
共享制造下基于数据迁移的滚齿加工碳耗预测方法
2023-12-01 09:40:57易茜罗雨松胡春晖卓俊康李聪波易树平
中国机械工程 2023年15期
关键词:迁移学习
易茜 罗雨松 胡春晖 卓俊康 李聪波 易树平
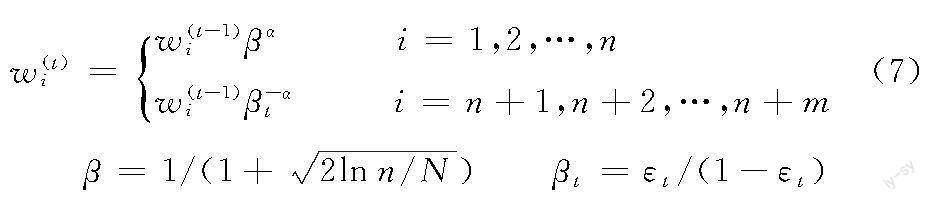

摘要:针对一般制造企业生产智能化程度不高、单个企业难以收集足够加工数据的问题,提出了一种共享制造下企业间数据迁移的滚齿加工碳耗预测方法。分析滚齿加工数据特征,在共享制造环境下提出用改进TrAdaBoost算法的数据迁移方法融合企业间的滚齿加工碳耗数据,形成跨企业联合数据集;利用蜻蜓算法优化支持向量回归,构造了跨企业滚齿加工碳耗预测模型。通过案例分析验证了所提方法的有效性,其预测性能在数据量少、数据关联性差的情况下具有优势,平均相对误差和决定系数分别比传统算法平均提高59.23%和16.56%。
关键词:共享制造;滚齿加工;迁移学习;碳耗预测
中图分类号:TH186
DOI:10.3969/j.issn.1004-132X.2023.15.007
Carbon Consumption Prediction Method of Gear Hobbing Based on Data Migration in Shared Manufacturing
YI Qian1,2 LUO Yusong2 HU Chunhui2 ZHUO Junkang2 LI Congbo1,2 YI Shuping2
1.State Key Laboratory of Mechanical Transmission,Chongqing University,Chongqing,400044
2.College of Mechanical and Vehicle Engineering,Chongqing University,Chongqing,400044
Abstract: Aiming at the problems that general manufacturing enterprises were not intelligent enough and it was difficult for a single enterprise to collect enough processing data, a prediction method of carbon consumption in gear hobbing processes was proposed based on data transfer between enterprises under shared manufacturing. The data characteristics of gear hobbing processes were analyzed, and the data migration method of improved TrAdaBoost algorithm was proposed to integrate the carbon consumption data of gear hobbing processes among enterprises under the data sharing manufacturing to form a cross-enterprise joint data set. The Dragonfly algorithm was used to optimize the support vector regression to construct a cross-enterprise carbon prediction model for gear hobbing processes. The effectiveness of the proposed method was verified by case analysis. Predictive performance has advantages when the data volume is small and the data correlation is low. Compared with the traditional algorithm, mean absolute percentage errors and coefficient of determination are improved by 59.23% and 16.56% respectively.
Key words: shared manufacturing; gear hobbing; transfer learning; carbon consumption prediction
0 引言
隨着第四次工业革命的到来,从工业文明迈向生态文明已成为全人类共识[1],为此,我国提出了“双碳目标”,强调低碳节能对生态文明建设的重要性[2]。2020年我国制造业碳排放量为3428 Mt,占总排放量的33.4%,是主要的碳排放源[3]。齿轮是我国制造规模最大的机械基础件之一,作为其核心制造工艺的滚齿加工过程的碳排放量十分突出。对滚齿加工过程的碳耗进行准确预测是优化齿轮生产过程碳耗的关键,对降低制造业的碳排放有重要意义。
目前,部分学者通过理论分析来构建加工过程的能耗模型。倪恒欣等[4]建立了滚齿加工能耗与加工质量预测模型,并利用改进多目标灰狼算法对模型进行求解。XIAO等[5]按照不同部件和加工阶段对滚齿加工能耗进行建模,并运用多目标帝国算法,以降低能耗和成本为目标求解最优滚齿加工参数。PRIARONE等[6]综合考虑车削各加工状态和加工条件,构建了综合直接能耗和间接能耗的车削能耗模型。ALBERTELLI等[7]分析了各机床部件功率与主要切削参数之间的关联关系,提出了一种数控铣削能耗分析模型。
面对多变的生产场景时,理论模型往往难以准确地反映加工过程的能耗特性。随着大数据技术的发展,部分学者基于实验数据或实际加工工艺参数建立数据驱动的能耗预测模型。李聪波等[8]通过分析数控车床各时段元运动与能耗的关系,采用高斯过程回归算法构建了车削能耗预测模型。吕景祥等[9]采用三种不同的机器学习方法分别构建车削和钻削能耗预测模型,并通过算法调参提高预测精度。CAO等[10]提出一种三阶段方法对滚齿加工过程碳耗、成本和加工时间进行多目标优化。BHINGE等[11]开展不同加工参数下的铣削实验,通过高斯过程回归算法构建了铣削加工能耗预测模型。NGUYEN等[12]利用铣削加工实验数据,基于Kriging模型构建了加工参数与比能耗和表面粗糙度之间的关联模型。
