
基于深度学习的微博舆情监测模型研究与实现
2023-12-18 18:13成哲丞
计算机时代 2023年11期
成哲丞

关键词:Java 分布式爬虫;Elasticsearch;注意力机制;Bi-LSTM;舆情预警
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)11-124-03
0 引言
网络空间不是法外之地,网络舆情监管和应对是一个非常棘手的问题。目前针对网络舆情监测的研究主要存在以下问题。
⑴ 针对单一事件:当前对网络舆情的监测往往都是针对已发生的且有着负面影响的事件,通常研究的舆情事件比较单一[1]。
⑵ 实时性差:由于网络事件所带来的海量数据,当前对事件进行舆情监测时不能够很及时,且往往没有考虑当数据量大时,系统的运行效率问题[2]。
⑶ 准确率低:当前对网络舆情事件的预警研究较少,且由于评论数据的多样性、复杂性,导致舆情预警的准确率不够高。
针对上诉问题,且为了提升舆情监测系统的性能和准确率,以新浪微博作为数据源,本文在传统舆情监测系统架构和情感分析方法的基础上提出了一种基于深度学习的微博舆情监测模型。本模型旨在监测和分析微博热搜的舆情信息,了解公众对某个话题或事件的态度和反应,及时对发生负面舆情的事件进行监测。
1 热搜数据采集与处理
1.1 基于Java 的分布式数据爬取框架
本节针对性地设计实现了一个基于Java 的分布式数据爬取框架,该框架可快速爬取新浪微博热搜榜的全部评论数据。该框架的结构如图1 所示。
该框架重要组成部件的相关功能作用如下:
⑴ 爬虫定时器(SpiderTimer):爬虫定时器负责定时地调用爬虫启动器;
⑵ 爬虫任务池(SpiderTask Pool):爬虫任务池负责管理子爬虫任务的权值,权值越大的子爬虫任务会被优先相应;
⑶ 爬虫管理器(SpiderManager):爬虫管理器会将子爬虫任务分配给爬虫线程池。同时爬虫管理器还会将爬虫返回的结果交给结果处理器;
⑷ 爬虫线程池(SpiderThread Pool):爬虫线程池负责将得到的子爬虫任务分配给池内空闲的线程,一条线程对应一个爬虫。
1.2 数据预处理
爬取到的原始评论数据可能存在着没有结构化,格式不规范等问题。为了之后更好地进行情感分析,提高情感分析模型的准确性,“纯净”的数据集是十分必要的,因此需要对爬取到的原始评论数据进行规范化处理。规范化处理主要包括三个部分:数据清洗、文本分词和去除停用词。经过上述规范化处理之后,将会得到“纯净”的标准化数据。
1.3 基于Elasticsearch 的分布式搜索存储方法
