
基于颜色通道特征融合的环境声音分类方法
2023-12-11 10:08董绍江夏蒸富方能炜胡小林
应用科学学报 2023年4期
董绍江,夏蒸富,方能炜,邢 镔,胡小林
1.重庆交通大学机电与车辆工程学院,重庆400047 2.重庆工业大数据创新中心有限公司,重庆400707
日常生活中的声音可划分为三大类:环境声音、音乐和语音[1]。智能声音识别(intelligent sound recognition,ISR)与其对应可划分为:环境声音分类(environmental sounds classification,ESC)、音乐信息识别(music information recognition,MIR)和自动语音识别(automatic speech recognition,ASR)。其中,ESC 是监控系统、机器人和自动驾驶汽车等研究领域开发智能应用的关键[2]。
相较于MIR 和ASR 等处理结构化信息(例如语音中的音素,音乐中的旋律),ESC 处理的声音具有变化的时间特性以及频谱特性,结构参数也更复杂。环境声音所具有的上述特点是各种ASR 和MIR 方法无法准确对环境声音进行分类的主要原因。随着人工智能的发展,除了机器学习之外,目前使用深度学习方法进行环境声音分类逐渐成为研究热点。文献[3] 首先将卷积神经网络应用于环境声音识别,使用的声音特征图为对数梅尔频谱图(log-Mel spectrogram,LMS)以及其对应的一阶变量频谱图。文献[4] 采用自监督学习方法进行环境声音分类。文献[5] 研究了声音特征进行拼接所得融合特征的差异。文献[6] 发现在相同维数下用多个特征的准确率优于单个特征。文献[7] 首先在原始音频数据上进行数据增强,然后再将增强后的音频转换为声谱图,使用迁移学习的方法进行训练。文献[8] 将原始音频信号和LMS作为两个不同模型的输入,采用Dempster-Shafer 证据理论融合两个模型的预测结果,得出最终的分类结果。文献[9] 研究了使用不同数据增强进行环境声音分类模型的集成差异。文献[10] 提出了一种基于神经网络提取特征和人工特征组合的城市声音特征。以上方法在环境声音分类方面取得了不错的效果,但都未考虑到环境声音在时频域上特征的复杂性以及传统神经网络提取的复杂环境声音特征微弱,从而导致分类准确率低的问题。
综上,本文提出一种基于颜色通道特征融合的环境声音识别方法,融合环境声音的不同时频域特征,增强表征环境声音能力,提高环境声音分类准确率。该方法首先提取出3 种声音特征:梅尔倒谱系数(Mel-scale frequency cepstral coefficients,MFCC)、LMS 以及能量谱图(energy spectrum,ES);然后分别将以上三者作为RGB 颜色通道分量进行特征融合;其次,对预训练模型VGG-16[11]采用微调方法进行训练;再次,在两个广泛使用的环境声音分类数据集和实际场景采集的音频上验证本文所提方法的有效性。
