
基于CSE-YOLOv5的遥感图像目标检测方法
2023-12-14 06:27:02沈凌云郎百和宋正勋温智滔
红外技术 2023年11期
沈凌云,郎百和,宋正勋,3,温智滔
基于CSE-YOLOv5的遥感图像目标检测方法
沈凌云1,郎百和2,宋正勋2,3,温智滔1
(1. 太原工业学院 电子工程系,山西 太原 030008;2. 长春理工大学 电子信息工程学院,吉林 长春 130022;3. 教育部学科创新引智基地(D17017),吉林 长春 130022)
针对复杂任务场景中,目标检测存在的多尺度特征学习能力不足、检测精度与模型参数量难以平衡的问题,提出一种基于CSE-YOLOv5(CBAM-SPPF-EIoU-YOLOv5,CSE-YOLOv5)模型的目标检测方法。模型以YOLOv5主干网络框架为基础,在浅层引入卷积块注意力机制层,以提高模型细化特征提取能力并抑制冗余信息干扰。在深层设计了串行结构空间金字塔快速池化层,改进了统计池化方法,实现了由浅入深地融合多尺度关键特征信息。此外,通过改进损失函数与优化锚框机制,进一步增强多尺度特征学习能力。实验结果显示,CSE-YOLOv5系列模型在公开数据集RSOD、DIOR和DOTA上表现出良好的性能。mAP@0.5的平均值分别为96.8%、92.0%和71.0%,而mAP@0.5:0.95的平均值分别为87.0%、78.5%和61.9%。此外,该模型的推理速度满足实时性要求。与YOLOv5系列模型相比,CSE-YOLOv5模型的性能显著提升,并且在与其他主流模型的比较中展现出更好的检测效果。
遥感图像;目标检测;注意力机制;金字塔快速池化;多尺度目标
0 引言
目标检测是遥感图像自动分析与智能解译的基础,主要目的在于从给定图像中识别出预定义类别的目标,并精确回归目标实例的定位,如水平边框(Horizontal Bounding Box)或有向边框(Oriented Bounding Box),这有助于实现多目标的快速准确分类或跟踪[1]。
2012年,AlexNet网络在ImageNet大规模图像识别赛中展现出卓越的特征表达与分类能力,基于CNN(Convolutional Neural Network)的目标检测方法开始受到学者关注。2014年Girshick[2]利用R-CNN(Region-based Convolutional Neural Network)生成目标候选区域(Region Proposals),再利用SVM(Support Vector Machines)对特征矢量分类并定位目标边界。此后,基于CNN的数据处理因其出色的特征表达和泛化能力,逐渐成为遥感目标检测研究领域的主要趋势[3]。根据分类和回归过程,基于CNN的目标检测方法可划分为两类。第一类是基于目标候选区域(Region Proposal-Based)检测方法,代表方法有R-CNN[4]。第二类是基于回归(Regression-Based)的检测方法,代表方法有SSD(Single Shot MultiBox Detector)[5]、RetinaNet[6]、YOLO(You Only Look Once)[7]、RefineDet[8]等。
