
基于Gossip的异步分布式训练算法
2023-12-02 12:11:16周嘉涂军任冬淋
湖北工业大学学报 2023年1期
周嘉 涂军 任冬淋
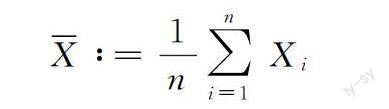
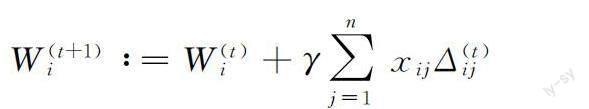
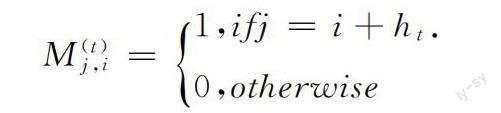
[摘 要]因此基于Gossip协议并结合SGD(Stochastic Gradient Descent)提出了一种用于深度学习的通信框架GR-SGD(Gossip Ring SGD),该通信框架是非中心化且异步的,解决了通信等待时间较长的问题。实验使用ImageNet数据集,ResNet模型验证了该算法的可行并与Ring AllReduce和D-PSGD(Decentralized parallel SGD)进行了比较,GR-SGD在更短的时间内完成了训练。
[关键词]非中心化分布式;Gossip;异步
[中图分类号]TP399[文献标识码]A
近年以来,人工智能(AI)在各种科学和工程中得到了越来越多的应用。在使用机器学习(ML)和深度学习(DL)技术处理和训练各行业巨大数据的时候,更大更深的模型有助于进一步提高效率以及准确性。因此,使用分布式模型来处理数据以及提供训练必要的计算资源也变得越来越普遍[1]。
已有的分布式深度学习算法分为中心化分布式算法和非中心化分布式算法。现常用的中心化分布式通信框架是参数服务器(Parameter Server,PS)[2-4]。当今主流研究是在PS框架基础上的改进,如:TensorFlow[5]、CNTK[6]、MXNet[7]。PS框架最大的问题就是中心节点上的通信瓶颈以及安全问题。因此,非中心化算法成为了一种研究趋势。比较典型的就是由百度硅谷人工智能实验室(SVAIL)提出的Ring AllReduce算法,目前,Ring AllReduce算法被应用在Uber开发的Horovod[8]中。虽然该算法解决了PS框架中心节点通信瓶颈的问题,且在大规模GPU集群中的性能高于PS框架[9]。但由于Ring AllReduce是一个同步的算法,所以当集群中有某一个节点速度很慢,甚至宕机时,会导致集群内其它节点无法继续工作。
对此,本文基于Gossip协议并结合SGD(Stochastic Gradient Descent)提出了一种用于深度学习的通信框架GR-SGD(Gossip Ring SGD)。并通过实验与Ring AllReduce算法、D-PSGD(Decentralized parallel SGD)算法进行了比较。
1 相关技术介绍
1.1 Gossip協议
Gossip是目前非中心化深度学习模型训练[10-14]的主要算法之一。该算法最初是为分布式平均问题[15-16]开发的,它迭代地计算对等网络拓扑中所有的多个节点的平均向量。例如,典型的GoSGD算法[12-13]的过程在一个训练epoch中包含三个步骤。首先,对于每个参与者和每次迭代,算法使用参与者的本地输入数据和模型计算梯度,并使用梯度更新参数。这一步通常采用mini-batch梯度下降法。其次,节点根据矩阵向其它参与者发送权重。最后,节点从其它参与者那里接收权重,并将它们与本地权重合并以更新模型。此外,Liu [17]还为D-PSGD[18]算法提供了另一种复杂度范围,它可以改善光谱间隙。
Gossip在DL中的工作流程如算法1的伪代码所示。首先,每个节点初始化本地的模型;然后,模型参数的子集定期发送到网络中的另一个节点。当每个节点接收到这样的参数样本时,它将其合并到自己的模型中,然后执行一个本地更新步骤。尽管所有节点的周期Δ相同,但节点通信的轮次是不同步的。任何收到的消息都会立即处理。
算法1 Gossip 在深度学习中的工作流程
1:Initialize the local model (x)
2:loop
3:wait(Δ)
4:p ← Random selectPeer()
5:send sample(x) to p
6:end loop
7:
8:procedure ONRECEIVEMODEL(r)
9:(x)←merge((x),(r))
10: (x)←update((x),D)
11:end procedure
1.2 平均共识
