
顾及地址语义和地理空间特征的多源POI位置融合
2023-12-08 10:02李朋朋刘纪平闫雪峰
测绘通报 2023年11期
李朋朋,刘纪平,王 勇,罗 安,桑 瑜,闫雪峰
(1. 西南交通大学地球科学与环境工程学院,四川 成都 610031; 2. 中国测绘科学研究院,北京 100830;3. 江苏海洋大学海洋技术与测绘学院,江苏 连云港 222005)
近些年,随着Web2.0、高精度定位、新兴媒体及移动互联网技术的融合发展,人们对基于位置服务数据的需求在急剧增加[1],特别是以POI数据为代表的地理空间数据也越来越备受关注。目前,基于POI数据开展的地理空间研究已成为GIS相关领域的研究热点,如城市功能区识别[2-3]、城市活力分析[4-5]和用户行为推荐[6-7]等。然而,这些研究几乎依赖于几何准确和语义详细的POI数据,但这些高质量的数据描述通常分散在不同POI平台上[8]。因此,匹配融合不同来源的POI数据,已经成为丰富数据完整性、增强数据质量、提高数据鲜活度的一个有效途径[9]。然而,由于不同POI数据源之间属性表达的多样性和复杂性[10],不可避免地导致多源POI数据之间存在地理位置编码上的差异及定位误差等问题,从而使得POI数据的匹配融合变得更加困难。
多源POI位置融合是将来自不同数据源中指向相同POI数据的位置进行合并,这也是实现地理空间数据匹配融合的关键技术之一。目前,关于这方面研究主要包括以下两类方法:①基于地理编码的空间位置预测,即利用地理编码技术对现有的地理位置数据(如街道地址、邮政编码、地名等)进行分析和建模,推断出未知或缺失位置坐标[11-12],从而实现空间位置信息的整合;②基于标准地理数据库的空间位置融合,即以标准地理数据库作为参考,对不同数据源的地理位置信息进行匹配、校正和整合,从而消除数据源之间的差异和不一致性[13-14]。综上所述,不同数据源使用不同的地理编码系统,导致融合过程中的匹配和转换困难;同时,缺乏统一的标准数据库和格式会影响数据融合的效率和一致性。
因此,本文提出一种顾及地址语义和地理空间特征的多源POI位置融合方法。基于神经网络模型分别提取地址属性的语义特征和位置属性的地理空间特征,并基于这些特征信息实现多源POI位置融合。
1 神经网络模型
1.1 长短时记忆网络
