
基于多源信息和深度学习的多作物叶面积指数预测模型研究
2023-12-13 06:36郝子源李民赞
光谱学与光谱分析 2023年12期
郝子源, 杨 玮*, 李 浩, 于 滈, 李民赞, 2
1. 中国农业大学“智慧农业系统集成研究”教育部重点实验室, 北京 100083 2. 中国农业大学农业农村部“农业信息获取技术”重点实验室, 北京 100083
引 言
叶面积指数(leaf area index, LAI)是表征与跟踪作物生长状态的一个重要参数, 其定义为单位土地面积上植物叶片总面积占土地面积的倍数[1]。 快速、 准确和低成本获取LAI对于农业生产具有重要意义, 其获取方法主要分为直接测量法和间接测量法[2]。 直接测量法通常是通过破坏性的方法测量作物LAI, 该方法费时费力, 会对作物造成损伤。 因此, 间接测量法得到了更加广泛的应用, 其主要包括反演法和图像处理法。 反演法又可以分为物理模型反演和植被指数反演[3]。 其中, 物理模型反演对植被类型依赖程度小, 适用范围广, 然而用于反演LAI的先验知识却难以获取。 与此相比, 通过提取植被指数反演LAI则更受研究者的欢迎[4], 此类方法建模简单, 而植被指数的获取过程往往较为复杂, 尤其对于遥感图像, 通常需要使用专业软件进行复杂的预处理才能提取植被指数, 因此难以实时反演作物LAI。 随着计算机视觉技术的发展, 基于图像处理的LAI测量方法也逐渐成为研究的热点。 目前已有部分研究通过获取和处理作物图像, 建立线性或非线性测量模型实现LAI的快速获取[5-7]。 与传统遥感反演方法相比, 对遥感图像进行图像处理获取作物LAI的方法具有较好的实时性, 测量准确性尚可。 然而过去的研究多是只将图像作为模型输入只针对同一作物建模, 本工作为了使所建立的LAI预测模型更加准确且普适性更好, 选取了四种作物的无人机低空多光谱图像融合相关一维数据进行建模分析。
考虑到LAI预测模型的输入信息包含图像以及一维信息, 需要进行图像特征提取、 多源信息融合以及LAI回归预测。 而卷积神经网络(convolutional neural network, CNN)算法是用于图像特征提取的最常用的方法之一。 该算法可以对输入的图像进行卷积运算, 从而获得图像的深层特征, 目前广泛应用于植物种类识别[8], 作物病害检测[9]和作物长势监测[10]等农业领域, 并表现出了卓越的特征提取能力。 由于CNN的网络卷积层数较多, 而本研究还需要融合一维数据, 一维数据在较深的网络中易出现梯度消失的问题。 因此, LAI预测模型在CNN算法提取图像特征的基础上, 还需增加用于信息融合和回归预测的算法。 而以随机梯度提升算法(gradient boosting decision tree, GBDT)为代表的决策树模型可以很好地实现数据特征融合以及回归分析。 GBDT的核心思想是在不断学习预测残差的过程中降低损失函数, 通常会对决策树的参数进行优化以提高预测能力, 但也会导致过拟合。 改进的GBDT即LightGBM(light gradient boosting machine method)则具有更高的预测率和更好的稳健性。 在农业领域, 已有研究将LightGBM算法用在农业环境和作物参数的回归预测研究中。 文献[11]通过温室环境因素预测温室温度, 并与多种机器学习算法对比, 证明了LightGBM算法在回归预测中的优秀性能。 有研究应用LightGBM算法预测作物损伤, 也取得了较好的结果。