提高目标检测性能的改进措施主要有:针对小目标检测,主要通过增大目标特征图的尺度或加强特征融合。在深层网络中采用上采样方式,有效提高特征图尺度[9]。将浅层的位置信息与深层的语义信息相结合,可增强特征融合能力[10]。此外,还有注意力机制与特征融合的方法[11]、特征嵌入[12]、特征迁移[13]等方法;针对多尺度目标检测,改进途径主要是加强多尺度信息融合。如跨层连接的特征金字塔网络[14];基于自注意力机制的Transformer模型;集成卷积块注意力机制等[15]。针对密集目标检测,主要从特征增强与精确定位入手。如设计特征细化模块避免特征错位(Misalignment)[16];利用特征金字塔网络(Feature Pyramid Network, FPN)和路径聚合网络(Path Aggregation Network, PANet)集成不同层的特征图,加强遥感小目标像素特征提取[17];设计无监督得分的边界框回归(Bounding Box Regression, BBR)算法,结合非最大抑制算法优化目标区域边界框[18]。
YOLO系列算法在速度、精度、轻量化和扩展性等方面各具优势,因而在遥感目标检测领域备受关注。为提高小目标或低分辨率目标、多尺度、密集遮挡等的检测性能,主要方法有:改善主干网络特征迭代以增强特征提取[19];融合注意力机制,突出目标特征权重[20];通过密集连接(Dense Connection)方式,增强层级之间的信息传输和共享,扩大特征的重用范围[21]等;优化锚框机制[22]、损失函数[23];利用自适应剪枝压缩算法提高推理速度[24];改进NMS(Non-Maximum Suppression)算法,优化目标区域筛选[13,25]等。
受此启发,我们在具有较好综合性能的YOLOv5基础上提出了CSE-YOLOv5遥感图像目标检测方法。
1 CSE-YOLOv5模型
CSE-YOLOv5的网络结构如图1所示,该模型的输出特征尺寸分别为80×80、40×40和20×20。

图1 CSE-YOLOv5网络结构
1)针对YOLOv5主干网络在目标特征信息提取方面的不足,将卷积块注意力模块(Convolutional Block Attention Module,CBAM)应用于主干网络浅层,建立像素级的上下文信息关联,提取小目标或低分辨率目标特征,从而强化多尺度特征融合。
2)深层部分,设计一种串行结构的空间金字塔快速池化(Spatial Pyramid Pooling-Fast, SPPF)层,用于融合不同分辨率的特征图、在关键特征信息融合过程中减少参数量,提高推理速度。
3)改进损失函数与锚框机制,设计EIoU_loss(Efficient IoU Loss)为预测框位置回归损失函数(Position Regression Loss)。
1.1 卷积注意力机制模块
卷积注意力CBAM结构,如图2(a)所示。分别从通道和空间两个维度进行特征图的注意力权值推断,与初始特征图进行自适应细化,输出结果为增强的自适应细化特征图[26]。通过注意力互补机制以提高多尺度特征表达,有利于遥感图像小目标或低分辨率目标的检测。
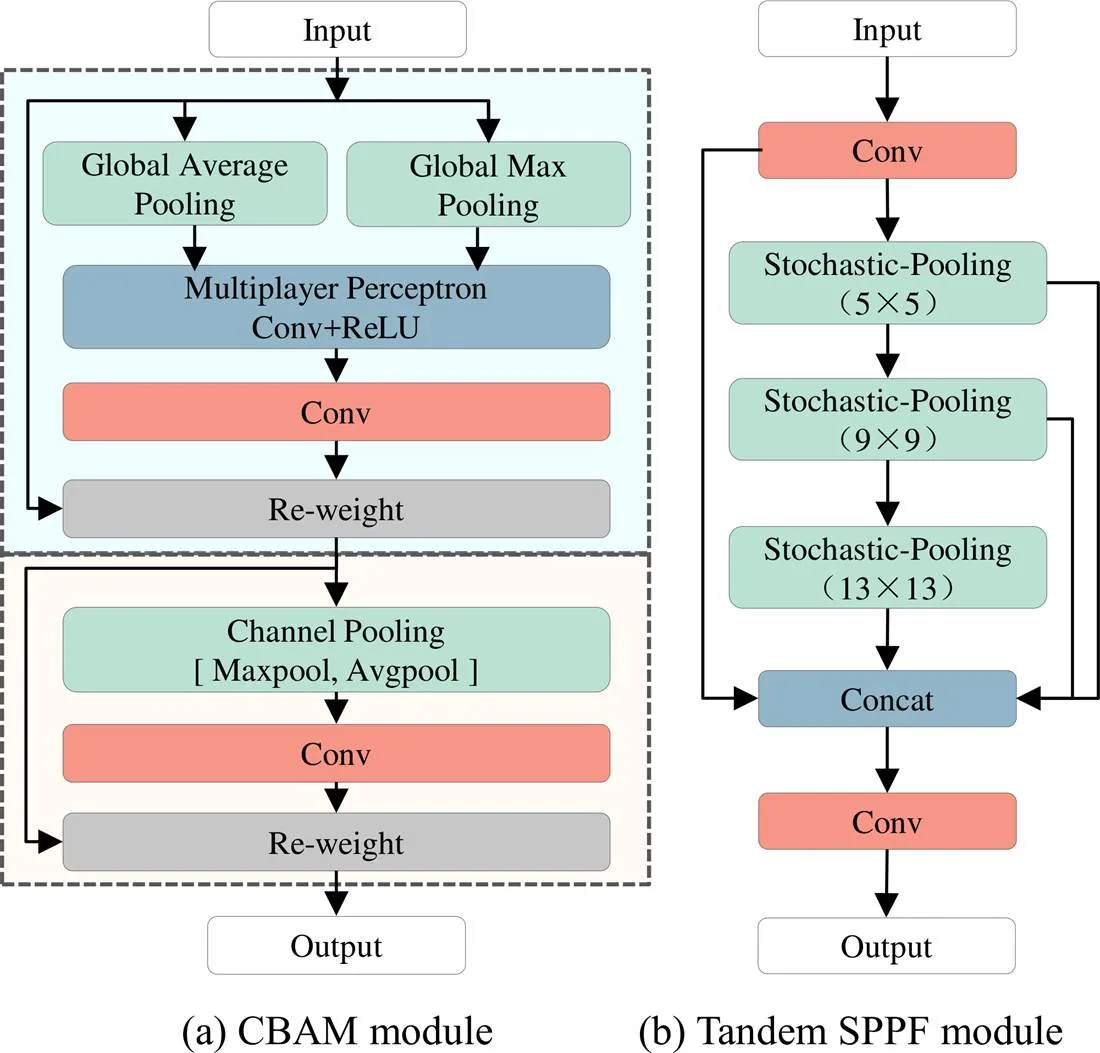
图2 CSE-YOLOv5改进模块细节
1.2 串行结构空间金字塔及其统计池化
