
基于非平衡问题的高斯混合模型卷积神经网络
2023-12-11 10:08矫桂娥张文俊
应用科学学报 2023年4期
徐 红,矫桂娥,张文俊
1.上海海洋大学信息学院,上海市201306
2.上海建桥学院信息学院,上海市201306
3.上海大学上海电影学院,上海市200072
非平衡问题是在数据集中不同类别分布差异较大,即样本数量多的类为多数类,拥有少量样本的类为少数类,类别分布不平衡的数据集增加了分类任务的难度,但是在分类任务中对于少数类的检测非常的重要。比如银行用户防诈骗检测、医疗疾病诊断、客户流失数据检测、设备故障检测等[1-5]。传统的分类学习器适合类别平衡分布的数据集,在对非平衡数据集分类时,模型会受多数类样本影响导致分类结果向多数类倾斜,从而会有少数类分类错误,但在数据挖掘中少数类的信息价值更高,因此更准确地判别少数类,对于非平衡分类问题的研究非常重要。研究人员对该类问题的解决方法主要有两大主流方法:数据层面和算法层面。
数据层面的方法主要是对原始数据进行重采样[6]和特征处理,改变数据分布状态,在数据预处理阶段降低类别非平衡程度,采样方法主要有欠采样、过采样和融合[7]。欠采样算法主要通过舍弃部分多数类样本,以达到样本类别的平衡;过采样算法根据某些规律生成少数类样本,来解决数据集中的不平衡问题;融合采样方法则融合了欠采样算法和过采样算法,舍弃部分多数类样本,增加少数类样本,进而平衡非平衡样本的分布。这些方法都是在数据层面的调整,让数据在输入分类模型前就实现分布平衡,但这种简单生成新样本的过采样方法在一定程度上会生成噪声样本,非但起不到提高检测少数类精确率的效果,还会对多数类的判别产生混淆影响。算法层面的方法主要有集成方法[8]和代价敏感方法[9],其思路是设计一个特定用于非平衡分类的算法。集成学习思想是将弱学习器组合成一个强学习器,弱学习器之间是否互通又将集成学习划分为Boosting 和Bagging 两类集成学习算法。代价敏感算法是针对传统分类器而提出的一种类似惩罚策略的算法,对于不同类别分类错误赋予不同大小的惩罚来构建分类学习器,一般是少数类分类错误代价更高。
算法层面的改进方法,目的是解决特定非平衡问题,实际应用中有多种特定的非平衡算法,其中卷积神经网络因为其优越的特征提取性能而广泛应用于非平衡问题中。卷积神经网络的发展在计算机视觉、自然语言等领域都取得了较好的成果,卷积神经网络可以用较少的参数获得更好的性能,作为一种高效的数据挖掘方法,许多研究人员将其用于解决非平衡问题。
