
基于邻居交互增强和多头注意力机制的跨域推荐模型
2023-12-14 00:46孙克雷汪盈盈
湖北民族大学学报(自然科学版) 2023年4期
孙克雷,汪盈盈
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
推荐系统(recommender systems,RS)在当前信息爆炸的时代扮演着关键角色,能帮助用户从海量信息中快速发现符合个人兴趣的内容[1-2]。协同过滤(collaborative filtering,CF)作为RS中的经典方法,依赖于用户-项目交互数据,通过学习用户和项目的表示来进行推荐[3]。然而,这种基于CF的方法面临着一个长期存在的挑战,即用户冷启动问题[4]。当涉及新用户时,由于缺乏足够的观察交互数据,导致推荐系统无法准确学习到其个性化的兴趣和喜好。
作为一种十分有效的用户冷启动问题解决方案,跨域推荐(cross-domain recommendation,CDR)旨在通过利用从其他相关源域收集的用户-项目交互信息来提高目标域的推荐准确度[5-6]。大多数跨域推荐的方法假设2个域中存在一定数量的重叠用户来搭建源域和目标域之间的桥梁[7]。只有在源域中有交互的用户(即非重叠用户)才可以被视为目标域的冷启动用户。Man等[8]提出了跨域推荐的嵌入和映射方法(cross-domain recommendation:an embedding and mapping approach,EMCDR),首先分别利用矩阵分解(matrix factorization,MF)和贝叶斯个性化排名来生成用户和项目表示,然后假设源域和目标域中用户之间的偏好关系对所有用户都是共享的,并学习1个公共的映射函数。基于EMCDR模型的思路,Zhu等[9]提出了一种面向跨域和跨系统的深度推荐框架,学习的映射函数是由目标域到标准域的映射,标准域即通过矩阵稀疏度将源域和目标域融合到一起的特征空间。考虑到现实场景中重叠用户往往较少的问题,Kang等[10]提出了基于半监督学习的模型,使用源域的项目数据和重叠用户数据一起训练映射函数。但该映射函数偏向于有限的重叠用户,这降低了模型的泛化能力。然而,由于用户复杂的个体特征,对所有用户使用公共映射函数可能会降低CDR的性能。为了克服这一缺点,Zhu等[11]提出了用户偏好个性化迁移跨域推荐模型(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR),从用户的历史交互信息中提取用户的个体特征,并利用元学习技术为每个用户学习1个偏好迁移函数,该模型能充分考虑到每个用户的个性化特征。Di等[12]扩展了PTUPCDR模型,将联邦学习方法与个性化跨域迁移方法相结合,有效缓解了用户隐私泄露问题。但这些模型的有效性严重依赖于用户-项目的交互数量,在用户冷启动场景中交互数量通常是非常稀缺的。因此,当源域知识相对不足时,如何捕获丰富的用户偏好知识对于解决冷启动问题就显得尤为重要。