在实际工业场景中,滚齿碳耗数据往往复杂多变、彼此间关联性差且数据量少,导致数据驱动方法应用效果不佳。针对数据量少的场景,有学者提出用迁移学习(transfer learning)来扩大数据量。迁移学习受人类能够跨领域转移知识的启发,旨在将已学习到的相关领域的知识用于新领域之中,以解决数据缺乏等问题[13]。RIBEIRO等[14]提出基于迁移学习的预测算法,利用不同建筑的历史能耗数据预测目标建筑的能耗。WU等[15]运用长-短期记忆循环神经网络建立不同轴承故障数据间的对应关系,生成辅助数据集,有效解决了轴承故障数据缺乏问题。但滚齿加工碳耗数据迁移的相关研究未见报道。在当前企业智能化程度不高、缺乏收集加工过程工艺参数与工艺结果机制、单个企业难以收集到足量数据的情况下,通过迁移学习融合企业间的滚齿碳耗数据、扩大数据量来改善碳耗模型的效果是一条可以考慮的路径。
近年来,随着工业互联网技术的提出,工业生产理念已从单个企业独立制造上升到多企业协同的共享制造。共享制造[16]是共享经济在制造领域的体现,是以工业互联网技术为基础,将闲散的制造资源和能力的使用权共享的新型智能生产组织模式[17]。共享制造的特征是统筹协调、资源共享、分层指导、协同推进,是制造业新业态新模式发展的重点任务之一[18]。目前,共享制造大多仅停留在企业间生产设备、专用工具等制造硬资源的共享上。在大数据时代,数据本身也已成为一种极具价值的软资源,因此,当单个企业无法独立收集到充足滚齿加工碳耗数据时,可将多个企业的生产数据加以共享,再利用迁移学习融合企业间的数据,来克服数据不够丰富的不足,实现跨企业的滚齿加工碳耗预测。
笔者所在团队采用反向传播神经网络建模方法解决了小样本条件下数据驱动的碳耗模型构建问题[19]。针对单个企业难以收集丰富数据并建立有效的碳耗预测模型的问题,本文进一步提出基于共享制造的理念,利用迁移学习融合企业间滚齿加工数据来实现跨企业滚齿碳耗预测。首先分析滚齿碳耗数据在共享制造下的可用性,并提出共享制造下滚齿加工碳耗数据迁移融合框架;其次分析滚齿过程碳排放特性并建立滚齿加工碳耗模型;再次基于改进TrAdaBoost算法提出滚齿碳耗数据迁移融合方法,得到联合数据集,利用经蜻蜓算法优化的支持向量回归建立滚齿碳耗预测模型;最后通过实际案例证明所提方法的有效性。
1 滚齿加工特点及共享制造下的数据迁移
1.1 共享制造下滚齿碳耗数据可用性分析
滚齿加工过程具有以下两个特点:
(1)滚齿的工艺参数和加工过程相似。齿轮生产涉及的设计参数与加工参数众多,但参数类型相对固定,因此,不同齿轮的生产数据类型、特征维度高度重合,便于实现跨企业共享。
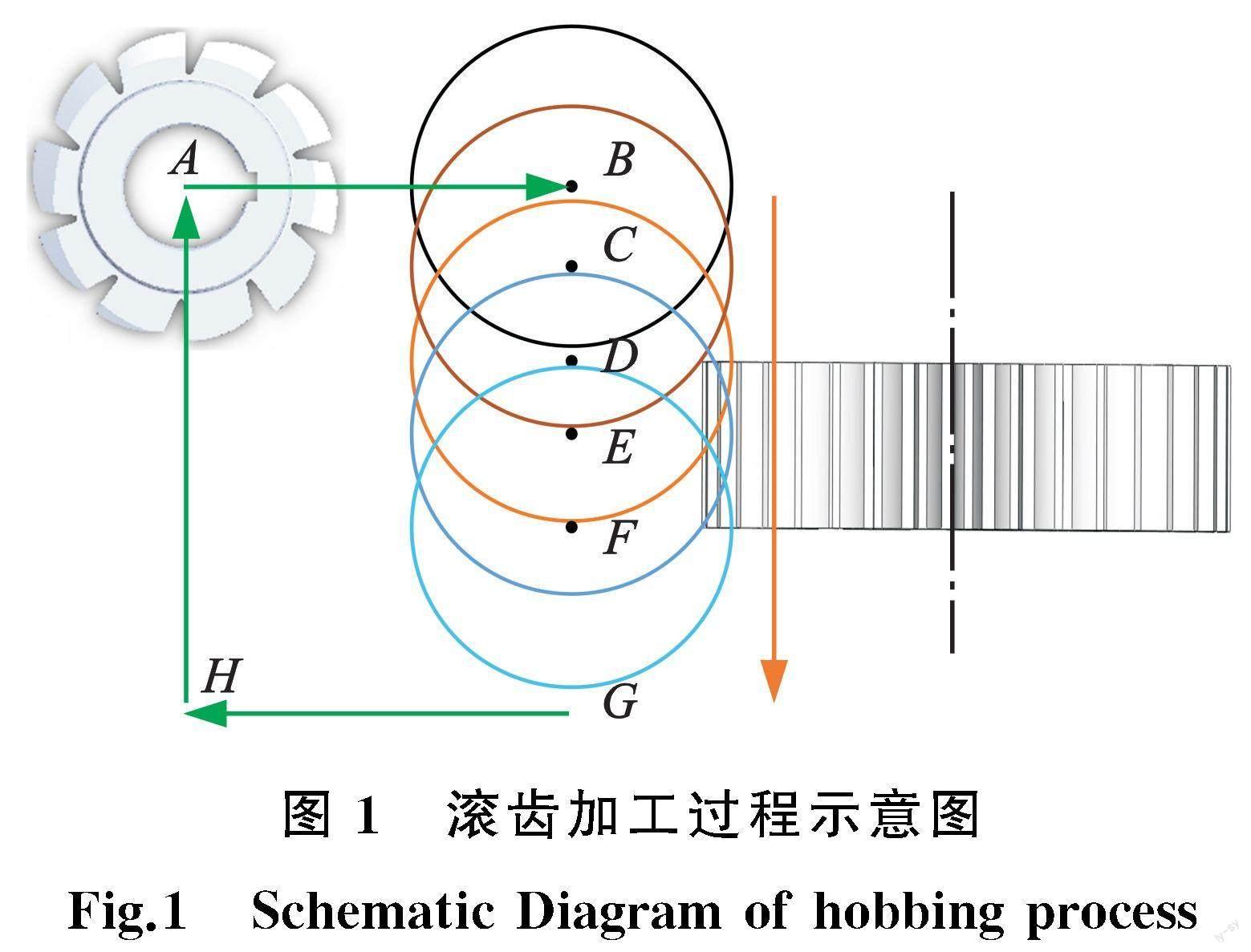
滚齿是齿轮加工的重要工艺,加工过程一般分为待机阶段、空切阶段、切削阶段、退刀阶段,其中切削阶段又包括切入、完全切削和切出三个过程,如图1所示。
待机阶段主要进行准备工作;空切阶段即机床主轴开始转动后,滚刀由机床原点移动至与齿坯相接触位置(位置A至位置C);在切削阶段,滚刀沿齿坯轴向向下进给,切除多余材料使工件成形,直至与工件分离(位置C至位置F);退刀阶段即滚刀与工件分离后,返回机床原点(位置G至位置A)。
在切削阶段,切入时,滚刀从与工件相接触位置(位置C)沿轴向移动,逐渐加大滚刀切深,当滚刀中轴线与工件上端面重合时(位置D)进入完全切削阶段。在完全切削阶段,滚刀保持最大切深继续沿轴向移动,当滚刀与工件下端面相切时(位置E)开始切出。切出时,随着滚刀继续沿轴向移动,滚刀切深逐渐减小,直到完全脱离(位置F)。
(2)滚齿加工过程功率曲线相似。虽然数控滚齿机床结构复杂,滚齿加工过程碳排放来源众多,但不同齿轮滚齿加工的功率曲线的结构相似,图2展示了滚齿加工过程中各阶段机床的功率变化情况。
图2中蓝色曲线为本文采集的滚齿加工过程实时功率变化曲线,黑色曲线为本文根据各滚齿加工阶段特点拟合的滚齿加工功率特征曲线。该实测功率变化曲线与拟合功率特征曲线也符合相关研究[5,20-22]对滚齿加工过程功率变化特征的描述。滚齿加工过程的上述特点支持在企业共享数据下企业间碳耗数据迁移融合的尝试。
1.2 共享制造下企业间滚齿碳耗数据迁移融合框架
在碳达峰、碳中和的环境保护和资源能源利用率亟待提高等压力下,制造企业越来越追求低投入的“轻量化”发展道路。基于共享制造的思想,通过共享制造资源,制造企业能够共同提高经济效益,并且快速实现绿色化、智能化发展[23]。
目前,共享制造主要体现在企业间生产设备和服务设备等资源的共享使用上。存在过剩设备资源的大型企业向中小企业提供以租代售、按需使用的服务,或是围绕物流仓储、产品检测等共性需求发展服务能力的共享。如阿里巴巴的“淘工厂”即是一个空闲产能共享平台[17]。制造企业的生产数据同样是一种极具价值的资源,如今正快速发展的工业互联网、智能制造、数据驱动、数字孪生乃至元宇宙等领域,其内核都是对数据的分析和应用。滚齿加工数据的共享能够帮助智能化程度不足的齿轮制造企业推进绿色化发展,实现滚齿加工碳耗预测。
图3所示为共享制造下企业间滚齿碳耗数据迁移融合框架。该框架分为4个部分:共享制造滚齿数据供应端、共享制造滚齿数据平台、共享制造滚齿数据需求端和滚齿碳耗预测端。
共享制造下企业间滚齿碳耗数据迁移融合框架的流程如下:在共享制造滚齿数据供应端,各企业将加工时采集到的工艺参数和工件参数等滚齿碳耗相关数据上传到共享制造滚齿数据平台;平台在对滚齿碳耗相关数据进行清洗和整合后,将数据进行储存;当目标企业由于自身数据不足,产生滚齿数据共享的需求时,可根据自身情况将已有滚齿数据与共享数据平台中的数据进行匹配,查找需要的共享数据并进行数据迁移融合;目标企业利用迁移得到的跨企业联合数据集建立适合目标企业实际情况的滚齿碳耗预测模型,最终实现滚齿碳耗预测。
2 面向共享迁移的滚齿碳耗建模
如图2所示,滚齿加工过程可分为待机、空切、切削(切入-完全切削-切出)和退刀等阶段。
(1)待机阶段。滚齿加工在待机阶段的主要碳排放为电能消耗碳排放,如图2所示,其值主要与滚齿机床自身性能与加工实际情况有关。待机阶段碳排放Cs计算公式如下:
式中,Felec为电能的碳排放因子,以中国南方区域电网基准排放因子[24]为参照,Felec取0.8042 kgCO2/(kW·h);ts为待机时间,可视为定值;Ps为待机功率,由机床本身性能决定。
