
低延迟低抖动的FAST 解码器设计与实现
2023-12-11 10:08张曦煌柴志雷冯一飞叶钧超
应用科学学报 2023年4期
张曦煌,丁 楠,柴志雷,冯一飞,叶钧超
1.江南大学人工智能与计算机学院,江苏无锡214122
2.无锡太湖学院智能装备学院,江苏无锡214064
金融信息交换适应性流协议(financial information exchange adapted for streaming,FAST)[1]是2005 年全球金融企业联盟组织FPL 提出的一种面向消息流的压缩、编码和传输方法。该方法主要是在消息流中对先后数据字段进行增量传输,压缩所需传送的数据内容,针对不同类型的二进制字段高效地提高二进制编码使得数据压缩率,降低传输数据大小。FAST协议主要应用在高密度、低延迟的数据传输领域。发送和接收方希望能够在传输带宽有限的情况下,减少不必要的信息传输,从而获得更多的数据信息[2]。
FAST 协议的一个典型应用场景是证券交易所的行情信息传输。证券交易所将行情信息通过FAST 协议压缩后传输给各个行情商,行情商采用FAST 解码器对数据进行解压缩并获得行情数据。例如,上交所新一代的Level-2 行情系统在原来FIX 的协议传输基础上对于部分数据采用了FAST 协议传输,在很大程度上提高了数据的传输效率[3]。
上交所证券成交量从2019 年53 792.145 4 亿股增长到2021 年的70 444.402 7 亿股,涨幅达到了30.96%。深交所证券成交量从2019 年的72 832.14 亿股增长到2021 年的90 805.84亿股,涨幅达到了24.68%。成交量暴涨的背后是证券交易信息数据的激增。在证券交易市场[4],第一时间获取行情信息就可以更精准地把握交易时机从而获得更高的收益。FAST 协议应用初期,解码器的设计主要以纯软件解码为主,分别为基于C++编程语言的Quickfast和Mfast 以及基于Java 的Openfast。纯软件解码开发周期短,同时在代码逻辑更新迭代上具有很大的优势。但是,由于编译器以及操作系统本身的中断机制和资源调度问题,使得解码过程中时延不稳定。此外,纯软件串行解码的特点可能会导致高峰交易时段的数据阻塞,使得整个解码系统不稳定。因此,纯软件解码越来越难以满足量化交易对行情数据实时稳定获取的需求。
为了解决纯软件解码高延迟、高抖动的问题,基于FPGA 的定制化硬件解码[5]逐渐替代了纯软件解码,其实现模式通常采用Verilog/VHDL 来进行解码逻辑的开发[6]。发挥FPGA并行流水及运行时间可精确到周期的特点,实现更低的时延和抖动。但是与纯软件相比,其开发和维护更新迭代的周期也大大增加了,很难适应交易策略和逻辑的快速迭代。
针对以上问题,已有通过Vivido HLS 完成核心模块的开发[7],从而在较低延迟的基础上提高核心模块的开发效率。但仍需要关注接口的定义以及内存的分配和管理,对开发者的硬件开发能力提出了较高的要求[8]。
