
一种基于邻域与位置时间感知的会话推荐方法
2023-12-01 03:44:10谭小辉祁正华张海桃何菲菲
软件导刊 2023年11期
谭小辉,祁正华,张海桃,何菲菲
(南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210023)
0 引言
如今,推荐系统已广泛应用于每一个数字平台,这些平台试图根据用户需求调整服务,以提高用户满意度[1]。在推荐系统研究中,大部分工作集中在依靠长期偏好模型为用户提供推荐的技术上。但在推荐系统应用的多个领域,用户通常是匿名的,用户的个人资料和长期互动历史记录难以获取,唯一可用的信息是匿名用户在当前会话中的交互序列。因此,合理的推荐必须基于其它类型的信息(如用户最近与网站或平台的互动情况)来确定[2-4]。为解决这些问题,基于会话的推荐系统(Session-based Recommender System,SBRS)悄然兴起。SBRS 通常利用基于神经网络[5-7]或邻域的方法[8-10]对会话中的历史交互序列进行建模,以捕获会话的兴趣为用户进行推荐。如Hidasi 等[5]将所有匿名用户浏览历史中的会话信息作为递归神经网络(Recurrent Neural Network,RNN)的输入序列,通过修改RNN 中的排名损失函数以及引入小批次的输出采样,使其在基于会话的场景下提升了推荐性能,但是模型训练需要大量数据(特别是密集的数据)。在可利用会话数据较少的情况下,基于邻域的方法具有较好的推荐效果。Jannach等[8]将K 近邻(K Nearest Neighbor,KNN)方法用于会话推荐,提出了SKNN(Session-based KNN)方法。SKNN 利用会话的交互数据,在训练集中确定过去最相近的K 个邻居会话,按照每个邻居会话与当前会话的相似度给候选项目打分。Garg 等[10]利用项目序列与会话之间的时间间隔,提出一种序列和时间感知邻域(Sequence and Time Aware Neighborhood,STAN)推荐方法。STAN 没有像SKNN 一样为会话中的所有项目赋予同等权重,而是根据项目序列和会话的起始时间来考虑项目与会话的权重,并为所考虑的特征设置不同的衰减函数。然而,以上方法仍然面临一些问题:①没有综合考虑整个会话中一般偏好与当前偏好对推荐结果的影响;②寻找候选项目时忽略了项目在会话中的时间信息,难以捕获到邻居会话与候选项目之间的关联;③忽略了匿名用户误点行为对推荐结果的影响。
为解决上述存在的问题,本文的主要工作如下:
(1)利用会话中的项目序列和时间信息,构建一种基于邻域与位置时间感知的会话推荐(Neighborhood and Position Time Awareness Session Recommendation,NPTAS)方法。该方法主要分为3 部分:①为综合考虑整个会话的一般偏好与当前偏好,利用会话中的项目位置和持续时间信息来分别捕获会话的当前偏好与一般偏好,并以此得到会话的偏好表示向量;②为找到兴趣最接近的邻居会话,利用会话的起始时间信息捕获会话之间的时间相关性,并以此得到会话之间的相似度权重;③利用候选项目在会话中的位置及持续时间信息捕获邻居会话与候选项目的相关性,并以此得到邻居会话对候选项目得分的贡献权重。同时为会话中持续时间短的项目赋予较小权重,以减少用户误点行为对推荐结果的影响。
(2)在两个真实的新闻数据集上进行实验,通过与现有方法进行对比,验证了该方法的有效性,同时分析了NPTAS 的变体方法和影响NPTAS 方法推荐性能的参数。
1 相关工作
基于会话的推荐系统利用匿名用户在交互过程中产生的会话数据挖掘和学习用户偏好,现有的SBRS 可分为基于神经网络和基于邻域的方法。
基于神经网络的SBRS 大多采用递归神经网络结构。GRU4REC[5]是一个基于RNN 的SBRS 模型,通过使用门控循环单元(Gate Recurrent Unit,GRU)为活动会话生成推荐列表,并针对应用场景,对数据特征的处理方法和神经网络结构中的排名损失函数进行修改,提高了模型对于会话场景的适应度。Li 等[11]通过一种带有注意力机制的混合编码器来模拟用户的交互行为,并捕获用户在当前会话中的主要目的,然后利用RNN 为每个会话生成一个会话表示向量,以此计算每个候选项目的推荐得分;Pang 等[12]提出一种考虑时间因素的自注意机制来学习用户的短期兴趣,并将其与用户的长期兴趣相结合进行会话推荐。
基于邻域的SBRS 通过在训练阶段建立邻里关系来进行会话推荐。基于项目的K 近邻(Item-based K Nearest Neighbors,IKNN)[13]是一种朴素的方法,通过利用活动会话中的最后一个项目来寻找邻居,传统上被认为是SBRS的基线。Jannach 等[8]利用一种基于整体性的方式从历史会话中寻找兴趣最接近的邻居会话,再根据邻居会话得到相应的候选项目。考虑到会话数据中项目的排列顺序在用户推荐过程中的重要性,Ludewig 等[9]对SKNN 进行扩展,提出了VSKNN(Vector Multiplication SKNN)方法,通过给予会话中最近的项目更多权重来捕获会话兴趣。为了利用会话数据中的更多特征来提高推荐结果的准确率,Garg 等[10]利用项目位置、会话间的时间差和项目在邻居会话中的点击距离等信息进行会话推荐,并为这些信息特征设置了相应的衰减函数来调整其对于推荐结果的贡献度。最近,Ludewig 等[14]将STAN 与VSKNN 的思想相结合提出VSTAN(Vector Multiplication STAN)方法,在STAN 基础上添加了一种加权方案,给频繁出现的项目以较低权重。虽然基于邻域的方法相对简单,但是关于SBRS 的研究表明[2,14-16],在某些场景下基于邻域的SBRS 方法在准确性和计算成本等方面都优于目前基于复杂神经网络的SBRS方法。