为了针对多种作物建立通用的基于多源信息的LAI预测模型, 本研究采用了组合型网络构架的解决方案。 该组合型网络结构可以分为两部分: (1)基于CNN的图像特征提取和分类模型; (2)基于LightGBM的LAI回归预测模型。 本工作使用CNN算法对无人机拍摄的低空多光谱图片的特征进行提取, 采用几种网络结构, 先提取图像特征, 建立作物分类模型对输入图像的适用性进行分析。 然后将提取的图像特征进行回归预测分析, 与一维数据进行融合, 使用LightGBM算法最终建立了基于多源信息的LAI预测模型。 本研究贡献了一种新的快速、 准确和低成本获取多种作物LAI的建模思路, 为LAI现场监测设备的开发奠定基础。
1 实验部分
1.1 实验地点
2020年10月-2021年11月在中国山东省泰安市的商业农场进行研究, 为了建立适合于多种作物的LAI预测模型, 选择了四种作物进行数据采集。 实验在4个地块进行, 分别种植了大豆、 小麦、 花生、 玉米[图1(a-d)]。 每个地块的作物种植信息和实验时期如表1所示, 对于每种作物, 均选择了6个生长状态存在差异的时期进行实验, 生长时期依据BBCH(Biologische Bundesanstalt, Bundessortenamt, and Chemical Industry)标准表示。

表1 作物种植信息和实验时期Table 1 Crop planting information and experimental period
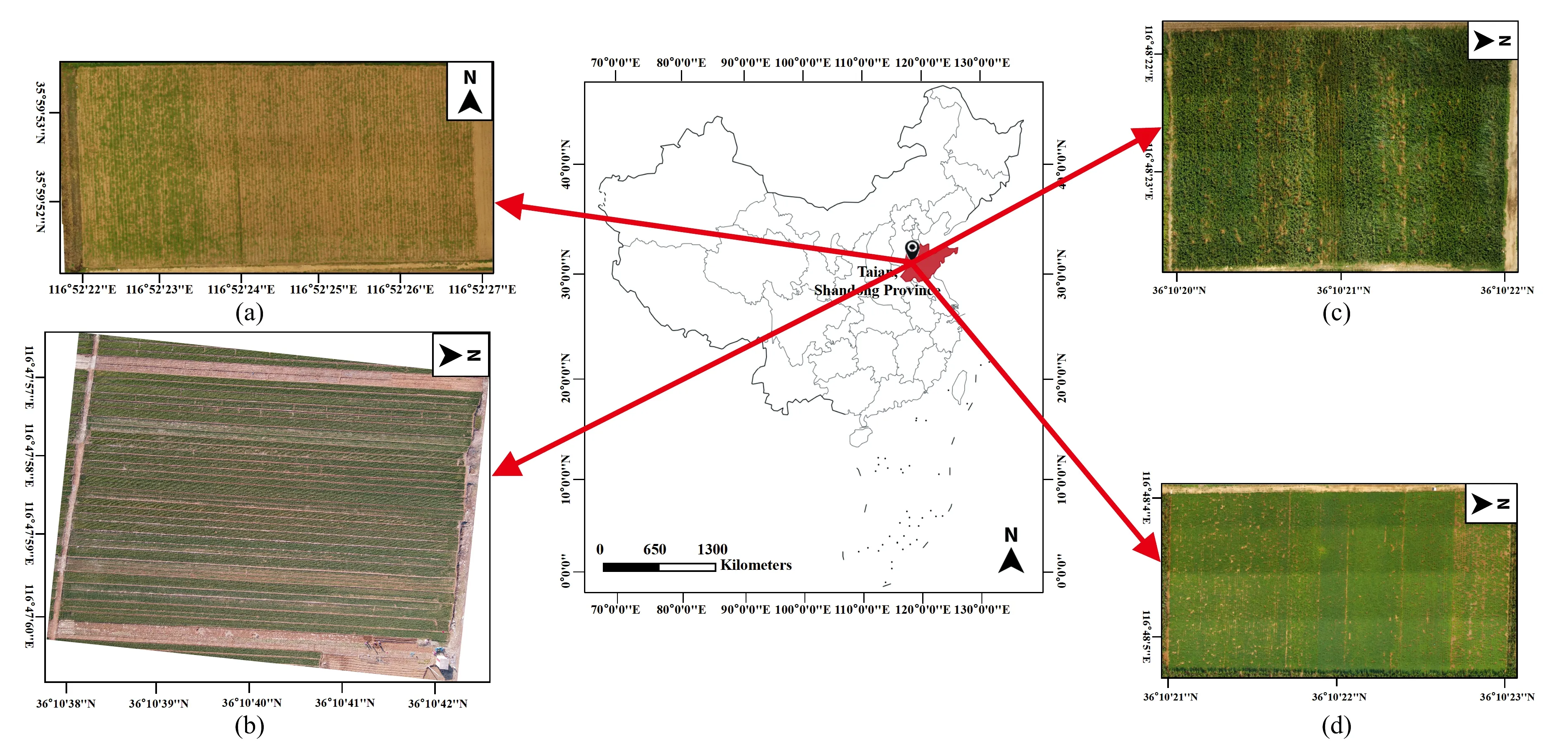
图1 实验位置和试验地块(a): 大豆地块航拍图; (b): 小麦地块航拍图; (c): 花生地块航拍图; (d): 玉米地块航拍图Fig.1 Experimental site and plots(a): Aerial image of the soybean plot; (b): Aerial image of the wheat plot; (c): Aerial image of the peanut plot; (d): Aerial image of the maize plot
1.2 无人机数据采集
使用Phantom 4无人机拍摄四种作物的多光谱图像, 无人机搭载的相机集成了RGB镜头[蓝(B): (450±16) nm; 绿(G): (560±16) nm; 红(R): (650±16) nm], 红边[(730±16) nm]镜头和近红外[(840±26) nm]镜头。 RGB图像中自带无人机三维坐标(经度, 纬度和无人机飞行高度)和无人机姿态信息(俯仰角、 横滚角和偏航角), 可通过解析图像的POS数据获得这些数据。 Tetila等在研究中已经证明了无人机在不同高度下拍摄的图片会影响模型的特征提取能力[12], 考虑到这一情况, 选择了10、 20、 30、 40、 50和60 m六个高度进行照片采集, 每个高度下拍摄100张图片。 Flavia等指出无人机的姿态会对图像视场角造成影响[13], 在航空图像采集过程中, 无人机姿态会因为航线规划和无人机震动的影响发生改变, 使图片之间存在差异。 因此, 在后续建立LAI预测模型时, 需要考虑姿态信息。
1.3 地面数据采集