为了让开发人员更多关注业务本身,而不需要关注底层硬件接口配置和内存分配及管理等重复造轮子的工作。本文探索了基于OpenCL 和HLS 快速开发FAST 解码器的技术路径。通过HLS 并行、流水指令级优化以及OpenCL 高层次的底层抽象设计开发模式,实现了一种低延迟、低抖动的FAST 解码器。其开发周期相比传统FPGA 硬件设计时间可以缩短至1/3,能够更好地适应金融行情市场解码及交易策略的快速迭代。同时,通过实验仿真和验证,该解码器解码延迟可以控制在183 ns。与纯软件相比处理速度提升了11 倍,解码延迟缩短至1/6,解码抖动幅度控制在10 ns 以内,可以满足FAST 解码的应用需求。
1 FAST 协议
FAST 协议采用存在位图PMAP(Presence Map) 值+字段压缩数据的压缩方式。具体流程是:首先,传输的字段数目和模板对应生成PMAP 作为FAST 数据的首位;其次,模板ID转换成二进制(通常为7 位二进制数,高位补0),并将高8 位补位1 作为模板值传输。再次,之后的字段数据采用停止位分割,将数据按照7 位一组进行分割,从高到低,最高位的一组高8 位补1,其余组补0,作为字段压缩数据接在模板数据之后,完成对原始数据的FAST 压缩。
FAST 数据解码则与压缩相逆,依据PMAP 值和模板获得传输数据的压缩字段数目和标签含义。设置每8 位为一组,根据后续每组的最高位来判断每一个字段的起始位置和终止位置。将每组的最高位去除,其余位合并,最终获得了每一个压缩字段数据的二进制数表示。
1.1 FAST 模板
FAST 模板作为发送方和接收方数据传输过程中的格式规则,模板的内容主要是传输数据的编号、数据类型、各个数据字段的标签含义、数据字段采用的加解密FAST 操作符、小数点的精度等标签信息。在传输总数据量不变的情况下,通过减少传输通用标签含义信息的数据,来提高有效信息的传输条数。通常FAST 协议的模板是以XML 文件的形式存放。FAST协议数据传输示意图如图1 所示。
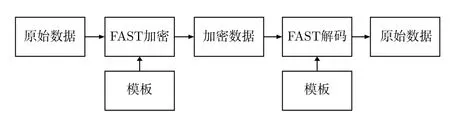
图1 FAST 协议数据传输示意图Figure 1 Data transmission diagram of FAST protocol
1.2 PMAP 值和FAST 操作符
通常而言,一条FAST 数据传输的首个字段是PMAP 值,其主要作用是判断对应数据字段解码是否需要采用FAST 操作符。
FAST 操作符主要分为无操作符、常值、缺省、复制、自增、差值、换尾。在本文解码的模板中,主要采用了无操作符、常值、复制、缺省以及自增操作符,其中常值操作符和无操作符不占用PMAP 值位元。无操作符始终出现在数据流中,而常值操作符来自于模板中的初值。复制是将上一条数据对应的字段复制到本条数据的位置。自增是在上一条数据对应字段的基础上自增1,而缺省和常值类似,也是输出模板中的初值。
1.3 数据类型和停止位
