
基于多源数据处理技术的智能学习质量分析方法研究
2023-12-09 02:55朱琪
电子设计工程 2023年23期
朱琪
(西安航空职业技术学院,陕西西安 710089)
近年来,大数据理论与人工智能技术的兴起推动了教育领域的不断革新,教育信息化逐渐成为新的发展趋势。而大学慕课等在线学习平台的兴起与发展,也产生了海量的相关学习数据。如何对这类数据进行挖掘及处理,进而依据这些数据对学生的在线学习质量情况实现分析和研究,是一个需要深入研究的课题[1-3]。
现阶段常见的在线学习质量分析方法主要有三个研究方向:基于传统概率的分析、基于机器学习技术(Machine Learning,ML)的分析与基于深度学习技术(Deep Learning,DL)的分析[4-6]。文中基于深度学习框架,使用TextRank 对线上平台的多源数据集进行文本处理,再将得到的词向量输入至CNN-BiGRU模型中进行行为数据分析,最终实现对学习质量的预测。
1 算法设计
1.1 改进的TextRank文本处理模型
TextRank[7]由PageRank 算法[8]发展而来,是一种基于图排序的文本处理模型。该算法的核心思想是将文本和图进行转换,使文本与图论中的节点相对应。若对应的两个文本数据相似度较高,则认为这两个节点间有一条无向线段,且线段的权值即为句子的相似度。最终将所得到的句子相似度权重进行排序,从而得到关键词。
对于在线学习质量评估而言,学习者发表的评论、提出的问题等均为关键指标,而这些关键指标都是通过文本来实现的。因此使用TextRank 模型对文本进行关键字处理,能够更好地帮助后续模型完成特征学习。
但原始TextRank 算法并未考虑到文本之间的联系,而文段中的文本有其自身的逻辑。因此若将句子的特征与词语进行合理地融合,训练结果便会更加全面、准确。改进后的TextRank 算法流程如图1所示。

图1 改进的TextRank算法流程
TextRank 算法关键处理过程如下所示:
1)相似语句合并去重
首先对文本中的语句进行词向量整理,可将文本看做为词向量集合W={s1,s2,…,si,sj},而si和sj表示文本中的语句。语句相似度可表示为:
式中,wk为语句中的词向量。当Sim(si,sj)>1 时,表明si、sj的相似度高;而当Sim(si,sj)≤1 时,则表明si、sj的相似度较低。
根据上式可对相似语句进行合并,则相似度α的计算公式为:
2)文本语义处理
在中文文本中,词语或句子语义的不同可表现在词出现的位置、标题含义及特殊文本等。通常文本的首句词语更具有重要性,且总结性的话语也较为关键。因此,需赋予这类重点数据更高的权重。
3)文本权重值计算
使用图论(Graph Theory)方法计算句子权重值。假设图中的两顶点关系用w表示,顶点为Vi,指向该顶点的向量用Vi(in)表示,而该顶点指出的向量使用Vi(out)表示,则权重的计算如下所示:
其中,d为概率系数。
4)文本摘要向量获取
根据式(3)获取词向量的权重,作为后续模型的输入数据。
1.2 基于CNN-BiGRU的学习行为特征提取模型
门控循环单元结构(Gate Recurrent Unit,GRU)模型[9-10]是一种基于门结构的时间序列数据训练模型。在工作过程中其能够对参数进行持续递归,并将所有时刻隐藏状态的输出数据全部反馈至数据输入端,从而完成不断的学习。GRU 单元的结构如图2 所示。该单元由更新门zt、重置门rt、相关的记忆单元及隐藏层组成。

图2 GRU单元结构示意图
GRU单元结构相关运算过程如式(4)-(7)所示:
式(4)为重置门rt的输出函数。可见,重置门能对t-1 时刻的隐藏层输出进行控制。其中,Wr和br为函数系数。式(5)表示状态函数,可对记忆单元的状态进行描述。而式(6)为更新门zt的输出函数,且Wz和bz为函数系数。式(7)为最终隐藏层的输出状态。
原始GRU 模型和其他同类型RNN 模型[11-12]相同,均为单向模型。而在学习行为特征提取模型中,除了要了解当前的行为外,还需对过去与后期的行为加以分析。因此,文中使用了双向GRU(BiGRU)模型,其模型结构如图3 所示。