关于地面获取的信息包括环境光照和作物高度, 有研究表明, 获取图像时的光照变化会对深度学习的预测准确性造成影响[14]。 在建立模型时, 考虑了光照对于预测准确性的影响, 使用光照度传感器获取试验环境中的光照度信息(单位为LUX)。
在预测LAI时, 作物高度是常被考虑的一个因素。 Scotford等指出高度更高的作物会因为有更多或更大的叶子而具有更大的LAI[15]。 为了快速获取作物高度, 通过手机拍摄的作物的侧视图[图2(a)], 使用图像处理获取作物的高度。 在拍摄图像时, 一根长为60 cm的红色圆棒作为参照物。 在HSV颜色空间模型中的H通道使用最大类间方差法分别得到参照物二值图像[图2(b)]和去除参照物二值图像[图2(c)]。 作物高度的计算公式为

图2 作物高度测量图像处理步骤(以玉米为例)(a): 原始图像; (b): 参照物二值图像; (c): 作物二值图像Fig.2 Image processing for measuring plant height (taking maize as an example)(a): Original image; (b): Binary image of reference object; (c): Binary image of crop
(1)
式(1)中,Hcrop为作物高度(cm),Hpx_crop为作物平均像素高度,Hpx_refer为参照物的像素高度。
1.4 作物种植信息采集
在建立模型时, 需要考虑作物种植信息的影响, 本研究主要分析了作物的生长天数和种植行距。 作物的LAI会随着作物的生长发生变化[16], 因此在模型输入中加入作物生长天数可以使LAI更准确地被预测。 种植行距的不同会使一个地块的LAI有明显差异。 Weber等指出, 较小的种植行距会使作物徒长, 使LAI过高[17]。 这些信息在作物播种时已经被确定, 可以直接从种植管理者处获取。
1.5 LAI实测值测量
LAI实测值的常用测量方法为直接测量和基于间接光学方法的仪器测量, 仪器测量的原理为测量穿过冠层的辐射进而推测LAI, 其结果依赖辐射传输模型的反演能力, 相比较直接测量可以获得相对准确的LAI实测值[18]。 为了提供每幅图像对应的LAI实测值, 本研究采用了直接测量方法。 在每个地块中, 每隔10 m选择5 m×5 m的小区域采集5株长势标准的作物。 对于小麦, 大豆, 花生三种作物, 由于其单片叶子面积较小, 将叶片裁剪平铺在白色纸板上, 放置刻度尺作为参考。 拍摄照片, 使用ImageJ软件测量叶片面积。 对于玉米, 测量叶片的最大宽度和长度, 使用式(2)计算玉米的叶片面积。
LAsingle=L×W×f
(2)
式(2)中, LAsingle为单个叶片的叶片面积,L为叶片长度,W为最大宽度,f为形状因子, 有研究证明对于玉米,f设为0.75[19]。 记录每个采样区域边界点的GPS数据, 用于匹配无人机图像, 通过式(3)获取LAI。
(3)
式(3)中, LAIimage为每张图像对应的地块的LAI,n为无人机图像中包含的小区域数量,i为每个小区采集的植株数, LAni为第n个小区域第i个植株的总叶片面积。ρn为第n个小区域的种植密度, 通过统计每平方米的植株数获得。
1.6 方法
1.6.1 模型构建
