
基于OCR 和图像检测的盖章文书图像自动审核方法
2023-12-04 02:59夏鹏程
应用科学学报 2023年6期
曹 菁,陈 康,齐 宁,夏鹏程,邱 渝
1.江苏省联合征信有限公司,江苏南京210000
2.南京大学软件学院,江苏南京210093
在金融业务数字化的过程中,企业所提交的盖章文书图像是十分重要的。通常,盖章文书图像中含有两种类型的信息,一种是以印章的形式出现,一种是以表格文档[1]的形式出现。相较于一般表格来说,盖章文书图像表格的格式更为复杂,内容繁多。随着金融业务数字化的快速发展,盖章文书图像的数量快速增加,现有的人工审核方式无法及时处理与日俱增的盖章文书图像审核工作,另外由于早期自动审核功能的缺失,盖章文书图像审核工作保有很大一部分存量,就江苏省某项目为例,待审核盖章文书图像数量已达30 万幅。此外,在对审核人员调研中了解到长时间重复性的审核工作,容易出现工作效率降低、审核错误率升高等问题,因此提供快速高效且有准确率保障的盖章文书图像自动审核线上服务十分迫切。
随着人工智能的发展,盖章文书图像审核领域有一定的研究成果,主要应用在金融和医疗领域,但对制式表格盖章文书图像自动审核尚无成熟的应用。随着深度学习的兴起,自动审核功能主要依托的文字识别(optical character recognition,OCR)[2]和印章识别技术也得以飞速发展。目前文字识别应用主要有阿里OCR、百度OCR、腾讯OCR、华为OCR 等,均提供不同场景的文字识别接口,主要针对受控场景,如票据、卡证、车牌等。表格文字识别主要应用于无印章的通用表格,针对带印章制式表格的文字识别效果并不好。考虑到盖章文书图像为人为拍摄或扫描上传,其中存在文字自身的复杂性问题(非水平、角度倾斜),文本检测有一定难度,针对此类场景文献[3] 提出了一种汉字检测算法(detecting text in natural image with connectionist text proposal network,CTPN)。此算法可以有效地检测水平或略微倾斜的文本行,但对于一些旋转的文本行,其检测效果比较一般,并且文本线的构造也是局限在矩形,当文本出现倾斜时,文本线的构造就不够精准。文献[4] 提出了一种适用于自然场景中的短文本的文本检测算法,对于旋转文本行的检测效果较好,但对盖章文书图像中存在的部分长文本的检测不够准确,并且模型的经验相对有限,这直接影响后面文本识别的准确性。目前针对水平文本的识别算法主要分为两种,一种是文献[5] 提出的基于attention 机制识别算法,主要应用于不规则排列的文字识别问题;另一种为文献[6] 提出的端到端的不定长文字识别算法,主要应用于不定长的规则排列的文字识别问题。印章识别包括印章检测和印章文字识别。随着深度学习技术的发展,识别印章是否存在以及确定印章位置已有大量的研究成果[7],国内不少公司也开发用于公章识别的SDK,例如阿里、易道博识等,但一旦图像质量不高或者有较大的形变,印章文字识别的效果不大理想。