图3 双向GRU模型结构
由图3 可知,该模型是将两层GRU 模型进行结合,并分别处理前向与后向的时间数据。
BiGRU 模型可对行为数据加以分析,但学生的行为数据较为复杂,且受多种情况影响,因此需对各特征赋予权重,再进行关键特征分析,而注意力机制(ATT)能较好地复制特征权重。文中将TextRank模型处理完毕的节点特征数据使用fa与fb来表示,eab表示节点数据之间的关联性,βab表示注意力参数,W为权重系数,则节点数据间关联性的计算可表示为:
而βab的值可由分类器得到,具体计算公式如下:
上文中的TextRank 模型分析了关键性的短语,但GRU 模型的全局性较强,局部特性却较弱。因此,还需加入CNN[13-14]补齐模型的局部特征,同时也可减少注意力机制[15-16]所引入的全局噪音。
CNN 能够利用大小可选的卷积学习词向量的局部特征,而文中采用了临近策略的CNN 模型。其通过计算目标词周围关键词的位置,以增强模型学习的准确性。首先计算关键词的相关性ri,则有:
式中,m为词向量长度,M为预设阈值,i为词向量序号,l为词向量的索引值。最终的特征提取模型如图4 所示。
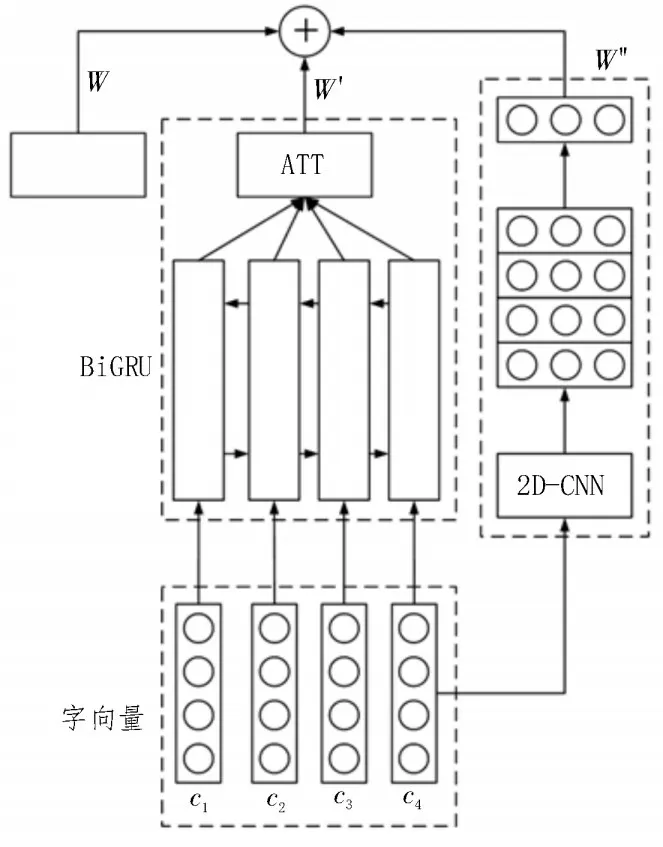
图4 特征提取模型
1.3 基于行为分析的学习质量预测模型
该文的整体系统架构如图5 所示。首先,对线上平台学习者的学习行为及发表的文本信息进行统计;然后,通过模型进行数据分析;最终,便可得到学习者的学习质量预测结果。
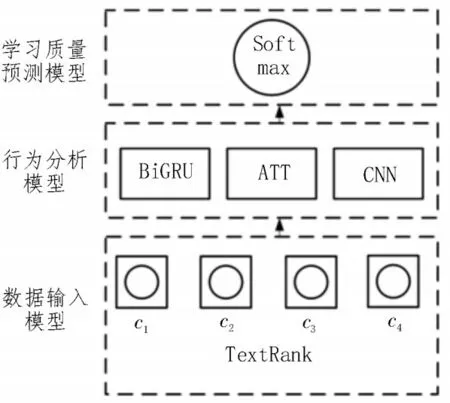
图5 整体系统架构
该模型共有三层结构:1)数据输入模型,在线学习平台获得的信息通过TextRank 模型分解为具有权重值的词向量,该向量值即可作为模型的输入部分;2)行为分析模块,数据输入至CNN 且带有注意力机制的BiGRU 模型中进行训练,以得到行为特征数据;3)学习质量预测模型,训练完毕的数据进入Softmax模型中完成评分,最终即可获得学习质量的评估值。
2 算法测试与结果分析
2.1 实验条件
该文选择某线上教育平台的学习者行为信息作为数据集,并分为理科、工科及文科数据,且在所有课程中均设有讨论区和作业回答区。通过将这些文本进行整理,得到的实验环境与数据集参数如表1所示。

表1 实验环境与数据集参数
2.2 分词性能测试
完成带有情感分析的TextRank 分词算法后,对分词效果进行性能评估。评估指标为双语评估替补(Bilingual Evaluation Understudy,BLEU),该指标可对分词的质量加以评估,且其值越接近1 越好。对比算法则使用词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)、TextCNN 及TextRank 原始算法。各算法所得结果如表2 所示。
由表2 可知,原始TextRank 算法在分词性能上稍逊于其他对比算法。而该文算法由于增加了情感分析与上下文分析算法(Context Analysis),因此其性能有所提高,且相较TextRank 原始算法提升了约0.05,在对比算法中为最优。
2.3 算法性能测试
性能测试首先需进行消融实验,以验证算法改进后的效果。对比算法使用了GRU、BiGRU 和BiGRUATT,同时采用了与上文一致的数据集及运行环境,测试指标则选择了精确率及F1 值。实验结果如表3所示。
从表3 中可以看到,该文提出的CNN-BiGRU 模型在数据集的训练中取得了最佳的效果。其在BiGRU-ATT 算法的基础上精确率提升约0.024,F1值提升约0.03。这表明,该文算法使用CNN 进行文本情感分析能够提升算法的整体性能。
此外,还与其他同类型算法进行性能对比,对比算法选择了双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)、随机存取存储器(Random Access Memory,RAM)及SynATT(Syn-Attention)算法。各类算法的精确率及F1 值结果如表4 所示。

表4 同类算法对比实验结果
由表4 可知,该文算法的精确率与F1 值均较优。虽然精确率低于RAM 算法,但RAM 算法的网络层数较多且结构复杂,故其训练速度过慢,F1 值也相对较差。因此总体而言,该文算法具有较大优势。
3 结束语
相比线下教学,线上教学难以有效把握学生的学习质量。基于此,文中对线上教学平台的学习者行为数据加以分析,并建立深度学习模型对数据进行训练,最后实现对学习者学习质量的评估。实验结果表明,所提分词模型的性能良好,且特征提取模型的精确率及F1 值两项指标在对比算法中均为最优。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
当代陕西(2020年17期)2020-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年19期)2018-11-14
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
河南科技(2014年15期)2014-02-27