1 基于颜色通道特征融合的环境声音分类
1.1 预处理及特征提取
为保证数据集中音频的完整性,本文没有消除无声片段。同时,为保留更多的高频信息,也没有降低采样频率,采样频率保持为44.1 kHz。同时,本文对音频进行分帧处理,每个帧包含1 024 个采样点,使用汉明窗口,其窗口长度为1 024 个采样点(23 ms),帧重叠率为50%。使用快速傅里叶变换,经过式(1) 运算得到能量谱图,即
式中:xw(n) 为经过加窗的信号;N为傅里叶变换的点数。
然后,将ES 输入梅尔滤波器组,从而达到模拟人耳对声音频谱的非线性响应效果。随后,对其采用对数运算得到LMS,采用对数变换可以更好地区分频谱中的高低频部分。梅尔滤波器是一组特殊的三角滤波器,假设第m个三角滤波器的中心频率为f(m),则相邻滤波器的间隔随着m值增大而增大,而响应值减小。三角滤波的频率响应定义为
式中:ln(·) 为以e 为底的对数变换;ES 为能量谱图;Hm(k) 为梅尔滤波器。将离散余弦变换(discrete cosine transform,DCT)作用到LMS 即可得到
式中:L为倒谱系数阶数;n为第n阶倒谱系数;M为滤波器数量。本文所选梅尔滤波器以及MFCC 滤波器数量均为128。经过上述预处理以及特征提取后,所得ES、LMS 以及MFCC特征维度均为128×431(频率× 时间)。
1.2 颜色通道融合
图像的颜色通道数取决于颜色空间,例如CMYK 图像具有4 个颜色通道,RGB 图像具有3 个颜色通道,灰度图像只有1 个颜色通道。彩色图片是由颜色空间内不同颜色通道构成的。本文采用RGB 颜色空间表征彩色图像,颜色通道深度为8 位,即取值范围为[0,255],也就是将ES、LMS 以及MFCC 特征取值范围量化到[0,255],方便后续进行颜色通道融合。本文以ESC-10 数据集[13]中的clock tick 类别中1-57163-A-38.wav 样本为例,展示本文所提颜色通道融合的具体过程。
将ES、LMS 以及MFCC 特征分别作为R、G、B 通道时的效果如图1 所示。

图1 采用不同特征分别作为RGB 颜色通道分量Figure 1 Different features are used as RGB color channel components respectively
对以上颜色通道分量进行融合获得RGB 彩色特征图。对于分辨率均为m×n的RGB 颜色通道分量特征图可表示为
式中:rij、gij、bij分别表示R、G、B 通道分量特征图在第i行第j列位置处像素值,其中i在区间[1,m] 内,j在区间[1,n],且rij、gij、bij均在[0,255] 范围内。
