
融合CNN和CapsNet的Wi-Fi室内定位方法
2023-12-08 10:02张天颖史明泉崔丽珍
测绘通报 2023年11期
张天颖,史明泉,崔丽珍,秦 岭
(内蒙古科技大学信息工程学院,内蒙古 包头 014010)
在科技引领的新时代中,基于位置的服务早已渗透到各行各业中,并不断地影响着人们的生活。对于室内定位,众多的学者和研究人员从未停止对其探索,如基于蓝牙、射频识别、超宽带无线电、Wi-Fi等室内定位技术[1-7]。其中,基于Wi-Fi的室内定位技术因Wi-Fi设备覆盖广泛,不需要花费时间和成本建设而得到广泛应用。
在离线阶段可选择不同的物理量作为位置指纹[8-17]。如,基于接收信号强度指标(received signal strength indicator, RSSI)、到达角、到达时间、到达时间差和信道状态信息(channel state information, CSI)等基础信号,以及基于信噪比、AP之间的信号强度差等复杂的信号。在基础信号中,CSI的波动小,相对于其他信号更加稳定,但CSI的采集需要专门的设备,不便于普及。研究表明[18],RSSI的空间分辨率更高,大部分位置指纹技术采用RSSI作为指纹。
卷积神经网络(convolutional neural network,CNN)可以通过一系列的卷积运算和池化运算提取数据中的高级特征,但其不能捕捉特征之间的关系,如相对位置关系、空间关系、尺度关系等。为了更好地表征这些特征信息,Hinton提出了“胶囊”的概念,胶囊网络(capsule network,CapsNet)[19]选取活动向量的长度来表示实体存在的概率,并使用它的方向来表示实例化参数。这使CapsNet可以从输入数据中提取更多细节特征,同时也减少了特征信息的丢失,增强了室内定位的稳健性和准确性。
综上所述,本文提出一种由CNN和CapsNet共同构成的CNN-CapsNet网络模型,以此对原始采集信息的特征进行充分的提取。同时,为了更好地利用采集数据中包含的信息,将采集到的RSSI数据按照一定的空间特征顺序构成二维位置指纹图像,并使用滑动窗口对数据集进行扩展,再使用CNN-CapsNet网络提取和学习特征,以期得到准确率更高的定位模型。
1 基于CNN-CapsNet网络的Wi-Fi室内定位系统结构模型
系统模型如图1所示,包括:离线阶段和在线阶段两个阶段。离线阶段是首先将采集到的数据进行预处理得到训练数据集,通过CNN提取底层信息,然后将其输入到CapsNet中进行训练,得到最优结构;而在线定位阶段就是通过训练好的最优结构直接进行测试数据的目标区域估计。