长短时记忆网络(long short term memory network, LSTM)[15]是循环神经网络(recurrent neural network, RNN)的一种变体,其主要目的是解决RNN无法获取长距离依赖问题,以及在训练过程中出现的梯度爆炸和梯度消失等问题。如图1所示,LSTM主要包括3个门控机制。其中,忘记门决定上一时刻的单位状态中有多少信息会被丢弃;输入门决定当前时刻的网络输入中有多少信息会被添加到单位状态中;输出门决定当前时刻的单元状态中有多少信息可以输出。具体计算公式为

图1 LSTM网络结构
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot·tanhct
(6)
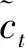
1.2 图神经网络
图神经网络(graph neural network, GNN)是对图中节点(Nodes)、边(Edges)、全局(Global)的属性值进行参数优化,并保持图的结构不变,即保持了图的对称性[16],如图2所示。目前比较流行的图神经网络有图卷积网络(graph convolution networks, GCN)[17]、图注意力网络(graph attention networks, GAN)[18]和GraphSAGE图神经网络[19]等。本文将使用图注意力网络提取地址属性的层级语义特征。
图2 GNN网络二阶邻接节点特征优化过程
2 研究方法
本文方法主要包括:数据预处理、属性特征提取和特征聚合3部分,如图3所示。

图3 多源POI位置融合框架
2.1 数据预处理
2.1.1 地址要素切分
中文分词是中文文本处理的基础工作,分词的准确性将直接影响后续任务的表现。POI地址属性是描述POI位置信息的一个重要属性,它通常由多个不同且具有空间拓扑约束的地址要素或附加词组成。这些地址要素可以描述某一个区域范围或某一特定地理实体,附加词可以描述一个方位、距离或拓扑关系等。因此,对于地址属性的切分只需将其切分成多个地址要素和附加词即可。本文采用文献[20]提出的基于Bi-GRU的中文地址要素切分方法进行分词,部分地址要素切分实例见表1。
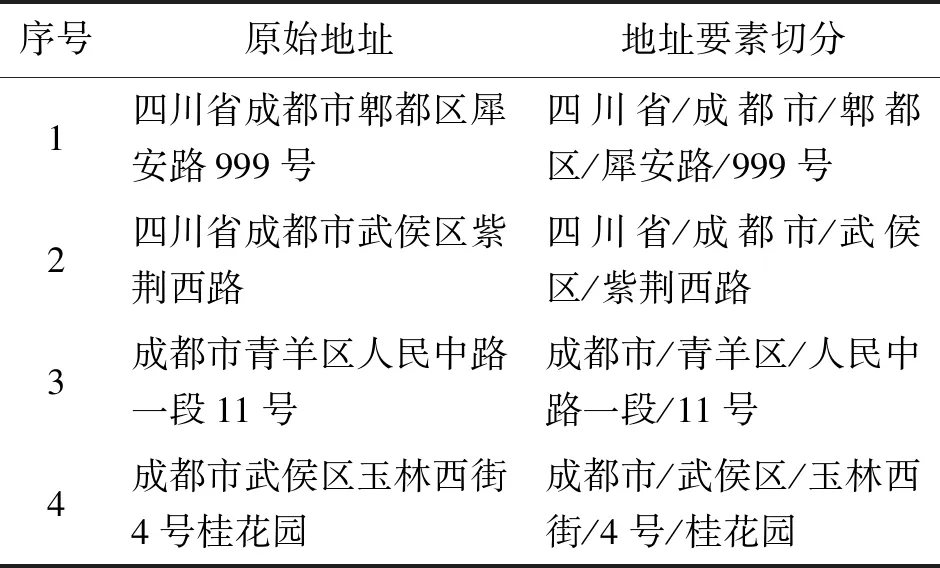
表1 POI地址要素切分实例
2.1.2 地址要素词向量表达
