
哈希算法异构可重构高能效计算系统研究
2023-12-04 02:59郑博文柴志雷
应用科学学报 2023年6期
郑博文,聂 一,柴志雷
1.江南大学物联网工程学院,江苏无锡214122
2.江南大学人工智能与计算机学院,江苏无锡214122
3.江苏省模式识别与计算智能工程实验室,江苏无锡214122
哈希算法一直在数字签名和消息验证等领域具有重要的地位。哈希算法应用场景日益多元化,这就要求哈希算法具有更高的计算性能和能效,纯软件的方式已难以满足需求。越来越多的研究开始探索使用FPGA 以硬件方式突破计算性能瓶颈。通过FPGA 实现哈希算法,目前主要的优化方法有预计算[1]、优化关键路径[2]和设计流水线结构[3]。文献[4] 对SHA-1 算法使用预计算和优化关键路径的优化方法,设置四级流水线,提升了单位逻辑资源的利用效率。文献[5-6] 通过对SHA-256 算法进行预计算,缩短计算的关键路径,并采用多周期划分流水线以提升硬件工作频率,加速SHA-256 算法计算。
在不同场景中使用多种哈希算法的组合也有明确的需求[7-8]。虽然对个别哈希算法进行硬件优化,可以满足算法的性能需求,但是,有些应用场景往往会涉及多个算法。因此,也有文献尝试设计多个哈希算法共用的硬件结构。文献[9] 设计了SHA-1/SHA256/SM3 算法的IP 复用电路,通过电路实现了算法中压缩运算的循环展开,并设计了流水线结构。比单独实现三种算法,节约了电路面积并提升了算法吞吐量。文献[10] 在同一个硬件方案中实现了SHA3-224、SHA3-256、SHA3-384、SHA3-512 算法的优化,在数据填充和压缩计算中使用流水线设计,降低了关键路径的延迟。虽然FPGA 硬件实现哈希算法和复用IP 的电路设计,提升算法性能的同时也具备了一定的通用性,但是已经设计好的电路结构无法扩展,当需要使用其他哈希算法时依旧需要重新设计。近年来,也有文献使用OpenCL 以及HLS 等高层次综合工具在FPGA 上实现了哈希算法,文献[11-13] 分别实现了MD5、SHA-1 以及SHA-256 算法,但是效果比起其他文献中Verilog 的设计还存在差距。
针对上述问题,本文提出了一种异构且可重构的哈希算法高能效计算系统,整体系统采用异构方式,适合硬件加速的部分采用专用硬件的方式进行加速;适合软件计算的部分由CPU执行。同时,硬件加速部分利用可重构技术,针对不同算法通过重构进行有针对性的硬件重构。从而获得整体系统的最佳计算能效。通过在FPGA SoC 上实现该架构,在可编程逻辑端实现哈希算法硬件加速,并利用OpenCL 实现异构设备间的交互,控制哈希算法在FPGA 上的动态重构。验证了上述方法的有效性。
1 哈希算法的结构分析
1.1 哈希函数的一般结构
哈希函数可以将无限定义域的输入映射为有限定义域的哈希值,这种压缩映射关系是通过压缩函数实现的。Merkle-Damgard 结构[14]是这种映射关系的典型代表。常用的哈希算法,如SHA-1、SHA-256 以及MD5 等算法均使用了此种结构。Merkle-Damgard 结构可以表示为
