
中国0~5.5岁汉语母语儿童语言发育里程碑
2023-12-15 02:39吴赛双王海娃张云婷
中国循证儿科杂志 2023年5期
吴赛双 赵 瑾 王海娃 潘 昊 张云婷 江 帆
早期语言能力已被证实为儿童日后认知发育多个领域发育和学业成就的重要预测因素之一[1],语言技能不佳会对个体发展产生深远而持久的影响[2]。与西方国家发生率相似[3],中国5~6岁普通话儿童发育性语言障碍的发生率约为8.5%[4]。这意味着在每30人的班级里就有2~3名儿童存在发育性语言障碍,然而这种障碍长期被大众、甚至医学和教育领域的专业人员忽视,对儿童的早期发展造成重要影响。
语言发育的早期监测,有助于在关键时期尽早识别有语言障碍的儿童,并提供及时有效的语言干预[5]。建立语言发育里程碑是进行语言发育早期监测的必要基础,也是语言筛查和诊断工具研发的前期基础。目前,已有较多对英语儿童的语言发育里程碑的研究报道[6-8]。尽管现有研究通过专家咨询法初步构建了中国儿童发育里程碑指标体系[9],但由于不同文化和语言环境下的各种语言发育规律存在差别[10],有必要专门基于汉语的语言特点对语言发育领域进行里程碑构建。为此,本研究将基于中国不同地区大规模儿童人群研究数据,创建适用于汉语儿童的语言里程碑监测清单,以期阐明汉语儿童早期语言发展过程与规律,并为后续开展临床监测以及语言发育评估工具研发相关的研究提供理论依据。
1 方法
1.1 研究设计 横断面调查。在代表我国4个不同经济区划省份的城市和农村的社区和幼儿园(20个数据点)中抽取1~73月龄儿童家长,以自我开发的发育筛查量表(待发表)中的语言领域相关的数据,采用项目反应理论(IRT)模型对不同年龄组儿童语言发育里程碑特征进行描述性分析。数据收集与另一个开发中的儿童发育筛查工具常模研究同步进行。
1.2 伦理和知情同意 本研究经上海交通大学医学院附属上海儿童医学中心伦理委员会批准(SCMCIRB-K2021080-1),所有家长均签署知情同意书,自愿参与本研究。
1.3 抽样方法 按照地理位置和经济发展水平,依据全国4个不同经济区划[11],抽取5个省(西部四川省,东北辽宁省,中部江西省,鉴于东部人口众多选择浙江省和海南省)。各省选择省级医疗机构作为一级项目点,其儿童保健负责人作为一级项目点负责人,一级项目点主要负责二级项目点抽取,对二级项目点技术支持及进度质量进行监测。