
基于跨语言词嵌入对齐增强少数民族预训练语言模型
2023-12-06 02:41申影利赵小兵周毛克
中文信息学报 2023年9期
申影利, 鲍 薇, 赵小兵, 周毛克
(1. 中央民族大学 中国少数民族语言文学学院,北京100081;2. 中国电子技术标准化研究院,北京100007;3.中央民族大学 信息工程学院,北京100081;4.国家语言资源监测与研究少数民族语言中心,北京100081)
0 引言
随着深度学习的快速发展,基于神经网络的词嵌入(Word Embeddings)成为单词分布表示的主流方法。从海量未标注的语料中学习词嵌入的过程被称为预训练,而经由预训练更新过参数的语言模型及其学习到的词嵌入则被称为预训练语言模型(Pre-trained Language Models,PLMs)[1]。早期以Word2Vec(CBOW、Skip-gram)[2]、Glove[3]为代表的静态词嵌入(Static Embeddings)预训练语言模型PLMs专注于学习词嵌入表示,但只能将词语映射到一个上下文无关的静态词表示空间上,无法解决一词多义等问题,并且在下游任务中仍要从零学习上下文信息。为了解决上述问题,以ELMo[4]、GPT[5]、BERT[6]引领的上下文词嵌入预训练语言模型(Contextual Embeddings PLMs),可以将词汇的语境信息融入其表示中,并从各个方面提升了预训练模型的效果。
最近,以XLM-R[7]为代表的上下文词嵌入预训练语言模型表现出惊人的跨语言能力,在多项跨语言理解任务中的应用刷新了最好性能记录。然而这种性能在很大程度上取决于跨语言词嵌入的对齐质量,相比于近距离语言对(如英语、德语),跨语言迁移能力在语言差异性较大的远距离语言对(如汉语与国内少数民族语言)上表现很差。另一方面,尽管静态词嵌入的表示能力不如上下文词嵌入,但静态词嵌入对齐[8-9]已经得到了很好的研究,通过简单的映射就可以产生高对齐质量的跨语言词嵌入表示,而由于上下文词嵌入具有动态特性,为跨语言对齐工作带来一定的挑战。
近期,哈工大讯飞联合实验室[10]基于跨语言预训练模型XLM-R,在多种国内少数民族语言语料上进行了二次预训练,发布了首个面向少数民族语言以及汉语的多语言预训练模型CINO(Chinese Minority Pre-trained Language Model)(1)https://github.com/iflytek/cino,填补了民族语言预训练模型这一研究空白。为了改善预训练语言模型在汉语与少数民族语言这类远距离语言对上的跨语言迁移效果,我们在面向少数民族语言的跨语言预训练模型CINO的基础上,探讨如何结合静态词嵌入、上下文词嵌入各自的优势,来提高民汉双语空间的对齐质量,以促进自然语言处理技术更好地迁移到资源稀缺的民族语言信息化处理任务中。
本文的主要工作包括:
(1) 提出了一个将静态词嵌入对齐到少数民族预训练语言模型CINO上下文词嵌入空间中的新框架,以进一步提升CINO预训练模型在下游任务中的表现。
(2) 通过设计双语词典归纳损失、对比学习损失两个损失函数,改善民汉远距离语言对的跨语言对齐表示。