式中:H为哈希函数;M为哈希的输入数据;CV 为链接变量;IV 为初始向量;f为压缩函数。M可以被划分为L个分组数据M0,M1,M2,···,ML-1,分别对应L轮压缩函数f的迭代计算。第i轮压缩函数计算的输入数据为分组数据Mi-1和上一次压缩函数的计算结果CVi。哈希函数会设置初始向量IV,作为CV0用于首次压缩函数的计算。当压缩函数计算完所有的分组数据,最后的计算结果CVL即为哈希值。哈希函数的结构如图1 所示。
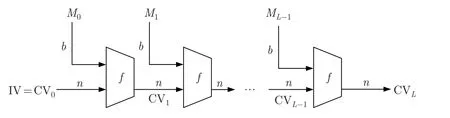
图1 哈希函数结构Figure 1 Hash function structure
许多哈希算法都使用了Merkle-Damgard 结构,如SHA-1、SHA-256 和MD5 等,表1 列举了它们的一些结构特点。这些哈希算法在结构上具有一定的相似性,但是压缩函数f中的逻辑运算存在着很大的差别,比如SHA-256 算法的压缩函数使用了64 轮相同的迭代计算,RIPEMD-160 算法的压缩函数则包括了两组各80 轮不完全相同的迭代计算。
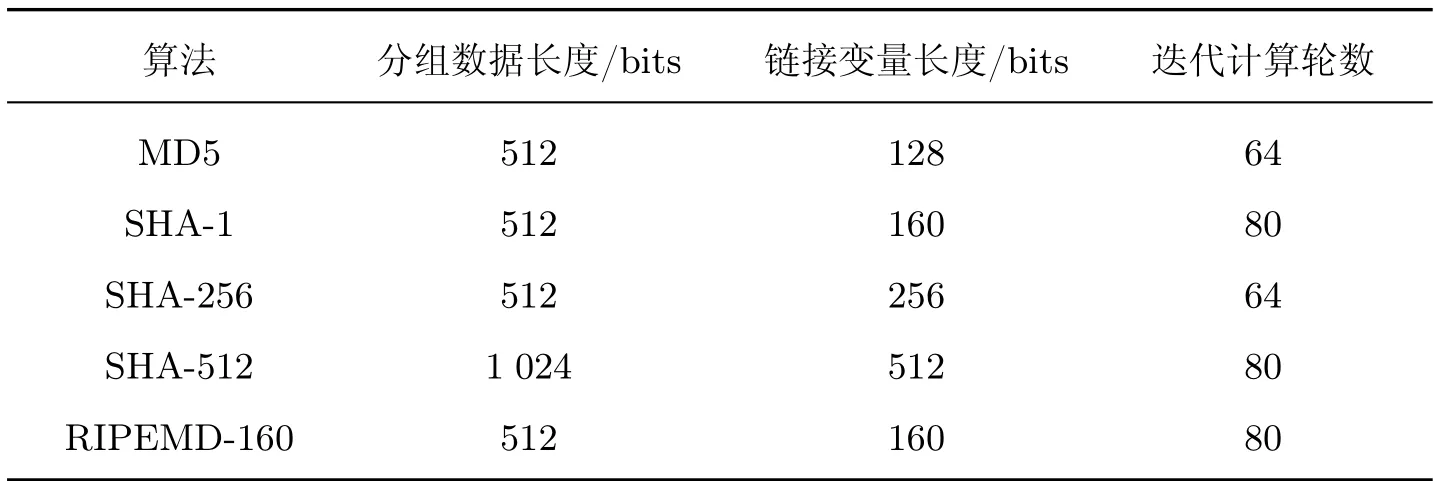
表1 部分哈希算法对比Table 1 Comparison of some Hash algorithms
1.2 算法并行性分析
哈希算法的核心部分是压缩函数f的计算,分析其并行性有助于针对性地进行算法优化。因篇幅有限,本文以较常用的SHA-256 算法[15]为例进行分析。SHA-256 算法的压缩函数f需要进行64 轮相同的迭代计算,如图2 所示。
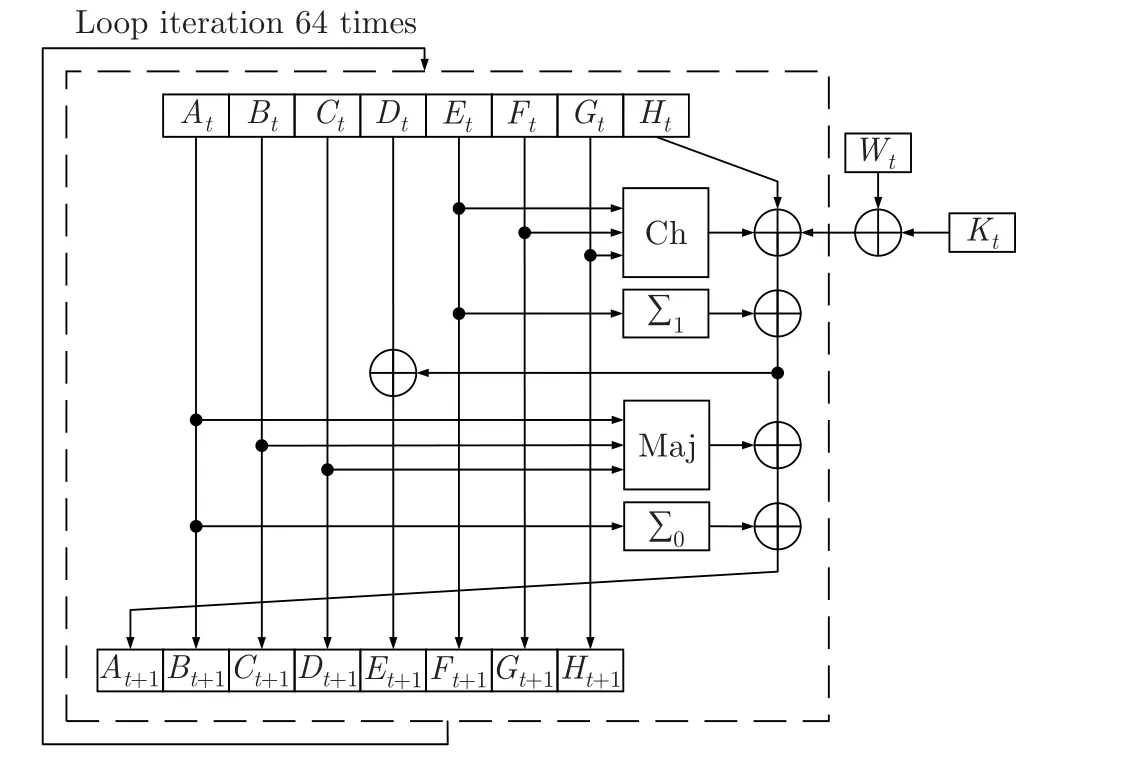
图2 SHA-256 算法的迭代计算Figure 2 SHA-256 algorithm single-step iterative calculation
压缩函数f输入CV 的长度为256 bits,可以拆分为8 个32 bits 的数据,分别对应图2中A-H。分组数据的长度为512 bits,被拆分为16 个消息字W0,W1,W2,···,W15,并且由式(2)∼(6) 计算得到更多的消息字W16,W17,W18,···,W63,对应迭代计算中的Wt。K0,K1,K2,···,K63为64 个常量关键字,对应迭代计算中的Kt。迭代计算中的逻辑函数描述见式(7)∼(10)。
压缩函数f完成64 轮迭代计算后,计算得到的A-H加上最初输入的CV,作为下一次压缩迭代输入的CV,直至所有计算完成后作为哈希值输出。SHA-256 算法不仅每次压缩函数f的计算存在数据依赖,压缩函数f中的64 轮迭代计算也存在数据依赖,使得SHA-256 算法只能串行执行,极大地限制了SHA-256 算法的性能。除了SHA-256 算法,其余常见的哈希算法也存在数据依赖,无法通过并行计算提升性能。Merkle-Damgard 结构哈希算法的核心部分是压缩函数,且不同算法的压缩函数结构相似。通过硬件加速压缩函数的计算,设计一种通用的硬件优化方案,有助于提升此类哈希算法的性能,在FPGA 上实现不同哈希算法的加速设计。