为了解决上述问题,本文结合文字识别和印章识别技术设计和实现了带印章的盖章文书图像自动审核方法。该方法主要包含3 个部分:文字识别、印章识别和表格内容审核。其中文字识别部分包括带有角度的文本检测算法SegLink[8]以及卷积递归神经网络(convolutional recurrent neural network,CRNN);印章识别部分包括印章识别与提取算法YOLOv3[9]和印章内容识别方法极坐标变换法;表格内容审核部分根据预设的规则对表格内容进行完备性和正确性检测。
1 方法总体介绍
本文提出的盖章文书图像自动审核方法包含3 个部分,分别为文字识别、印章识别和表格内容审核,图1 为盖章文书图像样本;图2 为该方法的具体流程图。

图1 盖章文书图像样本Figure 1 Sample image of stamped document
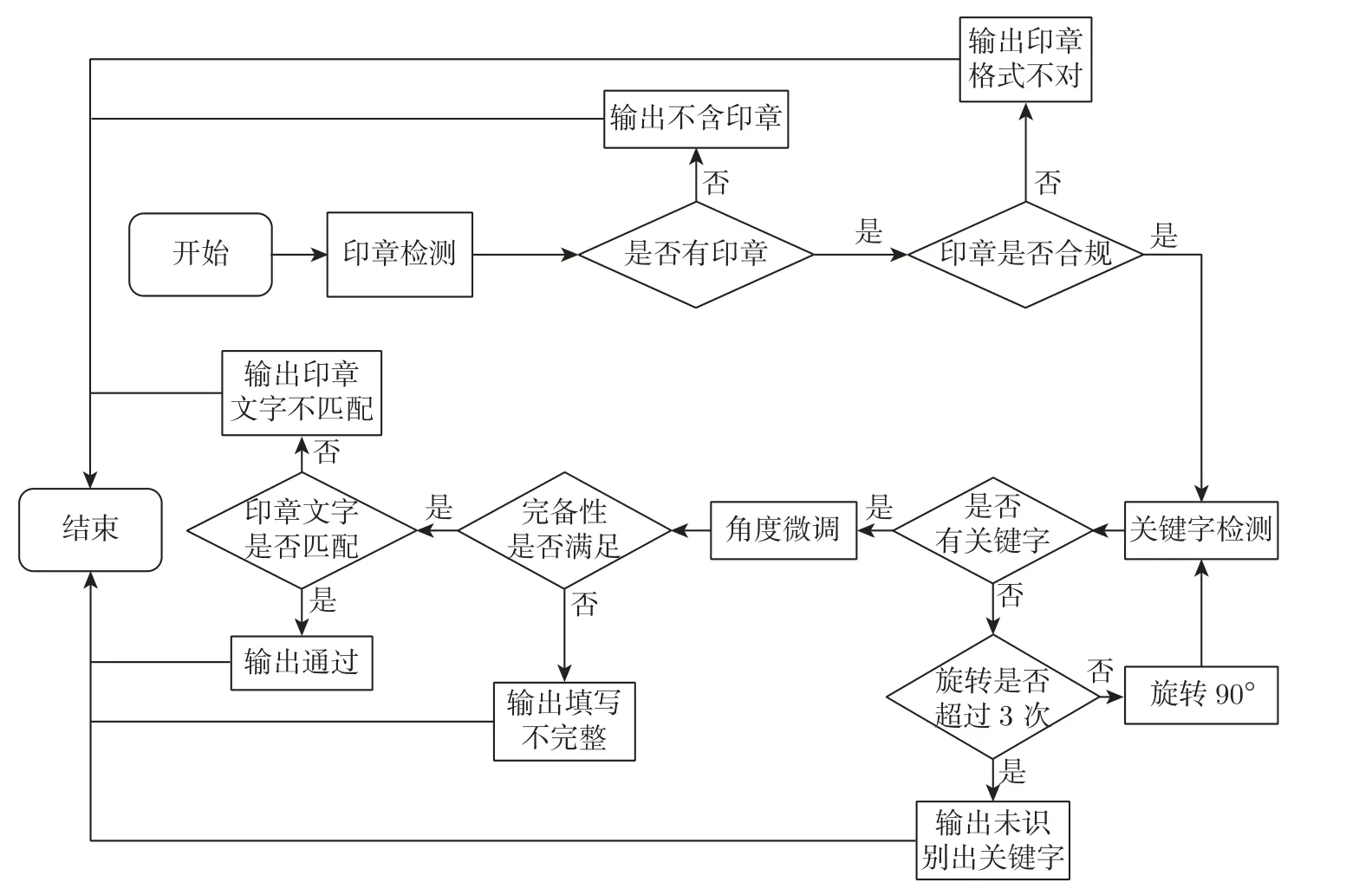
图2 自动审核流程图Figure 2 Process diagram of automated checking
自动审核具体步骤如下:
步骤1判定原始图像是否含有印章且位置正确,如满足继续进行文字识别;
步骤2根据预先设置的文本检测算法SegLink 确定文本框位置,然后使用预先设置的文字识别算法CRNN 识别文本内容;
步骤3对能够检测到关键字的图像再根据文本框的角度进行微调,至表格横向框线处于水平位置,然后识别表格所有单元格内容,判断是否完备;
步骤4对于不满足以上任意一个条件的图像判为内容不完备,并不通过审核;
步骤5比对识别出的单元格内容和预设值是否相同,若相同,通过卷积神经网络识别,作极坐标变换,再比对其预设内容是否一致,若一致,则判断为通过审核。
首先,根据预设的印章颜色、形状和位置判定原始图像是否含有印章且位置正确,如满足条件则继续对盖章文书图像进行文字识别,如果其不包含预定义的内容关键字,可能是因为图像位置不正,则对图像进行不超过3 次的90◦旋转,直到能够识别到关键字;
其次,对能够检测到关键字的图像再根据文本框的角度进行微调,至表格横向框线处于水平位置,然后识别表格所有单元格内容,根据预设规则识别表格必填项的名称和内容,判断是否完备,对于不满足以上任意一个条件的图像判为内容不完备,并不通过审核;
最后,对内容完备的表格进行正确性检查,包括:比对识别出的单元格内容和预设值是否相同,若相同,则截取印章,作极坐标变换,再通过文字识别技术获取印章内容,比对其与预设内容是否一致,若一致,则判为通过审核。
2 核心步骤详细介绍
2.1 文字识别
文字识别方法部分可分为3 个阶段:图像预处理、文本检测和文字识别。
在图像预处理阶段,由于表格盖章文书图像模板设计为上半部分填写信息,下半部分为权利、义务条款,所以在进行文字识别之前会对图像进行截取上半部分的操作。
