
YOLO 模型结合图像处理方法实现铝棒准确识别与计数
2023-12-20 16:26毕晓琳侯卓轩张瀛天
科海故事博览 2023年35期
毕晓琳,侯卓轩,张瀛天
(广东东软学院,广东 佛山 528225)
1 前言
铝型材产品被普遍应用到人们实际生活的许多环节,比如铝合金门窗、灯饰等,与人们的生活联系密切。铝棒是铝型材成品的加工的原料,目前,多数铝材厂商采用吨作为包装单位的方式按重量进行铝棒原料的采购,但是实际生产中常常要了解掌握的是具体的铝棒条数,因而要求铝材厂商对采购的铝棒实现更快速准确的复核和验收计数。目前大多数铝材厂对铝棒的数量清点工作主要依靠人工清点完成。这种方法不仅造成人力物力的浪费,而且计数的准确率通常不高,计数结果难以复核。
随着计算机科学与技术的发展日益成熟,铝材厂商都倾向于使用更加智能的方式来代替一些重复、乏味的人力工作。20 世纪70 年代便有棒材自动识别计数[1]的实践。第一种方法是使用机械装置来分离棒材,然后在机械装置的基础上利用光电管实现自动计数[2],第二种方法是将数字图像技术运用到棒材图像识别和处理中,比如采用模板匹配的方法进行计数[3],或连通区域匹配实现棒材计数的方法[4]。尽管使用图像处理方法进行计数的相关技术已经比较成熟,但是该类实践对图像拍摄背景、图像采集设备有较高的要求。在上述所提的研究中,棒材都是垂直放置,且拍摄背景是纯色,非常容易将背景与棒材分离,但是铝棒在实际的加工生产过程中,由未经培训非专业的工人拍摄到的铝棒图片大概率不是垂直放置的,且拍摄背景杂乱,因此仅依靠一般的数字图像处理方法进行计数是不符合实际的。
结合卷积神经网络图像识别算法的优点,能够在复杂环境中准确识别特征图像。YOLO 是由Redmon et al.[5]于2016 年提出的一种只完整查看一次图像的识别模型,YOLO 与其他卷积神经图像识别算法相比,YOLO 模型将对象检测视为简单的回归问题,具有快速、准确的优点[6]。本研究使用YOLO 算法作为图像识别模型,并在使用模型识别之前,采用系列图像处理算法压缩输入模型的信息量,提升训练和识别速度。
2 实验样本
2.1 样本采集
在本研究中,拍摄的铝棒端面样本图像都是来自铝材生产车间,在自然灯光状态下拍摄,样本图像背景中有设备、墙体、屋顶等干扰因素。
用手机拍摄共图像1309 张,其中我们将样本又分为训练集、验证集以及测试集。训练集是用于模型拟合的数据样本,验证集是用于调整模型的超参数和用于对模型的能力进行初步评估。通常用来在模型迭代训练时,用以验证当前模型泛化能力,以决定是否停止继续训练。测试集是用来评估最终模型的泛化能力。
2.2 图像标注
使用YOLOv5框架进行目标检测必须先对图片进行标注,生成对应的txt文档。本研究样本标注使用在线图像标注软件Roboflow(https://app.roboflow.com/)。用Roboflow 生成YOLOv5 能够读取的标注信息。
由于识别目标为单独对铝棒检测和计数,图片中没有其他与铝棒特征相似的对象,因此我们只标注1个类,名为“Aluminum bar”。图片总共1309 张,被随机化分为3 组:943 张为训练集,266 张为验证集,100 张为测试集。所有的铝棒都进行了标注,总的标注6492 个。图片标注好之后进行导出,导出时将图片尺寸调整为640*640 像素,以适应YOLOv5 模型。
2.3 图像处理
标注工作完成后,将铝棒端面彩色图片进行灰度化处理[7],去除掉图片原本的色彩信息,简化了输入训练模型的信息量,以达到提高训练效率的结果。
在真实生产环境中,拍摄到的铝棒端面图像背景相对复杂,铝棒端面相较复杂背景亮度更高,因此为了使铝棒端面在背景中更加突出,对铝棒端面灰度图作对比度增强[8]的处理,使得铝棒端面和背景亮度差异更大。为避免复杂背景产生噪点影响模型准确率,将对比度增强后的图片进行了高斯滤波[9]去噪。
为了进一步缩减图像信息量,仅将铝棒端面的形态信息输入图像识别模型进行训练,我们将去噪后的图片采用Sobel 算子边缘提取算法[10]获取铝棒形貌信息,至此完成模型训练前的图像处理工作。
3 图像识别模型与分析
3.1 YOLO 模型结构
基于YOLO 模型在图像识别领域的有着模型简单、识别准确的优点,综合YOLO 几种模型的优缺点,本研究采用YOLOv5 模型作为图像识别模型。YOLOv5 的总体架构由四部分构成:输入端、Backbone、Neck 和Head。
Backbone 部分作为特征提取网络,主要是由Focus和BottleneckCSP 组成。