为解决非平衡问题,在数据预处理阶段对非平衡数据集抽样较多采用过采样的方法,其中经典的过采样方法有SMOTE 等。该类算法的主要特点是依据少数类样本的某些规律生成更多少数类样本,但很多数据集的规律与SMOTE 生成样本所依据的规律并不相关。按照过采样方法生成的样本会有很大概率生成噪声样本,进而影响分类效果降低多数类的正确率。因此,本文在数据预处理阶段提出了一种新的过采样方法EMWRS(expectation-maximum weighted resampling)抽样算法,该方法将高斯混合模型与加权采样算法相结合,通过采样算法对数据进行预处理,降低训练数据集的不平衡程度。高斯混合模型是一种概率密度聚类算法,在预测数据分布概率方面有较好的分类效果。该模型会计算出数据点的分布概率,即归属于哪个单模型,对于数据集中这些样本分布概率表明算法对分类结果的把握程度,考虑到数据的统计特征。高斯混合模型考虑了多数类和少数类原始数据的分布概率,以及其相关统计特征和重叠范围。EMWRS 抽样算法在对原始数据的选择上更加注重少数类的分布特征,抽样较高质量的少数类新样本,本采样算法避免了生成大量噪声样本的弊端,使模型分类效果更好。
1 相关工作
1.1 数据预处理
许多研究成果表明,数据预处理可以有效提高非平衡分类模型的性能。目前数据预处理方法主要是通过改变原始数据分布降低数据类别分布不平衡程度,使用最多的预处理方法是重采样算法,通过对非平衡数据集进行重采样,使得采样后的数据集类别分布平衡。
数据预处理阶段的重采样技术主要包括过采样和欠采样。过采样算法的主要目的是得到更多的少数类样本,以此达到数据分布平衡,但这种简单生成新样本的方式,会使生成的新样本具有很大的不确定性,生成的少数类样本质量不高,极易产生过拟合问题,为了解决这一问题,文献[10] 提出了一种在少数类邻近线性合成新样本的SMOTE 方法,弥补了简单生成新样本的不足,可以避免一定的过拟合情况,但该方法合成的新样本有一定重复性,部分样本会变成噪声样本。因此,研究人员在此基础上将SMOTE 和欠采样方法相结合,对少数类进行SMOTE 进行过采样,在多数类中进行随机欠采样,该方法会过多地生成新的少数类样本,在一定程度上降低样本噪声的影响。文献[11] 提出了Borderline-SMOTE 算法,用边界上的少数类样本来合成新样本,以此改善样本类别分布不平衡的问题。文献[12] 提出了ADASYN(adaptive synthetic sampling) 算法,针对SMOTE 算法盲目生成样本的缺点进行了改进,利用少数类样本的密度分布来计算少数类样本合成样本的数目,让少数类样本合成更多样本平衡数据分布。为解决数据非平衡问题文献[13] 提出了基于样本难聚性为指标对样本加权的采样方法,该方法对数据集中数据依据样本进行加权,在抽样操作中被选中的概率由样本权重决定。
1.2 卷积神经网络中的非平衡问题
卷积神经网络是深度学习中的经典代表算法,在图像、视觉、数据挖掘和自然语言等领域都得到广泛关注[14-16],卷积神经网络具有高效快速提取特征的学习能力,所以在数据挖掘领域也被广泛应用,许多研究学者将其应用于非平衡问题。