一级项目点负责人进一步选择城乡各1个社区医院(<36月龄儿童)和1个幼儿园(≥36月龄儿童)作为抽样点(共20个),20个二级项目点是具体样本数据采集点。社区医院儿童样本来源于儿童保健预防接种/体检门诊,能实现在1个月内(2022年10~11月)基于不同年龄层样本量饱和收集;幼儿园儿童样本来源于包含小班、中班、大班不同年龄段的班级。
1.4 年龄分层 根据儿童的发育里程碑进展规律[12],早期发育较快(年龄段划分密集),晚期则较慢(年龄段划分疏松),划分为13个月龄段:1~4、~<6、~<9、~<12、~<15、~<18、~<23、~<29、~<35、~<47、~<59、~<66、~<73月龄,每个年龄段计划收集100名儿童。其中,为使得60~<66月龄的里程碑结果更加准确,纳入了在60月龄问卷所对应的实际月龄之后的1个月龄段的数据(即66.0~<73.0月龄的儿童),以消除“边界效应”,确保60月龄段的条目参数能被更稳定地估计。
1.5 样本量考虑 参考WHO开发的全球儿童早期发展量表(GSED)常模[13]建立研究的样本量估算以及大量模拟研究[14,15],对于条目数量在200左右的量表构建,1 000个样本量即能使得IRT模型对条目参数的估计具有足够的准确性。
1.6 纳入标准 ①于社区医院儿童保健预防接种/体检门诊就诊的1~36月龄儿童的主要照养人,②在幼儿园上学的36~73月龄儿童的主要照养人,③主要照养人具有基本中文阅读能力并能按统一的问卷指导语完成问卷的填写。
1.7 问卷调查
1.7.1 初始条目来源 基于现有的语言发育相关理论和临床实践[16],参考如下发育评估工具:格里菲斯神经发育评估量表(GDS-C)[17]、幼儿健康调查问卷(SWYC)[18]、人类早期发展指数(eHCI)[19]、 年龄与发育进程问卷(第三版)(ASQ-3)[20]、美国疾病控制和预防中心发育里程碑清单(CDC milestones checklist)[12]等,以及国内外相关文献[21-24],形成了65个0~5.5岁儿童语言发育里程碑初始条目库。
1.7.2 专家咨询和审核 专家组(2位发育行为儿科医生、1位中文语言能力评估量表开发专家、2位语言学专家)审阅主要内容如下:①该条目是否适合作为家长自汇报的语言发育里程碑;②是否适合放在相应月龄段;③修改本条目表述形式或增加其他条目的建议,对研究主题、研究计划和核心条目的其他补充和建议。专家组审阅形成了63个0~5.5岁儿童语言发育里程碑初始条目库。每个条目的回答选项包括“还不能”“有点可以”“完全可以”“不知道/拒绝回答”。
