
基于改进的Flume 实时数据采集系统应用研究
2023-12-14 07:39周伟
河北软件职业技术学院学报 2023年4期
周 伟
(攀枝花学院,四川 攀枝花 617000)
0 引言
随着互联网应用的普及,为了实现个性化的推送和推荐服务,有必要利用大数据处理技术对各种应用生成的日志数据进行分析和处理,因此如何采集各应用系统生成的实时数据成了大数据技术亟待解决的问题。陈飞等结合使用Flume、Elasticsearch 以及Kibana 等技术手段提出了一种分布式的日志采集分析系统,从系统设计和架构等方面提出了新的解决思路,并针对Nginx 的访问日志进行了实时采集和分析,完成了原型系统的实现。[1]朱涛等构建了基于改进的Flume 的实时数据采集系统,采用复合型Channel 与Flume 相结合的方式,通过Flume 采集数据,在保证数据源的丰富性和可靠性的前提下,提高采集效率。[2]李洋等提出了一种整合Hadoop 和Storm 的分布式框架,构建出一种融合了实时计算与离线计算的分布式日志实时处理系统,系统架构由数据服务层、业务逻辑层和Web 展示层组成,其中数据服务层使用Flume 实时采集日志数据。[3]
通过对以上采集方案和Flume 源码进行分析,发现Flume 在进行实时数据采集时,如果日志系统生成的日志文件存在重命名,就会重复采集数据。本文将构建基于改进的Flume 实时数据采集系统,从而提高Flume 在进行实时数据采集时的准确率。
1 Flume 工作原理
Flume 是一个可以从多个不同的数据源进行日志收集、聚合和传输大量数据的分布式、高可靠性和高可用性的日志采集系统。Flume 最主要的作用就是实时读取服务器本地磁盘的数据,将数据传输到HDFS 文件系统,供大数据分析使用。
Flume 架构如图1 所示,Flume 以Agent 为最小的独立运行单位,一个Agent 主要由Source、Channel 和Sink 三大组件组成。Source 将外部数据源的数据封装成Flume 数据模型的最小单位event,并把数据存储到Channel 中,Sink 负责取出Channel 中的数据并转发到目的地。[3]

图1 Flume 架构
Source 即数据源,通过Source 组件可以让Flume 读取指定的数据,然后将数据传递给后面的Channel。Source 可以处理avro、thrift、exec、jms、spooling directory、taildir、syslog、http 等各种类型、各种格式的日志数据。
Sink 负责轮询Channel 中的事件并批量删除它们,并将这些事件批量写入到存储系统或发送到另外一个Flume Agent。Sink 组件可以将数据写入HDFS、logger、avro、file、Hbase 数据库等目的地。
Channel 是位于Source 和Sink 之间起缓冲作用的组件,允许Source 和Sink 运行在不同的速率上。Flume 自带Memory Channel 和File Channel两种Channel,最常用的是Memory Channel。
2 Flume 实时数据采集方案对比
Flume 中有Exec、Spooldir 和Taildir 三种可以监控文件或者目录的Source,实现实时数据采集。
(1)Exec Source:实现文件监控。Exec Source可以实时监控文件中的新增内容,类似于Linux 命令中的tail-F 的效果,根据文件名进行追踪,并保持重试,即使该文件被删除或改名后,如果之后再次创建相同的文件名,会继续追踪;由于tail-F 命令跟踪文件内容默认显示为最新10 行内容,通过实验发现当Flume 采集进程由于意外停止以后,重新启动Agent 进程进行文件采集,如果被实时采集的文件数据追加内容超过10 行,Agent 进程重新启动采集任务以后会造成部分数据丢失。
(2)Spooling Directory Source:采集目录中新增文件的数据。Spooldir 可以监听一个目录,并同步目录中的新文件到sink,被同步完的文件可立即删除或打上标签,适用于同步新文件,不适合对实时追加日志的文件数据进行监听并同步。