图1 基于CNN-CapsNet的Wi-Fi室内定位系统
1.1 数据的采集
采集数据的试验区域是内蒙古科技大学逸夫楼一个空旷的长廊,如图2所示。其中共有50个采集点,每两个采集点之间间隔1.6 m。
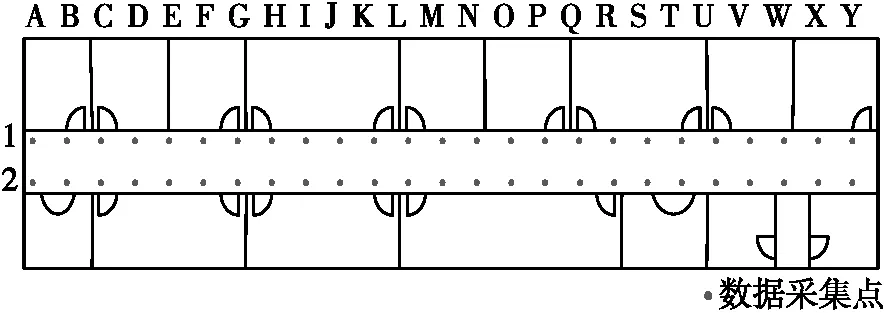
图2 数据采集区域平面图
考虑人在行走站立的过程中,手持移动终端的平均高度约为1.5 m,因此,将移动终端放置高度为1.5 m的手机支架上,分别在各采集点处进行采集。移动终端约2 s可对所有检测到的AP进行一次RSSI数据的采集,故选择在每个采集点处采集约90 min,可得到T=2700次数据。采集到的RSSI的取值分布在-100~-35 dbm范围内。
1.2 特征图像的构建
采集到的数据结构如图3所示,其中T为从AP接收到RSSI的次数,M为AP的数量。对于每个采集点均可以得到一个数据结构,共50个采集点。
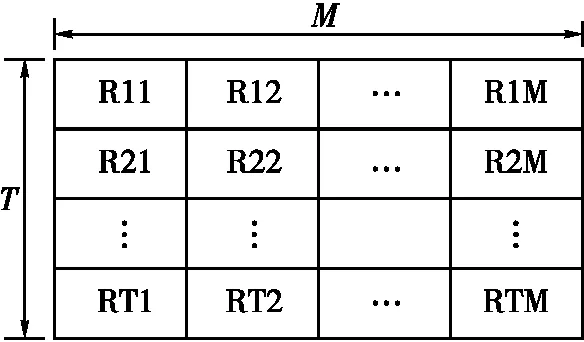
图3 采集点数据结构
1.3 数据库的构建
在机器学习中,绝大部分图像处理模型都需要很多数据进行训练学习。当训练数据不足时,会对训练数据中的图像做旋转、平移、缩放、填充、左右反转等变换。这些变化都是对同一个目标在不同角度的观察结果,但位置指纹图像则通过RSSI值构成,每个像素点都有着特定的含义。若使用上述方法对特征图进行变换,会破坏RSSI中包含的信息,因此,本文使用滑动窗口法来扩展训练集。
如图4(a)所示,RSSI特征图像的总测量次数为T,当测量次数为t时对数据进行分割,得到T/t个特征图。如图4(b)所示,当对数据使用滑动窗口进行分割时,每隔t/2次生成一个特征图,因此每两个相邻的特征图之间会有t/2的RSSI数据重合。即允许相邻的RSSI特征图像在时域内重叠,得到2(T/t)-1个特征图,从而构成离线数据库。
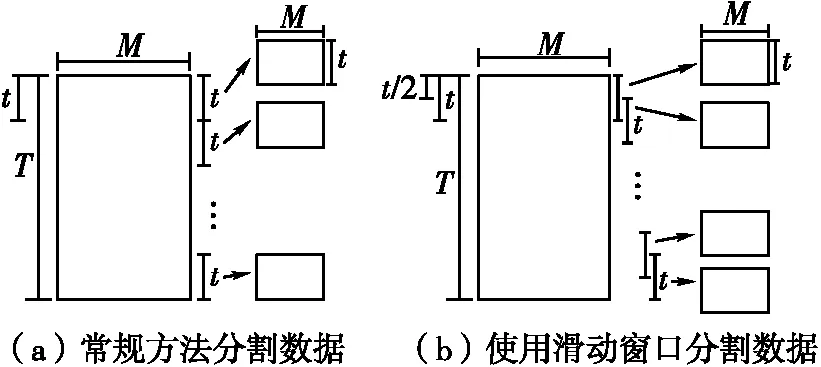
图4 滑动窗口分割数据对比
通过滑动窗口分割后,部分定位点的位置指纹特征图如图5所示。
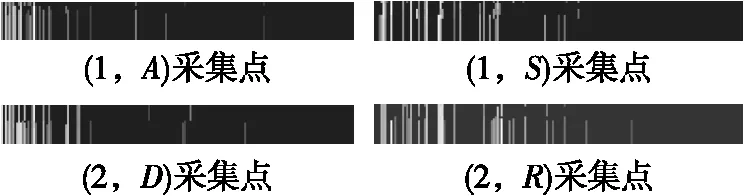
图5 部分位置指纹特征
1.4 模型训练和目标定位