文本数据作为一种标记性语言,无法直接作为模型的输入进行计算分析。因此,需要通过词嵌入的方式将文本转换成特征向量作为模型的输入。词嵌入通过训练给定的语料库来生成一个词嵌入向量矩阵M∈PD×d(D表示语料库中词的个数,d表示词嵌入向量维度),语料库中每一个词都能够根据其对应的索引在词嵌入向量矩阵M找到相应的向量表示Vc∈d。本文将基于地址要素语料库,使用Word2Vec的连续词袋模型(continuous bag-of-words model, CBOW)来训练生成地址要素的词嵌入向量矩阵M。
2.2 地址属性语义特征提取
将地址属性语义特征提取分为文本语义特征提取和层级语义特征提取。
2.2.1 基于TextRCNN的地址文本语义特征提取
TextRCNN是2015年提出的文本分类网络模型[21]。该模型既能够捕获句子序列中的长距离依赖关系,也能够提取句子序列中的局部特征。本文基于该模型进行了改进,如图4所示。首先,在给定一个地址要素表达序列S=(a1,a2, …,an)(an表示地址要素,n表示该地址中地址要素的个数),利用词嵌入向量矩阵M生成对应的词嵌入向量矩阵E=[e1e2…en],并将其作为双向长短时记忆网络(Bi-LSTM)的输入;然后,通过Bi-LSTM提取上下文特征矩阵H,并将其与词嵌入向量矩阵E进行残差连接生成向量矩阵K;最后,对向量矩阵K进行最大池化和全连接层操作,输出地址属性的文本语义特征向量xs。具体计算公式为
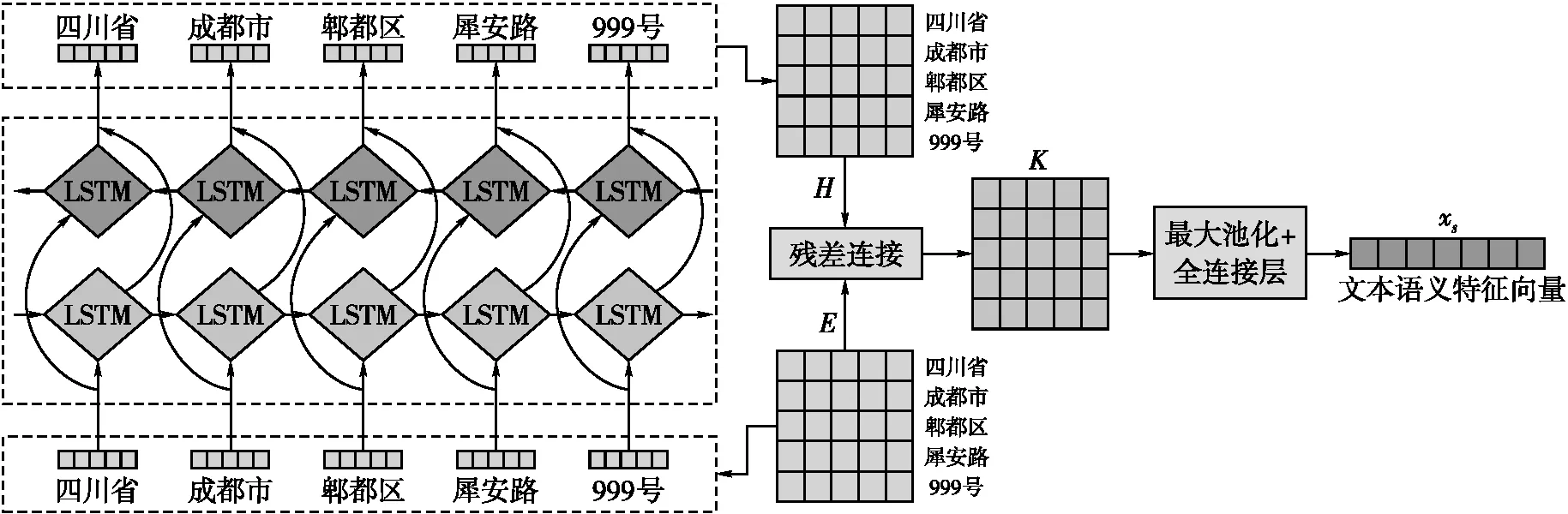
图4 POI地址属性文本语义特征提取
hr(ai)=fLSTM(hr(ai-1),cr(ai-1),ei)
(7)
hl(ai)=fLSTM(hl(ai+1),cl(ai+1),ei)
(8)
h(ai)=Wh(hr(ai)+hl(ai))+bh
(9)
k(ai)=Wk(h(ai)+ei)+bk
(10)
(11)
式中,hr(ai)和hl(ai)为地址要素ai在向右和向左方向上的LSTM隐藏层输出;fLSTM为LSTM计算公式;cr(ai-1)为地址要素ai-1在向右方向上的LSTM单位状态;h(ai) 为地址要素ai的Bi-LSTM隐藏层输出;k(ai) 为地址要素ai的残差连接输出;xs为地址属性的文本语义特征向量;W和b为需要进行训练的权重和偏置项。
2.2.2 基于图注意力网络的地址层级语义特征提取