(3)Taildir Source:可以监控多个目录,并且使用正则表达式匹配该目录中的文件名进行实时采集,可以说是Spooldir Source 与Exec Source 的结合体,并具有两者的优点。Taildir Source 适合用于监听实时追加的多个文件和断点续传,它以JSON 格式记录每个被采集文件的索引节点inode信息、绝对路径和最新采集位置信息,从而实现断点续传。Agent 进程重启后不会有重复采集问题,因此,可以选择flume 的Taildir Source 监控web服务器或日志服务器的所有搜索类日志文件并进行同步,按日期生成目录,并指定生成文件名前缀。
3 Taildir Source 实时数据采集的实现
3.1 Taildir Source 实时数据采集
(1)Agent 配置
基于Taildir Source 的Agent 配置如图2 所示。

图2 基于Taildir Source 的Agent 配置
(2)启动Agent
输入bin/flume-ng ageng -n agl -c conf -f conf/taildir-hdfs.conf,启动Agent。
(3)数据采集测试
数据采集测试操作步骤如图3 所示。
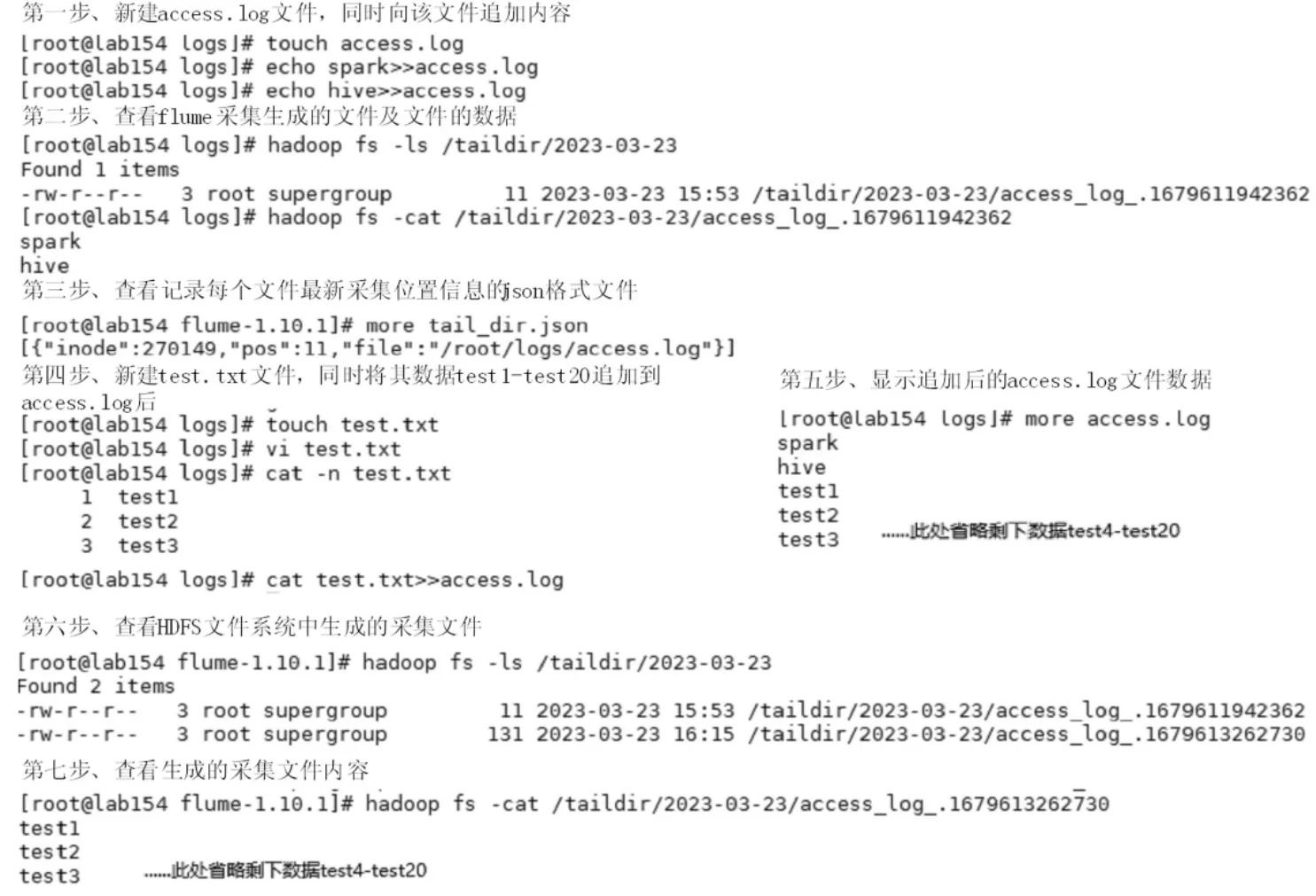
图3 Taildir Source 追加数据采集实验
3.2 Flume 实时数据采集Taildir Source 的缺点
Taildir Source 通过配置文件中filegroups 配置项设置,对文件数据进行采集时可以采用正则表达式对一类或一组文件进行采集,在图2 中通过设置配置项ag1.sources.src1.filegroups=f1 和ag1.sources.src1.filegroups.f1=/root/logs/access.*.log 可以实现对/root/logs 目录下文件名中包含关键字access 的所有文件数据进行采集,采集完成后将另一个文件test.txt 中的数据追加到access.log 文件中,通过实验发现追加的数据也被采集到了HDFS文件系统中。将图3 中的access.log 文件重新命名为"access-+年+月+日.log" 格式,然后查看HDFS文件系统中对应的目录,发现有新的采集文件生成,通过Web 端查看新生成的文件,发现最新生成的文件大小与前两个文件大小之和相等,同时通过haddoop fs-cat 命令显示内容,发现其数据与追加了test.txt 文件数据之后的access.log 文件数据相同,因此,Taildir Source 在进行实时数据采集时,如果被采集文件重命名,则存在数据重复采集,实验过程及结果如图4 所示。

图4 Taildir Source 对重命名文件数据重复采集
3.3 Flume 实时数据采集Taildir Source 的改进
在实际应用项目中,某些日志框架程序会对前一天产生的日志文件按照日期等格式进行重命名,使日志文件的绝对路径发生变化,由前面分析可知Flume 基于Taildir Source 采集文件数据时会以文件的inode 值和绝对路径作为更新和读取文件的条件,因此Flume 会对该文件的数据进行重新采集,影响数据采集的准确率而无法发挥出Taildir Source 断点续传的优势。根据Flume 的Taildir Source 数据采集特点,针对这种应用场景可以通过优化Flume 源码解决。
通过查看Taildir Source 的采集配置文件,发现Taildir Source 在采集文件数据时会自动生成保存采集文件位置信息的json 格式的文件,打开该文件内容为[{"inode":270149,"pos":144,"file":"/root/logs/access-2022-09-29.log"}],inode 表示该文件在Linux 系统中的索引节点,Linux 系统中每一个文件的索引节点都是唯一的,除非该文件被删除之后重建一个同名的文件,否则索引节点不会改变;pos 表示当前文件的采集位置;file 表示文件绝对路径;Flume 在采集文件数据的时读取json文件的inode、pos、file 信息。
通过分析发现,Flume 采集文件数据时文件是否重新上传是由文件的inode 值和文件的path(绝对路径)共同决定的,只要其中一个有变化(如inode 改变或者文件重命名)都会造成Flume 重新采集文件数据,因此修改Flume 源码中对应的更新文件的条件即可对Flume 实时数据采集Taildir Source 的缺点进行改进。
