
基于医学大数据的临床科研模型智能化构建研究
2023-12-04 14:31黄艺璠
重庆医学 2023年22期
王 飞,汪 鹏,黄艺璠,李 颖,胡 川
(陆军军医大学第一附属医院医学大数据与人工智能中心,重庆400038)
近年来,随着医学多模态数据的不断汇聚和人工智能技术的迅猛发展,基于大数据的临床研究已成为医学与计算机科学交叉融合的热点方向,越来越多的临床研究趋向于使用人工智能技术对医学数据进行建模、训练、分析,形成回顾性结论或前瞻性预判[1]。在医疗领域,将人工智能算法模型的构建方法与应用工具对临床科研人员开放,对建模方法进行流程化设计与实现,使其能够通过信息化工具进行算法模型的智能化构建,将有助于提高自主化、个性化临床研究能力,提升临床科研水平[2]。
1 需求分析
基于医学大数据的临床研究过程(包括数据采集与处理、数据标注与训练、模型迭代与应用等几个典型阶段),其核心在于采集相关原始数据进行清洗、去重、标注等处理后做算法训练支撑以验证研究思路与结果[3]。然而,对医疗行业而言,存在大量文本、影像等多模态数据[4],临床研究的主要瓶颈问题聚焦在以下两个方面。
1.1 如何对汇聚的文本与影像数据进行信息关联
临床诊疗数据类型丰富、结构复杂、模态多样,将影像数据与病历、检查等文本数据打通和融合是医学大数据应用和人工智能探索的重要方向,不同模态数据之间的有效融合与内部关联展示仍未得到充分体现[5]。基于本体构建方法,在文本结构化提取模型融合术语库,实现表述归一化的基础上,如何对影像数据进行结构化处理,将病灶类型、病灶大小、解剖学位置、影像学征象等核心内容与病历、检查报告等信息进行关联,实现多维综合分析处理与跨模态检索匹配仍是临床研究在数据搜索层面须解决的首要问题[6]。
1.2 如何建立符合医学数据特征的模型构建方法
在医学领域,人工智能为临床研究与诊疗提供了算法和模型支撑,包括Faster R-CNN、Logistic Regression、SVM、Random Forest等[7]。但由于医学本身的复杂性,现有框架体系下的算法模型还不能完全满足个性化研究需求,需要相关技术人员配合完成标注、调参、训练等过程[8]。如何结合医学研究流程,对模型自主化构建与自适应调参等进行工程化封装,实现模型自主构建、智能调参、迭代优化等功能,也是临床研究在工程化开发与应用层面提出的重要需求。
因此,对临床研究模型的构建流程进行信息化处理,将数据搜集、模型建立、统计分析等方法工具化,有助于进一步辅助科研人员灵活、高效地运用大数据与人工智能相关方法进行科学研究。
2 流程设计
基于医学大数据的临床科研模型构建的流程需经过临床问题定义、数据收集、数据处理、模型构建等几个主要步骤。临床问题定义:把建模解决的问题进行细化,让一个无法进行建模或分析的任务变成可执行的内容。数据收集:根据定义的临床目标,对数据进行采集与汇聚,主要涉及电子病历、检查、检验、移动医护、病理等主要业务信息系统数据[9-10]。数据处理:包括数据标签、数据清洗、缺失值填充、变量处理、归一化等。对重复值、异常值进行处理,以完善数据质量;根据模型对数据特征的要求,对空值、缺失值进行填充,按比例缩放使之落入特定的区间。模型构建:通过特征之间的关系,补充特征、过滤特征及选择特征,对模型进行超参数优化与迭代,对准确率、灵敏度、特异度和马太相关系数等指标进行验证与评价。模型构建流程见图1。
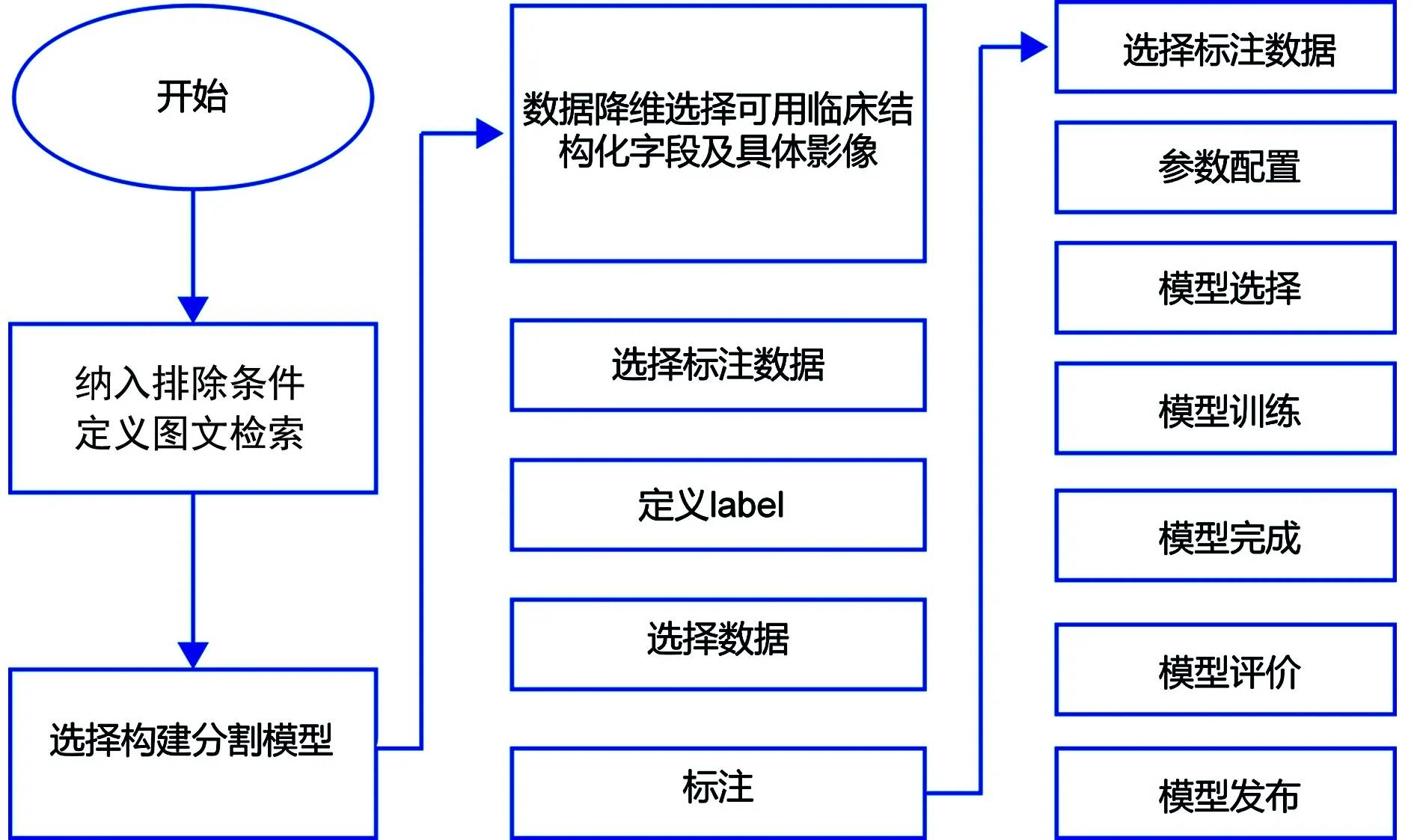
图1 模型构建流程图
