
QV-Electra: 引入Query-Value注意力机制的预训练文本分类模型
2023-12-06 02:41邵党国孔宪媛郭军军
中文信息学报 2023年9期
邵党国,孔宪媛,相 艳,安 青,黄 琨,郭军军
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
文本分类是自然语言处理的基础任务。随着Web 2.0时代的到来,互联网文本数量爆发式增长。对文本准确的分类有着巨大的经济价值和社会意义, 如对商品评论正确分类可应用于商品推荐和商品改进等方面,而对文本质量的分类则可用于筛选低俗文本,有助于健康互联网环境的构建。
文本分类按照模型发展时间先后可以分为两个阶段,分别为基于词典统计的方法,基于机器学习的方法[1]。①基于词典统计方法的模型初步工作为手动构建情感词典。情感词典包含情感词、否定词、程度词等。该种方法首先需要对情感词设置合适的权重,并通过对文本包含情感词的权重进行计算来获得文本的最终得分。但该类方法存在灵活性低、分类效果差[2]的问题。②基于机器学习的方法随模型规模增大和特征提取能力增强而逐渐演化出深度学习。传统的机器学习方法包括决策树、k-means、SVM等。该类方法在训练时学习数据特征,构建分类模型。但该类方法存在特征稀疏、特征提取困难、维度爆炸等缺点。
目前文本分类的主流方法是基于深度学习的方法。而基于Transformer[3]的预训练模型因其效果好和仅需少量下游任务语料的特点而备受学界和业界关注。
随着深度学习的发展,词嵌入被正式引入自然语言处理任务中。2003年Bengio提出NMLM[4]模型,随后一系列词嵌入方法(如Word2Vec[5]、Glove、FastTest等)被提出。上述方法虽然可为文本提供数值化的表示方法,但无法解决词的唯一数值表示与一词多义之间的矛盾。为解决该问题Elmo[6]被提出,它采用双向长短时记忆网络(Long Short-Term Memory,LSTM)预训练,使得词向量可结合上下文来获取嵌入表示。2018年以后,基于注意力机制[3]的Transformer的预训练模型层出不穷,并且不断刷新自然语言处理各项任务的基线。
GPT[7]打开了无监督预训练任务与有监督微调任务结合的序幕,使得预训练好的模型能在下游任务上直接微调。BERT[8]首次将双向Transformer用于语言模型,使得该模型在语义提取上较GPT更加强大。Electra[9]因为其采用的Generator-discriminator预训练任务单词利用率为100%,使其在文本分类任务中相对于BERT能以更小的模型达到同样甚至更优的分类效果。
现有Transformer预训练模型均是基于注意力机制,而传统的注意力机制仅将Query-Key做运算而疏忽了Query-Value之间的相互作用。Wu[10]等人提出了一种引入Query-Value交互的注意力机制QV-Attention。且通过实验表明,QV-Attention在文本分类和命名体识别效果优于传统注意力机制。
本文的主要贡献如下:
(1) 将QV-Attention引入开源的预训练模型得到本文模型QV-Electra;
(2) 在3个中文数据集上实验,表明本文模型仅通过添加0.1%参数,分类效果优于多项分类任务基线模型。