模型训练是通过已得到的数据集及其对应的数据标签,将其输入到CNN-CapsNet网络中,通过不断提取特征、学习特征,从而寻找最优的权重参数,使得模型的准确率最大化,训练好的模型在目标定位区域即可得到定位点。寻找最佳模型通常需要多次试验得到最佳参数,CNN-CapsNet网络的训练过程是十分耗时的,每次迭代使用所有的样本数据会使迭代速度变慢,且对计算设备的内存要求较高。因此,每次迭代时,仅使用一部分数据进行,以使学习训练过程具有更强的稳健性。
2 CNN-CapsNet模型
CNN-CapsNet网络模型架构如图6所示。定位区域采集得到的位置指纹特征图首先由卷积层和池化层构成的CNN进行初级特征提取,完成定位图像到初级特征图的转换。然后通过CapsNet进行更深层的特征提取,完成区域定位。
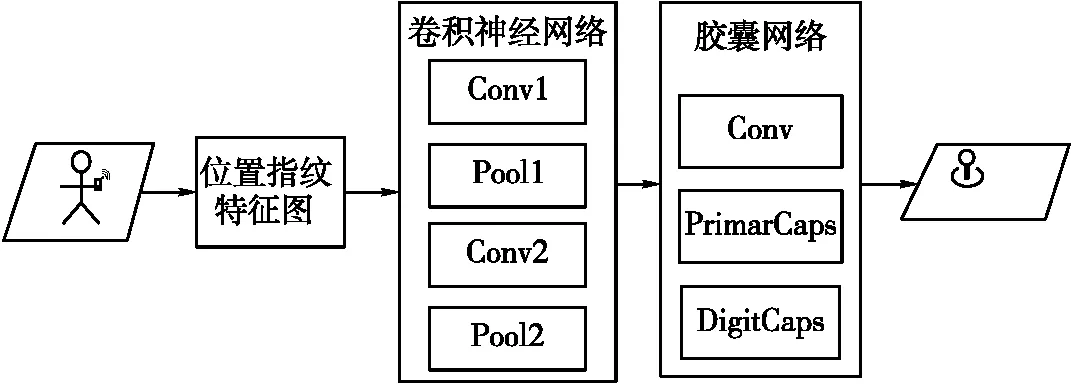
图6 CNN-CapsNet网络架构
2.1 CNN网络
CNN通常由卷积层、池化层和全连接层3部分组成,本文模型中仅使用卷积层和池化层。卷积层和池化层构成特征提取器,卷积核相当于特征探测器,通过卷积核对其进行特征提取运算,提取结果为一个新的特征层。为了使模型拥有非线性表达能力,常将卷积后的运算结果通过激活函数(ReLU)作非线性映射,其中ReLU函数表达式为
(1)
通过卷积层处理后的数据是十分庞大的,常通过池化层减小原卷积层输出张量的维度,降低计算量和时间复杂度。本文模型中CNN部分由两个卷积层构成,其结构如图7所示。
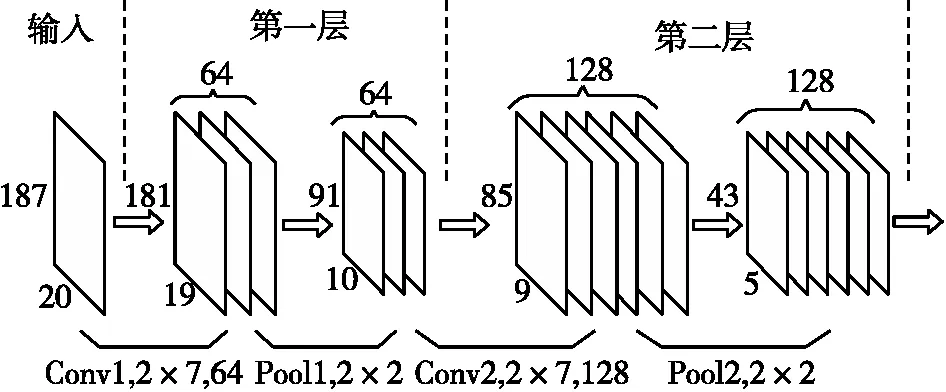
图7 CNN内部结构
输入的位置指纹特征图大小为20×187,首先使用64个大小为2×7的卷积核提取底层信息,卷积层输出特征图大小为19×181×64;然后使用2×2最大池化过滤器,则第一个卷积层输出特征图为10×91×64。第二层与第一层同理,则第二层卷积层输出特征图大小为5×42×128。
2.2 CapsNet网络
CapsNet算法是采用端到端的方式提取图像的空间信息,将输入标量转换为向量。使用输出向量的长度来表征实体存在的概率,方向表示实例化的参数或图形属性,从而降低特征信息的丢失,提高模型的特征提取能力。本系统使用的CapsNet架构如图8所示。
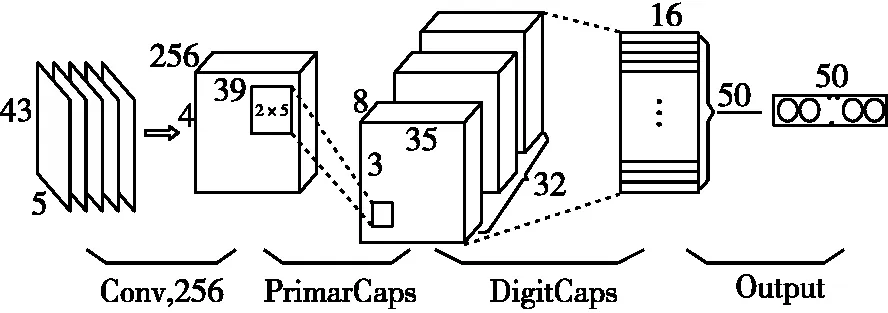
图8 CapsNet架构
将CNN网络处理后的特征图再使用256个大小为2×5的卷积核进行卷积,然后连接主胶囊层。在胶囊层中,神经元是一个向量而不是标量,但卷积后的特征层为标量,因此需将卷积之后的特征层重构成向量的形式。构建向量神经元的方法是将特征层的每8个通道合并成一个新的胶囊单元,而新的胶囊单元的通道数将减少为原来通道数的1/8,胶囊单元作为胶囊层的输入。