卷积神经网络的特征提取能力很强,并且卷积神经网络模型中的参数量也较小,一个卷积神经网络模型集成了特征提取与分类输出两个主要功能块。经典的神经网络模型由数据输入层、特征提取层卷积层、特征池化层、分类全连接层和结果输出层构成。卷积神经网络将输入数据进行特征提取、降维、归一、分类等操作,输出对数据的处理结果,整个训练学习流程都在一个模型中进行。卷积神经网络模型的训练过程是模型在训练数据集中学习最优模型权重的过程。在训练过程中,网络模型以最小的损失函数为目标函数,在不断的训练中更新网络权重使损失函数达到尽可能的小,在处理非平衡问题时,研究人员提出了很多针对卷积神经网络损失函数的改进方法。
较经典方法是代价敏感方法,对少数类和和多数类赋予不同大小的代价,并将类别代价与损失函数结合,该类方法可以有效解决非平衡分类问题。文献[17] 提出了线性指数损失的增量代价敏感学习,文献[18] 提出了一种焦点损失函数,用于解决红细胞形态分类的非平衡问题,文献[19] 还采用重加权方式改进交叉熵损失函数,将对数权重和有效样本权重线性组合为损失函数的权重,并在医学影像中取得了较好的效果。文献[20] 还将过采样方法与代价敏感方法相结合,在数据预处理阶段和神经网络的损失函数都做出和改进用以预测破产数据非平衡问题。
对于非平衡数据分类问题,本文采用的卷积神经网络结构,如图1 所示。在数据预处理中采用EMWRS 抽样算法对原始数据进行采样,神经网络对采样之后降低不平衡度的数据集进行分类,卷积神经网络结合WCELoss 损失函数优化分类模型。
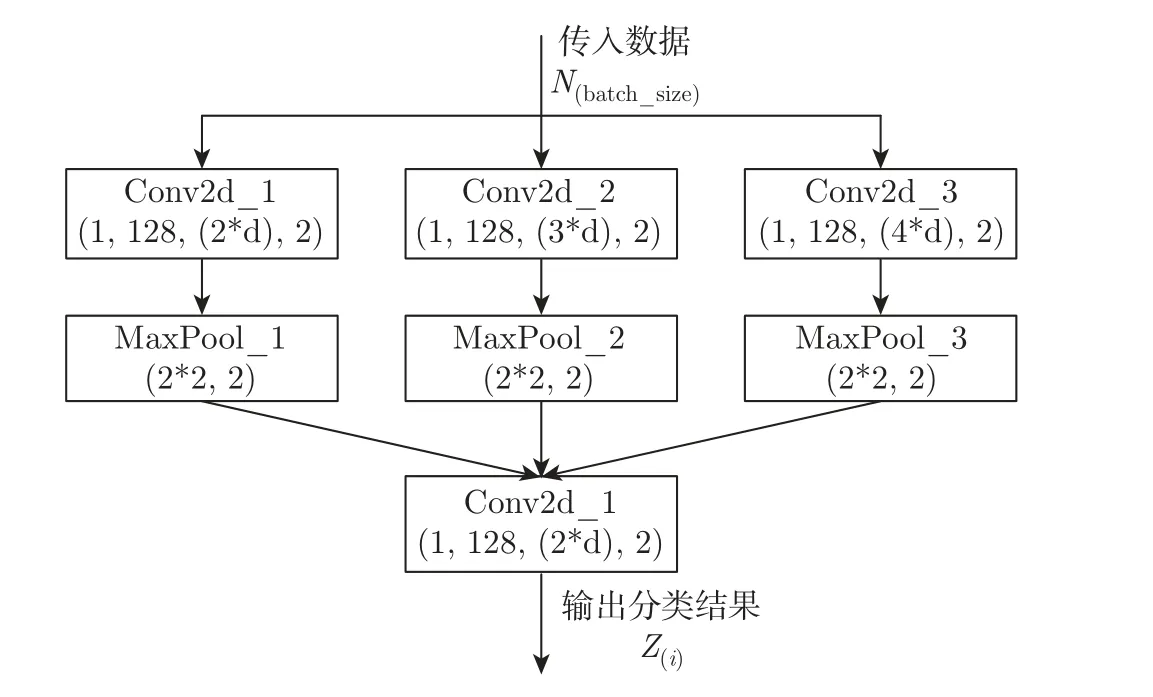
图1 卷积神经网络结构Figure 1 Convolutional neural network structure
从图1 中的结构来看,卷积神经网络卷积组由3 个特征提取的卷积层和特征降维的最大池化层对输入数据处理,经过分类层输出分类结果,模型中激活函数采用线性整流函数(rectified linear unit,ReLU),卷积层由ModuleList 组合而成,并将所需模型参数自动添加到整个网络中。经过卷积神经网络的训练,原始数据损失函数作为衡量模型分类结果和真实标签的差异程度的目标函数,将根据模型对输出的分类结果赋予样本相应的权重损失并反馈给模型,模型依据损失函数进行下一轮训练,以此逐步提高模型对于非平衡数据的分类准确性。
2 高斯混合模型及EM 算法
2.1 高斯混合模型
高斯混合模型是由多个单个高斯模型组成的混合模型,混合模型能够表示数据的总体分布,并且可以拟合任意形状。高斯混合模型具有较好的数学性质和良好的计算性能,实际中的数据集都较复杂,混合模型能够很好地拟合复杂的数据集。
鉴于高斯混合模型的这个优点,本文在数据预处理阶段采用混合模型对数据集进行整体概率分布的拟合。
高斯混合模型是表示多个高斯概率密度函数的统计模型,是高斯分布函数的线性组合,表示为
式中:N(x|µk,Σk) 是高斯混合模型中的第k个高斯分布概率密度函数,数据均值为µk,Σ 为协方差,N是数据维度;δ,µ,Σ 是高斯混合模型中的参数;δk表示样本x从K个高斯分布中选取时,第k个高斯模型的权重,也称为混合系数,其关系为