由于国内少数民族语言资源主要集中在蒙语、藏语以及维吾尔语,因此,我们在蒙语-汉语、藏语-汉语、维吾尔语-汉语三种远距离语言对上开展相关实验。结果表明,与多个鲁棒的基线系统相比,本文提出的基于跨语言词嵌入对齐的少数民族预训练语言增强模型,应用到双语词典归纳、文本分类以及机器翻译下游任务中均取得了一致的效果提升,验证了方法的有效性。
1 相关工作
为了将模型从资源丰富的语言迁移到资源匮乏的语言上,早期的工作通常利用大规模单语语料训练静态词嵌入进行跨语言对齐研究,使用简单的映射(包括线性映射[11]与非线性映射[12])就可以生成高质量的跨语言词嵌入。特别地,静态词嵌入在许多低资源场景具备无法替代的优势: 无须使用大型标注数据,采用无监督学习就能获得良好的词表示。例如,Conneau等人[13]提出了无监督的跨语言词对齐MUSE框架,通过对抗学习将两个单语词向量空间对齐,不断迭代更新映射矩阵来建立两种语言之间的双语词典。Artetxe等人[14]提出了跨语言词嵌入映射框架VecMap,在不需要监督信号的情况下学习跨语言词嵌入映射,在标准数据集上的结果甚至超越了之前的监督系统。但是这种词嵌入是静态的,一个单词对应唯一的词向量表示,不会随着新的上下文而变化,因而在许多应用中逐渐被上下文词嵌入对齐所取代。
相比静态词嵌入,上下文词嵌入可以根据上下文语境动态地获得每个单词的上下文表示,从而获得更加合理和灵活的词嵌入,在多语言及跨语言任务上表现出色。目前,上下文跨语言词嵌入对齐工作通常依赖于平行语料或可比语料库。例如,Aldarmaki等人[15]将学习到的句子级别对齐的映射关系应用到单词级上下文词嵌入;Nagata等人[16]将词对齐作为一项任务,并利用词对齐训练数据对模型进行微调;Gritta等人[17]使用机器翻译平行语料库提升跨语种预训练语言模型XLM-R关于特定任务的对齐效果。然而,尽管上下文表示包含丰富的语义信息,但也正是由于其动态特性,词级别的跨语言对齐表现仍然不能超过静态词嵌入。
为了充分利用静态词嵌入和上下文词嵌入之间互补的优势,Zhang等人[18]提出结合静态词嵌入和上下文词嵌入的相似性插值运算实现跨语言词嵌入对齐,在有监督及无监督双语词典归纳任务上带来一定的性能提升。随后,Hämmerl等人[19]在40种语言上结合静态词嵌入和上下文词嵌入来改进多语言词嵌入对齐表示,并在问答系统、序列标记、信息检索任务上验证了有效性。
由于国内少数民族语言自身的特点,如蒙古语族的蒙古语动词变化丰富、藏缅语族的藏语黏着性强以及突厥语族的维吾尔语借词丰富,导致民汉单语语义空间差异性大。而上述相关研究方法的性能在很大程度上取决于跨语言词嵌入的对齐质量,这对国内少数民族语言与汉语之间这类数据不平衡以及远距离语言对并不友好;另一方面,目前专门针对民汉跨语言词嵌入的研究相对匮乏,这严重阻碍了跨语言应用在民族语言上的发展。因此,本文提出一种基于跨语言词嵌入对齐的少数民族预训练语言增强模型,促进预训练语言模型在低资源、远距离语言对上的迁移应用,以期为相关研究提供参考。
2 方法