在第i行第j列位置处进行颜色通道融合后的最终值aij可采用式(8)∼(9) 计算
式中:rij、gij、bij分别表示取自不同特征图的RGB 颜色通道的10 进制值;表示将原始十进制的颜色数值转换为16 进制所对应的10 进制的颜色数值;Dec2Hex(·) 表示十进制转换十六进制操作。
若三通道分量均来自于同一特征,则进行RGB 颜色通道融合后特征图如图2 所示。

图2 来自同一特征RGB 通道分量融合所得特征图Figure 2 Feature maps obtained from the fusion of the same feature RGB channel components
若采用不同特征对应的颜色通道进行融合,来形成能够更加充分表征环境声音的特征图,可以得到6 种全新特征图,如图3 所示。

图3 来自不同特征RGB 通道分量融合所得特征图Figure 3 Feature maps obtained from the fusion of different feature RGB channel components
本文采用“X[R]-Y[G]-Z[B]”样式用来区分表示彩色声谱图的具体组成部分。[ ] 中的字母R、G、B 分别表示红色通道、绿色通道以及蓝色通道。X、Y、Z 则表示不同特征。X[R] 则表示红色通道分量来自于X 特征。因此,图3(a) 文字说明“M[R]-L[G]-E[B]”则表示该彩色声谱图的红色通道分量来自于MFCC,绿色通道分量来自于LMS,蓝色通道分量来自于ES。由图3 可知,经过颜色通道特征融合后的声谱图,从视觉直观上来看,会出现增强或削弱某些特征的情况。例如,图3(c) 相比于其他特征融合的声谱图,特征存在明显削弱现象。
值得注意的是,经过特征提取后的声谱图特征尺寸为128×431,在进行颜色通道融合时,n和m分别为431 和128。然而,VGG-16 模型输入图片尺寸为224×224,所以将其输入神经网络进行训练之前,需要对特征图进行尺寸变换。图像尺寸变化时常用的插值算法主要有最近邻插值、双线性插值、双三次插值和兰索斯插值。以上插值方法中,兰索斯插值、双三次插值、双线性插值、最近邻插值分别采用规模大小为8×8、4×4、2×2、1×1 的像素块施以权重来近似。所采用的像素块越大,插值输出的像素值就会越平滑、越细腻。综上,本文采用兰索斯插值法将图像尺寸大小进行变换,使尺寸为128×431 的特征图大小变为224×224,满足VGG-16 的输入要求。
1.3 本文模型
本文采用的预训练模型为VGG-16,除了自定义全连接层和分类层外,其余初始参数均与已在大型数据集ImageNet 训练过的VGG-16 参数相同。原始VGG-16 是一种深度卷积神经网络模型,由13 层卷积层与3 层全连接层组成,16 表示其深度。本文模型结构如图4 所示。