地址要素之间往往存在着一定的空间拓扑约束,如行政区划之间有包含、相邻等关系,行政区划与道路之间有包含、相交或相邻等关系,道路与标志物之间有包含、相邻等关系。虽然不同地址要素之间的空间拓扑关系复杂多样,但是大多数地址要素在地址表达中都是一种层级嵌套的包含关系。因此,本文主要考虑地址要素的层级嵌套关系,并基于图注意力网络提取地址层级语义特征。将地址要素语料库中所有的地址要素作为GAN网络节点,并根据地址要素在每条地址表达中的先后顺序构建GAN网络的边。同时,使用词嵌入向量矩阵M对每个节点特征进行初始化。GAN网络结构的构建如图5所示。
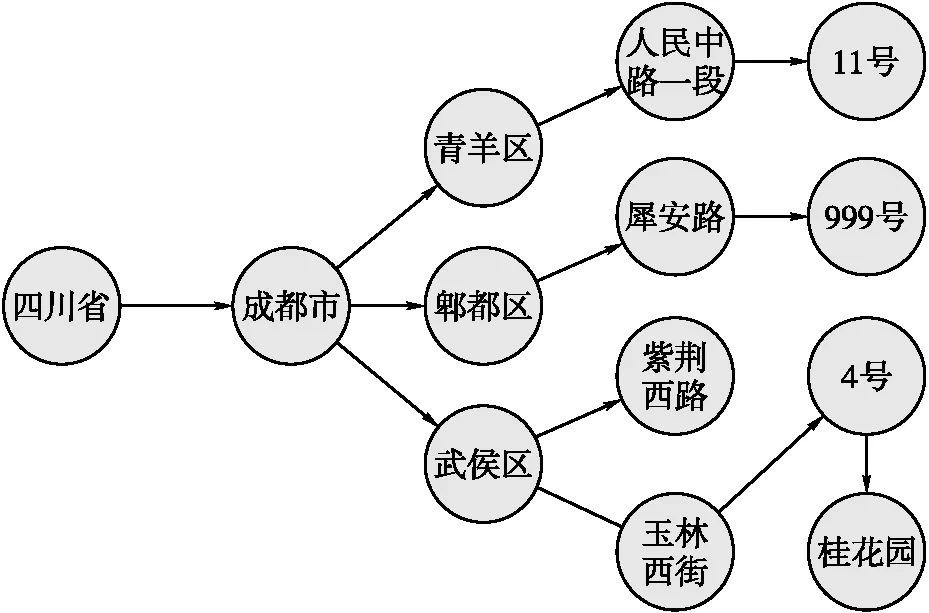
图5 GAN网络结构实例
在基于GAN网络提取地址层级语义特征中,定义输入GAN的一组图节点为N=(n1,n2, …,nm);对应的图节点特征记为
F=(f1,f2,…,fn),fi∈d,其中m为图中节点个数,d为节点特征;对应的输出为一组图节点特征F′=(f′1,f′2,…,f′2),f′i∈d′,其中图中节点个数m和输入图节点个数相同,但节点特征进行了更新。
在节点特征fi的更新过程中采用了注意力机制,首先,将节点特征fi和其一阶邻接节点特征fj进行拼接,并通过一个单层前馈神经网络将拼接特征映射为一个实数。该实数表示节点nj对于节点ni的重要程度,即注意力系数。然后,对于节点ni的其余一阶邻接节点及自身节点进行相同操作,以获取所有一阶邻接节点及自身节点对于节点ni的注意力系数。最后,对所有的注意力系数进行归一化操作,并将归一化结果与其对应的一阶邻接节点及自身节点的输入特征进行加权求和,以此来更新节点ni的特征。具体计算公式为
(12)
(13)
式中,aij为节点nj对于节点ni归一化后的注意力系数;αT∈2d′×1为单层前馈神经网络权重的转置;W∈d×d′为节点特征的线性变化权重,该权重在所有图节点中共享;LeakyReLU和σ为激活函数;‖为节点特征拼接;Ni为节点ni的一阶邻接节点以及自身节点的集合。
为了能够学习到更加丰富的地址层级语义特征,采用了多头注意力机制。即使用多个注意力机制进行上式相同的操作,然后将得到的多个更新节点特征进行拼接,得到新的节点特征,公式为
(14)
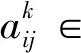
2.3 位置属性地理空间特征提取