通过建立模型处理作物的无人机多光谱图像和相关一维数据, 实现作物图像的分类和LAI的预测。 研究一共有14 400(单次实验100张图片×4种作物×6个生长时期×6种拍摄高度)组样本, 其中随机将10 400组划分为训练集, 2 500组划分为验证集, 1 500组划分为测试集。 模型构建如图3所示, 为了实现图像信息与一维数据的融合, 需要将图像信息进行特征提取, 将提取到的特征进行张量扁平化操作, 将图像特征转化为向量数据。 因此, 在建立组合架构模型时, 首先使用了4种经典的CNN模型结构, 并根据无人机多光谱图像特点对模型的输出层进行调整, 完成图像的特征向量提取和分类, 将CNN模型提取的图像深度特征向量与一维数据进行均值归一化处理, 输入LightGBM模型中进行回归分析。 基于TensorFlow深度学习框架对模型进行训练和调试。 计算机的CPU型号为Intel Core i7-9700K, 内存为16GB, 显卡型号为NVIDIA GeForce RTX 2080Ti。
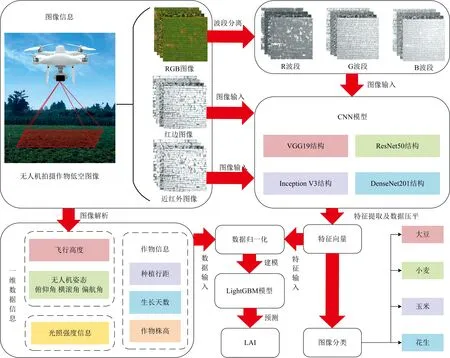
图3 模型构建示意图Fig.3 Construction of the models
1.6.2 CNN模型
CNN模型存在许多变种, 使用了四种在图像特征提取中应用较广泛的结构, 分别为VGG19, ResNet50, Inception V3和DenseNet201。
本研究使用的VGG19模型包括16个卷积核尺寸为3×3的卷积层和3个全连接层, 16个卷积层被分为5个block, 使用5个最大池化层进行分隔。 VGG19模型使用较小的卷积核对图像进行卷积, 在增加网络深度的过程中, 可以避免卷积的参数数量过多, 有助于提高网络性能。 ResNet50模型为了解决增加网络深度时容易出现的梯度消失、 收敛困难, 加入了残差学习的思想。 ResNet50模型将卷积核尺寸为1×1、 3×3和1×1的卷积层串联, 形成一个残差模块, 模型中共有16个残差模块, 还包括最初始的1个卷积层和最后的1个全连接层。 Inception V3模型不同于上述模型对于增加网络深度的研究偏向, 该模型将卷积核横向叠加形成Inception模块, 以此增加网络的宽度, 通过并行卷积计算, 可以更好地提取图像中不同尺寸的特征。 Inception V3模型的网络结构较复杂, 包含11个Inception模块以及额外的卷积层, 最大池化层, 平均池化层, Dropout层和全连接层。 DenseNet201模型的不同于上述三种模型, 其没有一味地增加网络的深度或宽度, 而是在兼顾了深度和宽度的研究之后, 通过特征重用使特征得到充分地利用。 DenseNet网络结构中包含4个Dense模块, 模块中每一层的输入都来自前面所有层的输出, 这样的设计可以使特征和梯度得到更有效的传递, 同时减轻梯度消失的问题, 使网络更容易加深以提高模型性能。
将RGB图像、 红边图像和近红外图像的尺寸压缩为224×224作为CNN模型的输入。 经过多次调参对比, 模型的超参数设置为: 基础学习率为0.000 1, 训练周期为100次, 单次训练使用的样本数为16个, 衰减常数为0.1。
1.6.3 LightGBM模型