(2)空切阶段、退刀阶段。这两阶段与切削阶段相比,功率低、持续时间短,其碳排放远低于切削阶段。并且,影响该阶段碳排放的主要参数是进刀退刀速率,通常由操作者设置为一定值,与齿轮设计及加工参数无关。故本文在进行基于数据迁移融合的滚齿碳耗计算时,忽略这两阶段碳耗。
(3)切削阶段。切削阶段分为切入、完全切削和切出三个子阶段,其碳排放来源包括电能消耗碳排放、切削液碳排放和刀具碳排放。电能消耗碳排放参照图2所示的滚齿加工功率曲线。滚齿切削阶段加工时间主要与齿轮自身设计参数和工艺参数有关。滚齿切削阶段加工实时功率随着切深的增大而不断增加;完全切削时,实施功率趋于平稳;在切出阶段,随滚刀切深减小,实时功率也逐渐降低。具体切削阶段功率Pcut计算公式如下:
Pcut=Pu+Pau+Pa+Pc(2)
其中,Pu为空载功率,与主轴转速和进给量成二次函数关系[25]。Pau为辅助系统功率,由机床本身性能决定。Pa为附加载荷功率,与切削功率Pc成二次函数关系,切削功率Pc的计算公式为[5]
式中,KF、XF、YF、ZF、UF、VF均为切削力系数,与齿轮材料、刀具材料、刀具角度、切削力方向均有关;m为滚刀法向模数;f为滚刀轴向进给率;λ为滚刀切入深度;arp为每次滚刀最大切入深度;d为滚刀外径。
切削液碳排放主要指废弃切削液处理产生的碳排放,主要与切削液的使用方式有关,难以量化为具体数据以供迁移融合,故将其忽略。
刀具碳排放主要指刀具制备过程中产生的碳排放,对于共享制造数据供应端的企业,在滚齿加工过程中其刀具磨损状态各不相同,其使用状况依赖于操作者经验判断,若强行进行迁移融合易导致负迁移问题,同理将其忽略。
故切削阶段的碳排放Ccut计算公式如下:
式中,Pin、Pfull、Pout分别为切入、完全切削和切出阶段的功率;tin、tfull、tout分别为切入、完全切削和切出阶段的时间。
综上,滚齿加工过程碳排放Ctotal计算公式如下:
综上,滚齿加工过程碳排放主要来源于待机阶段和切削阶段,并且受机床自身性能、齿轮设计参数和加工工艺参数的影响较大。目前,由于生产模式向柔性定制化转变,企业将面对大量多品种小批量订单,故单个企业的齿轮设计参数复杂多变、彼此间关联性较差。并且,企业技术人员在选取加工工艺参数时往往相对保守且取值固定,使得单个企业难以收集到丰富的滚齿加工数据。同时,部分企业智能化程度不足,缺少数据采集设备,使得单个企业无法收集到足够的数据来支持大数据方法的使用。因此,在建立跨企业滚齿碳耗预测模型时,需要对企业间的上述数据进行共享,并通过迁移融合。
3 滚齿加工数据迁移融合及碳耗预测方法
3.1 基于改进TrAdaBoost算法的滚齿数据迁移融合方法
迁移学习可以分为基于样本的迁移、基于特征表示的迁移、基于参数的迁移和基于关系型知识的迁移4种主要类型[26]。其中,TrAdaBoost算法[27]就是基于样本的迁移学习方法,其核心思想是将共享制造平台上的滚齿数据样本(源域)和具有数据共享需求的目标企业的滚齿数据样本(目标域)分别进行权重分配,使两个样本集的数据分布更加接近,将企业间滚齿碳耗数据融合形成联合训练集用于目标企业滚齿碳耗预测模型的训练。流程如图4所示。
TrAdaBoost算法在AdaBoost算法的基础上引入了迁移学习的思想,使其具备了使两个领域数据分布相适应的功能,但传统TrAdaBoost算法僅适用于离散的二分类问题,并不能迁移融合连续的滚齿碳耗数据,因此,本文对其进行了改进。改进TrAdaBoost算法的主要框架由滚齿数据权重分配器和碳耗模拟预测器两部分组成:
(1)滚齿数据权重分配器。滚齿数据权重分配器对来自共享制造平台和目标企业的滚齿数据样本分别进行权重初始化,并在迭代过程中对两领域的样本权重进行调整。权重分配器的输入是共享滚齿数据集Ts和目标滚齿数据集Td,迭代开始时,权重分配器生成初始化权重向量W(1)=(w(1)1,…,w(1)n,…,w(1)n+m),上标表示算法当前所处的迭代次数t,迭代开始时t=1,n和m分别是Ts和Td的样本容量。权重初始化过程如下:
当迭代次数t≥1时,权重分配器将根据碳耗模拟预测器提供的加权误差对权重向量的各分量进行迭代调整。权重迭代公式如下:
式中,N为预设的最大迭代次数;参数βt在迭代中控制εt≤1/2;εt为碳耗模拟预测器在目标滚齿数据集上的加权误差;α为本文设置的一个新参数,作为是否降低滚齿数据样本权重的判断依据。
新参数α的计算公式如下:
当碳耗预测值ht(xi)与实际碳耗值c(xi)的相对误差低于εα时,α取值为0,样本权重不变;反之α取值为1,样本权重降低。εα是本文引入的一个新的超参数,称为容忍系数,其值越小,算法对碳耗预测相对误差的容忍度越小,对企业间滚齿数据分布的差异越敏感。
权重迭代公式(7)与算法改进前的迭代公式形式一致,有着良好的收敛性[27]。其收敛速率主要由参数β决定,本文引入的容忍系数εα在一定程度上影响了收敛速率,但也使算法更加灵活,可以通过人为调整该系数控制算法对误差的敏感度来间接控制收敛速率。
综上,本文通过改进权重迭代方式并添加判别参数α的方式成功解决了传统TrAdaBoost算法无法迁移融合滚齿碳耗数据的问题。同时,引入容忍系数εα,使算法更加灵活多变,企业可根据实际需求调整滚齿碳耗数据迁移融合的门槛。
(2)碳耗模拟预测器。碳耗模拟预测器以一个基学习算法为基础,对联合训练集进行学习并建立滚齿碳耗预测模型,并在目标企业滚齿数据集上进行碳耗模拟预测。首先,输入联合训练集T=Td∪Ts并设置训练样本权重向量P(t),设置过程如下:
训练出滚齿碳耗预测模型ht。计算ht在Td上进行碳耗模拟预测的加权误差εt,用来指导滚齿数据权重分配器调整样本权重,εt计算公式如下:
式中,ht(xi)为碳耗预测值;c(xi)为碳耗实际值。
碳耗模拟预测器是改进TrAdaBoost算法的重要组成部分,基学习算法作为构建滚齿碳耗模拟预测模型的训练器,其效果对最终结果有较大影响。本文选择支持向量回归(support vector regression,SVR)算法[28]作为碳耗模拟预测器的基学习算法。
3.2 滚齿加工过程碳耗预测建模
3.2.1 滚齿碳耗数据分析处理
由第2节可知,滚齿碳耗主要受齿轮设计参数及加工工艺参数的影响,因此,滚齿碳耗预测模型是以上述参数为变量的非线性模型,上述参数组成的向量将是滚齿碳耗建模时的输入。