2 哈希算法加速器设计
2.1 算法硬件设计
Merkle-Damgard 结构哈希算法中的数据依赖是硬件加速的瓶颈,在FPGA 中以流水线结构实现哈希算法能够提升数据依赖部分的计算性能,并且对数据带宽的利用效率更高。哈希算法的压缩函数由消息字扩展和迭代计算两个部分组成,两者都存在着数据依赖关系,可以分别使用流水线结构实现。在SHA-256 算法中,虽然消息字扩展和迭代计算在各自的结构中存在数据依赖,但是两者之间的数据依赖仅存在于单步迭代计算中,第t轮迭代计算和消息字Wt之间存在数据依赖关系,与其他消息字则没有。因此压缩函数中的消息字扩展和迭代计算可以通过并行的流水线结构实现,图3 展示了流水线结构的串行执行和并行执行。
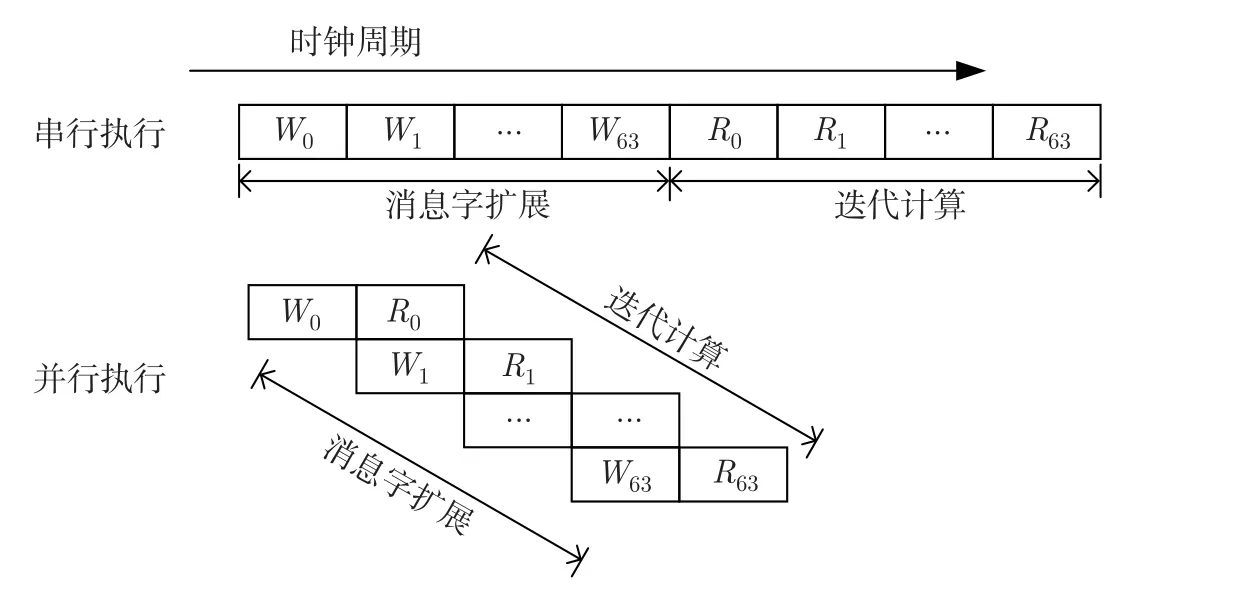
图3 流水线执行方式Figure 3 Pipeline execution mode
2.2 针对流水线结构的优化
流水线结构对于算法的性能提升是以硬件资源的消耗为代价的,可以通过硬件资源的复用对流水线结构进行优化。在SHA-256 算法中,压缩函数共需要64 个32 bits 的消息字,占用了2 048 bits 的存储空间,当使用流水线结构实现时,占用了大量的存储资源。由式(6) 可知,构造Wt时,依赖于Wt-2,Wt-7,Wt-15和Wt-16,并且最初的16 个消息字由分组数据拆分得到,因此通过16 个寄存器的复用实现消息字的存储,根据迭代计算的轮数不断更新,如图4 所示。前15 轮迭代计算中不更新寄存器中的消息字,从第16 轮迭代计算开始,消息字扩展和迭代计算同步执行,新的消息字更新至之后不会被使用的消息字的寄存器中。
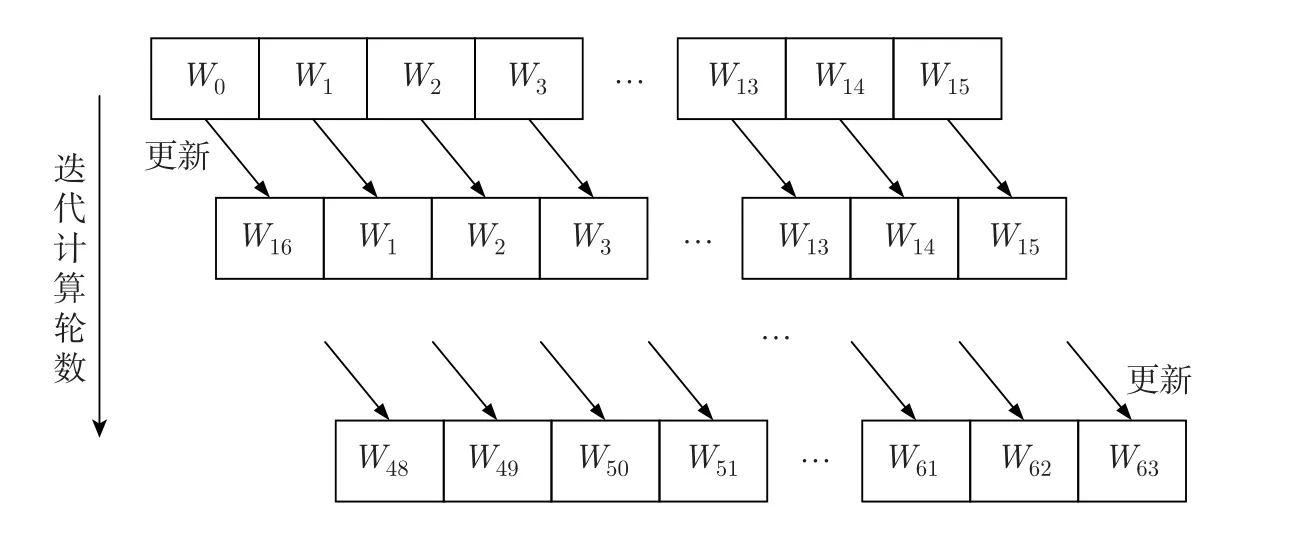
图4 消息字扩展的存储优化Figure 4 Memory optimization of extension
消息字扩展和压缩函数的流水线结构,以并行执行的方式共同组成了哈希算法的全流水线结构。对于第i次压缩函数计算,输入数据包括链接变量CVi和分组数据Mi。压缩函数中第j轮迭代计算的输入数据是常量Kj,消息字Mj以及上一轮迭代计算的结果Aj-Hj,其中首轮迭代计算中的A0-H0就是链接变量CVi。当第63 轮迭代计算完成后,计算结果A64-H64和链接变量CVi相加得到了链接变量CVi+1用于下一轮压缩函数计算。当所有分组数据都由压缩函数计算完成后,最后的链接变量作为哈希值输出。由式(2)∼(10) 可知,消息字扩展的逻辑运算比起迭代计算更加简单,计算的需要时钟周期更少,保证了每轮迭代计算和消息字扩展能够在同一个时钟周期启动,实现了压缩函数的全流水线计算,图5 展示了SHA-256 算法的全流水线结构。