由于FAST 模板包含了小数点的精度信息,因此数据类型主要分为整型和字符串类型。此外,FAST 数据每个字段的长度并不固定,以8 bits 为一个单位,首位作为标志停止位。如果首位为1,将后7 个bit 构成一个字段进行解码操作。如果首位为0,则需要观察后一个单位的停止位,直到找到停止位为1 的单位,将除停止标志位以外的位拼接成一个整体再进行对应的解码操作。停止位的存在使得有效传输数据利用率大大提升。
2 低延迟低抖动FAST 硬件解码器设计
FAST 硬件解码分为预处理FAST 数据提取模块与核心FAST 数据解码器。预处理FAST数据提取模块主要功能是提取嵌套在STEP 数据中的FAST 数据并将其送入FAST 数据解码器中解码。核心FAST 数据解码器由PMAP 值提取、标记字段起始和终止位置、字段切分、数据类型判断和合并、数据字段解码组成。
FAST 数据解码首先需提取PMAP 值,该操作为后续字段切分的边界和字段解码的规则提供判断依据。同时FAST 数据标记字段分割位置完成后,依靠位置存放数组进行字段切分。分割完成的数据通过判断数据类型来决定是否进行字段合并。最终各字段的解码由PMAP值,分割合并后的字段以及前值字典共同完成,并输出结果。此外,根据每一次的输出结果更新前值字典以供后续的数据解码。具体FAST 解码器设计流程如图2 所示。
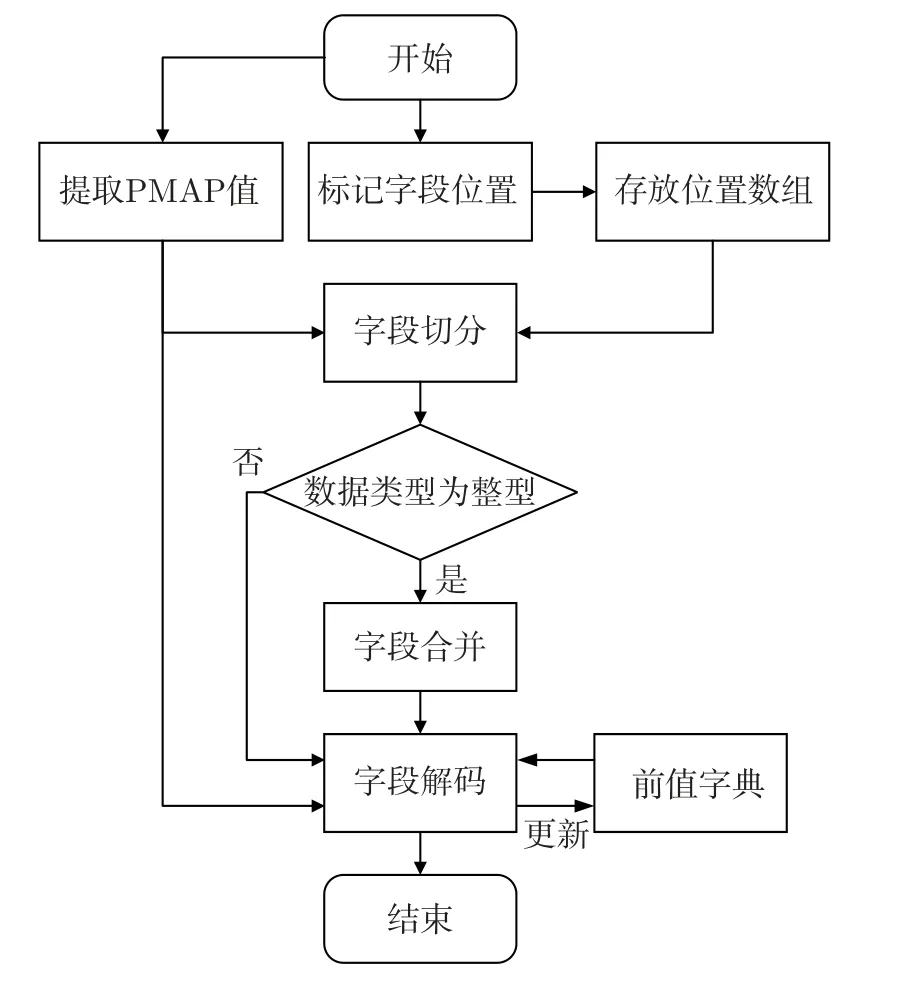
图2 FAST 解码器设计流程图Figure 2 Flowchart of FAST decoder design
2.1 硬件并行优化
2.1.1 切分数组存储映射
针对数据字段的切分,尽管每一个字段的起始和终止位置无耦合,且FAST 数据的特征不定长,但其实际大小始终以8 的整倍数比特在一定的范围内波动,最终根据模板数据类型大小计算汇总单条数据的长度最大为472 bits。为了确保FAST 数据解码器接收数据的完整性,从而减少多次读取产生的延迟抖动,将接口大小设计为512 bits。根据以上特征,采用并行切分的设计思想来降低数据切分的时延,从而提升整体的解码效率。考虑FAST 数据存放在一个数组中,而并行切分需要对数组进行多次的访问,可能会产生访问冲突,这将导致数据读取效率的降低。针对此问题,本文将FAST 数据数组映射到多个存储器,通过提高存储器的访问接口,提高切分的并行度,从而实现解码处理的低延迟。FAST 数组映射切分示意图如图3 所示。
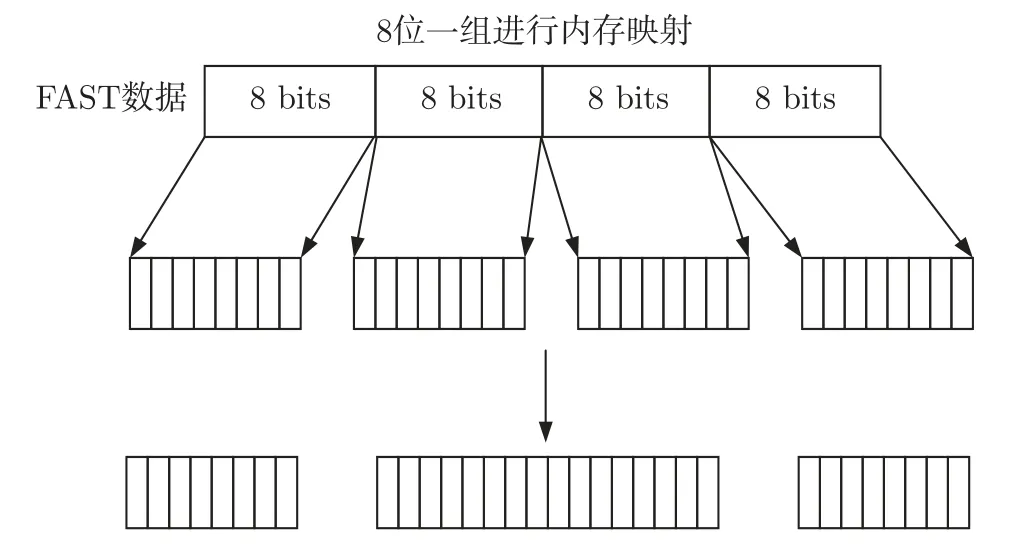
图3 存储映射切分示意图Figure 3 Storage mapping segmentation diagram
2.1.2 单元内核矢量化
并行分割完成的字段数据通过类型判断和合并将最终需要处理的数据送入解码器中。PMAP 值和FAST 操作符的联合判断决定解码器解码是否需要使用特定的FAST 操作符和前值字典。最终,根据解码的结果对前值字典进行更新。FAST 解码单元框架如图4 所示。
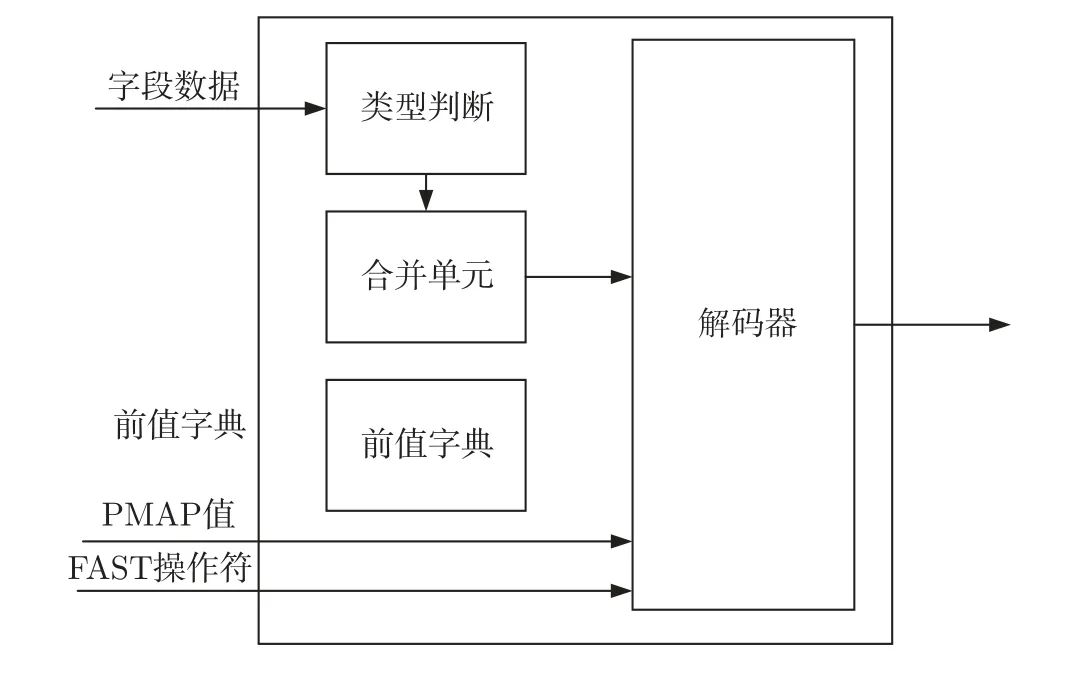
图4 FAST 解码单元框架图Figure 4 Frame diagram of FAST decoding unit