最后一层为数字胶囊层,用于存储高级别特征的向量,输出50个维度为16的向量,每个向量代表一种定位点。通过向量的模长来衡量各个类别的概率,模越值大,属于这个类的概率越大。
2.3 动态路由
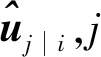

图9 CapsNet内部结构
(2)
(3)
cij为耦合系数,由动态路由算法确定,其目的是让输出的神经元自主选择最好的路径传输到下一层神经元,定义公式为
(4)
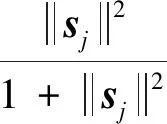
(5)
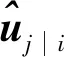
(6)
动态路由算法如下。
路由算法
2:对于所有l层的胶囊i和l+1层的胶囊j:bij→0
3:迭代r次
4: 对于所有l层的胶囊i:cij←Softmax(bij)
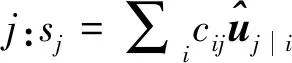
6: 对于所有l+1层的胶囊j:vj←Squash(sj)
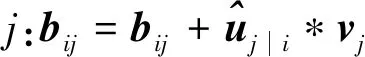
返回vj
2.4 模型的损失函数
在模型的训练过程中,模型的权值需要通过反向传播算法对其进行更新或迭代,而反向传播需要一个能度量模型输出值与真实值之间距离的损失函数。通过损失函数,在训练时就可以通过反向传播算法不断更新迭代模型的权重值。本文损失函数的表达式为
(7)
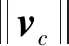
3 试验结果与分析
3.1 试验参数
本文的试验参数设定具体见表1。

表1 试验参数
3.2 数据集大小
在图像处理领域,数据集的大小与训练网络模型性能存在密不可分的关系,通常数据集越大,对特征的学习提取效果越好。CNN-CapsNet网络中,CapsNet的主要步骤在于动态路由,使用适量的数据集有助于在一定时间、参数范围根据空间特征训练出合适的网络,过大的数据集会加大路由时间和参数反而使得网络性能降低,因此数据集大小也是网络训练中的重要参数之一。
本文试验使用了3种数据集,分别为数据集1、数据集2和数据集3。3个数据集中都包含50个定位点,不同的是在数据集1中每个定位点包含25张位置指纹特征图,共1250张位置指纹特征图;数据集2中每个定位点包含50张位置指纹特征图,共2500张位置指纹特征图;数据集3中每个定位点包含100张位置指纹特征图,共5000张位置指纹特征图。