Focus 在减少计算量的同时实现下采样过程,Bottl eneckCSP 是此特征提取网络的核心。
Neck 部分采用了FPN 与Pan 相结合的结构。Head部分实现输出的功能,包括检测的Probability、Score以及Bounding-box。
3.2 模型训练与结果分析
在本研究的实验中使用的训练权重文件为YOLOv5m,使用Google Colab 提供的云GPU 进行训练。共训练了三组铝棒图片进行测试,581 张图片需要约7 小时13 分,450张图片需要5小时23分,178张图片需要2小时36分。
为了验证使用图像处理方法能够减少模型训练信息,提高模型训练速率,本研究做了两组对比实验。一组实验是直接将标注过的图片与和标注文件输入YOLOv5 模型进行训练,以下简称Y 模型。另一组实验则是在模型对图片进行训练前,对所有图片进行上述图像处理,再将图片和标注信息输入YOLOv5 模型进行训练以下简称M+Y 模型。
对于M+Y 模型来说,仅将铝棒形态信息输入模型,大幅压缩了图像样本信息量,因此训练时间得到大幅缩短。
本研究中,为排除偶然性的结果,采取不同数量的训练集和验证集图像,输入Y 模型和M+Y 模型进行训练,总共训练3 次YOLOv5 模型,综合比较训练时长。每次训练模型输入的训练集、验证集图像数量,以及Y模型与M+Y 模型的训练时间对比如表1 所示。结果表明,不论训练集和验证集图像数量多少,采用图像处理方法先提取有效信息再训练模型,都能大幅提升训练速度。M+Y 模型的平均训练时间仅为Y 模型的15.16%,平均训练时长大约缩短了85%。
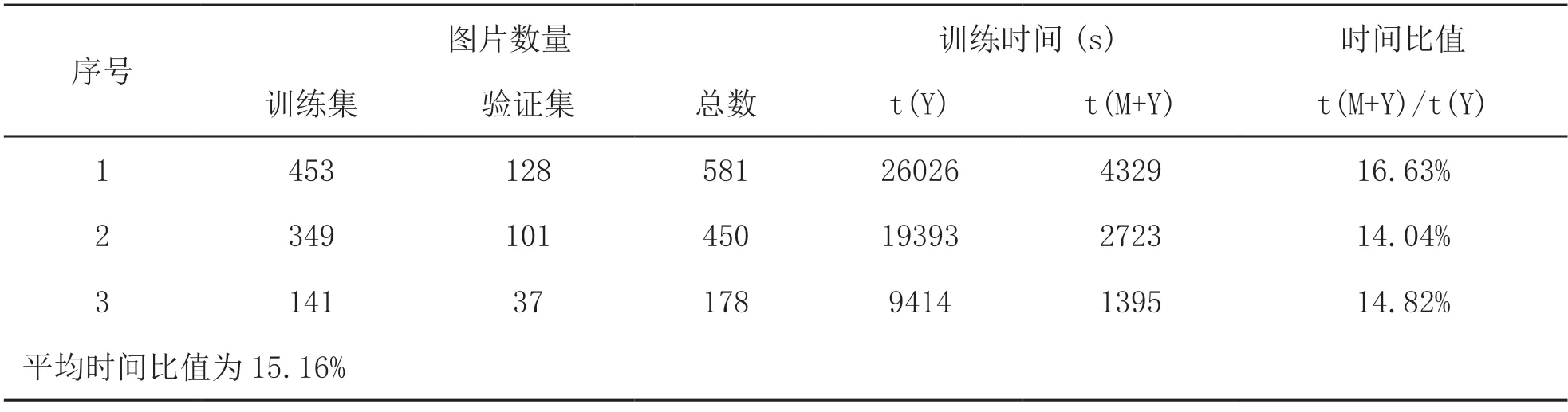
表1 模型和M+Y 模型训练时长对比
此外,在本研究中,使用准确率作为模型评估的标准,其中准确率分为单张图片(简称单图)的准确率和总体准确率。单图准确率定义为:
其中,i为本张图的序号,AI(Accuracy of one Image)为单图准确率,AN(Actual Number of aluminum bars)为单图中实际铝棒数,DN(Detected Number of aluminum bars)为单图中检测出的铝棒数量。n 张铝棒识别图的总体准确率定义为:
其中,A(n)为n 张图的总体准确率,AI(Accuracy of one image)为单图准确率。
运用Y 模型与M+Y 模型通过YOLOv5 训练,分别得到两个权重文件,即Y.pt 与MY.pt。分别使用这两个权重文件对100 张铝棒图进行识别与计数,其中100张铝棒图包含54 张来自测试集与46 张来自验证集的图像。将识别计数结果统计整理,Y 模型与M+Y 模型的总体准确率如表2 所示。若不采用图像处理方法,直接将铝棒彩图输入YOLOv5 得到的Y 模型的总体准确率为70%,而采用图像处理方法得到的M+Y 模型的总体准确率为84%。

表2 Y 模型与M+Y 模型的总体准确率
4 结论
本研究表明,在对铝棒端面图像进行铝棒识别计数的实践中,先采用图像处理方法提取有效信息,压缩图片信息,大幅减少输入模型训练的信息量,能够有效地提高训练速率,并且由于排除了无关信息造成的误差,识别计数的准确率也得到了提升。在本研究中,压缩铝棒图像信息量后,训练时长仅为未压缩前的15.16%,训练速度的大幅提升为实现模型自适应提供了实践基础。在真实铝材加工工厂的生产流程中,各生产线上有大量工人会在不同流程阶段在一天内多次使用该铝棒识别计数软件,一天累计新拍摄的铝棒端面图像有可能上千张,因此为了模型的优化,模型需要自适应地将新拍摄的图像作为补充训练样本,使模型能够“认识”更多各样格式排列的铝棒,从而提高模型的准确率,而在真实生产应用中,如果要频繁地自适应重新训练模型,且不耽误软件的日常使用,则对模型训练速度有极高要求。因此,本研究提出的先提取图像有效信息再进行模型训练的识别计数方法,不仅使训练速度得到大幅提升,而且能提高识别计数准确率,为棒材识别计数以及模型自适应发展提供了新的研究方向。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年19期)2018-11-14
电子制作(2018年18期)2018-11-14
电子制作(2018年14期)2018-08-21
电镀与环保(2017年6期)2018-01-30
电气化铁道(2016年4期)2016-04-16
设备管理与维修(2016年6期)2016-03-16