在文本检测阶段,针对本项目的实际场景,采用了一种可以检测任意角度文本的检测算法SegLink,其主要特点是更改了原先指定一个目标的位置的参数数量,由原先的4 个参数替换为5 个参数,增加了的参数为文本框的旋转角度。
在文字识别阶段,考虑到盖章文书图像文字排列规则且字符数量不定,选择端对端的不定长文字识别网络CRNN。它借鉴了语音识别中的长短期记忆网络(long short term memory,LSTM)[10]结合联接时间分类器(connectionist temporal classifier,CTC)[11]的建模方法,使用CNN 网络提取的图像特征向量代替语音领域的声学特征作为LSTM 的输入。LSTM 单元的结构如图3 所示,主要由3 个部分组成:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。
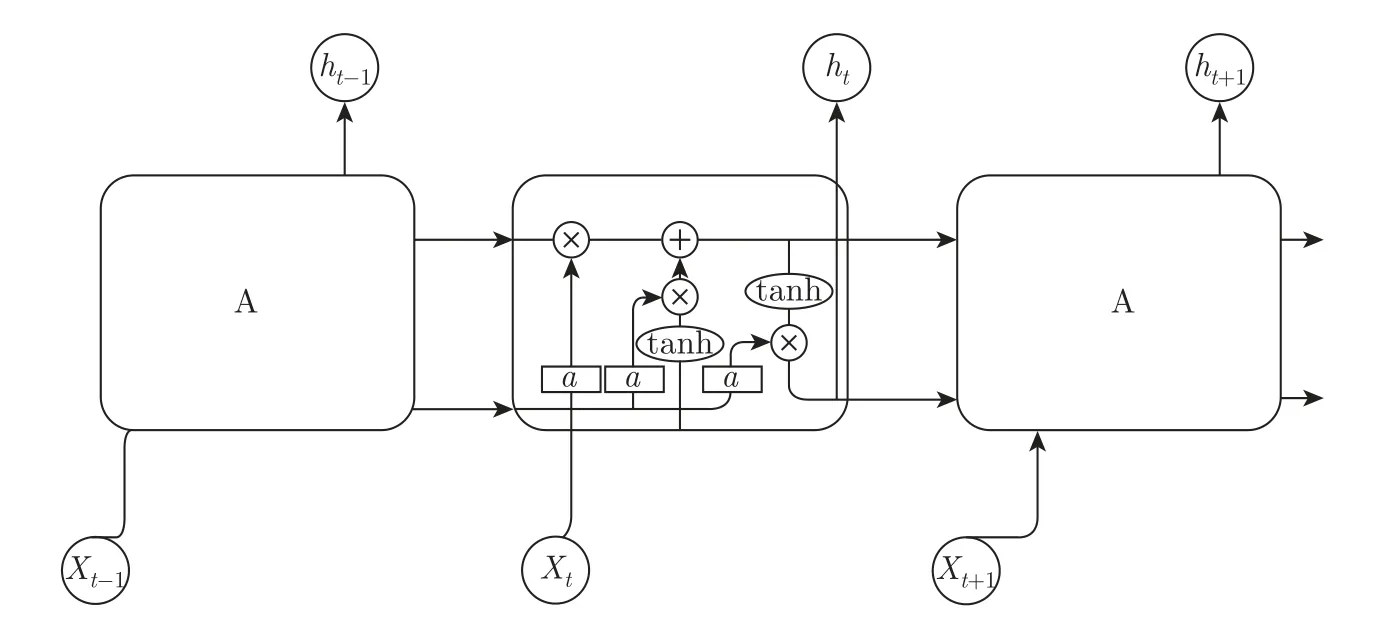
图3 LSTM 单元结构Figure 3 LSTM unit structure
由于文字变形或文字间隔不相同等问题,同一段文字可能会出现不同的表现形式,图4为CTC 识别示意图,具体的识别步骤如下:

图4 CTC 识别流程Figure 4 CTC identification process
步骤1将输入的图像按照进行分块,得到属于某个字符的概率,其中无法识别的特殊字符用“-”标记;
步骤2按照规则去掉重复字符和间隔字符,如果同一字符连续出现,则表示字符重复,保留1 个字符,如果中间有间隔字符,则表示该字符不重复,保留所有字符。
2.2 印章识别
印章识别方法部分可分为两个阶段,即印章识别和印章内容识别。
在印章识别阶段,本项目采用端对端的目标检测模型YOLOv3。它是目标检测最经典的网络之一,相较于之前的版本,它对网络结构进行了调整,借鉴了残差网络结构,通过在部分层中间设置快捷链路的方式形成更深的网络层次。除此之外,它还增加对象检测的特征尺度,将对象分类方法由SoftMax 变为Logistic,使得小物体检测效果得到一定提升。
在印章内容识别阶段,采用极坐标变换法将截取的圆形印章文字拉伸至水平。首先,根据模型输出的印章位置确定印章的中心点位置(x,y) 和半径r,然后将直角坐标系转化为极坐标系,图5 为具体变换示意图。

图5 极坐标变换示意图Figure 5 Polar coordinate transformation diagram
其中src 为输入图像,dst 为输出图像,输入图像的原点在为图像正中心,输出图像原点为左上角,首先根据原图像分别计算出缩放比例
