
基于改进DLT算法的单目标识别跟踪研究
2023-12-02 02:09黄君君
太原学院学报(自然科学版) 2023年4期
黄君君
(福建农业职业技术学院 信息工程学院,福建 福州 350007)
0 引言
计算机视觉技术日益受到学者、专家的关注。其中,视频流中未知目标物体的检测跟踪识别是计算机视觉中重要的一部分,具有很广的应用情景。比如,社会面视频监控、智能交通、银行、门禁、机器视觉,及人机交互、司法取证鉴定等[1]。视频跟踪识别的研究目的是获取运动物体的外在信息,通过相关技术对获取的信息进行分类,提高机器的识别判断能力,为视频中的目标行为、动态分析提供重要的数据[2]。因此,许多国内外的学者和爱好者从事相关技术的研究,相关的软硬件技术得到广泛应用[3]。国内的先驱研究者在该技术领域进行了深入的研究,包括从开始简单的单目标检测、跟踪识别到复杂的多目标检测、跟踪识别[4-5]。李志坚等[6]设计了一种高效的概念服务器页面(concept server page,CSP)结构,提高了视频图像特征提取能力,结合Deep Sort追踪算法实现车辆轨迹检测和跟踪的精度达92.8%。邱磊等[7]基于轻量化的EfficientDet网络和视频合成孔径雷达(synthetic aperture radar,SAR)多特征提取技术,解决了SAR阴影目标检测与跟踪的干扰严重、精度低等问题。任红格等[8]针对复杂环境视频图像目标丢失问题,通过ResNet进行深层特征提取,建立短期记忆尺度金字塔,提升视频目标跟踪的成功率。此外,清华大学、中国科学院、华中科技大学、上海交通大学、南京理工大学、西安电子科技大学等高等院校在视频目标的抓取、检测、跟踪、识别方面做了大量的理论研究,在理论上取得了突破。但是,目前国内的研究工作主要是基于理论的研究,还没有研发出稳定性高、实时效果好的视频跟踪检测系统。
本文以视频中运动目标的跟踪检测识别算法为主要研究对象,采用直接线性变化算法(direct linear transformation,DLT),构成DLT算法的三大部分,分别为基于光流法的跟踪器、基于级联分类器的检测器和基于P-N学习的学习器。根据不同的情况对DLT算法进行测试,分析各种情况的测试结果,得出算法中的不足之处,并结合实际情况进行改进,为视频图像目标检测和跟踪技术深度开发提供理论支撑。
