
节能调度下短期预估分布式光伏发电功率模型研究
2023-12-14 13:10:48张振臣刘国军
自动化仪表 2023年11期
李 丽,张振臣,刘国军
(国网冀北电力有限公司滦南县供电分公司,河北 唐山 063500)
0 引言
当前,我国电力供应仍以煤炭发电为主,不利于节能环保。因此,国务院办公厅发布的《节能发电调度办法》提出节能发电调度理念,建议以清洁能源为主,保障电力供应的环保性和稳定性。电网公司应用太阳辐射能发电技术,建立分布式光伏发电站。虽然分布式光伏发电站的装机容量有了很大的提升,但是对光能的利用效率始终不理想。光伏发电具有一定的不确定性和随机性,难以得到某一时刻的具体发电量。长此以往,无法保证发电与功率之间的平衡,进而影响电力系统的正常运转。为了保证电网的正常供电,对光伏发电功率进行预测十分必要。
为了对分布式光伏发电功率展开精准预测,徐潇源[1]等将自组织映射和宽度学习系统进行整合,构建了光伏发电功率超短期预测模型。该模型首先对光伏数据进行24 h不间断采集,并结合自组织映射对其进行聚类,得到具体的出力波动特征;然后利用宽度学习系统对光伏发电功率的步长展开预测,并增加节点数量,以完成预测。时珉[2]等将灰色关联分析算法与基于多层注意力机制网络的地理传感器时间序列预测(multi-level attention networks for geo-sensory time series prediction,GeoMAN)模型整合,共同实现对光伏发电功率的短期预测。该模型首先对分布式光伏电站采用灰色关联分析算法,完成各电站之间的空间相关性分析,在周围电站中选择与待预测光伏电站相关性最高的电站;然后通过GeoMAN模型实现预测光伏电站环境与气候特征的动态提取。GeoMAN模型由解码器和编码器2个部分构成。解码器用于获取待预测光伏电站的自身特征以及与周围电站之间的站间特征。编码器主要用于提取气象动态指数。解码器和编码器共同作用,得到光伏发电功率预测结果。
上述2种方法并未对采集到的各项数据进行预处理,使得最终的预测结果与实际结果之间存在较大误差。长短时记忆(long short-term memory,LSTM)网络是1种具有超强时序记忆能力的网络,近几年在光伏发电功率预测领域卓有成效。基于此,在节能发电调度理念下,本文利用LSTM,针对分布式光伏发电功率提出了1种短期预估方法。本文采用主成分分析[3](principal component analysis,PCA)法将光伏发电功率影响因素进行降维转换,以减少数据的计算开销,并进行归一化处理,从而为发电功率预估模型的运算提供简洁的数据基础。这不仅去除了冗余数据,还尽可能地保留了大部分有效信息,实现了精准预测。
1 分布式光伏发电功率和PCA
1.1 影响分布式光伏发电功率的因素
处于自然环境下的分布式光伏发电站,受多种因素的影响,随机性和波动性[4]较大。这会导致无法精准预测发电功率,进而浪费了大量的电能,不利于节能。本文对影响因素归类划分,得到2大类因素,分别为由发电设备自身原因引起的内部因素和由天气、气候等原因导致的外部因素。发电设备出厂时经过层层审核,操作和安装均按照标准规程,对发电功率的影响并不大。所以本文忽略操作和安装的影响作用,主要对外部因素展开分析,以减少数据冗余[5]。滤除外部因素中影响强度较低的因素后,则分析的气象因子主要包括总水平辐射强度、阵列辐射强度、法向辐射强度、风向、风速、垂直风速、温度、湿度。同时,一部分因素之间具有一定的耦合性,而另一部分因素则独立存在、互不影响。为避免这部分隐藏信息被忽略,本文采用PCA法进行降维处理,以挖掘更多隐藏的信息,同时尽可能保留数据中的有效信息。
1.2 PCA
PCA将分布在m维空间内的因素,通过映射作用转换到p维空间内(m>p),并保持原始数据特征不变,将因素进行拆分、重组,得到维度[6]普遍偏低的新主成分数据。PCA主要实现步骤如下。
①将元素矩阵定义为X=(x1,x2,…,xl)。该矩阵中包含l个因素和n组数据。X的原始矩阵可表示为:
