
基于YOLOv5的超市自动取货机器人设计与实现
2023-12-18 10:42:15高骏一郑榜贵王颖雪刘楚彤柳雨萌关景华
计算机时代 2023年11期
高骏一 郑榜贵 王颖雪 刘楚彤 柳雨萌 关景华


关键词:YOLOv5;神经网络;目标检测;自动取货;机器人
中图分类号:TP391.4;TP242.3 文献标识码:A 文章编号:1006-8228(2023)11-22-06
0 引言
为客户提供快速、便捷和舒适的购物环境是各大商场和超市所追求的目标。本文结合YOLOv5 神经网络识别算法,设计了一款超市自动取货机器人,力求在一定程度上减轻物流行业的压力,提升服务工作效率,同时尽量避免因人群聚集而引起的病毒传播。
1 整体设计
为使自动取货机器人具有独立决策、并行高效的特点,设计的机器人在树莓派上运行YOLOv5 算法。机器人底层硬件控制部分采用了树莓派4B,具有4G内存,搭载64 位操作系统Raspberry,给在树莓派上实现YOLOv5 算法的目标检测提供了保障。
在上层主机上配置YOLOv5 环境,下载源码,使用数据集进行训练。在底层树莓派上配置YOLOv5运行环境,主机通过VNC 软件与树莓派建立远程连接,树莓派控制摄像头进行图像获取,并通过无线传输的方式将图像传输给主机。如图1 所示。树莓派利用部署在主机上的YOLOv5 模型进行图像识别并返回识别结果,再控制机械臂进行抓取。
2 软件设计与实现
YOLOv5 的检测系统主要分为三个阶段:
⑴ 数据预处理,将输入图像缩放到统一的大小(将分辨率调整到448 ×448,见2.1.3),然后进行数据增强以增加模型的泛化能力。
⑵ 將图像通过全卷积神经网络。
⑶ 利用极大值抑制(NMS)进行筛选以去除冗余的检测框。
通过上述流程,结果中会显示最具有代表性的框,且具有较小的误检率和重复率。
2.1 YOLOv5 工作原理
YOLOv5 是基于卷积神经网络、网格视角和多尺度预测技术的目标检测技术,它能够快速准确地检测目标物体。YOLO 采用回归方法来解决物体检测问题,使用“端到端”网络,实现了从输入原始图像到输出物体位置和类别的全过程。YOLO 主要有以下突出特点[1]:
⑴ 不像其他目标检测算法采用回归问题+分类问题的检测方式,而是将目标检测当作一个回归问题来处理。
⑵ YOLO 使用单个网络进行目标检测,仅需一次前向传播即可输出图像中所有目标的检测框和类别信息。这种端到端的方法不仅方便了训练和优化网络,同时也提高了检测的速度和效率。
2.1.1 网络结构
YOLO 的检测网络由24 个卷积层和2 个全连接层组成。卷积层用于提取图像特征,全连接层用于预测目标的位置和类别概率。此外,YOLO 采用了多个下采样层来增加网络感受野以提高目标检测的准确性。YOLO 的网络结构受到了GoogLeNet 分类网络的启发[2],但与GoogLeNet 不同的是,YOLO 没有使用Inception 模块,而是使用1 × 1卷积层和3 × 3卷积层的简单组合来代替。
2.1.2 输出
YOLO 的目标检测方法将输入图像划分成一个S×S 的网格,在每个网格上预测出B 个边界框以及每个边界框所属物体的类别概率。当某个物体的中心点位于某个网格中时,该网格就负责检测该物体。每个边界框包含五个信息:中心点坐标(x, y)、宽度、高度以及边界框所属物体的置信度[3]。在卷积神经网络中,B 和C 的数量是预先设定的。
2.1.3 模型训练原理
⑴ 预训练。YOLO 网络的前20 个卷积层、1 个平均池化层和1 个全连接层使用ImageNet1000 类数据进行训练[4]。输入的图像被调整到224×224 的分辨率。
