
基于深度神经网络的人体动作识别研究
2018-05-23 11:46战青卓王大东
智能计算机与应用 2018年2期
关键词:迁移学习
战青卓 王大东

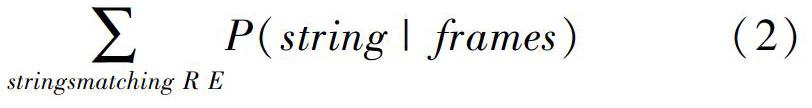

摘 要: 本文介绍了一种三维建模人体模型的方法,通过分层次地识别人体各部位的行为,从底层行为组合成为高层的动作和活动,应用隐马尔科夫模型完成人体行为的学习工作。同时,应用该模型,同样可以完成人体行为及活动的检索功能,通过输入一些自然语言,完成相关视频信息的获取。
关键词: 人体模型;迁移学习;隐马尔科夫模型
Abstract:This paper introduces a 3-dimensional method of human body modeling which uses the hidden Markov model to explore the learning and working of human body behavior by identifying the behavior of various parts of human body from bottom behavior to top action as well as body's activity. Based on the above by inputting the natural language the corresponding video information could be obtained.
Key words: model of human body;transfer learning;HMM
引言
随着互联网及基础通信行业的不断发展,视频影像逐渐成为社交媒体的主要方式之一,但是海量的视频信息大部分未能得到有效利用。而且,随着人口老龄化问题的突出与加剧,有关老年人照顾问题也对视频分析领域提出了更多的需求。相对于国外来说,国内的人体动作识别起步较晚,但是近些年却呈现良好进步态势[1-2]。成效卓著的当数中国科技大学的王上飞团队[3],通过使用自身采集的NVIE数据库针对人体行为和自发表情的图片去训练网络。而本文则主要研究了人体复杂行为理解方法,通过建立人体三维模型,分层次地应用隐马尔科夫模型,组合低层次的行为识别结果信息,并应用迁移学习,融合已有的数据库实现人体复杂行为理解。应用本文提出的算法,可以通过输入特定行为或活动的自然语言描述,最终成功达到视频检索的功能目的。
1 人体复杂行为的表示方法
1.1 行为、行动的表示
行为和活动有多种不同情况,运动状态可能是持续的(如行走、跑步),或具有可定位的特征(如抓、踢)。要知道人在某时的发生动作,需要由时间尺度来刻画。在本次的研究中,即把短时的运动称为行为,如向前走一步,如走路、跑步、跳跃、站立、挥舞。因而,可以辨识区分短时间尺度表示(行为),就像前进;中等时间的运动称为行动,如走路、跑步、跳跃、站立、挥手,其时间范围可以很短、但有些或许稍微长些,通常是多种行为的组合;研究中把长时间的运动称为活动,活动是复杂的行动的组合。为了处理活动,需要对行动建立模型。复杂的组合活动由一组基本的行动模型组成,利用人体的运动学模型作为行动模型特征。
1.2 肢體活动模型
肢体的行动模型建立后,将肢体行动模型通过状态转移概率串联成一个更大的隐马尔科夫模型。设行动A处于状态m,行动B处于状态n,定义状态m和状态n之间的距离为:
其中,om和on是转移值;p(om)和p(on)是转移概率;N是可能的转移状态数量;C(om,om)是转移值中心之间的欧几里德距离,而且也是矢量量化的三维关节点的聚类中心。
状态按肢体分组,将与一个特定肢体模型相对应的一组状态称为肢体活动模型。而身体各个部分的活动在隐马尔科夫模型下的描述则如图1所示。在连接这些状态时,可将当前行动转移到其它行动,若当前行动不发生转移,对其可分配相同的概率。计算每个状态的概率序列由一组确定行动的隐马尔科夫模型运算产生。
1.3 位置跟踪
跟踪器会输出人体的二维位置,但是不能提供研究需要的三维位置信息。研究人员也陆续展开了多种方法的探讨与攻关,如通过连续多帧的图像数据间的运动关系、双目立体视觉法、动态规划相机法等获取三维信息。其中,动态规划相机方法是通过动态规划相机的移动位置,来设计创建多角度的人体图像获取,进而恢复出人体的三维姿态。该方法的不足是如果没有捕捉到运动,则不能获得理想的图像匹配。本文在动态规划相机法基础上,提出如下设计改进:把身体分解成4个部分(2条胳膊,2条腿)。用局部匹配的方法匹配腿,但允许左右腿来自不同的运动捕捉片段 搜索20个摄像头的观看方向。每帧的匹配代价反映了相机在根坐标系下运行捕捉情况。以类似的方式选择手臂和腿,要求相机靠近腿。在研发实践中,这个方法能够从较小的运动中获得相当丰富的运动序列的捕捉集合。由此研究可得,行走、拾取、搬运的后验概率可如图2所示。
1.4 查询活动
为了找到某一特定事件发生时的视频记录,通过视频回看寻找视频所表达的活动,通过输入各个肢体的活动名称,得到符合该活动描述的视频图像数据,实际上,并不需要精确得到活动发生的确切时间点,而是只要找到这个活动发生的可能的时间序列位置即可。研究中,通用的运动查询方法就是正则化表达式的方法。对应的计算公式可表述如下:
将正则表达式替换为有限状态机后,利用sum-product方法计算这个状态机达到最终状态的概率。
假设研究要查找正在走路并且挥舞着双手的视频。对于腿,赋予一个走路的状态机。对于手臂,赋予挥舞的状态机。同时查询两者的状态机。图3、图4所示即为相应的查询状态机。
在形成有限状态机时,每个动作有一个单位长度ux。查询字符串被转换为正则表达式 然后基于这些单位长度的行动得到一个FSA。单位行动的长度与2个因素有关。一个是视频的fps,另一个是行动的可持续性的水平。行走和跑步等行为是可持续的,单位长度会定义得较长,而一些原地的运动,比如跳跃或触摸,则会定义得较短。
本方法不需要输入要查询的视频的图像例子,只要知道想要查询的视频的语意描述,便可以快捷查询到相关视频信息。
至此,研究中还涉及到复杂的复合查询编写。例如,欲搜索顺次标定有步行、站立、挥舞、步行、步行的视频序列,将得到一个人走进视野,站立和挥舞,然后走出视野视频图像。图4就展示给出了搜索走步、拾取、搬运。通过输入不同的查询信息实现不同复杂的行为检索。手臂和腿分开查询,因为拾取和蹲伏的动作在腿部的行动非常相似,为此就加设了一个“或”的查询以获得更广泛的搜索。
2 实验及分析
本文使用JAFFE和FER2013数据库对识别率的精度进行了测试。
为了测试及验证的便捷性,使用Matlab搭建了GUI交互的界面,使用电脑USB摄像头捕捉的实时视频截取图片,并提送测试结果的识别。
为了直观地验证、查证研究建立的卷积神经网络,编写了neuralnetwork.m函数。此函数可以观看建立的网络的训练、执行速度,梯度计算结果,以及有效性检查等参数。设计运行结果如图6所示。
为了测试系统的识别率,把2个数据库分别留有的100张256*256像素待测试的图片集聚成如图7格式所示的.mat文件。即把256*256的图片数据每一行首尾相接,组成1*65 536的向量,每一行代表一幅图片。
在此基础上,可使用如下的语句,计算网络预测结果,并与正确的结果展开对比,得到识别率。Theta1 Theta2为卷积神经网络的权值参数,采用这样的自动测试流程可以大大提升测试的效率。研发可得设计代码如下:
3 结束语
在当下的人体行为的识别研究中,仍然亟待建成一个规范、完善的数据库,且使未来的识别研发方法能够有效应用在不受控制的环境中。如没有正面的面部,部分遮盖的图像,自发的表情等等)。类似这样的问题,对目前的学术工程界也仍可堪称现实挑战[4-6]。本论文的研究主要立足于识别算法的普适性上,并且重点围绕在受控制的背景环境中,使经过训练的识别算法能够具有全局适用性,即可应用于不同国籍、不同种族的人体行为识别中。
参考文献
[1] 高文,金辉. 面部表情圖像的分析与识别[J]. 计算机学报,1997,20(9):782-789.
[2] 金辉,高文. 基于HMM的面部表情图像序列的分析与识别[J]. 自动化学报,2002,28(4):646-650.
[3] WANG Shangfei LIU Zhilei LV Siliang. A natural visible and infrared facial expression database for expression recognition and emotion inference[J]. IEEE Transaction on Multimedia,2010,12(7):682-691.
[4] LIU Mengyi LI Shaoxin SHAN Shiguang et al. Au-inspired deep networks for facial expression feature learning[J]. Neuro computing 2015,159(2): 126-136.
[5] MEGUID M K A E LEVINE M D.Fully automated recognition of spontaneous facial expressions in videos using random forest classifiers[J]. IEEE Transactions on Affective Computing 2014,5(2):141-154.
[6] TURAN C LAM K M. Regionbased feature fusion for facialexpression recognition[C]//IEEE International Conference on Image Processing (ICIP). Paris France:IEEE 2014: 5966-5970.
猜你喜欢
数字技术与应用(2018年4期)2018-08-18
文学教育(2018年7期)2018-07-17
现代商贸工业(2018年11期)2018-04-24
科技视界(2017年32期)2018-01-24
课程教育研究(2017年46期)2017-12-27
电脑知识与技术(2017年32期)2017-12-15
现代交际(2017年18期)2017-09-11
振动工程学报(2017年1期)2017-04-21
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年14期)2015-07-22