1 Electra预训练模型介绍
预训练模型是基于特定的预训练任务,在大规模语料上训练深层Transformer网络结构从而得到一组模型参数。将预训练好的模型参数应用于后续具体的自然语言处理任务上微调模型参数,这些特定任务通常被称做“下游任务”。
掩码语言模型(Masked Language Model,MLM)是一种常见的预训练任务。多个预训练模型(如BERT、ALBert、ROBERT、ENRIE)均采用了该预训练任务。MLM预训练任务类似于完形填空,即在预训练阶段随机掩盖输入文本的部分词语,在输出层获得被掩盖位置词语的概率分布,进而通过最大化似然概率来优化模型参数。
如BERT预训练模型,随机选择输入文本序列中的15%的词以供后续替换,但并非将这些词全都替换为[MASK]。其中,10%的词被替换为随机词,10%的词不做改变,另外80%的词被替换为[MASK][8]。上述引入随机词的操作可以理解为通过引入随机噪声来提升模型的鲁棒性。
Electra预训练模型提出一种新的预训练任务和框架,将生成式的MLM预训练任务改成判别式的替换词语检测(Replaced Token Detection,RTD)预训练任务,判断当前Token是否被语言模型替换过。
Electra按照模型可分为生成器和判别器。生成器的作用与MLM相同,预测被替换为[MASK]的词生成完整的文本,通常使用小型MLM预训练模型如BERT-small等,而判别器则是预测经过生成器补全的文本中哪些Token是被生成器生成的。这有点类似对抗学习,但与对抗学习不同的是,判别器的输出结果没有参与生成器的梯度更新。(具体训练任务见图1)。
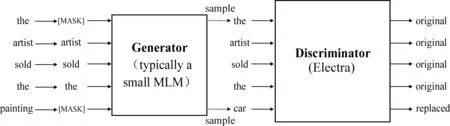
图1 Electra预训练任务图
由于Electra预训练Token均参与预训练任务,而如BERT仅15%不到的Token被替换为[Mask]。如文献[9]所述Electra-small的参数量仅为BERT-base的1/10,但分类效果优于BERT-base,故选择Electra预训练模型来完成分类任务是可取的,特别是二分类任务。
本文模型为研究QV-Electra的中文文本分类任务,故使用哈尔滨工业大学于2020年10月开源的Electra-180 GB-base[11]的中文预训练模型,该模型在180G中文语料上预训练。Electra-180G-base模型生成器参数量大约为1 000万,而判别器参数量大约为1亿。
2 QV-Attention机制
注意力机制在各种Transformer预训练模型中扮演至关重要的作用。Attention可以表述为一个三元函数,通过计算Query和Key之间的注意力权重加权到Value中将Key,Query,Value映射到输出。Attention机制如式(1)所示。
(1)
与Query,Key 交互类似,Query和Value之间也存在内在的相关性,结合Query和Value交互可以通过根据Query和Value的特征学习定制来增强输出。但是现有的注意力机制忽略了Query-Value的交互作用,可能不是最优的。如文献[10]中,注意力网络用来学习新闻文本的表示,用于新闻推荐,Query是用户嵌入表示,Value是该用户点击新闻中单词的表示。在这种情况下,可以使用Query和Value之间的交互来根据用户特征调整单词的表示,以学习更好的个性化新闻表示。