⑵ 使用步骤1 得到的前20 个卷积层的网络参数来初始化YOLO 模型前20 个卷积层的网络参数,然后使用标注数据进行训练。为了提高图像精度,训练过程中将输入图像的分辨率调整为448×448。
2.2 基于YOLOv5 的目标识别
2.2.1 系统训练
找到相关数据集共4100 张,其中包含“apple”,“permission”,“orange”等共9 类。在运行YOLOv5 程序前,需先对数据集进行标签化处理。由于图像标注工具“labelimg”具有速度快,以及可保证数据质量与准确性的特点,最终选择该平台进行数据标注。最终得到有效标签4000 个。
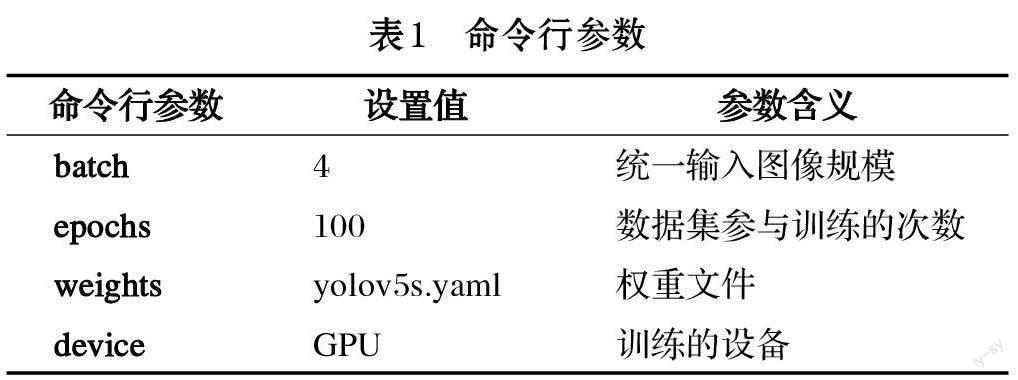
训练执行前,进行了命令行的参数预设,预设结果如表1 所示。
在训练过程中,模型通过反向传播算法计算梯度,并使用梯度下降算法来更新模型的权重参数,以最小化损失函数。本文使用的模型是YOLOv5s,在训练过程中,主要更改的是整个网络结构的权重参数。这包括主干网络和预测头网络。主干网络通过修改各层的权重参数,以获得更全面的特征信息。预测头网络则通过修改各层的权重参数,包括路径聚合和检测头,以提高检测性能,并使其适应于检测不同尺寸的目标。本文利用PyQt5 构建了可视化界面,增添了视频文件识别模块和摄像头实时识别模块。最终可视化界面如图2 所示。
2.2.2 目标识别
从以下评价参数对所得训练结果进行分析:
其中,T/F 表示最终预测是否正确(True/False),P/N 表示模型预测结果为正例或为负例(Positive/Negative),TP 表示模型预测结果为正例且正确的识别数量,TN,FP,FN 含义同理[5]。下同。
由式⑴可知,准确率是最简单、最直观的评价指标。但当样本分布不均时,指标的计算结果会被占比大的类别所主导,从而导致较大的误差。同时,由该公式得到的结果太过于笼统,实际应用中,可能更加关注某一类别样本的情况。
很明显,精确率和召回率是一对相互矛盾的指标,一般来说高精准率往往对应着低召回率,反之亦然。
精确率-置信度关系图与召回率-置信度关系图则是为更加直观地体现识别结果。为使实验结果更具代表性,本文中使用的各类数据集总数并不一致,其中“pear”和“mongo”等类的数据集数量较少。
由图3 可知,对于数据集数量较少的“pear”类和“mongo”类的准确率函数和随置信度(Confidence)的变化波动性极大,而对于“orange”等类的函数值较为稳定,且非常靠近1,这表示其精度较高。同时可知在置信度为0.902 时即可保证所有类别的识别结果正确的概率为1,其值较为可观。
类似地,由图4 可知,“pear”类和“mongo”类的召回率函数在相同的置信度条件下的函数值同样较小,“orange”等类的函数值较高。当置信度小于0.96 时,可识别较多的目标物体类别。
除此之外,在评估中还有精确率-召回率关系图。在该图像中,还涉及到了IoU,mAP 两个参数。
IoU 为深度学习模型中的常见评估指标,其常常用来评估性能。该指标表示预测边界框与真实边界框的重叠程度[7-8]。令A 为预测边界框面积,B 为真实边界框面积,则IoU 计算如下:
其中,A ∩ B 表示预测边界框和真实边界框之间重叠区域的面积,A ∪ B 表示两个边界框所占据的总区域的面积。显然,IoU 的值越大,表示检测器的性能越好。
mAP(Mean Average Precision),即均值平均精度,表示每个类的AP(Average Precision)的平均值[9]。