考虑到舆情监测模型的实际需求,基于Elasticsearch[3]的分布式搜索存储方法会维护一个热搜哈希表。热搜哈希表中存储的是登上过新浪微博热搜榜的热搜信息。哈希表的Key 值为热搜名,Value 值为热搜的相关信息。热搜的相关信息包括热搜名、导语、话题阅读次数、话题讨论次数、媒体报道次数、通用唯一标识符、年龄和情感状况。
哈希表中的一条数据对应一条热搜,也对应着Elasticsearch 中的一个索引库。该方法的存储逻辑如图2 所示。
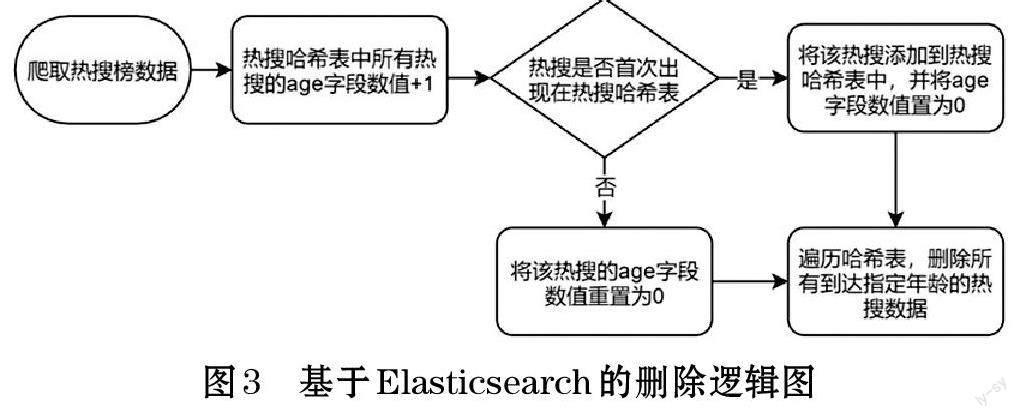
考虑到实际环境下评论总数每天可达数十万,甚至上百万条。及时地删除过时话题的数据,释放服务器资源是十分必要的。方法的删除逻辑如图3 所示。
2 融合改进注意力机制的Bi-LSTM 情感分析方法
2.1 方法原理
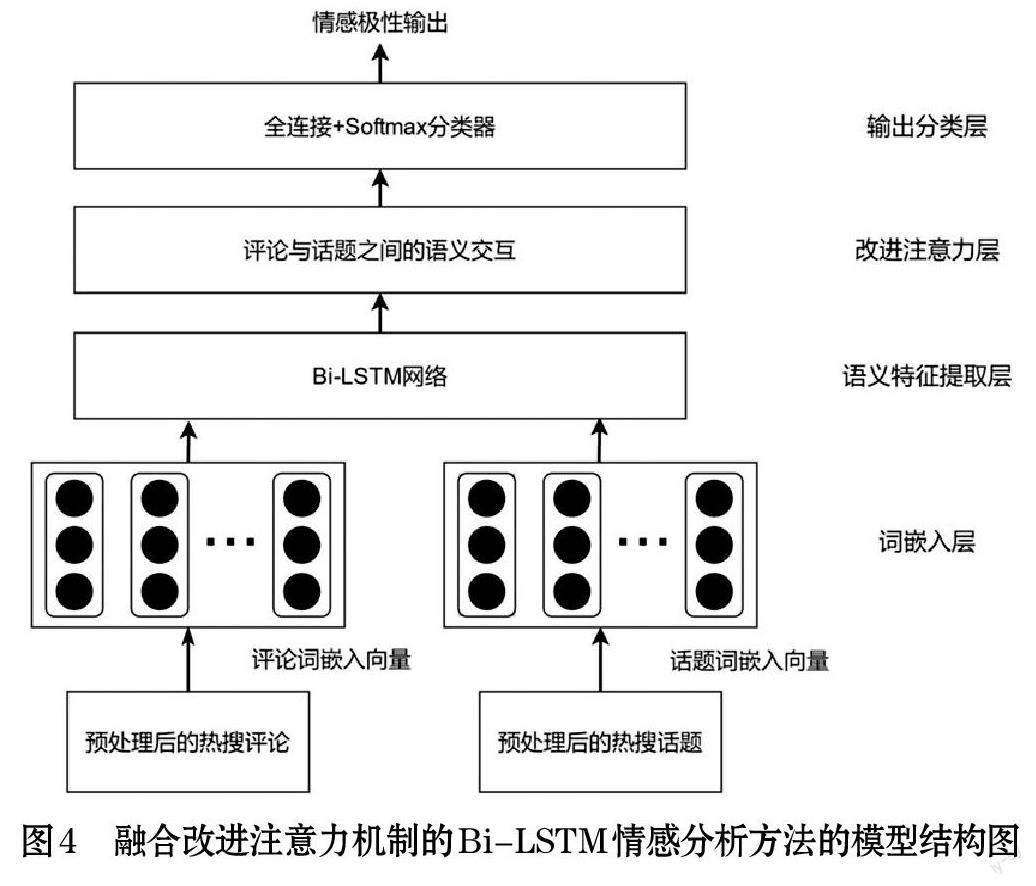
为了对用户评论进行情感分类,本章提出了一种融合改进注意力机制的Bi-LSTM 情感分析方法。该方法会降低热搜话题自身所带情感度的影响,更关注用户自身评论,更精确地分析用户评论的情感倾向。该方法所用模型的结构图如图4 所示。
由图4 可知,各层的工作内容为词嵌入层:通过Word2vec 中的Skip-Gram 模型[4]对热搜话题和评论进行向量化处理;语义特征提取层:通过引入双向长短期记忆神经网络(Bi-LSTM)来获取评论中上下文之间的信息;改进注意力层:通过引入改进注意力机制[5]来降低话题自身所带情感度的影响。输出分类层:将上一层的输出结果进行全连接,再通过Softmax 函數进行情感分类。其中改进注意力机制的工作流程如图5 所示。
由图5 可知,先计算计算话题词(query)与用户评论词(key)的相似度。再选择某种方式将相似度转换成最终的注意力得分(目的降低话题词的权重),这里可以选择将相似度取反的方式。接着通过softmax 函数对注意力分数做一个归一化,得到每个key-value 的注意力权重,将注意力权重与每个key 对应的value相乘,再求和,就可以得到最后的输出结果。
2.2 对比实验结果
本实验选用了CNN 和Bi-LSTM 两种当下最为常用的深度学习模型来做对比实验。实验数据集选用了CCIR 2020“疫情期间网民情绪识别”评测活动数据集和微博情感分析数据集,并把上述两个数据集都进行了8:1:1 的划分。实验指标选用了准确率(Accuracy)、查准率(Precision)和F1 值(F1-Score)三种。实验结果对比情况如图6 所示。
从图6 实验结果可以看出,融合改进注意力机制的Bi-LSTM 情感分析方法在公开数据集一和二上的效果都明显优于CNN 和Bi-LSTM 两个模型。