(1)
②xi和xj为式(1)矩阵中的2个变量。xi和xj之间具有rij=(i,j=1,2,…,l)的相关系数。
rij可表示为:
(2)
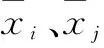
xi与xj之间的相关系数矩阵R[7]为:
(3)
③在式(3)矩阵的基础上,展开特征方程的计算,可以得到l个特征根λ1,λ2,…,λl(λ1≥λ2≥…≥λl>0)和l个单位特征向量e1,e2,…,el。
本文假设a为特征方程累计贡献率[8]阈值,则前p个阈值都被看作主成分。
λl的特征方程计算式为:
|R-λlI|=0
(4)
式中:I为特征单位向量[9]。
a的计算式为:
(5)
式中:λj为特征根。
④将原始数据序列映射到包含q个特征向量的新序列中,计算新序列的主成分,则:
(6)
式中:tj为新序列中数据的特征向量;Yij为经过降维处理后的q维数据主成分。
根据上述过程,本文提取气象因子自变量主成分。一般而言,相关系数矩阵R经过Bartlett球形检验分布后的检验值<0.05,可以认为自变量之间具有相关性,适合作PCA。对特征值进行贡献率分析后,将贡献率由大到小进行排序,取前a的主成分作为新序列的主成分。此时,经过原始序列与新序列的映射转换后,数据的单位和物理意义并不会发生改变[10]。a值的大小取决于映射前后数据序列的维数。降维处理可有效减少算法的计算开销。经过处理后,气象因子自变量之间的耦合性大大减少,同时可以保留自变量成员的特征信息,以作为功率预估模型的输入数据。
2 基于LSTM的分布式光伏发电功率短期预估
2.1 LSTM单元结构
LSTM基本单元结构如图1所示。
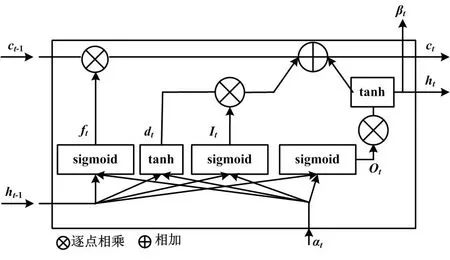
图1 LSTM基本单元结构图
图1中,ht、αt分别为短期状态[11]和长期状态;βt为最后输出;ct为当前单元状态;It、Ot和ft分别为输入门、输出门和遗忘门;dt为候选值。
LSTM的计算过程如下。
It=σ(wi,uut+wi,hht-1+bi)
(7)
式中:wi,u、wi,h为权值矩阵;ut为t时刻的输入内容;ht-1为(t-1)时刻的输出内容;σ为sigmoid激活函数。
Ot=σ(wo,uut+wo,hht-1+bo)
(8)
式中:wo,u、wo,h为权值矩阵。
ft=σ(wf,uut+wf,hht-1+bf)
(9)
式中:wf,u、wf,h为权值矩阵。
dt=tanh(wd,uut+wd,hht-1+bd)
(10)
式中:wd,u、wd,h为权值矩阵。
在t时刻将数据输入LSTM结构,则上一个单元状态ct-1会自动更新,产生当前单元状态ct。ct的更新过程可通过式(11)进行描述:
ct=ftct-1+Itdt
(11)
LSTM结构输出的βt为:
βt=ht=Ot×tanh(ct)
(12)
2.2 分布式光伏发电功率短期预估模型
2.2.1 数据预处理
在对分布式光伏发电功率进行短期预测时,受内部因素和外部因素的影响,发电功率信息会出现缺失或者损坏的情况。这将影响对发电功率的预测效果,导致供电不稳。针对此种现象,本文对原始数据进行填补和归一化处理。
缺失的发电功率信息可以是数据类型的,也可以是非数据类型的。如果为前者,即对与之对应的数据的均值进行计算,将计算结果作为缺失数据的填补。如果为后者,即参考统计学中的重数理论,找出与缺失信息相互对应的数据,并将出现频率最高的数据作为填补信息。补充完成后即对整体数据进行归一化处理。其计算如式(13)所示。
(13)
式中:ε为未处理前的发电功率;ε′为归一化处理后得到的发电功率;εmax、εmin分别为输入样本数据的最大值和最小值。
2.2.2 模型建立及参数设置
基于LSTM的分布式光伏发电功率短期预估模型为:
ε″=ε*(εmax-εmin)+εmin
(14)
式中:ε*为预估的归一化数据;ε″为模型预估结果。