1.7.3 儿童家长的认知访谈 为确保家长能准确理解每个条目,在5个抽样省和上海市对141名儿童家长进行认知访谈,家长文化程度从初中至博士。认知访谈的内容包括逐条询问家长“请用您自己的话告诉我这个问题问的是什么,或描述一下当您听到这个问题时您想到的是孩子的什么行为?”并记录家长的回答。根据认知访谈的结果,对存在理解偏差的条目进行了逐一讨论和修订。
1.7.4 预调查、问卷条目和排序 为了给正式调查提供实证数据以支持条目排序,咨询专家组在每个年龄段选择基本符合其月龄特征的20个条目,在5个抽样省和上海市开展问卷预调查,6个省市选取了3 355名儿童家长进行填写。通过计算预调查中儿童通过每一个条目的中位月龄,即有50%可能性达到“完全可以”的年龄,对正式调查中的条目进行排序。
1.7.5 问卷填写和回收 问卷均由家长在线上问卷平台填写回答,问卷填写助手(社区医生和幼儿园班主任)均接受了统一的填写导语线上培训,并被要求不对问卷条目进行额外的解释,当家长对问卷条目内容有疑问时,研究人员回答“请按照您自己的理解进行填写即可”;社区样本在社区门诊现场填写并上传,幼儿园样本由家长在家中填写后上传。
1.8 数据清洗 从线上问卷平台数据库中导出调查问卷数据并进行清洗。
1.8.1 数据剔除标准 ①通过姓名和电话号码鉴别不明原因的重复填写;②99%以上的条目填写了相同答案;③通过数据可视化和逻辑判断剔除不合理样本数据,判断标准为:<36月龄儿童家长对问卷中最后5题的任意一题回答了“完全可以”,≥36月龄儿童家长对问卷最前5题中任意一题回答了“还不能”;④早产儿。
1.8.2 问卷选题自适应 采用自适应的答题模式,在尽量减少家长填写条目数量的情况下提高数据与模型的拟合度。自适应设置逻辑:在家长连续回答10个“还不能”时,设置答题终点,并将后续条目的回答自动设置为“还不能”;在连续回答10个“完全可以”时,设置答题起点,将前序条目的回答自动设置为“完全可以”。
