
融合SikuBERT模型与MHA的古汉语命名实体识别
2023-12-21 03:36陈雪松詹子依王浩畅
吉林大学学报(信息科学版) 2023年5期
陈雪松,詹子依,王浩畅
(东北石油大学 a.电气信息工程学院; b.计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
汉语历经沧桑,传承中华文明。我国是世界上唯一一个文化传承没有中断的国家,想要学习和发扬中国优秀的传统文化,就需要从古汉语入手。如何实现使计算机对古文文本进行自动化的知识点标注,辅助学习和理解古汉语知识是当今的研究热点。
命名实体(NE:Named Entity)一词是在第6届信息理解会议(MUC-6:Message Understanding Conferences)[1]上提出的,通常是指文本中具有特殊意义或根据任务需求预先定义好的实体。常见的命名实体有人名、地名、机构名等。命名实体识别(NER:Named Entity Recognition)任务主要是从自然语言文本中识别出命名实体,是自然语言处理(NLP:Natural Language Processing)的一项基础性任务。对古文文本进行命名实体识别是对古文进行自动化知识点标注的基础,但传统的命名实体识别方法无法充分学习古汉语复杂的句子结构信息,并且在长序列特征提取过程中容易带来信息损失问题。因此需要在分析古汉语语料特点的基础上,研究命名实体识别方法,以提升古汉语命名实体识别的效果。
针对上述需要,笔者在分析古汉语句法的基础上,结合人名、地名、组织名、职位名和书名相关重要实体的命名形式,结构特征以及分布特点,研究命名实体识别方法,提出了以BiLSTM-CRF(Bidirectional Long Short-Term Memory-Conditional Random Field)模型为基础融合SikuBERT(Siku Bidirectional Encoder Representation from Transformers)模型和多头注意力机制的古汉语命名实体识别方法,并进行实验验证,以实现对古汉语实体识别效果的提升。
1 相关工作
1.1 古汉语命名实体及语料
表1是在分析古汉语句法的基础上,对人名、地名、组织名、职位名、书名相关重要实体的命名形式、结构特征以及分布特点的简要分析。

表1 古汉语实体特点
从表1可看出,掌握古汉语句子结构的规律以及学习古汉语的字词语义就能较准确理解句子,因此古汉语结构位置、语义信息对识别古汉语命名实体尤为重要。另外,古汉语的一些相关字符序列过长,模型识别实体时需要学习长距离的序列信息,可能带来信息损失问题。
1.2 命名实体识别方法
早期使用的NER方法是基于规则匹配的方法,该方法需要专家构建规则,再从文本中查找与该规则匹配的字符串。但规则过度依赖于领域知识,可移植性极差。此时,机器学习的兴起,给人们带来了新的思路。