多尺度表征法(Multiscale Representation)在提高多尺度目标检测性能方面具有显著优势。针对遥感图像目标分布特点,在主干网络深层设计了串行结构的SPPF。一方面,针对不同尺寸的特征图,自适应调整特征图尺寸向量至固定值,避免图像区域进行Resize操作引起的失真,降低计算成本。另一方面,通过融合不同分辨率的特征图为一致特征图向量,实现局部特征与全局特征融合。
为实现空间金字塔池化(Spatial Pyramid Pooling, SPP)的快速计算,设计串行空间金字塔池化结构,如图2(b)所示。将前池化层的输出作为后续池化层的输入,可以减少重复操作次数并提高网络效率。通过重复利用各层运算,有效避免冗余计算,从而将网络计算专注于从输入提取高级别特征。
池化方式上设计统计池化(Stochastic-Pooling)方式,通过平均池化(Average-Pooling)和最大池化(Max-Pooling)之间依概率选取元素,在平均情况下类似于平均池化,在局部信息的计算上遵循最大池化规则,可以避免过拟合。设特征f,其概率为:
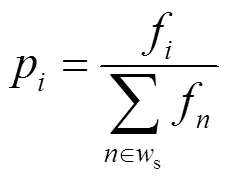
式中:s为采样窗。则依据概率进行统计抽样,统计池化输出为:
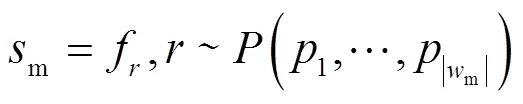
式中:m表示采样窗口尺寸;f表示采样特征值;表示依概率p随机选择的特征概率值。
1.3 锚框机制
基于回归的目标检测是对图像中感兴趣的目标进行预测,包括已知类别和预测框(Predicted Bounding Box)位置,CSE-YOLOv5使用3个尺寸的锚框来预测每个特征图中的目标。由于遥感目标在全局呈稀疏分布,而在局部呈稠密分布的特性,根据统计独立性原理,仅考虑目标空间点可能出现1~3个目标的情况,若输入图像网格中存在待测目标,与网格预测框匹配的锚框数量在3~9个之间。
增加正样本量有助于缩短模型训练时的收敛时间,锚框优化原则为提高真实框(Ground Truth Box)位于一个或多个特征图层所预测的有效正样本数量。在训练阶段,采用形状匹配原则,分别计算9种不同的锚框宽高比,如公式(3)所示。若锚框宽高比小于设定阈值anchor(RSOD数据集的最优超参数值为4.0),如公式(4)所示,预测框视为正样本;否则,将其作为无目标负样本。
若真实框与3个不同尺寸的锚框都匹配,那么匹配的锚框均可生成预测框。此外,我们还进一步改进锚框机制,根据真实框的位置,将与预测框相邻的网格(存在2~4个)作为预测网格,以增加正样本数量,降低漏检概率。
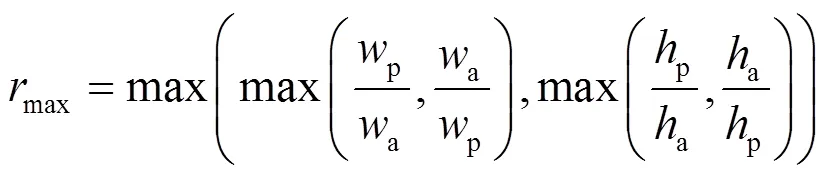
式中:p与p分别为预测框的宽与高;a与a分别为锚框的宽与高。
max<anchor=4.0 (4)
根据RSOD数据集目标框的统计特点,我们采用K-Means结合遗传算法(Genetic Algorithm,GA)对锚框尺寸优化。输入图像为640×640,将维空间的欧氏距离(Euclidean Distance)转换为二维平面数组距离,优化后获得9组锚框,尺寸参数分配如表1所示。
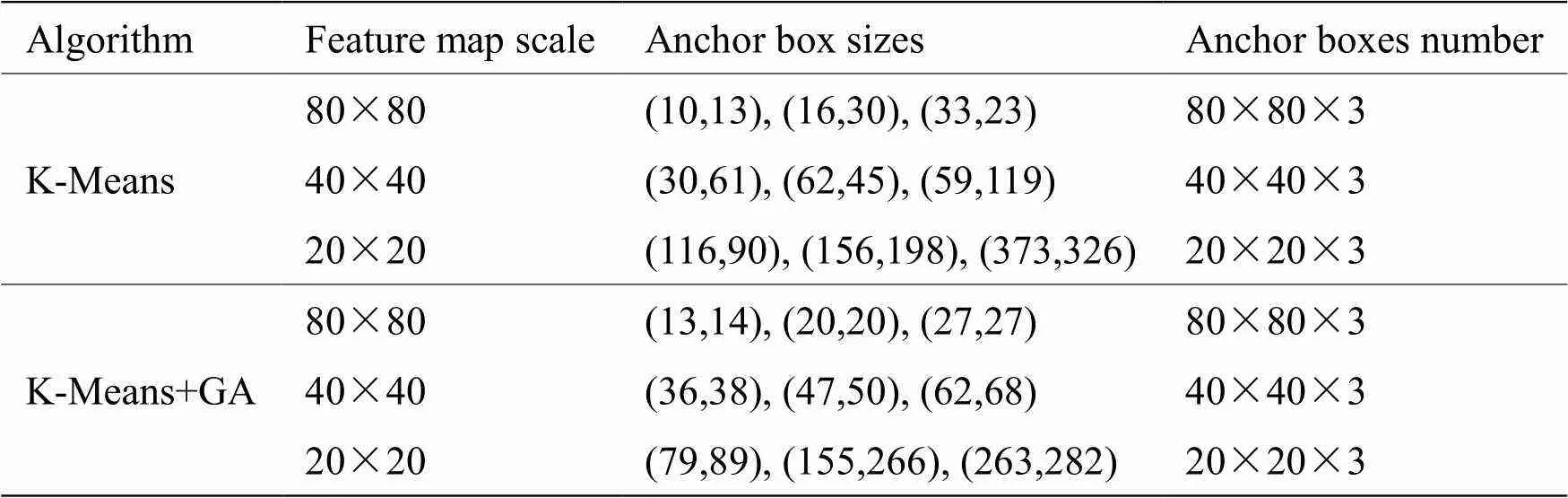
表1 基于不同聚类算法的RSOD数据集锚框参数
当采样率减小时,特征图的相对尺度会增大,感受野变小。采用小尺寸锚框,预测小目标或低分辨率目标,从而提高检测效果。反之,采样率增大时,应采用大尺寸锚框来预测大目标。