2 NPTAS方法
本文在分析多种基于邻域的SBRS 方法基础上,从数据集中提取项目在会话中的位置和时间等信息,设计了一种基于邻域与位置时间感知的会话推荐方法(NPTAS),其整体结构如图1所示。
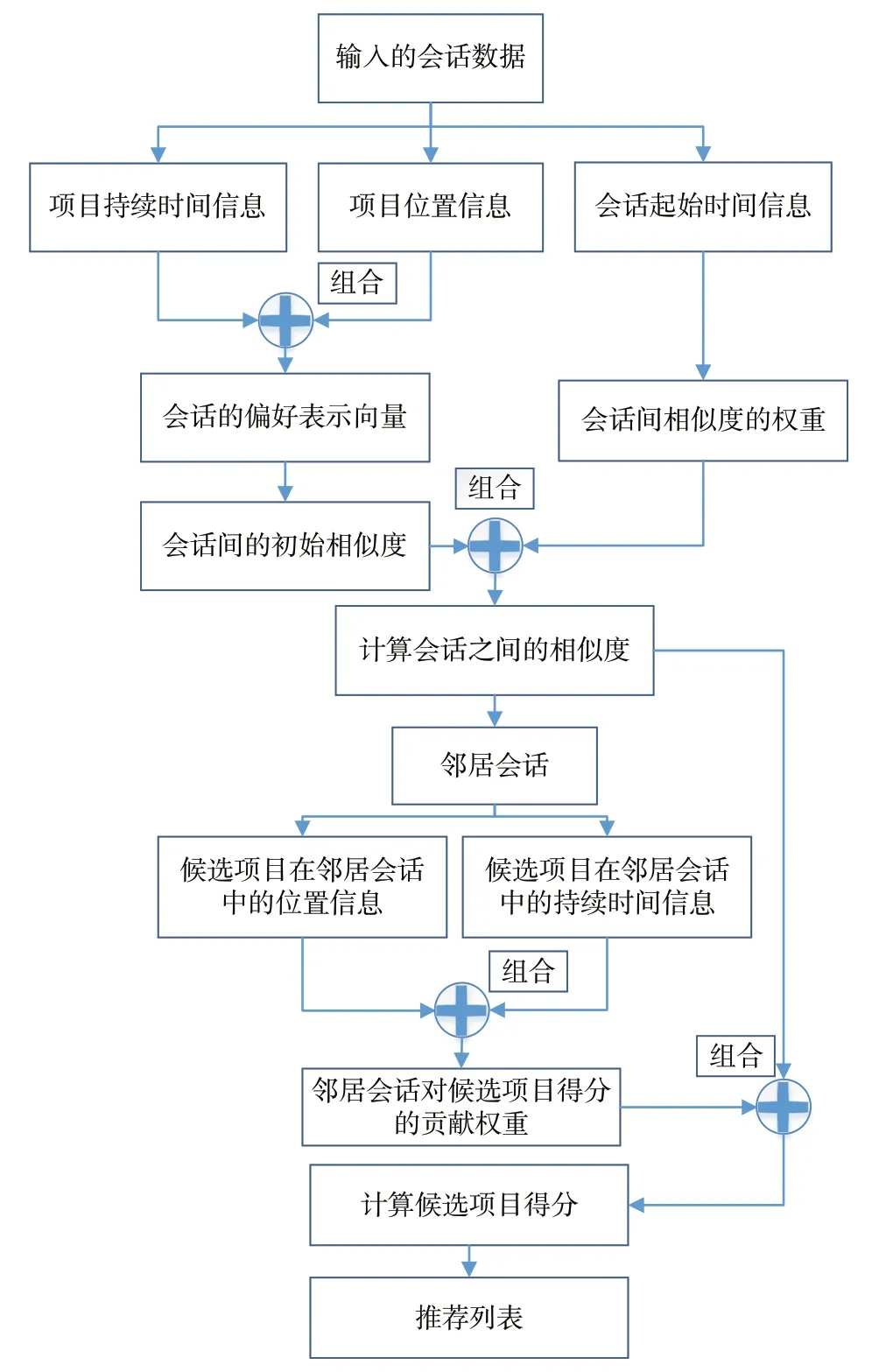
Fig.1 NPTAS method architecture图1 NPTAS方法结构
NPTAS 方法的具体实现可分为以下3部分:
(1)计算会话之间的初始相似度。利用会话中项目的位置和持续时间信息来捕获会话的当前偏好与一般偏好,并以此构建会话的偏好表示向量,再利用会话的偏好表示向量计算会话之间的初始相似度。
(2)构建邻居会话。首先利用会话间起始时间的差值来计算会话之间的相似度权重,然后将其与会话间的初始相似度相结合,得到会话之间的相似度,最后根据会话之间的相似度为每个会话选取对应的邻居会话。
(3)计算候选项目得分。利用邻居会话中候选项目的位置和持续时间信息来计算邻居会话对会话内某个候选项目得分的贡献权重,将此贡献权重与对应会话之间的相似度相结合,得到邻居会话对此候选项目得分的贡献值。通过将所有邻居会话对此候选项目得分的贡献值相加,得到此候选项目的最终得分。
2.1 问题描述
S={s1,s2,...,sm-1,sm}表示会话集,其中历史会话集Sh={s1,s2,...,sm-1},sm表示当前会话。I={i1,i2,...,i|I|}表示S中所有项目的集合,其中|I|表示项目集I包含的项目个数。会话sm的交互序列St={it,1,it,2,...,it,n},其中it,j∈I,n 表示会话sm对应的交互序列长度。NPTAS 方法旨在通过计算候选项目i(i∈I)的相关性得分来给会话sm推荐下一个点击项目it,n+1。表1 定义了本文使用的主要符号。

Table 1 Definition of main symbols表1 主要符号定义
2.2 会话之间初始相似度计算
会话推荐以捕获会话的短期兴趣给会话作推荐为目的,而会话中最近的项目更能代表会话的当前偏好,需要为其赋予一个较高权重。因此,在仅考虑当前偏好时,项目i对会话sm偏好表示向量的贡献度为:
其中,λ11>0(λ11表示在构建会话偏好表示向量时项目位置信息的重要程度)。
考虑到会话的短期兴趣通常反映在最近的几次交互中,但最后一次交互不一定直接反映会话的当前兴趣,因此利用会话中每个项目的持续时间来捕获会话的一般偏好。会话中项目的持续时间占会话持续时间的比重越高,表明用户对此项目越感兴趣,需要为其赋予一个较高权重。同时,在会话数据中,每个会话都有可能存在由于匿名用户误点而产生的交互数据,这些交互数据并不能代表用户的真实意图。相反,还有可能降低该方法的推荐效果。考虑到此类项目在会话中的持续时间通常很短,因而需要为其赋予一个较低权重。因此,在仅考虑一般偏好时,项目i对会话sm偏好表示向量的贡献度为:
其中,λ12>0(λ12表示在构建会话偏好表示向量时项目持续时间的重要程度)。
为了更好地捕获会话兴趣,引入参数φ1来综合考虑会话的当前偏好和一般偏好。因此,会话sm的表示向量在项目i对应维度上的值为:
其中,φ1∈[0,1]。
利用式(3)计算会话sm在每个项目i对应维度上的值,得到会话sm的表示向量(以同样的方式可以得到会话st的表示向量),然后计算会话sm与st之间的初始相似度为:
其中,l(st)表示会话st包含的项目个数。
2.3 邻居会话构建
借鉴文献[17]中的思想,为距离会话sm较远的会话赋予较低权重。因此,会话st与sm之间的相似度权重为:
其中,λ2>0 且λ2≠1(λ2表示会话起始时间差对于会话间相似度权重的重要程度),t(sm) >t(st)。
然后,将会话st和sm之间的初始相似度与其对应的相似度权重相结合,得到会话st与sm之间的相似度为:
利用式(6)计算会话sm与其它会话之间的相似度,把这些相似度值由高到低进行排序,选取前N 个相似度值对应的会话作为会话sm的邻居会话N(sm)。
2.4 候选项目得分计算
得到N(sm)后,出现在会话n(n∈N(sm))中但没有出现在会话sm中的任何一个项目都是候选项目。在会话序列中,相邻项目的相关性很强,对于会话n中越靠近的项目应该被赋予较高权重。因此,在仅考虑邻居会话中候选项目位置信息的情况下,会话n对候选项目i得分的贡献权重为:
其中,λ31>0(λ31表示邻居会话中候选项目位置对于候选项目得分权重的重要程度),In表示会话n包含的项目集。
对于同一个会话中持续时间相近的项目,当前会话对其的兴趣程度是相近的,其之间可能存在着某种关联,所以也需为其分配一个较高权重。因此,在仅考虑邻居会话中候选项目持续时间信息的情况下,会话n对候选项目i得分的贡献权重为:
其中,λ32>0(λ32表示邻居会话中候选项目持续时间对候选项目得分权重的重要程度)。
然后,利用φ2综合考虑上述两个贡献权重,得到会话n对候选项目i得分的最终贡献权重为:
其中,φ2∈[0,1]。当项目i存在于会话n中时,1n(i)=1,否则,1n(i)=0。
接下来将会话n对候选项目i得分的贡献权重和会话n与sm之间的相似度相结合,得到邻居会话n对候选项目i得分的贡献值为:
其中,sim2(sm,n)表示会话sm与n之间的相似度。
最后,候选项目i推荐给会话sm的得分为:
3 实验结果与分析
3.1 数据集
实验采用的两个数据集均来自现实世界。包括:
(1)Globo.com。巴西新闻门户网站globo 建立的一个新闻推荐数据集,包含大约314 000 个用户、46 000 篇新闻文章和300万次点击记录[18-19]。