为了改进NER方法,人们将目光投向了隐马尔可夫模型(HMM:Hidden Markov Model)[2]、最大熵模型(MEM:Maximum Entropy Model)[3]、支持向量机(SVM:Support Vector Machine)[4]、条件随机场(CRF:Conditional Random Field)[5]等经典机器学习模型上。其中效果较好的是CRF模型,不仅能容纳上下文信息,还能进行全局归一化获得最优解,在农业[6]、医疗[7]等领域都取得了较好的效果。在古汉语领域,石民等[8]提出了基于CRF的分词标注一体化方法,有效降低了人工标注的工作量。但复杂的特征提取工作依然离不开人工的参与。此时,深度学习的出现解决了这个问题。
深度学习[9]允许由多个处理层组成的计算模型学习具有多个抽象层次的数据表示,避免了繁琐的人工特征提取工作。经典的深度学习模型有卷积神经网络(CNN:Convolutional Neural Network)[10]、循环神经网络(RNN:Recurrent Neural Network)[11]等。其中,RNN因为具有较强的序列特征提取能力,在NER领域应用广泛。Lample等[12]提出的双向长短期记忆网络(BiLSTM:Bidirectional Long Short-Term Memory)是在RNN的基础上改进的,不仅在一定程度上解决了RNN存在的梯度爆炸或消失等问题,还具有获取上下文特征的能力; 他们还将BiLSTM与CRF模型结合,在英语、德语等语料上验证了识别的有效性。BiLSTM-CRF模型也被人们应用于NER的司法[13]、中医[14]等多个领域,是目前较为主流的模型。同时,人们还热衷于将BiLSTM-CRF模型作为基线模型,并根据具体的NER任务对其进行改进。例如,李丽双等[15]构建了CNN-BiLSTM-CRF神经网络模型,利用CNN网络卷积获得表示单词形态特征的字符向量,用以补充词向量的不足。王昊等[16]建立以字向量作为输入的BiLSTM-CRF历史事件元素命名实体识别模型,避免了分词可能带来的错误。
近年来,因为注意力机制(Attention)具有扩展神经网络的能力,所以融合注意力的模型在深度学习的各个领域均得到广泛的应用[17]。例如,在识别化学药物命名实体时,杨培等[18]将Attention机制引入了BiLSTM-CRF模型中,提高了全文的一致性和缩写识别的准确率。罗熹等[19]在BiLSTM-CRF模型的基础上,结合相当于多个Attention机制拼接而成的多头注意力(MHA:Multi-Head Attention) 机制捕获字符间潜在的语境和语义关联等多方面的特征,有效地提升了中文临床命名实体的识别能力。2017年,Vaswani等[20]提出了完全依赖于Attention机制的Transformer模型,因为其具有高效并行计算能力,从而在NLP领域的应用颇为成功。基于此,Devlin等[21]提出了采用双向Transformer编码器结构的BERT(Bidirectional Encoder Representations from Transformers) 预训练语言模型,能根据下游不同的NLP任务对神经网络输出层进行微调,提升模型的应用效果。目前常用的中文BERT是由Google官方提供的基于中文维基百科训练的包含简体和繁体中文的预训练模型。与中文BERT不同,王东波等[22]提供的SikuBERT是基于《四库全书》繁体语料在BERT上进行继续训练的预训练模型,其设计面向《左传》语料的命名实体识别等验证任务,验证了SikuBERT等预训练模型具有较强的古文词法、句法、语境学习能力和泛化能力。