为了建立预测精度更加准确的模型, 除了二维图像数据, 还引入了一维数据。 在模型的输入中, 无人机姿态信息(俯仰角、 横滚角和偏航角), 无人机高度, 光照度, 作物行距, 作物株高和作物生长天数信息均为一维数据。 一维数据输入模型之后, 如果通过较深的网络, 容易丢失特征, 难以发挥作用。 因此, 除了使用较深的卷积神经网络结构提取多光谱图像特征之外, 还加入LightGBM算法用于建立回归预测模型, 将图像特征向量与一维数据融合预测采样点LAI。
LightGBM算法是一种改进的梯度提升决策树, 其思想是利用决策树迭代训练获得最优的模型。 LightGBM算法的改进之处在于引入了基于直方图的决策树算法, 在合并了特征的直方图上寻找最优分割点, 降低数据分割的复杂度, 提高训练效率。 在本研究中, 经过调参将LightGBM模型的超参数设置为: 学习率为0.1, 叶子节点数为30, 线程数为6, 其余选择默认值。
2 结果与讨论
2.1 图像分类性能分析
使用CNN模型进行特征提取后, 为了直观地观察模型对于图像的特征提取能力, 先将提取到的特征用于图像分类, 分类准确度越高则说明模型的特征提取能力越好。 首先将RGB图像作为CNN模型输入, 模型分类的结果如表2所示, 将分类概率大于50%的类别作为图像的最终分类结果。 分类准确度如表4所示, 表4显示了每种模型分类获得的最高绝对准确度。 对于RGB图像, 四个CNN模型的分类准确度从高到低分别为DenseNet201(99.67%), Inception V3(98.60%), ResNet50(96.07%)和VGG19(88.13%)。 表5中给出了四种模型在进行模型训练和测试时所花费的时间, 其中时间以本研究中的硬件配置为参考。 在四个CNN模型中, 训练时间最短的是Inception V3, 训练时间最长的为DenseNet201。 同样地, DenseNet201的单组图片样本的测试时间也是四个模型中耗时最多的。 仅使用RGB图像建立模型的分类准确度已经令人满意, 为了获得更全面的作物冠层信息, 还获取了低空条件下作物冠层的红边波段图像和近红外波段图像, 将两种图像与RGB图像结合, 多段光谱的图像共同作为CNN模型的输入。 得到分类结果如表3所示、 分类准确度如表4所示, 准确度从高到低分别为DenseNet201(99.93%), Inception V3(99.73%), ResNet50(97.60%)和VGG19(90.33%), 四种模型的分类准确度都达到了90%以上, 说明使用CNN模型可以提取出有效的图像特征。 如表5所示, 四个模型的单组图片样本的训练时间和测试测试时间最长的依旧为DenseNet201, 而ResNet50和Inception V3耗费了相同的测试时间。

表2 CNN模型分类结果: 输入为RGB图像Table 2 Classification results for CNN models: RGB images as inputs

表3 CNN模型分类结果: 输入为多光谱图像Table 3 Classification results for CNN models: multispectral images as inputs
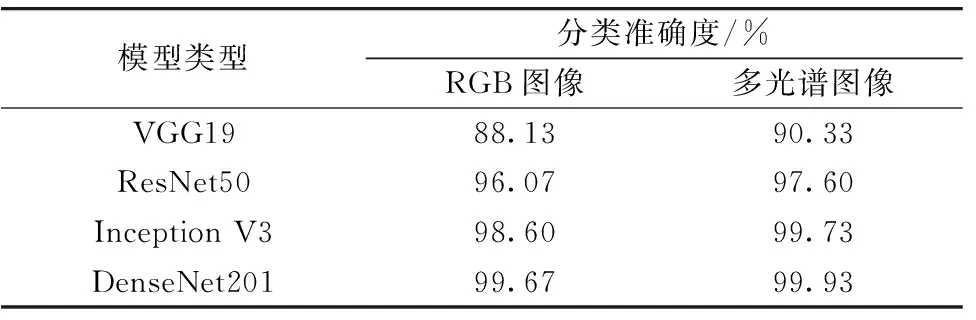
表4 模型分类准确度Table 4 Classification accuracy values of models
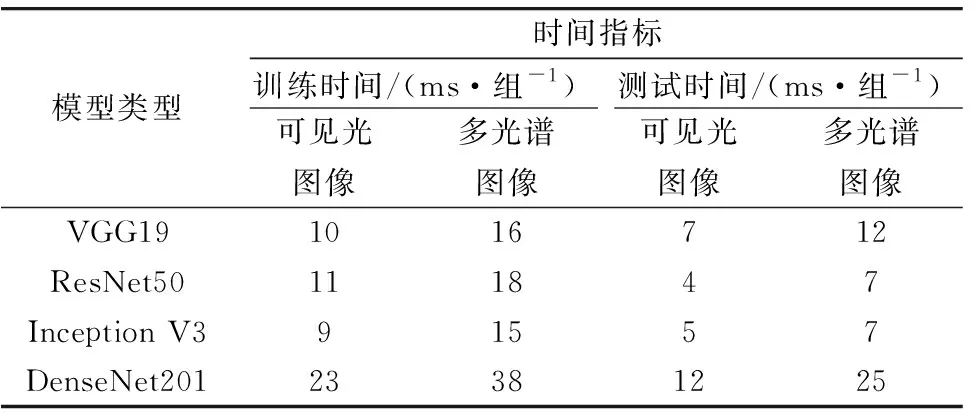