由于FAST 数据各字段的解码过程相互独立,无相关性。根据各字段数据的最大长度,设计接口位宽大小固定为64 bits。由于FAST 单个字段的解码处理所消耗的时钟周期为1∼8 个Cycles。在未采用并行设计的前提下,总消耗为12∼96 个Cycles,产生的延迟抖动较大,不易于解码系统的稳定。通过内核复制矢量化,可以将解码延迟控制在单个字段最大解码延迟上,其解码时钟周期抖动为2∼3 个Cycles。根据FAST 的字段数目,对单元内核矢量化,将FAST 解码单元复制成16 块,实现FAST 字段数据并行解码,从而降低字段解码的延迟和抖动幅度。码单元内核矢量化示意图如图5 所示。
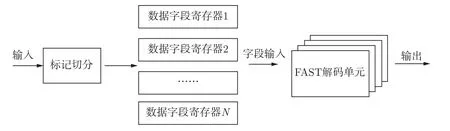
图5 FAST 解码单元内核矢量化示意图Figure 5 Vectorization diagram of FAST decoding unit kernel
2.2 存储优化设计
由于FPGA 硬件资源有限,而解码器设计对标记位和前值字典的存储空间需求较大。同时PMAP 值的存储以及各字段的存储范围跨度较大,这就造成采用传统的存储数据类型会浪费大量的存储空间。根据字段数据特定的范围,定制化地设计存储类型的位宽,从而优化存储空间,提高空间利用率。让更多的计算数据存放在片上SRAM 中,进而发挥片上存储高带宽读写速率的优势,提高传输速度,降低解码延迟[9]。
通过定制化数据类型存储优化[10]可在满足字段存储需求的同时,将存储空间利用率提升1∼2 倍。数据类型存储优化对比如图6 所示。
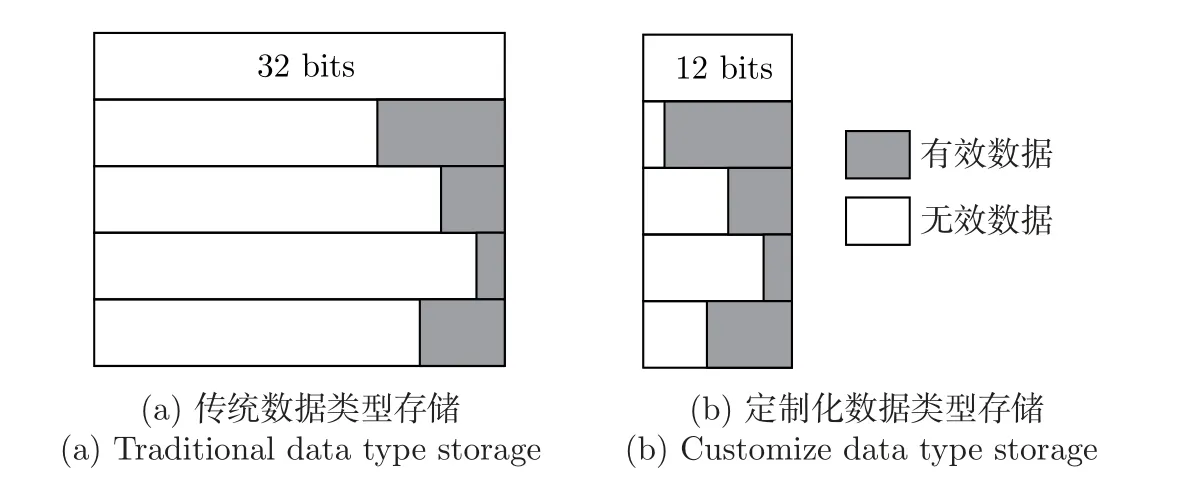
图6 数据类型存储优化对比图Figure 6 Comparison diagram of data type storage optimization
FPGA 的存储资源主要分为片上的SRAM 以及片外的HBM,SRAM 相比HBM 拥有更高的数据读写带宽,但是其存储空间远小于HBM,因此在设计空间存储中,首先将频繁读写的前值字典存放在SRAM 中,通过高带宽的读写速率,降低前值字段更新处理的延迟,从而进一步实现整体的低延迟处理[11]。
2.3 硬件流水设计
考虑到FAST 数据压缩强耦合性和增量传输的特点,不同FAST 数据之间无法做到并行处理,但单条数据各个模块之间的处理没有交叉关联。因此,为了能够确保流水的效率最优,在设计上将总体处理过程细分成多个部分,尽可能使得每一个部分的延迟(Latency)相等。将FAST 解码设计主要分为标记、切分、合并、解码这4 个部分处理,由于4 部分均不涉及复杂运算,处理延迟均为一个时钟周期。同时模块前后呈现单进单出的相关性,即前一个模块的输出作为后一个模块的输入[12],从而能够最优化实现硬件流水设计。流水设计处理对比如图7 所示。
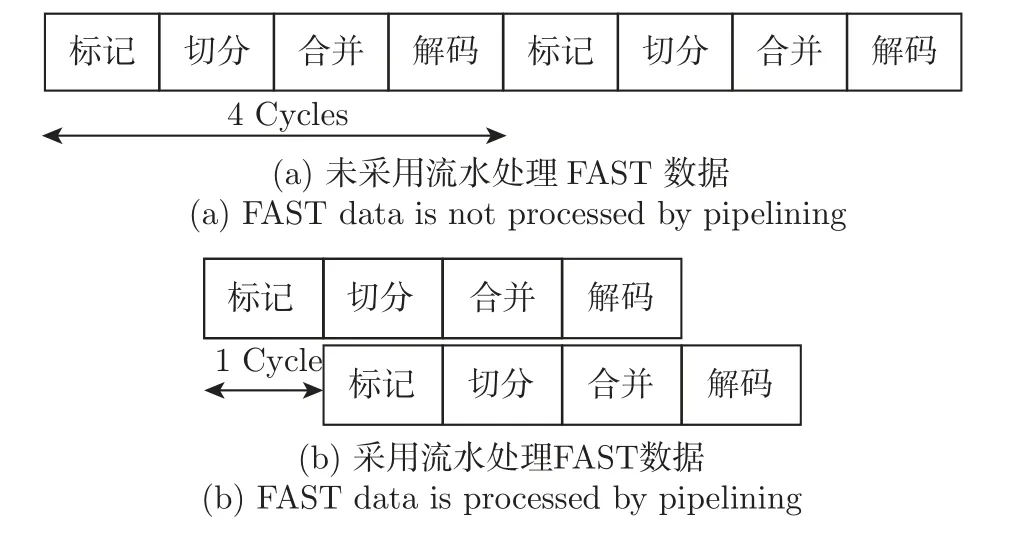