位置属性就是一组空间特征,但属于低维特征,地理空间特征表征有限。因此,需要对位置属性进行增维操作,生成高维特征以获得足够的地理空间表达能力。多层感知机(multilayer perceptron, MLP)作为一种常见特征增强方法[22],它由多个神经元层组成,其中每层神经元的输出将通过全连接的方式作为下一层神经元的输入,并生成新的特征表达。MLP包含一个输入层、一个或多个隐藏层和一个输出层,其中隐藏层的每一个神经元都是通过非线性激活函数将其输入转换为特征输出,这种转换可以获取高维特征,从而增强输入信息的特征表达能力。本文构建的MLP网络结构如图6所示。
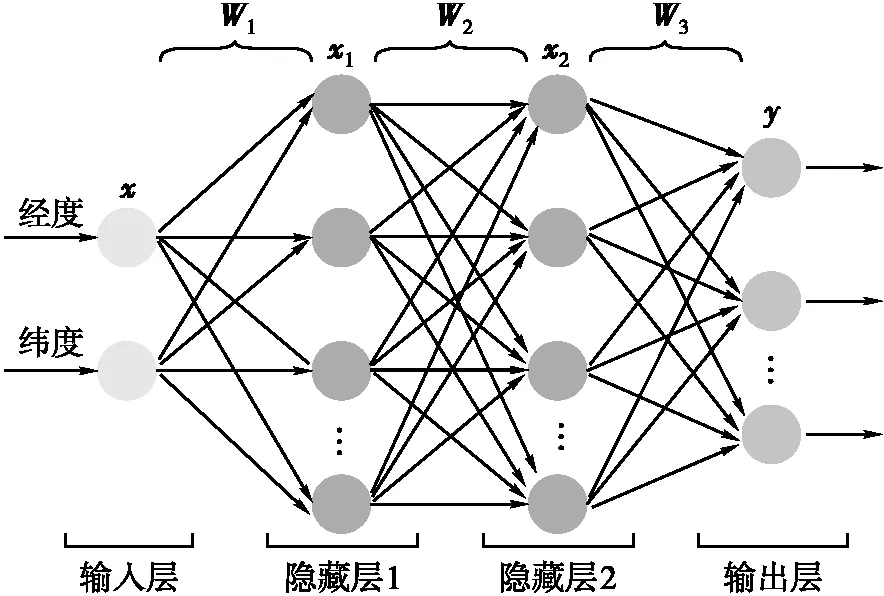
图6 多层感知机
x1=f1(W1x+b1)
(15)
x2=f1(W2x1+b2)
(16)
y=f2(W3x2+b3)
(17)
式中,x∈2为经纬度坐标;W和b为需要进行训练的权重和偏置项;f1和f2分别为隐藏层和输出层的激活函数。
2.4 基于自注意力机制的位置融合
自注意力机制是一种用于处理序列数据的机制,它通过计算输入序列中每一个元素与其他元素之间的相关关系,实现对不同元素的加权聚合[23]。本文使用自注意力机制对地址语义特征和地理空间特征进行聚合,实现多源POI位置融合任务。如图7所示,注意力机制计算主要包括3部分:注意力权重、加权求和、线性变换。计算之前,需要将地址语义特征和地理空间特征进行合并,构建序列矩阵X。在注意力权重计算时,需要对输入序列矩阵X分别使用线性映射矩阵WQ、WK和WV分别映射成Q、K和V,然后通过Q和KT的点乘计算注意力权重M,该权重通过归一化操作后将作为加权求和的输入;加权求和是对注意力权重M与V进行点乘计算,生成特征聚合矩阵H。最后,通过线性变换将特征聚合矩阵H映射到一个低维空间来预测多源POI合并位置点,从而实现多源POI数据的位置融合任务。具体计算公式为
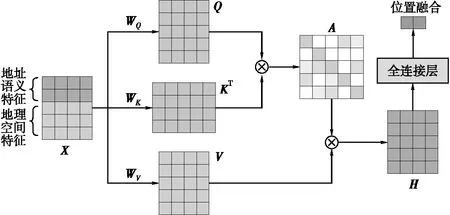
图7 基于自注意力机制的位置融合
Q=(WQX+bQ)
(18)
K=(WKX+bK)
(19)
V=(WVX+bV)
(20)
(21)
H=A⊗H
(22)
y=f(WyH+by)
(23)
式中,dk为矩阵Key的维度;f为激活函数;⊗ 为矩阵的点乘;W和b为需要进行训练的权重和偏置项。
在该任务中使用融合位置与参考位置之间的欧氏距离作为模型训练的目标函数和评价指标,计算公式为
(24)
式中,lonr和latr为参数位置的经纬度;lonf和latf为融合位置的经纬度。