混合高斯模型的本质是融合多个单高斯模型,使得模型更复杂,从而能够拟合更多数据样本。如果在高斯混合模型中,合理设置单个高斯模型的数量和相互权重,就可以拟合任意形状分布的数据。
假设X=[x1,x2,···,xn]T是n个N维独立分布的数据集,Z=[z1,z2,···,zn]T,zi维样本观测值xi所对应的隐含变量,即随机取一个样本数据点xi归属的类别。
根据高斯混合模型表达式中的概率密度N(x|µk,Σk),k=1,2,···,K,概率分布均值为µk,协方差Σk可知,对于每一个高斯分布来说,其概率密度分布函数为
对于n个N维独立分布的数据集来说,数据X分布服从于N(µ∈RN,Σ∈RN×N),均值为µ(µ=(µ1,µ2,···,µk)),协方差为Σ=E((x-)(x-)T) 且Σ=[Σ1,Σ2,···,Σk],得到X的联合概率密度为
因此对于多元高斯混合模型来说,参数θ=[δ,µ,Σ],高斯混合模型加入了隐含变量,通过样本的联合概率最大来估计模型参数,得到最佳的数据分布,可以尽可能地拟合该样本分布。
2.2 EM 算法
最大期望(expectation-maximization,EM)算法根据各类模型分布和采样数据可以分别采样数据来源类别,并得到各子模型的参数。EM 算法主要有两个功能:一是对每个数据点计算其归属于哪一个单模型的期望;二是更新模型参数,模型最优化对模型计算新一轮迭代的模型参数。
步骤1对一个n个样本的数据集,k个子分部概率模型,计算数据点的归属概率p(x|θ),迭代最优模型参数。对数据点的分布期望计算式为
式中:对θ的求值就是对模型参数的迭代更新,θ(old)是高斯混合模型中参数在EM 算法中上一次的迭代值;γ(Zik) 表示对xi来说由第k个高斯分布生成的概率,也称后验概率,其表达为
步骤2在步骤1 中采用最大似然方法求解模型参数为
步骤2求Q 的极大化,每进行一次迭代,模型参数就进行一次更新,迭代的过程就是参数矫正,最终似然函数达到局部最大,给定迭代停止条件直到算法收敛。
EM 算法是高斯混合模型的一种迭代算法,它是根据每个样本点的概率分布对其进行划分,不同于因距离等因素对数据进行类的传统算法,EM 算法是依据它们归属于哪一类进行划分的,这种分类策略更适用于现实中的复杂数据。
2.3 EMWRS 采样算法
在数据预处理阶段,高斯混合模型将数据集划分为一些最佳混合簇,每个混合簇的单模型概率分布中的数据可能是不同的。在划分结果中数据可能服从于不同的高斯分布,在每个簇中各类样本的概率分布确定多数类和少数类的重叠情况。
根据所得簇内的样本分布结果可以计算相对应样本的权重,本文所用数据集都是二分类非平衡数据集,所以EMWRS 抽样算法暂未考虑多标签的非平衡数据分类的情况,以二分类不平衡公共数据集adult 为例,最佳分类簇为30,统计观察这30 个簇内样本的分布情况,如表1 所示。