使用CNN-CapsNet定位模型分别对以上3种数据集进行训练,结果见表2。不难看出,随着数据集内位置指纹图像数量的增加,模型训练的损失逐渐降低,测试的准确率逐渐升高,模型整体性能呈现变好趋势。但随着数据集内数据数量的增加,所需的训练时长也逐渐增加,数据集2与数据集3之间准确率虽有提升,但提升微弱。综合考虑多种因素,数据集2即可表达各定位点数据特征,不需要使用更大的数据集,浪费更多的时间成本。
本文将主胶囊层及数字胶囊层的向量长度对系统定位精度的影响也做出了对比,见表3。可知在组合1至组合6中,模型的损失函数都是极低的。以至于在该数量级上,各个模型之间损失函数的差异性是可以忽略不计的。故损失函数的大小不是本文衡量模型性能最合适的指标。各模型之间存的差异是模型的收敛速度,当模型的稳定性相同时,模型的收敛速度越快其性能就相对越好。
图10为6种组合模型其损失函数值随训练位置指纹图像张数的变化情况。当数字胶囊层向量维度固定,随着主胶囊向量维度的增加,模型的收敛时间也越长。当主胶囊向量维度相同时,随着数字胶囊向量维度的增加,模型的收敛速度反而越快。由图10可知,当主胶囊层向量维度为8,数字胶囊层向量维度为16时,收敛速度最快,模型的性能最好。
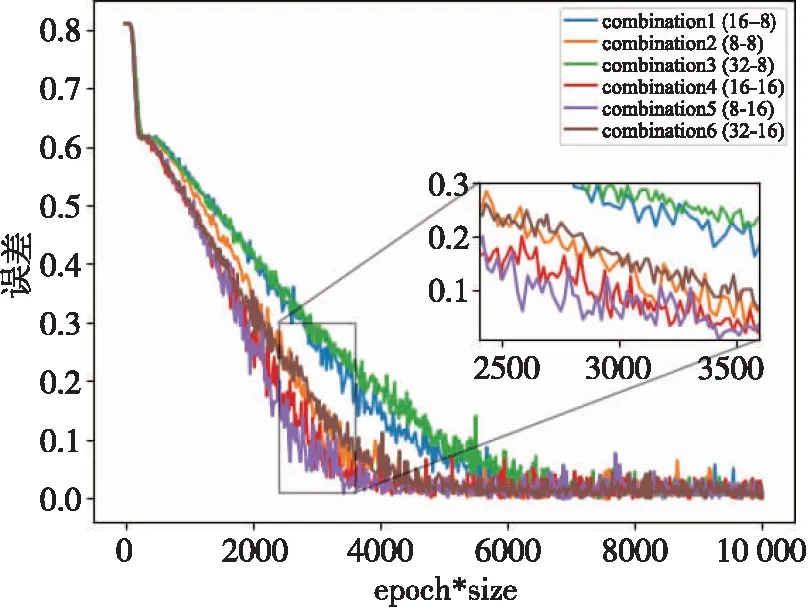
图10 损失模型函数值随训练图像张数的变化
在CapsNet中,除了向量维度,路由迭代次数也是影响模型好坏的重要因素。当迭代次数较少时,试验结果较差,这是因为较少的路由迭代次数导致耦合系数无法得到充分学习。然而当路由迭代次数过大时,模型参数的增加导致过拟合,准确率也会随之下降(见表4),当路由迭代次数设置为3时性能最高。
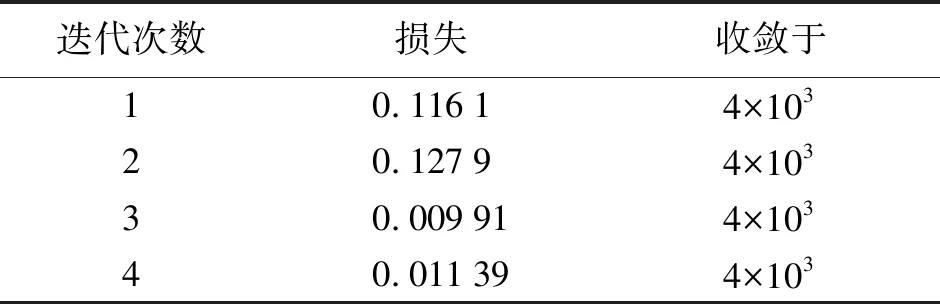
表4 路由迭代次数对定位模型性能的影响
3.3 对比试验与分析
为估计本文模型性能,将其与以下几个模型在构建的数据集上进行对比试验,各模型特点如下。
(1)模型1 CNN在图像处理领域的表现是十分出色的,但CNN网络中神经元之间传递的是标量,无法体现空间关系,缺少方向性。
(2)模型2 CapsNet是以向量的形式表示部分与整体之间的关系的,不仅能够以特征响应的强度来表示图像,还能够表征图像特征的方向、位置等信息。
(3)模型3、4、5是将注意力机制与CapsNet相结合,注意力机制是实现网络自适应注意的一种方式,使网络去关注更需要关注的地方。其中,SE为常用的通道注意力机制,可以使模型更加关注信息量最大的通道特征,而抑制那些不重要的通道特征;CBAM是表示卷积模块的注意力机制,是一种结合了空间和通道的注意力机制模块;ECA也是通道注意力机制模块,是SE的改进版。