2.3 查表法降低流水线延迟
查找表(look-up-table,LUT)是FPGA 上的一种基础结构,本质上是一个RAM。消息字扩展和迭代计算中的数据只和迭代轮数相关,各轮迭代计算中需要访存的寄存器相对固定,使用查找表记录各轮迭代计算中需要访存的寄存器地址和操作,可以避免生成负载的仲裁逻辑判断寄存器访存,节约硬件资源并降低访存效率,提升了全流水线结构的时钟频率。图6 展示了通过查表法实现的数据访存。
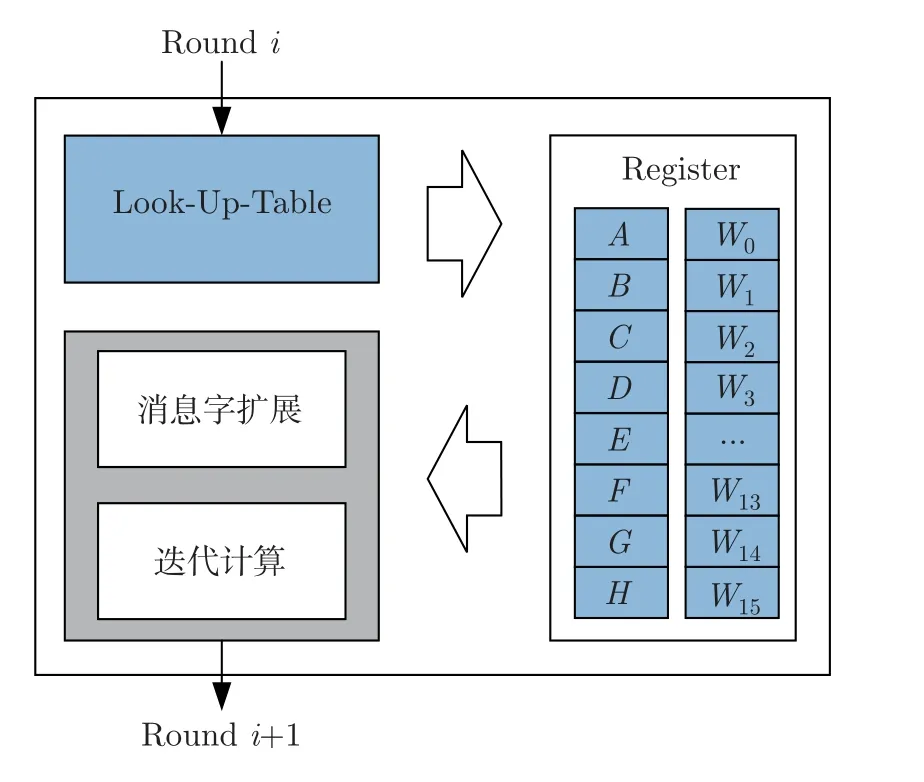
图6 查表法Figure 6 Look-up table method
寄存器中存储了迭代计算的结果A-H以及消息字W,随着迭代计算的进行不断更新。第i轮迭代计算执行时,查找表中已经记录的需要读写的寄存器地址和顺序,消息字扩展和迭代计算部分根据记录读取逻辑运算中需要使用的数据并写入计算结果。
3 基于OpenCL 实现异构计算系统
3.1 针对OpenCL 的数据存储优化
OpenCL(open computer language) 是一种面向异构系统的计算标准,使用OpenCL 的异构计算系统包括一个主机端(Host),一个或多个设备端(Device),主机端和设备端通过共享内存的机制实现数据交互。计算任务以内核(Kernel)的形式运行于设备端,由主机端负责调度和管理。OpenCL 为了提升开发效率,抽象了4 种内存模型:全局内存(global memory)、常量内存(constant memory)、局部内存(local memory)和私有内存(private memory)。各个内存模型具有不同的读取速度和存储空间[16]。表2 展示了FPGA 上不同内存模型的性能参数,常量内存中为只读数据,存储在全局内存中,当内核执行时加载到FPGA 的片上缓存中。
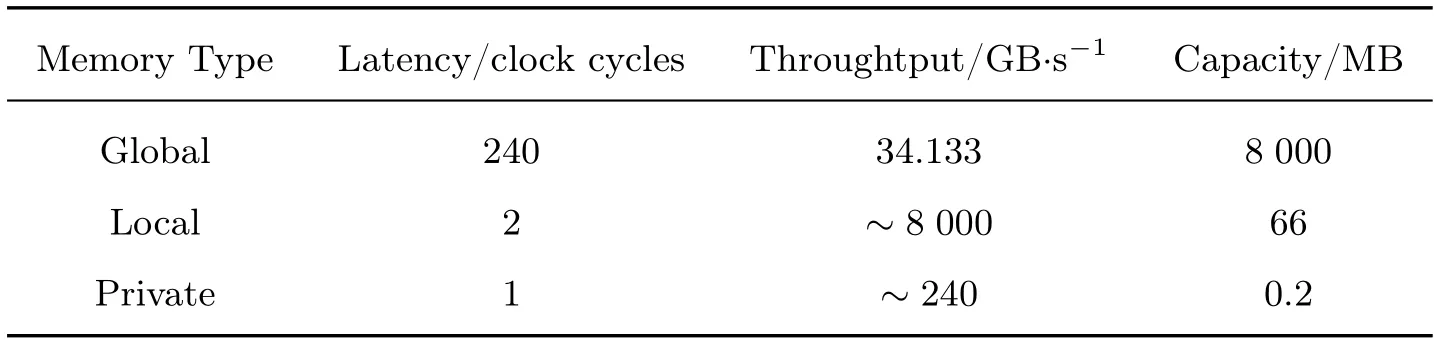
表2 不同内存类型的参数Table 2 Parameters of different memory types
OpenCL 在FPGA 上运行时,各个内存模型以不同的硬件资源实现。全局内存以DDR内存实现,存储空间最大,作为主机端和设备端的共享内存。局部内存由FPGA 的块内存实现,存储空间小于全局内存,但是访存速度更快。私有内存由FPGA 的片上寄存器实现,访存速度最快,存储空间最小。哈希算法处理的计算任务通常为密集计算,合理使用OpenCL 的内存模型十分重要。
哈希算法的输入数据长度可变,由主机端程序按照一定规则填充后,划分为固定长度的分组数据M存储在全局内存中,由内核程序计算。当FPGA 以固定数据位宽进行计算时,可以减少处理数据位宽的资源开销,提升电路的工作频率。依据哈希算法中各个数据的存储需求与访存频率,选择不同的内存模型实现。表3 展示了对SHA-256 算法的数据位宽调整和存储优化。