3 基于情感分析的舆情预警等级计算方法
基于情感分析的舆情预警等级计算方法[6]先利用用户评论的情感极性、点赞数和转发数计算出热搜话题的情感度。再根据热搜话题的阅读量、评论数、热搜话题情感度和热搜话题类型来计算话题的舆情预警等级。舆情预警等级计算方法的原理如图7 所示。
3.1 热搜话题情感度计算
先计算热搜话题下所有评论的情感倾向得分之和,其中正向情感得分为1,中性情感得分为0,负向情感得分为-1。再根据得分之和和评论数量计算热搜话题的平均情感倾向得分Score。为了减小不同话题之间平均情感倾向得分的差异,便于更加直观的得出热搜话题的情感度,最后利用Sigmoid 函数将平均情感倾向得分映射到(0,100)区间中,得到热搜话题的情感度E。热搜话题情感度的计算公式如下:
3.2 热搜话题舆情预警等级计算
参考网络舆情预警等级的划分,本方法将新浪微博热搜话题舆情预警等级分为了无风险、低风险、中风险、高风险和紧急预警这五种等级。热搜话题的情感度是定性的,决定了热搜话题的情感度好坏情况。热搜话题情感度[0,50)被认为是负面话题,[ 50,100]被认为是正面话题。而话题阅读量、话题评论量、媒体报道数、话题类型等数据是定量的,会影响热搜话题的舆情状况,但不会改变热搜话题的情感极性。热搜话题舆情预警等级计算公式如下:
其中,β1、β2、β3分别是话题阅读量、话题评论量、媒体报道数各自相较于其他热搜平均水平的百分比,同时还需对这些百分比设定一个最高值限制。β4表示话题类型的权重值,不同的话题类型设有不同的权值。计算完舆情预警等级分数,就可以将舆情预警等级分数映射到不同的舆情预警等级标签上。
4 总结
随着互联网的普及和社交媒体的兴起,网络舆情监测和管理变得越来越重要。本文提出的基于深度学习的微博舆情监测模型可以实时监测微博上的舆情状况,了解公众对某个事件或话题的态度和看法,从而帮助企业、政府等各方面做出更加准确的决策,预防发生舆情危机。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
小雪花·成长指南(2022年1期)2022-04-09
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
传媒评论(2017年3期)2017-06-13
电子制作(2017年9期)2017-04-17
第二课堂(课外活动版)(2016年2期)2016-10-21
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