(2)Adressa。由adreseavisen 网站构建的一个新闻推荐数据集,分为简易版(收集1 周的数据)和完整版(收集3个月的数据)两个版本[19-20]。
本文遵循文献[19]中的处理方法对两个数据集进行预处理,将匿名用户在30min 内产生的一系列点击事件视为一个会话,同时移除少于两个交互的会话。考虑到Globo.com 数据集只包含16 天的交互数据,因此在Adressa 数据集中只选择20 天的交互数据(整个数据集包含3 个月的交互数据)。表2为各个数据集的基本信息。

Table 2 Dataset basic information表2 数据集基本信息
为得到训练集和测试集,本文使用文献[19]中的方法,对于Globo.com 数据集,将每4 天分成一个子数据集,子数据集中前3 天的会话数据作为该组的训练集,剩下1 天作为该组的测试集。对于Adressa 数据集,由于一天内的会话数据较少,将10 天分成一个子数据集,同时为保持与Globo.com 相似的训练数据大小,对其训练天数进行了延长。
3.2 基准方法
在两个数据集上与6 个基准方法进行对比:①SKNN[8]是一个将K 近邻应用到会话场景下的推荐方法;②STAN[10]是SKNN 的一个扩展方法,具有3 个可控的时间衰减因子;③VSTAN[14]是STAN 的一个扩展方法,额外添加了逆文本频率指数(Inverse Document Frequency,IDF)加权方案;④GRU4Rec[5,21]是第一个采用RNN 进行会话推荐的模型,通过构建门控递归神经网络进行会话推荐;⑤STAMP[22]是一个短期注意优先模型,引入了注意机制来建模用户每次历史点击和最后一次点击之间的关系;⑥SRGNN[23]是一个基于会话的推荐器,使用图神经网络捕捉项目的复杂转换。
3.3 评估指标
为了评估推荐效果,采用文献[20]中的3 个评估指标,分别是:
(1)HR@K。命中率,其定义为:
其中,R(sm)为根据会话sm在训练集上的浏览记录给会话sm作出的推荐列表,T(sm)为会话sm在测试集上的浏览列表。
(2)NDCG@K。归一化折损累计增益,其定义为:
其中,reli表示第i个推荐的相关程度,当项目i被选中时,reli=1,否则reli=0;IDCG 是归一化的DCG,即根据理想排序获得的最大DCG 值。
(3)ILD@K。列表多样性,评估推荐列表中的主题多样性,并反映方法向同一用户推荐不同项目的能力,其定义为:
其中,d(ɑ,b)是项目ɑ与项目b之间距离的度量,如果项目ɑ和项目b属于不同主题(类别),d(ɑ,b)=1,否则d(ɑ,b)=0。
3.4 推荐方法结果比较
将NPTAS 方法与基准方法在两个数据集上进行比较,实验结果如表3所示。