3 试验与分析
3.1 试验环境与试验数据
本文试验环境的主要参数如下:深度学习框架为PyTorch 1.7,开发语言为Python 3.7,CPU为Intel(R) Core (TM) i9-9900K CPU @ 3.60 GHz,内存为 32 GB,GPU 为 NVIDIA GeForce RTX 2080 Ti。
本文试验数据均来自成都市范围内的POI数据。其中,用于多源POI位置融合的数据源分别来自百度地图、腾讯地图和高德地图3种数据源;用于参考位置的POI数据源来自当地测绘部门的实测数据。在构建样本数据集过程中,采用文献[9]的多源POI数据匹配方法寻找在百度地图、腾讯地图和高德地图中至少有两种数据源可以匹配到参考数据源中的同名POI数据。将匹配到的同名POI数据作为需要位置融合的POI数据,使用参考数据源作为样本标签。共生成样本数据集37 036条,其中训练数据集36 036条,验证数据集500条,测试数据集500条。
3.2 神经网络超参数设置
一个性能更优的网络模型,超参数的设置极其重要,给出了网络模型中超参数的一个初始值和最优值,见表2。其中,Hidden size、Batch size和Dropout rate3种超参数通过试验选取最优值,主要是因为网络模型对于这些超参数比较敏感,其余超参数的最优值使用初始值。

表2 网络模型超参数设置
3.3 试验结果与分析
为了验证本文方法对于多源POI数据位置融合的精度,将该方法与现有基于机器学习和深度学习的方法进行比较,对比结果见表3(位置融合精度的最大值、平均值和最小值指在测试数据集上取得的值)。
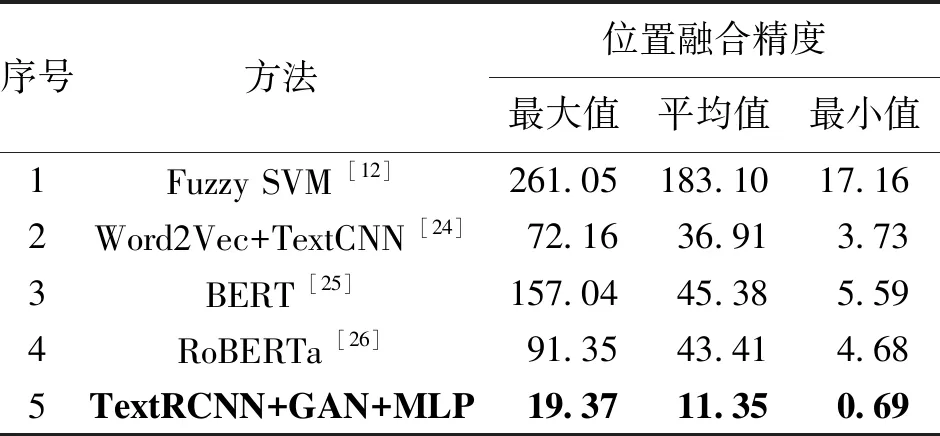
表3 多源POI数据位置融合方法对比试验结果 m
由表3可以看出,基于机器学习的Fuzzy SVM位置融合方法精度最低,相比之下,基于深度学习的Word2Vec+TextCNN、BERT和RoBERTa位置融合方法的精度都有很大提升。具体而言,基于Word2Vec+TextCNN的位置融合方法是所有深度学习方法中融合精度最优的,其次是基于RoBERTa位置融合方法,最后是基于BERT位置融合方法。本文方法在所有对比方法中取得最优值,分析其原因,主要得益于以下几点: ①基于TextRCNN网络可以有效地提取地址属性的文本语义特征; ②基于GAN网络可以有效地提取地址属性的层级语义特征; ③使用自注意力机制聚合了地址属性的语义特征和位置属性的地理空间特征,丰富了POI数据的表达特征,从而提高了融合精度。