从目标企业收集到的滚齿碳耗數据在进行碳耗预测建模之前需先经过数据处理,其目的是挖掘数据中的有效信息,同时将数据结构转化为算法需要的形式。本文数据处理过程如下:
(1)滚齿碳耗特征数据归一化。由于滚齿碳耗数据的各齿轮参数、加工参数等特征的量级存在差异,为消除各特征指标间不同量纲对算法运算的影响,需要对其进行归一化处理,将各特征变量值缩放在[0,1]范围内,公式如下:
式中,y为归一化后的值;x为滚齿碳耗数据某项特征变量的原始值;xmax、xmin分别为该特征变量的最大值和最小值。
(2)滚齿碳耗数据降维。滚齿碳耗数据涉及的特征变量众多,如齿轮的模数、齿数,加工的进给率、主轴转速等。降低原始数据的特征维度可以获取影响滚齿碳耗值的主要特征,便于后续处理,同时可减少算法的运算量。
本文利用主成分分析(principal component analysis,PCA)法对滚齿碳耗数据进行降维处理,通过正交变换将n维数据映射到m(m 计算前k(k (3)跨企业滚齿数据匹配。本文采用基于样本的迁移学习算法,为确保样本有效迁移融合,要求目标企业滚齿数据集与用于迁移的共享滚齿数据集具有共同的特征空间,因此需要对目标企业滚齿数据进行匹配分析,得到满足迁移条件的共享滚齿数据集。 假设经数据降维后的目标企业滚齿数据特征集合Xd={x1,x2,…,xm},共享制造平台上某企业滚齿数据的特征集合Xs={x1,x2,…,xq},则符合迁移条件的共享滚齿数据应满足XdXs。经匹配分析后,符合条件的共享滚齿数据需去除多余特征维度,使特征空间重合,即Xd=Xs={x1,x2,…,xm},最终得到待迁移的共享滚齿数据集(源域)。 (4)滚齿碳耗数据迁移融合。用改进TrAdaBoost算法将待迁移的共享滚齿数据集迁移融合进目标企业滚齿数据集,形成联合训练集D={(xi,yi)}ni=1,其中,xi=(xi1,xi2,…,xim)为第i个样本对应的m维滚齿碳耗特征输入向量,它包含经数据降维后的滚齿碳耗数据特征属性值;yi为该样本对应的滚齿加工碳耗值。 经过以上处理得到的联合训练集即是滚齿碳耗预测建模的输入,输出则为滚齿碳耗预测值。 3.2.2 滚齿碳耗预测建模过程描述 尽管实现了企业间滚齿碳耗数据迁移融合,但目前滚齿数据总量仍然较小,因此,本文选择利用SVR算法建立滚齿碳耗预测模型。在样本数据量较小的情况下,SVR算法相较于其他回归算法有着一定的优势[31]。同时SVR算法泛化能力强,能够在保证预测精度的同时,快速实现滚齿碳耗预测。 将迁移融合得到的联合训练集作为SVR算法的输入,算法将训练求解一个超平面: ωTx+b=0(13) 式中,x为滚齿碳耗特征输入向量组成的n×m维输入矩阵;ω、b分别为权重向量和偏置量。 于是SVR算法最终输出的跨企业滚齿碳耗预测模型f(x)的形式为 f(x)=ωTφ(x)+b(14) 式中,φ(x)为非线性函数。 SVR算法的超参数对算法效果影响明显,因此超参数设置是碳耗预测建模的必要步骤。SVR算法需要设置的超参数主要包括核函数类型、惩罚因子C和松弛变量ε。本文在目标企业滚齿碳耗数据集上进行碳耗预测试验以选取合适的超参数,具体如下: (1)核函数类型。SVR算法常用的核函数主要有线性核函数、多项式核函数、Sigmoid核函数和径向基核函数四种。 利用控制变量法,使用默认的惩罚因子C和松弛变量ε值,分别采用四种不同的核函数类型建立滚齿碳耗预测模型,比较多次预测的平均相对准确率后得到最优的核函数类型。 (2)惩罚因子C和松弛变量ε。这两个超参数均为连续型变量,本文利用蜻蜓优化算法(dragonfly algorithm,DA)辅助设置,与遗传算法相比,蜻蜓算法表现出更好的收敛性及泛化能力[32]。 为获取更具泛化能力的惩罚因子C和松弛变量ε,本文以SVR算法在目标企业滚齿碳耗数据集上的碳耗预测模型的决定系数R2为优化目标,以惩罚因子C和松弛变量ε为优化变量,在一定范围内搜索两者的最优值。完整的滚齿碳耗建模过程如图5所示。 4 案例分析 4.1 数据采集及分析处理结果 本文以重庆某集团下变速箱制造车间作为本文方法框架中的目标企业。对该车间进行调研和数据采集,该车间包含两台数控滚齿机床,型号分别为YS3132CNC6和YS3140CNC6,采集了该车间2021年内的部分滚齿加工数据,通过HIOKI PW3390功率分析仪获得其功率数据,并记录滚齿机床上对应的加工工艺参数,采集过程如图6所示。经整理,共收集到43种不同齿轮的滚齿加工工艺参数以及对应的滚齿加工碳耗数据。分析后发现该车间的滚齿加工数据呈现出品种多批量小的特点,收集到的齿轮参数多变,模数分布在1.2~8,齿数分布在13~126,齿宽分布在20~61.2 mm,数据间关联性较差。 本文收集到模数m、齿数z、齿宽b、压力角α、螺旋角β、齿顶高系数h*a、顶隙系数c*、变位系数x等齿轮设计参数,以及机床型号,粗、精滚主轴转速,粗、精滚进给率等滚齿加工参数。为了获得影响滚齿碳耗的主要特征变量,本文采用PCA法针对收集到的样本特征变量进行数据降维,结果如图7所示。 由图7可知,在收集到的样本特征属性中,粗、精滚机床主轴转速S1、S2,粗、精滚滚刀进给率F1、F2和齿轮齿宽b五个特征对该数据集的贡献度较高,这5个特征属性的累计贡献度为90.3%,可反映原高维特征集的信息。因此本文选取这5个参数作为滚齿加工样本的特征变量来进行滚齿碳耗数据迁移并构建碳耗预测模型,见表1,符合滚齿加工碳耗的数学模型,也便于制造企业后续通过优化滚齿加工工艺参数来节能减排。经特征分析筛选后,得到28组数据构成的目标企业滚齿数据集,见表2。 为获得特征领域重合的跨企业滚齿碳耗数据,本文将得到的目标企业滚齿数据集在同研究团队滚齿碳耗数据库中进行匹配,最终同研究团队在重庆某机床加工企业的滚齿加工碳耗实验数据[19]符合迁移学习条件,故将该企业作为本文的源域企业。该实验采用YS3120CNC6数控滚齿机床加工齿轮,对每个齿轮采用不同的工艺参数进行了粗、精两次滚齿加工。对同种齿轮进行了41次加工,并记录了所使用的工艺参数和对应的碳耗值。 4.2 滚齿数据迁移融合及碳耗预测结果与分析 本文采用改进TrAdaBoost算法对来自源域企业的滚齿加工实验数据进行迁移融合,与目标企业的实际滚齿加工碳耗数据组成跨企业联合训练集,用于建立跨企业滚齿碳耗预测模型。 本文随机抽取目标企业滚齿数据集中的75%作为训练样本集Td,25%作为测试样本集S。将源域企业滚齿数据集Ts和训练样本集Td输入算法,以形成跨企业滚齿碳耗联合训练集T。