(4)模型6为本文使用的模型,使用向量与标量相结合的方式对位置指纹特征图进行有效的特征提取。
以上模型在构建的数据集上进行对比试验,其结果见表5,将CapsNet与CNN两种模型的试验数据结果对比,充分体现了使用向量代替标量表示图像特征的优势。为了提升CapsNet的性能,尝试在CapsNet中融合注意力机制,通过注意力机制使CapsNet的注意力在训练时放在图像特征更突出的地方。当CapsNet与CEA和SE相结合时,损失函数的损失值增加了;只有与CBAM注意力机制融合时,模型的损失函数才有所降低,但3种融合方式,都增加了网络的训练时长。换而言之,3种融合方式均增加了原网络的计算复杂度。当CapsNet与CNN结合时,不仅损失值有明显的降低,训练所需时长也比其他融合方式短。由此可见,将标量和向量相结合的方式可对位置指纹特征图进行有效的特征提取,并降低网络的计算复杂度,节约网络训练时间。
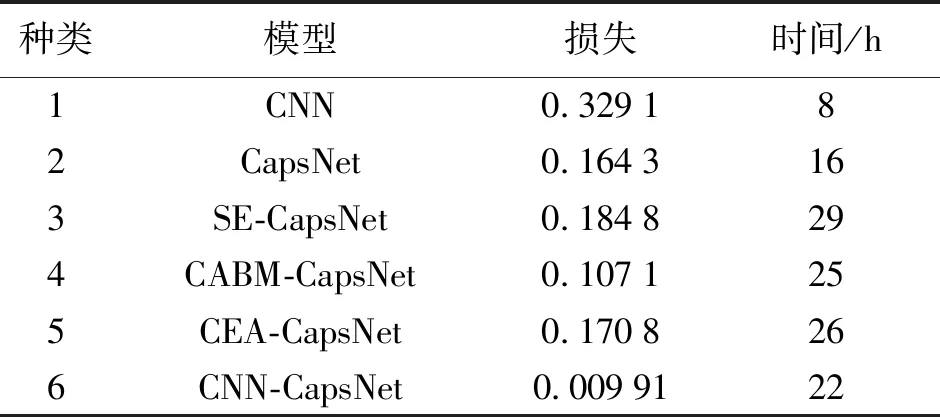
表5 不同算法的试验结果
4 结 语
本文提出了一种融合CNN和CapsNet的Wi-Fi室内定位方法。针对传统位置指纹数据存在单一性的问题,充分利用采集数据中包含的时间信息,构建成二维位置指纹图像,通过对位置指纹图像的特征学习实现定位区域的识别。相比于使用传统网络进行室内定位,本文将CNN和CapsNet相结合,将标量和向量相结合,增强网络对特征的提取能力,降低了网络的计算复杂度,节约了网络训练所需的时长。通过CapsNet的动态路由算法,不再一味地追求学习大数据集,减少了网络对数据库数量的依赖。试验结果表明,使用CNN-CapsNet网络进行室内定位,其损失可达0.009 91,并优于其他网络模型。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
电子制作(2019年11期)2019-07-04
网络安全和信息化(2018年3期)2018-11-07
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2016年8期)2016-04-16
青少年科技博览(中学版)(2015年7期)2015-08-12
电测与仪表(2014年16期)2014-04-22
电视技术(2014年19期)2014-03-11
