
基于随机森林的抗乳腺癌候选药物的优化
2023-12-02 15:26:28汤仕星曾莹
湖北工业大学学报 2023年1期
关键词:随机森林
汤仕星 曾莹

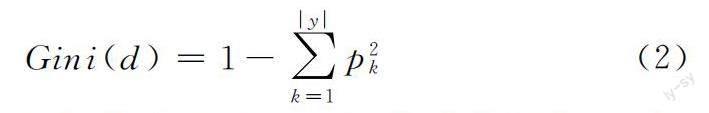
[摘 要]充分利用药物大数据平台和临床资源,运用数据分析方法预测抗乳腺癌候选药物的ADMET性质和抗乳腺癌活性,为实验室研制抗乳腺癌新药过程提供参考方向。针对1974种化合物的分子描述符变量数据,分别构建以ADMET性质和pIC50值为因变量的随机森林预测模型,模型的预测精度分别为88.7%和91.3%。基于随机森林模型求得的重要影响因子贡献率确定出4个变化显著的共同重要影响因子的取值范围,分别为MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)和SdssC(-1.92,2.76),对实现抗乳腺癌药物的优化具有指导意义。
[关键词]抗乳腺癌药物;抗乳腺癌活性;ADMET性质;相关性检验;随机森林
[中图分类号]F213.5 [文献标识码]A
乳腺癌是指在多种致癌因子的作用下,乳腺的上皮细胞发生增值失控的一种现象,是目前世界上最常见的致死率较高的癌症之一。对于治疗乳腺癌的药物研究,国内外已有不少学者在乳腺癌分子靶点和靶向治疗方向上取得显著进展,已发现不少抗乳腺癌活性表现良好的化合物,且在临床实践中取得明显疗效[1],例如查耳酮类化合物、他莫昔芬和雷诺昔芬;靶向治疗的优越性在于能在细胞分子水平上基因调控,代谢通路,某一靶点特异性结合而达到治疗作用,最终导致部分癌基因表达失调、肿瘤增殖减弱、受体表达缺失等。特别是雌激素受体α亚型(ERα)作为乳腺癌内分泌疗法的主要靶点[2],在超过70%的乳腺癌患者[3-5]中过度表达,因此拮抗ERα活性的化合物可能是治疗乳腺癌的候选药物。
近年来随着药物大数据平台的实现,丰富的原始临床试验数据[6]为构建化合物的定量结构-活性关系奠定了数据基础,不少学者在研究治疗乳腺癌过程中运用数据挖掘方法得到重要结论。例如秦璞应用随机森林和支持向量机对三阴性乳腺癌基因数据的降维和筛选[7],得到部分基因和三阴性乳腺癌的转移或者预后有相关性等;随着抗乳腺癌药物的生物活性被逐渐深入研究,评价抗乳腺癌药物的副作用的研究也越发受到关注,例如魏静通过实验研究得到羧甲基β-葡聚糖联合阿霉素具有协同抗乳腺癌以及减轻心脏毒性的功能[8]。国内外学者研究表明药效性和药代动力学的研究可以为新药研发提供指导,进而优化药方设计,通过将其与药物的靶点、理化性质等各方面信息相结合,可以发现其中存在的客观规律,为药物研究提供新思路。
随机森林是基于分类回归树的集成算法[9]。对于海量数据的研究,区别于传统的多元线性回归模型[10],随机森林算法在处理回归问题时能够克服协变量之间复杂的交互作用,且毋需預先设定函数形式[11],相较于神经网络[12],随机森林算法在处理分类问题时不易过度拟合,因而随机森林算法被广泛应用于各领域研究并取得较好效果,为此将随机森林模型应用于拮抗ERα活性的抗乳腺候选药物的ADMET性质的研究。相较于国内外学者通过临床试验探求新药的药效性的同时还要对新药的副作用进行验证的漫长过程,构建随机森林预测模型,充分挖掘临床试验数据的内在价值,不仅能更准确得到化合物的ADMET性质和生物活性,而且可以筛选出能共同影响化合物ADMET性质和生物活性的重要因子,进而优化抗乳腺癌候选药物的筛选过程,为寻求潜在的优质抗乳腺癌药物提供实证研究。