1.9 统计学分析 应用 IRT模型[25]对每个条目进行难度参数(α1、α2)和区分度参数(β)的估计,并估计出每个条目的25%、50%、75%通过年龄,即选择“完全可以”的概率为25%、50%、75%时的发育年龄。应用条目应答率、模型拟合优度、项目功能差异(DIF)等指标以判断每个条目是否适合作为家长汇报形式的监测里程碑。其中条目应答率反映了家长对条目的理解程度和回答的难易程度。对于模型拟合优度,使用 Hosmer-Lemeshow 检验分析每个项目的分级IRT模型与本研究数据的拟合程度[25]。模型拟合优度不佳意味着相应条目收集到的实际数据可能与IRT模型的假设不相符,严重的条目拟合不佳可能影响该条目的效度,使其无法有效区分不同能力的个体。而DIF则评估了条目能否“公平”地测量不同群体间的同一能力,本研究对不同的母亲教育程度、城乡、性别、省份进行了DIF的评估。应用Stata/MP 17.0进行数据整理、逻辑检查和基本数据分析,应用Mplus 8.3进行IRT模型构建和条目参数计算,应用R 4.1进行条目应答率、模型拟合优度、DIF指标计算。计数资料以n(%)表示。
2 结果
2.1 基本情况 基于抽样5省20个社区医院和幼儿园(城乡各半)的1 976名儿童数据,317名儿童数据被清洗,剔除重复填写数据(n=80)、早产儿(n=63)、不合理填写数据(n=174),1 659名儿童数据纳入分析。表1显示,相较于纳入分析的数据,不合理填写数据的儿童年龄更小,母亲教育程度初中及以下、高中/中专的占比较高。
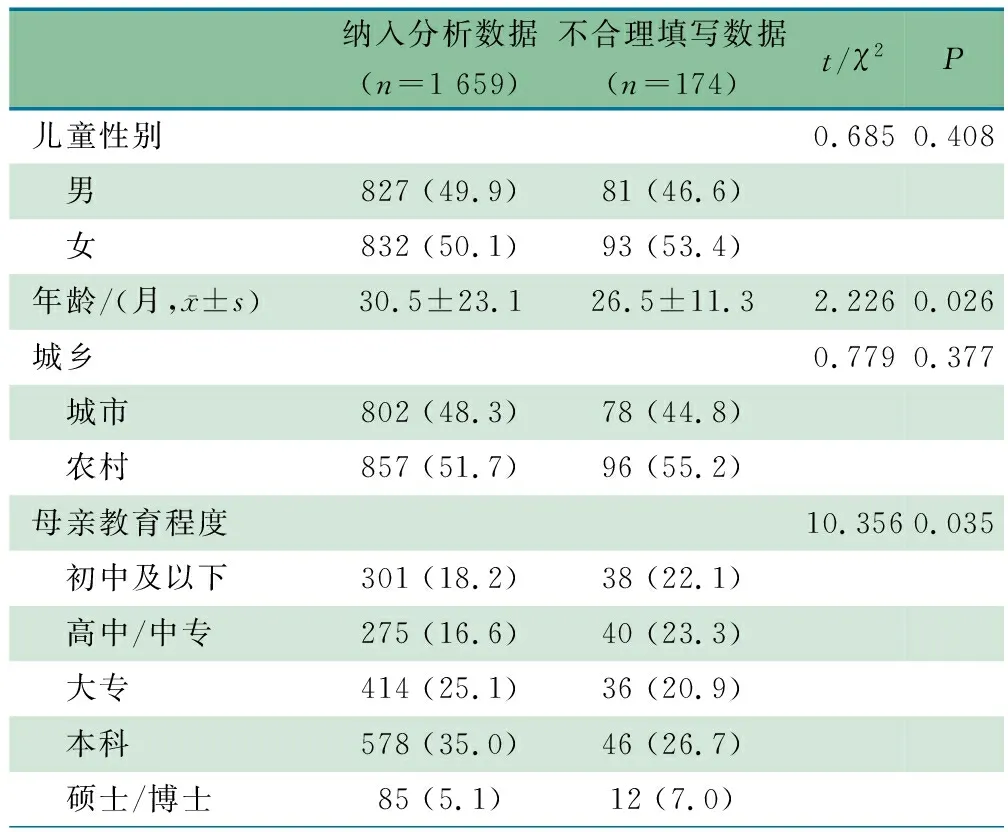
表1 纳入分析数据与不合理填写数据的特征比较[n(%)]
在最终纳入分析的1 659名儿童中,农村和城市分别为857名(51.7%)和802名(48.3%),社区和幼儿园分别为1 013名(61.1%)和646名(38.9%),来自浙江、四川、辽宁、江西和海南分别为312名(18.8%)、340名(20.5%)、382名(23.0%)、330名(19.9%)和295名(17.8%)。1 659名儿童中,男827名(49.9%)、女832名(50.1%),男女性别比0.99,平均年龄(2.5±1.9)岁,年龄范围在1.0~72.93个月。表2显示13个月龄组人口学构成。
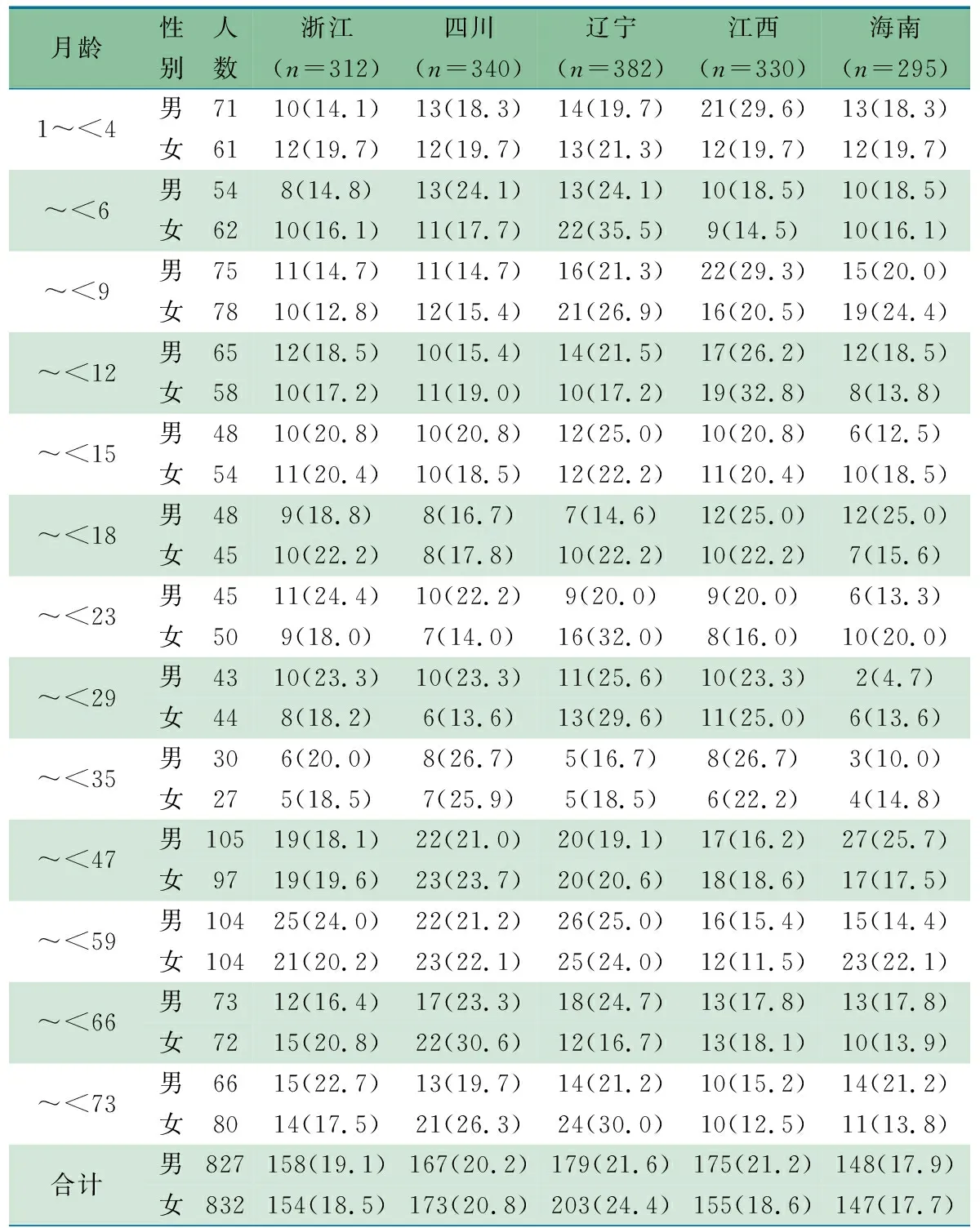
表2 5省1~6岁抽样儿童人口学构成 [n(%)]
2.2 语言发育里程碑筛选通过情况 语言发育里程碑的63个条目应答率均≥99%,即每一个条目均仅有<1%的人选择了“不知道/拒绝回答”。通过计算群体间DIF和模型拟合优度,有47个条目最终被纳入监测清单。由于模型拟合优度不佳而被剔除的14个条目的拟合图见图1。
