
基于多智能体深度强化学习的机器人协作搬运方法
2023-12-09 02:55廖登宇赵德京崔浩岩
电子设计工程 2023年23期
廖登宇,张 震,赵德京,崔浩岩
(1.青岛大学自动化学院,山东青岛 266071;2.山东省工业控制重点实验室,山东青岛 266071)
移动机器人在复杂环境中进行路径规划是完成协作搬运[1-2]的关键。传统的路径规划算法如A*算法[3]、遗传算法[4]、蚁群算法[5]等在多机器人场景下无法保证得到最优路径。强化学习[6-8]是一种马尔可夫决策过程(Markov Decision Process,MDP)优化方法。智能体仅通过与环境的交互试错获得最优策略。该文将参与协作搬运任务的机器人看作智能体,为每个机器人设计了回报函数,由此建立了随机博弈[9-10];并提出一种新的多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning,MADRL)[11-12]算法进行求解,得到其搬运时间最短的路径。
1 基于QTRAN Plus算法的机器人协作搬运方法
1.1 机器人协作搬运任务建模
将每个参与搬运的机器人看为是一个智能体,机器人协作搬运任务示意图如图1 所示。
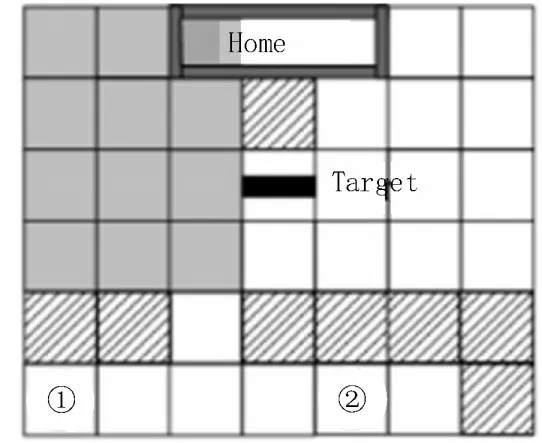
图1 机器人协作搬运任务示意图
其中,数字标号①、②表示两个机器人,实心矩形代表目标,带有斜杠的阴影方块代表障碍物,Home 是一个3×1 的区域。该任务的目的是规划两台机器人的行动路线,使其以最短的搬运时间准确抓取货物后将其运输到Home 区域。
机器人前往下一网格作为动作,在该任务中每个机器人有左、右、上、下和静止五个动作及静止、抓取左边、抓取右边三个抓取状态。机器人协作搬运任务的移动规则定义如下:两个机器人必须同时移动。若其中一个发生碰撞,则另一个将静止不动;只有两个机器人同时一左一右抓住目标,才能朝着相同的方向一起移动;在白色区域,如果两个机器人朝同一方向移动且没有发生碰撞,目标成功移动的概率为100%。在3×4 灰色区域内,其状态转移为非确定性的状态转移,机器人有50%的概率成功移动。
回报函数的定义如下:如果一个机器人抓住目标,它将获得+1 的立即回报;如果目标到达Home 区域,每个机器人将获得+100 的立即回报;如果目标在灰色阴影区域移动,每个智能体将获得0 的立即回报,如果目标未在灰色阴影区域移动,每个智能体将获得-4 的立即回报;在其他情况下,每个智能体都会获得-1 的立即回报。
1.2 QTRAN Plus算法
该文基于QTRAN[13]算法,提出一种合作型MADRL算法QTRAN Plus,对联合动作Q 值函数进行值分解,使用混合网络和智能体Q 值函数Qi(si,ai)逼近联合动作Q 值函数,其计算过程如图2 所示。
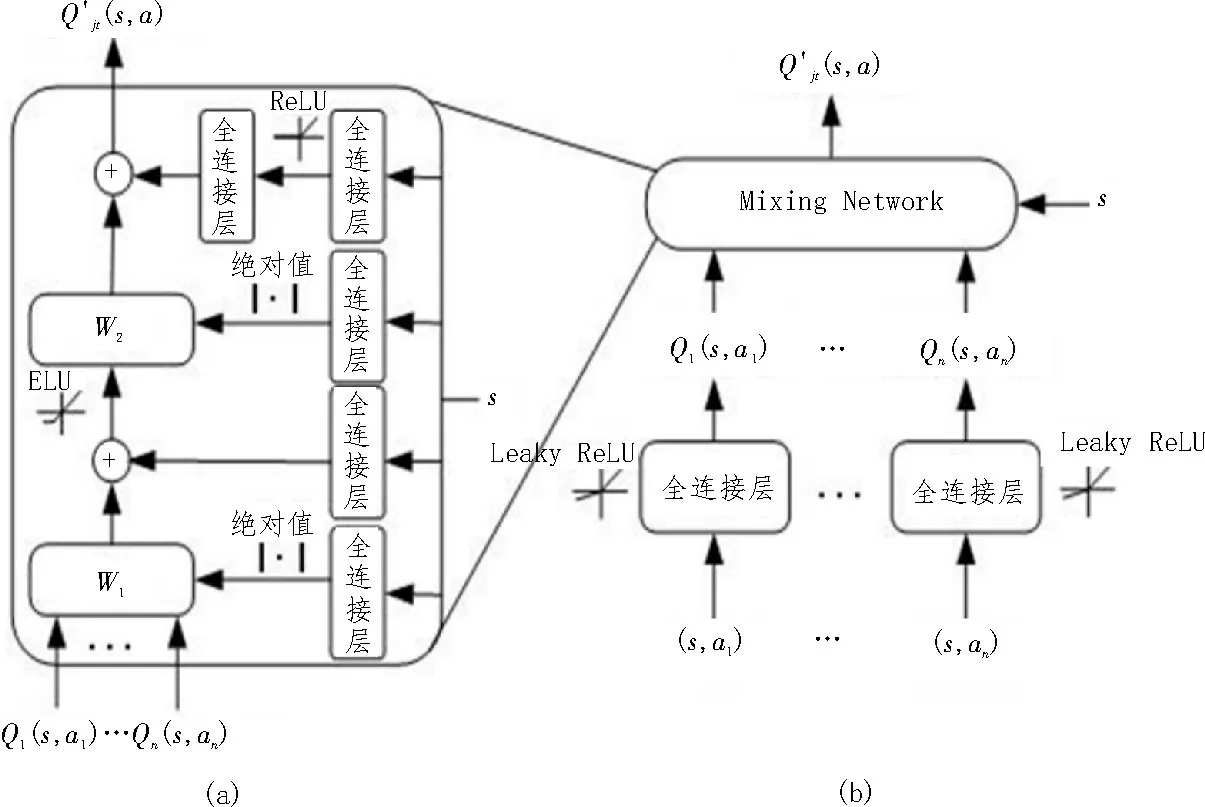
图2 Q′jt(s,a)值分解示意图