3 功能构建
3.1 图文结合的多模态数据库与搜索引擎
基于大数据技术框架,采集整合患者诊疗数据,包括病历文书、医学影像、实验室检验、病理检测等,应用大数据存储搜索、大数据治理、多模态特征结构化提取等技术,构建多模态数据库与搜索引擎[11],见图2。
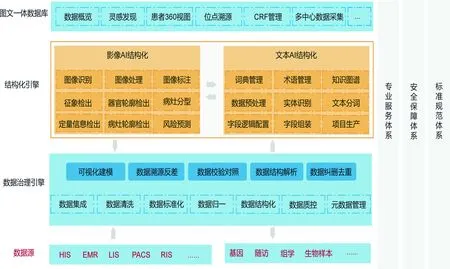
图2 数据采集与治理框架图
文本数据标准化与结构化:基于已建立的医学大数据治理平台,结合患者真实入院、出院记录中主诉、手术、影像报告、病理等医学文本数据,使用多个信息抽取模型提取症状、病灶信息、诊断结果等信息。同时,提取疾病原词、手术原词,将其归一化处理[12]。
影像数据集建立:以影像特征建立数据集,提取影像信息tag值进行结构化处理,影像信息提取结果可与检查报告文本信息进行关联。影像病灶识别支持对病灶自动进行检测,圈定ROI区域,并能够对检测的ROI进行分类,甄别病灶ROI及非病灶ROI,以及对病灶ROI进行检测结果及定位的输出,支持ROI区域的快速访问[13]。病灶特征描述包括大小、密度、位置、征象、历史配准、倍增时间等。
多模态数据搜索引擎构建:将影像高维数据集与临床信息数据集进行整合,进而实现临床文本数据与影像数据的高精融合,构建图文结合的多模态数据库。基于深度学习的多模态影像数据和文本资料表示方法,实现基于图像深度特征与局部语义感知的语义层次模型,通过注意力机制等方式获取细粒度语义区分能力,有效解决多语义、图描述和细粒度交互等问题,进而提高图文匹配的准确度[14]。基于混合迁移学习策略和深度重构哈希机制的高层语义特性图像标注方法,引入标签偏置正则约束机制,建立基于双向特征学习的“图像-文本”跨模态检索方法和支持系统。
3.2 基于机器学习的流程化建模方法
根据影像数据特点,提供合适的医学影像模型框架,建立机器学习模型流程化建立方法[15]。影像研究的每一个任务都可以看成一个机器学习,其目的就是建立输入的影像数据与临床结论之间的关系,并将这种关系以机器学习模型的形式存储起来,当有新影像数据的时候,可以使用机器学习模型进行结论预测,见图3。
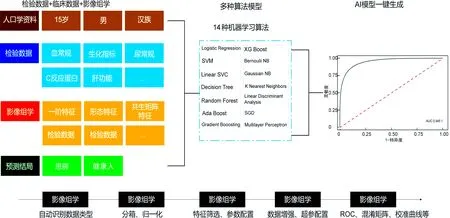
图3 医学模型建立与评估流程图
影像多维度特征提取:针对多模态影像数据,采用基于multi-phase FCN的深度学习算法,提取并比较分析多种模态下肿瘤的高维影像学特征,实现病变区域的精准分割;针对分割出的病灶,实现基于multimodal and multiscale CNN的深度学习算法充分提取不同维度的影像特征,并通过神经网络算法分析多模态影像学特征和肿瘤的关联[16]。
特征选择:主要包括两个部分,第一部分是从影像数据中高通量地提取影像特征,第二部分是应用这些特征建立有价值的预测模型。特征选择需要挑选与临床结论相关的、不冗余的特征信息,可提供多种单因素、多因素和联合方法,包括F-test、皮尔逊、互信息、L1正则、树模型、循环特征删除等6大类特征选择方法,并支持数值特征自动选择。
机器学习模型算法:在获得了高通量影像特征并经过选择后,提供常用的多种机器学习模型算法,包括Logistic Regression、Random Forest、SVM等,以支持完成机器学习建模流程。为了更好地掌控模型训练过程,将开放机器学习算法在建模过程中的参数调节接口,研究人员可通过选择合适的算法模型和调整模型的参数来改变算法的效能,从而获得更好的模型[17]。