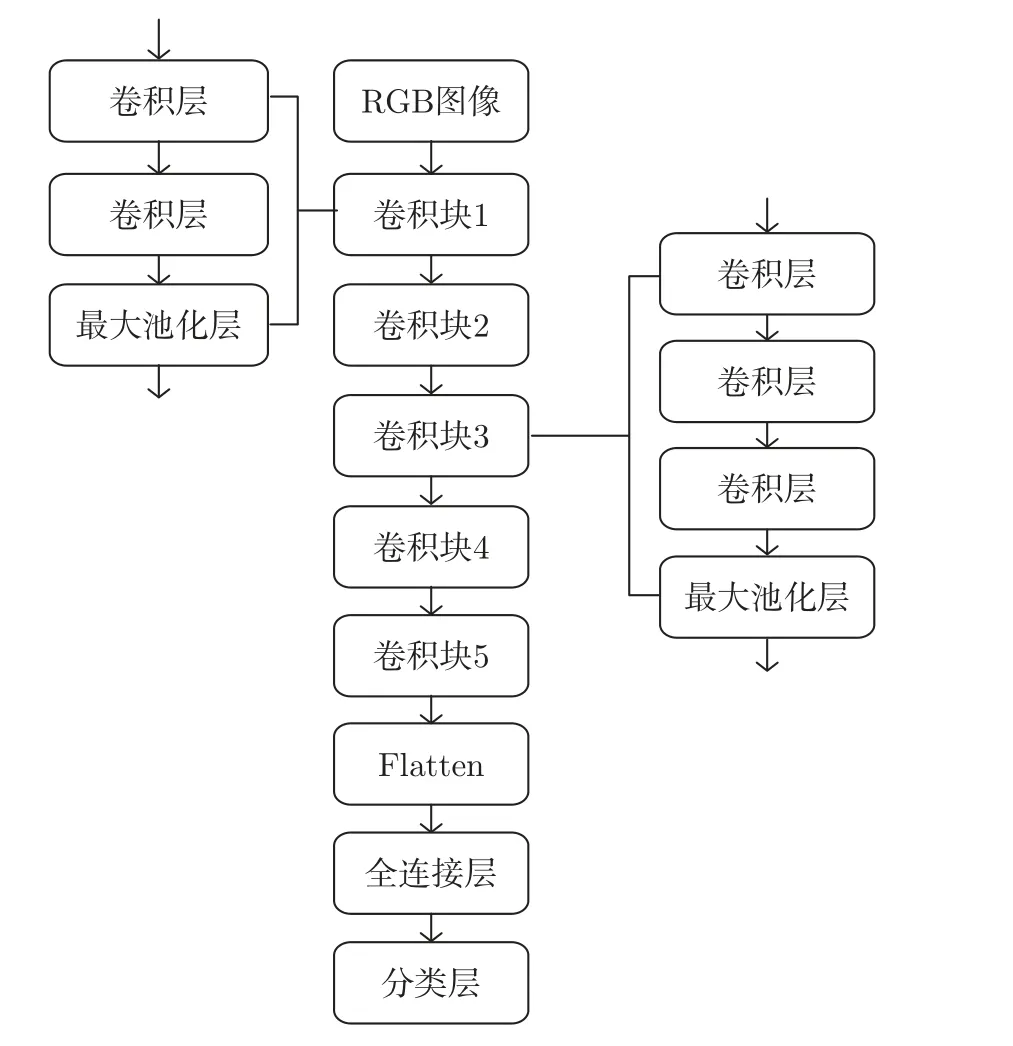
图4 密集连接层经过改进的VGG-16Figure 4 Dense connection layer modified VGG-16
图4 中RGB 图像的输入尺寸为224×224;卷积块1 和2 具有相同的网络结构,卷积核的数量分别为64 和128,卷积核大小均为3×3,最大池化层的尺寸为(2,2),步长为(2,2);卷积块3、4、5 具有相同的网络结构,卷积核的数量分别为256、512、512,卷积核大小均为3×3,最大池化层的尺寸为(2,2),步长为(2,2);全连接层参数为256;分类层参数与所需分类数对应。除分类层的激活函数为Softmax,其他层的激活函数均为整流线性单元(rectifier linear unit,ReLU)。
1.4 微调模型
预训练模型是已在大型数据集训练好的模型,并且取得了不错的效果。为了避免由于数据集较少导致所训练的模型泛化能力较差,本文采用微调方法训练模型。首先,训练自定义密集连接层参数,如图5 所示。
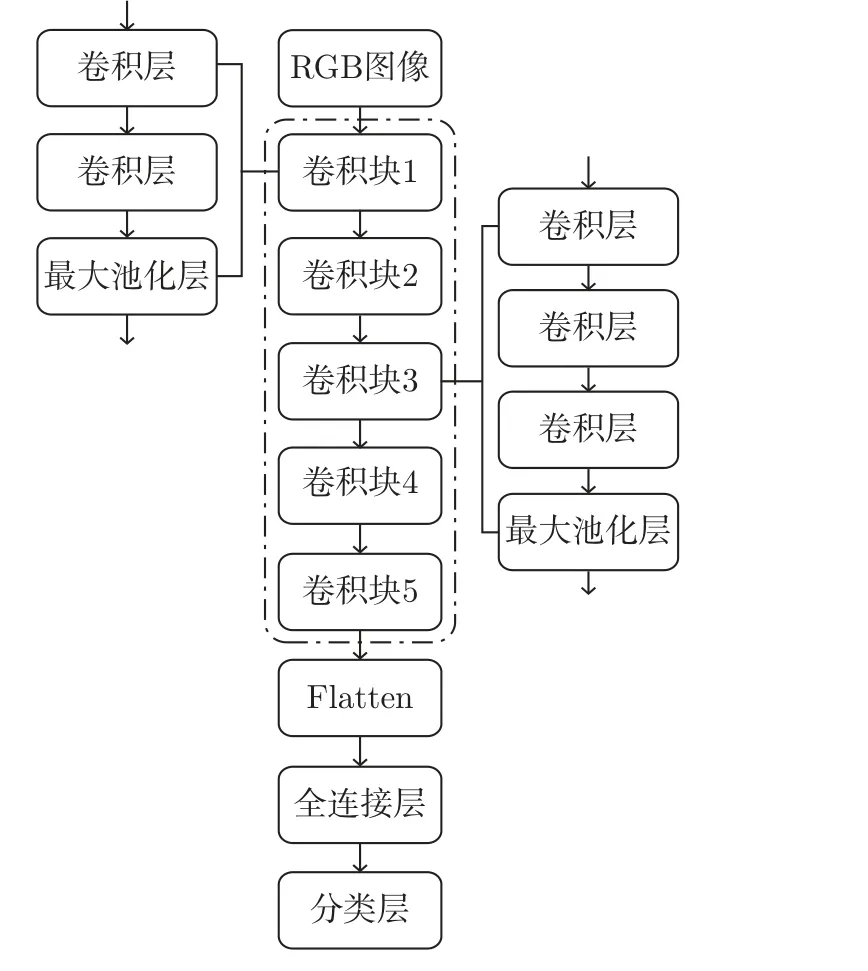
图5 训练自定义全连接层参数Figure 5 Train custom full connection layer parameters
微调模型的原理是在预训练模型的基础上,略微调整靠近模型后端的网络参数,使得最终所提取的特征与待解决的问题相关。因为模型中靠近输入端的网络层提取的是通用特征,远离输入端的网络层提取的是差异度较高的特征。
由图5 可知,“冻结”预训练VGG-16 模型所有权重参数,即保持虚线框中所包含模块权重参数不变,使自定义的密集连接层的权重参数得到训练。随后,将第5 个卷积块进行“解冻”,即固有参数能经过训练进行调整,但依旧固定前4 个卷积块的参数,如图6 所示。
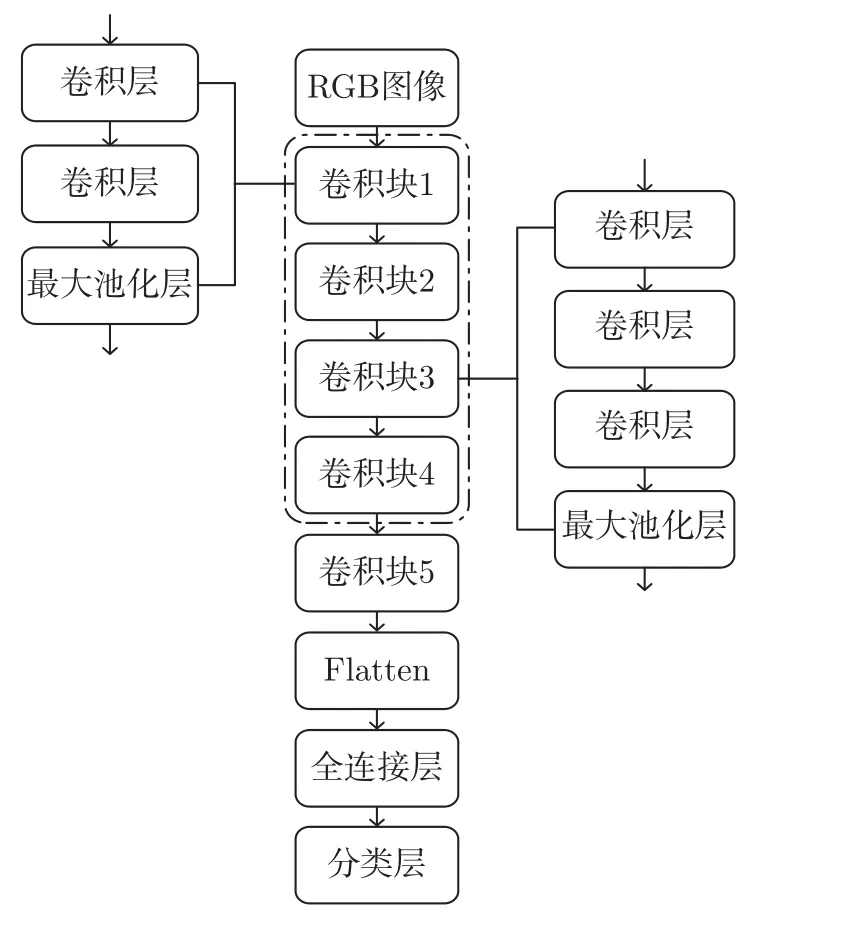
图6 微调卷积块5 以及自定义全连接层参数Figure 6 Fine tuning convolution block 5 and custom full connection layer parameters
2 实验结果与分析
2.1 数据集
本文选取广泛使用的ESC-10 和ESC-50[12]公开数据集作为研究对象,所提方法进行验证使用的ESC 数据集规模大小如表1 所示。

表1 所使用ESC 数据集规模Table 1 Size of the ESC dataset used