表5 模型时间指标Table 5 Time consuming indexes of models
根据结果分析, 加入红边图像和近红外图像之后, 四种模型的分类准确度均得到提高, 然而由于输入图片增加, 使得模型的训练时间和测试时间也随之延长。 在四种模型中, DenseNet201模型的层数较多, 可以提取到更多的图像特征, 因此始终具有最高的分类准确度, 但是训练和测试的耗时也是最长的。 由此可见, 在处理本研究中的分类问题时, 获得高的分类精度会牺牲模型的运行效率。 Inception V3模型的整体分类准确度也较高, 尤其是输入为多光谱图像时, 其分类准确度与DenseNet201模型接近, 均达到99%以上, 而模型的训练时间和测试时间是最短的, 整体表现令人满意。 ResNet50模型的分类准确度更低一些, 在耗时上也没明显优势。 VGG模型的分类准确度是最低的, 可能是与其网络层数较少有关, 然而在耗时上, 尤其是在对多光谱图像分类时, 时间还要长于ResNet50模型和Inception V3模型, 可见VGG模型并不适合处理本研究中作物低空冠层图像的分类问题。 在本研究中, VGG模型和ResNet50模型更加注重加深网络的层数, 然而所得到的分类效果不如Inception V3模型和DenseNet201模型。 Inception V3模型偏向于加宽网络的宽度, 而DenseNet201模型兼顾了网络深度和宽度的, 因此, 本研究中的图片特征可能更容易被加宽的网络提取到。 在本研究的图像分类问题上, Inception V3模型既保证了较高的分类准确度, 也能损耗较少的训练和测试时间, 因此该模型是最佳的选择。
2.2 回归性能分析
通过经典的ResNet50, Inception V3和DenseNet201模型提取图像的特征后, 使用LightGBM模型进行特征融合和LAI的回归处理, 最终建立LAI的回归预测模型。 为了探讨了不同输入对于模型回归准确性的影响, 将LightGBM模型的输入分为四组: (1)无人机低空RGB图像数据集; (2)无人机低空RGB图像融合红边图像和近红外图像形成的无人机低空多光谱图像数据集; (3)仅有相关一维数据的数据集; (4)无人机低空多光谱图像加入相关一维数据后组合成的多源信息数据集。
首先, 分析了仅有无人机低空RGB图像输入情况下的回归预测结果, 如图4(a, b, c)所示。 在三种模型中, DenseNet201模型的预测值和实测值的R2相较于ResNet50和Inception V3模型分别提升20.20%和3.48%。 说明DenseNet201模型提取出的图像特征在处理回归预测问题时, 也最具优势。 然而, 在该输入下, 三种的模型提取出的特征在输入LightGBM模型之后,R2最大也仅为0.711 1, 总体预测准确性较低。
模型的输入使用无人机低空多光谱图像数据集。 结果如图5(a, b, c)所示, 当输入信息从无人机低空RGB图像拓展到多光谱图像时, 基于ResNet50, Inception V3和DenseNet201三种模型提取的特征在输入LightGBM模型后, LAI的预测值和实测值的RMSE分别降低42.44%、 39.10%和35.44%,R2分别提升26.10%, 14.64%和15.20%。 另外, DenseNet201模型的LAI预测值和实测值的RMSE相较于基于ResNet50和Inception V3模型的RMSE分别降低31.81%, 29.21%,R2分别提升7.23%和3.99%。 总体加入红边图像和近红外图像, 三种CNN模型提取的特征向量输入LightGBM模型后, 回归预测效果都得到了提高, 而DenseNet201模型依旧具有最好的预测准确性。