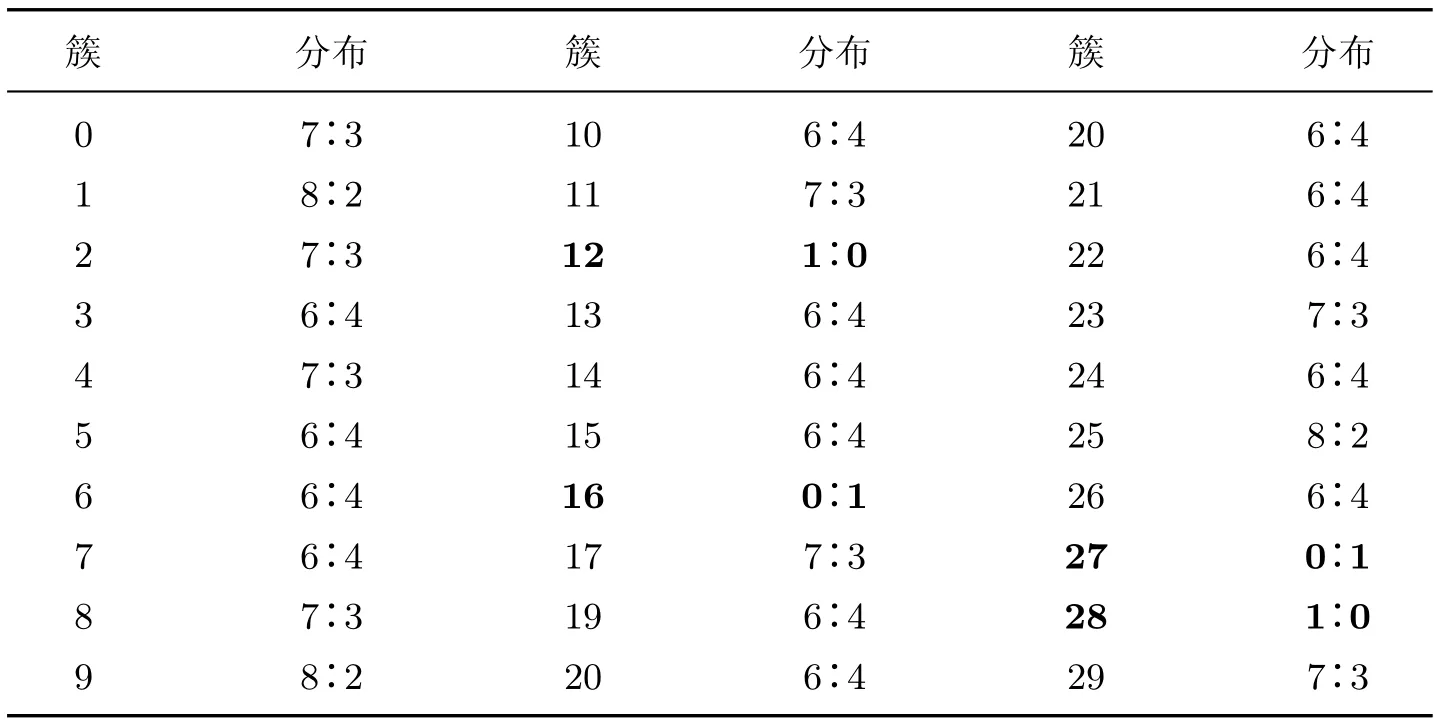
表1 Adult 在高斯混合模型中的聚类结果Table 1 Clustering results of adult in Gaussian mixture model
由表1 可以看出,簇12、16、27、28 中的数据分布极度失衡,在簇内只有一种类别的数据。这样的数据对于模型的分类来说是非常“容易”的,可以把它们理解为软噪声样本,其分类对模型没有起到训练的作用,因此在训练中对它们赋予权重较低,对样本相对不平衡的簇,比如类别比例为8∶2 的簇,样本权重根据类别比例赋予权重,本文所用的数据集都是二分类的非平衡数据,所以权重赋值非常的重要。
利用高斯混合模型求的最佳的聚类簇后,确定每个簇类中各类样本数量的占比βi=,统计类别的比例,然后确定每个类别采样的权重ωi=log0.5βi。在非平衡数据集中,类别权重简单互置的作用并不理想,因此依据实验配置权重比例,根据指数的性质,采用log0.5βi来计算类别权重,当类别失衡越严重时,其相对应的权重越大,当类别趋于平衡时,类别占比接近0.5,那么其相对权重为1∶1,此时类别分布平衡。
传统加权采样方法是从n个样本集中依据样本权重选择m个样本,每个样本被选中的概率由其相对权重决定,样本i被选中的概率为
传统加权采样算法按照顺序采样样本被选中的概率由样本权重唯一决定,该采样方法会造成采样集的失衡,所以本文采用的抽样为步长式加权采样,保证了采样集的合理性。
EMWRS 采样算法是不是顺序采样,而是依据采样步长进行采样,设采样步长之内的所有样本权重之和为Sw,这里的Sw为一个连续的随机变量,服从于指数分布,步长的选择是与Sw总和相对应的随机跳跃,这保证了采样类别的均衡,采样集中设置k值阈值Tw,这里的步长计算公式为Xw=,其中Tw=,α为期望的类别比例,α为0.5,期望类别平衡。样本抽样采用步长式加权采样方法在一定程度上降低了采样算法的时间复杂度,即表示为O(n)→O(mlg(n/m))。
EMWRS 采样算法的流程如下:
最后在采样结果中计算样本密度ρ=Ss/Sd,Ss为采样集S数据中少数类的数量,Sd为S中多数类数量,以此确定采样集S中的数据是否分布平衡。该抽样算法能够有效避免产生噪声样本,在适当的数据区域内对少数类样本重采样。
对于任意的ε ∈[0,1],在样本权重wi>0 时,样本的分布函数FXi(ε) 表示为
其密度函数为fXi(ε)=wiεwi-1
对于每一个vi成为下一个进入采样集S的概率为p,其计算公式为
假设wd,i-1=wd+wd+1+···+wi-1,wd,i=wd+wd+1+···+wi-1+wi,
2.4 WCELoss 损失函数
卷积神经网络的训练与优化过程主要在于最小化损失函数,获得最佳目标函数,使模型性能达到最优。损失函数是描述模型分类结果与真实样本标签差距的函数,常用的二分类损失函数为交叉熵损失函数。但交叉熵损失函数在非平衡分布的数据集中表现并不理想,因此,为解决数据分布不平衡的问题,本文提出了一种结合样本权重的损失函数。