在表示時,常常表示为“a mAP @ b”,其中a 表示mAP 值,b 表示IoU 的阈值。在精确率-召回率关系图中,其图像与横坐标所围面积即为所求的均值平均精度[10]。一般地,我们希望曲线可以尽可能的地靠近(1,1)点,即所围面积尽可能地靠近1,这样所得的平均精度最高。如图5 所示,本系统的平均精度为0.844,其值较高。
我们通过图6 可视化训练结果,更加明显地体现上述参数的波动性:上述几个函数随训练轮数的增大,波动不是很大,且体现出稳步上升趋势。
⑶ 损失(loss)函数
YOLO 使用均方和误差作为损失函数,即计算输出的S × S × (B × 5 + C)维向量与真实图像对应的向量的均方和误差[11]。如式⑸所示:
在损失函数图像中,通常使用Box_loss 表示bounding box 的损失,其值越小则表示方框越准,式⑸中对应coordError;使用Objectness_loss 表示目标检测损失均值,其值越小则目标检测越准,在式⑸中对应iouError;使用Classification_loss 表示分类损失的均值,其值越小则分类越准,式⑸中对应classError。由图7可知,无论是在训练集还是在验证集中,随着训练轮数的增大,以上三种函数均体现出较好的函数趋势。
2.3 机器人控制端软件实现
主机通过VNC 软件与树莓派建立远程连接,为树莓派安装Opencv 与Pytorch。通过文件传输将主机上训练好的pt 模块传入到树莓派上,用Linux 命令进入到YOLO 文件夹中并运行detect 文件。
2.3.1 图像识别
以图像中心点的(x,y )坐标作为设定值,以当前获取的(x,y )坐标作为输入值更新pid。电机速度会根据图像位置的反馈进行计算,最后通过位置的变化使速度值发生线性变化,从而达到物体跟随的效果。
2.3.2 舵机控制
在上位机识别出商品类型后,如果与要抓取的商品类型相同,上位机会向树莓派发出指令,启动抓取程序,机械臂根据之前记录的(x,y )坐标值抓取物体。
根据舵机的规格,将逆运动学计算得到的角度转换为相应的脉冲宽度值。其中最小脉冲宽度对应于舵机的最小角度,最大脉冲宽度对应于舵机的最大角度。接着,使用控制器或微控制器的输出引脚,生成相应的PWM 信号。舵机接收到PWM 信号后,解析脉冲宽度值,并根据该值控制自身的位置。舵机内部的电路将根据脉冲宽度的变化来决定舵机的转动方向和速度,从而使舵机转动到与脉冲宽度对应的角度位置。
3 硬件设计与实现
样机采用了TankPi 机器人,在其中结合了软件的功能,实现了视觉识别系统和运动系统的合并,使其能够实现在超市中自动识别、取货。
3.1 运动结构设计
针对机器人运动系统功能要求,选择履带作为机器人行走构件,高压舵机作为履带的驱动机构。履带能很好地保证机身运动时的流畅性与便捷性,履带结构不易打滑,在机器人运动时能提供稳定的状态。同时,履带的装配能实现前进、旋转能功能,使机器人能在实际应用场景中灵活地运动,实现所需的取货功能。机器人在面对实际应用场景中常常有负重的情况,故采用LX-224HV 高压舵机以保证在小车在各种情况下的正常运行。
3.2 控制系统设计
本机器人的控制器设计采用基于树莓派的微控制器。树莓派有完善的操作系统,且对Python 的支持很好。使用Python 语言可以快速地在树莓派上开发控制机器人各类结构的软件。控制器算法设计采用YOLOv5 实现视觉识别目标物体,可方便地在树莓派4B 上运行。另外,树莓派体积小巧,占用机身空间很小,是主控器的理想选择。