为了充分利用静态词嵌入的鲁棒性以及上下文词嵌入包含的丰富句法及语义信息,改善民汉跨语言词嵌入的对齐质量。本文提出一个将静态词嵌入对齐到基于CINO模型抽取出来的上下文词嵌入空间的新框架。具体地,本文方法分为三步: 首先,将两种大规模单语语言的静态词嵌入进行跨语言对齐;其次,给定民汉平行句对,从CINO模型中抽取上下文词嵌入,并设计两种损失函数(双语词典归纳损失、对比学习损失)将静态词嵌入对齐到上下文词嵌入的语义空间中;最后,将经过跨语言词嵌入对齐的CINO增强模型应用于资源匮乏的民族语言下游任务(如双语词典归纳、文本分类、机器翻译等)。以蒙语-汉语这一语言对为例,本文提出的模型框架如图1所示。在这一部分中,首先介绍本文用到的符号定义(2.1节),再介绍静态词嵌入的跨语言对齐方式(2.2节)以及将其对齐到上下文词嵌入空间所设计的两种损失函数(2.3节)。
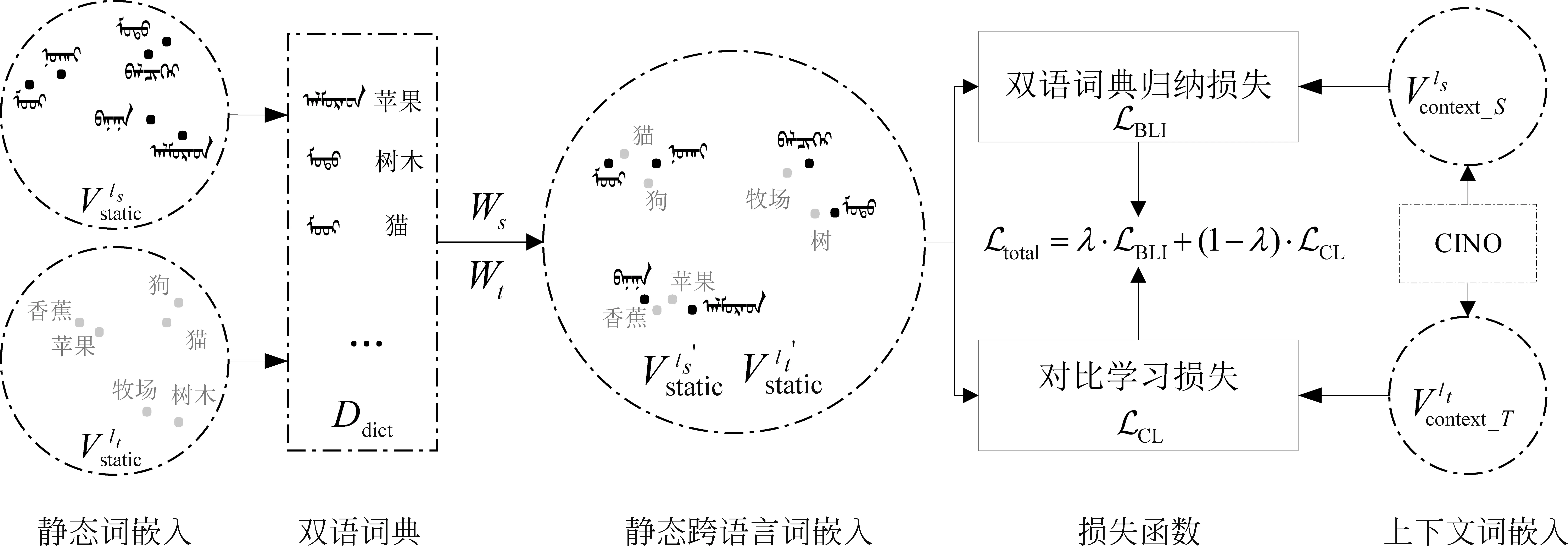
图1 模型架构图
2.1 符号定义

2.2 单语静态词嵌入的跨语言对齐
近年来,一些工作[13-14]在研究没有任何监督信号的情况下,采用从源语言到目标语言的单向映射实现双语空间对齐。但是,他们所提出的方法在很大程度上依赖于两种语言相似的语言特性,即两种语言之间含有大量的词汇重叠。然而,国内少数民族语言与汉语之间不存在任何词汇重叠,并且语言形态不同,属于远距离语言对。因此,受语法、构词上的差异及单语训练语料主题不一致等因素的影响,汉语与国内少数民族语言的单语词嵌入空间并不同构,而传统单向投影的跨语言词嵌入方法没有考虑这种差异性带来的影响,导致最终获取到的民汉跨语言词嵌入效果不佳。另一方面,在赖文等[20]的工作中对少数民族语言与汉语之间的跨语言词向量进行了深入研究,他们发现,少数民族语言与汉语之间的无监督跨语言词嵌入的性能极差,但是在加入少量的双语词典作为监督信号时,会极大改善跨语言词嵌入的表现。因此,本文参照相同思路,利用少量的双语词典,提升了跨语言词嵌入对齐的性能。

(1)
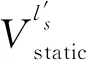
(2)
2.3 词嵌入对齐下的预训练语言增强模型
在2.2节获得两种单语语言对齐的静态跨语言词嵌入之后,我们研究如何将对齐后的静态词嵌入进一步对齐到少数民族预训练语言模型CINO的上下文词嵌入中。为此,本文设计了两个目标损失函数: 双语词典归纳损失和对比学习损失。下面将分别详细介绍这两种损失函数。
2.3.1 双语词典归纳损失
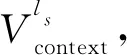
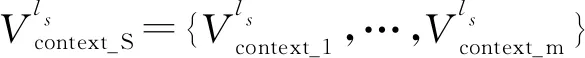
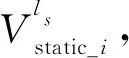
最终,我们设计的双语词典归纳损失函数如式(5)所示。
LBLI=Distance+Coverage
(5)
2.3.2 对比学习损失
对比学习(Contrastive Learning)[21]目的是: 将模型中语义相似的实例(正样本)在词嵌入表示中尽可能地接近,而偏离那些语义不同的实例(负样本),所以如何构建正样本和负样本成为对比学习中最关键的问题。对于正样本,已经对齐的目标语言单词即为正样本;在语义上相近但是并没有对齐的单词即为负样本。更具体地,对于一个单词ws,我们将集合Cstatic中除wt以外的单词作为负样本。
本文采用了InfoNCE损失[22],这是一个在对比学习研究中普遍使用的一个损失函数。我们将该损失结合目标实现了静态词嵌入与上下文词嵌入的对齐。具体地,目标函数表示如式(6)所示。