基于LSTM的分布式光伏发电功率短期预估模型共有2层,其中包含了100个神经元。为了避免计算过程中出现过度拟合的情况,本文在模型中引入了参数为0.2的dropout理论和early-stopping机制。均方根误差为预估模型的损失函数,优化器选择的是adam。本文将截尾正态分布理论的偏置设为0.1,对权值进行初始化处理,取Batch size为24、学习率为0.001、Epoch为200。经过模型处理后输出的结果为发电功率短期预估结果。
3 试验测试
为了验证本文方法在实际应用中是否可以取得理想的光伏发电功率预测结果,本文方法与自组织映射和灰色关联分析算法进行了对比试验。试验数据来自某地40 kWp分布式光伏发电站。试验采集了2021年1~12月的发电功率数据。每个季度分别选取连续3天的发电功率数据,采样间隔为6 min。夜间没有光照,故光伏系统的输出功率值为0。自变量包括:预测日前一天每小时的平均输出功率;预测日前一天每小时的平均辐射强度;预测日前一天环境温度最大值、最小值、差值;预测日环境温度最大值、最小值、差值;预测日前一天风速最大值、最小值、差值;预测日风速最大值、最小值、差值。自变量共计14个输入量。试验将得到的200组监测数据作为测试数据,其余天数内的2 100组监测数据作为训练数据。在接下来的试验中,3种算法所用到的数据均为相同的数据。
3.1 评价指标
采用单一的评价指标很难对3种算法的优劣性能作出合理评价。为了保证试验对比结果的公平性,本文选取平均绝对误差M′、均方根误差R′和相关系数F作为算法预测结果的评价指标。
(15)

(16)
(17)
式中:V为相关系数参数。
M′和R′的值越小、F的值越大,则算法的预测性能越优。
3.2 测试结果及分析
3种算法在4个季节连续3天发电功率预测结果对比如图2所示。

图2 3种算法在4个季节连续3天发电功率预测结果对比
评价指标下3种算法的对比结果如表1所示。

表1 评价指标下3种算法的对比结果
由图2和表1可知,通过本文方法预测到的发电功率曲线与实际结果更接近,甚至多处出现了重合现象,而自组织映射和灰色关联分析算法预测曲线均与实际结果曲线存在较大的偏差。同时,本文方法取得的M′值和R′值在3种算法中始终最小,而F值始终最大。由此可以说明,通过本文方法对分布式光伏发电功率进行预测,可保证最小的误差,取得与实际数据最接近的结果。
4 结论
电力行业大力倡导低碳化发展,提出节能降耗的发电要求。在电网发电稳定的前提下,必须以节能环保为中心理念,对电网的发电调度作出改进。由于分布式光伏发电功率数据受天气和季节影响因素较大,存在一定的非线性特征,传统方法在对其预测时难以取得理想的预测效果。由此,本文提出了应用LSTM理论的分布式光伏发电功率的短期预估方法。该方法主要考虑了来自外部因素即气象因子的影响,利用PCA法深度挖掘气象数据的关联,降低气象因子自变量之间的耦合性。在此基础上,该方法填补和归一化处理数据,利用LSTM构建分布式光伏发电功率短期预估模型,并通过试验验证了该方法具有最高的相关系数,以及最低的均方根误差和平均绝对误差。其结果与实际发电功率接近。该方法降低了发电过程中的电能损耗,使分布式光伏发电更节能、更经济。
猜你喜欢
矿山安全信息(2022年22期)2022-11-24 09:51:46
环球时报(2022-06-15)2022-06-15 15:21:32
科学大众(2021年9期)2021-07-16 07:02:50
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
下一代英才(酷炫少年)(2017年3期)2017-06-15 13:00:06
学与玩(2017年4期)2017-02-16 07:05:40
当代化工研究(2016年2期)2016-03-20 16:21:21
雷达与对抗(2015年3期)2015-12-09 02:38:50
自动化博览(2014年12期)2014-02-28 22:34:27