然后设置改进TrAdaBoost算法的参数:迭代次数N=15,容忍系数εα=0.4。最后设置SVR算法超参数,包括核函数类型、惩罚因子C和松弛变量ε。 不同核函数下10次碳耗预测平均相对准确率比较结果见表3。可以看出径向基核函数的预测效果比较好,并且在样本分布规律未知时使用该核函数有较好预测效果,故本文选用径向基核函数。惩罚因子C和松弛变量ε由蜻蜓优化算法自动选取,本文设置蜻蜓算法在种群数为40、迭代次数为50条件下搜寻最优超参数。 改进TrAdaBoost算法通过调整联合训练集样本权重迁移融合两企业滚齿数据,通过在目标企业训练集Td上进行滚齿碳耗预测实验可验证数据迁移融合效果。权重调整前后联合样本集T在目标企业训练集Td上的碳耗预测结果与碳耗测算值如图8所示。图8a、图8b分别表示权重调整前后的碳耗预测结果,图中两数据点间的线段长度表示碳耗预测值和测算值间误差。由图8可知,经算法调整后,模型在目标域上的预测误差明显减小。模型的决定系数R2也由0.83提升到0.94,模型的拟合效果提高。 为验证基于样本迁移的滚齿碳耗预测模型的预测效果,本文在测试集S上测试模型,并将预测结果与反向传播神经网络(back propagation neural network,BPNN)、极限学习机(extreme learning machine,ELM)、SVR等传统机器学习方法的预测结果进行比较。 本文使用均方根误差(root mean square error,RMSE)、平均相对误差(mean absolute percentage error,MAPE)、平均绝对误差(mean absolute error,MAE)和决定系数(R2)来评估模型的性能,各评价指标计算公式如下: 式中,n为数据集样本数量;Ct为第t项碳耗测算值;Ctpre为第t项碳耗预测值。 各预测模型的效果见表4。其中RMSE为均方误差的算术平方根,MAPE表示相对误差的平均值,MAE反映絕对误差之间的平均值。以上三个指标越低,则表示模型具有更好的预测性能。R2∈[0,1]用以评价动态预测模型的拟合程度,其值越接近1说明预测模型的拟合效果越好。 根据表4中结果,使用本文方法进行滚齿碳耗预测得到的各项指标均优于所比较的传统预测模型,其中MAPE值和R2值分别相较于传统模型平均提高59.23%和16.56%,证明其预测效果和预测稳定性都强于传统预测模型。 4.3 模型预测能力影响因素分析 改进TrAdaBoost算法的一个优势是影响最终滚齿碳耗预测模型预测能力的因素较少,该部分将针对以下关键因素进行分析。 (1)源域企业数据、目标企业数据样本比例。TrAdaBoost作为基于样本的迁移学习算法,源域企业数据与目标企业数据间样本数量的比例对该算法的效果影响较大。将目标企业数据样本按数量分为28组、20组、12组三个等级,为避免发生负迁移现象,在进行数据抽样时,以齿宽b作为枢纽属性,剔除与源域齿宽差距大的样本数据,其余保留。经数据抽样后,三个等级的数据量及特点见表5,三个等级下各方法滚齿碳耗预测结果如图9所示。 图9a~图9d展示了不同预测方法在不同数据量等级下的滚齿碳耗预测效果。由图9可知,随着样本数量的降低,各传统机器学习模型碳耗预测的平均相对误差MAPE值和决定系数R2值呈现出先下降后升高的趋势,其中SVR模型最为明显,MAPE值由11.56%下降至12.87%后升高至8.97%。除SVR模型外,各传统模型在等级3条件下的MAPE值虽然较等级2有所提高,但仍未超过原本28组样本的MAPE值。 经分析,MAPE值下降是因样本数量减少而造成传统机器学习算法无法建立起效果良好的滚齿碳耗预测模型。后续虽然样本数量进一步降低,但数据分布集中,样本关联性提高,故MAPE值有所回升,但R2值仍较低(最高为SVR模型的0.863),预测稳定性较低,易出现过拟合现象。SVR模型在等级3下各指标相对较好,一定程度上体现了该算法在小样本数据下的优势。 本文方法在三个等级下的各项指标均明显优于传统预测模型,算法预测能力呈现出随样本数据量减少先提升再降低的特点,如MAPE值由4.27%提高至2.81%后降低到5.71%,误差保持在较低水平,预测碳耗平均绝对误差MAE在0.1262以内。同时模型的R2值维持在较高水平,超过0.927,最高可达0.980,说明本文方法在不同情形下的预测稳定性高,模型泛化能力优秀。 本文方法由于迁移融合了跨企业共享滚齿数据进行辅助,在样本数据较小条件下,体现出明显的优势。影响算法预测能力的关键因素由样本数量变为企业间滚齿数据分布相似程度,对于本文方法,等级1到等级2数据量仅减小了12%(由69降至61),远低于传统模型的29%,而样本关联性的提高使得企业间滚齿数据分布更接近,故预测能力明显提升。而在等级3下目标企业数据量过少,模型学习到的目标企业样本分布知识减少,故预测能力相对下降,但优势仍然明显。 综上所述,基于数据迁移融合的碳耗预测模型在滚齿加工数据量较小且数据关联性较差时预测能力优于传统预测模型,且当源域企业数据与目标企业数据样本比例接近2∶1时优势最为明显:各项误差小,RMSE、MAE和MAPE的值分别为0.0867、0.0691和2.81%;拟合效果好,R2值高达0.980。 (2)容忍系數εα。为使TrAdaBoost算法适用于滚齿碳耗数据,本文对该算法进行了改进,其中定义了一个新的超参数容忍系数εα∈[0,1],见式(8)。其值代表算法对当前滚齿碳耗预测相对误差的容忍度,进而可反映算法对源域企业滚齿数据与目标企业滚齿数据间样本分布差异的敏感度。同样在上述三个样本等级下对εα的值进行分析讨论,以MAPE值作为评价指标,碳耗预测结果如图10所示。由图可知,在等级1和2下MAPE值均在εα=0.4时达到最小值,等级3下在εα=0.5时MAPE值达到最优值 5.60。 为进一步分析算法的收敛性,在相同最大迭代次数N和源域样本数n条件下,比较改进后算法与原算法的收敛性。算法收敛率随迭代次数t的变化曲线如图11所示,本文将单次迭代前后权重值变化低于万分之一的样本点视作收敛,并以收敛样本点与样本总数的百分比作为衡量算法收敛情况的标准。 由图11可知,由于权重迭代公式一致,算法改进前后都具有良好的收敛性。原算法经过11次迭代后收敛率便达到100%,而算法改进后,在εα=0.4条件下,收敛率达到100%需经过13次迭代;在εα=0.8条件下,收敛率达到100%需经过16次迭代。可见算法改进后,收敛性与原算法相同,收敛速率略有下降。