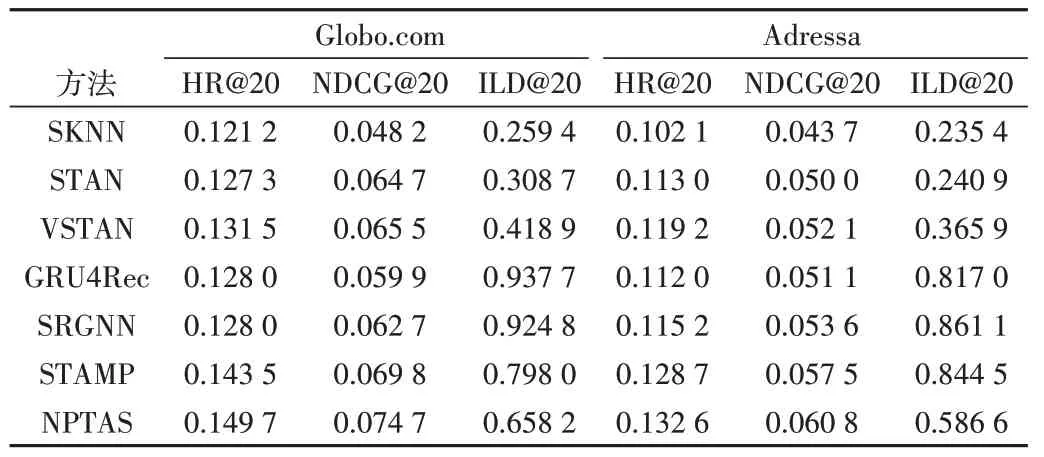
Table 3 Performance comparison of different methods on two datasets表3 两个数据集上不同方法性能比较
从表3可知:
(1)在Adressa 和Globo.com 数据集上,NPTAS 方法相较于SKNN、STAN 和VSTAN 等基于邻域的会话推荐方法,HR@20 和NDCG@20 指标均有不同程度的提升(除SKNN和VSTAN 外,其余基线方法的结果均来自文献[20])。这是因为NPTAS 利用会话中项目的持续时间和位置信息来挖掘会话的一般偏好与当前偏好,更好地挖掘了当前会话的短期兴趣。而SKNN 平等地对待会话中的所有项目,难以找到当前会话的兴趣。STAN 和VSTAN 只重视当前会话中最近的项目,忽略了当前会话的一般偏好。其次,NPTAS 考虑了会话中项目的停留时间,这在很大程度上降低了会话中误点记录对于推荐结果的影响。此外,NPTAS方法相较于现有基于神经网络的方法(包括GRU4Rec、STAMP 和SRGNN),HR@20 和NDCG@20 指标也均有所提升,说明NPTAS 方法在某些方面的推荐效果可以与现有的神经网络模型相媲美。
(2)在Adressa 和Globo.com 数据集上,NPTAS 方法相较于SKNN、STAN 和VSTAN 等基于邻域的会话推荐方法,ILD@20 指标得到了极大提升。说明相较于基于邻域的基准方法,NPTAS 方法能更好地利用会话信息来发现用户潜在的多样化兴趣。同时发现NPTAS 方法相较于基于神经网络的方法(包括GRU4Rec、STAMP 和SRGNN),ILD@20指标有所下降,说明基于神经网络的方法能更好地为用户推荐多样化的列表。
3.5 方法变体分析
将NPTAS 方法与其3 种变体方法进行比较:①变体NPTAS-W1。不使用会话中项目的位置和持续时间来捕获会话的当前偏好与一般偏好,即给予会话中每个项目相同的权重;②变体NPTAS-W2。不利用会话之间的起始时间来考虑会话之间的时间相关性,即给予所有邻居会话相同的相似度权重;③变体NPTAS-W3。不使用候选项目在邻居会话中的位置及持续时间信息来捕获邻居会话与候选项目的相关性,即给予邻居会话中候选项目平等的权重。图2、图3 分别显示了在Globo.com 和Adressa 数据集上的实验结果。
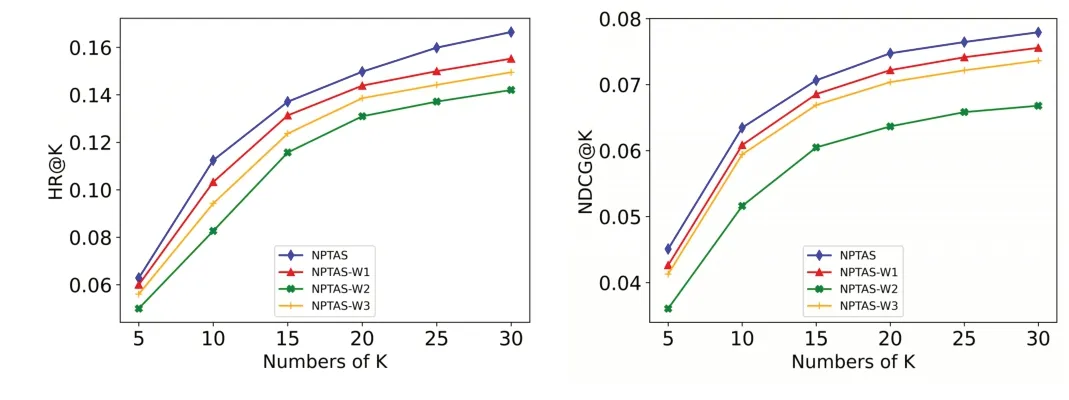
Fig.2 Experimental results of the NPTAS variant method on the Globo.com dataset图2 Globo.com数据集上NPTAS变体方法实验结果
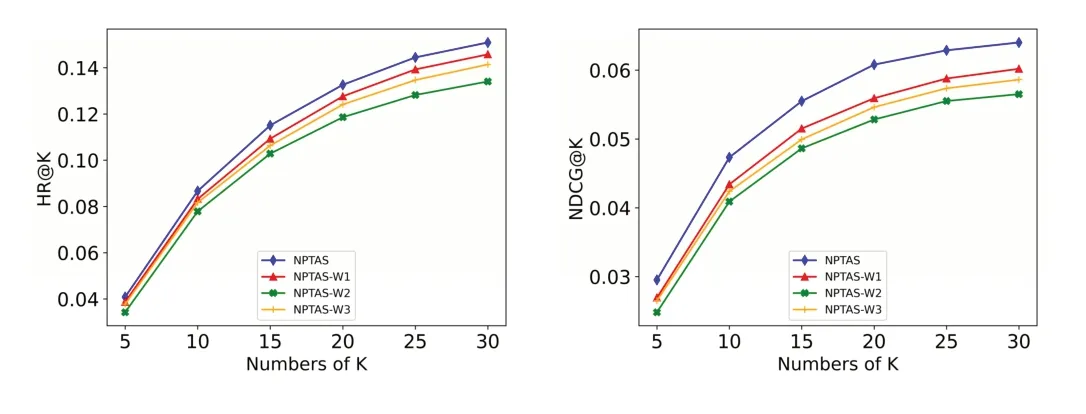