1 DLT算法及其改进
1.1 DLT算法结构
DLT算法是一个用于针对视频中未知物体长期跟踪的架构。DLT长时间跟踪任务由3个子任务组成[9],这3个子任务都有各自的功能模块,算法运行时,它们是相互关联并一起运行。跟踪器模块对视频流里的帧不停得跟踪;检测器模块把之前检测到的目标框通过分类器进行处理,根据需求更正跟踪器的错误;学习器模块通过P-N学习对检测器进行估计,并产生检测器的错误,根据这些错误及时更新检测器,从而避免检测器在以后的检测中出现类似的错误。DLT中三大组成部分的工作流程见图1所示。
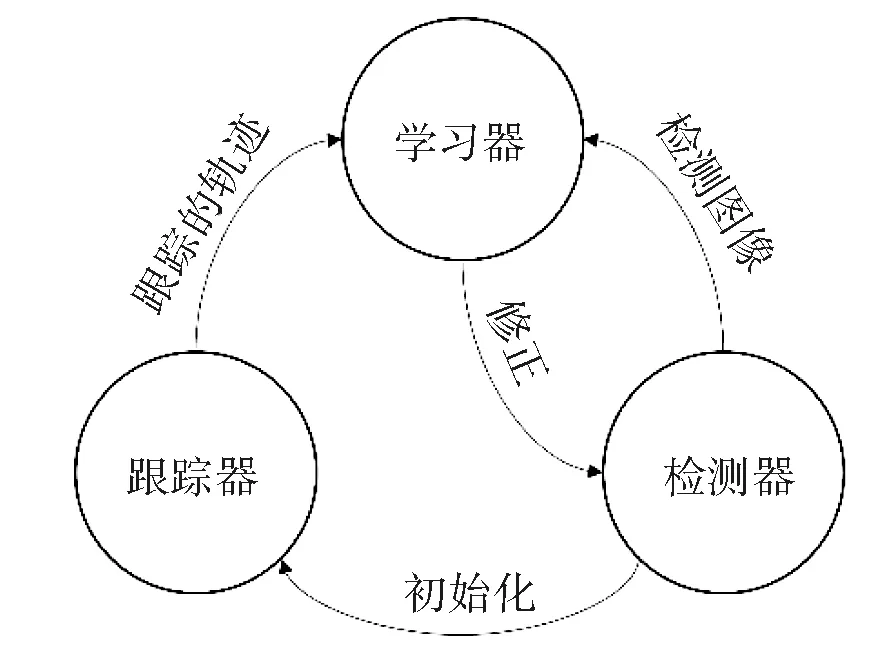
图1 DLT算法架构图
1.1.1基于级联分类器检测算法
视频流中每帧图像上有个扫描窗[10],扫描窗逐行扫描图像上的任何一个区域。扫描到的每个位置形成一个矩形框,矩形框里的图像区域里的目标成为一个图像元,每个图像元的标签用一个点表示。扫描窗在扫描时,把每一个图像元看成彼此独立的。若网格中有N个矩形框,即图像元的个数,则每一帧有2N个标签组合。因此,每个图像帧将产生矩形框的数量非常多,这些矩形框中有许多是没有用的,为了提高算法的处理速度,需要对这些矩形框进行筛选、分类,即采用级联分类器,其包含3个级别:1)图像元灰度方差分类器;2)集成分类器;3)最近邻分类器。级联分类器各个级别之间工作流程见图2所示。
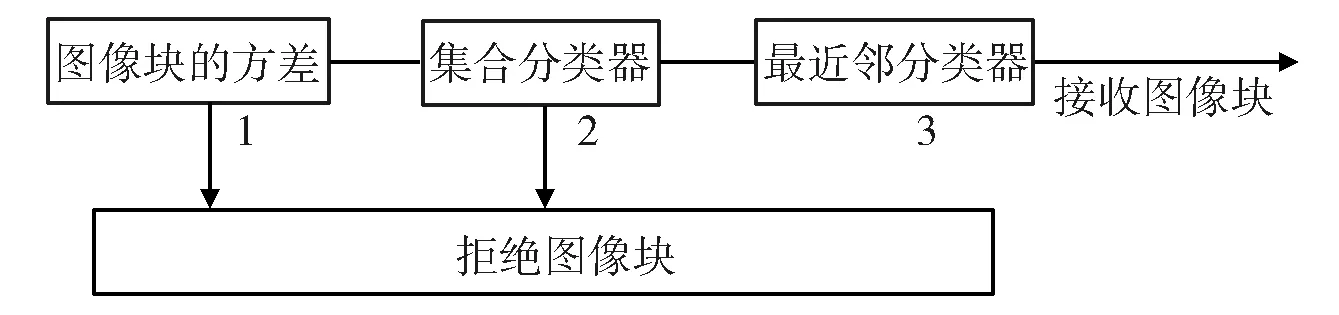
图2 级联分类器框图
计算图像块的方差是级联分类器的第一个级别,如果当前的图像元与目标图像元的像素值方差小于50%,则淘汰当前的图像元;集成分类器是级联分类器的第二个级别,它是基于改进的随机森林,即随机蕨;最近邻分类器是级联分类的最后一个级别,分类的参考标准是通过前面所算的相关相似度,与阈值θNN相比较,如果大于阈值θNN,那么图像元所在位置就是目标区域,阈值θNN是通过测试得到的实验值,它的范围在0.5~0.7之间[11]。
1.1.2基于光流法的追踪算法