其主要原因是改进前后算法处理的是回归预测问题,相较于原算法处理的二分类问题更为复杂;此外,由于引入容忍系数,一定程度上影响了算法的收敛速率,容忍系数的取值也间接影响了算法的收敛速率。 由实验可知,若εα取值过小,联合训练集样本权重下降快,算法快速收敛,容易忽略源域企业数据集中有利于建立目标企业滚齿碳耗预测模型的样本;若εα取值过大,算法权重缩放效果微弱,收敛缓慢,算法最终效果受限。综上,εα取0.3~0.5为宜,源域企业数据样本量充足时εα取较大值,反之取较小值。本文为充分搜索,选取εα=0.4以尽可能地获得合适的辅助数据。 5 结论 (1)本文提出了一种共享制造下滚齿数据迁移融合及碳耗预测方法。分析了滚齿加工数据特征,用改进TrAdaBoost算法迁移融合企业间的滚齿加工碳耗数据。利用SVR算法构建了跨企业滚齿加工碳耗预测模型,实现了滚齿加工碳耗预测。 (2)通过仿真对比验证了相较于SVR、BPNN、ELM等算法,基于本文方法建立的滚齿碳耗预测模型的预测性能在数据量小、数据关联性差的情况下具有明显优势,MAPE值和R2值分别比传统算法平均提高59.23%和16.56%。在共享迁移滚齿数据与目标企业滚齿数据的样本比例为2∶1时,本文方法优势最为显著。各项误差小,RMSE值、MAE值和MAPE值分别为0.0867、0.0691和2.81%;拟合效果好,R2值高达0.980。证明所提方法在多品种小批量制造模型下对滚齿碳耗预测具有一定的优越性。 (3)在共享制造下本文方法能够有效迁移融合企业间滚齿加工数据,建立具有良好预测效果的跨企业碳耗预测模型,可以解决实际工业场景中滚齿碳耗的小样本预测问题。后续将持续采集齿轮生产数据,扩大已有企业数据量,同时收集更多齿轮制造企业生产数据,实现多源域数据迁移,进一步提高模型的泛化能力。 参考文献: [1] 曹华军, 李洪丞, 曾丹, 等. 绿色制造研究现状及未来发展策略[J]. 中国机械工程, 2020, 31(2):135-144. CAO Huajun, LI Hongcheng, ZENG Dan, et al. The State-of-art and Future Development Strategies of Green Manufacturing[J]. China Mechanical Engineering, 2020, 31(2):135-144. [2] 中共中央国务院关于完整准确全面贯彻新发展理念做好碳达峰碳中和工作的意见[N]. 人民日报, 2021-10-25(001). Opinions of the CPC Central Committee and The State Council on Fully, Accurately and Comprehensively Implementing the New Development Concept to Achieve Carbon Peak and Carbon Neutrality[N]. Peoples Daily, 2021-10-25(001). [3] 国家统计局. 中华人民共和国2020年国民经济和社会发展统计公报[J]. 中国统计, 2021(3):8-22. National Bureau of Statistics. Statistical Bulletin of the Peoples Republic of China on National Economic and Social Development in 2020[J]. China Statistics, 2021(3):8-22. [4] 倪恒欣, 阎春平, 陈建霖, 等. 高速干切滚齿工艺参数的多目标优化与决策方法[J]. 中国机械工程, 2021, 32(7):832-838. NI Hengxin, YAN Chunping, CHEN Jianlin, et al. Multi-objective Optimization and Decision-making Method of High Speed Dry Gear Hobbing Processing Parameters[J]. China Mechanical Engineering, 2021, 32(7):832-838. [5] XIAO Qinge, LI Congbo, TANG Ying, et al. Multi-component Energy Modeling and Optimization for Sustainable Dry Gear Hobbing[J]. Energy, 2019, 187(2):115911. [6] PRIARONE P C, ROBIGLIO M, SETTINERI L, et al. Modelling of Specific Energy Requirements in Machining as a Function of Tool and Lubricoolant Usage[J]. CIRP Annals—Manufacturing Technology, 2016, 65(1):25-28. [7] ALBERTELLI P, KESHARI A, MATTA A. Energy Oriented Multi Cutting Parameter Optimization in Face Milling[J]. Journal of Cleaner Production, 2016, 137:1602-1618. [8] 李聰波, 尹誉先, 肖溱鸽, 等. 数据驱动下基于元动作的数控车削能耗预测方法[J]. 中国机械工程, 2020, 31(21):2601-2611. LI Congbo, YIN Yuxian, XIAO Qinge, et al. Data-driven Energy Consumption Prediction Method of CNC Turning Based on Meta-action[J]. China Mechanical Engineering, 2020, 31(21):2601-2611. [9] 吕景祥, 唐任仲, 郑军. 数据驱动的车削和钻削加工能耗预测[J]. 