1.4 损失函数
模型的损失函数设计包括:位置回归损失函数、目标置信度损失函数与目标类别损失函数。
1.4.1 位置回归损失函数
YOLOv5原模型采用CIoU_loss损失函数,当两个或多个预测框的中心点与真实框的中心点以一定概率重合,且宽高比相等时,位置损失函数将失效。
为了解决这个问题,将宽高比惩罚信息修改为宽、高边长惩罚信息,并重新定义高效交并比损失函数EIoU_Loss,如公式(5)所示。函数返回值为box_loss,数值越小、预测回归的准确性越高。
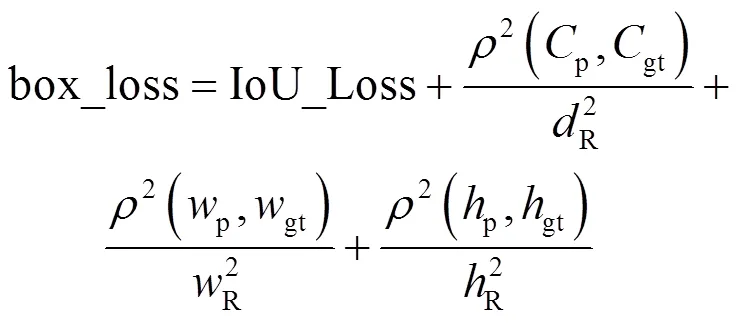
1.4.2 目标置信度损失函数与目标类别损失函数
利用二元交叉熵损失函数BCE With Logits Loss,可以分别计算目标置信度损失函数与目标类别损失函数。其中,目标置信度损失函数返回值为obj_loss,值越小表示目标检测准确性越高,如公式(6)所示;目标类别损失函数返回值为cls_loss,其值越小意味着目标分类越准确,如公式(7)所示。
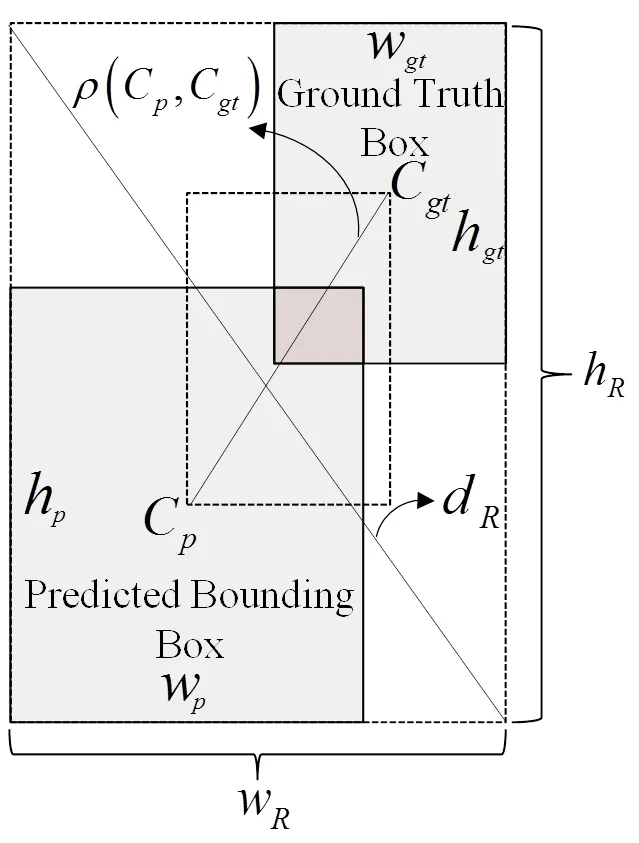
图3 位置回归损失函数的成本计算
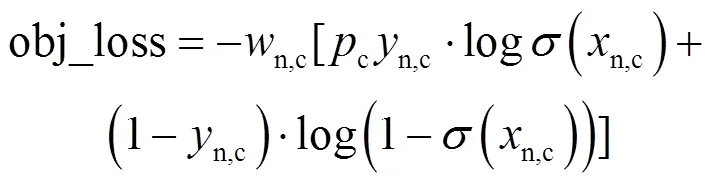
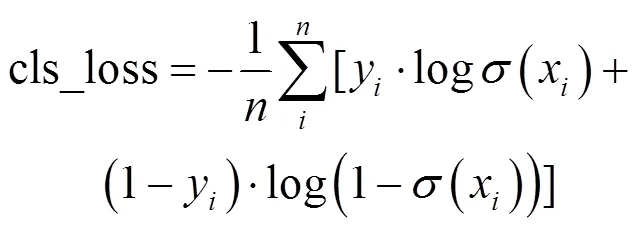
式中:()=1/[1+exp(-)]为sigmoid函数;表示样本总数,第样本的类别表示为y,其预测概率表示为x。在模型测试阶段,由于同一目标可能存在多个相似的预测框,为了获得最佳的预测边界框并防止因图像中目标遮挡而导致漏检,需要通过非极大抑制算法(NMS)过滤并筛选最佳预测框。
1.4.3 损失函数
损失函数由3部分组成:预测框位置回归损失函数、目标置信度损失函数和目标类别损失函数,计算分别如公式(5)、(6)、(7)所示,根据成本变化速率与损失值点梯度趋势,经大量实验与调参,选择优化后的经验权重值分别为0.05、1.0和0.5,损失函数如公式(8)所示:
loss=0.05×box_loss+1.0×obj_loss+0.5×cls_loss(8)
优化后的损失函数增强了多尺度特征学习能力,提高模型的训练效果与检测性能。
2 实验与结果分析
2.1 实验数据集
实验检测基准选择,模型训练与测试分别采用RSOD数据集[18],DIOR数据集与DOTA数据集(v1.5)。其中,RSOD数据集由4类标注目标Aircraft、Oiltank、Overpass、Playground组成,包含936张标注图像与40张背景标注图像,实验将RSOD数据集按8:1:1比例随机划分为独立的训练集、验证集以及测试集。
DIOR包含来自多种场景和视角的23463张图像,涵盖了20个不同的目标类别和190288个目标实例。随机选取DIOR数据集图像,其中训练集2170张,验证集和测试集各50张。
DOTA v1.5版本包含2806张遥感图像,覆盖了188种场景类别的16个目标类别与近40万个目标(包括小于10个像素的小目标)。训练集、验证集和测试集的划分比例为6:2:2,实验需要将数据集的有向边框标注数据格式转化为水平边框标注格式。
2.2 评价指标