DLT算法的跟踪模块主要基于中值的光流法。使用光流法对目标物体进行跟踪检测,如果目标物体不运动的,则光流法失效,特征点将会丢失。为了解决这个问题,跟踪目标特征点的选取是通过FB误差和归一化互相关系统来获取,提高了特征点的准确度。跟踪过程主要反映时域和空域上正反连续性,基于此提出了FB误差,即跟踪目标在t时刻位置上产生一个像素灰度的值,预测跟踪目标运动到t+1时刻,再从t+1时刻运动到t时刻的位置,获得预测t时刻位置像素点的灰度值,根据初始位置的像素灰度值与预测位置的像素灰度值求绝对差(即FB误差)。FB误差产生过程见图3所示。
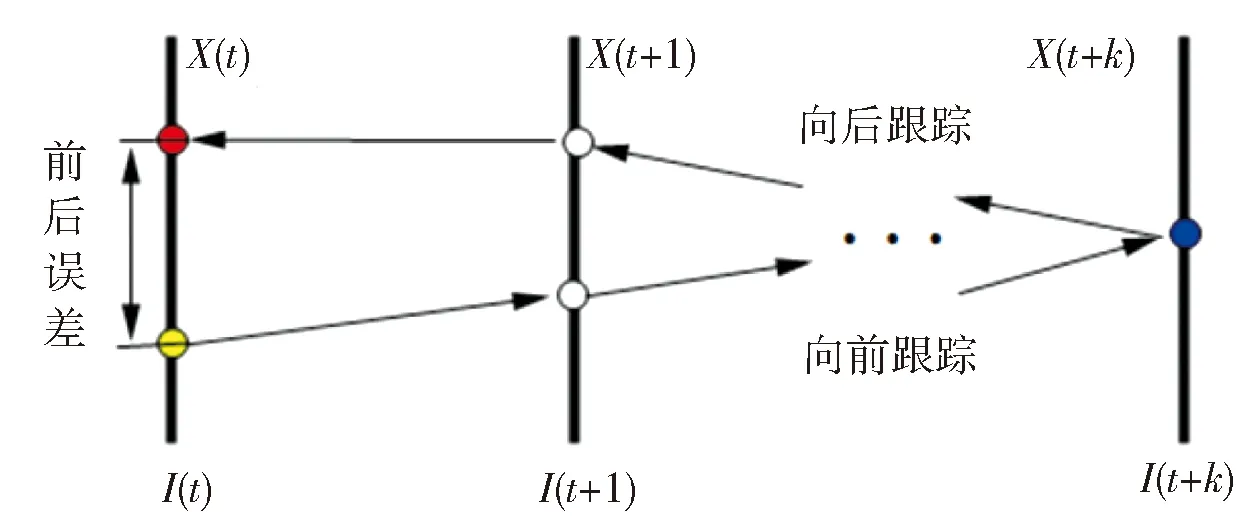
图3 FB误差图
归一化互相关[12]的匹配程度是指固定模板跟待匹配图像的相关值。假设图像帧F,模板图像元T,从F中随机选取一块跟模板T一样大小的子图像块fu,v,其中(u,v)为子图像块左下角的坐标。子图像块与模板的归一化互相关值为R(u,v)。R(u,v)的计算方法见式(1)。
(1)
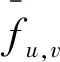
1.1.3基于DLT算法的位置识别
DLT算法是通过最小二乘法对线性变换系数l的解算与目标空间坐标(X,Y,Z)方程的解算,实现识别框的定位:
(2)
式中,li(i=1,2,…,k)为变换系数,其数量与控制点的精度有关,精度越高则数量越多,反之则越少。
1.2 DLT算法的改进
1.2.1阈值参数的变化分析
DLT原算法中共有17个参数,每个参数的变化都会影响算法的实时效果及算法的效率。在DLT原算法中的参数分别为
min_win=15,patch_size=15,num_tree=10,angle_init=20,noise_init=5,num_closest_update=10,valid=0.5,ncc_thesame=0.95,thr_nn=0.65,thr_nn_valid=0.7,shift_init=0.02,scale_init=0.02,overlap=0.2,et al
通过自适应阀值的选择提高跟踪性能,比如patch_size参数的选取决定归一化互相关系数的值。原算法中它的值被锁死(如原patch_size=15),当目标图像变大,并且里面的目标的特征点较多,将会影响到检测跟踪的效果。因此,在目标空间坐标的计算方程中引入放大或缩小系数α:
(3)
式中,α为放大或缩小系数。改进后patch_size根据目标框的大小,自动选取,从而避免了图像变大,而影响跟踪效果。
1.2.2目标矩形框选取分析
原DLT中没有用到聚类算法,本文设计一种对跟踪到的目标框的聚类算法,将空间重叠度大于一定阈值的跟踪目标框归为一类,把小于阈值的跟踪目标框归为不同的类,计算出各类跟踪目标边界框的位置、大小和置信度。这样当各个跟踪器预测出的目标框出现偏移的时候,通过跟踪目标边界框的聚类,跟踪器便能够对跟踪到的目标框进行适当的调整,可以降低聚类后的目标框对像素点的选择敏感程度,以便增加跟踪器对目标遮挡和对光照变化的鲁棒性,从而可以提高最后目标框的位置和大小的精度,进而提高TLD中跟踪器的性能。这里的聚类算法是输出聚类以后的各个聚类目标框。目标框聚类算法的流程见图4所示。
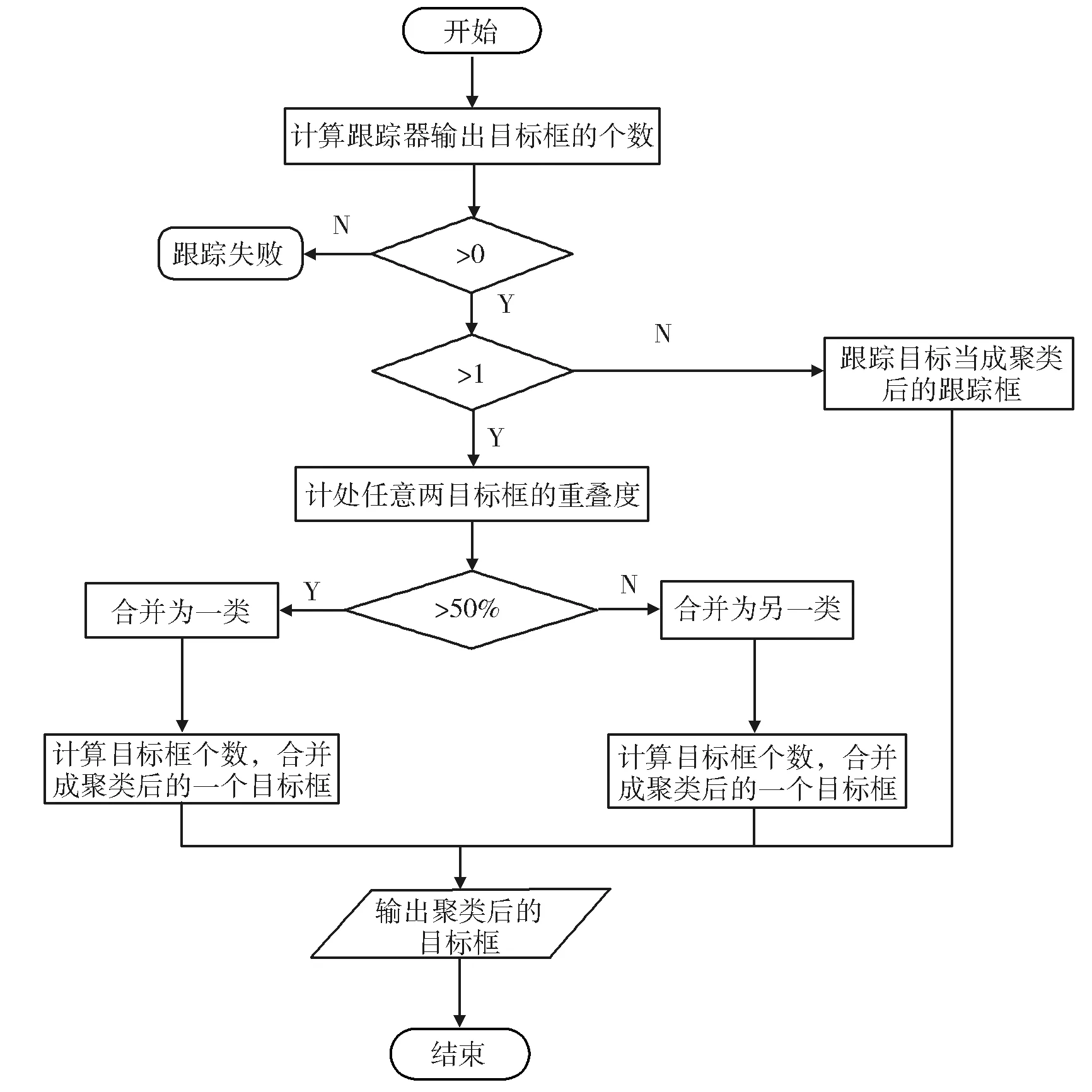
图4 目标框聚类算法的流程图
2 结果分析
2.1 测试平台配置环境
本文中用的是VS2010、OpenCV开发,利用Cmake,VS2010和TBB下编译OpenCV,调用OpenCV库函数。为了更好地测试原算法的性能,做如下界面,将从摄像头获取的视频显示在MFC中Picture Control控件中,测试过程中分为有学习与无学习过程,无学习过程是指不进行学习与检测单独跟踪。为了验证改进后算法检测跟踪的效果更加理想,对原算法和改进后算法进行跟踪的速度、距离、角度、环境、不同物体等方面进行测试。
2.2 DLT算法测试结果
2.2.1目标角度旋转变化及其跟踪效果分析
为了分析当物体位置发生变化时,跟踪效果是否受到影响,角度范围内依然能够跟踪到目标物体。对DLT算法进行角度旋转测试,以中心位置误差(即跟踪目标中心位置与手工标定的准确位置之间的平均欧式距离,该值越小则代表准确率越高)和成功率(测试目标框与真实目标框的重叠率,当重叠率大于50%时即为跟踪成功)为跟踪效果指标,测试结果见表1所示。通过对角度的测试,目标物体在固定一个角,保证其他条件不变的情况下,依次缓慢地旋转,当物体的旋转角度由0°逐渐转为70°时中心位置误差逐渐增大,即跟踪准确率逐渐下降;当角度等于70°时,则跟踪将会丢失。