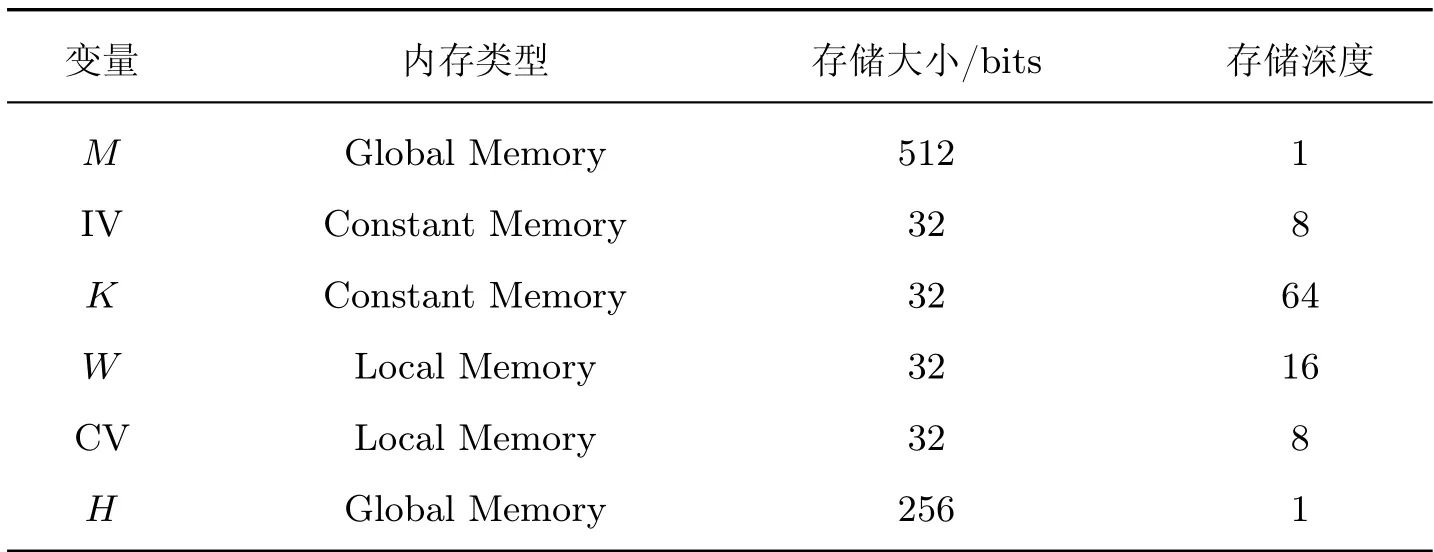
表3 SHA-256 算法存储资源Table 3 SHA-256 algorithm storage resources
其中,M使主机端程序填充后的512 bits 分组数据,由于数据量大,所以在全局内存中存储。IV 是初始向量,K是关键字,两者均为常量且会被频繁读取,使用常量内存进行实现,提升数据的访问速度。W是消息字,CV 是链接变量,在算法计算过程中需求的存储空间较大,使用局部内存进行实现可以获得较低的访存延迟。H是哈希值,和M一样存储在全局内存中,便于在主机端和设备端之间进行交互。
3.2 多线程管理
命令队列对于OpenCL 的使用是不可或缺的。主机端程序通过命令队列可以自由地操作各个OpenCL 对象,如内存对象的读写、内核对象的执行等。当计算系统中需要执行多组计算任务,或者不同哈希算法的计算任务,大量的命令队列就会使得系统的运行十分混乱。因此主机端程通过多线程来管理命令队列,以及通过命令队列提交不同的哈希算法内核到FPGA执行,图7 展示了多线程管理命令队列的流程。
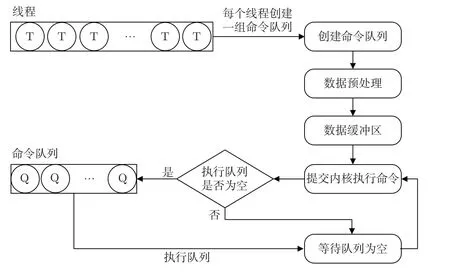
图7 多线程管理命令队列Figure 7 Multithreaded management command queue
主机端程序根据计算任务启动线程,由线程创建一系列的命令队列,负载OpenCL 执行时的内存操作以及内核执行。并且线程还会对计算需要的输入数据进行预处理,存储于数据缓冲区中,等待内核执行时传输至FPGA 上的全局内存。主机端程序在创建数据缓冲区时,会根据线程数量对缓冲区进行内存划分,避免多线程同时访存引起的冲突。内核执行时,需要提交命令队列,当上一个计算任务还未执行完毕时,命令队列会排队等待直到队列为空。各个线程间在命令队列等待时实现同步。线程在对计算数据进行预处理时,主要对数据按照算法规则进行填充分组。内核在FPGA 的全局内存中获取的数据可以直接被用于压缩迭代计算,使得内核的执行效率更高,发挥了异构计算的优势。
3.3 FPGA 动态可重构
通过FPGA 可重构可以实现计算系统对不同哈希算法的加速,主机端程序可以灵活部署不同的哈希算法到FPGA。在多线程管理中,主机端程序根据使用的哈希算法创建线程,当计算任务需要使用不同的算法时,会启动新的线程并创建命令队列。主机端程序通过OpenCL的API 函数clEnqueueNDRangeKernel 根据命令队列的内容提交内核到FPGA 执行,并且在这一过程中实现对FPGA 的可重构。实现哈希算法的FPGA 镜像文件存储在主机端的DDR 内存中,通过PCI Express 总线配置到FPGA 上[18]。
3.4 哈希算法高能效计算系统