2019年7月9日,万科物流继续开启并购模式,与太古实业举行并购签约仪式,将太古实业旗下太古冷链物流资产包收入囊中,具体包括上海、广州、南京、成都、厦门、廊坊、宁波在内的7座冷库。作为可口可乐的冷链运营商,太古冷链物流成立于2010年,其仓库设施基于国际领先的冷库技术设计、并依据中国有关技术标准建设,所有仓库均能作为区域仓储中心,并具备分拣配送服务功能,设多温区存储以满足不同产品对温控仓储服务的需求。
式中:src.cols 为原图像的长;src.rows 为原图像的宽;maxRadius 为最大圆半径。然后根据缩放比例计算出极坐标系下点的坐标
其中
式中:center.x和center.y为圆中心点坐标。经过变换后,印章图像如图6 所示。
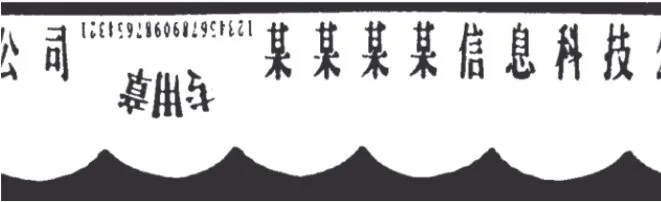
图6 极坐标变换后印章示意图Figure 6 Schematic diagram of seal after polar coordinate transformation
2.3 表格内容审核
在表格内容审核阶段,主要是对前面识别出的表格内容以及印章内容根据预先定义的规则进行完备性和正确性的检测,具体规则如表1 所示。

表1 完备性和正确性检测规则表Table 1 Completeness and correctness inspection rule table
表格完备性检测包括表格是否包含印章,表格内容是否填写齐全。使用印章识别模型对图像进行识别,判断是否包含印章。一般来说,填写表格信息只有两种方式,一种是电脑填写,一种是手写,这两种方式绝大多数字体都会是黑色,根据这一颜色特性,使用文字识别模型提取出表格内容关键字,如“公司名称、公司法人统一社会信用代码”等字样,获取其文本框信息,通过设定的范围获取填写区域,计算该区域的黑色像素的数量,与预设的阈值进行比较,大于阈值则表示已填写。
表格正确性检测包括印章位置是否正确、印章类型是否正确、表格所填信息是否匹配。印章位置判断主要是为了审核部分未按规定将印章盖至规定区域的图像,由于指定区域为右上角,首先截取右上角区域,然后根据印章的颜色特性,将图由RGB 模型改为HSV 模型,其中H表示色调、S表示饱度、V表示亮度,根据红色和蓝色的取值范围,确定图像中是否包含红色和蓝色的区域,所述红色取值范围为H(156∼180)、S(43∼255)、V(46∼255),蓝色的取值范围为H(0∼10)、S(43∼255)、V(46∼255),像素点阈值为100,超过100 个像素点则表示图像中包含有红色或蓝色的区域,根据该区域红色像素的数量进行判断。印章类型通过印章识别模型输出的类型进行判断。表格所填信息的正确性是将表格所填文字的内容和印章文字的内容与预设的正确内容进行字符串匹配,然后根据匹配结果确定,匹配则正确,不匹配则错误。
3 实验结果与分析
3.1 印章图像数据集