表1 目标物体角度发生变化情况
2.2.2目标物体不同遮挡程度的跟踪分析
为分析目标物遮挡程度对跟踪效果的影响,以中心位置误差和成功率为跟踪效果指标,进行正负遮挡测试。正测试:人脸遮挡面积由0逐渐增加至2/3;负测试:人脸遮挡面积由2/3逐渐减小至0,测试结果见表2所示。

表2 不同遮挡程度的效果情况
在保持其他条件不变下,当目标被遮挡0~2/3时,目标能够跟踪到,中心位置偏差逐渐增大;当被遮挡超过2/3时,中心位置误差为94.2,目标将会发生丢失。当目标被遮挡2/3~0时,中心位置偏差逐渐减小;当遮挡小于1/3时,能够成功地跟踪上目标。
2.2.3不同光照下的跟踪情况
为了测试不同光照(白天和黑夜)条件下DLT算法检测跟踪的目标性能,分别对满足跟踪条件的目标物进行测试,结果见图5所示。

图5 人脸在白天与黑夜下相似度分布的直方图
从图5的数据可以看出,白天的跟踪效果比晚上好,白天相似度集中在0.6~1.0之间的图像元数比晚上要多。
2.3 改进前后算法目标矩形框中像素点的选取
2.3.1像素点选取
算法中像素点的选取也是非常关键的一步,原算法中每个框里总特征点数是固定的,如果目标靠近摄像设备,框里总特征点较少,对于特征描述不够详细,目标容易丢失,从而影响目标物体的检测跟踪效果。改进前后的测试结果见图6所示。

图6 像素点数随着目标框变化的跟踪情况
从图6可以看出,通过改进后,目标框内的像素点数随着矩形框大小的变化而变化,同时相应的特征点也随之变化,对于特征的描述更加准确。
2.3.2目标跟踪距离及其跟踪效果分析
为分析单目标在线跟踪过程中目标跟踪距离对跟踪效果的影响,以中心位置误差和检测时间(跟踪指令开始至识别框出现的时间)为跟踪效果指标,对目标离摄像头距离为0.6~3.6 m进行原DLT算法和改进DLT算法的跟踪测试,结果见表3所示。

表3 不同跟踪距离的效果情况