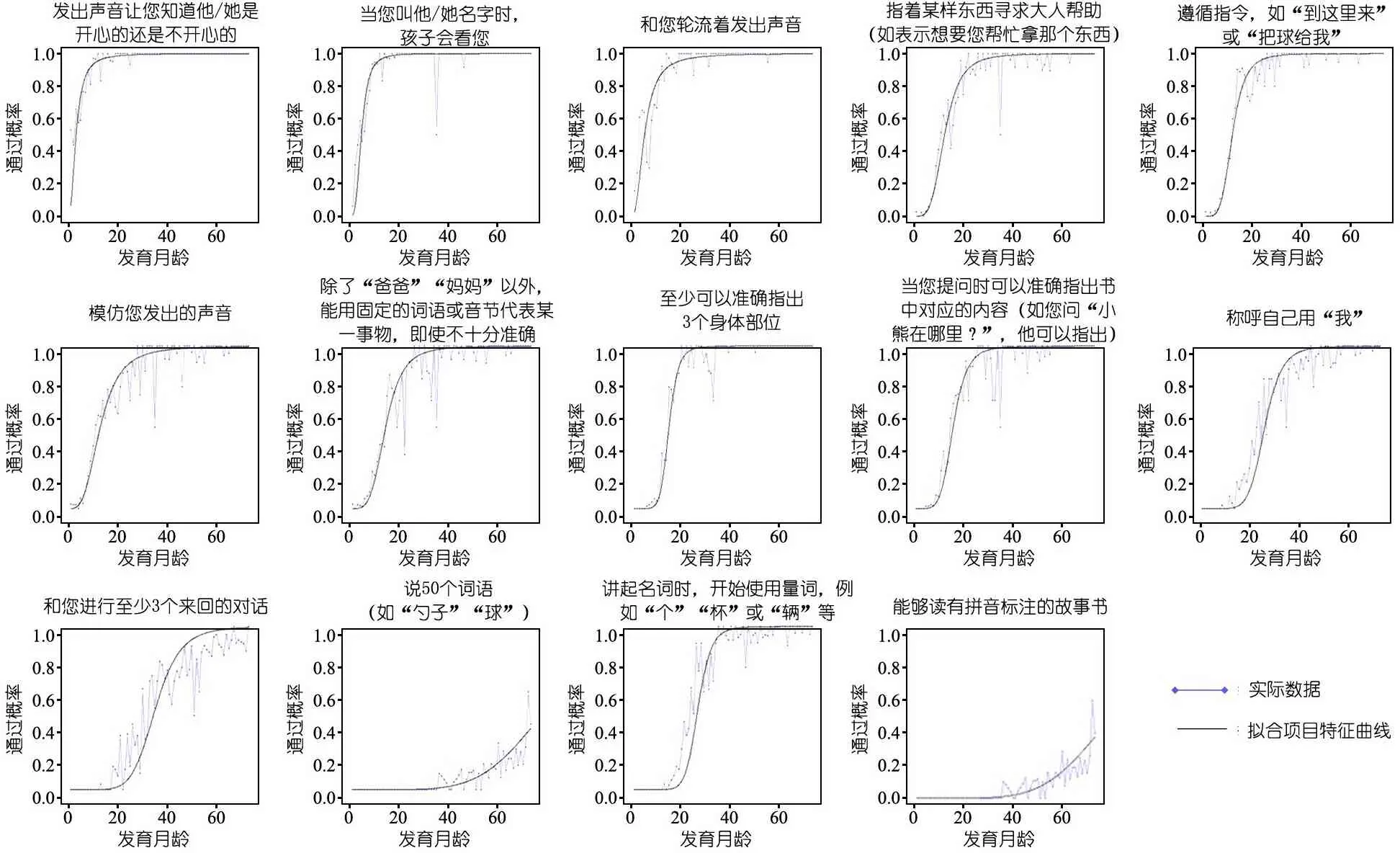
图1 模型拟合优度不佳的14个条目的拟合图
表3显示,每一个里程碑条目通过概率为25%、50%、75%时估计的发育月龄,纳入监测清单里程碑条目按照50%通过概率的发育年龄排序。按照75%通过概率的发育年龄,结合我国儿童保健体检时间点,对监测月龄范围进行推荐意见。表4显示被剔除的16个里程碑条目及其原因,其中有3个条目呈现出了母亲教育程度上的DIF,有14个条目呈现出模型拟合优度不佳。

表3 汉语儿童语言发育里程碑通过的发育月龄

表4 未纳入监测清单的汉语儿童语言发育里程碑条目及剔除原因
2.3 语言发育里程碑的中英文条目比较 不同文化发育里程碑的比较非常重要。选取与本研究具有可比性的同类型研究SWYC[18]中的21条英文语言里程碑条目进行通过年龄的比较。SWYC亦是基于IRT模型报告了每个发育里程碑在通过概率为25%、50%、75%时的估计通过年龄。表5显示,①在发音习得方面,涉及到音位的习得与组合的能力在汉语和英语儿童中的发展规律基本相近,呈现出从简单到复杂的模式。例如,英语母语的儿童在8.2月龄有75%的概率能够发出类似“ga”“ba”“ma”的声音,汉语母语儿童为9.8月龄。②在词汇习得方面,如“理解禁止命令”“遵循指令”等涉及到语言运用与交流能力的里程碑条目,其发展基本规律也较为接近。例如,“遵循指令”这一里程碑条目在本研究中通过概率为25%、50%、75%时的发育月龄分别为9.5、12.5、16.5月龄,而在美国的研究中为11.0、12.6、14.3月龄。③在句法习得方面汉语母语儿童和英语母语儿童则存在较多差异,如在英语环境中,比较级的词态变化是衡量儿童语言发育水平的重要里程碑之一,美国的儿童在31.3月龄有75%的概率能使用“bigger”“shorter”这些词来表示比较的概念。尽管汉语中不存在比较级的词态变化,但本研究纳入了一个类似的条目,即“会用‘比’或‘更’来表达比较的含义(比如‘哥哥比我高’)”,结果表明在36.5月龄有75%的儿童能掌握这一技能。④由于英语采用拉丁字母,汉语采用方块字,两类儿童在书写和阅读能力的发展规律上也存在明显差异。方块字的书写较难,需要长期的记忆和练习。例如“能写自己的名字”这一条目,汉语母语儿童75%通过概率在69.7月龄,明显落后于英语母语儿童的75%通过概率在57.1月龄。