其中,图2(a)展示了混合网络的内部结构,图2(b)展示了带有混合网络的联合动作Q 值网络的整体架构是图2(b)中用混合网络和智能体Q 值网络逼近得到的联合动作的Q 值函数。为了用逼近Qjt(s,a),因此在使用Lopt和Lnopt学习时,通过固定的Qjt(s,a)来稳定学习。用来表示固定的Qjt(s,a),即使用损失函数更新参数时,不更新带有“”标记的网络。和QTRAN 算法中用所有智能体Q 值函数简单加和逼近联合动作Q 值函数相比,采用混合网络提高了逼近能力,因而更有可能提高算法的优化能力。
在集中训练阶段,有两个主要目标需要训练。一个是联合动作Q 值函数Qjt(s,a),另一个是过渡后的联合动作Q 值函数。QTRAN Plus 中损失函数设计如下:
其中,Ltd用于训练联合动作Q 值网络Qjt(s,a),Lopt和Lnopt用于训练混合网络和智能体Q 值网络,这三个损失函数是QTRAN 算法中原有的,为了提高算法收敛速度,该文新增了损失函数Lmix,Lmix、Lopt和Lnopt共同用于训练混合网络和智能体Q 值网络,λopt、λnopt和λmix分别代表损失函数Lopt、Lnopt和Lmix的权重。下面具体介绍式(1)右侧的四个损失函数。
Ltd表达式如下所示:
其中,θ-代表目标网络参数,r(s,a)代表在状态s下选择联合动作a时获得的回报代表s′下的最优联合动作。
为满足IGM,定义如下条件:
Lopt用于确保得到的联合动作是否满足式(5),Lnopt的目的是检查在每一步中样本选择的动作是否满足式(6)。其定义如下:
其中,β表示混合网络和智能体Q值网络中所有的参数。如在Lopt(;β)中,只对β进行更新而不更新θ。
为了加快收敛速度,该文所新增的损失函数定义如下:
其中,β-表示目标混合网络的参数。λopt、λnopt和λmix代表三个损失函数的权重,为了更好地训练参数,将权重设置为λopt=λnopt=λmix=1.0。
QTRAN Plus 算法架构图如图3 所示。

图3 QTRAN Plus算法架构图
图3 展示了智能体Q 值函数、联合动作Q 值函数以及式(1)中损失函数的计算过程。为了保证训练稳定,一方面,计算损失函数Ltd和Lmix时使用了目标网络。每隔时间周期T,将当前网络的参数值拷贝到目标网络的参数;另一方面,计算损失函数Lopt和Lnopt时使用了当前网络Qjt(;β)作为目标值,即图3中含有“”符号的网络代表对其进行固定,不需要对其进行梯度下降更新。此外,图3 中计算和使用的网络是相同的,计算Qjt(s′,aˉ′;θ-)和Qjt(s,a;θ)使用的网络是相同的,只是由于输入值的不同,因此得到不同的输出值。为了提高样本的使用率和训练的平稳性,该算法使用回放缓冲区(Replay Buffer)[14]对样本进行收集采样,该方法针对交互样本使用效率过低的问题,将采集到的样本放到一个类似于缓冲区的地方。每个样本的格式为
其中,α表示学习率表示第i个样本按照式(2)和式(3)计算得到的损失,b表示一个batch包含的样本数。
2 实验仿真数据分析