(6)
其中,sim(·)计算的是两个向量之间的余弦相似度,+和-分别表示正例和负例,R(s)(表示单词的上下文词向量,τ是一个温度系数,使用它来控制鉴别正例和负例的难度(τ越大表示从负例中鉴别正例的难度越大)。
2.3.3 静态词嵌入的跨语言对齐
我们最终的训练目标由2.3.1和2.3.2节的两部分损失函数进行迭代优化,如式(7)所示。
Ltotal=λ·LBLI+(1-λ)·LCL
(7)
其中,λ为超参数(我们将在5.3节中对该超参数进行分析),来详细说明双语词典归纳损失、对比学习损失对总体损失的重要程度。
3 实验
3.1 数据
单语数据集汉语单语数据来自CCMT2021(3)http: //sc.cipsc.org.cn/mt/conference/2021/,使用Jieba(4)https://github.com/fxsjy/jieba分词。由于目前缺少开源的大规模蒙语、藏语以及维吾尔语的单语数据,所以我们对相关民族语言文字网站进行语料爬取,通过句子切分、过滤掉含有乱码的句子、去重、Moses(5)https://github.com/moses-smt/mosesdecoder/tree/master/scripts预处理等步骤,最终构建了1 000万句汉语、蒙语、藏语以及维吾尔语的单语语料库,用于单语静态词嵌入的训练。
双语数据集本文使用第17届全国机器翻译大会(CCMT2021)提供的蒙汉、藏汉以及维汉机器翻译平行句对,通过CINO模型抽取上下文词嵌入。
3.2 实验设置
我们使用FastText(6)https://github.com/facebookresearch/fastText/对汉语、蒙语、藏语以及维吾尔语四种单语语料进行静态词嵌入训练,词嵌入维度设为300。对于上下文词嵌入,本文使用X2Static[23]工具分别对少数民族预训练语言模型CINO的base和large版本抽取获得,该工具即使利用少量数据也能取得更好的效果,其中当使用CINO-base时,词嵌入维度为768;使用CINO-large时,词嵌入维度为1 024。同时,我们使用词对齐工具Fast_Align(7)https://github.com/clab/fast_align从民汉平行句对中获得所有翻译词对,并作为额外知识指导不同语言之间的词嵌入的对齐训练。
3.3 下游任务
预训练上下文语言模型在大量未标注的语料上进行预训练,能够获得通用的词嵌入表示,然后应用到下游任务中,并根据任务的特点进行微调以修正网络,这种预训练加微调的方式不仅能大幅度提升下游任务性能,而且避免从头训练的额外开销。以下内容将依次评估我们提出的基于跨语言词嵌入对齐的少数民族预训练语言增强模型CINO在双语词典归纳、文本分类以及机器翻译三个下游任务中的表现。
4 实验结果
4.1 双语词典归纳
在有监督双语词典归纳任务中,我们使用的双语词典来自本实验室经相关母语专家人工标注及校正的蒙汉、藏汉以及维汉词典。由于上述民汉词典中的一些词语不一定出现在单语语料库中,所以需要进一步抽取出全部包含在单语数据集中的词组。最终,我们筛选出蒙古语、藏语、维吾尔语与汉语之间相互6个方向的双语词典,并在词典具有唯一的源语言单词的情况下,划分为5 000对训练集、1 000对验证集及测试集。该任务的基线系统包括:
(1)MUSE[13]: 基于普氏分析(Procrustes analysis,PA)[24]执行对齐算法归纳种子词典,使用对抗的方式学习映射矩阵。
(2)VecMap[14]: 一个学习双语词嵌入的通用框架,包括: 归一化、白化、正交映射、重加权、去白化和降维等步骤。
(3)RCSLS[25]: 通过优化跨域相似性局部缩放(Cross-domain similarity local scaling,CSLS)损失[13],学习非正交映射,其目标函数直接面向双语词典归纳任务。
(4)InterpolationRCSLS[18]: 提出一种spring network来拉近翻译词对的词嵌入距离,并建立静态双语词嵌入和上下文双语词嵌入相结合的统一词表示空间,随后在统一词表示空间和上下文词嵌入空间之间执行相似性插值运算。
(5)X2S-MA[19]: 从XLM-R中提取静态词嵌入X2S-M,并使用VecMap对其进行对齐获得X2A-MA,再通过对齐损失将X2S-MA更好地对齐XLM-R的表示空间,我们利用这个方法在CINO模型上进行实验。
(6)CINO[10]: 通过少数民族预训练语言模型CINO(包括base、large版本)编码整个句子并抽取每个单词的上下文词嵌入表示,我们参照基线(5)使用VecMap(8)https://github.com/artetxem/vecmap工具进行对齐。
表1展示了基于跨语言词嵌入对齐的CINO模型与基线在双语词典归纳任务上的实验结果。实验分为四组: ①静态词嵌入跨语言对齐(MUSE、VecMap和RCSLS); ②预训练语言模型CINO抽取的上下文词嵌入跨语言对齐(CINO-base、CINO-large); ③结合静态词嵌入与上下文词嵌入的跨语言对齐(Interpolation、X2S-MA); ④文本提出的静态词嵌入对齐到CINO模型上下文词嵌入的跨语言对齐(Our-CINO-base、Our-CINO-large)。评价指标使用词汇对齐的准确率P@k,选取k=1,5,即P@1、P@5表示基于跨语言词嵌入的源语言中的某个单词中寻找最近邻的1,5个单词,有多大的概率是在词典测试集的目标单词中。
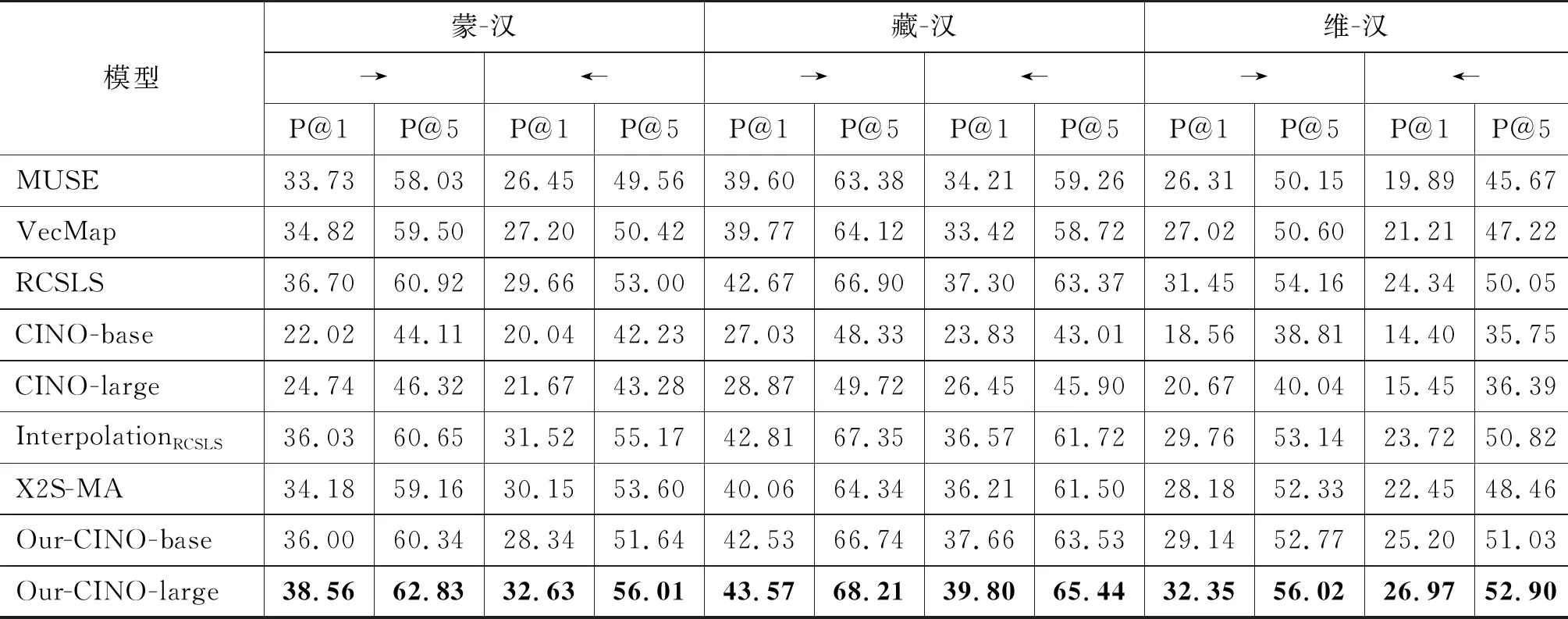
表1 双语词典归纳任务实验结果 (单位: %)
通过表1的实验结果,可得出以下结论:
(1) 预训练语言模型抽取的上下文词嵌入(表中CINO-base和CINO-large)在没有任何辅助信息的情况下,词嵌入对齐准确率远不如静态词嵌入对齐(MUSE、VecMap和RCSLS),这是因为预训练模型是在大规模单语语料中训练获得并且其预训练目标为一些常规的掩码语言模型,并不是如双语词典归纳这种严格的词级别的对齐任务。
(2) 相比于从预训练语言模型中抽取的上下文词嵌入对齐,结合静态词嵌入与上下文词嵌入的跨语言对齐(InterpolationRCSLS和X2S-MA)表现出较好的性能,但是在民汉语言对上,由于语言差异性大(如藏语的黏着性及曲折性变化、维吾尔语的形态丰富性等)而表现出不稳定性,即并不能超过所有的静态词嵌入基线。