3 讨论
为了解汉语儿童语言发育规律并进一步构建临床语言里程碑,本研究在全国5省收集并分析了1 659名0~6岁儿童家长报告的语言里程碑横断面数据,通过构建IRT模型,建立了汉语儿童发育里程碑的监测条目清单并提供了每个条目的估计通过年龄。
3.1 汉语儿童语言发育里程碑通过年龄分析 经过与人民卫生出版社《儿童保健学》第4版[26]和《实用儿童保健学》第2版[27]的详细对比,本研究中通过概率为75%时估计的发育年龄与现有教科书中的阐述基本一致。例如,“3~4 月龄时有反复的咿呀作声”这一阐述与本研究中3.7月龄有75%的儿童能发出类似于“喔喔喔”“啊啊啊”的声音这一里程碑相符;12月龄时会用姿势表示意思,如“挥手表示再见、用小手指点图片”这一描述与本研究中12.4月龄有75%的儿童能达到“挥手表示‘再见’”这一里程碑相符。因此,本研究提供的发育里程碑实证数据,进一步提供了现有专业领域儿童语言发育关键年龄界定的理论依据。
3.2 语言发育规律的跨文化比较 语言发育规律的跨文化、跨语种比较研究对于理解儿童语言习得机制有重要意义[28]。本研究在构建语言发育里程碑基础上更进一步对英语和汉语母语儿童的语言发育规律进行了比较。研究发现,儿童在语音发展和词汇习得方面其发育进程具有相似性。本研究团队前期有研究表明,上海儿童的词汇量发展规律与美国儿童基本类似[22],许多研究也证实词汇爆发期的发生时间在不同语种环境下基本相近[29,30]。本研究进一步丰富了关于汉语母语儿童词汇量增加、词汇类型习得顺序、词汇组合等相关规律的实证数据。同时也发现,不同语种语言发育里程碑的差异主要体现在句法相关的条目中。相比现有国内研究,大多采用英语发育里程碑并进行翻译后应用[23]。本研究将大量汉语特有的语法,如量词、“把”字句和“被”字句等纳入考察范围,扩展了目前对于汉语发展规律的认识。
3.3 本研究的方法学优势 不同于既往研究直接运用原始数据呈现结果,本研究构建了IRT模型用于估计里程碑到达年龄[25],比直接运用原始数据具有更强的预测能力与信息提供能力。①IRT模型能很好地解决大规模人群研究中普遍存在的数据缺失问题。基于家长报告的类似研究数据出现缺失是较为普遍的现象,如用原始数据分析会导致某些里程碑的精确通过时间无法计算,而基于IRT模型则可以对原始数据中未采集到的年龄段通过概率进行估算。