因此,考虑到BERT模型[21]具有学习上下文结构位置和语义信息的能力、MHA机制[19]具有从多个角度捕获字符间的关联权重和降低序列信息损失的优势,并且由于本文针对的古汉语领域的命名实体识别任务的原始语料与《四库全书》语料更为相近,SikuBERT比中文BERT更适合于增强文本的语义表示。因此笔者在BiLSTM-CRF模型的基础上融合SikuBERT模型与多头注意力机制,设计一种古汉语命名实体识别方法SikuBERT-BiLSTM-MHA-CRF,以实现古汉语命名实体识别效果的提升。
2 融合SikuBERT模型与MHA的古汉语命名实体识别模型
2.1 模型整体架构设计
图1是模型的整体架构图,主要包括SikuBERT层、BiLSTM层、MHA层和CRF层。为充分利用古汉语实体之间的结构位置信息以及字词的语义信息,将具有预测结构位置、语义信息能力的SikuBERT模型放到第1层对古汉语语料进行预训练。再将SikuBERT模型输出的信息向量输入到第2层具有获取上下文特征能力的BiLSTM模型中进行特征提取,使输出字符序列,如l=[l1,l2,…,ln],具有更多的上下文信息。但BiLSTM模型不能很好地处理过长的序列,会带来信息损失的问题,因此需要第3层MHA机制提升关键字符在句子中的权重,减少信息的损失。最后通过第4层具有学习标签之间约束能力的CRF模型对MHA输出的特征信息进行解码,得到字符标签序列,获得最终的预测结果。
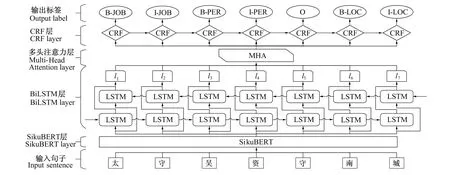
图1 模型的整体架构
2.2 SikuBERT模型
BERT[21]模型是通过训练大规模无标注语料获得包含文本丰富信息向量的预训练语言模型。BERT模型将字向量、文本向量、位置向量作为模型的输入。字向量用于表示文本中字的信息,文本向量用于表示文本全局的语义信息,并将文本向量和字向量融合,由于文本不同位置的字所携带的语义信息不同,因此给文本中每个字附加一个位置向量用以区分。并且BERT模型的网络结构由多层双向Transformer编码器结构叠加而成,使模型在学习和预测每个字时,可以参考前后双向的文本语义信息,获取文本的结构特点。因此BERT模型输出的序列向量具有强大的语言表征能力。
SikuBERT与BERT的区别是预训练时使用的语料不同,SikuBERT[22]是基于《四库全书》繁体语料在BERT上进行继续训练的预训练模型。笔者针对的古汉语领域的命名实体识别的原始语料与《四库全书》语料更为相近,因此SikuBERT比中文BERT更加适合本文的任务,以增强文本的语义表示。
2.3 BiLSTM模型