(3) 本文提出的方法,在双语词典归纳任务中具有更优秀的表现,其中Our-CINO-large方法超过了以上基线系统的对齐性能,这归功于我们设计的双语词典归纳损失,进一步提高了民族语言与汉语这类远距离语言对的跨语言词嵌入对齐准确率。
4.2 文本分类
Yang等人[10]为了评估少数民族预训练语言模型CINO的跨语言及多语言能力,根据少数民族语言维基百科语料及其分类体系标签,首先构建了分类任务数据集Wiki-Chinese-Minority(WCM),以及后来的WCM-v2(9)https://github.com/iflytek/cino版本调整了各类别与语言的样本数量,分布相对更均衡。该数据集覆盖蒙古语、藏语、维吾尔语、粤语、朝鲜语、哈萨克语以及汉语普通话,包括艺术、地理、历史、自然、自然科学、人物、技术、教育、经济和健康十个类别,并在汉语训练集上训练模型,在其他语言上进行zero-shot测试。
在该下游任务中,我们同样使用少数民族分类数据集WCM-v2训练我们提出的基于词嵌入对齐的预训练语言增强模型,并使用其中的蒙语测试集(2 973条)、藏语测试集(1 110条)以及维吾尔语测试集(300条)进行测试。基线包括: XLM-R的base版本、large版本以及CINO的base版本、large版本。
为了考虑民族语言资源匮乏导致类别分布不均衡问题,比如在300条维吾尔语测试集,除地理类别占据256条外,其他9个类别的样本数量为个位数或者是零样本。因此,在这种极度不均衡情况下,评价指标选取多分类评价指标weight-F1值(10)https://scikit-learn.org/stable/modules/generated/sklearn.me-trics. f1_score. html,即通过把每个类别的样本数量作为权重,计算加权F1值,以充分考虑不同类别的重要性。实验结果如图2所示,其中所有基线系统中的实验结果源自CINO模型的github(11)https://github.com/iflytek/cino公布的最新实验结果。
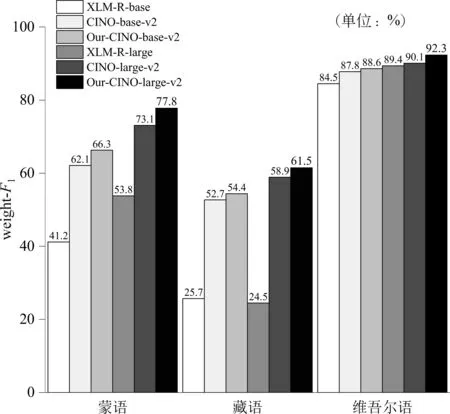
图2 WCM-v2数据集上文本分类任务实验结果
实验结果表明,本文所提出的方法在文本分类任务中性能表现良好,超过了所有的基线。具体地,在蒙语测试集(覆盖10个类别)上,weight-F1值相比基线中性能最优的CINO-large-v2模型提升4.7%;同时在维吾尔语测试集(仅覆盖6个类别)上,CINO-large-v2的weight-F1值已经达到90.1%,而我们的方法仍能进一步提高2.2个百分点。这一性能的取得很大程度上取决于我们设计的对比学习损失,因为对比学习使得模型中同一类别的句子在表示空间中比较接近,而不同类别的句子在表示空间中距离比较远。
4.3 机器翻译
在该任务中,我们使用CCMT2021蒙汉、藏汉、维汉的训练集、验证集以及CWMT2018(12)http: //www.cipsc.org.cn/cwmt/2018/测试集,选取神经机器翻译模型Transformer[26]以及在机器翻译任务上微调CINO模型作为基线,同时微调我们提出的预训练语言增强模型。评测指标为机器双语互译评估值(BLEU)[27],实验结果如表2所示。