平均共识问题是使得网络中所有节点达到初始状态均值的一致状态,它可以被广泛的用于参数估计、定位、同步等方面。按照传统的方法将网络中的数据直接汇聚到某个节点中,将产生大量的通信开销并造成通信瓶颈。而Gossip利用节点的本地信息处理能力,仅通过随机唤醒网络中的节点并与邻居节点进行数据交换的方式使网络达到平均共识状态,从而避免了网络中多余的通信开销和瓶颈效应。简单来说,Gossip算法在平均共识的问题上是线性收敛的。平均共识问题包括找到n个局部向量的平均向量,从形式上定义为下面公式:
对于具有压缩通信的共识算法[19],被指出并不能收敛到正确的解[20],只能收敛到解的邻域(其大小取决于压缩精度)。自适应[21]的方法都需要完全(非压缩)通信才能达到较高的精度。而最近Anastasia[22]等人基于Gossip协议提出了新的压缩通信的方法,能够实现线性的收敛。此外Ye[23]等人还提出了多共识非中心化加速梯度下降的方法。
在Gossip协议中,针对平均共识问题通常有公式
其中γ是范围(0,1]的步长参数,xij是[0,1]的平均权重值,Δ(t)ij∈ ?d表示在迭代t的时候节点j发送到节点i的向量。其收敛速度取决于八卦矩阵(X)ij=xij,其中矩阵X∈?n×n。
1.3 系统设计
目的是设计一种异步的非中心化分布式通信框架并应用到深度学习训练中。该框架使用Gossip通信协议而不是MPI。在框架中每个节点都能进行异步的通信,即使其中某一个或者某几个节点出现宕机或者变慢时,整个系统无需等待阻塞节点。没有中心节点意味着每个Worker都被期望收敛到相同的值,Worker之间达成严格的共识。中心节点的缺失可以通过通信矩阵的第一行和第一列为0表示出来,通信都以对等方式执行[15]。通信矩阵中,列是发送方,行是接收方。
通信框架中,使用Gossip协议,Worker不用等待其它Worker的消息也可进行计算的工作。非对称的Gossip协议[24]能转化为通信矩阵X(t)系数非零的约束,因此没有Worker同时发送和接受消息。为了保证算法收敛到共识,权重w(t)m需要与每个变量x(t)m相關并由Workers使用相同的通信方式所共享。当Worker完成本地更新后,被唤醒时会向其它随机Worker发送数据,依次循环。虽然在同一时间每个节点的数据不同或梯度不同,但最终所有节点都会趋于一致。
以4个节点为例,这里设定每个Worker在每次迭代中只发送和接收1条消息。如图1所示,在整个系统中每个时间步长t内只有一个节点被唤醒。当节点0被唤醒时,它随机向其它1个节点发送消息,接收到消息的节点会在本地更新数据,依次循环直至训练完成。在一次迭代中,每个节点会发送1条消息,并接收1条消息,所以在这个网络中通信负载是平衡的。为了保证每个节点在每次迭代中不重复发送和接收消息,本文引入了混合矩阵M(t)。此混合矩阵是列随机的 (列的和为1),每个节点i都可以选择它的混合权重(矩阵M(t)的第i列),因此独立于网络中的其它节点。在图1网络拓扑中,每个节点只随机向其它一个节点发送消息,即得到下面矩阵
这里ht表示在时间步长t内节点邻居间的距离。
1.4 收敛性分析
GR-SGD的收敛性分析基于下面2个假设。
假设1 有界方差。存在2个常数C1和C2,使得
其中i∈[n]。其中C1代表了每个节点上的随机梯度方差,C2代表不同节点上的数据分布。
假设2 f(x)是L-smooth,有
‖?F(x)- ?Fy‖≤L‖x-y‖其中L>0,F(x)是可微的。
即收敛性得到了证明。
2 实验
实验使用华中科技大学的高性能服务平台,在实验的集群中包含16张tesla V100s GPU,每个GPU作为一个节点。实验使用ImageNet数据集以及ResNet50[25]作为训练模型。每个节点使用256的mini-batch大小。实验将Ring AllReduce,D-PSGD和GR-SGD进行对比,在GR-SGD算法中,由混合矩阵控制每个节点在每次迭代中只发送并接收一条消息。对比实验中,将主要体现GR-SGD异步通信算法的优势。
图2给出了GR-SGD、 Ring AllReduce和D-PSGD在4、8、12和16个节点的时间方向的训练收敛。在训练的速度上GR-SGD是明显优于D-PSGD和Ring AllReduce的。可以看到,随着节点数的增加GR-SGD比Ring AllReduce和D-PSGD在更短的时间内完成160个epoch。随着节点数量的增加,GR-SGD和D-PSGD平均迭代时间几乎保持不变,而Ring AllReduce的每次迭代时间明显增加,导致整体训练时间变慢。通过本文实验结果可以推断,当GPU数量不断增大时,GR-SGD的优势会越来越明显。