(1)修改更新文件的条件
修改flume-taildir-source 目录中对应包下TailFile 类中updatePos()方法的更新条件。
//TailFile 类的构造方法
public TailFile(File file,Map
//*********省略部分代码*************
//path:被采集文件的绝对路径
this.path = file.getAbsolutePath();
this.inode = inode;
}
public boolean updatePos(String path,long inode,long pos)throws IOException {
//把文件inode 值和文件的绝对路径作为更新的条件
if (this.inode == inode&& this.path.equals(path)){
//*********省略部分代码*************
return true;
}
return false;
}
//*********省略部分代码*************
将TailFile.java 中的if(this.inode == inode&&this.path.equals(path))更改为if(this.inode == inode),即只把inode 值作为更新的条件。
(2)修改采集数据的条件
修改flume-taildir-source 目录中对应包下ReliableTaildirEventReader 类的updateTailFiles(参数列表)方法的更新条件。
public List
//*********省略部分*************
TailFile tf = tailFiles.ge(tinode);
//把文件inode 值和文件的绝对路径作为读取数据条件
if(tf == null || !tf.getPath().equals(f.getAbsolutePath())){
long startPos = skipToEnd ? f.length():0;
tf = openFile(f,headers,inode,startPos);
} else {
//*********省略部分*************
}
tailFiles.pu(tinode,tf);
updatedInodes.add(inode);
}}
return updatedInodes;
}
//*********省略部分代码*************
将ReliableTaildirEventReader.java 中的if(tf==null|| !tf.getPath().equals(f.getAbsolutePath()))改为if(tf == null),即只把inode 值作为读取条件。
(3)把项目重新打包后生成新的flume-taildirsource-1.10.1.jar 文件。
(4)把重新打包生成的jar 文件上传到Flume安装包下替换原来的jar 文件。
(5)重新启动Flume 进行测试
测试步骤及结果如图5 所示。从图5 中可以发现,对文件重命名之后,Flume 不会重新采集数据,对重新重命名后追加到文件中的数据同样会被Flume 监控到并进行采集,不会对原有的数据进行再次采集,从而避免了数据的重复采集。
4 结论
本文比较了三种Flume 实时数据采集方案的优缺点,对其中基于Taildir Source 的实时数据采集方案进行了改进,对改进前后的数据采集结果进行了实验对比。结果表明,相比于改进前的实时数据采集方案,改进后的基于Flume 的Taildir Source 实时数据采集方案避免了文件重命名后数据重复采集,提高了数据采集准确率。
猜你喜欢
新闻传播(2023年4期)2023-03-11
电脑报(2020年20期)2020-06-30
电脑报(2020年11期)2020-06-30
电脑爱好者(2020年1期)2020-04-28
电脑爱好者(2019年9期)2019-10-30
电脑爱好者(2019年13期)2019-10-30
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
电脑知识与技术·经验技巧(2017年1期)2017-03-21
浙江大学学报(工学版)(2015年2期)2015-05-30