从表3可知,目标离摄像头在0.6~1.2 m之间时,原DLT算法跟踪效果很好,中心位置误差均小于5.0,并且检测速度快、延迟短,检测时间小于30 ms;距离在1.8~3.6 m,跟踪效果一般,检测速度有点卡、延迟较长,检测时间大于40 ms;尤其是当距离为3.6 m时,中心位置误差达89.1。而改进DLT算法在0.6~3.0 m之间的跟踪效果均很好,在3.6 m时跟踪效果一般,中心位置误差为64.0,但检测时间延迟,检测时间达70.3 ms。综上所述,改进DLT算法的检测跟踪的效果比原DLT算法更加理想。
2.3.3目标运动速度及其跟踪效果分析
为分析单目标在线跟踪过程中目标运动速度(通过手持速度检测仪测定运动速度)对跟踪效果的影响,以中心位置误差和成功率为跟踪效果指标,对目标离摄像头距离为3 m进行原DLT算法和改进DLT算法的跟踪测试(目标物为书本,在检测视野范围内直线运动),结果见表4所示。

表4 不同运动速度的效果情况
从表4可知,目标运动速度在5.1~39.4 km/h之间时,原DLT算法和改进DLT算法的跟踪效果均较好。在目标运动速度为59.7 km/h时,原DLT算法的跟踪识别效果一般,而改进DLT算法的跟踪效果均很好。综上所述,目标运动测试中改进DLT算法的检测跟踪的效果比原DLT算法更加理想。
3 结语
DLT算法采用固定图像元的像素点数方法进行目标跟踪,视频中目标物体因移动或光照变化等原因,导致目标物像素点变化明显影响跟踪效果。本文运用一种新的在线学习机制P-N学习改进DLT算法,用标记样本训练分类器,修改错误的正负样本,然后通过分类器对未被标注的数据进行标注,依次进行迭代训练。利用误差法和NCC法筛选出跟踪点,根据跟踪点的位置和距离的变化计算出目标框的大小和位置,实现目标跟踪。结果表明,改进后的DLT算法的目标跟踪的鲁棒性增强,能够根据目标框的实际情况获取有效的特征点,减少视频流中的目标过大或过小导致跟丢的情况。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
中国特种设备安全(2019年1期)2019-03-13
上海大学学报(自然科学版)(2018年5期)2018-11-02
电子测试(2018年1期)2018-04-18
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