为了验证地址文本语义特征和地址层级语义特征对于位置融合精度的影响,进行了消融试验。第1组消融试验仅使用了地址的文本语义特征和地理空间特征进行位置融合,没有使用地址层级语义特征。第2组消融试验仅使用了地址的层级语义特征和地理空间特征进行位置融合,没有使用地址文本语义特征,试验结果见表4。
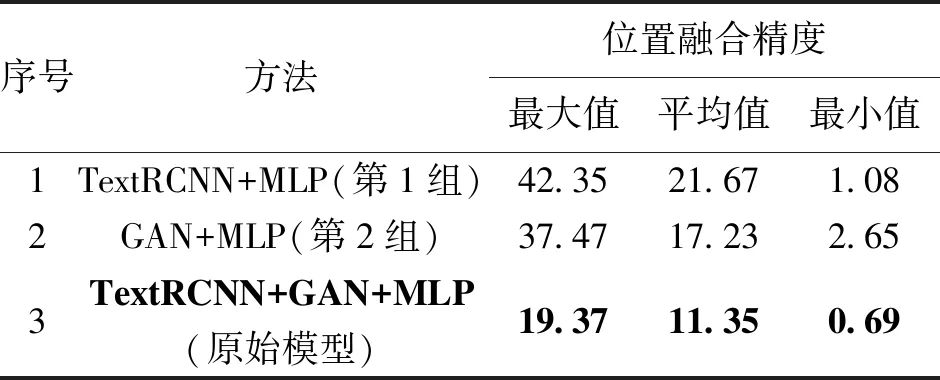
表4 消融试验对比结果 m
由表4可以看出,在第1组消融试验中,相比原始模型,其最大融合精度降低了22.98 m;平均融合精度降低了10.32 m;最小融合精度降低了0.39 m。在第2组消融试验中,相比原始模型,其最大融合精度降低了18.10 m;平均融合精度降低了5.88 m;最小融合精度降低了1.96 m。因此,可以看到取消TextRCNN和GAN任何一个网络都会严重影响位置融合精度。
4 结 论
针对不同POI数据源之间位置编码的差异与定位误差,本文提出了一种顾及地址语义和地理空间特征的多源POI位置融合方法。该方法使用了TextRCNN、GAN和MLP网络模型提取地址属性和位置属性的语义特征和地理空间特征,并基于自注意力机制的聚合特征实现多源POI数据的位置融合。最后,对成都市范围内的百度地图、腾讯地图和高德地图中的同名POI数据进行位置融合试验,其平均位置融合精度优于12 m。尽管本文提出的方法取得不错的融合精度,但还是存在一些局限性。如本文只考虑了地址要素之间的拓扑包含关系,但除此之外还有相邻、相交、相接等关系。因此,在未来的研究中需要对GAN网络的图结构进行优化。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
计算机与生活(2018年3期)2018-03-12
传媒评论(2017年3期)2017-06-13
中国科技期刊研究(2017年2期)2017-05-14
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
浙江大学学报(工学版)(2015年2期)2015-05-30
大连民族大学学报(2015年2期)2015-02-27
土木建筑工程信息技术(2013年4期)2013-10-17