在上述的基于个性化映射的跨域推荐模型中,未充分关注源域中交互稀疏的用户,可能会降低用户偏好的迁移效率。此外,这些模型无法有效地从用户复杂的交互中提取可迁移的偏好。因此,提出一种基于邻居交互增强和多头注意力机制的跨域推荐(neighbor interaction enhancement and multi-head attention mechanism based cross-domain recommendation,NMACDR)模型。首先通过利用邻居的交互项目增强源域中用户的短序列,从而能够全面地捕获用户的偏好。然后利用多头注意力机制从交互序列中提取用户可迁移的偏好特征,并将提取的用户偏好特征输入元网络构建个性化映射函数。NMACDR模型有效地提高了用户偏好的迁移效率,避免了负迁移问题。
1 问题定义

2 模型设计
NMACDR模型结构如图1所示。由图1可知,该模型包含3个主要组件:邻居交互增强模块、用户特征编码器模块和个性化特征迁移模块。1) 邻居交互增强模块:利用矩阵分解模型学习源域和目标域中用户和项目的嵌入。在源域用户嵌入层,利用局部敏感哈希(locality-sensetive hashing,LSH)算法检索到具有相似兴趣的前k个邻居用户,然后将邻居用户的交互项目整合到查询用户的交互列表中,从而增强了源域用户的交互序列。2) 用户特征编码器模块:采用多头注意力机制从增强后的交互序列中提取用户的可迁移偏好。多头注意力机制允许模型全面地捕捉用户兴趣的多个方面,使得用户特征更丰富和更有表现力。3) 个性化特征迁移模块:利用上一阶段提取的用户可迁移特征作为元网络的输入,生成个性化映射函数,并将用户在源域的嵌入通过个性化映射函数桥接到目标域,以进行项目预测。
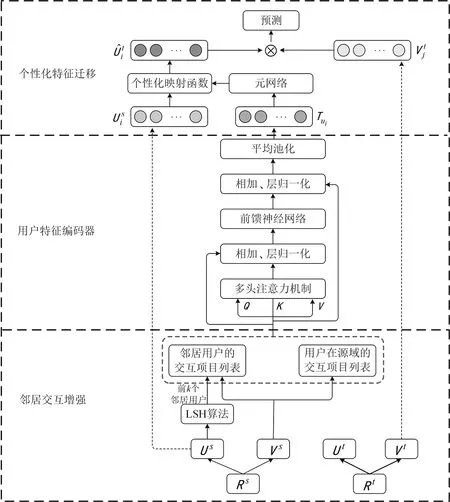
图1 NMACDR模型整体结构Fig.1 The overall structure of the NMACDR model
2.1 邻居交互增强
通过源域的矩阵分解模型,可以获得用户和项目的嵌入表示。用户向量之间的相似性反映了它们在统计上的共现关系。换句话说,如果2个用户在对项目的偏好上有高度的重叠,训练过程将导致这些用户的嵌入向量高度相似。因此,可以在用户嵌入层利用最近邻检索算法找到具有相似偏好的邻居用户。具体而言,最近邻检索算法采用了LSH技术,它将高维空间中的向量映射到低维空间,并使用哈希函数进行快速的近似最近邻搜索。
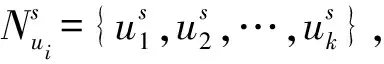

图2 邻居项目填充过程Fig.2 Neighbor item supplementing process
1) 通过式(1)将前k个邻居用户的交互项目串联形成推荐列表。
Su1…k=Fconcat(Su1,Su2…Suk),
(1)
式(1)中,Su1…k为推荐列表,Suk为用户uk的交互项目列表,Fconcat为串联操作。
2) 对推荐列表进行一系列的筛选和排序操作:① 删除查询用户已经交互过的项目,以避免重复推荐;② 统计推荐列表中每个项目的出现次数,并按照出现次数进行排序,以便更好地捕捉热门和受欢迎的项目;③ 从排序后的列表中截取k个连续的项目作为最终的推荐项目列表SNi。