如图1所示,BiLSTM模型由双向的LSTM(Long Short-Term Memory) 模型[23]组合而成,可以学习文本双向的上下文特征。LSTM模型在RNN的基础上,采用遗忘门f决定上一个细胞中需要抛弃的信息,输入门i控制本细胞需要加入的信息,输出门ο决定当前阶段的输出信息。
3个门具体的计算公式为
ft=σ(Wf[ht-1,xt]+bf),
(1)
it=σ(Wi[ht-1,xt]+bi),
(2)
ot=σ(Wo[ht-1,xt]+bo),
(3)
ct=ft·ct-1+it·tanh(Wc[ht-1,xt]+bc),
(4)
ht=ot·tanh(ct),
(5)
其中ft、it、οt分别为遗忘门、输入门、输出门在t时刻的结果;σ为sigmoid激活函数;W、b分别为3个门的权重矩阵和偏置矩阵;xt为t时刻的输入内容;ht-1、ht分别为t-1、t时刻的输出内容;ct为LSTM在t时刻的细胞状态;·为点积运算。
LSTM通过引入“门控”的选择机制,有选择地保留或删除信息,解决了RNN在处理长序列数据时容易出现的梯度爆炸或消失问题。但单向的LSTM无法保留后文的信息,因为其输入来自前文。而双向LSTM网络拼接成的BiLSTM网络可以捕捉前后文信息,获取全局的前后文特征[12]。
2.4 多头注意力机制
虽然BiLSTM能提取全局的前后文特征,但在处理过长的序列时会出现信息损失问题,不能充分表达文本中关键字的重要性。因此,在此基础上,笔者引入多头注意力机制给BiLSTM层的输出向量分配不同的权重。通过分配权重,获取词与词之间的相关度,使模型关注重点词,抑制无用词,能有效解决BiLSTM模型带来的信息损失问题,提高模型的识别效果。
多头注意力机制相当于多个单头注意力机制的拼接,单头注意力机制的计算过程为
(6)
其中A为单头注意力机制的计算结果,S为Softmax函数,Q、K、V分别为query、key和value的简写,K和V是一一对应的,Q∈Rn×dk,K∈Rm×dk,V∈Rm×dk,dk为神经网络的隐藏层单元数。首先将上层模型(如BiLSTM模型)的输出向量通过3次不同的映射转换成3个维度均为dk的输入矩阵Q、K、V,再根据Q与K的相似性计算权重,并利用softmax函数对权重进行归一化处理,最后通过与V相乘获得权重求和结果。
与单一注意力机制相比,多头注意力机制分别对Q、K、V的各个维度进行多次线性映射,使模型的效果更佳:
M(Q,K,V)=C(h1,…,hn)WO,
(7)
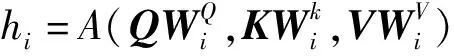
2.5 CRF推理层
条件随机场CRF模型是指在输入一组序列x=[x1,x2,…,xn]的情况下,输出另一组序列y=[y1,y2,…,yn]的条件概率分布模型。CRF通过学习上层模型输出的状态特征关注当前位置的字符可以被转换成哪些实体标签,通过学习转移特征关注当前位置和其相邻位置的字符可以有哪些实体标签的组合,能解决无约束标注可能带来的错误标签。预测序列y=[y1,y2,…,yn]的得分为
(8)