1 模型和数据
从阿尔伯塔大学的DrugBank药物分子数据库中获取针对ERα靶点的化合物样本集[13]。DrugBank数据库拥有独特的生物信息学和化学信息学资源,它将详细的药物数据和全面的药物目标信息结合起来,以便科学家们研究药物机制和探索新型药物[14]。数据集包含了1974个化合物样本,并给出了每个化合物的SMILES式,每个化合物样本都有729个分子描述符变量,1个生物活性数据(IC50为测定值、pIC50为转化值)和5个ADMET性质数据(Caco-2、CYP3A4、hERG、HOB和MN)。
1.1 符号说明
Erα:雌激素受体α亚型;IC50:ERα的生物活性值(值越小代表生物活性越大,对抑制ERα活性越有效);pIC50:IC50值转化而得的ERα的生物活性指标(与生物活性具有正相关性);ADMET:药代动力学性质和安全性;Caco-2:小肠上皮细胞渗透性;CYP3A4:细胞色素P450酶(Cytochrome P450, CYP)3A4亚型;hERG:化合物心脏安全性评价;HOB:人体口服生物利用度;MN:微核试验。
1.2 模型设定
1.2.1 相关性检验 本文采用皮尔逊相关系数[15]判断不同的变量之间的相关程度,其公式为:
其中:n代表样本的个数,xi,yi分别表示两个变量的第i个样本值,相关系数r的取值范围为[-1,1]。r值越大,表示其相关性越强,当r>0,表示两个变量间呈现正相关,r<0,表示两个变量为负相关。
1.2.2 随机森林 决策树是一种基于IF-then-else规则的算法,属于有监督学习算法[16]。它是一种树形的结构,每个节点表示其一个树形上的判断,每个分支表示其一个判断结果的输出,它是根据基尼系数通过训练数据统计而得到的。基尼系数的大小代表数据集中样本的差异程度大小,基尼系数越大说明数据集的种类越多,即说明有多种的分类结果。其计算公式为:
决策树的缺点就是可能会对训练的数据过拟合,而随机森林通过构造很多棵树的方式,在得知每棵树的预测结果的情况下,综合分析每棵树的分类和回归预测结果,不仅可以减少过拟合,而且还能很好的保持树的预测效果。
1.3 数据准备
1.3.1 数据预处理 对分子描述符变量值进行初步的分析发现:样本集中数据不存在缺失值,除了化合物的SMILES属性是字符型外,其他字段的变量都是数值型且有明确含义,数据是完备的。依据相关性检验,通过R软件循环遍历求出pIC50指标与729个变量的相关系数,发现存在225个缺失值,即有225个分子描述符变量的取值全为零,可认为其包含有用信息的可能性较少,这些分子描述符的变量值在化合物样本的分类和回归问题无区分度。考虑到随机森林会出现树的冗余现象,为提高算法的计算效率,数据处理时剔除这些无差别的变量,将剩余的504个变量组成一个新训练集。
1.3.2 确定IC50和pIC50函数关系 为了保持生物活性指标与生物活性具有正相关关系,通常将实验测定值IC50通过对数变换进而转换为pIC50值来表示生物活性的强弱,IC50值越小,表明生物活性越强,进而pIC50值越大,实际中它们满足一种特定的函数关系,因此本文引进中间变量ln(IC50)来对数据进行分析,求得ln(IC50)和pIC50的相关系数为-1,证实了pIC50和IC50的负对数满足确定的函数关系。利用R软件对两者进行线性拟合,求得pIC50=-0.4343*ln(IC50)+9,因此可将pIC50作为生物活性指标用于新化合物抗乳腺癌活性的预测,进而也可通过预测出的pIC50值求出IC50实验测定值。