通过与VDN[15]、QMIX[16]、QTRAN[13]算法对比,在机器人协作搬运任务中验证所提算法的有效性,特增加QTRAN Plus w/oLmix以作为消融实验。其中通过消融实验来研究混合网络和新增加的损失函数在QTRAN Plus 中的必要性。仿真实验共进行50 回合取平均结果,每回合实验包含L个学习回合和5 000个评价回合。在每一回合的评价阶段中,每个机器人都使用其所学的固定策略。完成任务的最小期望步长为12,最大期望累积回报为182。如果任务在12个步长内完成,则判断其学习成功。QTRAN Plus 算法中损失函数的权重设置为λopt=λnopt=λmix=1.0 。QMIX、VDN 和QTRAN 算法的参数设置与QTRAN Plus 相同。
机器人协作搬运任务中各算法及消融实验的成功率、平均累积回报及标准差和平均步长及标准差数据如表1-3 所示。由仿真数据可知,只有QTRAN Plus 的成功率最终达到100%。QMIX 的学习速度虽然快,但因为缺乏联合动作Q 值函数的指导,有时会落入局部最优甚至会得到糟糕的策略。而QTRAN Plus 为了算法稳定性,牺牲了一部分学习速度来训练联合动作Q 值网络。因此,尽管在学习回合数达到30 000 时,QTRAN Plus 的成功率不如QMIX,但在平均累计回报和平均步长方面已经优于QMIX 并且呈现稳定趋势。QTRAN 的学习速度较慢,因此成功率仅为32%。从消融实验的仿真数据来看,QTRAN Plus w/oLmix的优化能力优于QTRAN,这说明用混合网络代替QTRAN 中的加和操作能的确能够提高优化能力。其次,与QTRAN Plus相比,QTRAN Plus w/oLmix的收敛速度低,且最终学习效果不如前者,这说明新增加的Lmix对提高收敛速度和学习效果都有重要的作用。

表1 成功率

表2 平均累积回报及标准差
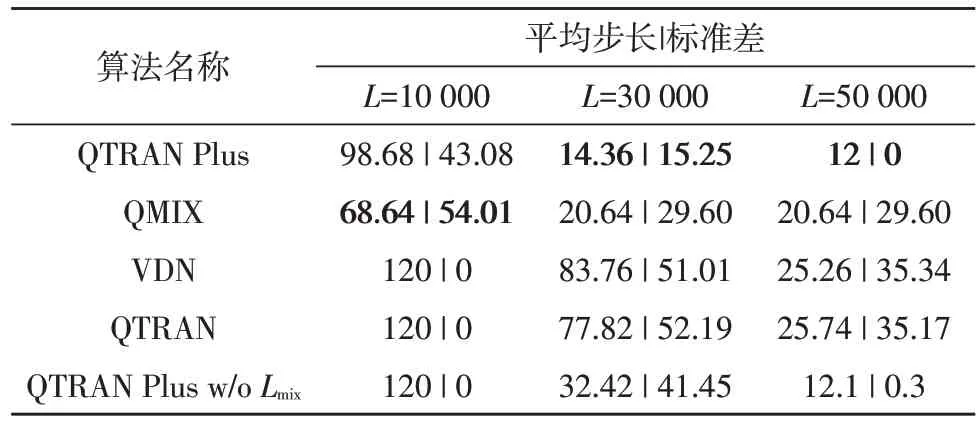
表3 平均步长及标准差
图4 所示为经过50 000 回合学习后,QTRAN Plus 算法得到的联合策略。箭头表示机器人执行的动作。该任务将在12 个步长中完成,这是该任务的最小期望步长。

图4 QTRAN Plus在协作搬运任务中获得的最优联合策略
3 结论
该文以机器人协作搬运任务这一实际问题为研究背景,提出了一种基于多智能体深度强化学习的算法QTRAN Plus。仿真实验表明,通过把机器人协作搬运任务建模成随机博弈,并使用多智能体深度强化学习算法求解,能够求解得到搬运时间最短的路径。同时,对比实验和消融实验说明,QTRAN Plus 算法使用混合网络代替Q 值网络的加和,以及并使用新的损失函数确实能够提升算法的稳定性和最优性。下一步将会在更为复杂的场景中设计相关的多智能体深度强化学习算法并进行验证。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
数学小灵通·3-4年级(2021年5期)2021-07-16
作文成功之路·小学版(2019年8期)2019-09-18
今日农业(2019年15期)2019-01-03
读者(2017年14期)2017-06-27
读写算(下)(2016年9期)2016-02-27
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
电子工业专用设备(2015年4期)2015-05-26
读者·校园版(2015年19期)2015-05-14
河北科技大学学报(2015年5期)2015-03-11