②不同儿童之间的个体发育差异很难直接使用原始数据计算的通过概率校准,而IRT模型能够基于群体儿童的发育进程数据,估计每个发育里程碑在相应月龄段中的难易程度和区分度,更加准确地估计每个月龄段的通过概率。③本研究采用了条目应答率、模型拟合优度、DIF等指标用于筛选发育里程碑条目。作为家长自填问卷,确保每个条目有较高的应答率十分重要,这表示对大多数家长来说题目是易于填写的。而DIF评估了具体条目对不同特征群体进行评估的一致性。例如,本研究中“发出类似‘ga’‘ma’或‘ba’的声音(指声母+韵母的组合)”这一条目在母亲教育程度上呈现了功能差异,很有可能是因为照养人本身的受教育程度影响了其对条目的理解,导致该条目的特征在不同受教育程度的样本中呈现出差别,进而使其无法“公平”地测量不同群体间的同一能力。另外,由于发育里程碑的特征符合随着年龄增长,孩子掌握该技能的可能性逐渐增加的规律,IRT模型假定每个条目均可由一条以儿童发育年龄为横轴、条目通过概率为纵轴的“S”形特征曲线描绘。但若某条目的实际数据与此假设差异较大,则会表现为条目模型拟合优度不佳。但需要注意的是,表现出较差的模型拟合优度并不一定意味着这些指标不是重要的发育里程碑,很有可能是因为这些条目不适用于父母报告的形式。
3.4 语言里程碑监测清单的临床应用 临床工作中,发育里程碑(如“12月龄会使用1个字”“18~24月龄表达短语”“3岁开始出现复杂句”等)为医生提供了语言发育规律的参照,医生往往根据自己对里程碑的理解及经验询问家长相关发育问题,并且不同教育水平的家长在理解和回答问题时可能出现差异。针对这一问题,本研究基于大规模儿童语言发育数据全面分析,为临床医生列出了每个月龄段详细且可以观察到的语言里程碑监测清单。同时,所有条目均被证实对于不同教育水平的家长可以理解,该清单也为临床工作中医生询问家长儿童语言发育状况提供了范本。最为重要的是,临床医生可以根据家长对于该清单的回答初步判断儿童的语言发育状况,以进一步指导诊疗。本研究详细列出了每个监测条目25%、50%及75%通过概率的月龄段,既往研究推荐该月龄段75%通过概率的能力作为发育里程碑的预警条目[8]。也就是说,如果儿童未达到该月龄段75%的儿童都能达到的能力,提示儿童可能存在该能区的发育问题,建议进一步用标准化语言发育问题筛查工具进行评估。