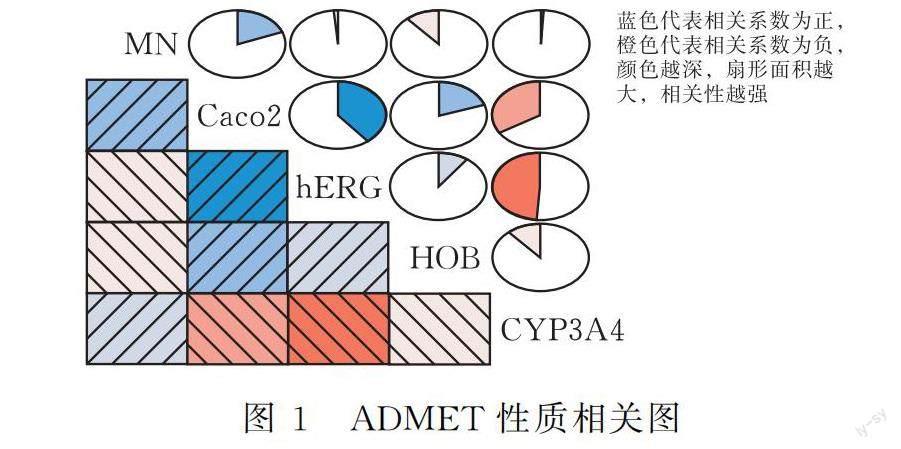
1.3.3 ADMET性质相关性 在化合物样本的ADMET性质数据中,分类变量hERG与MN用“1”表示具有毒性,“0”则表示没有毒性,这与其他3种性质分类变量数据表示的一致性相反,与意识中认为的“1”代表性质好,“0”代表性质劣的逻辑相反,于是先对分类变量hERG与MN进行重编码。在R软件中将hERG与MN的数据重新赋值,将原始数据中的“1”赋值为“-1”,再将hERG与MN的全部数据进行加1操作,使得hERG与MN性质数据中原有的“1”转化为“0”,“0”转化为“1”,于是ADMET性质可同趋势化。然后可以求出ADMET性质两两之间的相关关系,并在R软件中画出ADMET性质相关图(图1)。
从图1中可以看出Caco-2与hERG(0.393)、HOB(0.201)、MN(0.190)之间都存在较弱的正相关性,而CYP3A4与hERG(-0.487)、Caco-2(-0.337)和HOB(-0.113)之间都存在较弱的负相关性,MN与hERG(-0.019)和CYP3A4(-0.010)之间的相关性很小,这使得化合物同时满足ADMET性质最优的情况较少,药代动力学性质和安全性之间很难达到最优。于是可对每个样本的5种ADMET性质变量进行求和,将其记为化合物的ADMET性质得分,ADMET性质得分越高,代表化合物的药代动力学性质和安全性越好。
在1974个化合物样本中ADMET性质得分为3的样本有444个,得分为4的样本有177个,ADMET性质最优即得分5的样本个数仅为11,再求出pIC50和ADMET性质得分的相关系数为-0.261,存在弱负相关性,符合现实中药效性和药代动力学性质与安全性俱佳的化合物很少的现象。为了扩大候选药物的筛选范围,将ADMET性质得分大于等于3定义为ADMET性质较优的化合物并记为“1”,ADMET性质得分小于3定义为ADMET性质较差的化合物并记为“0”,使得将ADMET性质得分二分类。
2 实证分析
2.1 随机森林分类
为了判定不同化合物的药代动力学性质和安全性,用于对抗乳腺癌药物的副作用研究,对于新药的生产提供可参考性建议。将基于化合物的分子描述符变量构成训练得到随机森林分类器用于对化合物的药代动力学性质和安全性的判定,进而筛选出ADMET性质得分更高的化合物,并寻找出影响ADMET性质得分的重要因子。
对于剔除无差别变量后的数据,在R软件中分别构建5种分类变量ADMET性质与504个分子描述符变量的随机森林分类模型,采用默认棵数500,随机抽取90%的样本作为训练集,对分类器进行训练,剩下10%的样本作为测试集用于对模型的评估,分别计算出模型的预测精度。为减小随机因素的影响,再采用R软件中的ipred包的errorest函数进行10折交叉验证,用于计算分类模型的错分率,进而可判断出随机森林分类器的效果(表1)。
表1结果显示,5个随机森林分类模型的预测精度都在85%以上,最高精度达到96%,模型的错分率大部分在10%以内,因此可认为随机森林分类模型的分類准确率都较高,模型具有可行性。
为了寻找出对ADMET性质影响更重要的分子描述符变量,结合ADMET性质得分的优劣,随机森林分类预测模型也可应用于二分类后的ADMET性质得分。考虑到影响ADMET性质得分的因素的复杂性,设置决策树的棵数为1000,将训练后的模型用于测试集的分类预测,然后画出随机森林预测ADMET性质得分效果图(图2)。