3) 将最终的推荐项目列表与查询用户的交互列表串联,如式(2)所示:
(2)
式(2)中,Z∈Rd×m为增强交互矩阵,其中d表示项目嵌入向量的维度;Sui为用户ui的交互项目列表,SNi为最终的推荐项目列表;zj表示第j列,也称为第j个项目的嵌入向量。随后,可以利用每个重叠用户的增强交互矩阵Z作为偏好特征来指导个性化映射函数的构建。
2.2 用户特征编码器
考虑到不同交互项目对用户可迁移偏好的重要性差异,采用多头注意力机制网络结构来捕捉用户可迁移偏好。多头注意力机制可以实现对用户交互列表中不同维度信息的全面挖掘,通过对不同注意力头的特征进行融合,模型可以更全面地关注用户与邻居之间交互项目在多个维度上的关系,从而提高对用户可迁移偏好的建模能力。
多头注意力机制网络[13]是由h个并行计算的注意力模块组成的。给定用户增强交互矩阵Z,通过转换生成其查询矩阵Q、键矩阵K和值矩阵V,并且随机初始化权重矩阵Wq、Wk和Wv,具体转换如下:
Q=WqZ,K=WkZ,V=WvZ。
(3)
通过使用点积运算对查询矩阵Q和键矩阵K进行相似度计算,挖掘出特征之间的相互联系,捕获内部依赖关系,如式(4)所示:
(4)
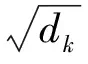
在多头注意力机制网络中,不同的注意力头执行单独的计算,并将每个注意力头得到的矩阵拼接起来,再乘以权重矩阵Wo,得到最终多头注意力表示M,具体可以描述为
(5)
M=Fconcat(H1,H2,…,Hh)Wo,
(6)

将多头注意力表示与输入的用户增强交互矩阵进行残差连接,并进行层归一化,有助于信息的传递和梯度的稳定性,其公式为
Y=FLN(M+Z),
(7)
式(7)中,Y为层归一化的结果,层归一化操作FLN使用LayerNorm实现。在经过残差连接和层归一化之后,将得到的隐藏表示作为输入,通过前馈神经网络进行非线性变换。前馈神经网络由2个全连接层和1个激活函数组成,其公式为
Ffnn(Y)=φ(YW1+b1)W2+b2,
(8)
式(8)中,Ffnn(·)为前馈神经网络,φ为ReLU激活函数,W1和b1为第1个全连接层的权重矩阵和偏置,而W2和b2为第2个全连接层的权重矩阵和偏置,均为可训练参数。再次将前馈神经网络的输出与用户增强交互矩阵进行残差连接,并进行层归一化。这个过程与第1步的残差连接和层归一化相似,具体可以描述为
Y′=FLN(Ffnn(Y)+Z)。
(9)
最后将得到序列矩阵Y′平均池化,获得用户的可迁移偏好表示向量,其计算公式为
T=FMP(Y′),
(10)
式(10)中,T为用户的可迁移偏好表示向量,FMP为平均池化操作。
2.3 个性化特征迁移
跨域推荐方法的核心是将源域的知识迁移到目标域中,一种有效的实现方式是训练映射函数。在理想情况下,这种映射应该是个性化的。由于每个用户的偏好不同,所以映射函数的参数也应该因用户而异。模型的用户个性化特征迁移过程如图3所示。由图3可知,采用基于参数生成的元网络技术,将用户的可迁移

图3 用户个性化特征迁移过程Fig.3 User personalized feature transfer process