其中A为转移分数矩阵;Ayi,yi+1为yi标签转移为标签yi+1的概率;P为状态分数矩阵;Pi,yi为第i个字被标记为yi的概率;n为序列长度。显然S(x,y)越高,预测越准确。所有可能的序列路径归一化后得到关于预测序列y的概率为
(9)

(10)
3 实验与分析
3.1 实验数据的获取与整理
该实验主要使用的C-CLUE(Classical-Chinese Language Understanding Evaluation Benchmark) 数据集[25]是天津大学数据库课题组基于众包标注系统构建的文言文数据集。该系统引入“二十四史”的全部文本内容,允许用户标注实体,并通过在线测试判断用户的专业度确保标注结果的准确性。该数据集被划分为训练集、验证集和测试集,实体主要包括人名、地名、组织名、职位名和书名,标注采用BIO(Begin Inside Outside)标注体系。表2是本文对实际获取的C-CLUE原始数据集的统计情况,实体主要包括人名、地名、组织名、职位名和书名,共22 502个实体。

表2 C-CLUE原始数据集的统计
从表2可看出,原始数据集标注的组织名实体、书名实体过少,甚至验证集中标注的书名实体为0。经检查数据集的标注情况,笔者发现数据集中各类实体标注都存在漏标的情况(见图2),人名实体“袁绍、高幹”、职位名实体“并州牧”、地名实体“壶关口”、组织名实体“御史台”、书名实体“《典言》”、“《质疑》”都是原始数据集中存在的漏标情况。

图2 实体标注漏标情况的部分展示
因此笔者基于原始数据集,根据C-CLUE数据集的标注规则对实体进行了补标。表3是对实体进行补标后C-CLUE数据集的统计情况,总共有24 982个实体。

表3 当前C-CLUE数据集的统计
为验证模型的有效性,笔者构建了自己的数据集----Siku数据集。笔者通过python对典籍《四库全书》中的《史部》内容进行了批量获取,并划分为训练集、验证集和测试集,采用BIO标注体系对其中的人名、地名、组织名、职位名和书名实体进行标注。该数据集格式如图3所示,其中实体类别数量如表4所示,共有25 558个实体。
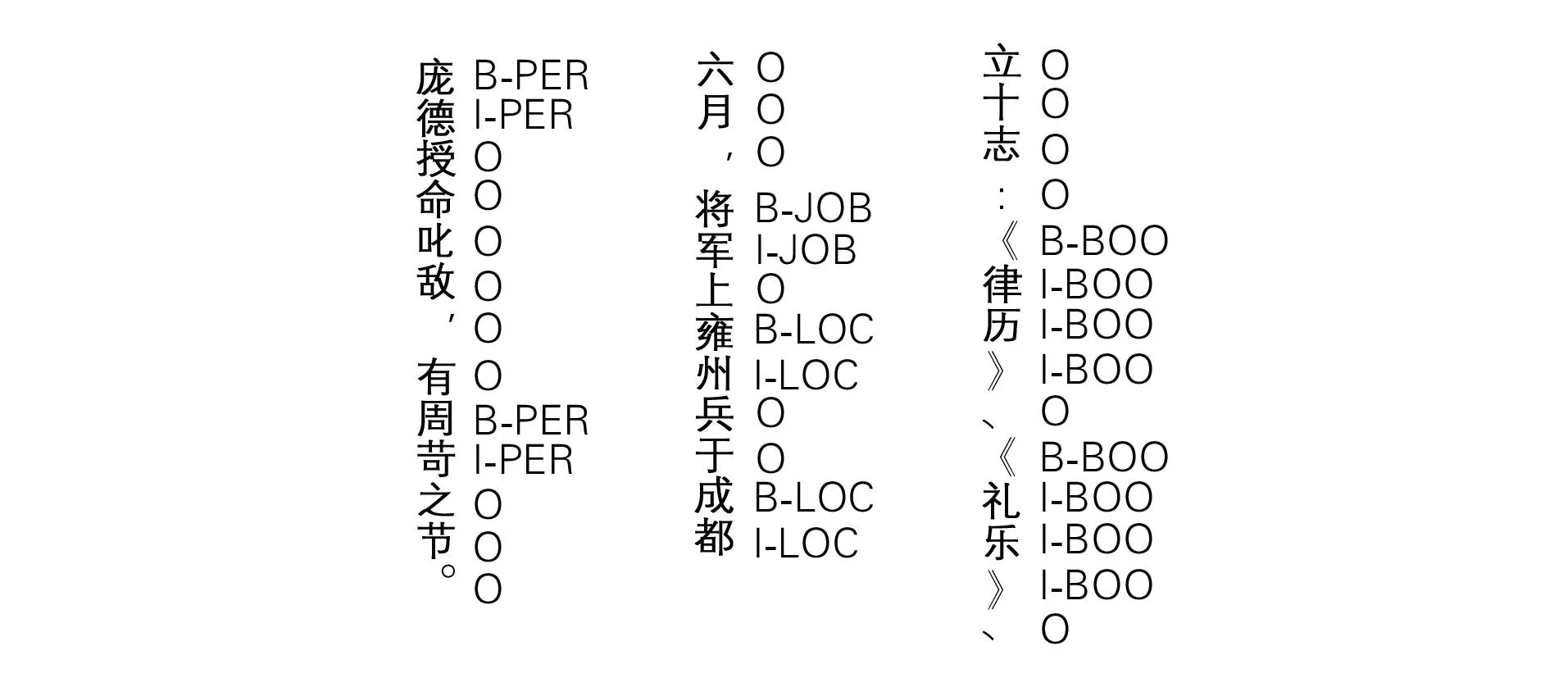
图3 Siku数据集部分展示

表4 Siku数据集的统计
3.2 实验设计
1) 实验环境与参数设置。实验模型采用PyTorch深度学习框架进行搭建,主要的实验环境如表5所示。

表5 实验环境
经过试验,主要的参数设置如表6所示。实验采用Adam优化算法对参数进行优化; 在BiLSTM的输入输出中使用Dropout防止过拟合,取值为0.5。

表6 实验参数设置
2) 实验结果的评价指标。笔者采用命名实体识别常用的评价方法,用精确率(Precision,P),召回率(Recall,R)和F1值(F1-score,F1) 作为评价指标,如下:

(11)
(12)
(13)
其中TP为模型预测实体标注正确的数量;FP为模型预测实体标注错误的数量;FN为模型没有预测出实体标注的数量。