由于金融业务中的盖章文书图像属于企业经营的关键信息,安全管控要求较高,真实样本数据较少,通过网络收集、人工模拟和少量真实样本构建一个印章图像数据集。其中真实样本数量为20,人工模拟数量为80,网络收集并人工标注数量为900,总数量为1 000。该数据集包含了印章和法人章两种类型,其中印章类695 幅,法人类305 幅,印章都为红色圆形,法人为蓝色矩形。随后,按照Pascal VOC[12]数据集的格式对印章图像数据集进行标注,便于后期的网络训练与测试。
3.2 印章识别网络训练与测试
为验证印章识别方法的有效性,在印章图像数据集上进行了训练与测试。所有网络模型的训练与测试均在服务器上进行,服务器配置为CPU: i7-8700/GPU: RTX 2080Ti,使用的操作系统为ubuntu 18.04,采用的深度学习架构为Pytorch。因本文构建的印章图像数据集中样本图像较少,为保证训练集、验证集样本分布一致,将1 000 条数据按标签、类别以0.7/0.3 的比例切分为训练集与验证集。为检验模型泛化能力,将标注数据按三折交叉检验方法,划分为共3 组训练集与验证集。表2 为最终数据集分布情况。

表2 数据集分布Table 2 Data set distribution
3.3 印章识别实验结果
查全率R的计算公式为
F1 分数的计算公式为
式中:TP(True Positive)为真正例;TN(True Negative)为真负例;FP(False Positive)为假正例;FN(False Negative)为假负例。
本文在印章图像数据集上使用YOLOv3 进行测试,测试结果如表3 所示。图7 展示本文印章识别方法YOLOv3 取得的PR 曲线,根据曲线计算面积得到两类印章的平均精确度(mAP) 为87.6%,证明了本方法能够有效地对盖章文书图像印章进行提取。

表3 测试结果Table 3 Test result %
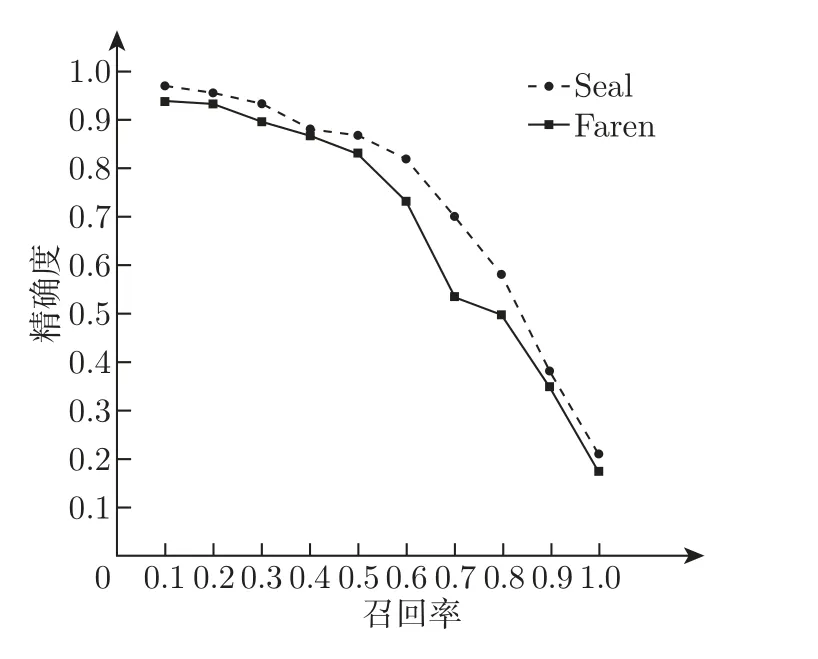
图7 印章识别方法PR 曲线Figure 7 PR curve of seal recognition method
3.4 盖章文书图像自动审核方法实验设置
在进行实验之前,需要对实验环境进行部署,服务器数量为10,每台服务器配置为6 核,内存为8 G,操作系统为CentOS。本文在上述环境下,对真实盖章文书图像数据集进行了自动审核,该数据集包含130 277 幅盖章文书图像,其中审核结果通过的数量为42 682,审核结果不通过的数量为62 545,审核结果待定的数量为25 000。待定主要是指不能保证识别结果一定正确或者非正确的部分,例如判断必填项是否缺失,印章中文字是否为公司名称等误判率较高的情况。
3.5 盖章文书图像自动审核功能实验结果
本文通过准确率(Accuracy)来评估盖章文书图像自动审核功能的性能,计算公式为
本文采用随机分层抽样方法,对审核结果为“通过”和“不通过”的盖章文书图像从0 开始进行编号,将其各分成1 000 个区间,在每个区间利用随机数抽取1 个样本,最终结果如表4 所示。