计算系统由主机端和设备端两个部分组成,选择CPU 作为主机端,FPGA 作为设备端。主机端程序负载OpenCL 运行环境的配置,并且通过多线程管理实现不同哈希算法在设备端的加速。FPGA 根据主机端程序的命令执行配置的哈希算法硬件电路。CPU 和FPGA 之间通过PCI Express 总线进行数据交互,图8 展示了计算系统的总体架构。计算系统在运行时,由主机端程序对OpenCL 平台进行初始化配置,包括查询OpenCL 平台和设备的信息。对需要执行的计算任务通过多线程管理,预处理计算数据,等待FPGA 执行对应的哈希算法硬件电路。FPGA 执行内核时,将预处理后的计算数据由全局内存搬运至局部内存以全流水线结构执行。执行完毕后得到的哈希值会由局部内存搬运至全局内存,通过PCI Express 总线传输回主机端的内存中存储,并在之后由外部程序使用。FPGA 中丰富的逻辑资源支持实例化多个全流水线结构,通过并行计算提升性能。在内核中实例化的硬件电路被OpenCL 称为计算单元(compute unit,CU)。
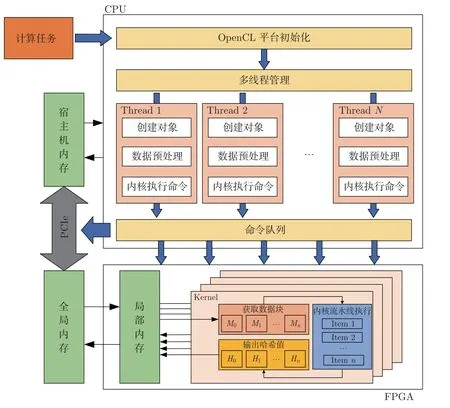
图8 计算系统整体架构Figure 8 Computing system architecture
4 实验与结果分析
4.1 实验环境
本文选取Intel Xeon E5-2650 V2 CPU 和Intel Stratix 10 GX2800 FPGA 搭建OpenCL异构计算平台,其中FPGA 的逻辑资源ALMs 为933120,寄存器资源为3732480。选取Intel Core I7-10700 CPU 作为CPU 计算平台,NVIDIA GTX 1650 SUPER 作为GPU 计算平台进行对比验证。
4.2 测试结果及分析
本文为了验证计算系统对不同哈希算法的性能提升,在计算系统中实现了多个哈希算法的内核设计,内核中设置单个计算单元时算法的性能测试如表4 所示,计算性能的单位是百万哈希/秒。
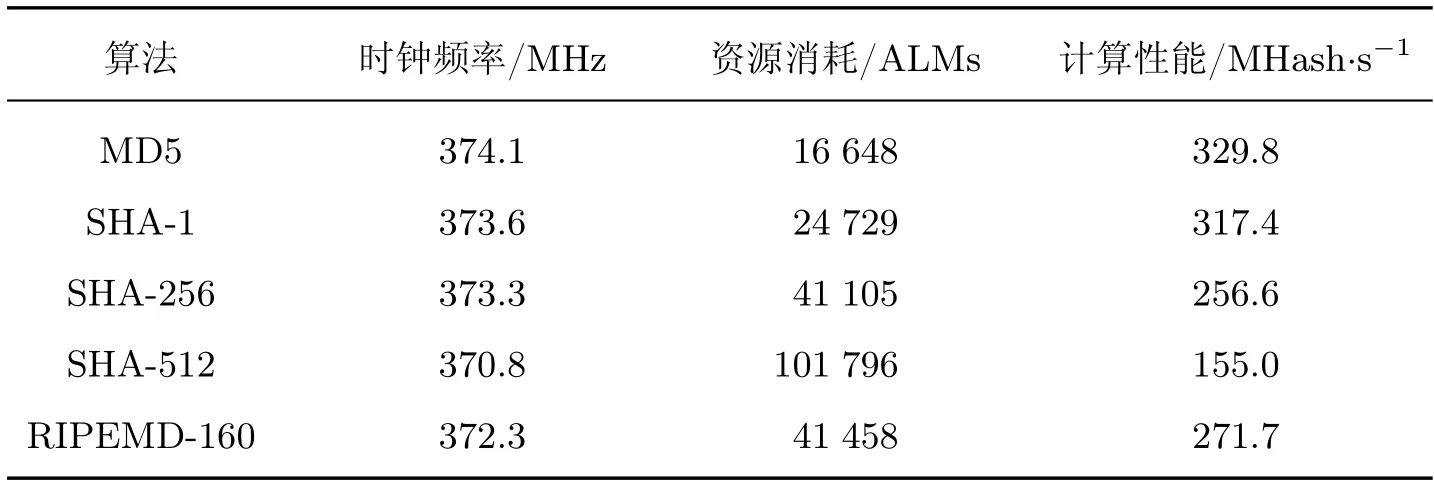
表4 不同哈希算法的性能Table 4 Performance of different Hash algorithms
由测试结果可知,在算法硬件实现时,计算逻辑越复杂占用的逻辑资源就越多。虽然5 种哈希算法的时钟频率都在370 MHz 左右,理论上以全流水结构计算时每个时钟周期可以完成一次哈希计算,但是算法性能和理论值存在差距。测试用时使用OpenCL 的API 函数在主机端程序获取,包括了局部内存与全局内存、FPGA 和CPU 之间的数据通信时间,可能导致了计算性能的差距。5 种哈希算法的哈希值长度不同,其中MD5 算法的哈希值长度最短为128 bits,计算性能最高,SHA-512 算法的哈希值长度最长为512 bits 并且数据吞吐量达到了带宽限制,所以实际计算性能与理论值差距较大,之后会在4.3 节中进行验证。