Wu等[10]提出一种新型的注意力机制QV-Attention。通过引入Query和Value之间的交互来增强传统Attention机制的语义表征能力,并根据原文实验可知QV-Attention相对于原始Attention在命名实体识别和文本分类任务上性能均有提升。
QV-Attention相对于传统Attention机制在英文AG数据集和Amazon文本分类任务上准确率提升了0.3%和0.8%。为进一步适应分类任务且减少参数量,将原文QV-Attention计算公式稍作改动得到本文QV-Attention计算公式,如式(2)~式(6)所示。
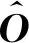
3 QV-Electra模型
如前所述,Electra模型可分为生成器和判别器两部分。而下游分类任务仅需使用判别器,故本文仅对哈尔滨工业大学开源官方预训练模型Electra-108G-base/discriminator[11]做修改,而忽略Electra-180G-base的Generator模型。
基于Transformer的各种预训练模型可以视为深度Attention层堆叠的网络模型。具体可见图2,图中将Electra-180G-base/discriminaton中Attention层修改为QV-Attention层。

图2 QV-Electra文本分类模型图
观察图2可知,原始预训练模型Electra-base网络主要结构为堆叠的12层Transformer块,而每个Transformer的语义提取能力来源于Attention层,所以Attention机制在预训练模型中起着至关重要的作用。因此注意力机制的改善将有利于提高预训练模型的性能,而QV-Attention机制在语义表征上理论上强于Attention机制。
注意观察式(3)和式(5),β由式(5)计算得来,调节着Query-Value交互计算得到的值与原始Value输入值的聚合比率。当β=0时,QV-Attention层中g(Q,V)完全使用Query-Value交互计算得到的值。而当β=1时,g(Q,V)则完全使用原始输入值Value,那么此时QV-Attention退化为传统的Attention机制。β值由网络模型学习得到,由万能逼近定理可知当某分类任务无须使用Query-Value交互的注意力机制,则网络将会把β调整至0。而此时QV-Attention机制将会退化为传统Attention机制,而QV-Electra模型也会退化为原始Electra模型。从理论上来说,本文模型QV-Electra的性能下界为原始的Electra,这是本文的理论基础。而从下文实验分析可知,QV-Electra的分类效果优于多项中文文本分类的基线模型,这进一步表明了本文模型的可行性。
上述理论保证在同样大小预训练语料上将Electra所有Attention层改为QV-Attention层所得的预训练模型,理论上其特征提取能力强于原始Electra预训练模型。