图7 流水设计处理对比图Figure 7 Comparison diagram of flow design treatment
通过流水设计,尽管无法优化降低单条数据的解码延迟。但是针对连续多条数据的处理,可以提高整体处理数据的吞吐量,从而降低总体的解码延迟,提高解码速率。
3 基于OpenCL 的硬件解码器实现
总体框架设计采用OpenCL 和HLS 协同开发的设计方式,基于Vitis 开发平台进行实现。其中OpenCL 负责数据在HOST 端(CPU)和FPGA 端的传输和接口通信工作。FAST解码器整体设计框架如图8 所示。
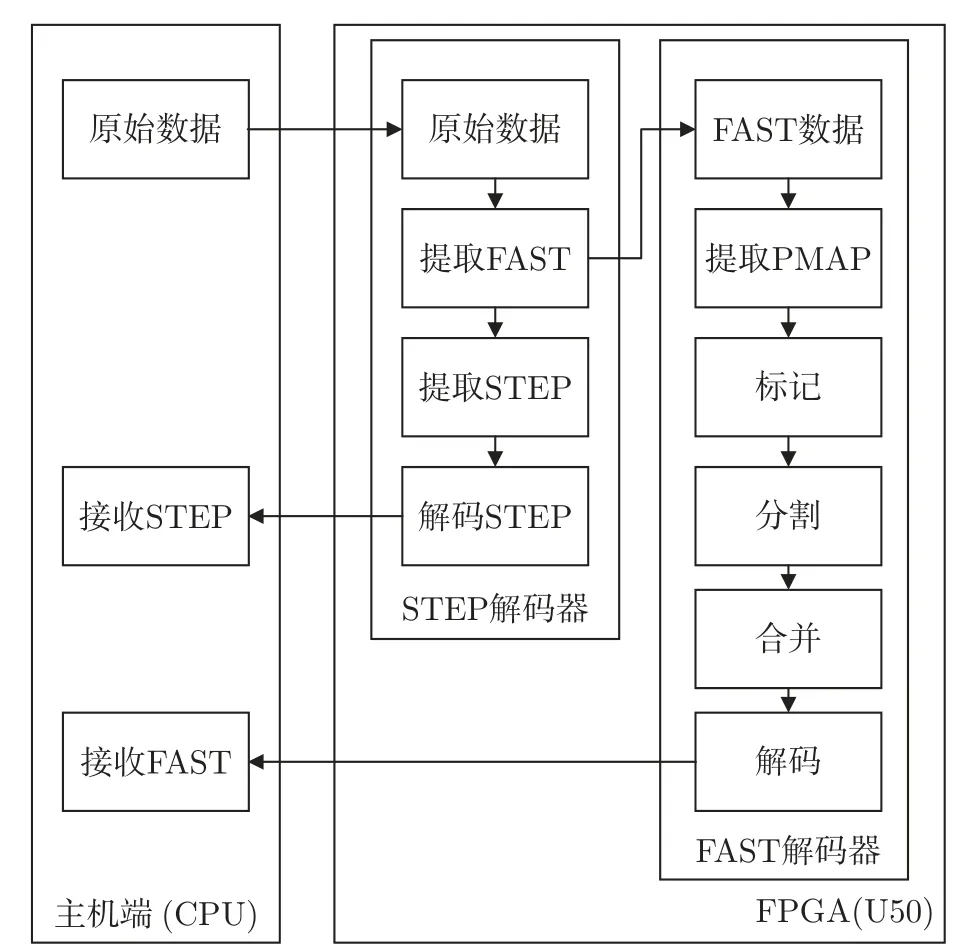
图8 低延迟低抖动FAST 解码器整体设计实现流程Figure 8 Overall design and implementation flow chart of low delay and low jitter FAST decoder
数据接收以后存放在HOST 端的内存上,通过OpenCL 将数据搬运到FPGA 的全局存储器中,再送入相应的计算单元处理完成以后,返回至全局存储器中。处理完成后,通过OpenCL 将数据从全局存储器调回主机端。同时在FPGA 上的数据解码主要分成两块:一块是基于STEP 协议的解码模块,其主要功能是筛选出FAST 数据,并将数据送至FAST 数据解码模块进行解码;另一块是基于FAST 协议的解码模块,其主要功能是将FAST 数据进行标记、字段切分、合并、解码。最终将解码完成的数据返回。
3.1 Vitis 开发平台
Vitis 开发平台集成了Vitis 目标平台,Xilinx RunTime(XRT)库以及Vitis Core 开发套件构成了整个硬件设计的底层框架。其中Vitis 目标平台定义了软硬件的基本框架和应用开发环境,包括外部存储接口,自定义的输入输出接口等。XRT 库主要负责HOST 端和FPGA加速卡之间的通信,包括用户API,内核驱动等。Vitis Core 开发套件则包括了V++程序编译器,性能指标分析器和代码调试器,用以对比分析程序设计优化的性能指标。
实验主要借助Vitis 开发平台V++编译器完成内核与软硬件平台的链接形成可执行的二进制文件(.xclbin),在硬件加速设备上运行。最后借助Vitis 分析器对实验结果延迟和硬件资源占用进行对比和分析。Vitis 平台框架如图9 所示。

图9 Vitis 平台框架图Figure 9 Vitis platform frame diagram
3.2 基于OpenCL 的主机端设计与实现
OpenCL 作为异构并行计算平台编写程序的标准框架,可以将异构计算映射到不同的计算设备上。其优势在于减少手动时序收敛的延时消耗,同时负责FPGA、CPU 以及片外存储器之间的接口通信设计工作[13-14]。
本文主要通过OpenCL 完成CPU 和FPGA 的异构计算设计。首先对于内核镜像的加载首先通过OpenCL 找到工程应用的Alveo U50 加速卡,并为其编号,然后初始化OpenCL 的环境配置和命令队列,接着将设计的FAST 解码内核程序通过PCIE 加载到加速卡中,最后完成FPGA 的编程工作。
