
基于深度学习的智能机器人语音自动校准系统
2023-12-18 05:53金豪圣
电子设计工程 2023年24期
金豪圣
(国网浙江省电力有限公司信息通信分公司,浙江杭州 310000)
近几年,随着智能机器人技术的不断发展,人们将各种不同的信息输入到智能机器人中。当前,大部分的语音处理软件都是在收到声音之后,利用云计算服务或者语言分析引擎或者模型来寻找与声音相符合的词语。并且通过用户接口查询一个或者更多的词汇,使用户能够确定智能机器人语音是否正确,如果用户确定语音是对的,就直接输出;如果用户确定语音是错的,就把正确的语音输入到语言分析引擎中,以便对话音分析机制进行再训练。但是,该系统的不足之处在于,它必须时刻向使用者提问,从而对语言分析模式进行修正,因此造成使用者的不便。目前提出的基于深度前编码卷积网络的校准方法,首先构建语音序列模型,通过该模型判断语音序列长度敏感度。然后使用深度卷积神经网络构建语音校准模型,并对音频频谱特征进行分析和前编码处理。最后通过提取深层特征缓解建模压力,实现对语音的精准校准[1]。提出的一种多尺度前向注意力模型的校准方法,首先建立正向注意力模型,通过计算不同时间点的注意力分数,使模型得到最优解。然后根据该模型将多尺度正向注意力与多层次语音相结合,并将所得的多层次目标矢量进行融合,解决了注意力分数异常情况,从而实现了语音的校准[2]。然而,目前使用的校准方法容易受到用户多样性意图和多样任务执行的适应性影响,导致语音校准结果不精准。为此,提出了基于深度学习的智能机器人语音自动校准系统,实现用户多样性意图和多样任务执行之间的松散耦合。
1 系统硬件结构设计
1.1 语音自动校准引擎A/D电路
为了解决智能机器人语音信号的采集要求采用了模数变换,以提高采样效率,一般采用150 kHz 以上的频率,实现语音自动校准[3-4]。A/D 转换电路的校准是智能机器人语音转换的重要环节,它可以从电路中获取原始的语音信号,从而提高系统自动纠错语音的准确性[5]。A/D 转换使用多核频振荡器集成了智能A/D 取样结果,该过程所需的采样芯片由I2C 总线提供15 V 的输出电压。一般情况下,采用4路15 比特A/D 电路转换器进行并联和串行控制,以保证A/D 变换电路输入电压稳定[6]。在设计语音精度数据采集电源时,采用115 V 的数字信号处理(DSP)板对电容进行滤波处理。通过模拟信号发射范围进行同步采样,由此完成语音自动校准引擎A/D 电路的设计。
1.2 音频接收器
使用一种紧凑型嵌入式音频接收器,该接收器结构如图1 所示。
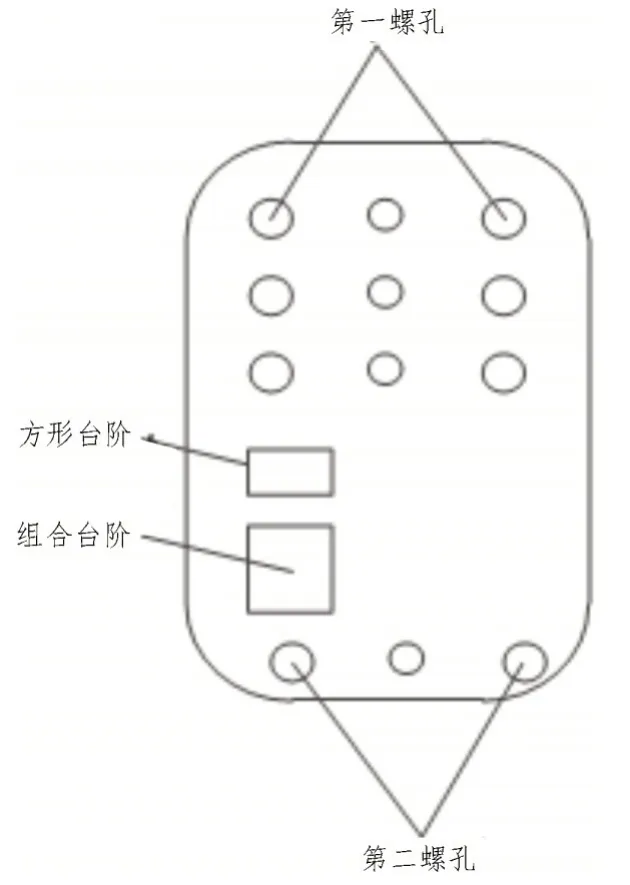
图1 音频接收器结构