通过绘制模型的均方误差图和ROC曲线可见,将ADMET性质较差的化合物错判成ADMET性质较好的错误率为7.94%,将ADMET性质较好的化合物错判成ADMET性质较差的错误率为26.7%,AUC=0.854,95%的置信区间为(0.746,0.962),计算得到模型的错分率为13.9%,预测精度为88.7%。较单个分类模型预测效果有所下降,可能是因为ADMET性质之间的相关性,造成现有的样本数据的价值信息不足,进而提高了错分率。
2.2 随机森林回归
随机森林作为集成学习常用的模型,通过建立多个决策树不仅可以用于解决分类预测问题,也常用于解决回归预测问题,且模型的准确率较高。将基于化合物分子描述符构成数据训练得到的随机森林预测模型用于对化合物抗乳腺癌活性的检测,便于筛选出生物活性更好的化合物作为抗乳腺癌候选药物,并找出影响抗乳腺癌活性的重要分子描述符。
针对含有504个不同分子描述符变量和pIC50值的数据集,随机将1974个样本平均分成10份,取出9份用于随机森林预测模型的训练,另外1份作为用于评估模型预测精度的测试集。通过R软件构建以pIC50值为因变量的随机森林预测模型,将训练后的模型用于测试集的预测,然后画出随机森林回归模型的预测效果图(图3)。
从图3可以看出真实值与预测值的散点均匀分布在y=x直线的两侧,且散点在一个狭长的范围内;通过真实值和预测值的数据概况可以发现,真实值的分布相对均匀,适合作为测试集代表一般预测样本,预测值的均值和真实值的中位数大致相等,分布相对真实值更为集中,这和随机森林在同一类样本中取特征的平均值作为输出有关。通过R软件计算可知预测值与真实值之间的相关系数为0.913,在訓练数据变量如此之多和测试集预测样本较大的情况下,可解释性方差还能达到75.73%,残差平方均值为0.507,相对多元线性回归模型的预测准确率好很多,因此认为随机森林用于抗乳腺癌活性的检测是有效的,具有一定的优越性。
2.3 随机森林优化
为了寻找出药效性良好同时具有良好的药代动力学性质和安全性的候选药物,即在化合物保持抗乳腺癌活性良好的同时具有更高的ADMET性质得分。需要找到能共同影响生物活性pIC50值和ADMET性质得分的重要因子,而随机森林在预测pIC50值的同时可根据分子描述符变量的可解释性方差的大小计算出各变量的贡献率,在处理ADMET性质得分的分类问题时,可根据各个分子描述符变量的袋外误差率与原误差率的差值大小计算出分子描述符变量的重要程度。依据上述研究,通过随机森林模型可分别求出影响pIC50值大小和ADMET性质得分排名的前30个重要影响因子,利用R画出重要影响因子曲线图(图4)。
由图4可以发现:在影响pIC50值和ADMET性质得分的前30个重要变量中,能共同显著影响pIC50和ADMET性质得分的变量共有9个,分别是MLFER_BH、MLFER_S、ETA_Shape_Y、minHBa、MDEC-33、VCH-7、ATSc2、WTPT-5和SdssC。
为了进一步优化候选药物的筛选,可参考化合物在共同重要影响因子上的表达,划定共同重要影响因子的取值范围作为候选药物的基本条件。可在研究治疗乳腺癌候选药物时充分利用药物大数据平台和临床资源,大大节省人力和物力成本,而划定共同重要影响因子的取值范围显得尤为重要。