1)精确率(Precision,)
精确率定义为分类预测为正的样本中实际为正的样本比率。如公式(9)所示:
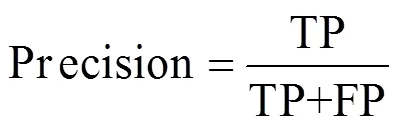
式中:TP(Ture Positive)为真正,即实际为正被分类预测为正的样本数量。FP(False Positive)为假正,即实际为负却被分类预测为正的样本数量。
2)召回率(Recall,)
召回率定义为实际为正的样本中被分类预测为正的样本比率。如公式(10)表示:
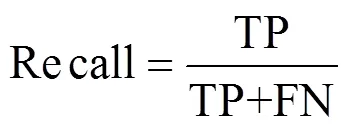
式中,FN(False Negative)为假负,即实际为正却被分类预测为负的样本数量。
3)平均精度均值(mean Average Precision,mAP)
平均精度均值mAP表示各类目标的平均精度的算术平均值。如公式(11)所示:
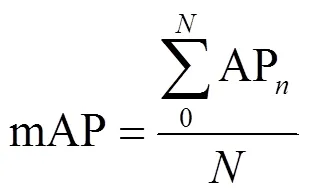
式中:AP表示第类目标的平均分类精确率,其数值等于Precision-Recall函数与坐标轴所覆盖的面积。对于多目标分类,各类别目标的分类精度AP用其平均值mAP表示。IoU参数阈值为0.5时的平均精度均值表示为mAP@0.5;IoU阈值分别取0.5、0.55、0.6…0.95时对应的mAP值,再取平均值得到mAP@ 0.5:0.95。
2.3 模型训练与测试
实验环境如表2所示。模型的训练超参数设置如表3所示。

表2 实验环境

表3 模型训练超参数设置
训练过程采用学习率衰减(Learning Rate Decay)方法,随着训练迭代轮次(epochs)的增加,学习率逐渐减小,令模型训练过程更加稳定。在最优解处平稳收敛,避免震荡。图4展示了CSE-YOLOv5s模型以及YOLOv3、YOLOv4、YOLOv5、YOLOv8和Faster R-CNN在训练集和验证集上随着迭代(epochs)变化的损失函数曲线,计算如公式(8)所示。由图可知,各损失函数的均值随epoch次数而急剧减小。当训练epoch接近200次时,损失函数的均值趋于收敛。随着迭代轮次增加,Precision、Recall及mAP@0.5值迅速提升并逐渐趋近于稳定值,如图5所示。
为了比较原模型YOLOv5s和改进模型CSE-YOLOv5s在目标检测方面的表现,我们在同一组图像上展示了两种模型实验结果的对比示意图,如图6所示。通过图中可以明显观察到,相较于YOLOv5s模型,CSE-YOLOv5s模型在漏检和误检方面都有显著改善,从而大幅提高了对多尺度目标的检测性能。

图4 损失函数随模型训练迭代变化曲线图(RSOD)
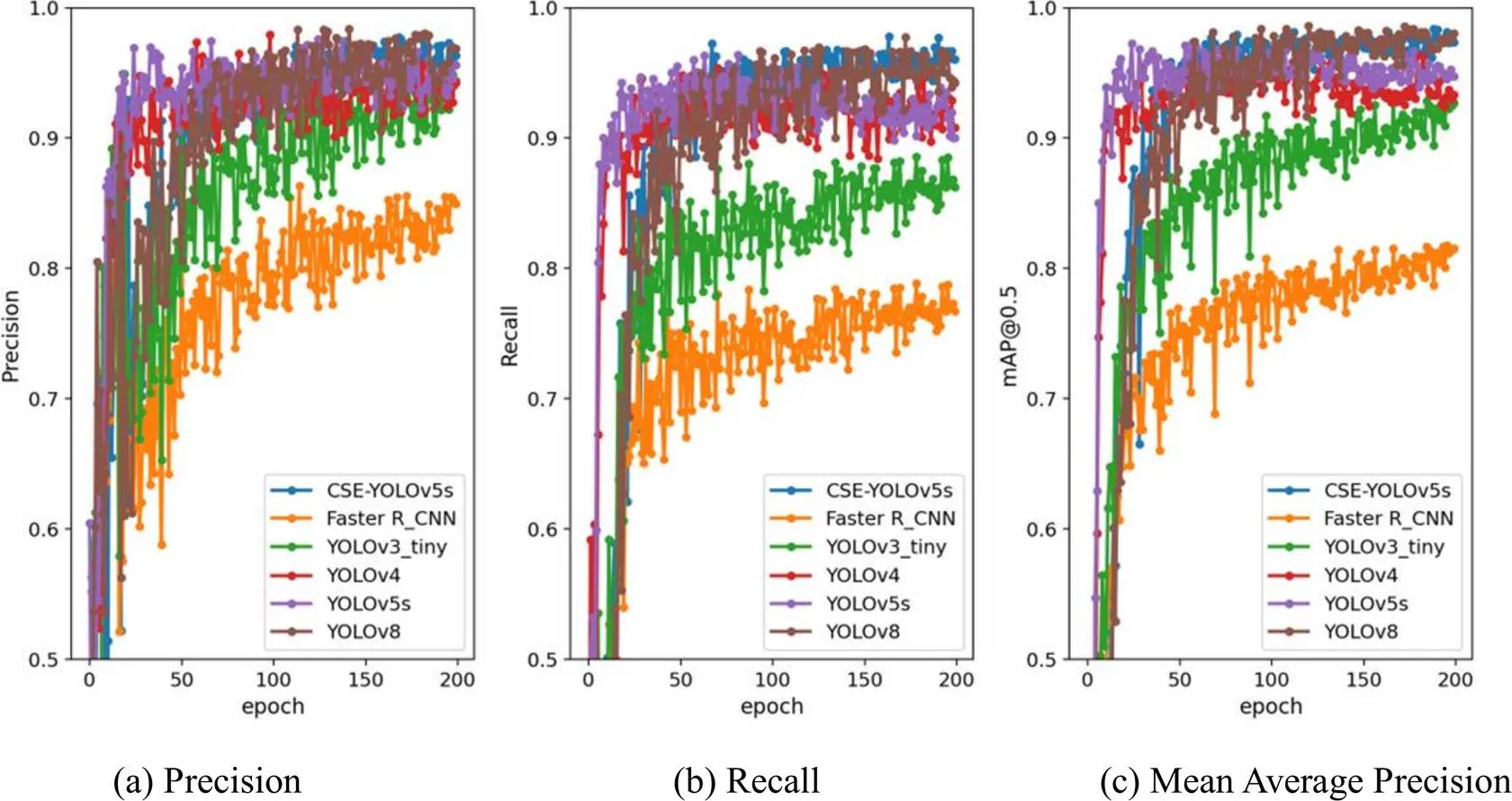
图5 RSOD数据集上精确率、召回率及平均精度均值(mAP@0.5)的迭代变化曲线图

2.4 消融实验
为了验证CBAM层、串行结构SPPF层、损失函数EIoU(同时锚框机制优化)对CSE-YOLOv5性能影响,我们在RSOD数据集上进行模型组合训练与测试,结果如表4所示。当YOLOv5s增加CBAM层后,mAP@0.5提高了0.9%,RSOD测试集各目标类别的检测平均精确率提高了1.1%,推理时间增加了0.1ms。说明增加CBAM层提高了模型的多尺度特征学习能力。YOLOv5s模型与YOLOv5s+CBAM模型在DIOR与DOTA测试集的可视化结果对比分别如图7、图8所示。