但重新预训练一个模型成本高昂,QV-Attention机制相对于传统Attention机制仅增加少许参数。故本文提出一种新的基于QV-Attention的QV-Electra预训练文本分类模型,该模型与Electra/discriminator模型保持一致的模型结构,只是将每个Transformer块中的Attention层替换为QV-Attention层。并读取Electra/discriminator预训练参数,将每层QV-Attention新加入参数采用高斯初始化并在下游任务中以较大的学习率来学习。
4 实验结果及分析
4.1 实验环境
本文实验环境及其机器配置如表1所示。
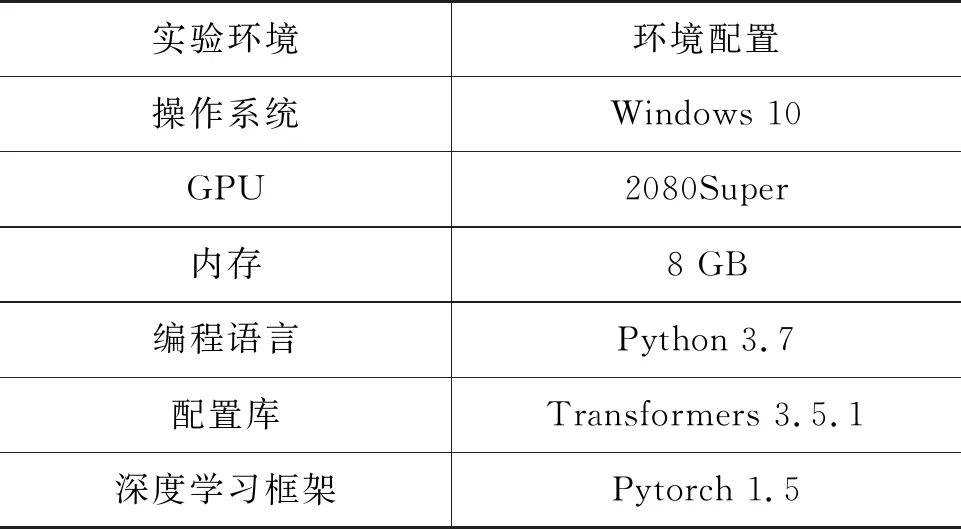
表1 配置表
4.2 数据集和评价指标
为验证本模型的可行性,本文采用携程酒店评论数据集ChnSentiCrop,微博评论数据集NLPCC2014,搜狗新闻数据集SogouNews。由于数据集没有明确划分训练集和测试集,本文对上述数据集均采用10折交叉验证。其中携程酒店评论数据集、新浪微博评论数据集分类任务为二分类: 正向和负向。而搜狗新闻数据集任务为四分类任务: 文化、财经、军事、运动。具体数据信息如表2所示。
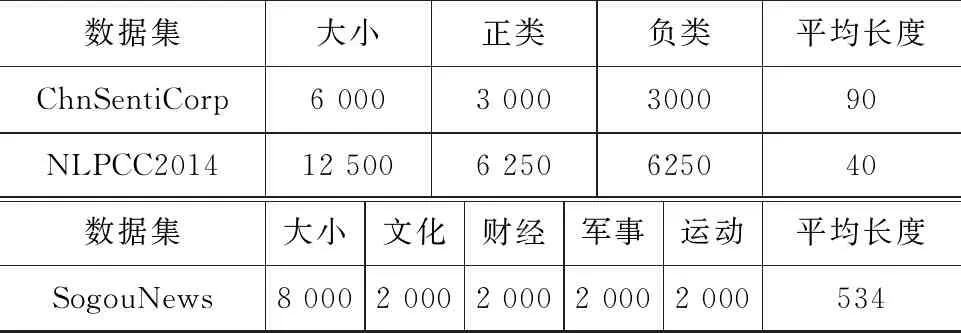
表2 数据集介绍
本文采用四个评价指标: 准确率(Accuracy)、精确率(Precision)、召回率(Recall),具体计算如式(7)~式(10)所示。
TP为预测为正向实际上预测正确的样本数目,TN为预测为负向实际上预测正确的样本数目,FP为预测为正向实际上预测错误的样本数目,FN为预测为负向实际上预测错误的样本数目。
4.3 实验超参数设置
本文模型参数可以分为两部分: ①原始Electra读取参数; ②QV-Attention新加入参数。本文实验将上述两部分参数设置不同的学习率:①0.000 01; ②0.000 05。而其他对比预训练模型学习率均设置为0.000 01。迭代次数(Epoch)设置为20,批次数(batchSize)设置为16。
4.4 实验结果分析
为检验模型的效果,本文将与多个深度学习方法进行对比,基准模型分别包括: 卷积神经网络(CNN)[12-13],循环神经网络(RNN)[14],双向长短时记忆网络(BiLSTM)[15],预训练模型BERT-base[16],预训练模型Electra-180G/discriminator[11]。表3列出6种模型在上述三个数据集上的实验结果。
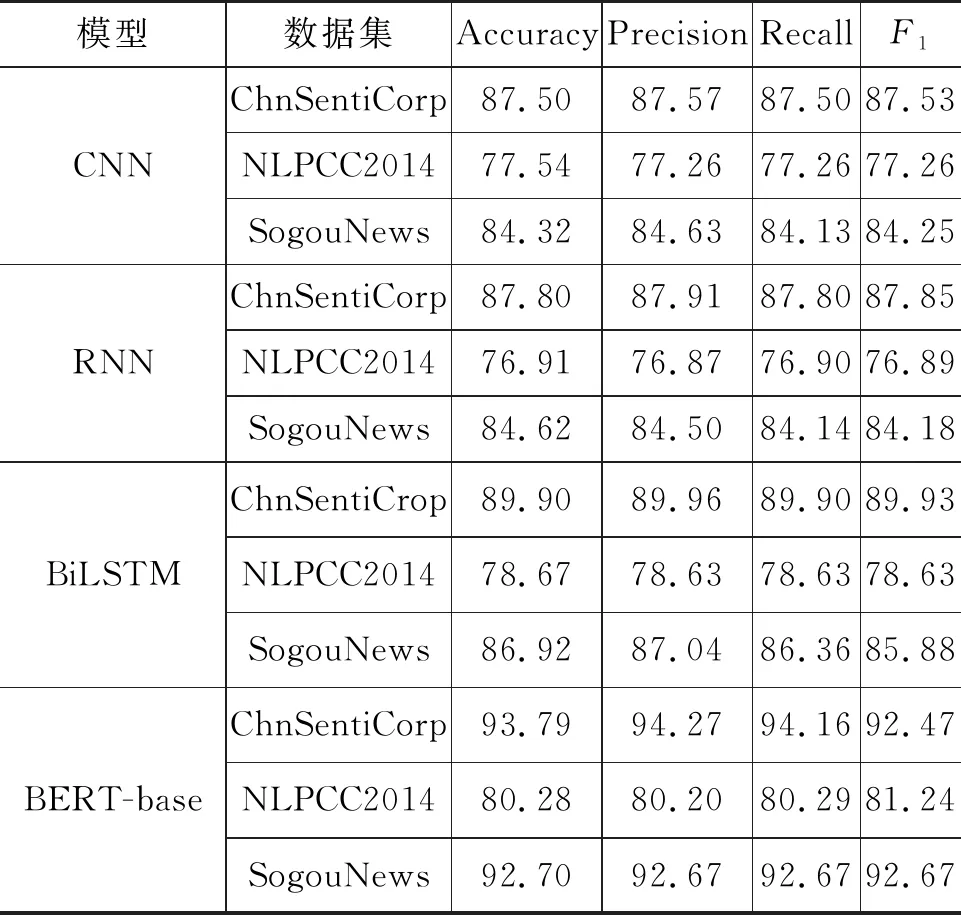
表 3 模型结果对比 (单位: %)
通过对比实验发现,本文模型在上述三个数据集上4个评价指标均相对于上述5种基线方法有所提升。ChnSentiCorcuracp数据集上Accuracy相对于CNN,RNN,BiLSTM,BERT-base,Electra分别提高了8.35%,8.05%,5.95%,2.06%,0.58%。而在NLPCC2014微博数据集上Accuracy相对于上述5个基线模型分别提高了5.99%,6.62%,4.86%,3.25%,1.99%。而在文本长度较长的SogouNews新闻数据集上Accuracy相对于上述5个基线模型分别提高了9.99%,9.69%,7.39%,1.61%,0.81% 。