ESC-50 数据集共包含2 000 条环境声音音频,总类别数为50,每个类别包含40 条音频,可大致划分为5 大类别:动物鸣叫声、流水声、自然环境声、人类非交流声以及室内室外声。所有音频长度为5 s,采样频率为44.1 kHz。
ESC-10 数据集共包含400 条环境声音音频,是ESC-50 数据集的子集,其音频数据均从ESC-50 数据集中获得,总类别数为10,每个类别包含40 条音频。具体类别包括狗叫声、雨声、海浪声、婴儿哭声、时钟声、人打鼾声、直升机飞行声、电锯声、公鸡打鸣声以及火焰燃烧声。
2.2 参数设置
采用基于Python-Tensorflow-2.1 版本的深度学习框架,编程语言版本为Python3.7,操作系统为Window10。硬件环境为英伟达显卡RTX2080,显存为8 G,CPU 为英特尔i9-10900。为保持音频的完整性,没有去掉音频中无声部分,并且为保留更多高频信息,也没有进行下采样操作,采样频率依旧为44.1 kHz。在第1 次训练阶段,优化器采用Adam,初始学习率设置为0.001,损失函数采用交叉熵损失函数,训练轮数为50。第2 次微调阶段,将优化器更换为RMSprop,学习率改为0.000 01,避免参数波动较大,训练轮数仍为50。所有图片在输入模型之前均进行了归一化,确保颜色值属于[0,1] 范围内。
同时,为避免由训练数据少导致的过拟合问题,使用了在线增强,即在训练模型的同时,对图像进行拉伸、旋转、剪切等变换,增加训练数据的多样性。本文所设置的在线数据增强参数如表2 所示。以dog 类别中的3-144028-A-0.wav 音频样本,所对应的E[R]-L[G]-M[B] 颜色通道融合声谱图举例,采用数据增强方法的前后效果对比可见图7 所示。

表2 在线数据增强参数Table 2 Online data enhancement parameters

图7 在线数据增强可视化Figure 7 Online data enhancement visualization
2.3 实验结果与分析
本文采用数据集已预先划分好的5 个部分进行交叉验证,取5 次测试集准确率的平均值作为模型的最终结果。首先,分别使用数据集ESC-10 里的单个特征声谱图训练模型,所得准确率如表3 所示。
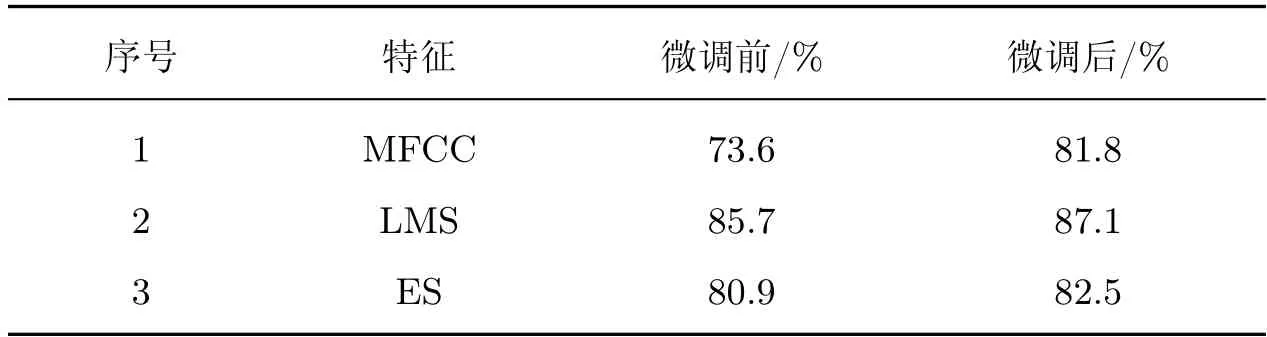
表3 单个特征微调前后模型准确率对比Table 3 Comparison of model accuracy using single feature before and after fine-tuning
由表3 可知,不同特征对环境声音表达效果有差异。对于本文模型,用单个特征进行训练时,LMS 效果最好,并且用微调均能够提升预训练网络准确率。用数据集ESC-10 探索不同颜色通道融合特征的有效性以及差异,具体结果如表4 所示。