3) 实验方案。首先,BiLSTM-CRF模型是命名实体识别领域的基线模型,因此设计了与BiLSTM-CRF模型的比较实验,并且为对比数据质量对实验的影响,将BiLSTM-CRF模型分别在实体补标前后的C-CLUE数据集上进行实验对比。其次,为分析多头注意力机制以及SikuBERT模型对实体识别的影响,设计了BERT-BiLSTM-CRF、SikuBERT-BiLSTM-CRF、BERT-BiLSTM-MHA-CRF以及SikuBERT-BiLSTM-MHA-CRF模型的比较实验,并将上述模型分别基于当前C-CLUE、Siku数据集进行实验对比。最后,为比较当前C-CLUE数据集包含的5类特点不同的实体的识别效果,设计了不同实体的识别效果的对比实验。
3.3 实验结果与分析
3.3.1 模型性能综合对比实验
在同一实验环境与条件下,对BiLSTM-CRF、BERT-BiLSTM-CRF、SikuBERT-BiLSTM-CRF、BERT-BiLSTM-MHA-CRF和SikuBERT-BiLSTM-MHA-CRF模型进行实验。表7是BiLSTM-CRF模型分别在实体补标前后的C-CLUE数据集上的实验对比结果,表8是以上模型在当前C-CLUE数据集上的实验对比结果。图4是以上模型在Siku数据集上的F1值对比情况。
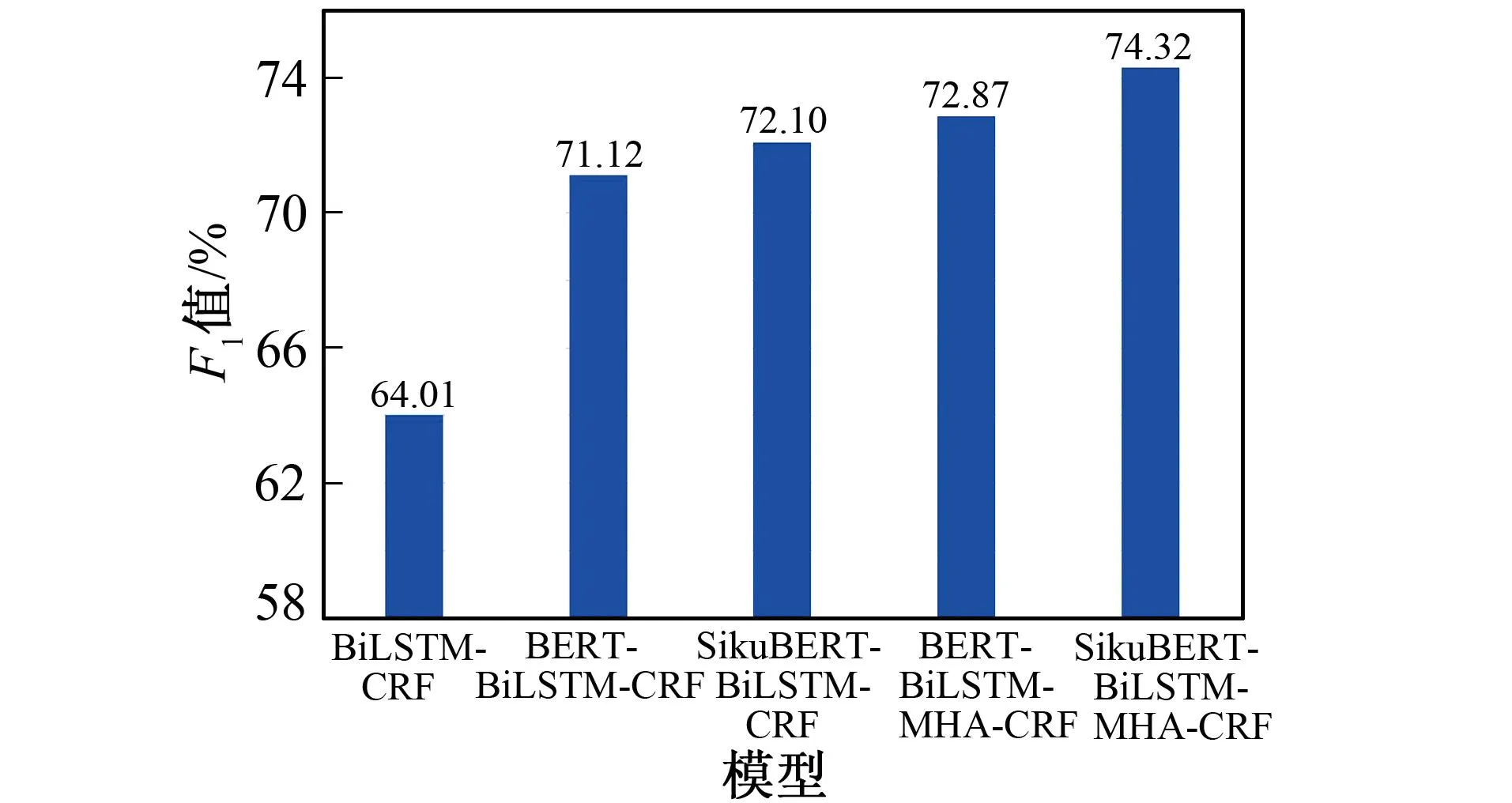
图4 Siku数据集上不同模型F1值结果对比

表7 BiLSTM-CRF模型在实体补标前后的C-CLUE数据集上的实验结果对比

表8 当前C-CLUE数据集上不同模型实验结果对比
从表7可看出,BiLSTM-CRF模型在实体补标后的C-CLUE数据集上的实验结果好于实体补标前的实验结果,模型识别的精确率、召回率、F1值均有较大提升。由此推测数据集质量的好坏对实验结果产生了一定的影响,数据实体数量越多,模型的学习和预测效果越好。
从表8可看出,与BiLSTM-CRF模型相比,加入BERT预训练模型的BERT-BiLSTM-CRF模型识别的精确率、召回率、F1值分别提升了1.27%、12.88%、7.06%,加入SikuBERT预训练模型的SikuBERT-BiLSTM-CRF模型识别的精确率、召回率、F1值分别提升了3.74%、11.72%、7.83%,说明加入预训练语言模型后,增加了表达结构位置、语义的信息,使模型识别效果有较大提升,并且由于SikuBERT模型预训练时的原始语料《四库全书》相对于BERT的中文维基百科语料更接近本实验的古汉语语料,SikuBERT-BiLSTM-CRF模型的识别效果比BERT-BiLSTM-CRF模型也要更好一些。与BERT-BiLSTM-CRF模型相比,加入了多头注意力机制的BERT-BiLSTM-MHA-CRF模型识别的精确率、召回率、F1值分别提升了2.65%、0.87%、1.84%,与SikuBERT-BiLSTM-CRF模型相比,加入了多头注意力机制的SikuBERT-BiLSTM-MHA-CRF模型识别的精确率、召回率、F1值分别提升了1.11%、3.78%、2.38%,说明用多头注意力机制增加了古汉语各类实体的权重,减少了信息损失,可以有效提升模型的识别效果。