对欺诈检测数据样本量大、样本类别不平衡等特点,结合VAE、LightGBM和GWO的优异性能,充分利用各自的优势克服各自的不足[19-20],构建了基于VAE-GWO-LightGBM的信用卡欺诈检测分类方法.总体框架如图2所示.

图2 基于VAE-GWO-LightGBM的欺诈检测框架
检测流程如下:
(1) 对输入的原始数据进行异常特征处理,然后对数据进行归一化预处理.
(2) 训练正常数据和欺诈数据,欺诈样本数据量远小于正常数据样本,样本类别严重不平衡.因而通过VAE对训练集中少数欺诈数据进行过采样平衡样本.
(3) 样本平衡后,训练LightGBM模型,并使用GWO优化LightGBM的超参数.优化过程如图3所示.

图3 GWO算法优化LightGBM参数流程
(4) 将优化得到的GWO-LightGBM模型在信用卡欺诈数据集上进行验证,检测模型分类结果.
3 实验过程
3.1 实验数据与设计
本文使用数据来源于Kaggle平台2018年最新公开发布的信用卡欺诈检测专题,数据集有31个特征,类别是0和1,1表示少数类欺诈样本.为了证明模型的适用性,同时选取UCI和Kaggle平台的4个其他类型的不平衡数据集进行实验,数据集特征如表1所示.

表1 数据集信息
实验前先对不同数据集进行标准化处理,将每组数据集取80%样本数量作为训练集,20%作为测试集.根据当前不平衡数据集,首先分别以采样效果展示和数据对比的形式将VAE方法同其他经典过采样方法进行比较,验证将其作为过采样方法的有效性;再将本文算法VAE-GWO-LightGBM同其他分类方法进行比较,证明该集成分类方法对不平衡数据进行分类表现效果更好.
3.2 VAE方法验证与分析
图4给出原始数据集以及采用不同过采样方法的生成样本可视化对比图.其中Original dataset是原始数据集的分布图,可以看出原始数据集中少数类样本规模较小且生成的部分样本会落在多数类区域;从SMOTE采样方法分布图可以看出,SMOTE方法从局部邻域出发并通过线性插值的方法合成新样本,合成的新样本与原始样本差异较小,存在较多的重叠样本不利于分类器的训练;从Borderline-SMOTE和SVMSMOTE采样图可以看出,两者采样效果分布类似,两者少数类样本与正常样本存在部分交叉,边界附近生成部分噪声样本;ADASYN和VAE过采样可视化图分布也是类似,两者所生成的新样本与真实样本分布基本一致但又不完全相同,VAE能够有效减缓经典过采样方法出现的样本重叠等问题.总体比较这些采样效果图,可以看出本文方法所生成的样本能较好地模拟原始数据的分布特征,基本都在原始样本的分布区域中,虽然有小部分噪声样本的产生,说明本文采用VAE过采样方法对少数类样本进行扩充,可以有效学习到少数类样本分布特征,生成更符合原始数据特征的少数类新样本.

图4 不同过采样方法生成样本对比图
然而,仅凭直观的可视化展示还不足以证明本文过采样方法在不平衡数据分类处理方面的有效性和泛化性,本文将进一步对VAE改进前后的合成样本质量进行评估,并基于上述评价指标在信用卡欺诈数据集和其他数据集进行欺诈分类性能比较.
3.3 在信用卡数据集的实验结果
实验设置选用两组对比实验进行分析,第一组将本文所采用的过采样方法与其他经典过采样方法在信用卡欺诈公开数据集以准确率(A)、F1、xAUC和yAUPRC为评价指标进行比较,实验中均采用LightGBM轻量级梯度提升机作为分类器,验证VAE过采样方法在处理不平衡数据上的有效性;第二组实验,将本文采用的VAE-GWO-LightGBM集成学习分类方法与其他机器学习方法在信用卡欺诈数据集上做比较,进一步验证本文所提出的将VAE过采样方法与改进的LightGBM方法相结合的方式,可进一步提升不平衡数据的分类性能.实验中设置VAE迭代次数为2 000,将数据样本编码映射到高斯分布N(0,1)中.其中,编码器和解码器是3个隐层,每层为100个神经元的神经网络.使用Relu函数作为激活函数、Adam optimizer优化器进行最小损失求解.GWO算法种群规模为2 000,最大迭代次数为500.
表2为信用卡数据集使用VAE、SMOTE、Borderline SMOTE、SVMSMOTE和Adasyn与LightGBM所得出的A、F1、xAUC和yAUPRC等评价指标.表3为信用卡数据集使用RF、MLP、Catboost、KNN所得出的评价指标A、F1、xAUC和yAUPRC.