对于OpenCL 的内存分配首先申请简单的缓存分配。主要是用以存放FAST 数据的数组,大小为512 bits。另外则是申请解码完成后的数据存放数组,数组大小为12 个int64。然后将分配的缓存映射到OpenCL 缓存对象。接着将主机内存迁移到加速卡中,并设置好内核参数,最后运行内核,等待内核运行完成后,将内核计算的结果传输回主机端内存。基于OpenCL 的主机端设计流程如图10 所示。
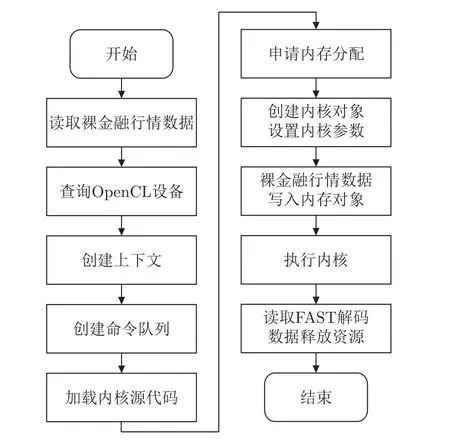
图10 基于OpenCL 的主机端设计流程图Figure 10 OpenCL based host end design flow chart
3.3 基于HLS 的架构实现
3.3.1 FAST 数据输入输出接口优化
通过将FAST 数据输入接口定义成AXI-Stream 类型,编译器会将FIFO 放置在FAST数据输入、输出和解码模块之间,从而不用频繁的在设备之间搬运数据,减少I/O 口的时间消耗。FAST 数据流式接口优化流程如图11 所示。

图11 FAST 数据流式接口优化流程图Figure 11 Flow chart of FAST data flow interface optimization
3.3.2 任意精度的数据类型优化
C 语言传统的整型数据类型字节长度以32 位、64 位为主。在FAST 数据存储设计中,某些字段的最大位宽可能远小于传统的整型数据类型字长,为避免传统的数据类型可能会导致存储空间资源上的浪费,通过引入HLS 任意精度的数据类型进行空间优化,将存储数据类型设置为ap_int
3.3.3 FAST 数据字段切分优化
针对FAST 数据字段数组,HLS 可以通过添加指令将数组作为内存(RAM、ROM、FIFO)来实现。其中,RAM 端口还可以配置端口类型是单端口还是双端口。由于对FAST 数组切分的过程需要频繁的访问数据数组里的元素,端口的数目限制无法满足并行访问设计的需求。通过数组最优化指令重新配置数组结构,根据FAST 数据标志停止位的特点,采用BLOCK切分,将数据每8 位一组进行分割,使FAST 数组分割成多个小的数组,映射到多个寄存器块上。确保在切分操作时,能够在各自数组接口上单独实现,从而提高并行访问的限度。FAST数组BLOCK 切分示意图如图12 所示。
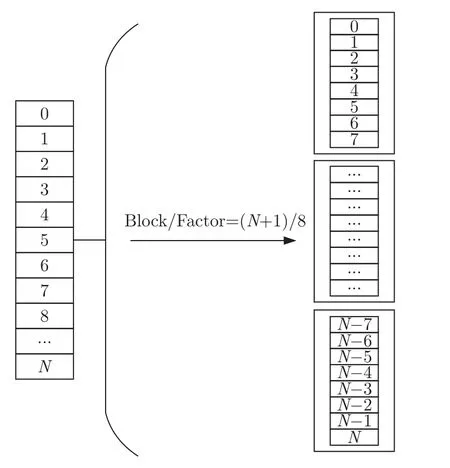
图12 FAST 数组BLOCK 切分示意图Figure 12 BLOCK segmentation schematic of FAST array
其中Block为数组的元素数目,Factor为每一个数据切分块的数组元素数目。Block/Factor的结果即为数组通过切分映射优化后的访问并行度。
3.3.4 解码各模块Dataflow 流水优化