Fig.3 Experimental results of the NPTAS variant method on the Adressa dataset图3 Adressa数据集上NPTAS变体方法实验结果
从图2、图3 可以看出,当NPTAS 方法不使用会话之间的起始时间来考虑会话之间的时间相关性时,HR@K 和NDCG@K 指标下降最为明显。说明在NPTAS 方法中,利用会话起始时间之差来考虑会话之间的相关性是必要的。这是因为使用会话之间的起始时间差来考虑会话之间的时间相关性时,可以找到兴趣更接近的邻居会话。当NPTAS 方法不使用会话中项目的位置和持续时间来捕获会话的当前偏好与一般偏好时,NPTAS 方法在HR@K 和NDCG@K 指标上有所下降,说明利用项目在会话中的位置和持续时间来考虑会话的当前偏好与一般偏好是合理的。同时发现,NPTAS 方法不使用候选项目在邻居会话中的位置及持续时间信息来捕获邻居会话与候选项目的相关性时,HR@K 和NDCG@K 指标也有所下降,说明利用候选项目在邻居会话中的位置及持续时间信息来捕获邻居会话与候选项目的相关性也是合理的。
3.6 方法参数分析
主要分析在Globo.com 数据集中,NPTAS 方法中的7个参数对方法HR@20 指标的影响,实验结果如图4 所示(在其它数据集中也观察到相似的结果)。其中,NPTAS 方法中7个参数在两个数据集上的最优值如表4所示。
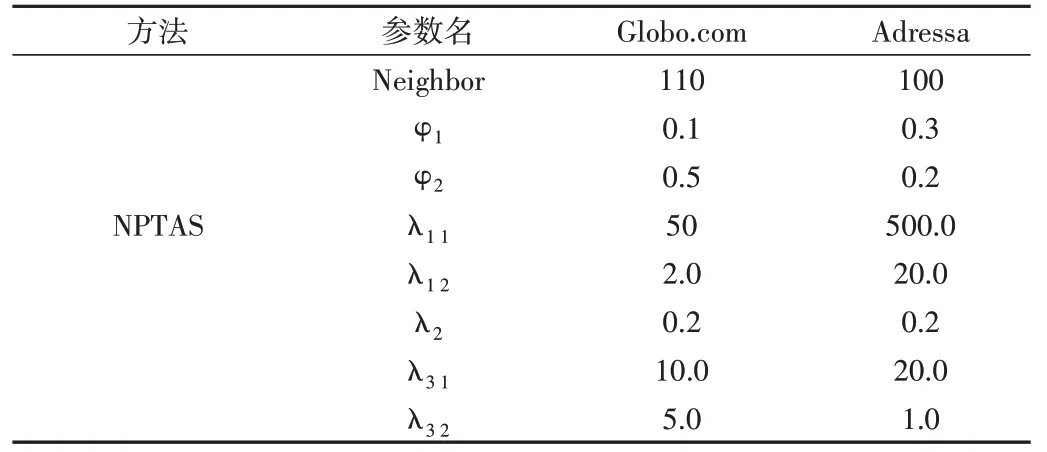
Table 4 Optimal parameter values for the NPTAS method表4 NPTAS方法最优参数值
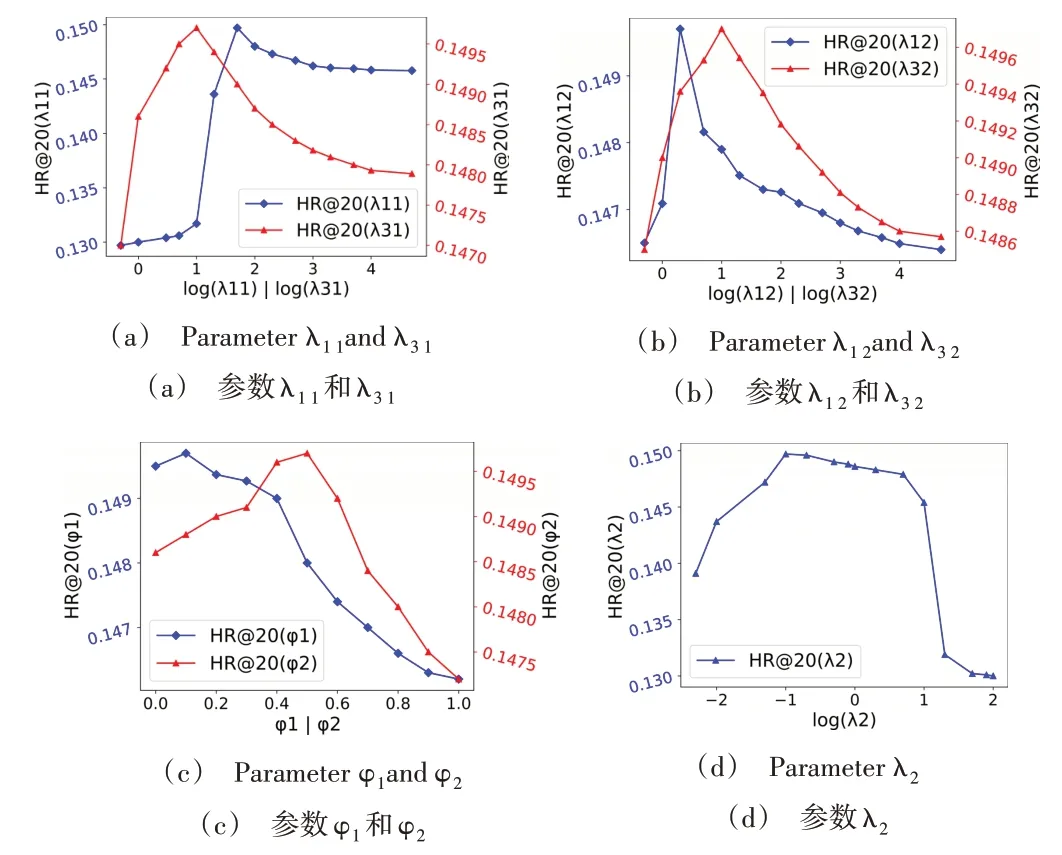
Fig.4 Effect of seven parameters on the NPTAS method HR@20 metric on the Globo.com dataset图4 Globo.com数据集上7个参数对NPTAS方法HR@20指标的影响
从图4(a)中可以看出,只考虑最近项目(λ11<<1),而忽视会话中的其它项目,或把会话中每个项目平等看待(λ11→∞),结果都不是最优。除最近的项目外,当前会话中的其它项目也很重要,但不如最近的项目重要。λ31在NPTAS 中发挥了重要作用,因为HR@20 根据λ31的不同发生了显著变化,当只利用推荐会话中被点击项目在邻居会话中的相邻两个项目(λ31<<1),或者给予邻居会话中所有项目相同的得分权重(λ31→∞),取得的效果都不是最佳的。当利用λ31来控制项目位置对于项目得分权重的重要性,取得的效果更好。