表2 各种采样方法的评估指标值

表3 各模型的欺诈检测指标比较
从表2可以看出各种采样方法在A这一项都相差不大且表现良好,都达到了99%以上.对比各种采样方法中可以看出采用原始数据进行检测效果最差,F1、xAUC、yAUPRC值都低于其他过采样方法;VAE作为过采样方法表现最好,对比SMOTEF1提高了6.7%,xAUC提高了7.6%,yAUPRC提高了6.8%;对比BorderlineSMOTEF1值提高了4.7%,xAUC提高了7.1%,yAUPRC提高了4.7%;对比SVMSMOTEF1值提高了6.9%,xAUC提高了9.7%,yAUPRC提高了6.3%;对比ADASYNF1值提高了9.3%,xAUC提高了7.6%,yAUPRC提高了9.6%.
从表3可以看出各种分类算法的A都表现较好,尤其本文方法的准确率最好,达到了0.999 7.对比F1值和yAUPRC值,表现最差的是KNN,本文VAE-GWO-LightGBM方法比KNN模型的F1值提高17.7%,yAUPRC提高17.3%.对比其他分类模型,本文的xAUC值同样表现最好.
综上分析,从少数类欺诈检测评估指标检测A、F1、xAUC和yAUPRC、整体方面考虑,在处理非平衡的信用卡欺诈检测数据时,VAE-GWO-LightGBM方法具有较好的整体检测效果.
3.4 在其他数据集上的实验结果
为了证明本文方法的适用性,在UCI和Kaggle的4个数据集上进行同样的实验.表4和5分别为各算法在这些数据集上所得出的A、F1、xAUC和yAUPRC值.从表4和5可以看出,以F1、A、xAUC和yAUPRC值为评价指标,在Pima、Wine_red、UCI_breast、BankNote_Authentication这4个数据集中,本文提出的算法整体表现性能最好,与其他分类算法对比,A最高提高了14.9%,F1值最高提高了19.0%,xAUC值最高提高了16.0%,yAUPRC最高提高了12.8%.

表4 不同算法在数据集上的A值

表5 不同算法在数据集上的F1值
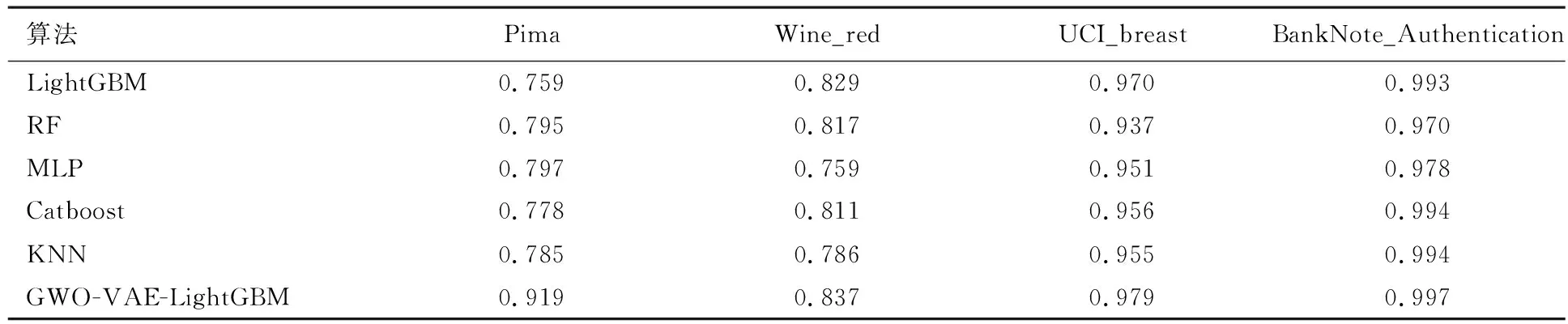
表6 不同算法在数据集上的xAUC值

表7 不同算法在数据集上的yAUPRC值
4 结论
VAE作为过采样方法处理不平衡数据时易受到少数类样本规模的限制,在数据规模偏小的情况下难以有效学习其分布特征,导致生成的样本质量欠佳.针对上述问题,本文以VAE和集成学习为基础,同时在数据层面和算法层面对不平衡数据处理方法进行改进,提出了一种基于GWO-VAE-LightGBM的不平衡数据集成分类算法,第一阶段首先采用VAE方法快速生成少数类样本,使少数类样本达到一定规模,保证VAE能充分学习到少数类样本的分布特征提高合成样本的质量;第二阶段对原始LightGBM模型进行改进,采用GWO算法优化LightGBM参数,使优化后的LightGBM方法更好地适用于不平衡数据的分类;最后用优化后的LightGBM方法训练平衡数据集得到集成分类模型,以A、F1、xAUC和yAUPRC作为评价指标,在5组公开数据集上的对比,结果表明,所提方法可以显著提高不平衡数据的分类精度.后续工作考虑将此模型与其他学习算法融合,构建更为强大的欺诈检测分类器,进一步提升分类器性能.
猜你喜欢
眼科新进展(2023年9期)2023-08-31
眼科新进展(2022年12期)2022-12-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年10期)2019-08-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
瞭望东方周刊(2017年35期)2017-09-22
中国防伪报道(2016年10期)2016-11-21
公民与法治(2016年24期)2016-05-17