在分类模型中应用最多的交叉熵损失函数(cross entropy loss)[21],一般通用公式为
式中:ti是数据的真实标签;yi是模型的分类结果;交叉熵损失函数就是这两个值之间的差距。
为平衡非平衡数据,样本权重的损失函数对不同类别的样本赋予不同损失权重,在训练集中,,xi表示样本中第i个样本,yi表示xi对应的样本标签,yi ∈{0,1}是样本对应的标签值。在加权采样中添加的权重是依据类别样本在总样本集中所占比例设定的,虽然需要对损失函数添加权重,但添加的权重不宜过大,否则神经网络在训练时会倾向于权重过大的少数类,从而造成模型的过拟合,根据log(x) 对数函数的单调性质可知,自变量x的值越大时,函数的走向越趋于平缓,因此采用log(x) 来计算权值,权重计算公式为
式中,Nk表示的是类别k的样本总数;log 函数的自变量是大于1 的,保证了少数类别的权重不过高导致模型分类失衡。
添加了权重的交叉熵损失函数(weighted cross entropy loss)为
本文的研究为二分类非平衡问题,因此权重取值范围为w=[w1,w2]。本文提出的优化损失函数在公共数据集adult 上的分类效果很好,这也表明本文对损失函数的改进能够解决不平衡数据的分类问题。
3 实验结果与分析
3.1 实验数据集
本文采用公共数据集UCI 数据库中的二分类非平衡数据集:adult 数据集,该数据集是类别分布不平衡的数据集,对于数据集的分类结果也都会受大多数类的影响,将少数类分类错误,所以在本文实验中将adult 不平衡数据集作为模型的验证数据集。
3.2 评价指标
在不平衡数据分类问题中,通常模型会自动忽略少数类别,因而用精确率作为唯一的评价标准,不能较全面地衡量模型的分类性能。所以在保证准确率的前提下,需要格外注意少数类的正确分类,因此召回率这个评价指标就非常重要。研究人员提出了一种对不平衡数据分类非常重要的G-mean 指标,这个指标值直接体现多数类和少数类的召回率,能够较好地评价分类器的性能。为了更全面地评价模型的性能,本文采用混淆矩阵的三级指标F1 调和平均值和G-mean 对模型进行评估。F1 的值可以从整体上反映分类的性能,混淆矩阵如表2 所示,评测指标的计算公式如式(16)∼(17) 所示。
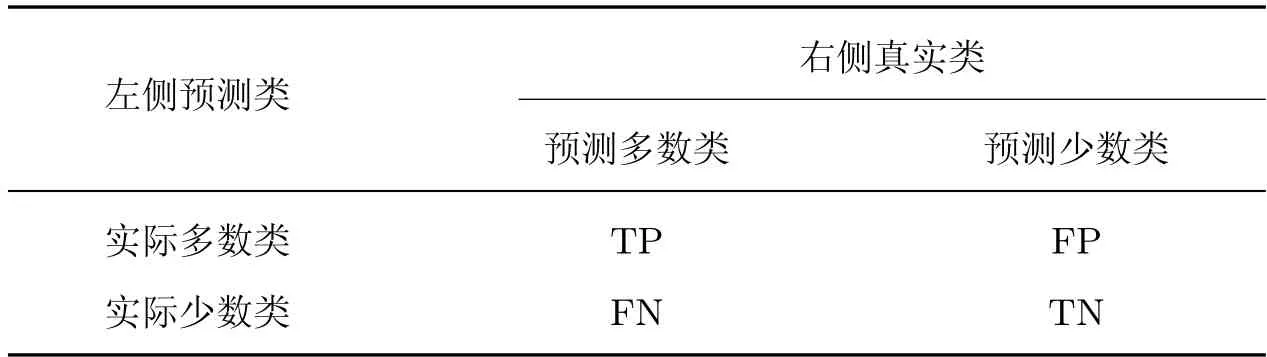
表2 混淆矩阵Table 2 Confusion matrix
式中:Pre 和Rec 是混淆矩阵的二级指标,计算公式为Pre=,Rre=
3.3 实验过程
本文使用的深度学习框架是PyTorch。将实体嵌入层连接在卷积神经网络输入层之前,后面接3 个卷积层和池化层来提取学习特征。为避免模型的过拟合,添加了一个dropout 层,参数为0.5,对特征进行随机丢弃,后面一个全连接层对卷积组得到的特征图进行分类。该模型采用的是Adam(Momentum+Adagrad+RMSProp 的结合)优化器,训练集、验证集和测试集的比例是8∶1∶1,batc_size 设置为512。