比较CNN、RNN、BiLSTM和BERT、Electra效果发现,基于Transformer的预训练模型效果优于使用word_embedding后接初始化参数模型(RNN、RNN、BiLSTM)的效果,这是因为Transformer预训练模型强大的深层Attention网络结构和在大规模语料上预训练而获取的语义表征能力。
而对比QV-Electra和BERT,Electra模型的实验效果显示QV-Electra的分类效果较BERT和Electra有略微提升,这表明引入QV-Attention的预训练Transformer模型语义表征能力强于基于Attention的Transformer的预训练模型,即便QV-Electra并非重新预训练而来。
为验证本文模型性能提升不是因为在QV-Electra新加入参数以较大学习率导致,本文在搜狗新闻数据集上对本文模型QV-Electra所有参数学习率均设置为0.000 01,得到四项指标分别为: 94.31%,94.42%,94.34%,94.28%。与实验结果表3对比,发现在相同的学习率情况下,QV-Electra分类效果均优于上述多项基线模型,这表明本文模型QV-Electra本身的性能优于上述基线模型。而对QV-Electra新添加参数适当增大学习率可以进一步提升模型效果,这表明对新加入参数以较大学习率微调是正确的。
上述对比实验表明,本文模型QV-Electra在3个数据集上(囊括两个短文本数据集和一个长文本数据集)均优于非Transforemer结构的神经网络模型和现有同等参数规模的预训练模型,且在长短文本上提升效果幅度类似。这表明本文模型应用于中文文本分类任务是可行的。
5 结论
本文在官方开源模型Electra的基础上,将Attention机制修改为QV-Attention机制,在0.1%参数提升(新加入参数规模约为10万,官方模型参数规模为1亿)的基础上获得性能提升。
该改进几乎没有额外的算力及时间消耗,仅需与原始训练模型Electra一样在下游任务中微调网络参数。这在预训练模型规模爆发式增长(如GPT 1,2,3三代参数分别为1亿,15亿,1500亿)的如今为算力所限的个人或机构提供一种新的思路。
本文模型在短文本评论数据集和长文本新闻数据集上实验,结果表明,本文模型相较于多项分类基线模型效果更优。这说明本文模型在中文分类任务上是有效且有意义的。后续工作中,我们考虑将本文模型应用于其他语言的文本分类任务以及其他自然语言处理任务中去。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
当代体育科技(2020年9期)2020-05-12
数学物理学报(2019年6期)2020-01-13
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
当代体育科技(2019年33期)2019-01-14
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
数学物理学报(2017年5期)2017-11-23
兵器知识(2017年8期)2017-10-16
初中生世界·七年级(2017年9期)2017-10-13