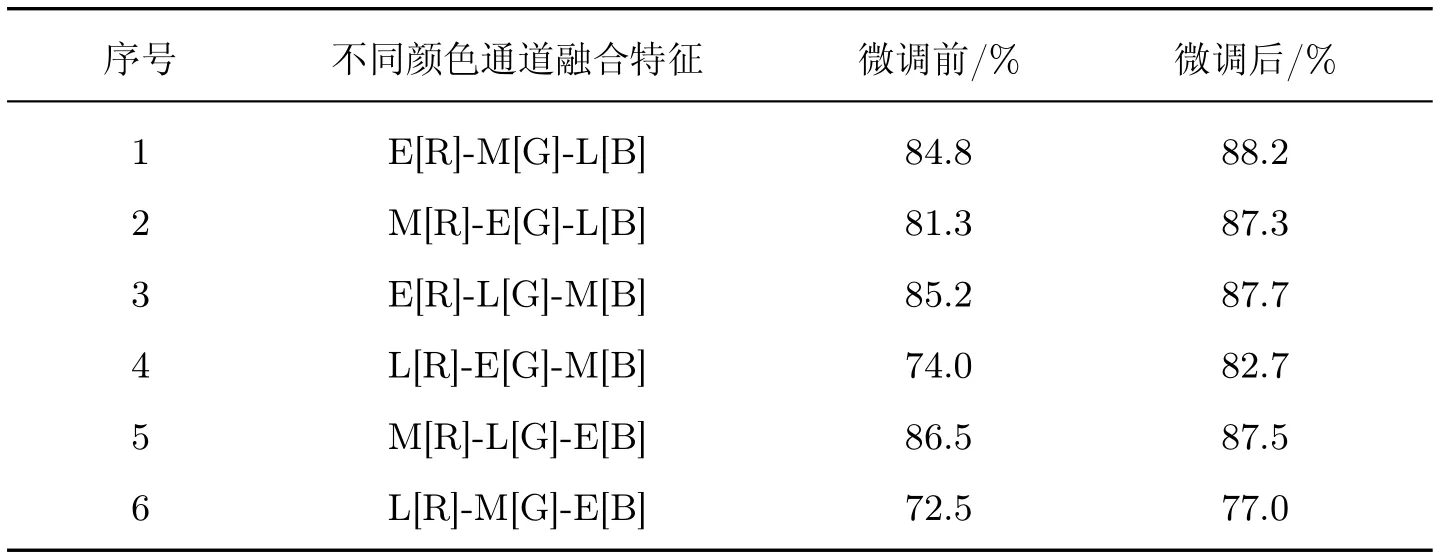
表4 不同颜色通道融合特征微调前后模型准确率对比Table 4 Comparison of model accuracy before and after fine-tuning of fusion features of different color channels
由表4 和3 的对比可知,并非所有颜色通道融合特征都能够有效提升环境声音识别效果,有些融合特征甚至还不如仅仅用单一特征的效果好。例如表4 中的序号1 的融合特征能够增强环境声音特征,而表4 中的序号6 融合特征却起着相反的效果。这表明颜色通道融合特征存在既能增强也能削弱环境声音特征表达的情况,关键在于如何选取正确的融合方式。
另外,本文选取在ESC-10 数据集上进行微调后融合效果最好的组合方式,即表4 中序号1 的融合特征,使用相同的方法在ESC-50 数据集上进行测试,并与现有一些方法的准确率进行对比,结果如表5 所示。
由表5 可知,对深度学习模型与传统的机器学习模型在环境声音数据集上的性能分析,可从数据集样本数量和种类较少以及数据集样本数量和种类较多两方面进行。在处理样本数量和种类较少的环境声音数据集时,K 最邻近算法(K-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)、Random Forest 这些较传统的机器学习模型与深度学习模型差异并不是特别大,例如KNN 与Piczak CNN 相比,其准确率减小了13.8%;甚至机器学习模型能比深度学习模型性能更好一点,例如KNN 与Google Net 相比,其准确率还高出了3.5%。其主要原因在于,当仅使用样本数量和种类较少的数据集训练模型时,传统的机器学习模型由于具有参数较少的特点,所训练出来的模型具有鲁棒性,而深度学习模型参数较多,其所训练出来的模型一般会过拟合,鲁棒性较差。在处理样本数量和种类较多的环境声音数据集时,较传统的机器学习模型与深度学习模型差异就体现出来了,例如KNN 与Alex Net 相比,其准确率减小了46.4%,并且此时基本没有出现机器学习模型比深度学习模型性能好的情况。其主要原因在于,当仅使用样本数量和种类较多的数据集训练模型时,传统的机器学习模型由于具有参数较少的特点,所训练出来的模型一般会欠拟合,即对数据集的拟合度不高,而深度学习模型参数较多,具备对复杂问题进行有效建模的能力。