表4 随机分层抽样结果表Table 4 Random stratified sampling result table
由随机分层抽样结果计算得到自动审核的准确率为98.3%,本文所提出的自动审核功能的准确率高,能够满足自动审核的要求。
4 结语
早期的盖章文书全部依靠人工审核,存在效率低下、成本高、长时间审核容易出错等问题。人工审核效率慢,与盖章文书增长速率不匹配,导致积压待审核文书十余万份。为了解决这个问题,本文提出了一种基于OCR 和图像检测的盖章文书图像自动审核方法。本文对盖章文书的特征进行分析,使用目标检测算法和文字识别技术,实现了盖章文书的自动审核:1)基于数字图像处理的常用方法对盖章文书图像进行预处理,包括截半、旋转等。2)将经过预处理的盖章文书图像使用SegLink 模型来确定其文本信息。3)基于深度学习的CRNN 模型对文本信息进行识别,输出文字内容信息。4)通过基于深度学习的YOLOv3 模型对盖章文书图像进行印章识别,确定印章类型和位置。5)将提取出的印章使用极坐标变换法使印章文字转为水平,之后通过文字识别模型得到印章内容。6)根据预设的内容审核规则对盖章文书图像内容进行审核,最终输出审核结果。
在设置处理步骤顺序过程中,考虑到盖章文书特性、各步骤性能,将印章检测步骤放在最前,一方面是因为漏盖、错盖印章的负例比例较大,另一方面YOLOv3 模型检测印章速率远大于文本识别速率,因此能够快速筛选掉不符合要求的盖章文书。
由于该方法应用于金融领域的盖章文书识别,对于准确率要求较高。因此在审核结果中设置了待定选项,例如印章文字识别步骤错误率高,如果识别出的文字不能完全对应公司名称,则将审核结果判别为待定,交由人工审核。这样能够保障审核结果的准确率,符合应用领域要求。
目前基于本方法的自动审核功能运行稳定,审核方法审核准确率较高。在此基础上,针对神经网络模型还将引入学习功能,根据上传的盖章文书图像文件对文字识别和印章识别网络进行训练,调整神经网络的权重,进而学习到更准确的特征;在业务完善方面,信息比对功能正在开发中,审核人员可以对上传的盖章文书图像和识别的文字内容在界面上进行比对,让审核人员能在系统中更加直观地了解审核情况,方便后续做出相应的处理。
猜你喜欢
故事作文·低年级(2023年11期)2023-12-05
邯郸学院学报(2022年2期)2022-07-05
大灰狼画报(2022年4期)2022-06-05
少儿画王(3-6岁)(2022年2期)2022-02-22
安徽警官职业学院学报(2020年6期)2020-07-21
西夏学(2019年1期)2019-02-10
课堂内外(高中版)(2017年12期)2017-12-27
童话世界(2017年14期)2017-06-05
幼儿智力世界(2016年11期)2017-02-21
工业设计(2016年8期)2016-04-16