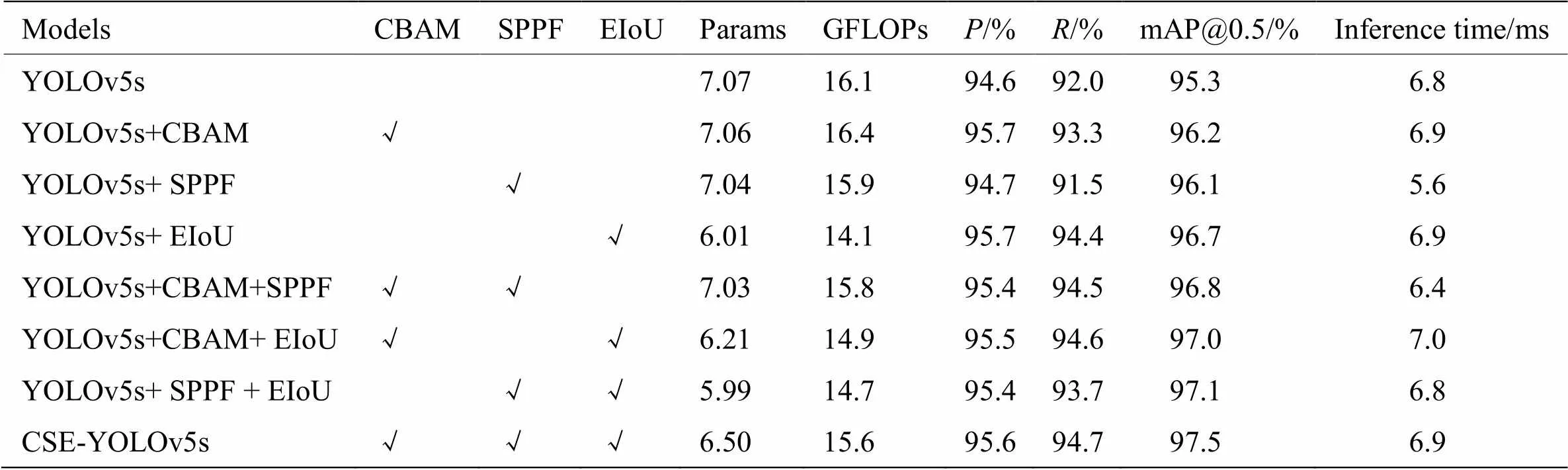
表4 消融实验(RSOD)


图8 YOLOv5s 与YOLOv5s+CBAM 在DOTA测试集目标检测结果对比
当YOLOv5s模型改进串行结构的SPPF层后,mAP@0.5提高了0.8%,推理时间减少了1.2ms;当YOLOv5s模型改进损失函数EIoU和优化锚框机制后,mAP@0.5提高了1.4%,提高较为明显,同时推理时间增加了0.1ms。
当同时改进CBAM、SPPF、EIoU与优化锚框机制后,得到CSE-YOLOv5s。mAP@0.5提高了2.2%。推理时间仅增加了0.1ms。说明模型在多尺度遥感图像目标检测方面精度有明显的性能提升,同时仅有轻微的推理时间增加。
消融实验结果表明,增加CBAM层可以有效解决卷积迭代中细节特征丢失的问题,提高模型的多尺度特征学习能力。串行结构的SPPF层通过降低关键特征信息融合时的参数数量,缓解了模型推理时间的增加。统计池化方式的使用有效避免了模型过拟合的问题。通过优化锚框机制和损失函数,可以解决固定锚框尺寸导致的自适应能力不足,进一步提高目标检测的有效性。
2.5 与其他模型测试对比实验
为了量化分析CSE-YOLOv5模型在不同场景下的检测性能,在公开数据集RSOD、DIOR与DOTA上,我们将CSE-YOLOv5系列模型与主流目标检测模型进行了训练和测试对比实验。实验结果见表5。
在数据集RSOD上的结果表明,相对于YOLOv5不同尺寸系列模型YOLOv5-nsmlx,CSE-YOLOv5系列模型的mAP@0.5分别提高了2.6%、2.2%、1.2%、0.6%和0.6%,平均提高了1.5%,达到平均值96.8%。mAP@0.5:0.95分别提高了0.7%、0.7%、0.6%、0.4%和0.4%,平均提高了0.56%,达到平均值87.0%。平均推理时间仍能达到21.68ms(即46fps),虽然略有牺牲,能够满足实时性目标检测需求。相较于Faster R-CNN、YOLOv3、YOLOv4和YOLOv8,CSE-YOLOv5模型在检测精度方面同样有了显著提升。其中,CSE-YOLOv5s模型的推理时间为6.9ms,虽然略逊于YOLOv8s模型的推理时间6.1ms,但mAP@0.5达到97.5%,高于YOLOv8s模型的93.3%。
在数据集DIOR与DOTA上的结果表明,CSE-YOLOv5系列模型在多尺度遥感图像目标检测方面表现优异,mAP@0.5分别达到平均值92.0%与71.0%,mAP@0.5:0.95分别达到平均值78.5%与61.9%。
表5中对比结果显示,CSE-YOLOv5系列模型通过自适应调整注意力权重来细化特征提取,强化多尺度特征融合,有效改善小目标或低分辨率目标的检测,检测精度得到了明显的提升。CSE-YOLOv5模型在RSOD、DIOR与DOTA数据集上目标检测结果如图9所示。
3 结论