本文所提方法在数据集ESC-10 上的最高准确率为88.2%,准确率明显有提升,但在数据集ESC-50 上的准确率为65.2%,提升效果较小,这可能与预训练模型VGG-16 所提取特征并不能完全适用于环境声音识别有关。毕竟训练好的图像识别领域的VGG-16 模型参数并不能完全适用于环境声音识别。详细来说,训练VGG-16 模型的ImageNet 数据集的同种类别可抽象出通用特征,例如飞机类别具有机翼和尾翼,汽车类别具有4 个轮子等。然而环境声音并无规律可言,即不能抽象出通用特征。人类对于数据集ESC-10 以及ESC-50 的识别准确率分别约为95.7%、81.3%。可见,使用深度学习的方法提升环境声音分类准确率还具有很大的提升空间。本文模型在数据集ESC-50 上的混淆矩阵如图8 所示。
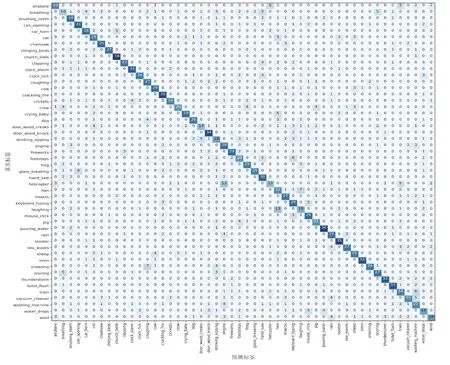
图8 本文模型在数据集ESC-50 上的混淆矩阵Figure 8 Confusion matrix of the model in this paper on the ESC-50 dataset
由图8 可知,本文模型对church bells、clock tick、cracking fire、door wood knock、pouring water、rooster 类的识别准确率为80%(32/40)及以上。本文模型对church bells 类的识别准确率最好,为95%(38/40);其次是pouring water 类,其识别准确率为90%(36/40);紧随其后的是cracking fire 类和rooster 类,两者的识别准确率均为87.5%(35/40)。然而,本文模型对breathing 类识别准确率最差,为25%(10/40),有12.5%(5/40)的breathing 类分别被误分类为snoring 类以及hand saw 类;其次是helicopter 类,其识别准确率为32.5%(13/40),有30%(12/40)的helicopter 类被误分类为engine 类;紧随其后的是door wood creaks 类,其识别准确率为35%(14/40),有10%(4/40)的door wood creaks 类被误识别为cat 类。总的来说,在环境声音识别领域,模型对有些音频类型分类准确率高的原因在于其本身特征就具有足够辨识度,而有些类型分类准确率低的主要原因在于某些环境声音场景的时频域特征非常相似,模型无法对此类特征进行有效的分辨。
2.4 实际场景验证
为了更加详细地说明该问题,并验证所提出特征融合方法的有效性,用智能手机自带麦克风对我们身边常见的环境声音进行采集与识别,具体的采集环境声音的场景如图9 所示。

图9 环境声音采集场景Figure 9 Environmental sound collection scenarios