计算机集成制造系统, 2020, 26(8):2073-2082. LYU Jingxiang, TANG Renzhong, ZHEN Jun. Data-driven Methodology for Energy Consumption Prediction of Turning and Drilling Processes[J]. Computer Integrated Manufacturing Systems, 2020, 26(8):2073-2082. [10] CAO Weidong, NI Jianjun, JIANG Boyan, et al. A Three-stage Parameter Prediction Approach for Low Carbon Gear Hobbing[J]. Journal of Cleaner Production, 2021, 289:125777. [11] BHINGE R, PARK J, LAW K H, et al. Toward a Generalized Energy Prediction Model for Machine Tools[J]. Journal of Manufacturing Science and Engineering, 2017, 139(4):041013. [12] NGUYEN T T. Prediction and Optimization of Machining Energy, Surface Roughness, and Production Rate in SKD61 Milling[J]. Measurement, 2019, 136:525-544. [13] ZHUANG Fuzhen, QI Zhiyuan, DUAN Keyu, et al. A Comprehensive Survey on Transfer Learning[J]. Proceedings of the IEEE, 2021, 109(1):43-76. [14] RIBEIRO M, GROLINGER K, ELYAMANY HF, et al. Transfer Learning with Seasonal and Trend Adjustment for Cross-building Energy Forecasting[J]. Energy and Buildings, 2018, 165:352-363. [15] WU Zhenghong, JIANG Hongkai, ZHAO Ke, et al. An Adaptive Deep Transfer Learning Method for Bearing Fault Diagnosis[J]. Measurement, 2020, 151:107227. [16] BRANDT E. Deborah Wince-Smith:a Vision for Shared Manufacturing[J]. Mechanical Engineering, 1990, 112(12):52-55. [17] 晏鵬宇, 杨柳, 车阿大. 共享制造平台供需匹配与调度研究综述[J]. 系统工程理论与实践, 2022, 42(3):811-832. YAN Pengyu, YANG Liu, CHE Ada. Review of Supply-demand Matching and Scheduling in Shared Manufacturing[J]. Systems Engineering—Theory & Practice, 2022, 42(3):811-832. [18] 臧冀原, 刘宇飞, 王柏村, 等. 面向2035的智能制造技术预见和路线图研究[J]. 机械工程学报, 2022, 58(4):285-308. ZANG Jiyuan, LIU Yufei, WANG Baicun, et al. Technology Forecasting and Roadmapping of Intelligent Manufacturing by 2035[J]. Journal of Mechanical Engineering, 2022, 58(4):285-308. [19] 易茜, 柳淳, 李聪波, 等. 基于小样本数据驱动的滚齿工艺参数低碳优化决策方法[J]. 中国机械工程, 2022, 33(13):1604-1612. YI Qian, LIU Chun, LI Congbo, et al. A Low Carbon Optimization Decision Method for Gear Hobbing Process Parameters Driven by Small Sample Data[J]. China Mechanical Engineering, 2022, 33(13):1604-1612. [20] 李均亮, 王时龙, 王四宝, 等. 基于工件材料去除率的滚齿机床能耗模型[J]. 中国机械工程, 2020, 31(21):2626-2631. LI Junliang, WANG Shilong, WANG Sibao, et al. Energy Consumption Model of Hobbing Machine Tools Based on Workpiece Material Removal Rate[J]. China Mechanical Engineering, 2020, 31(21):2626-2631. [21] 倪恒欣, 阎春平, 孙菡, 等. 高速干切滚齿机床能耗分布特性及其预测模型[J]. 中国机械工程, 2022, 33(7):842-851. NI Hengxin, YAN Chunping, SUN Han, et al. Energy Consumption Distribution Characteristics and Prediction Model of High-speed Dry Gear Hobbing Machine[J]. China Mechanical Engineering, 2022, 33(7):842-851. [22] 李聪波, 付松, 陈行政, 等. 面向高效节能的数控滚齿加工参数多目标优化模型[J]. 