本研究通过较大的样本量和严谨的建模过程,初步揭示了汉语儿童语言发育规律,并建立了中国儿童语言里程碑的监测清单。结果提示,汉语儿童语言发育规律总体上与英语母语儿童的发育规律相似,但由于语言本身特征的差异,在清单条目的选择上存在较大差异,尤其是句法相关的条目。相关研究结果为汉语儿童语言发育规律提供新的证据,不仅可以作为儿科及儿童保健医生在临床场景中初步评估儿童语言发育水平的借鉴,也可以作为家长自我监测儿童语言发育的参考。同时,本研究结果还可以为进一步研发汉语语言发育评估工具提供重要的参考,并为探索语言发育脑机制的神经科学研究提供发展尺度上的行为学依据。
致谢:感谢各数据收集点工作人员在本研究中的辛勤付出。浙江省(慈溪市第三人民医院医疗健康集团、慈溪市周巷中心幼儿园、杭州市拱墅区小河湖墅街道社区卫生服务中心、杭州市华媒维翰幼儿园)、江西省赣州市(于都县第二人民医院、于都县银坑镇中心幼儿园、于都县妇幼保健院、于都县科技幼儿园)、海南省三亚市(崖州区崖城卫生院、崖州区崖城中心幼儿园、妇女儿童医院计免门诊、第一幼儿园)、四川省成都市(大邑县芙蓉社区卫生服务中心、大邑县东街幼儿园、华阳社区卫生服务中心、天府新区第一幼儿园)、辽宁省大连市(普兰店区铁西街道防保站、普兰店区爱儿坊天都城幼儿学苑、高新园区七贤岭社区卫生服务中心、点石万达华府幼儿园)。
特别感谢各省的数据收集负责人对本研究的大力支持:浙江省邵洁、郑双双,江西省徐萍、陈绍红,海南省孙韬,四川省章岚以及辽宁省孙瑾、曾敏慧。同时,感谢香港理工大学盛欐、上海交通大学附属上海儿童医学中心章依文、华东师范大学周兢对条目和研究设计的仔细审阅并提出宝贵意见。
最后,由衷感谢所有参与研究的家长和儿童,使得我们能够获取宝贵的数据,为中国儿童语言发展研究做出贡献。
猜你喜欢
科学生活(2019年7期)2020-01-01
养殖与饲料(2019年10期)2019-02-25
神州·下旬刊(2019年1期)2019-02-11
新闻传播(2018年6期)2018-12-06
山东畜牧兽医(2018年3期)2018-04-26
中国神经再生研究(英文版)(2017年10期)2017-11-08
中国卫生(2016年12期)2016-11-23
科学24小时(2016年5期)2016-05-10
听力学及言语疾病杂志(2015年5期)2015-12-24
教育与职业(2014年19期)2014-01-21