SHA-256 算法是应用最广泛的哈希算法之一,为了进一步验证本文设计哈希算法加速模块的性能,也与相关文献中的SHA-256 算法性能进行对比。文献中通常使用吞吐量表示算法性能,本文通过式(11) 将SHA-256 算法性能转换为吞吐量进行对比。
式中:block_size 为消息分组长度,SHA-256 算法的block_size 为512 bits;num 为哈希算法的运行次数;time 为Kernel 执行时间,实验结果如表5 所示。
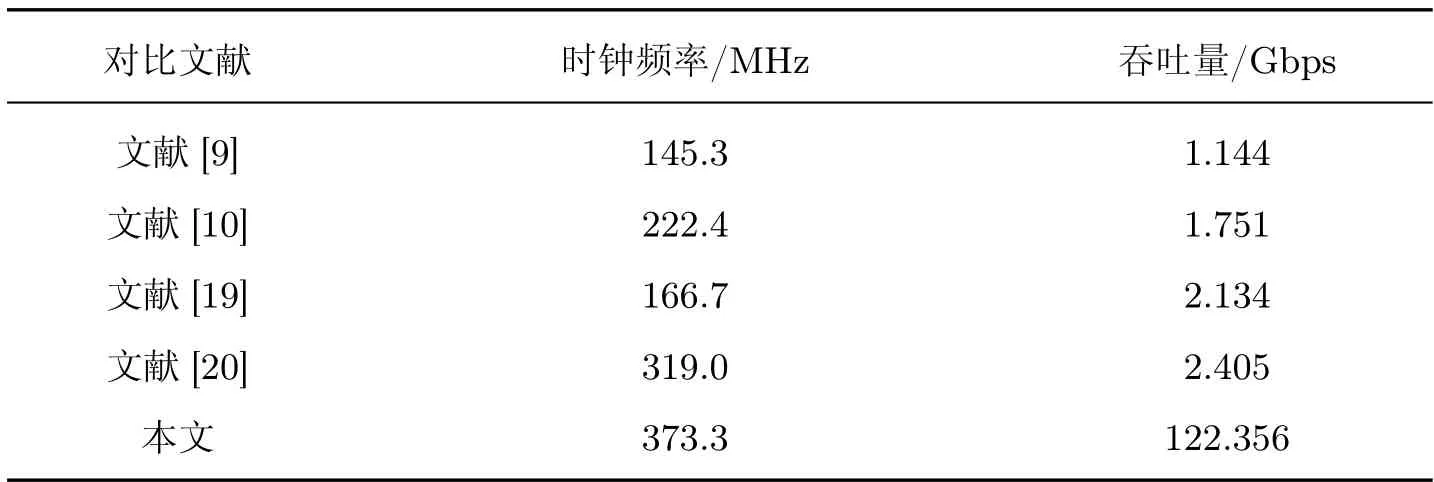
表5 不同文献SHA-256 对比Table 5 SHA-256 comparison of different documents
由SHA-256 算法的性能对比可知,本文的流水线设计可以使用较高的时钟频率,并且对算法进行优化,结合数据位宽调整、数据存储优化等方法降低每级流水线的延迟,对SHA-256算法的吞吐量提升明显。上述文献中的设计使用Verilog 进行开发,耗时较长,而本文基于OpenCL 实现的哈希算法加速模块设计,可以快速应用于其他Merkle-Damgard 结构哈希算法,取得不错的性能提升,极大地降低了哈希算法硬件设计的时间成本。不但保证了不同哈希算法计算性能,还可以通过异构计算的方式实现FPGA 的动态重构,根据不同的计算任务灵活组合哈希算法,为解决多哈希算法组合计算的需求提供了一种思路。
4.3 计算系统性能表现
加解密是哈希算法的主要应用领域。哈希值具有不可逆性,只能通过不断尝试密码组合,生成哈希值后与待破解哈希值对比,因此对哈希算法的计算性能要求很高。为了测试计算系统在应用场景中的表现,本文将哈希计算系统应用于哈希值的破解,在FPGA 上部署多个计算单元CU,测试暴力破解下各哈希算法的性能表现。Hashcat 自称是目前世界上最快的密码恢复程序,支持多种哈希算法。为了对比验证本文计算系统的性能,选择CPU 和GPU 分别运行Hashcat 进行对照,实验结果如图9 所示。
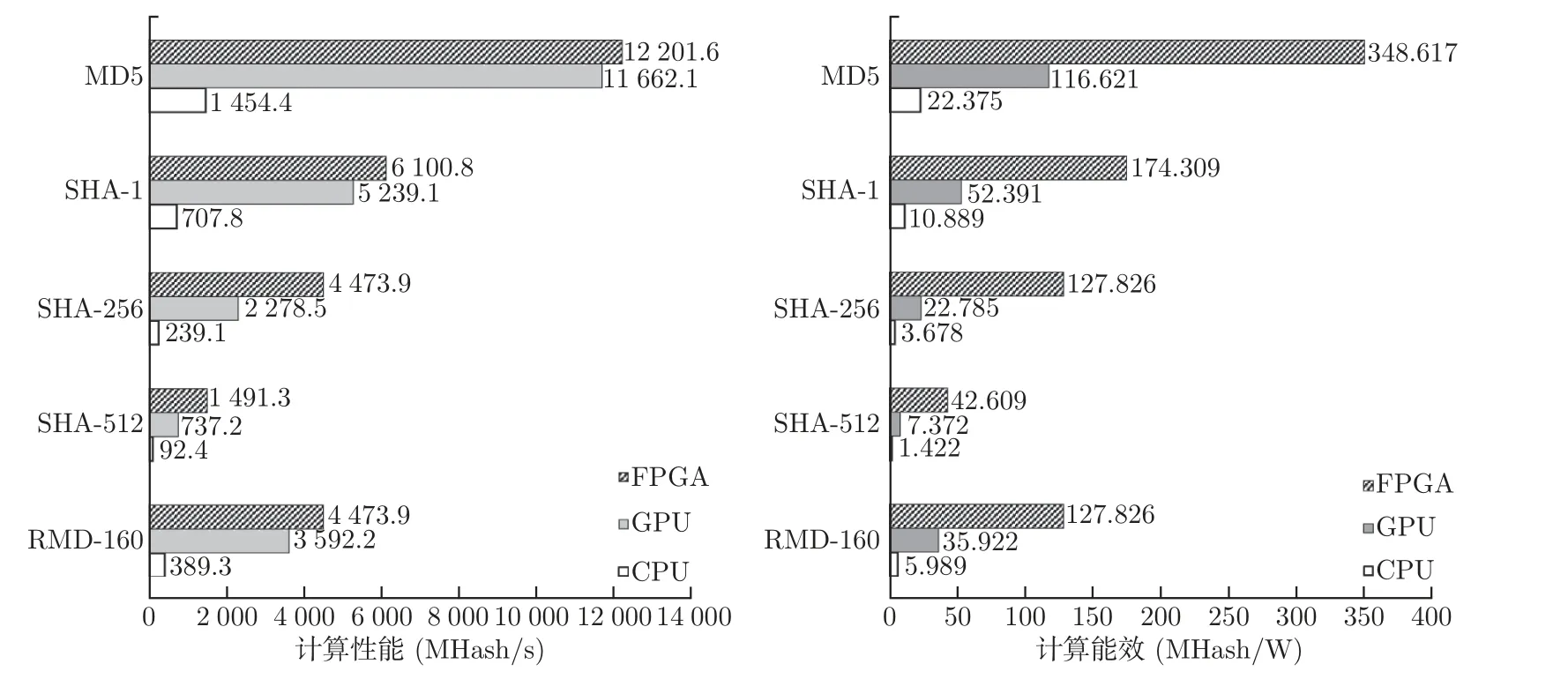
图9 不同计算平台加解密对比Figure 9 Comparison of encryption and decryption of different computing platforms
本文实现了5 种哈希算法的加速模块设计,计算性能明显高于CPU(I7-10700)、GPU(GTX 1650 SUPER),但是FPGA 的功耗明显低于GPU。性能提升最明显的SHA-256 算法,FPGA的计算性能是GPU 的2 倍,能效比是5.6 倍。在加解密时,将待破解哈希值传输到FPGA,在FPGA 上设计对比验证模块,降低了数据在全局内存传输的延迟,使各个计算单元的计算性能和工作频率持平,证明了哈希算法能够以全流水线结构执行,每个时钟周期可以完成一次哈希计算。表6 中展示了不同哈希算法内核能够设置的计算单元数量,以及每个计算单元的性能。