针对硬件流水设计思想的实现,通过HLS 中的Dataflow 流水优化指令来实现。Dataflow优化是在函数与函数之间穿插通道,设置通道的寄存器类型为FIFO,将前一个模块首先处理好的部分数据存放到FIFO 中,供下一个模块处理,使函数模块与模块之间呈递流水的处理过程,以提升解码数据的吞吐量,降低总体解码的延时。Dataflow 对比实现示意图如图13所示。
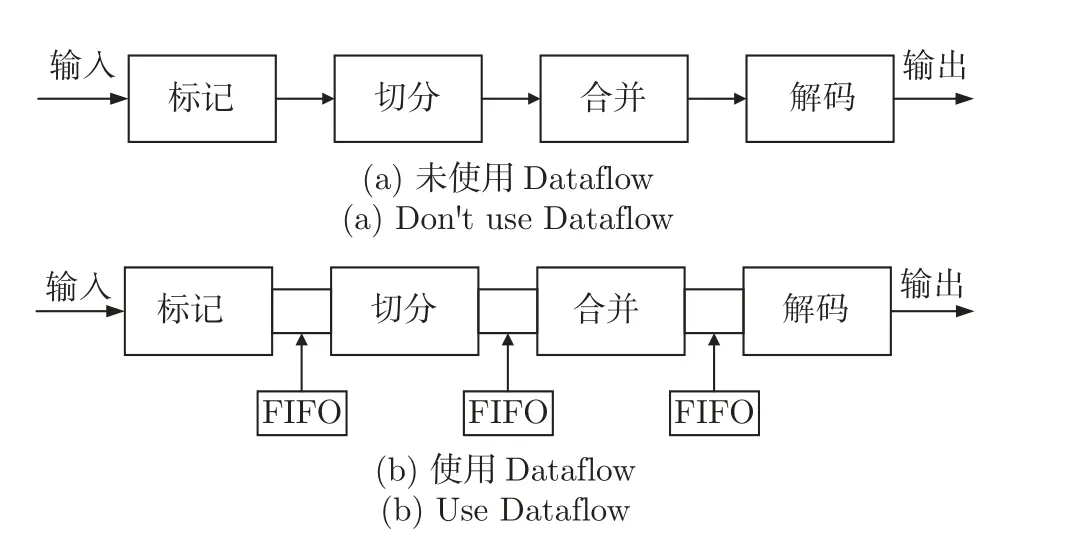
图13 Dataflow 对比实现示意图Figure 13 Dataflow comparison implementation schematic
4 实验结果与分析
4.1 数据来源和环境模拟
实验数据来源是上海证券交易所接收到的Level-2 行情数据。将数据存放成pcap 文件,通过tcpreplay 按照原速率进行数据回放,通过抓取端口的回放数据存放至HOST 端的内存中从而模拟真实上交所行情数据的接收过程。
4.2 平台和软硬件环境
FPGA 硬件测试平台:采用了Xilinx Alveo U50 加速卡,实验工作频率为300 MHz,具备8 G 的HBM 和28 MB 的SRAM 存储。在Xilinx Vitis 2020.1 的开发平台上完成仿真、上板的测试工作,将测试结果通过OpenCL 返回主机端打印验证设计的正确性,并通过平台的分析器分析总体的性能。
对比测试纯软件服务器系统为Centos7,CPU:I9-9900X 10C20T,主频3.5 GHz,由于操作系统的调度问题,数据测试存在延迟波动,采用多次测试取平均的方式对时延进行测试,保证软硬件的测试数据为同一组数据。
4.3 主要资源占比
经过存储优化,FPGA 片上的SRAM 资源足以满足FAST 数据的存储需求。因此,在数据空间定义和分配上,并未采用BRAM 存储,U50 HBM 总带宽为316 GB/s,而内部SRAM总带宽可以达到24 TB/s,合理利用片上存储SRAM 高带宽读写速率的优势,可以有效降低解码时延。此外,合并和解码的工作主要通过位运算实现。因此并没有使用到DSP 资源。主要硬件资源占用如表1 所示。
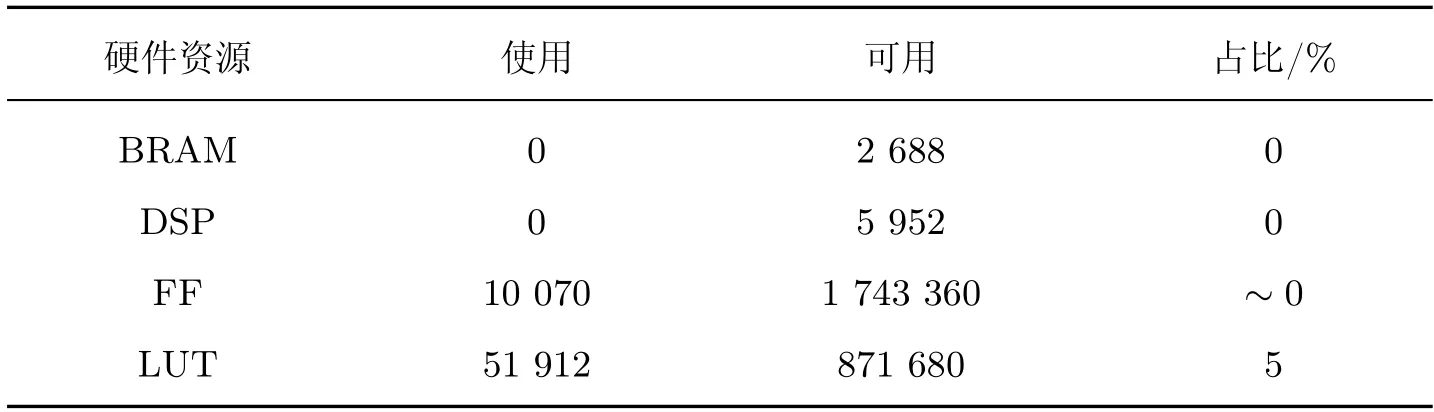
表1 FPGA 主要硬件资源使用Table 1 Usage of main hardware resources of FPGA
4.4 解码延迟抖动性对比
对于同样大小的数据测试解码延迟,横坐标为测试数据编号,纵坐标为解码延迟。由于实际测试数据长度变化以75 个十六进制数字符为基准上下浮动且该长度的样本数量较多,具有一定的代表性,因此测试选用了30 个大小相同的数据,均为75 个十六进制数字符。实验分别测试其在纯软件,硬件不使用Dataflow 优化以及硬件使用Dataflow 优化的解码延迟。因为硬件固有的时钟周期使得在FPGA 上的硬件解码延迟相比软件解码更加稳定。解码抖动延迟控制在10 ns 以内。解码延迟抖动性对比如图14 所示。