仅将一维数据作为输入时, 如图6所示, 所建立回归模型的预测值与实测值的RMSE为0.460 9,R2为0.790 8。 当输入信息为多源信息数据集, 如图7(a, b, c)所示, 基于ResNet50, Inception V3和DenseNet201的回归模型的LAI预测值和实测值的RMSE相比较仅输入一维数据时均有明显降低, 且R2均有明显提高。 相比较无人机低空多光谱图像数据集, RMSE分别降低62.80%, 71.50%和62.55%,R2分别提升26.06%, 22.62%和18.45%。 基于DenseNet201模型的预测值和实测值的RMSE相较于基于ResNet50和Inception V3模型的RMSE分别降低31.34%,6.97%,R2分别提升3.19%和0.45%。 总体使用多元信息数据集作为回归模型的输入后, 三种模型的回归预测精度均得到了显著的提高, 而且R2均达到了0.9以上, 尤其是基于DenseNet201和Inception V3的模型在此输入下,R2和RMSE的值没有特别显著的差异, 均在0.95以上。
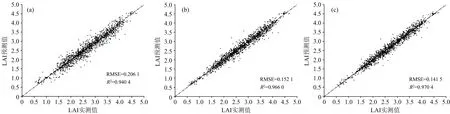
图7 以多源信息为输入的回归预测模型(a): ResNet50; (b): Inception V3; (c): DenseNet201Fig.7 Regression prediction models based on multi-source information(a): ResNet50; (b): Inception V3; (c): DenseNet201
综上所述, 当输入信息包含无人机低空RGB图像、 红边图像、 近红外图像和相关一维数据时, 基于三种CNN模型的回归模型效果均可以达到最好, 说明多光谱图像和一维数据与输出的LAI值之间有着很高的关联性, 通过增加输入信息可以显著提升模型的预测性能。 尤其是当图像信息结合一维数据后, 模型预测性能得到明显的改善, 考虑到回归系数R2的边际效益递减的原因, 一维数据对于模型输出值LAI的关联性要高于红边图像和近红外图像的关联性, 考虑到可能无人机低空RGB图像已经很大程度反映图像与输出之间的对应关系, 而红边图像和近红外图像也只能反映作物的冠层俯视信息, 对于模型特征信息的补充有限。 在一维信息中除了一部分信息(无人机姿态信息、 无人机高度信息和光照度信息)可以对图像进行修正[12-14], 另有一部分重要的信息(作物行距、 作物株高和作物生长天数)是独立于图像的额外信息, 根据文献可知[15-17], 这些与作物生长相关的一维信息也可以在一定程度反应作物LAI的值, 而本实验结果也证明了这一点。 一维信息在本研究的模型建立中起到重要作用, 但是也不能忽视图像信息的贡献, 仅使用一维数据进行建模, LAI的预测精度相比多源信息仍有较大的差距, 说明了图像特征信息在LAI预测中的必要性。 