接下来,为了模拟集群不稳定的情形,在实验时让每个Worker有1/16的概率变慢,这样集群中会产生慢节点和快节点。如图3所示,其中RA1和GR-SGD1代表有节点变慢,当有Worker变慢时,对Ring AllReduce会有比较明显的影响,而对GR-SGD几乎没有影响。很显然这证明了在集群中,使用异步的通信方法能有效增加系统的效率。
3 结论及展望
本文在非中心化分布式深度学习的基础上,参考了现有的Ring AllReduce算法,通过使用Gossip协议以及引入混合矩阵,提出了GR-SGD算法。该算法通过混合矩阵控制节点的通信次数,能实现异步,解决了Ring AllReduce算法会因节点变慢而导致通信等待问题。通过实验,验证并推断了在节点数量庞大的集群中,GR-SGD算法在速度上会优于Ring AllReduce和D-PSGD。在下一步的工作中,将考虑通过混合矩阵增加通信的次数,来达到加快模型收敛,增加训练精度,并为系统带来容错的目的。
致谢:本文的计算工作得到了华中科技大学网络与计算中心提供的高性能计算公共服务平台支持。
[ 參 考 文 献 ]
[1] CHANDRASEKARAN V, RECHT B, PARRILO P A, et al. The convex geometry of linear inverse problem [J]. Foundations of Computational Mathematics 2012,12:805-849.
[2] LI M, ANDERSEN D G, PARK J W, et al. Scaling distributed machine learning with the parameter server[C].∥11th {USENIX} Symposium on Operating Systems Design and Implementation 2014,({OSDI} 14):583-598.
[3] LI M, ANDERSEN D G, SMOLA A J, et al. Communication efficient distributed machine learning with the parameter server[J]. Advances in Neural Information Processing Systems, 2014,27: 19-27.
[4] XING E P, HO Q, DAI W, et al. Petuum: A new platform for distributed machine learning on big data[J]. IEEE Transactions on Big Data, 2015,1(2): 49-67.
[5] MARTN ABADI, PAUL BARHAM, JIANMIN CHEN,et al. Tensorflow: a system for large-scale machine learning[C]. In Proceedings of USENIX Symposium on Operating Systems Design and Implementation (OSDI),2016,265-283.
[6] Seide F, Agarwal A. CNTK: Microsoft's open-source deep-learning toolkit[C].∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016: 2135-2135.
[7] TIANQI CHEN, MU LI, YUTIAN LI, et al. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems[C]. In Proceedings of NIPS Workshop on Machine Learning Systems, 2016.
[8] ALEXANDER SERGEEV, MIKE DEL BALSO. Horovod: fast and easy distributed deep learning in TensorFlow[EB/OL]. 2018, https:∥arxiv.org/abs/1802.05799v3.