偏好特征作为输入,在源域和目标域的用户嵌入之间生成个性化的映射函数。元网络的公式定义如下:
wui=g(Tui;ε),
(11)
式(11)中,wui为元网络的输出,Tui为用户ui的可迁移偏好特征,g(·)是元网络,ε是元网络的参数。使用2层前馈神经网络来表示元网络,并通过以下公式定义个性化偏好函数:
fui(·;wui),
(12)
式(12)中,fui(·)是个性化映射函数,同样采用了2层前馈神经网络的结构。为了适应个性化映射函数参数的大小,将向量wui∈Rk2重塑为矩阵wui∈Rk×k。映射函数的参数wui根据用户偏好而变化,从而实现用户嵌入的个性化映射。
给定目标域上的冷启动用户,其在源域上的嵌入通过个性化映射函数桥接到目标域,公式定义如下:
(13)
在个性化特征迁移之后,将转换后的用户嵌入和目标域的项目嵌入进行内积计算,可以生成冷启动用户的预测,计算公式如下:
(14)
3 实验及分析
3.1 实验设置
3.1.1 数据集 实验采用了亚马逊数据集[11]和豆瓣数据集[14]。亚马逊数据集是1个包含了数百万个商品信息的综合数据集,涵盖了多个领域。实验从中挑选出4个领域,分别为视频、玩具、运动和服装。根据所选领域定义2个跨域场景,分别为场景1(视频→玩具)和场景2(运动→服装)。豆瓣数据集是从豆瓣网站获取的数据集,它包含了丰富的电影、图书和音乐信息。根据这3个领域定义2个跨域场景,分别为场景3(电影→图书)和场景4(电影→音乐),详细数据集统计信息如表1所示。由表1可知,2个数据集都表现出较高的数据稀疏度,而在场景1和场景2中,这一问题相较于场景3和场景4则更加显著。
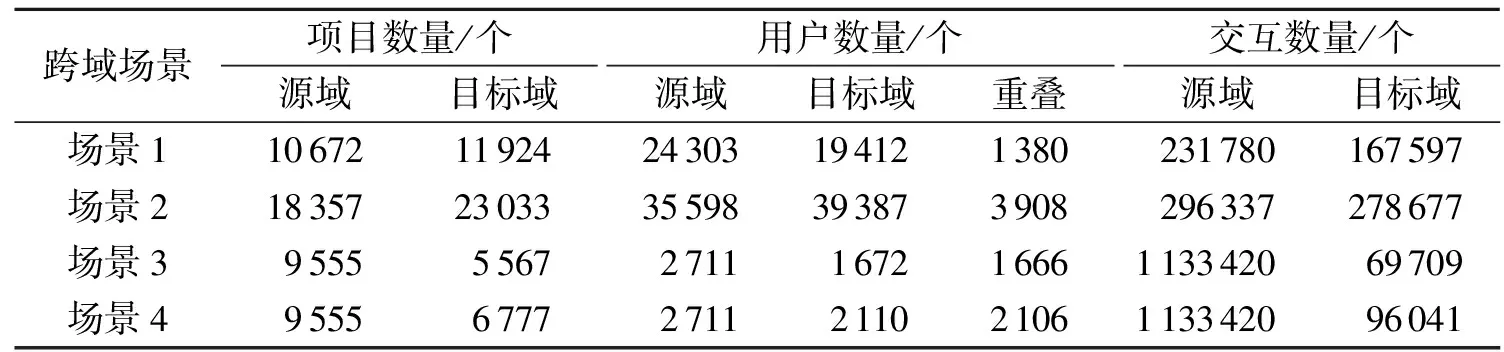
表1 数据集统计信息Tab.1 Statistics of dataset
3.1.2 评价指标 与现有研究[15-16]保持一致,实验采用平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error,RMSE)2个评价指标,公式定义如下:
(15)
(16)
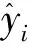
3.1.3 基线模型 NMACDR模型与以下4个经典的跨域推荐模型进行性能的比较。1) 基本矩阵分解(basic matrix factorization,BasicMF)模型:直接使用目标域的数据进行矩阵分解操作。2) 集体矩阵分解(collective matrix factorization,CMF)模型[17]:该模型将2个域的评分矩阵集体分解为用户表示和项目表示,并约束用户表示在不同领域之间共享。3) EMCDR模型[8]:该模型首先应用MF分别生成源域和目标域的用户和项目表示,然后基于多层感知机学习映射函数,将源域的用户表示映射到目标域。4)PTUPCDR模型[11]:该模型利用元网络构建个性化偏好桥,从而实现用户偏好的个性化迁移,是目前最先进的基于映射的跨域推荐模型。
3.2 对比实验