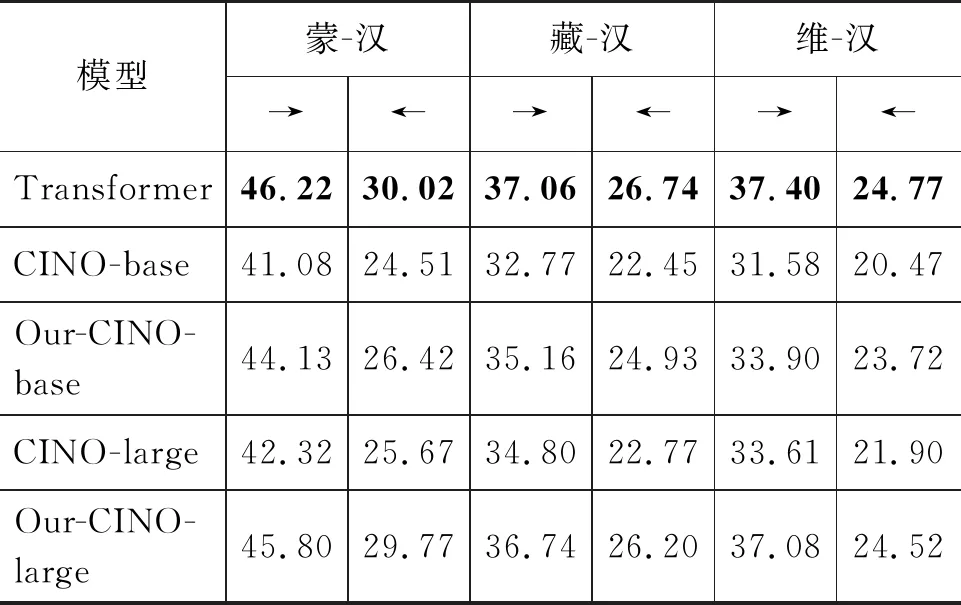
表2 民汉机器翻译任务实验结果 (单位: %)
由表2可知,虽然预训练语言模型(CINO-base和CINO-large)在许多跨语言任务中表现出很强的性能,但是在机器翻译这类传统的句子级别对齐的任务中表现稍差。原因在于,预训练语言模型是在大规模单语语料上训练获得的,尽管预训练加微调的方式能为低资源神经机器翻译模型提供更多的跨语言信息,其效果还是与有监督神经机器翻译模型Transformer有一定的差距。不过,本文方法仍能远远超过不经过任何修改的CINO系统,其中Our-CINO-large方法的翻译效果甚至可以与强大的Transformer基线相媲美。这主要归功于我们设计的两种损失函数将两种语言在词级别的层次上做了很好的对齐,使得预训练语言模型可以在机器翻译模型训练初期提供朴素的词对翻译信息,能够有效改善翻译质量。
5 分析
5.1 消融实验
为了提升CINO模型的跨语言词嵌入对齐效果,我们在2.3节中引入了双语词典归纳损失LBLI、对比学习损失LCL两个损失函数,为了探究哪个损失函数更重要,我们设计了两组实验进行验证。第一组实验,我们探究两个损失函数在双语词典归纳任务中的表现;第二组实验,我们探究两个损失函数在文本分类中的表现。我们将分别在5.1.1节和5.1.2节中分析这两组实验。
5.1.1 双语词典归纳任务
以维汉双语词典归纳任务为例,基于跨语言词嵌入对齐的预训练语言增强模型(Our-CINO-Large)的实验结果如表3所示。

表3 损失函数对维汉双语词典归纳的影响 (单位: %)
实验结果表明,在维吾尔语与汉语之间的词典归纳任务中,如果不添加所设计的两种损失函数,我们的模型尽管结合了静态与上下文词嵌入,但是总体效果无法超越表1中的静态词嵌入对齐(MUSE、VecMap和RCSLS)表现。而一旦引入双语词典归纳损失LBLI或者对比学习损失LCL后,双语词嵌入对齐效果会得到明显改善,其中LBLI对于性能的提升占据了主要的作用,例如,在维-汉方向P@1值相对提高5.68个百分点,远远超过LCL的作用(提升仅3.16个百分点)。此外,将两个损失结合能够进一步提升性能,但加入LCL后提升的效果没有LBLI明显。
5.1.2 文本分类任务
我们使用少数民族分类数据集WCM-v2,记录基于跨语言词嵌入对齐的预训练语言增强模型(Our-CINO-large)分别在蒙语、藏语、维吾尔语测试集上的表现,weight-F1值评价结果如表4所示。
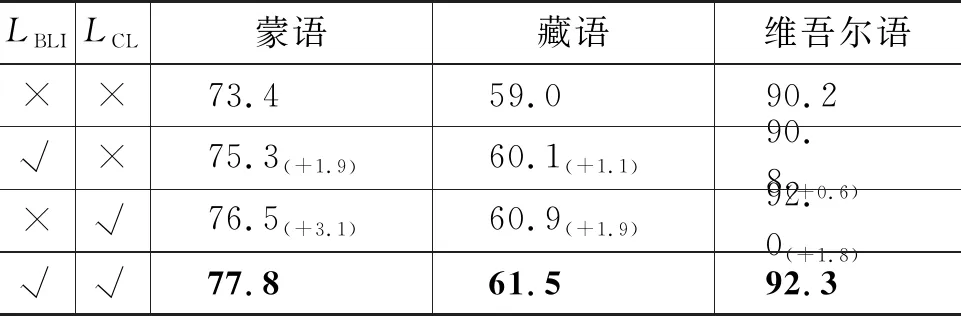
表4 损失函数对文本分类的影响 (单位: %)
实验结果表明,模型在引入双语词典归纳损失LBLI或者对比学习损失LCL损失函数后,文本分类的效果会进一步提高。其中,LCL起了更重要的作用,例如在蒙语测试集上,weight-F1值能够再增加3.1个百分点。这一实验现象与4.2节中的结论保持一致,即对比学习损失使相同类别的句子尽可能地接近,并分散不同类别的句子。
5.2 k的取值对实验结果的影响
在2.3.1节中,本文方法提到双语词典归纳损失中的超参数k,下面我们以藏-汉双向翻译任务为例,分析k的不同取值对实验性能的影响,使用BLEU值的评价结果如表5所示。