3.3 临床研究流程化实现
文本与影像智能搜索:应用自然语义处理技术,结合医疗专业术语的语义结构,实现医疗语义信息从原始的自然语言表达扩展分析为结构化的Key-Value模式[18]。对原文使用关键词进行搜索,满足多个搜索条件间的逻辑关系,支持多层逻辑关系或与非的嵌套组合,快速完成科研纳入排除过程。对影像数据进行清洗筛选和重采样,支持影像高维度量化变量提取,将影像特征提取的数据纳入数据库,形成影像tag、影像病灶轮廓信息检索。
医学模型流程化构建:集成影像处理算法包,建立影像数据标注、多维度特征提取、特征选择、模型建立、研究结果分析全流程的医学模型构建功能。其中数据标注包括手动分割、半自动分割、扩展标注、插值标注等功能,可自动检测出病灶并分割,实现自动勾勒标注;同时,临床研究人员可完成像素级图像标注,支持淋巴结的自动识别、自动分区,自动完成影像标注。多维度特征提取可从影像数据中提取出>1 000维度的影像特征,可对数据的缺失值和异常值进行补全或删除处理。特征选择提供多种单因素、多因素和联合方法,支持与临床结论关联程度较高的特征参数。模型建立提供包括Logistic Regression、Random Forest、SVM等模型算法,实现个性化选择。研究结果分析可以输出一般研究所需要的ROC曲线下面积(AUC)、灵敏度、特异度等值,并展示模型训练和校验结果[19]。
4 小 结
通过对临床科研模型智能化构建的研究,建立流程化、模块化、智能化的数据采集、处理、标注、建模、分析等功能,满足研究人员对数据检索、数据标注、模型构建等方面的个性化需求,在一定程度上解决了人工智能算法应用在临床研究上的技术和工程阻碍,提升了临床科研与应用能力。但在实际应用中,根据模型构建的几个关键步骤,还需关注以下方面。
4.1 数据质量
高质量的数据集是支撑医学研究的前提条件,在应用过程中需考虑从数据获取、处理、业务适配等方面进行差异性分析。要对汇聚的数据按层级进行质控规则校验,对不满足值域设定的要进行排除,按照规则的分类进行分类筛选[20]。
4.2 数据标注
当前的数据标注方式仍由临床科研人员进行手动标注,标注耗时长、精度低、一致性差,不同人员对同一份数据的标注,同一个人对同一份数据在不同时间的标注都会略有差异,不利于后续用数据进行模型训练。
4.3 模型迭代
医学影像数据的处理关键是提取数据的特征和属性,根据特征值与属性值进行分类和关联分析。而使用的分类模型和分析方法都对最终的分析结果产生影响,如何选取最佳数据挖掘分析方法,需要不断地进行参数调整与验证。
4.4 数据安全
医学大数据研究涉及病历文本、影像等大量诊疗数据,须重点防范出现数据安全问题。要建立多角度的防控措施,包括大数据集群建立单独的管理区,在核心交换机划分专用VLAN,部署数据库审计、堡垒机的安全设备等,对数据进行实时监控,确保数据安全。
猜你喜欢
动漫星空(兴趣百科)(2020年12期)2020-12-12
High Technology Letters(2020年4期)2020-11-27
祝您健康(2020年4期)2020-05-20
解放军医学院学报(2020年12期)2020-03-29
新校长(2016年5期)2016-02-26
西南军医(2016年2期)2016-01-23
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
科学中国人(2015年13期)2015-02-28
计算物理(2014年2期)2014-03-11