针对遥感图像卷积后多尺度特征学习能力弱、检测精度与模型参数数量相互制约等问题,在YOLOv5不同尺寸系列模型YOLOv5-nsmlx的基础上,提出了改进的CSE-YOLOv5系列模型,通过增加卷积块注意力机制,强化细化特征提取并抑制冗余信息干扰,设计了串行结构空间金字塔快速池化层,优化锚框机制,改进损失函数,增强多尺度特征学习与融合能力。在满足推理的实时性要求下,显著提高了模型的检测精度。实验结果验证了CSE-YOLOv5模型在遥感图像目标实时检测应用中具备较强的性能优势。
[1] WANG K, LI Z, SU A, et al. Oriented object detection in optical remote sensing images: a survey[J/OL]., 2023,https://arxiv.org/ abs/2302.10473.
[2] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//, 2014: 580-587.
[3] Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks[J]., 2017, 60(6): 84-90.
[4] Girshick R. Fast R-CNN[C]//(ICCV), 2015: 1440-1448.
[5] LIU Wei, Dragomir Anguelov, Dumitru Erhan, et al. SSD: single shot multibox detector[J/OL]., 2015, https://arxiv.org/ abs/1512.02325.
[6] LIN Tsungyi, Goyal Priya, Girshick Ross, et al. Focal loss for dense object detection[J]., 2020, 42(2): 318-327.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//(CVPR), 2016: 779-788.
[8] ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection[C]//, 2018: 4203-4212, Doi: 10.1109/CVPR.2018.00442.
[9] CHEN H B, JIANG S, HE G, et al. TEANS: A target enhancement and attenuated no maximum suppression object detector for remote sensing images[J]., 2020, 18(4): 632-636.
[10] HOU L, LU K, XUE J, et al. Cascade detector with feature fusion for arbitrary-oriented objects in remote sensing images[C]//(ICME), 2020: 1-6. Doi: 10.1109/ICME46284.2020.9102807.
[11] LU X, JI J, XING Z, et al. Attention and feature fusion SSD for remote sensing object detection[J]., 2021, 70: 1-9.