SikuBERT-BiLSTM-MHA-CRF模型比BiLSTM-CRF模型识别的精确率、召回率、F1值分别提升了3.92%、13.75%、8.9%,说明在BiLSTM-CRF模型的基础上,融合SikuBERT模型和多头注意力机制的SikuBERT-BiLSTM-MHA-CRF模型不仅能充分利用实体的结构位置以及语义信息,还能突出实体自身权重以及结构位置信息权重,减少信息损失,使模型实体识别更加有效。
从图4中Siku数据集上不同模型F1值对比结果可看出,与表7类似,与其他模型相比,笔者提出的方法取得的效果最好,进一步验证了SikuBERT-BiLSTM-MHA-CRF模型在古汉语领域的有效性、先进性与泛化能力。
3.3.2 不同类别实体识别效果对比实验
同一环境下,基于当前的C-CLUE数据集,用5组不同模型分别对5类不同实体进行识别,实验结果如表9所示。可以看出,书名实体的识别效果最好,这可能是因为书名实体周围有较为明显的特征,如符号“《》”,如“予观《春秋》《国语》,其发明《五帝德》《帝系姓》章矣”,因此能使模型获取较为明显的特征进而有效标注。人名实体因为实体数量较多,模型的识别效果也相对不错。而组织名实体因周围无明显的特征,且与上下文字符过于相似,不能很好地使模型学习到结构信息,从而导致识别效果不好。另外,笔者提出的融合SikuBERT模型和多头注意力机制的方法在书名、地名实体上未取得最佳的效果,这可能是因为书名、地名实体数量过少,且常以并列形式出现,规律比较简单,而提出的模型方法复杂度过高,导致过拟合,使模型识别效果下降。

表9 不同模型类别结果对比
4 结 语
笔者对古汉语领域的命名实体识别进行了研究,提出了一种融合SikuBERT模型与多头注意力机制的古汉语命名实体识别方法。该方法利用SikuBERT模型对古汉语语料进行预训练,将训练得到的信息向量输入到双向长短期记忆网络中提取特征,再利用多头注意力机制给BiLSTM层的输出向量分配不同的权重减少长序列的信息损失,最后通过条件随机场解码得到预测的序列标签。在C-CLUE和Siku数据集上的实验表明,该方法的识别效果好于常用的BiLSTM-CRF、BERT-BiLSTM-CRF等方法。
虽然本实验模型较基线模型识别效果有较大提升,但由于部分类别实体数量过少导致其识别效果依然不够理想。在未来的研究中,将扩大数据规模,同时针对组织名等类别实体与上下文字符过于相似,不能使模型很好地学习到结构信息等问题展开研究,以达到更好的识别效果。
猜你喜欢
潍坊学院学报(2021年4期)2021-11-20
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
汉字汉语研究(2018年1期)2018-05-26
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
语言与翻译(2014年1期)2014-07-10
外语教学理论与实践(2014年2期)2014-06-21