计算机集成制造系统, 2020, 26(3):676-687. LI Congbo, FU Song, CHEN Xingzheng, et al. Multi-objective CNC Gear Hobbing Parameters Optimization Model for High Efficiency and Energy Saving[J]. Computer Integrated Manufacturing Systems, 2020, 26(3):676-687. [23] 中国机械工程学会. 中国机械工程技术路线图(2021)[M]. 北京:机械工业出版社, 2022:367-371. Chinese Mechanical Engineering Society. Technology Roadmaps of Chinese Mechanical Engineering(2021)[M]. Beijing:Mechanical Industry Press, 2022:367-371. [24] 生态环境部应对气候变化司. 2019年度减排项目中国区域电网基线排放因子[EB/OL]. [2022-11-22]. http:∥www. mee. gov. cn/ywgz/ydqhbh/wsqtkz/202012/t20201229_815386. shtml. Department of Climate Change, Ministry of Ecology and Environment. Emission Factors of Chinas Regional Power Grid Base Line in 2019[EB/OL]. [2022-11-22]. http:∥www. mee. gov. cn/ywgz/ydqhbh/wsqtkz/202012/t20201229_815386. shtml. [25] SCHUDELEIT T, ZST S, WEISS L, et al. The Total Energy Efficiency Index for Machine Tools[J]. Energy, 2016, 102:682-693. [26] 张雪松, 庄严, 闫飞, 等. 基于迁移学习的类别级物体识别与检测研究与进展[J]. 自动化学报, 2019, 45(7):1224-1243. ZHANG Xuesong, ZHUANG Yan, YAN Fei, et al. Status and Development of Transfer Learning Based Category-level Object Recognition and Detection[J]. Acta Automatica Sinica, 2019, 45(7):1224-1243. [27] DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Boosting for Transfer Learning[C]∥International Conference on Machine Learning. New York, 2007:1224-1243. [28] VAPNIK V N. An Overview of Statistical Learning Theory[J]. IEEE Transactions on Neural Networks, 1999, 10(5):988-999. [29] 趙京, 李立明, 尚红, 等. 基于主成分分析法的机械臂运动灵活性性能综合评价[J]. 机械工程学报, 2014, 50(13):9-15. ZHAO Jing, LI Liming, SHANG Hong, et al. Comprehensive Evaluation of Robotic Kinematic Dexterity Performance Based on Principal Component Analysis[J]. Journal of Mechanical Engineering, 2014, 50(13):9-15. [30] 李聪波, 孙鑫, 侯晓博, 等. 数字孪生驱动的数控铣削刀具磨损在线监测方法[J]. 中国机械工程, 2022, 33(1):78-87. LI Congbo, SUN Xin, HOU Xiaobo, et al. Online Monitoring Method for NC Milling Tool Wear by Digital Twin-driven[J]. China Mechanical Engineering, 2022, 33(1):78-87. [31] 陈果, 周伽. 小样本数据的支持向量机回归模型参数及预测区间研究[J]. 计量学报, 2008, 29(1):92-96. CHEN Guo, ZHOU Jia. Research on Parameters and Forecasting Intreval of Support Vector Regression Model to Small Sample[J]. Acta Metrologica Sinica, 2008, 29(1):92-96. [32] MIRJALILI S. Dragonfly Algorithm:a New Meta-heuristic Optimization Technique for Solving Single-objective, Discrete, and Multi-objective Problems[J]. Neural Computing & Applications, 2016, 27:1053-1073.
猜你喜欢
文学教育(2018年7期)2018-07-17 18:50:52智能计算机与应用(2018年2期)2018-05-23 11:46:20现代商贸工业(2018年11期)2018-04-24 11:59:38科技视界(2017年32期)2018-01-24 17:54:40课程教育研究(2017年46期)2017-12-27 13:56:25电脑知识与技术(2017年32期)2017-12-15 23:10:32现代交际(2017年18期)2017-09-11 20:34:02知识管理论坛(2016年6期)2017-05-27 19:44:03振动工程学报(2017年1期)2017-04-21 10:24:46物联网技术(2015年9期)2015-09-22 09:23:43