[12] LI Q, MOU L, LIU Q, et al. HSF-Net: multiscale deep feature embedding for ship detection in optical remote sensing imagery[J/OL]., 2018, 56(12): 7147-7161.
[13] DONG R C, XU D Z, ZHAO J, et al. Sig-NMS-based faster R-CNN combining transfer learning for small target detection in VHR optical remote sensing imagery[J]., 2019, 57(11): 8534-8545.
[14] LI C, LUO B, HONG H, et al. Object detection based on global-local saliency constraint in aerial images[J/OL]., 2020, 12(9): 1435, https://doi.org/10.3390/rs12091435.
[15] ZHU X K, LYU S C, WANG X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//2021(ICCVW), 2021: 2778-2788.
[16] YANG X, YAN J, FENG Z, et al. R3Det: Refined single-stage detector with feature refinement for rotating object[C]//, 2022: 3163-3171.
[17] QING Y, LIU W, FENG L, et al. Improved YOLO network for free-angle remote sensing target detection[J]., 2021, 13(11): 2171.
[18] LONG Y, GONG Y, XIAO Z, et al. Accurate object localization in remote sensing images based on convolutional neural networks[J]., 2017, 55(5): 2486-2498.
[19] XU D, WU Y. FE-YOLO: A feature enhancement network for remote sensing target detection[J]., 2021, 13(7): 1311.
[20] CHEN L, SHI W, DENG D. Improved YOLOv3 based on attention mechanism for fast and accurate ship detection in optical remote sensing images[J]., 2021, 13(4): 660.
[21] XU D, WU Y. Improved YOLO-V3 with DenseNet for multi-scale remote sensing target detection[J]., 2020, 20(15): 4276.
[22] 赵玉卿, 贾金露, 公维军, 等. 基于pro-YOLOv4的多尺度航拍图像目标检测算法[J]. 计算机应用研究, 2021, 38(11): 3466-3471. ZHAO Y Q, JIA J L, GONG W J, et al. Multi-scale aerial image target detection algorithm based on pro-YOLOv4[J]., 2021, 38(11): 3466-3471.
[23] Gevorgyan Z. SIoU Loss: more powerful learning for bounding box regression[J/OL]., 2022,https://arxiv.org/abs/ 2205.12740.
[24] 王建军, 魏江, 梅少辉, 等. 面向遥感图像小目标检测的改进YOLOv3算法[J]. 计算机工程与应用, 2021, 57(20): 133-141. WANG J J, WEI J, MEI S H, et al. Improved Yolov3 for small object detection in remote sensing image[J]., 2021, 57(20): 133-141.
[25] XU Z, XU X, WANG L, et al. Deformable ConvNet with aspect ratio constrained NMS for object detection in remote sensing imagery[J]., 2017, 9(12): 1312.
[26] Sanghyun Woo, Jongchan Park, Joon-Young Lee, et al. CBAM: convolutional block attention module[J/OL]., 2018, https://arxiv.org/abs/1807.06521.
Remote Sensing Image Target Detection Method Based on CSE-YOLOv5
SHEN Lingyun1,LANG Baihe2,SONG Zhengxun2,3,WEN Zhitao1
(1. Department of Electronic Engineering, Taiyuan Institute of Technology, Taiyuan 030008, China; 2. Sch. of Elec. and Info. Engineering, Changchun University of Science and Technology, Changchun 130022, China;3. Overseas Expertise Introduction Project for Discipline Innovation D17017, Changchun 130022, China)
We proposed a new object detection method based on the CSE-YOLOv5 (CBAM-SPPF-EIoU-YOLOv5) model for insufficient multi-scale feature learning ability and the difficulty of balancing detection accuracy and model parameter quantity in remote sensing image object detection algorithms in complex task scenarios. We built this method on the YOLOv5 model's backbone network framework and introduced a convolutional attention mechanism layer into the shallow layers to enhance the model's ability to extract refined features and suppress redundant information interference. In the deep layers, we constructed a spatial pyramid pooling fast (SPPF) with a tandem construction module and improved the statistical pooling method to fuse multi-scale key feature information from shallow to deep. In addition, we further enhanced the multi-scale feature learning ability by optimizing the anchor box mechanism and improving the loss function. The experimental results demonstrated the superior performance of the CSE-YOLOv5 series models on the publicly available datasets RSOD, DIOR, and DOTA. The average mean precisions (mAP@0.5) were 96.8%, 92.0%, and 71.0% for RSOD, DIOR, and DOTA, respectively. Furthermore, the average mAP@0.5:0.95 at a wider IoU range of 0.5 to 0.95 achieved 87.0%, 78.5%, and 61.9% on the same datasets. The inference speed of the model satisfied the real-time requirements. Compared to the YOLOv5 series models, the CSE-YOLOv5 model exhibited significant performance enhancements and surpassed other mainstream models in object detection.
remote sensing images, target detection, attention mechanism, spatial pyramid pooling-fast, multi-scale target
TP391
A
1001-8891(2023)11-1187-11
2023-06-07;
2023-08-07.
沈凌云(1979-),女,工学博士,副教授,主要从事机器视觉与智能信息处理方向研究。E-mail:shenshly@163.com。
山西省引进人才科技创新启动基金(21010123);山西省高等院校大学生创新项目(S202314101195);吉林省科技发展计划基金(YDZJ202102CXJD007)。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
软件导刊(2022年3期)2022-03-25 04:45:04
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
计算机技术与发展(2019年1期)2019-01-21 00:56:38
太空探索(2016年5期)2016-07-12 15:17:55