所提出的NMACDR模型和其他基线模型的性能对比结果如表2所示。由表2可知,NMACDR模型在所有的跨域场景中均优于基线模型。

表2 NMACDR与其他模型的性能对比Tab.2 Performance comparison of NMACDR with other models
通过进一步分析,可得出以下结论:1) BasicMF模型是单域推荐模型,仅使用目标域的数据进行训练,而其他基线模型则是跨域推荐模型,可以利用源域的数据。显然,BasicMF模型在所有评估中表现最差。在数据稀疏的情况下,仅使用单个域的数据为冷启动用户推荐项目是不够的。因此,利用来自源域的信息可以缓解数据稀疏和冷启动问题。2) NMACDR模型优于基于公共映射函数的CMF和EMCDR模型,表明个性化迁移策略在用户偏好的迁移中是有效的。3) PTUPCDR模型最接近所提出的NMACDR模型。然而,NMACDR模型在MAE和RMSE指标上都优于PTUPCDR模型。具体而言,在场景1中,MAE指标提高了2.86%,RMSE指标提高了2.90%;在场景3中,性能提升最为显著,MAE指标提高了6.54%,RMSE指标提高了3.73%;在场景2和场景4中,也呈现出显著的提高。这是因为PTUPCDR模型没有关注源域中数据稀疏的用户,无法从用户的交互历史记录中更全面地捕获用户偏好,从而导致迁移效果较差。所提出的邻居交互增强模块和用户特征编码器模块可以有效弥补这一不足。
3.3 消融实验
在4个跨域场景上对模型进行消融实验,验证所提出的邻居交互增强模块和用户特征编码器模块的有效性。实验结果如图4和图5所示,其中w/o NIE(without neighbor interaction enhancement)表示移除所提出的邻居交互增强模块,即不考虑邻居用户的交互项目;w/o MHA(without multi-head attention)表示移除所提出的用户特征编码器模块。由图4和图5可知,NMACDR在每个跨域场景下都比w/o MHA取得更好的推荐结果,这表明所提出的用户特征编码器模块在提取用户可转移偏好特征方面的重要性。此外,NMACDR的性能在每个跨域场景下都优于w/o NIE,这表明增强邻居交互行为的有效性。从这个结果来看,在NMACDR模型中添加邻居交互增强模块有助于捕获更多用户偏好,从而提高大多数跨域场景下的推荐准确性。总体而言,这些实验结果证明了所提出的2个组件对用户偏好迁移的积极影响及其在增强目标域性能方面的有效性。

(a) MAE评价指标下的模型效果 (b) RMSE评价指标下的模型效果图4 亚马逊数据集上消融实验结果Fig.4 The results of the ablation experiment on the Amazon dataset
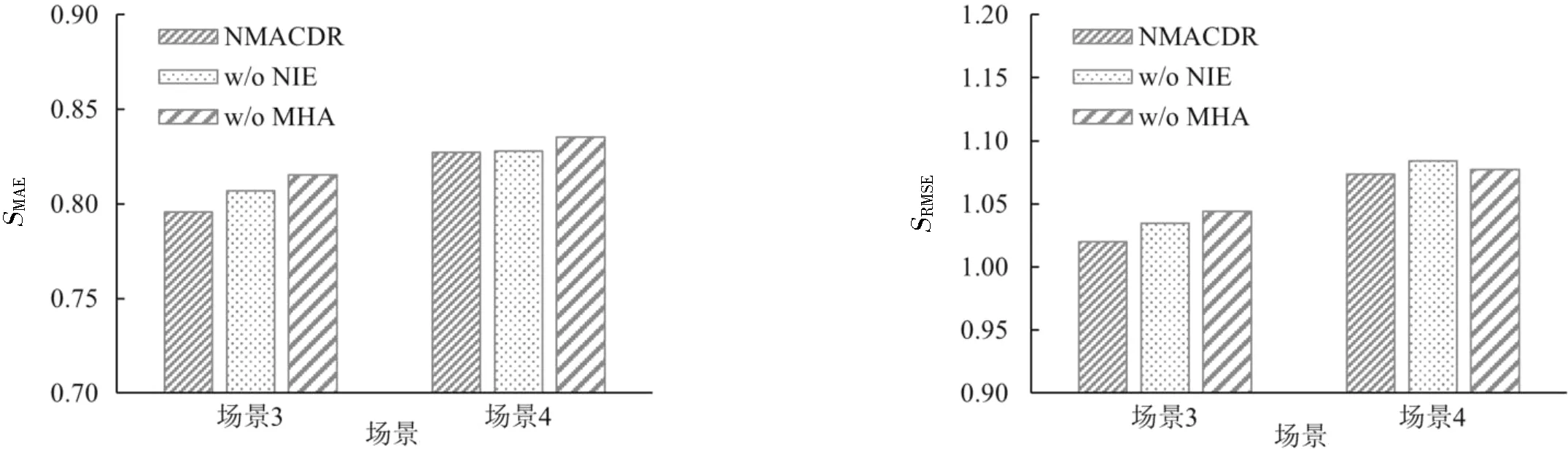
(a) MAE评价指标下的模型效果 (b) RMSE评价指标下的模型效果图5 豆瓣数据集上消融实验结果Fig.5 The results of the ablation experiment on the Douban dataset