机器人的环境感知方面,主要采用了摄像头和超声波传感器。2 自由度的高清晰度摄像头能实现人脸检测、颜色识别等等视觉识别功能。摄像头安装设计时增加LFD-01 防堵转舵机和LD-20MG 数字舵机,这样能使摄像头的转动角度增加,从而大大增加了检测画面的范围。同时,机器人的超声波传感器能通过发射超声波并接收反射的超声波,通过发射波和接收波的时间差来计算机器人与目标物体的距离。摄像头和超声波传感器的融合能使机器人实现较为复杂的抓取物品控制,还能实现机器人的自动避障功能。
机器人的目标物体抓取方面,采用了BigClaw 合金爪作为实现抓取功能的机械爪。3 自由度的机械爪能胜任许多物品的抓取。通过树莓派控制器,机器人可以实现目标物件的抓取控制功能。
将上述的机器人运动部件、控制器、传感器、抓取爪和供电模块进行集成并组装,形成了本设计的超市取货机器人样机。组装时,首先将底部的机器人运动部件履带作为底座,再采用金属框架搭建,将机械臂安装到金属框架的前端,形成机器人抓取的空间环境。然后,将机器人的控制器主板固定在靠近机器人的几何中心位置,完成电机与控制器之间的正确连线。最后,将机器人的传感器部件安装在控制器主板上方,其中摄像头固定在机器人的最上方,为机器人的图像采集提供合适的视野,并完成传感器与控制器的正确连线。
机器人系统框图如图9 所示,机器人树莓派控制器根据顾客的物品需求,通过摄像头采集到图像数据,利用基于YOLO 网络的算法软件,识别到目标物体的存在,再融合超声波传感器的检测信息,获得了目标物体的三维位置信息。控制器通过计算得到了运动路径信息,并将该信息传送至运动机构,履带运动至目标位置后,控制器再发送抓取命令至机械臂,抓取目标物体,并搬运到指定地点。
4 系统测试
为了对机器人样机进行功能测试,本文构建了如图10 所示的实验场景。
⑴ 将机器人被放置在一个超市货架前,货架上陈列着各种商品,例如:苹果、香蕉、橘子等等。
⑵ 机器人通过摄像头识别每个商品的种类和位置,并将识别结果传回系统。
⑶ 发出抓取命令,观察机器人是否能够正确成功抓取。
实验测试发现,测试中发出抓取苹果的命令,机器人成功在货架中抓起了苹果,并运送至实验员面前。
经过多次测试发现,机器人能够在实际应用环境中成功运行YOLO v5 视觉识别系统。如图11 所示,在50 次系统测试中,对目标物体的识别置信度浮动在0.85 上下。其准确性与软件算法的模拟结果接近,达到预期目标。
此外,在测试过程中发现机器人还能完成利用超声波传感器进行障碍规避行驶的自动避障。同时,机器人也能实现目标物体的跟随。
5 结束语
本文阐述了基于YOLOv5 网络的超市自动取货机器人的设计与实现,包括软件设计以及硬件设计组装,得到的机器人样机经过测试取得了较高的准确率与稳定性。在后续研究中,将尝试在实际超市环境下做目标物体的检测实验,验证YOLOv5 算法的有效性和硬件设计的可靠性,并根據实验结果对机器人样机进行改进优化,简化参数的复杂程度,以进一步提高样机的识别速度和准确性。同时,尝试使用更多商品种类和拍摄角度进行训练和优化,进一步增强模型的泛化能力,争取避免漏检漏取等情况。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
重型机械(2016年1期)2016-03-01 03:42:04
科技视界(2016年4期)2016-02-22 13:09:19
大连工业大学学报(2015年4期)2015-12-11 04:06:52
少儿科学周刊·少年版(2015年4期)2015-07-07 21:13:44
少儿科学周刊·少年版(2015年4期)2015-07-07 21:09:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:08:08