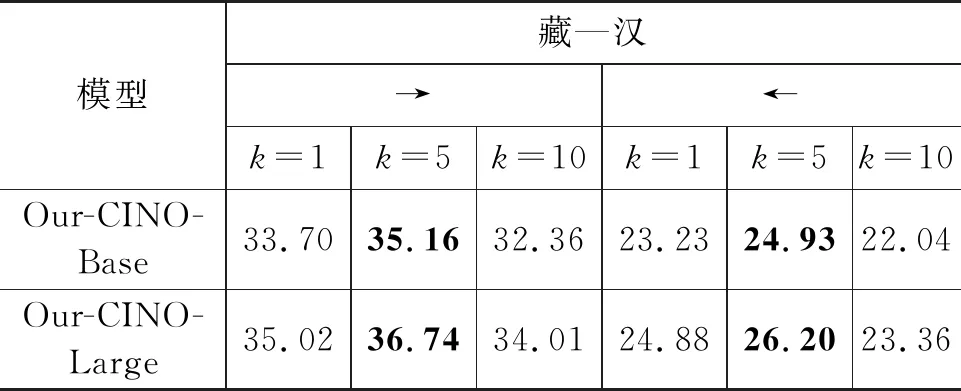
表5 k值对翻译性能的影响 (单位: %)
由表5可知,在k=5的取值下,我们的方法在base和large版本均中取得了最优的性能。这一现象符合我们的预期,因为,当k=1的时候,这种方式为严格的双语词对齐,表1中的实验结果同样显示其词对齐准确率不佳,所以对机器翻译任务没有很好的性能提升;当k=5时,这种方式在词的对齐层面取得了很好的效果,进而对机器翻译任务有了正面的提升。但是,当k=10时,因其在双语对齐任务中含有大量的噪声,在一定程度上阻碍了机器翻译任务的性能。
5.3 λ取值对实验结果的影响
在2.3.3节中提到训练目标中的超参数λ,分别对这个参数取不同的值,基于跨语言词嵌入对齐的预训练语言增强模型(Our-CINO-large),依次判断其在双语词典归纳、文本分类以及机器翻译各个任务中的重要程度,实验结果如图3所示。
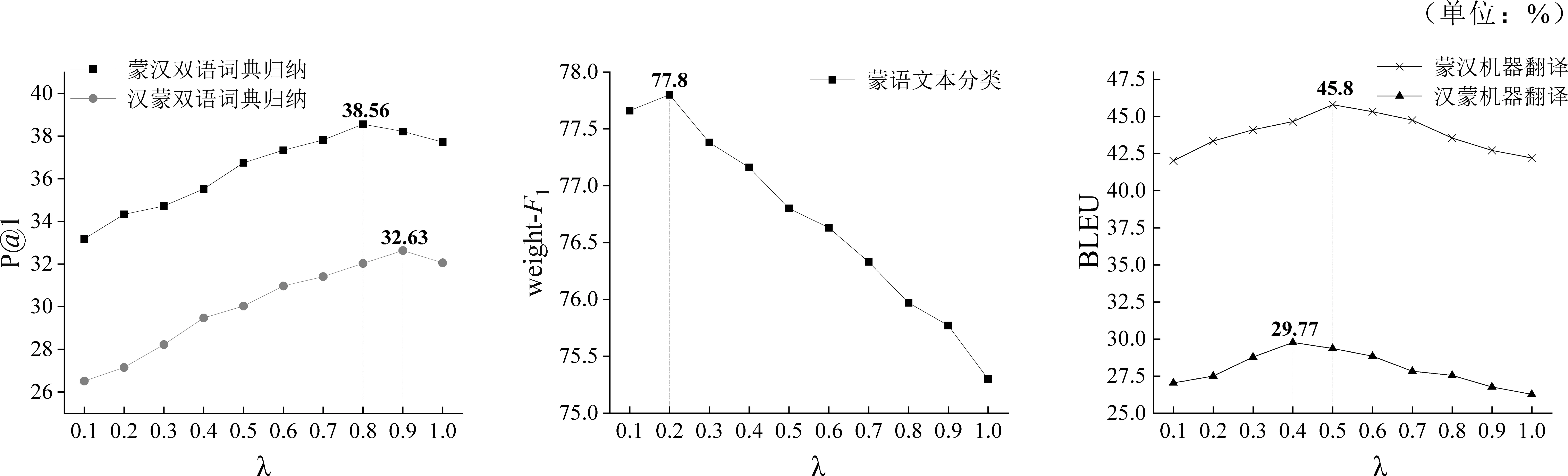
图3 λ对下游任务的作用程度
实验结果表明,λ的不同取值与5.1节中的结论保持一致:
(1)λ作为双语词典归纳损失LBLI的权重,随着λ取值的不断增大,LBLI占据了目标函数的主要成分,其词嵌入对齐提升的效果越加明显,即LBLI对双语词典归纳任务更重要。其中,最优超参数取值分别为蒙汉方向(λ=0.8)以及汉蒙方向(λ=0.9),表示LBLI、LCL两个损失结合,进一步提升了性能。
(2) (1-λ)是对比学习损失LCL的权重,因此文本分类效果随着λ的增大,整体呈现单调递减,即LCL对文本分类任务更加重要。其中,当λ=0.2时,蒙语文本分类性能达到最优。
(3) 与上述两个任务不同的是,我们发现,这两种损失在机器翻译任务中表现出相同的重要性,当λ取值约为中间值时,即两个损失函数在训练目标中的占比相当,蒙语与汉语互译方向的翻译效果达到最佳。
6 结论
针对民汉低资源场景下语言差异性大、跨语言词嵌入对齐效果差,导致预训练语言模型在下游任务中的迁移效果不佳的问题。本文提出将静态词嵌入对齐到少数民族预训练语言模型CINO的上下文词嵌入空间中的新框架,进一步提升下游任务的性能。我们通过设计双语词典归纳损失、对比学习损失两个损失函数将静态词嵌入对齐到CINO模型的上下文词嵌入,以提高远距离语言对的跨语言词嵌入对齐质量。此外,我们还进行了一系列更精细的评估、分析和消融研究。在蒙语-汉语、藏语-汉语、维吾尔语-汉语三种民汉远距离语言对上的实验表明,相比鲁棒的基线系统,本文方法充分结合了静态词嵌入和上下文词嵌入互补的优点,并在双语词典归纳、文本分类以及机器翻译下游任务中都实现了显著的性能提升,验证了本文方法的有效性。
猜你喜欢
云南画报(2021年8期)2021-11-13
文苑(2019年24期)2020-01-06
阅读(低年级)(2019年4期)2019-05-20
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
电子设计工程(2015年15期)2015-02-27
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
上海金属(2013年6期)2013-12-20