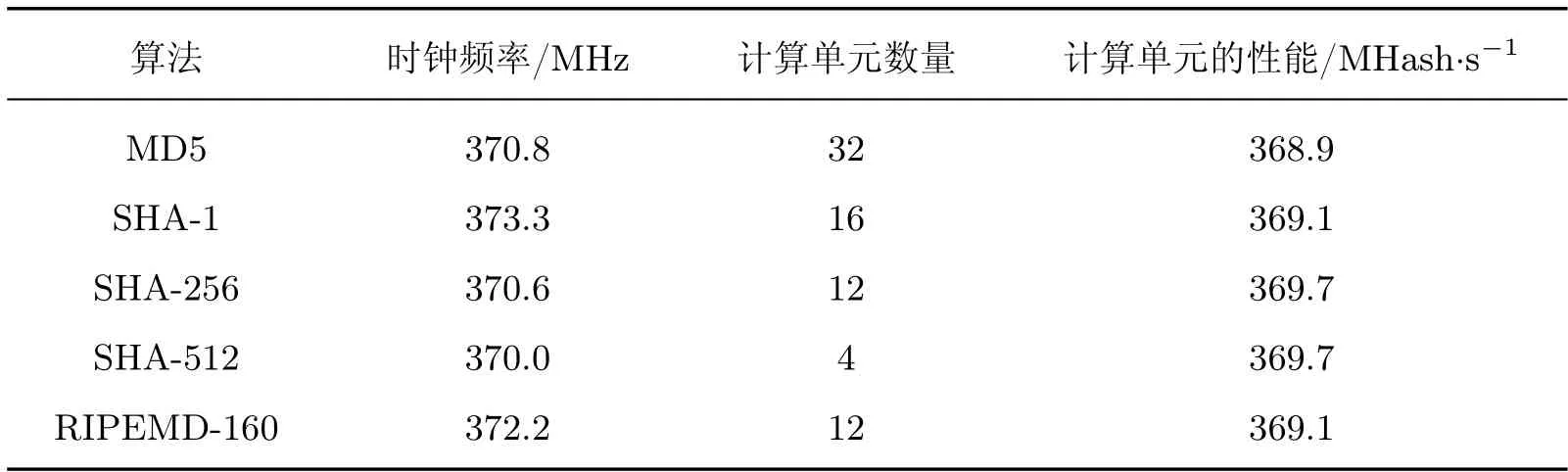
表6 加解密各计算单元性能Table 6 Computing performance of each computing unit for encryption and decryption
4.4 计算系统的可重构机制
为了进一步验证计算系统的可重构机制的性能,本文设计了包含不同哈希算法的计算任务,分别在本文设计的计算系统中和CPU 计算平台上进行测试并对比结果,CPU 使用的测试软件使用开源软件库OpenSSL 中开源的哈希算法代码实现,保证测试结果的可靠性。选择本文实现的5 种哈希算法进行测试,测试内容为连续执行这五种算法各10 亿次,测试结果如图10 所示,其中FPGA 的测试结果包括了可重构的时间。
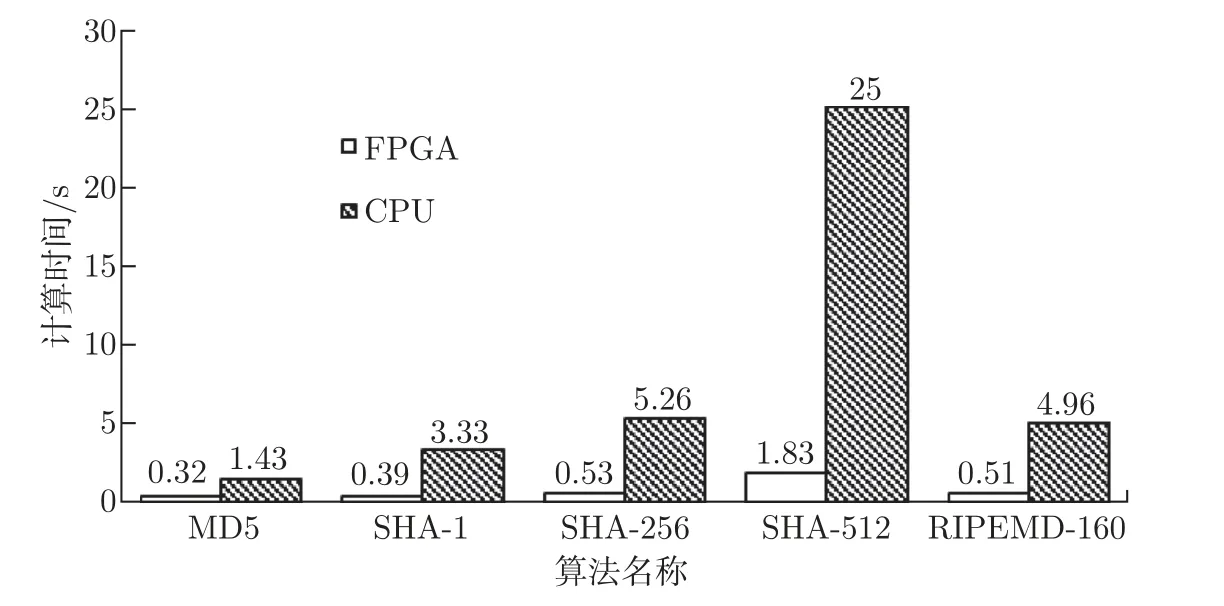
图10 不同哈希算法的计算时间Figure 10 Calculation time of different hash algorithms
本文在使用计算系统进行性能测试时,对FPGA 硬件重构的时间也进行了测试。5 种哈希算法重构的时间基本保持在180∼200 ms 之间。从测试结果可以发现,对于5 种哈希算法,CPU 计算的时间都明显大于FPGA。虽然FPGA 在重构时需要花费额外的时间,但是比起对于算法性能的提升,这明显是值得的。
5 结语
本文针对哈希算法在实际应用中对高速计算和多算法组合的需求,提出了一种异构且可重构的计算系统,由软件和硬件协同处理,发挥异构计算优势。硬件加速设计使用可重构技术,提升系统整体计算能效。在FPGA 上实现计算系统,并应用于加解密,实验结果表明对MD5、SHA-1、SHA-256、SHA-512、RIPEMD-160 等算法性能提升明显,相较于CPU和GPU 计算平台,性能分别提升了8.3∼18.7 倍和1∼2 倍,能效分别提升了15.5∼34.7 倍和2.9∼5.7 倍。虽然本文仅实现了Merkle-Damgard 结构的5 种哈希算法,但是对于其他同结构的哈希算法也可以推测具有性能提升。本文设计的计算系统,由于使用异构计算实现,可以便捷地应用于不同地场景中。除了本文已经实现的加解密计算,哈希算法在数字货币、区块链[25]以及数据验证等领域也有很广泛的应用空间,具有较高的实用价值。
猜你喜欢
今日农业(2021年9期)2021-07-28
高技术通讯(2021年5期)2021-07-16
当代陕西(2019年13期)2019-08-20
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
新农业(2016年23期)2016-08-16
工业设计(2016年8期)2016-04-16
计算机工程(2015年8期)2015-07-03
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