EMWRS-WCELoss 算法如下:
算法1数据预处理阶段
输入原始数据集V
输出采样之后的数据集S
对输入的原始数据进行聚类,确定最佳聚类簇数j。依次计算每个聚类簇中的样本分布,根据高斯混合模型所得θk=(µk,σk),k=s,d,计算均值µs与均方差σs,并确定簇类中少数类的样本权重;
对每个分类簇进行统计分析,确定样本权重,并计算采样的数据量;
加权采样算法根据样本权重选取数据,并依据ρ=Ss/Sd统计采样后的数据集分布是否平衡。
算法2采用WCELoss 损失函数训练神经网络
输入预处理之后的数据集S
输出分类结果zi
初始化神经网络模型,按照训练epoch 训练数据集;
根据输出结果统计样本分类正确率,依照类别权重分别赋予不同样本损失,将损失函数反馈到模型中,模型依此调整逐步提高分类准确率。
3.4 实验结果分析
EMWRS-WCELoss 卷积神经网络模型的分类结果,其对比算法主要是基于集成学习算法的数据分类结果。集成学习方法是对结构化数据较常用的方法,在许多数据比赛成果中,获胜方法都会用到集成学习算法。编码方案采用one-hot 编码,本文通过公共数据集adult 来验证本文提出的卷积神经网络模型的分类性能。
用于对比的模型处理的数据都经历过特征工程,本文的对比模型是LR+SMOTE、RF+SMOTE、SVM+SMOTE、XGBoost+SMOTE、LR+BorderlineSMOTE、SVM+BorderlineSMOTE、LR+ADASYN 和SVM+ADASYN。以上模型都是经典的机器学习分类模型,应用范围较广,其中XGBoost 模型采用集成学习的思想,这种通过弱分类器组合得到一个更强的分类器的思想,在很多竞赛中都有应用,分类效果较好;为验证本文所提算法能有效提升对神经网络分类性能,本文设置了对卷积网络的对比,在adult 数据集上,对各采样算法在分类指标F1 和G-mean 上EMWRS-WCELoss 的表现都非常好,其中CNN+SMOTE,CNN+BorderlineSMOTE,CNN+ADASYN,CNN+EMWRS 是本文采样算法结合卷积神经网络模型。在公共数据adult 集上,SMOTE、BorderlineSMOTE 和ADASYN 等算法与本文所提抽样算法的实验结果如表3 所示。
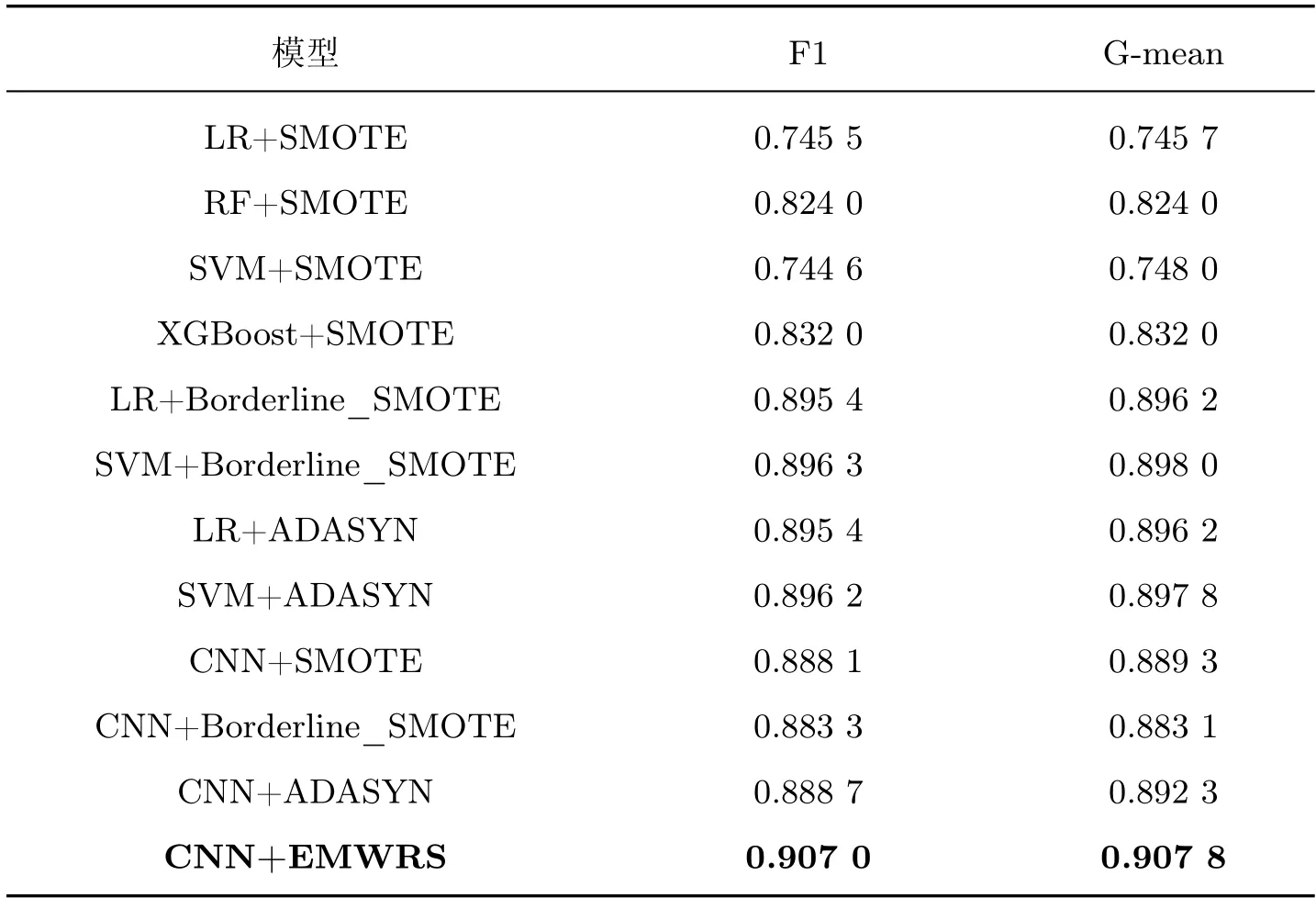
表3 在公共数据集adult 上的实验结果Table 3 Experimental results on the public data set adult