由图1 可知,音频接收器结构主要是由后箱、主板、前盖、USB 组成,其中后箱的中间部分是一个底部箱,底部箱的开口前面设有一个容纳底部箱的空间,底部箱的前面设有一个卡边,该卡边包含一个固定盘,并且在固定盘的第一个螺丝孔上设有一个固定片[7];固定片与主板连接,该主板置于底部盒体的容纳空间,并与该底部箱体的背面固定相连,该USB插口固定在该主板的前端;前盖设置在后箱的前面,在前盖的上、下各有一个螺丝孔,在盖子上也有一个正方形的阶梯孔,这个阶梯孔由一个前阶梯孔和一个后面阶梯孔组成[8];前盖通过第一螺孔、第二螺孔以及后箱体被紧固;USB 前端被封入背景台阶孔中,可用作顶板支承[9]。
2 系统软件部分设计
基于深度学习的智能机器人语音自动校准流程设计如下所示:
步骤1:通过对历史语音资料的语音识别,将其转化为拼音语句的文本数据集,并通过修正语句中的文本数据集获得正确的语句文本样本集[10]。
步骤2:采用深度学习建立校正模型,校正模型建立的详细步骤如下所示:
1)校正模型输入部分的构建
将所有拼音按照字母顺序依次排列,形成拼音词典。利用拼音词典对步骤1 中的拼音语句文本数据集xp进行编码处理,由此得到输入校正模型的部分内容。对于所得的输入内容中每个样本都具有一个n维的稀疏矩阵,利用word2vec 对输入样本进行词嵌入训练处理,得到训练后的矩阵[11]。
对于输入的样本文字位置,使用正弦和余弦函数进行编码处理,公式为:
式(1)中,w表示文字位置;n表示维度。在获取位置编码后,将位置编码和嵌入矩阵依次叠加,得到输入样本集合[12]。将得到的输入样本集合输入到注意力模型中,该模型可表示为:
式(2)中,q表示查询矩阵;c表示密钥矩阵;u表示价值矩阵;dc表示注意力维度;cT表示密钥矩阵的转置[13]。将注意力模型输入到前馈神经网络中进行训练,基于深度学习的前馈神经网络结构如图2所示。
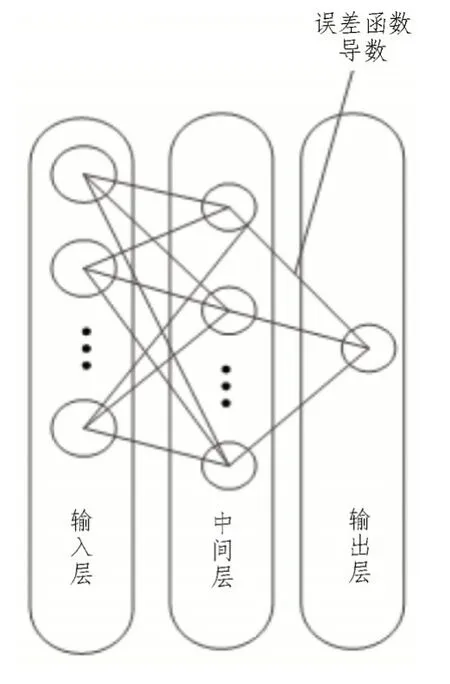
图2 基于深度学习的前馈神经网络结构
由图2 可知,通过该结构的训练结果能够得到一个特征矩阵,由此完成校正模型输入部分的构建。
2)校正模型输出部分的构建
将拼音语句文本数据集xp作为输入样本集,经过编码处理步骤获取汉字词典[14]。利用该词典对语句文本样本集xc进行编码处理,并将处理后的结果进行词嵌入训练,得到有位置编码的标签嵌入矩阵[15]。在该部分需要使用两个注意力模型,将这两个模型堆叠后输入到前馈神经网络中,并将该网络的输出作为sottmax函数的输入值,由此得到一个概率。选择概率最大的为预测结果,通过与词典对比,能够得到相应的文字,完成校正模型输出部分的构建;
步骤3:对所选语句的样本进行编码,得到所需的样本;通过对输入的样本采用字嵌入的方法获得标记的嵌入矩阵;输入的是一个输入的样本集,而输出的是一个嵌入的矩阵;通过训练步骤2 得到的修正模型,得到一个已修正的模型[16]。
步骤4:采用了基于输入模型的数据处理方式,对待纠正的语音进行了矢量化,并将其输入到经过训练的修正模型中,得到了相应的修正文本,由此获取智能机器人语音自动校准结果。
3 实 验
为了验证基于深度学习的智能机器人语音自动校准系统设计合理性,进行了如下实验。