以上每个环境场景都采集了3 段时长均为5 s 的音频,共计12 段环境声音音频片段。分别提取其对数梅尔频谱图以及采用本文方法获得的E[R]-M[G]-L[B] 颜色通道融合特征,选取采集的一段音频进行特征处理后的展示,如图10 所示。随后,使用两者输入训练好的模型进行预测,检验其识别准确率。

图10 主要场景的声谱图示例Figure 10 Main scenarios examples of spectrograms
由测试结果可以发现,若仅采用LMS 特征,能够完全准确地识别下雨声以及键盘敲击声,但飞机声和敲门声分别被误分类为下雨声和鼠标点击声,也就是说采用实际采集的测试集的模型准确率为50.0%(6/12);若采用颜色通道融合特征,除了能够完全准确地识别下雨声和键盘敲击声之外,还能识别出2 段敲门声,即此时的模型测试准确率约为66.7%(8/12)。至于飞机声被误分类为下雨声的原因,从图10(a)∼(c) 的相似性可以看出,两者在时间维度上具有连续性,并且在频域上都具有较大值。至于敲门声被误识别为鼠标点击声的原因同理。为了验证我们的想法,再次实际采集了点击鼠标时发出的声音,提取其LMS 特征,并与敲门声的LMS 特征进行比较,如图11 所示。

图11 鼠标点击采集场景及其LMS 特征图Figure 11 Collection scenario of mouse clicking and its LMS feature map
观察图11(b)∼(c),同样能够发现两者在声谱图上的相似性,即都具有间断跳跃性的峰值。此外,在研究中还发现,若对采集的音频内添加到一定程度的高斯白噪声时,非下雨声类会有非常大的概率被误分类为下雨声,并且从实际听觉感受来讲,确实与淅淅沥沥的下雨声类似。此外,白噪声包含整个人类耳朵可以听到的振动频率,可以帮助人类放松或睡眠。这就是为什么我们在下雨天睡觉时会觉得非常香,以及有些助睡眠手机应用程序会有白噪声模式的原因。
3 结语
本文全面探索了MFCC、LMS、ES 三种声音特征,在采用颜色通道特征融合时所有的情况,得出融合效果最佳特征。结果表明,将LMS 作为蓝色通道,MFCC 作为绿色通道,ES 作为红色通道进行融合,能够得到识别效果最好的颜色通道融合特征,相较于仅使用单个特征的准确率有明显提高。所提方法在ESC-10 和ESC-50 数据集上的准确率分别能够达到88.2%和65.2%,并且能提高实际场景采集的音频分类性能。值得注意的是,本文只是借鉴有关图像识别领域的模型,此类模型对环境声音识别通用性并不是特别高。构建能够对环境声音进行充分表征的特征,并结合环境声音特点,有针对性地构建网络模型对环境声音进行更加高效准确地处理与识别,是我们今后研究的重点。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
少儿科学周刊·儿童版(2015年11期)2015-12-17