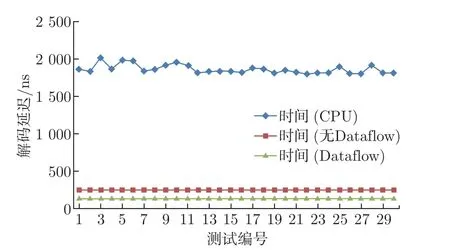
图14 解码延迟抖动性对比图Figure 14 Comparison diagram of decode delay jitter
4.5 解码延迟与数据字段长度关系
由于数据字段的标记和切分所需要的时钟周期与字段的长度有关,因此数据字段长度与解码延迟存在一定的关联性。同时,并行设计将解码优化到单个字段的解码过程,因此单个字段最长解码延迟波动较小。经测试表明,随着字段长度的增加,解码的延迟也会相应的有所提高,但变化浮动较小。解码延迟与数据字段长度关系如图15 所示。
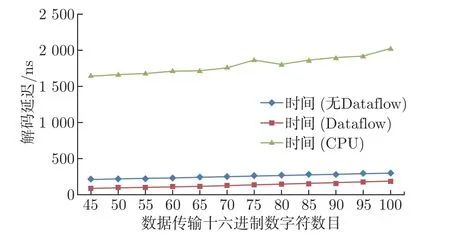
图15 解码延迟与数据字段长度关系图Figure 15 Decoding delay and data field length diagram
4.6 FAST 解码延迟分析对比
由于国内上交所采用的是STEP 嵌套FAST 的编码模式,因此本实验数据对比主要以国内研究为主。相比以往实验研究[15],在相同频率下,通过Dataflow 等优化,在开发周期缩短的同时,FAST 解码速度提升了23.7%。FAST 解码延迟分析比较如表2 所示。
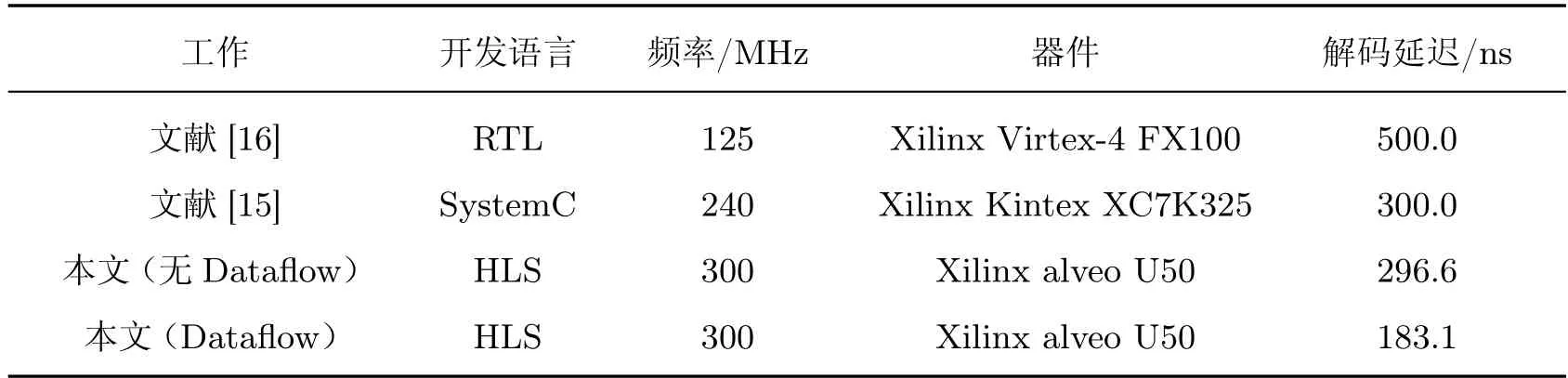
表2 FAST 解码延迟分析比较Table 2 FAST decoding delay analysis and comparison
5 结语
本文提出的FAST 解码器设计主要是针对上海交易所level-2 系统的行情解码,采用了OpenCL 和HLS 协同开发的设计模式。本文基于OpenCL 的框架设计,可以避免底层细节开发。相比于传统的RTL 语言开发,本文实验整体的开发周期缩短至1/3。同时采用HLS 能到高效硬件架构,HLS 优化设计将解码延迟降低至183 ns,抖动延迟控制在10 ns 以内。实验结果表明:OpenCL+HLS 可以得到FAST 行情解码所需要的硬件系统。这种方式能满足计算性能、延迟,同时还能满足快速迭代的需求。FPGA 板卡资源报告显示FAST 数据解码仅占用了极少的资源,平台对后续的交易策略和实时交易过程算法设计有着很大的拓展空间。随着FPGA 板卡的不断迭代以及性能的不断提高,金融行情通过FPGA 高层次综合语言实现业务加速和拓展将会成为未来重要的发展方向。
猜你喜欢
电脑报(2022年13期)2022-04-12
小学生必读(低年级版)(2021年10期)2022-01-18
电子元器件与信息技术(2021年5期)2021-07-27
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
电脑报(2020年24期)2020-07-15
数码世界(2020年5期)2020-06-23
家庭影院技术(2019年8期)2019-12-04
林业调查规划(2017年6期)2017-03-27
计算机时代(2017年2期)2017-03-06