确定共同重要影响因子的取值范围需要满足分子描述符变量在化合物样本中显著表达的特征,于是设定在所有化合物样本中抗乳腺癌活性排名前25%且药代动力学性质和安全性较好的化合物属于优质抗乳腺癌候选药物。通过判断pIC50值是否大于上四分位数7.57和ADMET得分是否大于等于3,筛选出69个优质抗乳腺癌候选药物,对比优质抗乳腺癌候选药物和总体化合物样本在共同重要影响因子上的取值范围。发现优质抗乳腺癌候选药物的部分共同重要影响因子的取值范围较大,相较于总体化合物样本的共同重要影响因子的区间长度衰减并不明显,这样得到的共同重要影响因子的取值范围对于候选药物的优化意义不大,于是设定区间长度衰减的阈值为20%,即衰减后的区间长度小于全局区间长度的20%认定为表达更显著的重要影响因子。通过迭代优化,从9个共同重要影响因子中找到了4个变化更为显著的变量,并求出其取值范围见表2,然后在R中画出表达显著的共同重要影响因子在优质抗乳腺癌候选药物中的分布直方图(图5)。
从表2可以看出:共同重要影响因子MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)、SdssC(-1.92,2.76)的衰减区间长度均大于总体区间长度的85%以上,因此可以认为这些因子在优质抗乳腺癌候选药物中表达更显著,它们的取值将更有可能共同影响抗乳腺癌候选药物的抗乳腺癌活性和ADMET性质。
由图5可以发现:优质抗乳腺癌候选药物的共同重要影响因子除了相对总体样本取值的分布更为集中之外,它们的分布还近似满足某一区间内的正态分布,因此可以认为这些共同重要影响因子在优质抗乳腺癌药物中有在其均值附近波动的趋势,共同重要影响因子不在此区间范围之内的化合物有可能在药效性和药代动力学性质与安全性中表达异常,便于筛选出劣质抗乳腺癌候选药物,简化抗乳腺癌药物的优化过程。
3 结论
针对实验室研发抗乳腺癌新药的艰难而漫长的过程,为了提高新药物研发的效率、缩短研发周期、节省时间和成本。本文选取1974种化合物的高维分子描述符变量数据,分别构建了以ADMET性质为因变量的随机森林分类预测模型和以pIC50值为因变量的随机森林回归预测模型,模型的预测精度都较好,判定模型具有可行性。基于随机森林计算得到的袋外误差与原始误差的差值大小和可解释性方差的大小判定重要因子贡献率,从ADMET性质和pIC50值排名前30的重要影响因子中筛选出9个共同影响因子,再通过设定优质抗乳腺癌候选药物的衰减阈值为20%确定4个表达显著的共同重要影响因子,并求出其取值范围,分别为MLFER_BH(0.56,2.65)、MLFER_S(1.30,4.41)、WTPT-5(0.00,10.01)和SdssC(-1.92,2.76)。随着药物大数据平台和合成药物技术的发展以及进一步临床试验的数据验证,控制变化显著的4个共同重要影响因子在最优的取值范围之内,将更容易实现抗乳腺癌新药物满足良好的生物活性且具有良好ADMET性质,达到抗乳腺癌候选药物优化的目的。
[ 参 考 文 献 ]
[1] DE LAURENTIIS M, CIANNIELLO D, CAPUTO R, et al. Treatment of triple negative breast cancer (TNBC): current options and future perspectives[J]. Cancer Treatment Reviews, 2010, 36(suppl.3):80-86.
[2] 宁文涛, 胡志烨, 董春娥等. 抗乳腺癌双靶点药物研究进展[J]. 中国药物化学杂志,2020,12(30):778-788.