由上述实验结果可知,本文算法在F1 值和G-mean 值均高于其他对比算法。SMOTE、Borderline_SMOTE 和ADASYN 算法都是典型的不平衡数据集采样算法,结合支持向量机和XGBoost 等集成算法,它们在各大赛事的取胜方案中使用频率非常高。由表3 中实验结果对比可知,本文算法相较于以上算法有较大的提升,对于类别分布不平衡数据集的分类准确性有较高提升。在F1 指标上本文所提算法相比其他算法至少提升了1.2%;在G-mean 指标上,也至少提升了1.5%。这也表明,相较于XGBoost 等集成学习算法,卷积神经网络模型效果更佳,因此可以证明卷积神经网络在非平衡问题中的效果。仅对比在卷积神经网络上采样算法的实验结果也可以看出,简单生成少数类的采样方法如SMOTE 算法会产生一些噪声样本,对分类模型产生负面影响,因而降低模型的分类性能。
本文对加权损失函数以及卷积神经网络对非平衡数据的分类效果对比实验,数据集采用adult 公共数据集,在此数据集上的损失函数比较结果如图2 所示,横坐标为训练epoch,随着epoch 的增加,损失函数在逐步降低,在adult 数据集分类中交叉熵损失函数最小值在0.3左右,但WCELoss 损失函数最小值在0.2 左右,除此之外,本文WCELoss 损失函数下降的幅度与速度效果都更好,并逐步趋于稳定,因此加权损失函数能够较好降低模型损失,提升模型的分类性能。
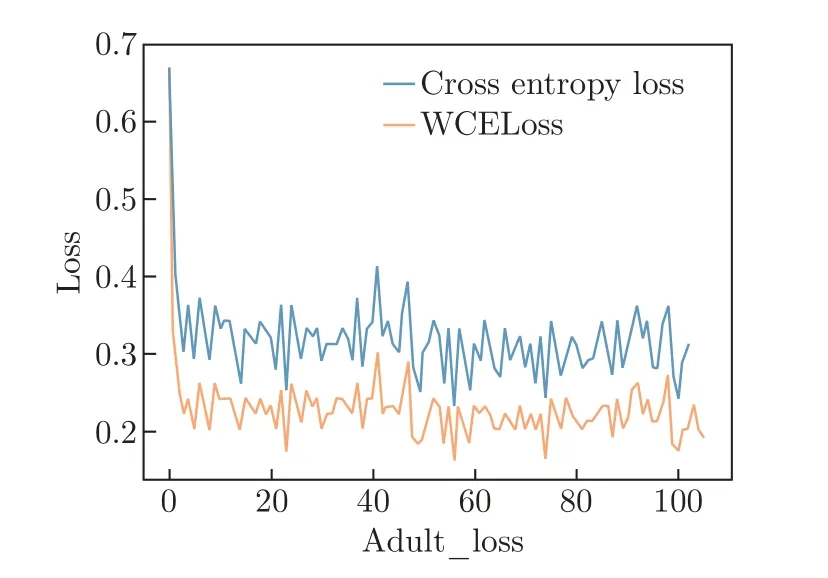
图2 损失函数对比Figure 2 Comparison of loss functions
4 结语
对于非平衡数据集问题,本文提出了EMWRS 算法和WCELoss 损失函数,其中EMWRS算法是基于高斯混合模型和步长采样方法,使采样集内数据达到类别分布平衡。在卷积神经网络分类模型中采用加权损失函数WCELoss,其依据于数据集中的类别权重为模型的分类效果进行反馈。EMWRS 在公共数据集adult 上取得了较好的分类效果,同时实验结果也表明卷积神经网络在数据挖掘和分析中效果也较传统机器学习模型更好,结合EMWRS 抽样算法和样本权重损失函数WCELoss 的卷积神经网络模型可以极大地提升卷积神经网络模型的分类性能,能够较好地分类不平衡数据集。为更进一步提升模型的各项性能,下一步的研究重点让模型在有限数据集中学习到更多的样本特征,进一步提升模型对不平衡数据的分类性能。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年17期)2020-10-28
电子制作(2019年11期)2019-07-04
人大建设(2018年5期)2018-08-16
北京航空航天大学学报(2018年1期)2018-04-20
电信科学(2017年6期)2017-07-01
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
电视技术(2014年19期)2014-03-11
中国中医药现代远程教育(2014年16期)2014-03-01