3.1 实验环境设置
通过语音识别技术,实现了多源音频的匹配,实验环境设置为:
1)配置PXI-6713 语音播放通道,系统以15 MHz以下的频率自动采集音频;
2)采用VPP 标准设备,对语音进行识别,在整个校准过程中,语音识别精度不小于5 位;
3)由于语音信号的输入频段很宽,所以在语音采集时,必须采用五个信道进行同步和异步输入;
4)在低功率工作方式下,A/D 转换率在150 kHz以上,总线传送的解析度必须达到10 位[17-19]。
3.2 实验平台设置
实验平台设计如图3 所示。

图3 实验平台
由图3 可知,这项任务是操控一个微型的智能机器人,它能通过接收语音到处走动。智能机器人利用ARM 微控制器与话筒同步进行语音采集与识别,并依据识别结果对其进行控制。
对智能机器人下达的语音指令是:1)后退1.5 m,将垃圾扔进垃圾箱内;2)向前行驶2 m,清扫桌子底下的灰尘。获取语音指令后,对音频数据进行参数化整理,如图4 所示。
由图4 可知,语音指令下达后出现的振幅有可能是噪声,但不对整个音频产生影响。
3.3 实验结果与分析
分别使用基于深度前编码卷积网络的校准系统、多尺度前向注意力模型的校准系统和基于深度学习的智能机器人语音自动校准系统进行对比分析,两种指令下音频显示结果如图5-6 所示。

图5 指令1下音频显示结果
由图5 可知,使用基于深度前编码卷积网络的校准系统与图4(a)振幅波动情况不一致,其波动范围为12~18 dB;使用多尺度前向注意力模型的校准系统与图4(a)振幅波动情况不一致,其波动范围为5~25 dB;使用基于深度学习的智能机器人语音自动校准系统与图4(a)振幅波动情况一致,其波动范围为9~22 dB。
由图6 可知,使用基于深度前编码卷积网络的校准系统、多尺度前向注意力模型的校准系统与图4(b)振幅波动情况不一致,波动范围分别为11~19 dB、14~16 dB;使用基于深度学习的智能机器人语音自动校准系统与图4(b)振幅波动情况一致,其波动范围为7~21 dB。
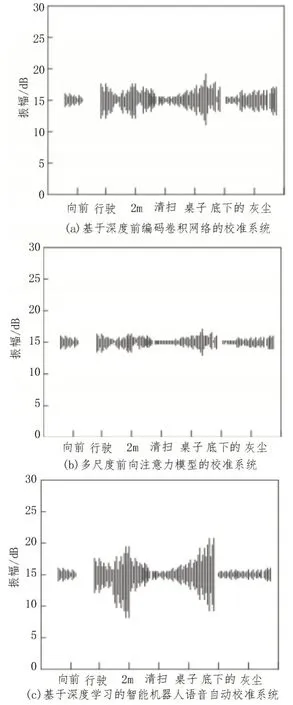
图6 指令2下音频显示结果
通过上述分析结果可知,使用基于深度学习的智能机器人语音自动校准系统能够精准校准语音。
4 结束语
该文提出的基于深度学习的智能机器人语音自动校准系统,利用深度学习法训练音频样本,解决了由于语音识别过程复杂,使用传统的校准方法难以发现发音差异性的问题。实验结果表明,该系统的设计是合理的,具有较高的可靠性。在后期,从均衡网络计算复杂性的角度考虑,改进了校准结果的准确性。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
家庭影院技术(2018年11期)2019-01-21
疯狂英语·新读写(2018年3期)2018-11-29
小说界(2018年5期)2018-11-26
电子制作(2018年19期)2018-11-14