[3] HARBECK N, PENAULT-LLORCA F, CORTES J, et al.Breast cancer[J].Nat Rev Dis Primers, 2019,5(01):66.
[4] GUAN J, ZHOU W, HAFNER M, et al.Therapeutic ligands antagonize estrogen receptor function by impairing its mobility[J]. Cell,2019,178(04):949-963.
[5] SIEGEL R L,MILLER K D,JEMAL A.Cancer statistics,2018[J].CA Cancer J Clin,2018,68(01) :7-30.
[6] 袁升月, 金羿, 廖俊. 藥物大数据平台在抗乳腺癌药物药代动力学/药效学研究中的应用[J]. 中国临床药理学杂志,2017,23(33):2464-2467.
[7] 秦璞, 郭志旺, 郭维恒等. 应用随机森林和支持向量机对三阴性乳腺癌基因数据的降维和筛选[J]. 中国卫生统计, 2020,37(03):71-76.
[8] 魏静,李婷英,张莹等. 羧甲基β-葡聚糖联合阿霉素抗乳腺癌以及减轻心脏毒性的实验研究[J]. 中国临床药理学杂志,2021,37(03):275-279.
[9] BREIMAN L. Random Forests [J]. Machine Learning,2001(45):65-68.
[10]吴喜之.多元统计分析[M].北京:中国人民大学出版社, 2019:245-247.
[11]曹桃云,陈敏琼.基于学生化极差分布的随机森林变量选择研究[J].统计与信息论坛,2021,36(08):15-22.
[12]王奕森. 随机森林和深度神经网络的若干关键技术研究[D].北京:清华大学,2018.
[13]LEI T L, SUN H Y, KANG Y, et al. ADMET evaluation in drug discovery. 18. reliable prediction of chemical-induced urinary tract toxicity by boosting machine learning approaches[J]. Molecular Pharmaceutics, 2017, 14(11): 3935-3953.
[14]许美贤, 郑琰, 李炎举,等.基于PSO-BP神经网络与PSO-SVM 的抗乳腺癌药物性质预测[J].南京信息工程大学学报,2022,1.18:3.
[15]孙兆亮. 数学建模算法与应用[M].北京:国防工业出版社, 2017:425-428.
[16]丘佑玮. 机器学习与R语言实践[M].北京:机械工业出版社, 2016:146-170.
Optimization of Anti Breast Cancer Drug
Candidates based on Random Forests
TANG Shixing,ZENG Ying
(School of Science, Hubei Univ. of Tech., Wuhan 430068,China)
Abstract:By making full use of big pharmaceutical data platforms and clinical resources, we used data analysis methods to predict ADMET properties and anti-breast cancer activity of anti-breast cancer drug candidates. It provided a reference for the process of developing new anti-breast cancer drugs in the laboratory. Random forests were constructed for the molecular descriptor variable data of 1974 compounds, and the dependent variables of prediction models were ADMET properties and pIC50 values. The prediction accuracies of the models were 88.7% and 91.3% respectively. Based on the random forest model, we obtained the contribution rate of important impact factors. Then we established the ranges of four common significant influencers that varied significantly. They were MLFER_BH (0.56,2.65), MLFER_S (-1.30, 4.41), WTPT-5 (-0.00, 10.01) and Sdssc (-1.92, 2.76). The result was instructive to optimize the anti-breast cancer drugs.
Keywords:anti-breast cancer drugs; anti-breast cancer activity; ADMET properties; correlation test; random forest
[责任编校:闫 品]
猜你喜欢
中国中药杂志(2017年7期)2017-05-26 00:10:21
湖北农业科学(2017年7期)2017-05-13 08:01:24
电脑知识与技术(2017年5期)2017-04-08 13:00:44
时代金融(2017年6期)2017-03-25 22:21:13
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电脑知识与技术(2016年23期)2016-11-02 23:25:12
软件(2016年2期)2016-04-08 02:06:21
现代电子技术(2015年15期)2015-08-14 21:28:48