3.4 超参数敏感性分析
邻居交互增强模块可以解决源域数据稀疏性的问题。为了探究用户序列增强的长度对模型推荐准确性的影响,实验测试了模型在不同序列长度下的推荐性能。由于亚马逊数据集和豆瓣数据集具有不同的数据分布,因此在亚马逊数据集中,跨域场景的序列长度被设置为10、20、30、40、50、60、70个;而在豆瓣数据集中,跨域场景的序列长度则被设置为20、40、60、80、100个。总体的实验结果如图6和图7所示。实验结果表明,m的最优值因跨域场景而异,这归因于不同跨域场景的数据分布差异。由图6可知,对于场景1,当序列长度为30个时,MAE达到最小值,NMACDR取得最佳推荐性能;当序列长度为60个时,RMSE达到最小值,NMACDR取得最好的结果。对于场景2,当序列长度为20个时,MAE和RMSE达到最小值,NMACDR取得最好的结果。由图7可知,对于场景3和场景4,当序列长度为60个时,MAE和RMSE达到最小值,NMACDR取得最佳推荐性能。然而,当序列长度大于60个时,NMACDR的推荐准确性逐渐下降,可能是因为邻居交互信息过度补充导致噪声的引入。总体而言,不同超参数设置对模型性能的影响相对较小,表明NMACDR模型对超参数设置具有鲁棒性。

(a) MAE评价指标下的模型效果 (b) RMSE评价指标下的模型效果图6 亚马逊数据集上序列长度对模型性能的影响Fig.6 The effect of sequence length on model performance on the Amazon dataset

(a) MAE评价指标下的模型效果 (b) RMSE评价指标下的模型效果图7 豆瓣数据集上序列长度对模型性能的影响Fig.7 The effect of sequence length on model performance on the Douban dataset
4 结论
提出了一种基于邻居交互增强和多头注意力机制的跨域推荐模型NMACDR,该模型可以更全面地捕获用户的可迁移偏好,并提高目标域的推荐准确性。与以往仅利用用户历史交互信息来学习个性化映射函数的模型不同,NMACDR能够探索邻居用户的交互信息,还能利用多头注意力机制和元网络构建个性化桥梁,从而可以跨域迁移每个用户的个性化偏好特征。实验结果表明,NMACDR在4个跨域场景上相较于最优的基线模型,MAE指标最高提升了6.54%,RMSE指标最高提升了3.73%,可以为冷启动用户提供更准确以及个性化的推荐服务。在现实跨域场景中,2个领域中的重叠用户数量有限。今后会将模型扩展到更为复杂的跨域场景,涉及2个领域中不重叠的用户。
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
科学家(2021年24期)2021-04-25
计算机技术与发展(2020年11期)2020-12-04
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
电子与信息学报(2015年12期)2015-08-17
中国卫生(2015年1期)2015-01-22