在图4(b)中,发现只利用会话中停留时间长的项目(λ12<<1)或给予当前会话中所有项目同等权重(λ12→∞),效果都不佳。在给予会话中持续时间长的项目较高权重时,也需要考虑会话中的其它项目。同时发现,仅考虑和邻居会话中项目持续时间相近的项目(λ32<<1)或给予邻居会话中所有项目同等权重(λ32→∞),效果都不是最佳的。利用λ32来控制项目持续时间对于项目得分权重的重要性,所取得的效果更好。
由图4(c)可以看出,仅考虑最近的项目(φ1→1)或会话中持续时间长的项目(φ1→0)都不能很好地捕获当前会话的短期兴趣。使用φ1综合考虑当前会话的一般偏好和当前偏好所表现出来的效果更好。随着φ2从0 开始不断增大,推荐结果的准确率不断提高,说明候选项目在邻居会话中的位置信息十分重要,只考虑候选项目在邻居会话中的持续时间(φ2→0)所取得的效果不是最佳的。但随着φ2的继续扩大,推荐结果的准确率开始下降,说明只考虑候选项目的位置信息(φ2→1)所取得的效果也不是最佳的,使用φ2来控制这两个因素的重要性所取得的效果更好。
从图4(d)中明显看出,仅考虑最近的历史会话(λ2<<1)或给予所有历史会话同等权重(λ2→∞)都降低了推荐效果,使用λ2来控制历史会话的权重,取得的效果最好。除最近的历史会话外,其它历史会话也很重要,但其重要性低于最近的历史会话。
从表4 可以看出,NPTAS 方法在不同数据集上的最优参数值各有不同,说明了实验选取数据集的多样性,以及NPTAS 方法能通过调整参数来适应各种应用场景的能力。
4 结语
本文提出一种基于邻域与位置时间感知的会话推荐方法(NPTAS),该方法通过捕获会话的一般偏好与当前偏好来构建会话的表示向量,利用会话的起始时间来获取会话相似度的权重因子,并利用会话中项目的持续时间来减小由于匿名用户误点产生的影响,最后利用邻居会话中候选项目的时间和位置信息来捕获邻居会话对候选项目得分的贡献度,有效挖掘了用户的短期兴趣。在后续工作中,将利用会话数据中隐含更深的信息来挖掘匿名用户的短期兴趣,提升推荐效果。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
数学物理学报(2019年6期)2020-01-13 06:08:16
自动化学报(2018年7期)2018-08-20 02:59:04
数学物理学报(2017年5期)2017-11-23 07:51:31
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:37
海外华文教育(2016年3期)2017-01-20 08:22:18
周口师范学院学报(2016年5期)2016-10-17 06:36:47
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:48
山西大同大学学报(社会科学版)(2014年5期)2014-01-23 01:30:51