[9] ZHANG Lizhi, RAN Zhejiang, LAI Zhi-quan, et al. Performance analysis of distributed deep learning communication architecture[C]. In Computer Engineer & Science,2020.
[10]Oguni H, Shudo K. Communication scheduling for gossip sgd in a wide area network[J]. IEEE Access, 2021.
[11]HAN R, LI S, WANG X, et al. Accelerating gossip-based deep learning in heterogeneous edge computing platforms[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(07): 1591-1602.
[12]BLOT M, PICARD D, THOME N,et al. Cord, Distributed optimization for deep learning with gossip exchange[J], Neurocomputing, 2019,330: 287-296.
[13]BLOT M, PICARD D, CORD M,et al. Thome, Gossip training for deep learning[EB/OL]. (2021-01-02).[2016-11-29].https:∥arxiv.org/abs/1611.09726.
[14]LU Y , SA C D . Optimal Complexity in Decentralized Training[C].∥ International Conference on Machine Learning. PMLR, 2021. [15]S. Boyd, A. Ghosh, B. Prabhakar, and D. Shah, Randomized gossip algorithms[J], IEEE Trans. Inf. Theory, 2006, 2508–2530.
[16]I COLIN, A BELLET, J SALMON, et al. Gossip dual averaging for decentralized optimization of pairwise functions[C]. in Proc. 33rd Int. Conf. Int. Conf. Mach. Learn., 2016,1388-1396.
[17] LIUIU JI, CE ZHANG HANGCE. Distributed learning systems with first-order methods[EB/OL]. (2021-01-02).[2021-04-21]. https://arxiv.org/abs/2104.05245.
[18]LIAN X, ZHANG C, ZHANG H, et al. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent[C]. In Advances in Neural Information Processing Systems, 2017,5330-5340.
[19]YUAN D, XU S, ZHAO H, et al. Distributed dual averaging method for multi-agent optimization with quantized communication[J]. Systems & Control Letters, 2012, 61(11):1053-1061.
[20]XIAO L, BOYD S,LALLa S. A scheme for robust distributed sensor fusion based on average consensus[C]. In IPSN 2005. Fourth International Symposium on Information Processing in Sensor Networks, 2005, 63-70.
[21]THANOU D, KOKIOPOULOU E, PU Y, et al. Distributed average consensus with quantization refinement[J]. IEEE Transactions on Signal Processing, 2013,61(1):194–205.
[22]KOLOSKOVA A, STICH S U, JAGGI M. Decentralized stochastic optimization and gossip algorithms with compressed communication:, 10.48550/arXiv.1902.00340[P]. 2019.
[23]HAISHAN Y E, LUO LUO, ZIANG ZHOU, AND TONG ZHANG. Multi-consensus decentralized accelerated gradient descent[EB/OL]. (2020). https:∥arxiv.org/abs/2005.00797.
[24]KEMPE D, DOBRA A, GEHRKE J. Gossip-based computation of aggregate information[C].In: Proceedings of the Forty-Fourth Annual IEEE Symposium on Foundations of Computer Science,IEEE, 2003, 482-491.
[25]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. In Proceedings of the IEEE conference on computer vision and pattern recognition,2016, 770-778.
Asynchronous Distributed Training Algorithm based on Gossip
ZHOU Jia, TU Jun, REN Donglin
(School of Computer Science, Hubei Univ. of Tech., Wuhan 430068, China)
Abstract:Ring AllReduce algorithm, one of the existing decentralized distributed clusters, can reduce the bottleneck of the central node communication. However, the communication algorithm is synchronous, which will lead to longer communication waiting time inter-node in the cluster. Combined the Gossip protocol with Stochastic Gradient Descent (SGD), this paper proposes a communication framework Gossip Ring SGD (GR-SGD) for deep learning. GR-SGD is decentralized and asynchronous, and solves the problem of long communication waiting time. This paper uses the ImageNet data set and the ResNet model to verify the feasibility of GR-SGD and compares it with Ring AllReduce and D-PSGD, and it turns out that GR-SGD finishes the training in shorter time.
Keywords:distributed Decentralization; Gossip; asynchronous
[責任编校:张岩芳]