随着输入信息的逐渐增多, 模型之间的预测性能的差异性也在逐渐变小, 但使用网络结构更深的DenseNet201总可以在各种输入中取得最好的预测结果, 可以说明DenseNet201在提取数据集特征时有更好性的适用性, 但综合考虑算法的训练时间以及后续嵌入式系统的模型应用时, 应当权衡准确度与模型效率的平衡。 当输入信息较少时, 可以选择准确度较高网络结构更深的CNN网络作为图像特征提取部分的主干网络, 而当输入信息逐渐增多, 以及包括一维数据时, 可以选择更加轻量化的CNN网络作为图像特征提取部分的主干网络。 虽然基于DenseNet201的模型在分类和回归的准确度上均取得了最好的效果, 但由于其特征提取时间较长, 网络结构较深, 且模型输入信息多源, 信息种类较多, 因此, 准确度仅次于其基于Inception V3的模型是预测LAI的最佳选择。
3 结 论
为了建立适用于多种作物的通用LAI预测模型, 降低LAI获取成本, 提高获取速度, 采用多源信息和深度学习研究了LAI预测的建模方法。 LAI预测模型由CNN算法和LightGBM算法设计而成, CNN模型主要实现了图像特征向量提取和作物图像分类, LightGBM模型负责多源信息融合和LAI回归预测。 研究了不同输入对建模的影响, 具体结果如下:
(1)为了验证CNN模型对于RGB图像和多光谱图像的特征提取能力, 分别应用VGG19, ResNet50, Inception V3和DenseNet201四种CNN网络结构设计了作物分类模型。 在两种输入下DenseNet201模型均取得了最好的分类准确度, 当输入为多光谱图像时, Inception V3模型的分类准确度接近DenseNet201, 两者均在99%以上, 且Inception V3模型的训练和测试时间均少于DenseNet201的一半, Inception V3模型在该研究中更适合进行图像特征提取和完成分类任务。
(2)将CNN模型提取到的图像特征向量分别输入到LightGBM模型中, 发现仅使用RGB图像特征预测LAI时, 预测值和实测值的R2最大为0.711 1, 当使用多光谱图像特征时,R2的最大值增加到0.819 2。 而在输入中加入一维数据信息之后, 回归预测模型的R2均高于0.9, 这说明一维数据在LAI预测中发挥了重要作用, 将多光谱图像信息和一维数据等多源信息融合建模可以有效提高LAI预测模型的准确度。
本研究所提出的LAI预测模型可以预测多种作物的LAI, 同时可以给出作物种类的判别结果, 本研究中模型的输入信息均容易获取, 无人机多光谱图像和相关一维数据可以直接作为模型的输入信息, 无需复杂的处理过程, 具有快速、 低成本获取多作物LAI的优势。 本研究还为无人机平台下LAI的监测研究提供了一种可现场获取监测结果的解决思路, 本研究中的模型可以嵌入到硬件设备中帮助开发LAI监测设备。
猜你喜欢
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
世界农药(2019年4期)2019-12-30
电子制作(2018年19期)2018-11-14
建筑科技(2018年6期)2018-08-30
自动化学报(2017年11期)2017-04-04
上海农业学报(2016年2期)2016-10-27
中国交通信息化(2016年5期)2016-06-06
噪声与振动控制(2015年4期)2015-01-01
天津冶金(2014年4期)2014-02-28
